RPC框架的实现原理,及RPC架构组件详解
RPC的由来
随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,亟需一个治理系统确保架构有条不紊的演进。
- 单一应用架构
- 当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。
- 此时,用于简化增删改查工作量的 数据访问框架(ORM) 是关键。
- 垂直应用架构
- 当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。
- 此时,用于加速前端页面开发的 Web框架(MVC) 是关键。
- 分布式服务架构
- 当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。
- 此时,用于提高业务复用及整合的 分布式服务框架(RPC),提供统一的服务是关键。
例如:各个团队的服务提供方就不要各自实现一套序列化、反序列化、网络框架、连接池、收发线程、超时处理、状态机等“业务之外”的重复技术劳动,造成整体的低效。
所以,统一RPC框架来解决提供统一的服务。
以下我将分别从如下四个方面详解RPC。
RPC的实现原理
也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。
比如说,A服务器想调用B服务器上的一个方法:
Employee getEmployeeByName(String fullName)
整个调用过程,主要经历如下几个步骤:
1、建立通信
首先要解决通讯的问题:即A机器想要调用B机器,首先得建立起通信连接。
主要是通过在客户端和服务器之间建立TCP连接,远程过程调用的所有交换的数据都在这个连接里传输。连接可以是按需连接,调用结束后就断掉,也可以是长连接,多个远程过程调用共享同一个连接。
2、服务寻址
要解决寻址的问题,也就是说,A服务器上的应用怎么告诉底层的RPC框架,如何连接到B服务器(如主机或IP地址)以及特定的端口,方法的名称名称是什么。
通常情况下我们需要提供B机器(主机名或IP地址)以及特定的端口,然后指定调用的方法或者函数的名称以及入参出参等信息,这样才能完成服务的一个调用。
可靠的寻址方式(主要是提供服务的发现)是RPC的实现基石,比如可以采用redis或者zookeeper来注册服务等等。
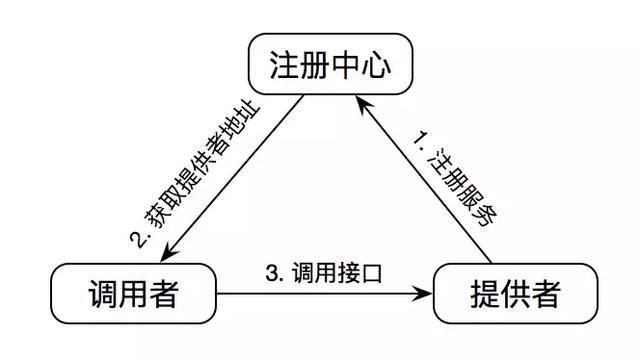
- 从服务提供者的角度看:当提供者服务启动时,需要自动向注册中心注册服务;
- 当提供者服务停止时,需要向注册中心注销服务;
- 提供者需要定时向注册中心发送心跳,一段时间未收到来自提供者的心跳后,认为提供者已经停止服务,从注册中心上摘取掉对应的服务。
- 从调用者的角度看:调用者启动时订阅注册中心的消息并从注册中心获取提供者的地址;
- 当有提供者上线或者下线时,注册中心会告知到调用者;
- 调用者下线时,取消订阅。
3、网络传输
3.1、序列化
当A机器上的应用发起一个RPC调用时,调用方法和其入参等信息需要通过底层的网络协议如TCP传输到B机器,由于网络协议是基于二进制的,所有我们传输的参数数据都需要先进行序列化(Serialize)或者编组(marshal)成二进制的形式才能在网络中进行传输。然后通过寻址操作和网络传输将序列化或者编组之后的二进制数据发送给B机器。
3.2、反序列化
当B机器接收到A机器的应用发来的请求之后,又需要对接收到的参数等信息进行反序列化操作(序列化的逆操作),即将二进制信息恢复为内存中的表达方式,然后再找到对应的方法(寻址的一部分)进行本地调用(一般是通过生成代理Proxy去调用,
通常会有JDK动态代理、CGLIB动态代理、Javassist生成字节码技术等),之后得到调用的返回值。
4、服务调用
B机器进行本地调用(通过代理Proxy)之后得到了返回值,此时还需要再把返回值发送回A机器,同样也需要经过序列化操作,然后再经过网络传输将二进制数据发送回A机器,而当A机器接收到这些返回值之后,则再次进行反序列化操作,恢复为内存中的表达方式,最后再交给A机器上的应用进行相关处理(一般是业务逻辑处理操作)。
通常,经过以上四个步骤之后,一次完整的RPC调用算是完成了。
PRC架构组件
一个基本的RPC架构里面应该至少包含以下4个组件:
1、客户端(Client):服务调用方(服务消费者)
2、客户端存根(Client Stub):存放服务端地址信息,将客户端的请求参数数据信息打包成网络消息,再通过网络传输发送给服务端
3、服务端存根(Server Stub):接收客户端发送过来的请求消息并进行解包,然后再调用本地服务进行处理
4、服务端(Server):服务的真正提供者
RPC调用过程
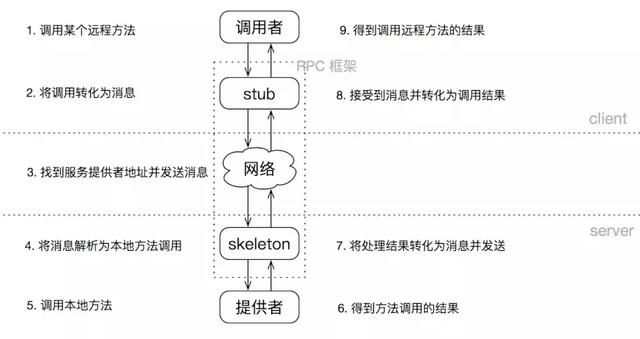
1、服务消费者(client客户端)通过本地调用的方式调用服务
2、客户端存根(client stub)接收到调用请求后负责将方法、入参等信息序列化(组装)成能够进行网络传输的消息体
3、客户端存根(client stub)找到远程的服务地址,并且将消息通过网络发送给服务端
4、服务端存根(server stub)收到消息后进行解码(反序列化操作)
5、服务端存根(server stub)根据解码结果调用本地的服务进行相关处理
6、本地服务执行具体业务逻辑并将处理结果返回给服务端存根(server stub)
7、服务端存根(server stub)将返回结果重新打包成消息(序列化)并通过网络发送至消费方
8、客户端存根(client stub)接收到消息,并进行解码(反序列化)
9、服务消费方得到最终结果
原文链接:http://youzhixueyuan.com/implementation-principle-of-rpc-framework.html