Netty权威指南:Netty总结-高性能与可靠性
第二十二章 高性能之道
22.1 RPC调用性能模型分析
22.1.1 传统RPC调用性能差
三宗罪:
- 网络传输采用同步阻塞I/O导致经常性阻塞
- 序列化性能差
- 线程模型问题
22.1.2 I/O通信性能三要素
- 传输:BIO、NIO或者AIO
- 协议:HTTP公有协议,内部私有协议
- 线程:数据报如何读取,Reactor线程模型
22.2 Netty高性能之道
22.2.1 异步非阻塞通信
I/O多路复用技术
22.2.2 高效的Reactor线程模型
可以灵活切换Reactor线程模型
22.2.3 无锁化的串行设计
采用串行无锁化设计,I/O线程内部使用串行操作,避免多线程竞争和同步锁导致性能下降。局部无锁化
22.2.4 高效并发编程
- volatile的大量、正确使用
- CAS和原子类的广泛使用
- 线程安全容器的使用
- 通过读写锁提升并发性能
22.2.5 高性能的序列化框架
影响性能的关键因素:
- 序列化的码流大小
- CPU的占用情况
- 是否支持跨语言
22.2.6 零拷贝
Netty的零拷贝主要体现在三个方面:
- Netty接收和发送ByteBuf采用DIRECT BUFFERS,使用堆外直接内存进行Socket读写,不需要进行字节缓冲区的二次拷贝。传统堆内存进行Socket读写,JVM需要将堆内存再复制到直接内存,才写入Socket,多了一次缓冲区的内存拷贝
- CompositeByteBuf,将多个ByteBuf封装成一个ByteBuf
- 文件传输,Netty文件传输类DefaultFileRegion通过TransferTo方法将文件发送到目标Channel中,而不需要循环拷贝。更加高效
22.2.7 内存池
为了重用缓冲区,Netty提供了基于内存池的缓冲区重用机制。通过RECYCLE的get方法循环使用ByteBuf对象
22.2.8 灵活的TCP参数配置能力
几个对性能影响较大的参数:
- SO_RCVBUF和SO_SNDBUF:通常建议值为128KB或者256KB
- SO_TCPNODELAY:NAGLE算法通过将缓冲区内的小封包自动相连,组成较大的封包,阻止大量小封包的发送阻塞网络,从而提高网络应用效率。但是对于时延敏感的应用场景需要关闭该优化算法
- 软中断:如果Linux内核版本支持RPS(2.6.35以上版本),开启RPS后可以实现软中断,提升网络吞吐量。RPS根据数据包的源地址,目的地址以及目的和源端口,计算出一个hash值,然后根据这个hash值来选择软中断运行的CPU。从上层来看,也就是说将每个连接和CPU绑定,并通过这个hash值,来均衡软中断在多个CPU上,提升网络并行处理性能
第二十三章 可靠性
23.1 可靠性需求
23.1.1 Netty可靠性需求
Netty的应用场景:
- RPC框架的基础网络通信框架:用于分布式节点之间的通信和数据交换
- 私有协议的基础通信框架:如Dubbo
- 公有协议的基础通信框架:如HTTP
23.2 Netty高可靠性设计
23.2.1 网络通信类故障
客户端连接超时
传统的同步阻塞编程模式在连接时会直接阻塞直到连接成功或者连接超时,NIO的异步连接超时无法再API层面直接设置,需要通过定时器来主动监测
Netty实现:
在创建客户端时,可以配置连接超时参数
Netty在发起连接的时候,会根据超时时间创建ScheduledFuture挂在Reactor上,用于定时检测是否发生连接超时,具体定时任务由NioEventLoop执行。
通信对端强制关闭连接
NIO编程出现的可靠性问题:
- IO的读写等操作并非仅仅集中到Reactor线程内部,用户自定义行为可能导致IO操作外溢
- 一些异常分支没有考虑到,外部诱因导致进图异常分支
Netty通过SocketChannel的read操作报出异常,由NioByteUnsafe同一处理
链路关闭
同样,Netty通过SocketChannel的read操作返回值处理异常
定制I/O故障
