极智AI | labelme 标注与处理分割数据方法
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
大家好,我是极智视界。本文详细介绍了 labelme 标注与处理分割数据的方法。
图像分割是计算机视觉任务中常见任务,有实例分割、语义分割、全景分割等之分,在送入分割任务前,需要先对数据做标注处理。大家知道,深度学习中数据的质量对最后的检测效果影响很大,所以数据标注的好坏重要性不言而喻。
下面开始。
文章目录
-
- 1、安装 labelme
- 2、内置 json to datset
-
- 2.1 单图json to dataset
- 2.2 批量json to dataset
- 3、另一种分割标签制作
1、安装 labelme
不管你是 windows 还是 linux 都可以这么安装:
# 首先安装anaconda,这个这里不多说
# 安装pyqt5
pip install -i https://pypi.douban.com/simple pyqt5
# 安装labelme
pip install -i https://pypi.douban.com/simple labelme
# 打开labelme
./labelme
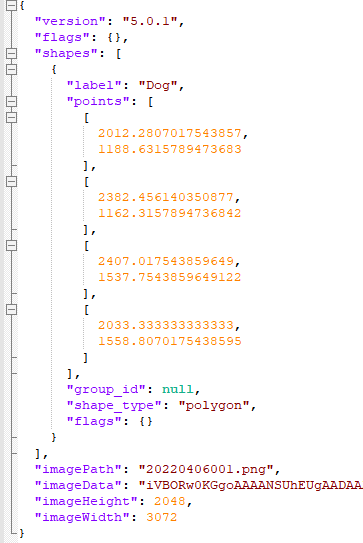
然后会生成对应图片的json文件,里面会有label和标注的分割掩膜信息,差不多像这样:
2、内置 json to datset
2.1 单图json to dataset
直接执行:
labelme_json_dataset xxx.json
然后会生成:
-
img.png:原图;
-
label.png:掩膜图;
-
label_viz.png:加背景的掩膜图;
-
info.yaml、label_names.txt:标签信息;
2.2 批量json to dataset
找到 cli/json_to_dataset.py 目录,然后:
cd cli
touch json_to_datasetP.py
vim json_to_datasetP.py
加入如下内容:
import argparse
import json
import os
import os.path as osp
import warnings
import PIL.Image
import yaml
from labelme import utils
import base64
def main():
warnings.warn("This script is aimed to demonstrate how to convert the\n"
"JSON file to a single image dataset, and not to handle\n"
"multiple JSON files to generate a real-use dataset.")
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
json_file = args.json_file
if args.out is None:
out_dir = osp.basename(json_file).replace('.', '_')
out_dir = osp.join(osp.dirname(json_file), out_dir)
else:
out_dir = args.out
if not osp.exists(out_dir):
os.mkdir(out_dir)
count = os.listdir(json_file)
for i in range(0, len(count)):
path = os.path.join(json_file, count[i])
if os.path.isfile(path):
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
captions = ['{}: {}'.format(lv, ln)
for ln, lv in label_name_to_value.items()]
lbl_viz = utils.draw_label(lbl, img, captions)
out_dir = osp.basename(count[i]).replace('.', '_')
out_dir = osp.join(osp.dirname(count[i]), out_dir)
if not osp.exists(out_dir):
os.mkdir(out_dir)
PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png'))
#PIL.Image.fromarray(lbl).save(osp.join(out_dir, 'label.png'))
utils.lblsave(osp.join(out_dir, 'label.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png'))
with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir)
if __name__ == '__main__':
main()
然后批量进行转换:
python path/cli/json_to_datasetP.py path/JPEGImages
若报错:
lbl_viz = utils.draw_label(lbl, img, captions)
AttributeError: module 'labelme.utils' has no attribute 'draw_label'
解决办法:需要更换labelme版本,需要降低labelme 版本到3.16.2 ,方法进入labelme环境中,键入 pip install labelme==3.16.2 就可以自动下载这个版本了,就可以成功了。
3、另一种分割标签制作
若你想生成类似下面这种标签:
原图:

对应标签 (背景为0,圆为1):

此标签为 8 位单通道图像,该方法支持最多 256 种类型。
可以通过以下脚本进行数据集的制作:
import cv2
import numpy as np
import json
import os
# 0 1 2 3
# backg Dog Cat Fish
category_types = ["Background", "Dog", "Cat", "Fish"]
# 获取原始图像尺寸
img = cv2.imread("image.bmp")
h, w = img.shape[:2]
for root,dirs,files in os.walk("data/Annotations"):
for file in files:
mask = np.zeros([h, w, 1], np.uint8) # 创建一个大小和原图相同的空白图像
print(file[:-5])
jsonPath = "data/Annotations/"
with open(jsonPath + file, "r") as f:
label = json.load(f)
shapes = label["shapes"]
for shape in shapes:
category = shape["label"]
points = shape["points"]
# 填充
points_array = np.array(points, dtype=np.int32)
mask = cv2.fillPoly(mask, [points_array], category_types.index(category))
imgPath = "data/masks/"
cv2.imwrite(imgPath + file[:-5] + ".png", mask)
以上是 4 个分类的情况。
到这里就大功告成了。以上分享了 labelme 标注与处理分割数据的方法,希望我的分享能对你的学习有一点帮助。
【公众号传送】
《【模型训练】labelme 标注与处理分割数据方法》

扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !
