为Tesseract适配多语言模型
摘要:我们描述了将Tesseract开源OCR引擎用于多种脚本和语言的工作。人们的努力集中于实现通用的多语种操作,以至于一种新的语言除了提供文本语料库之外,还需要进行微不足道的定制。尽管需要对各个模块进行更改,包括物理布局分析和语言后处理,但字符分类器不需要更改几个限制。Tesseract的分类器很容易适应简体中文。从随机抽取的书籍中的英语,欧洲语言的混合物,和俄语进行测试,结果显示出相同且一致的错误率,即在3.72 %和5.78 %之间,而简化汉字的错误率仅为3.77 %。
介绍(radicals in Han, Jamo in Hangul, and letters in Hindi)
汉语和日语都是汉字,包含几千种不同的字形。研究特定语言的解决方案比通用更容易实现。例如,汉字、韩文和印地语的大型字符集主要由数量少得多的组成部分组成,这些组成部分在汉语中被称为偏旁/部首,在韩文中被称为词根,在印地语中被称为字母。由于为少数类开发分类器要容易得多,一种方法是识别偏旁[参考文献1,2,5],并从偏旁的组合推断出实际的字符。这种方法对韩文来说比对汉文或印度语更容易,因为韩文中词根形状变化不大,但是在汉语中,偏旁经常被压扁来适应汉字,而且大多与其他偏旁挨着。又比如阿拉伯语,很难通过将连通区域分割为字符的方法来确定字符边界。一种常用方法是将单个垂直像素strips分类,每个像素strips都是一个字符的一部分,并将分类中引入HMM模型,该模型对字符边界建模[参考文献3]。
本文基于Tesseract,讨论了我们在其国际化的方向上所做的工作,其中一些可能能够轻松实现。我们采用了语言泛化的模式/方法,以此来尽量少覆盖多语言的手工工作。
拉丁语的Tesseract的回顾
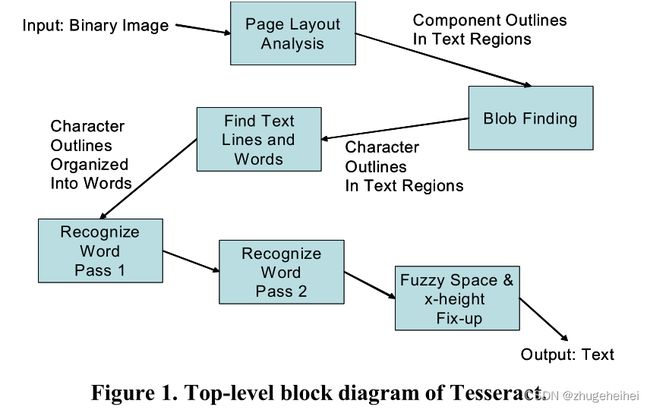
Tesseract的新的版面分析技术从一开始就被设计为语言无关的[参考文献10],但引擎的其余部分是为英语开发的,并没有过多考虑如何适配其他语言。在注意到当时的商业引擎严格的使用black-on-white文本后,Tesseract最初的设计目标之一是它应该像识别black-on-white黑白文本一样容易识别white-on-black(逆视频)文本。这使得设计(结果很偶然)朝着连接组件(CC,Connected component)分析的方向发展,并对组件的轮廓进行操作。在连通组件分析后的第一步就是在文本区域中寻找blobs。一个blob是一个假定的分类单元,可能是一个/多个水平重叠的CCs及其内部的嵌套轮廓/洞(holes)。问题在于检测box内的inverse文本还是字符里面的洞。对于英语来说,很少有字符有超过2级的轮廓(如© and ®),而且也很少有超过2个的洞,因此任何打破这些规则的blob一定是一个包含有inverse 字符的box,甚至是围绕黑白black-on-white字符的框架的内部/外部。
在确定哪些轮廓构成blobs后,文本行检测器通过文本行上相邻字符的垂直重叠来检测(仅水平)文本行。【参考文献11】。对于英语,这个重叠和基线表现得很好以至于他们可以用来非常精确地检测到一个非常大角度的倾斜。在找到文本行后,固定音高检测器检查固定音高字符布局,并根据固定音高采用两种不同的单词分割算法之一进行运行。识别过程的大部分是独立地对每个单词进行操作,然后是最终的模糊空间解析阶段,在这个阶段中确定不确定的空间。
