Python爬虫实战 - 视频下载001
(内容仅供技术探讨,切勿用于商业用途)
一、开发环境
IDE:Pycharm
Python 3.7 (三方库:requests、pybloom_live)
接口调试工具:Apifox
二、网站分析调研
1、目标网站
aHR0cHM6Ly9oYW9rYW4uYmFpZHUuY29tLw==
2、流程分析
2.1 获取频道信息
如图,该网站通过频道分类,将视频进行分为了不同的栏目,我们可以根据此分类,对指定的频道视频信息进行提取,也可以以为为依据对下载的内容分类保存。
2.2 获取频道下视频信息
以生活频道为例,可以看到此频道下,既存在直播的内容,也存在视频内容,我们在提取的过程中,可能会遇到直播的内容,此类内容无法下载保存,如遇到,应直接跳过。
此页面中,我们可以获取到视频的标题、作者、视频发布日期、播放量及封面图片等信息,可以作为我们保存的数据字段。
2.3 获取视频链接

想要下载视频,必须获取该视频的链接,我们可以查看在视频列表页返回的内容中查看是否存在链接信息,也可以点进视频详情页中查看链接信息。具体情况需根据网站的返回情况进行判断处理。
三、程序开发
1、API参数调试
1.1 频道信息API
aHR0cHM6Ly9oYW9rYW4uYmFpZHUuY29tLw==

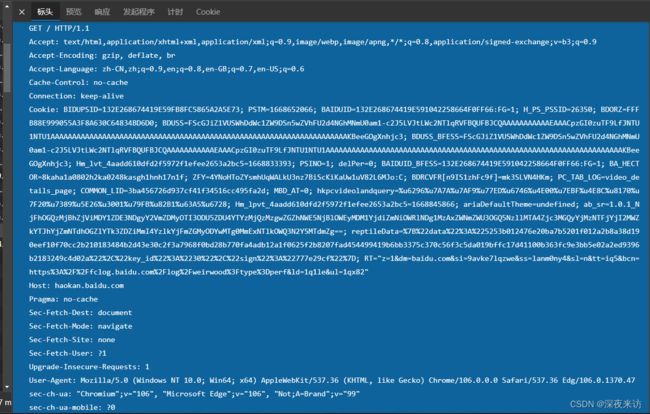 可以看到,请求头的信息很多,但经过一步步筛选,最后发现,真正有用的参数只有一个,如下
可以看到,请求头的信息很多,但经过一步步筛选,最后发现,真正有用的参数只有一个,如下

比较有意思的是,cookie的这个参数,值甚至可以为空,但如果不带这个参数,却无法获取到频道内容
1.2 视频列表API
aHR0cHM6Ly9oYW9rYW4uYmFpZHUuY29tL3RhYi95aW55dWVfbmV3P3Nmcm9tPXJlY29tbWVuZA==

我们的目标是获取频道下的所有或多页内容,所以在调研分析过程中,我们需要查看下一页来判断不同页码的参数有什么规律。
通过测试发现,该页面是通过ajax的方式,不断向下滚动获取视频内容,且API的参数始终保持不变,但内容却并不一致。
我们可以在此基础上,通过滤重技术,直至再无新视频内容返回位置,也可以只获取指定次数的视频列表内容。

参数不过,稍做处理即可,也可以选择全部保留
1.3 视频API
aHR0cHM6Ly9oYW9rYW4uaGFvMTIzLmNvbS92P3ZpZD02ODYxNTA3NTEzNDQ1NTA0OTMyJnBkPXBjJmNvbnRleHQ9

通过测试,我们可以发现视频的链接就在视频列表内容中,至此已经可以满足我们的需求,就无需再到视频详情页获取链接了。
2、代码
话不多说,直接上代码
import csv
import hashlib
import json
import os
import re
import requests
from pybloom_live import ScalableBloomFilter
class HaokanSpider(object):
def __init__(self):
self.bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001)
def insert_data(self, fileName, data):
"""
插入数据
:param fileName: 文件名
:param data: 要写入的数据
:return:
"""
with open(f"./{fileName}.csv", 'w', encoding='utf-8', newline='') as f:
# 1:创建writer对象
writer = csv.writer(f)
# 2:写表头
header = data[0].keys()
writer.writerow(header)
# 3:遍历列表,将每一行的数据写入csv
rows = [ch.values() for ch in data]
for r in rows:
writer.writerow(r)
def download_video(self, path, name, url):
"""
下载视频文件
:param path: 文件夹路径
:param name: 视频名称
:param url: 视频链接
:return:
"""
try:
response = requests.get(url)
if not os.path.exists(f"./{path}"):
os.mkdir(f"./{path}")
with open(f"./{path}/{name}.mp4", "wb") as f:
f.write(response.content)
return True
except Exception as e:
print(e)
def get_channel_info(self):
"""
获取频道信息
:return:
"""
url = "https://haokan.baidu.com/"
headers = {
"Cookie": 'BAIDUID=',
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
top_big_list = re.search('"tab":(\[.*?\]),', response.text).group(1)
data = json.loads(top_big_list)
results = []
for ch in data:
item = dict()
item['name'] = ch.get("name")
item['page'] = ch.get("page")
results.append(item)
return results
def get_video(self, channel):
"""
获取视频信息
:param channel: 频道信息
:return:
"""
results = []
for i in range(10):
print(f"{channel['name']} -- 第{i+1}页")
try:
url = f"https://haokan.baidu.com/web/video/feed?tab={channel['page']}&act=pcFeed&pd=pc&num=20"
headers = {
"Cookie": 'BAIDUID=',
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
videos = response.json().get("data").get("response").get("videos")
for video in videos:
play_url = video.get("play_url")
if not play_url:
continue
item = dict()
title = video.get("title")
id = hashlib.md5(title.encode(encoding='UTF-8')).hexdigest()
item['id'] = id
item['标题'] = title
item['作者'] = video.get("source_name")
item['播放量'] = video.get("fmplaycnt")
item['播放量'] = video.get("fmplaycnt")
item['发布日期'] = video.get("publish_time")
item['资源链接'] = play_url
if id not in self.bloom:
print(f"{item['标题']} 下载中...")
flag = self.download_video(path=channel['name'], name=id, url=play_url)
if flag:
results.append(item)
self.bloom.add(item['id'])
except Exception as e:
print(e)
if results:
self.insert_data(fileName=channel['name'], data=results)
def run(self):
channels = self.get_channel_info()
for channel in channels:
self.get_video(channel)
if __name__ == '__main__':
spider = HaokanSpider()
spider.run()
四、优化方案
1、代理IP配置
对同一网站进行大批量数据采集,极有可能被判断为爬虫行为,从而被封禁IP来保证服务器的稳定,我们可以通过设置随机代理的方式,来规避用户行为异常的检测
2、设置间隔时长
除了配置代理,我们也可以通过设置请求间隔时间来规避单位时间内请求量过大的问题,进一步保证程序的稳定运行。
3、重试机制
再视频下载的过程中,随时可能因为网络波动等原因导致下载失败,我们可以通过增加重试的机制,保证视频内容的完整。