数据仓库及数据挖掘
建立数据仓库的意义在于使用这些数据,而最典型的应用是数据挖掘。
一、数据仓库概述
数据仓库是一个面向主题、集成、相对稳定、反映历史变化的数据集合。其中,
1)数据源是数据仓库系统的基础,是整个系统的数据源泉
2)OLAP(On-Line Analytical Processing,联机分析处理)服务器对数据进行有效集成,按多维模型予以组织;
3)前端工具应用、挖掘数据
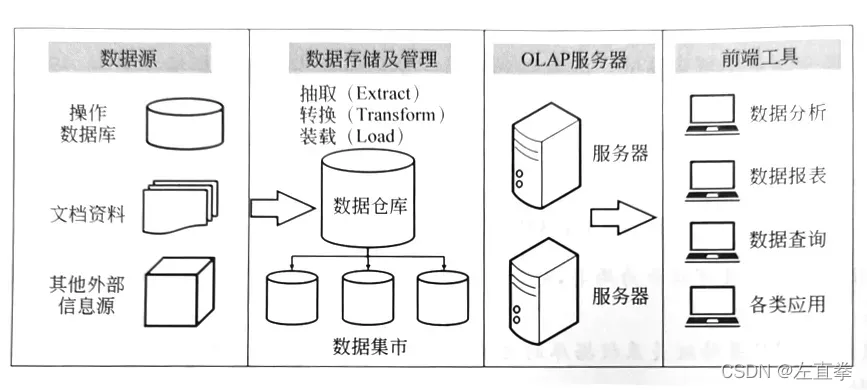
二、数据仓库的分类
从结构的角度看,数据仓库可分为3种模型:
1、企业仓库
面向企业级应用,搜集企业各个主题的所有信息,提供全企业范围的数据集成。其数据通常来自多个操作型数据库(即OLTP,我们应用程序常用的数据库)和外部信息提供者,并且跨多个功能范围。
企业仓库通常包含详细数据和汇总数据,数据量可达TB级。
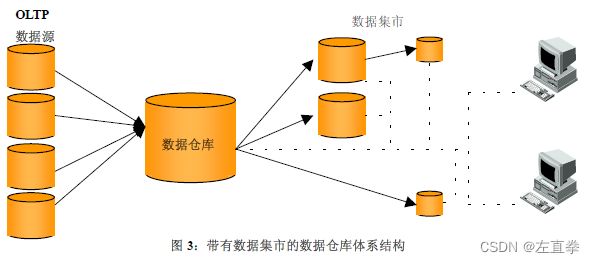
2、数据集市
数据集市(Datamart),面向企业部门级应用,针对特定用户,是企业范围数据的一个子集,范围限定于选定的主题。为什么叫集市呢?可能是各取所需之意吧。根据数据来源的不同,分为
1)从属数据集市(Dependent Datamart)
数据来源于中央数据仓库。为一些部门单独复制、加工一份数据,建立数据集市,可以提高部门的访问速度,也能满足部门的特殊分析要求。从属数据集市的数据与中央数据仓库保持一致,已经经过了处理和检验。
2)独立数据集市(Independent Datamart)
数据直接来源于业务系统。
独立数据集市优点是建立迅速,成本低廉,但由于各自独立,想整合成统一的中心数据仓库时可能会遇到困难,需要重新设计和部门协调等。
3、虚拟仓库
数据虚拟仓库(Virtual Warehouse)是视图的集合。只定义了来自各个操作型数据库上的查询,除了一些汇总视图可能被物化外,并没有存储数据。
虚拟仓库容易建立,但消耗操作型数据库服务器资源,需要它们具有剩余的工作能力。
【补充知识】
1、数据虚拟化
数据虚拟化 是一种数据管理方法,它允许应用程序检索和操作数据而无需有关数据的技术细节,例如在源上如何格式化或在物理上位于何处,并可以提供 单一客户视图 (或任何其他实体的单一视图)。数据虚拟化不同于传统的提取,转换,加载 (“ ETL”)过程,数据仍然保留在原处,并实时访问源系统以获取数据。
数据虚拟化有如下特点:
1)可连接到任何数据来源
数据虚拟化可连接到所有类型的数据来源,包括数据库、数据仓库、云应用程序、大数据存储库甚至 Excel 文件。
2)可合并任何类型的数据
数据虚拟化可将任意数据格式的相关信息合并到业务视图中,包括关系数据库、noSQL、Hadoop、Web 服务和云 API、文件等。
3)可在任何模式下使用数据
数据虚拟化使业务用户能够通过报表、仪表板、门户、移动应用程序和 Web 应用程序使用数据。
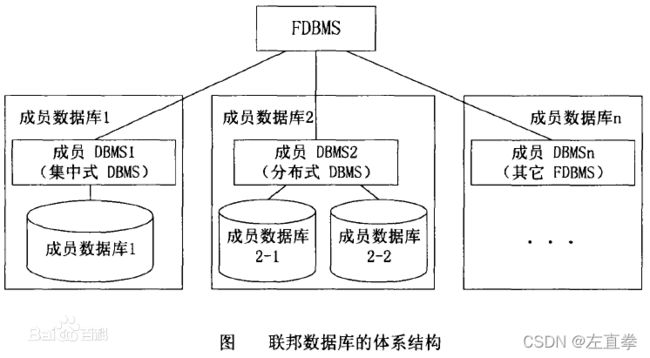
2、联邦数据库
联邦数据库系统 (FDBMS) 是一种元数据库管理系统,透明地映射多个自治数据库系统,变成一个联合数据库。组成的各数据库(称为单元数据库)可能分散于各个地域,通过计算机网络连接起来 。由于组成数据库系统保持自治,因此与合并多个不同数据库的任务相比,联邦数据库系统是一个可对比的替代方案。联邦数据库只是一个管理软件,本身并没有实际的数据集成。