下图2是单词识别器的架构。在大多数情况下,一个blob对应一个字符,因此单词识别器首先对每个blob进行分类,并将结果提供给字典搜索,以便在单词中每个blob的分类器选择的组合中找到一个单词。如果结果不好,则下一步就是删除难以识别的字符,这提高了分类器的置信度。在穷举分割可能性后,对所得到的分割图进行最佳搜索,这会将切碎的字符片段或在原始图像中被分割成多个CCs的字符部分重新组合在一起。在最佳优先搜索的每一步中,对任何新的blob组合进行分类,并将分类器结果再次提供给字典。单词的输出是根据单词是否在字典中和/或是否有合理的标点符号排列进行加权后,具有最佳的基于距离的总体评级的字符串。在英文版本中,大多数标点规则都是硬编码的。

图像中的文字被处理了两次。在第一阶段中,成功的单词,即字典中没有危险歧义的单词,被传递给自适应分类器进行训练。一旦自适应分类器有足够的样本,它就可以提供(最后的)分类结果,即使是在第一阶段。在第二阶段中,第一次传递中不够好的单词进行第二次处理,第二次处理,以防自适应分类器在第一次遍历单词后获得了更多信息。
从前面的描述来看,对于非拉丁语言,这种设计显然存在问题,一些更复杂的问题将在第3、4和5节中处理,但有些问题只是简单的复杂工程。例如,字符类的一个字节代码是不够的,但是它应该被UTF-8字符串或更宽的整数代码所取代吗?起初,我们为拉丁语言改编了Tesseract,并将字符代码更改为UTF-8字符串,因为这是最灵活的,但这最终导致了字典表示的问题(参见第5节),因此我们最终使用UTF-8字符串表的索引作为内部类代码。
- 版面预处理
Tesseract的“textord”(文本排序)模块的几个方面需要更改,以使其更加独立于语言。本节将讨论这些更改。
3.1 垂直文本布局
汉语、日语和韩语在不同程度上都是水平或垂直阅读文本行,而且经常在同一页上混淆方向。这个问题并不是CJK独有的,因为英文杂志页面经常在照片或文章旁边使用垂直文字来表示摄影师或作者。
垂直文本由页面布局分析检测。如果大多数在制表位上的ccs都满足:CCs的左边在左边制表位上,CCs的右边在右边制表位上,那么制表位之间的所有内容都可以是一行垂直文本。为了防止表中的假阳性,进一步的限制要求垂直文本在ccs之间的垂直间距中值小于ccs的平均宽度。如果页面上的大多数ccs是垂直对齐的,则将页面旋转90度,并再次运行页面布局分析,以减少在垂直文本中发现假列的机会。
在旋转后的页面中,原本水平的少数文本将变成垂直文本,而文本正文将是水平的。

在最初的设计中,Tesseract没有处理垂直文本的能力,并且在代码中有很多地方假设字符被安排在水平文本行上。幸运的是,Tesseract操作的是有符号整数坐标空间中ccs的轮廓,这使得90度的倍数旋转变得微不足道,并且它不关心坐标是正还是负。的垂直和水平文本块进行不同的旋转。因此,解决方案很简单,就是不同地旋转页面上的垂直和水平文本块,并根据分类需要旋转字符。图3显示了英文文本的一个例子。图3(a)中的页面包含右下角的垂直文本以及其余的文本,在图3(b)中检测到。在图4(下图)中,垂直文本区域顺时针旋转90度,(在图像的左下角居中),因此它看起来远低于原始图像,但在水平方向。

图5显示了中文文本的示例。主要垂直的主体文本从图像中旋转出来,使其水平,而最初水平的标题则保持在起始位置。垂直和水平文本块在坐标空间中分离,但Tesseract只关心文本行是否水平。文本块的数据结构记录了在块上执行的旋转,因此当字符传递给分类器时,反向旋转可以应用于字符,使它们直立。自动方向检测[12]可用于确保文本在传递给分类器时是直立的,因为垂直文本可能具有相对于阅读方向至少有3个不同方向的字符。在Tesseract处理旋转后的文本块后,坐标空间将重新旋转回原始图像方向,以便报告的字符包围框仍然准确。

3.2 文本行和单词查找
最初的Tesseract文本行查找器[11]假设组成字符的cc大部分垂直重叠文本行。唯一的例外是i点。对于一般语言来说,这是不正确的,因为许多语言的变音符号位于文本行的上方和/或下方。例如,对于泰语,从文本行主体到变音符的距离可能非常大。Tesseract的页面布局分析旨在通过将文本区域细分为具有统一文本大小和行间距的块来简化文本行查找。这使得强制拟合行间距模型成为可能,因此文本行查找已被修改以利用这一点。页面布局分析还估计文本区域的剩余倾斜,这意味着文本行查找器不再对倾斜不敏感。
改进后的文本行查找算法从布局分析开始对每个文本区域独立工作,首先搜索小CCs的邻域(相对于估计的文本大小)来寻找最近的body-text-size CC,如果附近没有body-text-size CC,则将小CC视为可能的噪声,并丢弃。(虚线导语除外,通常在目录中可以找到。)否则,将构造一个包含小CC及其较大邻居的包围框,并在接下来的投影中使用刚构造的框来代替小CC的包围框。
使用包围小CCs的新修改框,从CCs的边界框构建与估计的倾斜水平平行的“水平”投影轮廓。然后,动态规划算法在投影轮廓中选择最佳分割点集。成本函数是在切点处的剖面项之和加上它们之间间距的方差度量。对于大多数文本,其和为零,加入方差有助于选择最规则的行间距。对于更复杂的情况,方差和修改后的小ccs的包围框一起使用来帮助指导行切割,以最大限度地增加与适当的主体字符保持一致的变音符的数量。
一旦确定了切线,整个连接的组件被放置在它们垂直重叠最多的文本行中(仍然使用修改后的框),除非某个组件强烈重叠多条线。这样的ccs要么被假定为来自多行相互接触的字符,因此需要在切线处进行切割,要么是下沉的首个字母(drop-caps),在这种情况下,它们被放置在顶部重叠的行中。这个算法运行良好,即使对阿拉伯语也是如此。
文本行提取后,一行上的blob被组织成识别单元。对于拉丁语言,逻辑识别单元对应于以空格分隔的单词,这自然适合基于字典的语言模型。对于不以空格分隔的语言,例如中文,对应的识别单元应该是什么就不那么清楚了。一种可能是将每个汉字符号视为一个识别单位。然而,由于汉语符号是由多个字形(偏旁)组成的,如果没有识别的帮助,很难得到正确的字符分割。考虑到在处理的早期阶段可用的信息量有限,解决方案是在标点处分解blob序列,这可以根据它们的大小和与下一个blob的间距非常可靠地检测到标点符号。尽管这并不完全解决一个非常长的blob序列的问题,长的blob序列是在搜索分割图时决定效率和质量的关键因素,但这至少会将识别单元的长度减少到更易于管理的大小。
如第2节所述,黑白文本white-on-black的检测是基于轮廓的嵌套复杂度。同样的过程也拒绝非文本,包括半色调噪声,侧面的黑色区域,或侧栏或反向视频区域中的大容器框。部分过滤是基于blob的拓扑复杂性的度量,复杂度由内部组件的数量、嵌套孔的层数、周长与面积比等进行估计。然而,繁体字的复杂性,无论以何种标准衡量,往往都超过了一个框内的英文单词。解决方案是为不同的语言应用不同的复杂度阈值,并依赖于后续的分析来恢复任何被错误拒绝的blobs。
3.3 估算西里尔文字中的x高度
在完成文本行查找步骤并将blob块组织成行之后,Tesseract估计每个文本行的x高度。
x高度估计算法首先根据为块计算的初始行尺寸确定可接受的x高度最大值和最小值的界限。然后,对于每一行,分别将该行上出现的blobs的边界框的高度进行量化并聚合为直方图。从这个直方图中,x-height查找算法寻找两个最常出现的高度模式,它们之间的距离足够远,成为潜在的x-height和上升器高度。为了实现对一些噪声的鲁棒性,该算法确保选择为xheight和上升器高度的高度模式相对于直线上的blobs总数有足够的数量或出现次数。
