ubuntu18.04 —标注数据集以及安装YOLOv4 并训练
ubuntu18.04 —标注数据集以及安装YOLOv4并训练
1.安装labelImg图像标注工具
Python 2 + Qt4安装
1. cd labelImg/
2. sudo apt-get install pyqt4-dev-tools
3. sudo pip install lxml
4. make qt4py2
5. python labelImg.py
2.安装yolov4相关文件
1.sudo apt-get update
2.sudo apt-get upgrade
3.git clone https://github.com/AlexeyAB/darknet.git
4.sudo nano Makefile
根据电脑的配置进行电脑的配置来修改文档里面的具体参数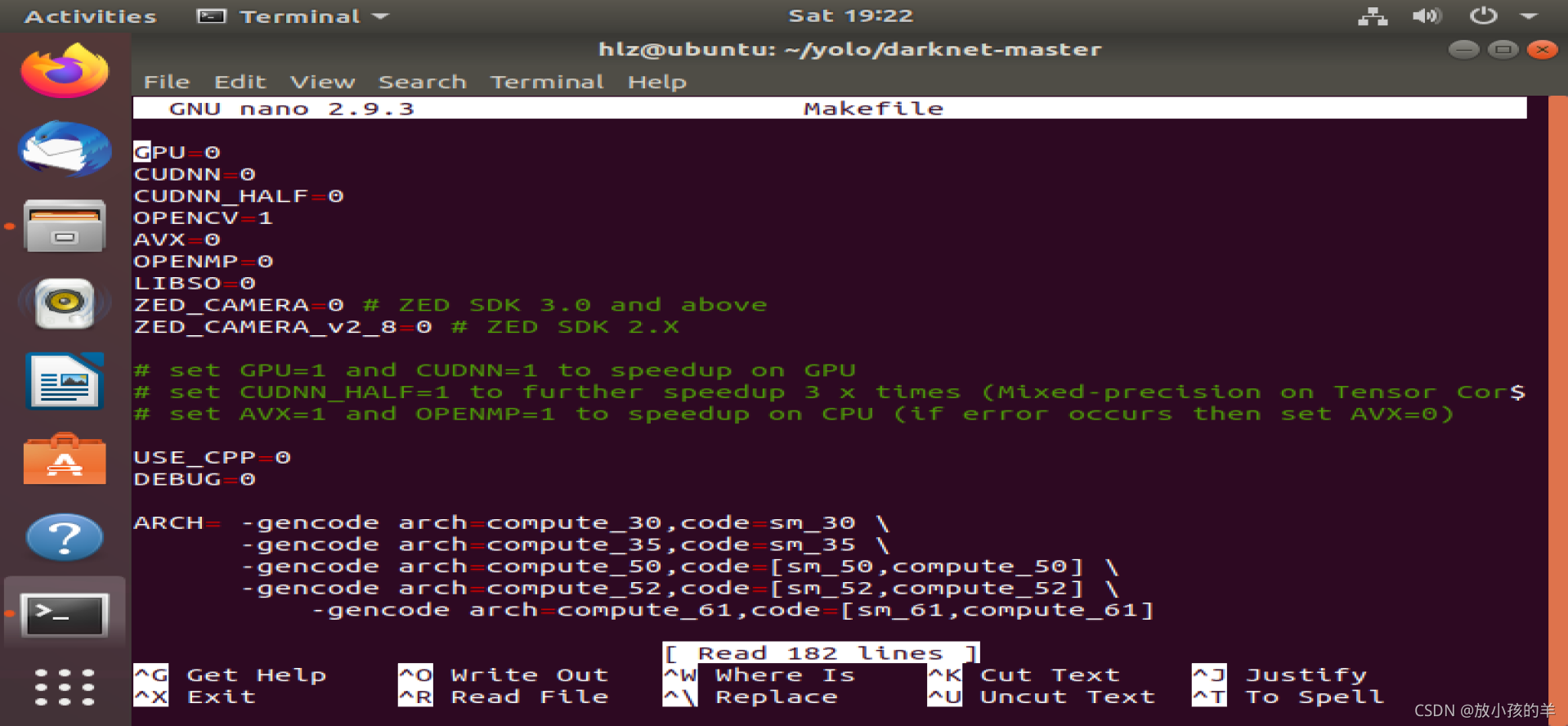

修改完毕之后,执行make -j8
./build.sh
可能显示cmake版本过低安装失败(安装成功请跳过)
1.apt-get autoremove cmake
2.wget https://cmake.org/files/v3.9/cmake-3.9.1-Linux-x86_64.tar.gz
3.tar zxvf cmake-3.9.1-Linux-x86_64.tar.gz
4.sudo ./configure
5.sudo make
6.sudo make install
7.cmake --version
下载yolov4权重文件以及预训练文件
链接:https://pan.baidu.com/s/1UrXQKaN0NM5b2suknpYuoQ
提取码:sq4w
./darknet detect cfg/yolov4.cfg yolov4.weights data/dog.jpg

3.训练部分
打开labelImg工具 标注
建立文件夹层次为 darknet / VOCdevkit / VOC2007
VOC2007下面建立两个文件夹:Annotations和JPEGImages
第一个是Annotations 用来存放标注好的xml文件
第二个是JPEGImages用来存放在照片
千万记得要一一对于,要不然训练的时候就会出现奇奇怪怪的bug
新建genfile.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
classes=["i","love","you"]// 这里是你标注的对象类别,全部放进来
// 这里是你标注的对象类别,全部放进来
// 这里是你标注的对象类别,全部放进来
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
out_file = open('VOCdevkit/VOC2007/labels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
work_sapce_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
work_sapce_dir = os.path.join(work_sapce_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
VOC_file_dir = os.path.join(work_sapce_dir, "ImageSets/")
if not os.path.isdir(VOC_file_dir):
os.mkdir(VOC_file_dir)
VOC_file_dir = os.path.join(VOC_file_dir, "Main/")
if not os.path.isdir(VOC_file_dir):
os.mkdir(VOC_file_dir)
train_file = open(os.path.join(wd, "2007_train.txt"), 'w')
test_file = open(os.path.join(wd, "2007_test.txt"), 'w')
train_file.close()
test_file.close()
VOC_train_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/train.txt"), 'w')
VOC_test_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/test.txt"), 'w')
VOC_train_file.close()
VOC_test_file.close()
if not os.path.exists('VOCdevkit/VOC2007/labels'):
os.makedirs('VOCdevkit/VOC2007/labels')
train_file = open(os.path.join(wd, "2007_train.txt"), 'a')
test_file = open(os.path.join(wd, "2007_test.txt"), 'a')
VOC_train_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/train.txt"), 'a')
VOC_test_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/test.txt"), 'a')
list = os.listdir(image_dir) # list image files
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
for i in range(0,len(list)):
path = os.path.join(image_dir,list[i])
if os.path.isfile(path):
image_path = image_dir + list[i]
voc_path = list[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
if(probo < 75):
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
VOC_train_file.write(voc_nameWithoutExtention + '\n')
convert_annotation(nameWithoutExtention)
else:
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
VOC_test_file.write(voc_nameWithoutExtention + '\n')
convert_annotation(nameWithoutExtention)
train_file.close()
test_file.close()
VOC_train_file.close()
VOC_test_file.close()
新建eval.py
import xml.etree.ElementTree as ET
import os
#import cPickle
import _pickle as cPickle
import numpy as np
def parse_rec(filename):
""" Parse a PASCAL VOC xml file """
tree = ET.parse(filename)
objects = []
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
#obj_struct['pose'] = obj.find('pose').text
#obj_struct['truncated'] = int(obj.find('truncated').text)
obj_struct['difficult'] = int(obj.find('difficult').text)
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return objects
def voc_ap(rec, prec, use_07_metric=False):
""" ap = voc_ap(rec, prec, [use_07_metric])
Compute VOC AP given precision and recall.
If use_07_metric is true, uses the
VOC 07 11 point method (default:False).
"""
if use_07_metric:
# 11 point metric
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap = ap + p / 11.
else:
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
def voc_eval(detpath,
annopath,
imagesetfile,
classname,
cachedir,
ovthresh=0.5,
use_07_metric=False):
"""rec, prec, ap = voc_eval(detpath,
annopath,
imagesetfile,
classname,
[ovthresh],
[use_07_metric])
Top level function that does the PASCAL VOC evaluation.
detpath: Path to detections
detpath.format(classname) should produce the detection results file.
annopath: Path to annotations
annopath.format(imagename) should be the xml annotations file.
imagesetfile: Text file containing the list of images, one image per line.