Netty的处理策略为发生I/O异常时,释放底层资源,再将异常信息发送给用户
链路有效性检测
心跳检测机制
23.2.3 Reactor线程的保护
异常处理要谨慎
Reactor除了会发生IO异常,也可能会发生非io异常,也要捕捉Throwable
捕获 Throwable之后,即便发生了意外未知对异常,线程也不会跑飞,它休眠1S,防止死循环导致的异常绕接,然后继续恢复执行。这样处理的核心理念就是:
- 某个消息的异常不应该导致整条链路不可用;
- 某条链路不可用不应该导致其他链路不可用;
- 某个进程不可用不应该导致其他集群节点不可用。
规避NIO BUG
著名的epoll bug
Netty的解决策略:
- 根据该BUG的特征,首先侦测该BUG是否发生
- 将问题Selector上注册的Channel转移到新建的Selector 上
- 老的问题Selector关闭,使用新建的Selector 替换
23.2.4 内存保护
NIO的内存保护主要集中在以下几点:
- 链路总数控制
- 单个缓冲区上限控制
- 缓冲区内存释放
- NIO消息发送队列的长度上限控制
缓冲区的内存泄露保护
Netty提供了内存池和对象池,这种机制下JVM不会自动释放对象,需要显式释放,防止用户遗漏导致内存泄露,Netty在PipeLine的尾Handler中自动堆内存进行释放
缓冲区溢出保护
在内存分配时指定缓冲区长度上限
在对缓冲区进行写入操作时,如果容量不足需要扩展首先对最大容量进行判断,如果容量超过上限,则拒绝扩展。
在消息解码时,对消息长度进行判断,如果超过最大容量上限,就抛出解码异常,拒绝分配内存。
23.2.5 流量整形
流量整形(Traffic Shaping)是一种主动调整流量输出速率的措施,一个典型应用是基于下游网络节点的TP指标来控制本地流量的输出。
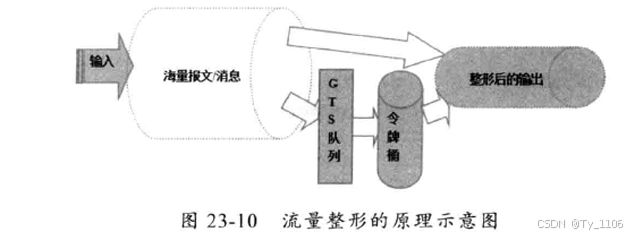
Netty的流量整形有两个作用:
- 防止由于上下游网元性能不均导致下游网元被压垮,业务流程中断
- 防止由于通信模块接收消息过快,后端业务处理不及时导致的“撑死”问题。
全局流量整形
作用范围是进程级的,也就是说对所有的Channel都有效。
可以通过参数设置:报文接收速率、发送速率、整形周期。
Netty流量整形原理:
对每次读取到的ByteBuf可写字节数进行计算,获取当前的报文流量,然后与流量整形阈值对比。如果已经达到或者超过了值。则计算等待时间delay,将当前的ByteBuf放到定时任务Task中缓存,由定时任务线程池在延迟 delay之后继续处理该ByteBuf。
链路级流量整形
与全局流量整形的区别就是作用域不同。
23.2.6 优雅停机
Java的优雅停机通常通过注册JDK的ShutdownHook来实现,当系统接收到退出指令后,首先标记系统处于退出状态,不再接收新的消息,然后将积压的消息处理完,最后调用资源回收接口将资源销毁,最后各线程退出执行。
通常优雅退出有个时间限制,例如30S,如果到达执行时间仍然没有完成退出前的操作,则由监控脚本直接 kill-9pid,强制退出。
23.3 优化建议
23.3.1 发送队列容量上限控制
发送队列并没有容量上限,如果对方网络处理速度较慢,或一次发送消息量过大,都会导致ChannelOutboundBuffer的内存膨胀,可能导致系统内存溢出
优化方式:通过启动项的ChannelOption设置发送队列的长度
23.3.2 回退发送失败的消息
当网络发生故障的时候,Netty会关闭链路,然后循环释放待未发送的消息,最后通知监听 listener。
大多数场景下,业务用户会使用RPC框架,他们通常不需要直接针对Netty编程,如果Netty提供了发送失败消息的回推功能,RPC框架就可以进行封装,提供不同的策略给业务用户使用,例如:、
1.缓存重发策略:当链路发生异常之后,尚未发送成功的消息自动缓存,待链路恢复正常之后重发失败的消息;
2.失败删除策略:当链路发生异常之后,尚未发送成功的消息自动销毁,它可能是非重要消息,例如日志消息,也可能是由业务直接监听异常并做特殊处理:
3.其他策略…