这种算法适用于大多数拉丁字体。然而,当按原样应用于西里尔字母时,Tesseract无法为大多数行找到正确的xheight。结果,在一组俄语书籍的数据集上,Tesseract的单词错误率达到了97%。错误率如此之高的原因是双重的。首先,西里尔字体的高度上升统计数据与拉丁字体有很大不同。用西里尔字体写的统计数据与用拉丁字体写的有很大不同。
简单地降低每行上升字母/器的预期数量的阈值并不是一个有效的解决方案,因为一行文本包含一个或没有上升字母的情况并不少见。性能如此糟糕的第二个原因是西里尔字体的大小写高度模糊。例如,在33个大写的现代俄语字母中,只有6个字母的小写形状与大多数字体中的大写字母有显著不同。因此,在使用西里尔字母时,Tesseract很容易被错误的x高度信息误导,并很容易将小写字母识别为大写字母。
我们解决西里尔字母x高度问题的方法是调整一行上上升字母的最小预期数量、考虑到下降字母的统计数据并更有效地使用来自同一文本块中相邻行的x高度信息(块是由页面布局分析确定的文本区域,块具有一致的文本blobs和行间距,因此很可能包含相同或相似字体大小的字母)。对于给定的文本块,改进的x-height查找算法首先尝试单独查找每行的x-height。基于计算结果,每条线分为如下四类:
(1)发现了x-height和上升模式的线,(2)发现了下降模式的线,(3)发现了可用于估计字母高或x-height的普通blob高度的线,(4)没有发现上述任何一种模式的线(极有可能是包含噪声的线条,包含太小、太大或只是大小不一致的blob)。如果在块中发现第一类中的任何具有可靠的x高度和上升高度估计的线,那么它们的高度估计将用于第二类中具有类似x高度估计的线(存在下降高度的线)。同样的x-高度估计用于第三类(没有发现上升或下降线)的线条,其最常见的高度在x-高度估计的小范围内。如果逐行方法没有找到任何可靠的x-height和ascender height模式,则聚合文本块中所有blob的统计信息,并使用此累积信息重复对x-height和ascender height模式的相同搜索。
由于上述改进的结果,用一套俄语书籍作为测试集,单词错误率降低到6%。在改进之后,测试集仍然包含一些错误,因为无法估计文本行的正确x高度。然而,在许多这种情况下,即使是人类读者也必须使用来自邻近文本块的信息或关于书籍共同组织的知识来确定给定的行是大写还是小写。
- 单词/字符识别
将Tesseract应用于多语言OCR需要克服的主要挑战之一是将主要为字母语言设计的功能扩展到处理表意语言,如汉语和日语。这些语言的特点是拥有大量的符号,缺乏明确的单词边界,这对搜索策略和分类引擎构成了严峻的考验,这些搜索策略和分类引擎是为小写字母表中划分良好的单词设计的。
我们将在下一节讨论大量表意文字的分类,并首先描述为解决检索问题而需要进行的修改。
4.1 分割和搜索
如3.2节所述,对于非空格分隔的语言,如中文,在西方语言中同等的识别单元现在对应于标点分隔的短语。处理这些短语需要考虑两个问题:它们涉及比拉丁语中典型单词更深入的搜索,并且它们与字典中的条目(entry)不对应。Tesseract在分割图上使用最佳优先搜索策略,分割图随着blob序列的长度呈指数增长。虽然这种方法处理的是较短的拉丁词,切分点较少,并且在词典中找到结果时存在终止条件,但在对中文短语进行分类时往往会耗尽可用的资源。为了解决这个问题,我们需要大幅减少置换/排列中计算的分割点数量,并设计一个更容易满足的终止条件。