classname: Category name (duh)
cachedir: Directory for caching the annotations
[ovthresh]: Overlap threshold (default = 0.5)
[use_07_metric]: Whether to use VOC07's 11 point AP computation
(default False)
"""
# assumes detections are in detpath.format(classname)
# assumes annotations are in annopath.format(imagename)
# assumes imagesetfile is a text file with each line an image name
# cachedir caches the annotations in a pickle file
# first load gt
if not os.path.isdir(cachedir):
os.mkdir(cachedir)
cachefile = os.path.join(cachedir, 'annots.pkl')
# read list of images
with open(imagesetfile, 'r') as f:
lines = f.readlines()
#imagenames = [x.strip() for x in lines]
imagenames = [x.strip().split('/')[-1].split('.')[0] for x in lines]
if not os.path.isfile(cachefile):
# load annots
recs = {}
for i, imagename in enumerate(imagenames):
recs[imagename] = parse_rec(annopath.format(imagename))
if i % 100 == 0:
print('Reading annotation for {:d}/{:d}'.format(
i + 1, len(imagenames)))
# save
print('Saving cached annotations to {:s}'.format(cachefile))
with open(cachefile, 'wb') as f:
cPickle.dump(recs, f)
else:
# load
with open(cachefile, 'rb') as f:
recs = cPickle.load(f)
# extract gt objects for this class
class_recs = {}
npos = 0
for imagename in imagenames:
R = [obj for obj in recs[imagename] if obj['name'] == classname]
bbox = np.array([x['bbox'] for x in R])
difficult = np.array([x['difficult'] for x in R]).astype(np.bool)
det = [False] * len(R)
npos = npos + sum(~difficult)
class_recs[imagename] = {'bbox': bbox,
'difficult': difficult,
'det': det}
# read dets
detfile = detpath.format(classname)
with open(detfile, 'r') as f:
lines = f.readlines()
splitlines = [x.strip().split(' ') for x in lines]
image_ids = [x[0] for x in splitlines]
confidence = np.array([float(x[1]) for x in splitlines])
BB = np.array([[float(z) for z in x[2:]] for x in splitlines])
# sort by confidence
sorted_ind = np.argsort(-confidence)
sorted_scores = np.sort(-confidence)
BB = BB[sorted_ind, :]
image_ids = [image_ids[x] for x in sorted_ind]
# go down dets and mark TPs and FPs
nd = len(image_ids)
tp = np.zeros(nd)
fp = np.zeros(nd)
for d in range(nd):
R = class_recs[image_ids[d]]
bb = BB[d, :].astype(float)
ovmax = -np.inf
BBGT = R['bbox'].astype(float)
if BBGT.size > 0:
# compute overlaps
# intersection
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
# union
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(BBGT[:, 2] - BBGT[:, 0] + 1.) *
(BBGT[:, 3] - BBGT[:, 1] + 1.) - inters)
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
if ovmax > ovthresh:
if not R['difficult'][jmax]:
if not R['det'][jmax]:
tp[d] = 1.
R['det'][jmax] = 1
else:
fp[d] = 1.
else:
fp[d] = 1.
# compute precision recall
fp = np.cumsum(fp)
tp = np.cumsum(tp)
rec = tp / float(npos)
# avoid divide by zero in case the first detection matches a difficult
# ground truth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
ap = voc_ap(rec, prec, use_07_metric)
return rec, prec, ap
新建draw.py
#import cPickle
import _pickle as cPickle
import matplotlib.pyplot as plt
fr = open('testball/ball_pr.pkl','rb')
inf = cPickle.load(fr)
fr.close()
x=inf['rec']
y=inf['prec']
plt.figure()
plt.xlabel('recall')
plt.ylabel('precision')
plt.title('PR cruve')
plt.plot(x,y)
plt.show()
print('AP:',inf['ap'])
4.修改配置文件
第一个是建data/voc-hu.names(添加自己的标注名称)
第二个是cfg/voc-hu.data(一些信息)
第三个是cfg/yolov4-hu.cfg(修改classes, convolutional)
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=64
subdivisions=8
width=608
height=608
channels=3
momentum=0.949
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.00261
burn_in=1000
max_batches = 500500
policy=steps
steps=400000,450000
scales=.1,.1
#cutmix=1
mosaic=1
#:104x104 54:52x52 85:26x26 104:13x13 for 416
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-7
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=128
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-10
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=256
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-28
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=512
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-28
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-16
[convolutional]
batch_normalize=1
filters=1024
size=1
stride=1
pad=1
activation=mish
##########################
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
### SPP ###
[maxpool]
stride=1
size=5
[route]
layers=-2
[maxpool]
stride=1
size=9
[route]
layers=-4
[maxpool]
stride=1
size=13
[route]
layers=-1,-3,-5,-6
### End SPP ###
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = 85
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[route]
layers = -1, -3
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = 54
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[route]
layers = -1, -3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
##########################
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear
[yolo]
mask = 0,1,2
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
scale_x_y = 1.2
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
[route]
layers = -4
[convolutional]
batch_normalize=1
size=3
stride=2
pad=1
filters=256
activation=leaky
[route]
layers = -1, -16
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear
[yolo]
mask = 3,4,5
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
scale_x_y = 1.1
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
[route]
layers = -4
[convolutional]
batch_normalize=1
size=3
stride=2
pad=1
filters=512
activation=leaky
[route]
layers = -1, -37
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear
[yolo]
mask = 6,7,8
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
scale_x_y = 1.05
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
到此准备工作okk
python genfile.py
./darknet detector train cfg/voc-hu.data cfg/yolov4-hu.cfg
yolov4.conv.137