通过数据抽象,联邦数据库系统可以提供统一的用户界面,而存储和检索的数据来自多个不连续的资料库,甚至构成的数据库是异质的。为此,联邦数据库系统必须能够将查询分解为子查询以提交给相关组成部分。 之后系统也必须能将各子查询的结果集汇集。由于各种数据库管理系统采用不同的查询语言,联邦数据库系统可以将子查询加以转换为适当的查询语言。
一个单元数据库可以加入若干个联邦系统,每个单元数据库系统可以是集中式的,也可以是分布式的,或者是另外一个FDBMS。
3、主题数据库
主题数据库,顾名思义,这种数据库是面向主题的,根据不同的业务主题来进行组织和存储。例如,企业中需要建立的典型的主题数据库有:产品、客户、零部件、供应商、订货、员工、文件资料、工程规范等。
与应用数据库只为一个应用系统服务,或者说根本就是隶属于特定的应用系统不同,主题数据库是为了信息共享。意思就是说,这个数据库是公共数据库,作为一种基础的数据资源而存在,可以给多个应用系统使用。这种数据资源,根据不同的业务主题分门别类,井井有条,一切都为了方便使用。
主题数据库有一些特点。其中之一是表符合第三范式(3NF),规范化程度还是比较高的。这意味着主题数据库的表中没有冗余列、派生列、计算列这些东东,消除了非主属性对主属性的传递依赖。
4、联邦数据库与分布式数据库的异同
(我瞎掰的)
【相同点】
数据分布于不同计算机或地方,通过网络连接起来;每个节点(或称子数据库)都有自治能力;以一个统一的数据库对外提供服务。
【不同点】
联邦数据库的子数据库可以是异质的,而分布式数据库各节点数据库是同质的;联邦数据库的子数据库不同执行全局应用,而分布式数据库的节点可以通过通信子系统执行全局应用;联邦数据库的子数据库相互之间没有什么联系,数据可能不一样,而分布式数据库的节点可以存在多个副本,分布式数据库的可靠性比联邦数据库要高。本质上,联邦数据库是一个管理软件,本身并不存储数据,而分布式数据库是真正的数据库。
三、数据仓库的设计方法
1、自顶向下的方法
由总体规划和设计开始,通过对原始数据进行抽取、转换和迁移等处理之后,将数据输出至一个集中的数据驻留单元,然后数据和元数据装载进入数据仓库。这样子建立起来的数据仓库就是企业级仓库,之后各个部门再从中获取本部门需要的数据形成从属数据集市。
投资大,周期长,需求难以确定,开发人员要求高。但有长远价值。
2、自底向上的方法
核心思想是从企业最关键部门(或功能需求)开始,先以最少的投资完成当前的需求,获得最快的回报,然后再不断扩充和完善。这种方法最先产生的是独立数据集市,而后从多个独立数据集市抽取数据,形成企业级数据仓库。
投入少,见效快。
3、混合法
上面两种方法结合。
四、数据仓库的存储和管理
1、ETL
数据仓库的真正关键是数据的存储和管理。企业数据仓库的建设,是以现有企业业务系统和大量业务数据的积累为基础、针对现有各业务系统的数据,进行抽取、清理、并有效集成,按照主题进行组织,整个过程可以简称为ETL(Extraction-Transformation-Loading,抽取、转换和加载)过程。