为了减少分割点的数量,我们在像中文和日语这样的单行距语言中加入了字符宽度大致恒定的约束。在这些语言中,字符大多具有相似的长宽比(aspect radios),并且他们的位置不是全音高就是半音高。尽管标准化的宽度分布会因字体而异,间距也会因行对齐和包含数字或拉丁单词而变化(这并不罕见),但总的来说,这些约束为特定的分割点是否与另一个分割点兼容提供了强有力的指导。因此,使用分割模型的偏差作为代价,我们可以消除大量不合理的分割状态,有效地减小搜索空间。我们还使用这个估计来修剪基于局部最优解的搜索空间,使其有效地进行波束搜索。当没有进一步的扩展可能产生更好的解决方案时,这也提供了终止条件。
另一个强大的约束是短语中字符脚本的一致性。当我们从多个脚本中包含形状类时,不同脚本中的字符之间的混淆错误就不可避免了。虽然我们可以确定该页面的主要文字或语言,但我们也必须考虑到拉丁字符,因为英语单词在外文书籍中出现是如此普遍。基于一个识别单元内的字符具有相同的脚本的假设,如果一个字符解释能够提高整个识别单元的整体脚本(中文/英文/拉丁文?)一致性,我们就会推广它。但是,如果子/词组是真正的混合文字,那么盲目地基于先验知识推广文字,反而会对效果造成影响。因此,只有当顶部(排分靠前?)解释中超过一半的字符属于同一脚本时,我们才应用约束,并且像任何其他排列一样,调整是根据形状识别得分加权的。
4.2 形状分离
对大量类别进行分类仍然是一个研究问题;即使在今天,特别是当它们需要以OCR所需的速度运行时[13,14]。维度的诅咒在很大程度上是罪魁祸首。Tesseract形状分类器在5000个汉字上工作得令人惊讶地好,这不需要任何重大修改,因此它似乎非常适合处理大型类/大类别的问题。这个结果值得/需要一些解释,因此在本节中我们将描述Tesseract形状分类器。
特征是形状轮廓的多边形近似的组成部分。在训练中,从多边形近似的每个元素中导出(x, y位置,方向,长度)的4维特征向量,并聚类形成原型特征向量。(因此得名:Tesseract)。在识别中,多边形的元素被分割成等长的更短的片段,从而从特征向量中消除长度维度这一维。多个短特征与训练中的每个原型特征相匹配,这使得对破损的字符的分类更有鲁棒性。
图7(a)显示了字体Times Roman中字母“h”的示例原型。绿色线段表示“重要聚类 significant clusters”的聚类方法,其中包含了Times Roman中几乎所有“h”样本中的样本。蓝色的部分是簇均值,它与另一个簇合并形成一个重要的簇。品红段没有被使用,因为它们与现有的重重要聚类相匹配。红色片段没有足够的样本来组成重要聚类,不并且能与任何相邻的聚类合并形成重要聚类。

图7(b)显示了未知的短特征如何与原型匹配以实现对破碎字符的不敏感/丢弃。
短而粗的线条是未知的特征,是一个破碎的“h”,较长的线条是原型特征。颜色代表匹配质量:黑色->良好,品红->合理,青色->较差,黄色->不匹配。垂直的原型都匹配得很好,尽管h是破碎的。
形状分类器分为两个阶段。第一阶段称为类修剪器,使用与局部敏感哈希(LSH)[13]密切相关的方法,将字符集减少到1-10个字符的短列表。最后一个阶段计算未知字符与短列表中的字符原型之间的距离。
类修剪器最初设计为一个简单而重要的节省时间的优化器,通过单独考虑每个3-D特征来划分高维特征空间。用一个简单的查找表替代LSH的哈希表,查找表返回一个范围为[0,3]的整数向量,一个向量代表字符集中的每个类,其值表示该特征与字符类原型的近似匹配度。对未知字符的所有特征进行求和得到向量形式的结果,并返回总得分在最高分数内的类作为第二阶段分类的短名单。类修剪器速度相对较快,但其时间规模与类数和特征数呈线性关系。
第二阶段分类器计算每个特征到其最近的原型的距离df,作为(x,y)特征坐标到二维空间中原型线的欧氏距离d的平方,加上与原型的角度θ的加权(w)差值:
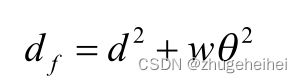
这本质上是一个生成式分类器,在某种意义上,它计算了与理想的距离。利用下式将特征距离转换为特征证据Ef:
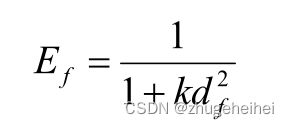
常数k用于控制证据evidence随距离衰减的速率。随着特征与原型的匹配,特征证据evidence Ef被复制到原型Ep。由于原型期望多个特征与它们匹配,并且“最佳匹配”的收集是为了速度而独立完成的,因此特征和原型证据evidence的总和可能是不同的。这些和通过特征的数量和原型长度之和Lp进行归一化,并将结果转换回距离dfinal:

请注意,实际的实现使用了定点整数算术,上面的方程省略了许多会使计算变得模糊的缩放常数。
第二阶段分类器的部分优势在于允许每个类标签中有多个理想(在Tesseract中称为配置configs),因此允许由字体或排版的任意差异引起的多模态分布。上述匹配过程在计算最终距离时选择最佳配置config。从这个意义上说,分类器实际上是一个最近邻分类器。
我们假设类修剪器和二级分类器对于大量的类都能很好地工作,因为它们使用了在多个小维的“弱分类器”之间投票,而不是依赖于一个高维的单一分类器。这就是提升[15]背后的概念,只是目前的弱分类器没有加权。特征空间的维度被量化到256级,这提供了足够的精度来存储CJK字符和印度音节的复杂形状,dfinal计算以类似于类修剪的方式避免了维度的诅咒。
- 基于上下文的后处理过程
Tesseract通过提供了一种从任意单词列表生成新语言字典的方法,其训练过程支持部分扩展语言模型。为了紧凑compactness和快速搜索,这些字典用有向无环词图(dawg)表示。在最初的实现中,DAWG数据结构用于按顺序搜索几个字典,包括预先生成的系统字典、文档字典(从已经OCR过的文档中的单词动态构造)和用户提供的单词列表。
最初,DAWG中的每条边都存储了一个8位字符,以表示DAWG中用于相应转换的字母。然而,这种表示是有限制的,因为以这种方式操作多字符字形和多字节Unicode字符是很困难的。DAWG数据结构被修改为存储字符分类器使用的单字符集id。这大大简化了构造和搜索dawg的过程。另一个改进是在所有的dawg上并行搜索。为了确定给定的字符串是否是有效的字典单词,现在搜索从一组初始的“活跃”dawgs开始。由于考虑了单词中的每个字母,这个集合被简化为只包含那些仍然“接受”部分字符串的字母。在进程结束时,“活跃”的dawgs集合仅由包含单词的dawgs组成。这种重组允许我们动态加载任意数量的dawgs,而不需要添加任何自定义支持来搜索每个新添加的dawgs。它也是允许Tesseract支持任意语言组合的必要修改之一——这是Tesseract在多语言文本上工作所需的特性。
5.1 约束模式
Tesseract中的标点符号和数字状态机是硬编码的,除了拉丁脚本之外没有推广。即使是拉丁脚本,状态机也不能接受相当一部分有效的标点符号和数字模式。为了帮助Tesseract处理非拉丁文字中的标点符号和数字,Tesseract的训练过程扩展了代码,以收集和编码一组经常出现的标点符号和数字模式。收集这些模式的步骤是与处理大型文本语料库以构建给定语言的字典并行实现的。为了表示和匹配生成的模式,使用了用于生成和搜索单词dawgs的现有代码。对算法进行了一些修改,以确定给定的分类器选择是否是语言中的有效单词,这一改变使Tesseract能够同时搜索所有包含单词、标点符号和数字模式的dawgs。通过这种修改,可以删除所有特定于语言和脚本的数字和标点符号的硬编码规则。生成和搜索标点符号和数字模式的过程被设计为完全由数据驱动的,到目前为止,对于任何特定的语言都不需要特殊的大小写。