ETL负责将分布的、异构数据源中的数据(例如,关系数据、平面数据文件等)抽取到临时中间层后进行清洗、转换和集成,最后加载到数据仓库或数据集市中,成为数据分析处理(OLAP)和数据挖掘的基础。
数据仓库是一个独立的数据环境,通过抽取将数据从OLTP等各种源头导入。数据仓库中的数据不要求与源数据库实时同步,ETL可以定期进行。但ETL的操作时间、顺序、成败对数据仓库的信息有效性至关重要。
2、非结构化数据
数据仓库的数据通常来源多种多样,面对的数据,既有结构化数据,也会有像图片、视频这类的非结构化数据。如何管理非结构化数据,时数据仓库应用的一个重要问题。
数据仓库采用元数据来管理非结构化数据。元数据记录数据的文件标识符、索引字、处理日期等信息,凭元数据能找到源文件;而且元数据包含的信息很多,甚至不用看源文件,只看元数据就行。非结构化数据对分析与决策同样有重要意义,但存储成本高,数据仓库不一定要保存这些数据,只要能找到它们就行;即使存储一部分,也可以根据情况变化而清除。
五、数据的分析处理
数据处理大致可以分为OLTP和OLAP。OLTP是传统数据库的应用,我们开发的应用程序大部分都使用该模式使用数据库。
OLAP(联机分析处理)是数据仓库的主要应用。支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
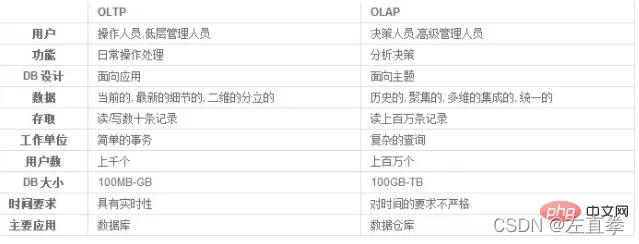
在OLTP中,数据以二维表的形式进行组织,但在OLAP中,数据是多维的。
六、数据挖掘
将信息加以整理归纳和重组,并及时提供给相应的管理决策人员,是数据仓库的根本任务。
数据挖掘采用各种科学方法,从大量数据中挖掘出隐含的、先前未知的规律和信息,可用于建立决策模型,为各领域提供预测性决策支持。
1、概述
1)体系结构
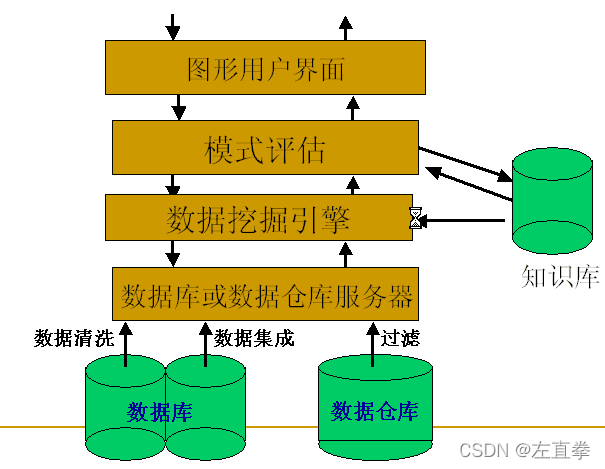

2)数据挖掘流程
(1)问题定义
熟悉背景知识,弄清用户需求,对目标有清晰明确的定义,搞清楚到底想干什么。
(2)建立数据挖掘库
收集要挖掘的数据资源,收集到一个数据库中,一般不直接使用原数据库或者数据仓库。一方面挖掘过程中可能要修改数据,另一方面是统计分析比较复杂,数据仓库不一定支持相关的数据结构。
好理解,拷贝数据出去以后,随便挖,随便折腾。
(3)分析数据
找规律和趋势
(4)调整数据
经过上面步骤之后,对数据状态和趋势有了进一步了解,为进一步明确和量化,需要对数据有针对性的增删。
(5)模型化
建立知识模型。这是数据挖掘的核心环节。
(6)评价和解释
对得到的模型进行检验。既可以拿挖掘库中的数据来检验,也可以取新数据进行检验。
2、常用技术与方法
1)挖掘技术
神经网络,决策树等等
2)分析技术
(1)关联分析
用于发现不同事件之间的关联性
(2)序列分析
用于发现一定时间间隔内接连发生的事件,这些事件构成的序列是否具有普遍意义。
(3)分类分析
对未知类别的样本进行分类。
(4)聚类分析
根据物以类聚的原理,将本身没有类别的样本聚集成不同的组。
(5)预测方法
根据样本的已知特征,预测其连续取值过程。
(6)时间序列分析
预测发展趋势。
3、应用
很多,如
空间数据挖掘、多媒体数据挖掘、文本数据挖掘。数据挖掘最典型的故事,应该是啤酒和纸尿片。