5.2 解决形状歧义
除了预先训练好的形状模板,Tesseract的形状分类器还包括一个自适应组件,该组件可以学习OCRed文档中看到的字符的模式。为了确保自适应组件是在可靠的数据上进行训练,分类器只适应字典中无歧义的单词。OCRed单词如果满足两个条件,就被称为“明确的/无歧义的”。首先,形状分类器必须在单词的所有备选选项中识别出一个明确的获胜者(即最优选择的分类器评分必须显著高于次优选择的评分)。第二个约束是字典中不可能存在形状模糊的词来为该词进行最佳选择。这个要求对识别速度也很重要,因为(取决于分类器的得分)一旦Tesseract发现这样的单词选择,它就可以接受识别结果并停止对单词的进一步处理。
对于拉丁字体,Tesseract包含一个手工制作的数据文件(称为“危险的歧义”文件),该文件指定在大多数拉丁字体中哪些字母组合固有地/天然地具有歧义。为使用其他脚本的语言启用此功能的可伸缩解决方案是开发一种自动生成任意给定语言的模糊/歧义的n-gram对列表的方法。从一个大型文本语料库中收集了一组n-grams(在本例中是单格、双格),其组合权重占语言中所有n-grams的95%。n-grams是用一组常用字体在一些退化模式和曝光下渲染得到的。然后在渲染的图像上运行Tesseract的形状分类器,以此为每个n-grams获得一组得分最高的分类。为每个n-grams聚合分类评分统计数据,丢弃分类器评分低的异常值(在某些字体和退化模式下,字符被渲染得无法识别,这种情况只会污染数据)。然后对每个不正确的OCRed n-gram和对应的正确n-gram对计算歧义评分。歧义评分被定义为形状分类器感知的错误和正确n-gram之间的相似性(在所有字体和退化模式中聚合)和语言中正确n-gram的频率的函数。为了在Tesseract的速度和精度之间达到理想的平衡,有必要选择由于n-gram形状模糊性而允许发生的预期错误数量的阈值(从n-gram频率和分类器错误统计数据计算)。为了生成“危险歧义”文件,歧义n-gram对按照其歧义分数的非递增顺序进行排序,并在文件中包含适当数量的得分最高的歧义,以确保期望的错误率。
使用这种自动化方法生成的数据文件,与使用手工制作的“危险的歧义”文件相比,可以在拉丁脚本(EFIGS数据集)上实现类似的改进(尽管在某些语言中,结果略弱)。在俄语数据集上使用自动生成的文件可以降低10%的单词错误率。检查为其他语言生成的文件还显示,自动生成的文件包含相当多的常见混淆形状,但还需要对相应的数据集进行进一步测试,以量化改进。
5.3 处理变形验证的语言
Tesseract的速度和准确性与字典的质量息息相关,在最大限度地提高速度和准确性的同时,尽量减少存储字典所消耗的空间,这始终是一个挑战。从严重变形语言的语料库生成字典是一项特别困难的任务。在严重变形语言中,单词的频率分布更均匀,因此要达到相同的语言覆盖范围,就需要一本更大的词典。此外,即使是更频繁的单词的许多词形也可能在训练语料库中出现的次数不够多,无法被收录到字典中,因此字典可能无法很好地泛化到训练语料库之外。图8通过绘制语料库的覆盖范围与构成字典的最常用单词数量的关系图,说明了在语言集合上的这个问题。
由于DAWG数据结构的头部和尾部压缩,添加DAWG中已经存在的单词的变形形式可能会导致字典的总体大小略微增加。这是因为单词的开头和结尾可能已经存储在DAWG中(例如,如果已经插入了“talk”和“making”,那么将单词“talking”添加到字典中就相对便宜了).
为了解决捕获更多形变单词形式的问题,对字典生成过程进行了修改,即先生成单词变体(在单词列表中不存在)并将它们添加到字典中。首先,正如前面所做的,DAWG是从单词列表构建的。然后为DAWG中的每个词根root收集一组后缀。使用组平均分层聚类算法对集合进行聚类。结果聚类集群中的后缀集合并为扩展后缀集。然后,对于每个词根和相应的后缀集(在第一次遍历DAWG期间预先计算),确定最近的扩展后缀集。由扩展集的后缀组成的新词形被插入到DAWG中。
- 实验结果
我们的数据集由谷歌图书搜索项目收集的随机选择的书籍页面组成。对于每种语言,随机选择100本书,并从每本书中随机选择10页进行手工实地调查。因此,这些页面涵盖了从布局、字体typeface、图像质量到主题和术语使用的各个方面。
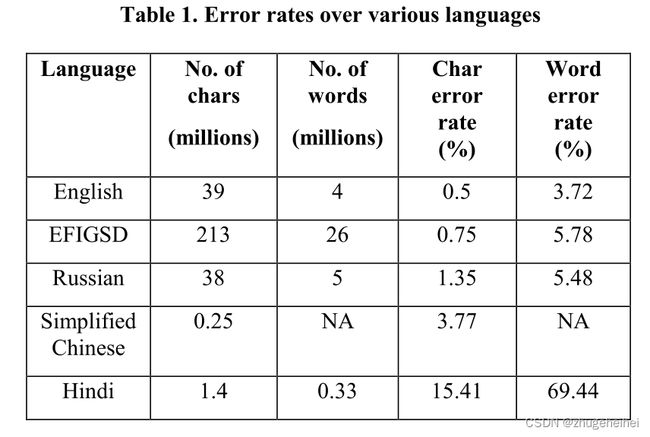
然后,数据集被分解为训练集、验证集和测试集,其中训练集和验证集用于在开发期间学习和对标/评估算法,而测试集则保留用于发布期间的最终评估。表1总结了数据集的大小和在一些语言上当前的准确性。
对于字母语言,我们报告了字符级别和单词级别的错误率。对于词义模糊的汉语,我们只报告了字符替换率。EFIGSD是英语、法语、意大利语、德语、西班牙语和荷兰语的结合
对于简体中文,我们注意到不同书籍的错误率有很大的偏差。这种差异主要是由于字体和质量的差异。在页面质量和精度合理的情况下,错误主要是由于相似或几乎相同的形状类之间的混淆造成的。我们计划增加形状匹配器中特征空间的容量,这应该有助于区分相似的形状。
在几乎相同的情况下,字体之间的类内变化可能比类间变化更大。幸运的是,它们的用法和先前情况(priors)是如此不同,当我们为CJK引入语言模型时,它们很容易被纠正。
- 结论和展望
我们描述了我们对Tesseract进行改造以适应多种语言的实验,并惊奇地发现这主要是一个工程问题。在没有对分类器进行任何重大更改的情况下,我们能够为各种基于拉丁的语言、俄语甚至简体中文获得良好的结果。到目前为止,印地语的测试结果令人失望,但我们发现我们的测试集包含新旧字体的混合,很大一部分错误是由于训练集不包含旧字体的字符造成的。这项工作还没有涵盖从右向左书写的语言,这主要是另一个工程问题,但阿拉伯语有自己的一组问题,Tesseract可能无法解决——即字符分割。另一种我们没有讨论的语言是泰语,它的字符存在高度歧义的问题,并且就像中文一样,单词之间没有空格。
一个重要的未来项目是改进训练过程,以便能够使用真实数据进行训练,而不仅仅是带有字符边界框的合成数据。这将大大提高印地语的准确性。我们还需要测试阿拉伯语和泰语,我们预计这两门语言会出现更多问题。对于中文、日语和泰语,我们需要允许语言模型搜索任意连接的单词的空间,因为这些语言的单词之间没有空格(For Chinese, Japanese, and Thai, we need to allow the language model to search the space of arbitrarily concatenated words, since there is no whitespace between the words of these languages)。同样的功能对于德语也很有用,尽管德语复合具有大小写更改和插入字母的额外复杂性。