详解 TensorFlow TFLite 移动端(安卓)部署物体检测 demo(3)——训练模型
文章目录
-
- 写在前面
- 开箱 README
- `tf1.md` 和 `tf1_detection_zoo.md`
-
- `tf1.md`
- `tf1_detection_zoo.md`
- `tf1_training_and_evaluation.md`
-
- Local Traing
- Tensorboard
- `model_main.py` 和 pipeline config
-
- 先说 pipeline config
- 再说 `model_main.py`
-
- (1)实例 estimator
- (2)实例 train_spec
- (3)实例 eval_spec
- 上面 3 个实例的源信息哪里来?
-
- 创建 RunConfig 实例
- 创建实例 estimator 以及各种 input_fn
- 创建实例 train_spec 和 eval_spec
- 训练
写在前面
前面已有两篇主干内容记录使用 TFLite 在安卓移动端部署物体检测模型,分别是照本宣科按照官方 demo 部署以及如何替换其他模型部署。本篇承接前面两篇,主要记录如何通过 tensorflow object detection API 来训练自己的模型,当完成了这一步获得自己的模型以后,就可以按照前一篇的流程将其部署到移动端,识别某些特定种类的物体,完成你自定义的某些任务。
需要说明的是,在写这篇记录的过程中,发现有关于 object detection API 本身的很多细节要讲述。但如果陷入 API 本身,那么这篇记录就又臭又长了。在使用过程中就会慢慢熟悉了解这个 API,因此本篇在涉及 API 相关的细节可能会简述,重点仅放在用这个 API 训练自定义任检测模型的整体流程上。
所有参考资料均来自 tensorflow 官方(哎就是有时候相关的资料没有及时更新也引导得不是很好……),主要就是前两篇多次提到的 models 项目下的 object detection API /models/research/object_detection/,后面不再特意说明的时候,约定好默认就在这个 obejct_detection 文件夹下。本篇基本就在这里摸爬滚打了,好了关门,谁也别想出去了(^ __^) ~~~
仍然考虑过先简略说明本篇的流程和能达成的效果,但是经过多次浏览还是苦于这个 part 该怎么说。想要真的“自定义”模型结构、训练和验证涉及的细节很多,写了感觉很杂乱,不写又感觉不明所以。
总之,如果你想要训练自定义的模型(任务自定义,不是完全从 0 自定义,比如至少特征提取部分一般都用现有的),如果遵循“拿来主义”什么都尽量简化先用现成的,那么至少你需要以下几部分工作:
(1)针对移动端的话,根据对速度和质量的要求,选择整体的模型结构。模型结构可以直接按照 ./samples/configs/ 路径下给定的很多 feature extractor 样例来选择,比如 faster_rcnn_resnet50 或 ssd_mobilenet_v2 等等。如果这些不能满足需求,也可以把自己的 feature extractor “注册”进 object detection API,可参考 ./g3doc/defining_your_own_model.md。
(2)准备适合自己任务的数据集,我是用 labelimg Pascal 格式标注,然后对应参考 ./dataset_tools/create_pascal_tf_record.py 创建 tfrecords 用于训练和验证即可。
(3)根据你的任务需求,可以改动 config 文件来设定模型相关或者训练相关的参数。config 中细节较多,比如分类类别、预训练模型、batch_size、数据路径等等。
(4)训练,完事儿。
python model_main.py -- 给参数
后面就记录些细节。
开箱 README
它多处强调了更新了 tf2 支持 tflite,整得我以为以前的模型全都支持了,但并没有。tf1 tf2 都有各自支持的模型,需要先查看好了再确定你用 tf1 还是 tf2。比如前两篇中 SSD MobileNet V2 这个 feature extractor 的话,还要用 tf1。所以本篇中,全都按照 tf1 的相关文档来。
但是吧,目前更新后向移动端部署的 examples 项目下的 demo 和实际使用中,那个 API 又是按照更新后的来的,也就是必须写入 metadata,而写入 metadata 的引导只在 models 的 tf2.md 文件中有聊到……
要疯了,可能先接触 models 这个项目再接触 examples 移动端部署的同学会更省点资料查看的力气。像我一开始就本着移动端部署先接触的 examples 再来细看 models 的,真的吐槽 tf 文档一百遍……
言归正传,长期来看肯定会 tf2 的,1 和 2 的相关文档我都截了一下,可以多关注。按照 README 的引导,我们需要参考 g3doc/tf1.md 和 g3doc/tf1_detection_zoo.md。

不可忽略的是 g3doc 下还有很多其他的说明文件,在本篇流程中,还会涉及其中的相关资料。
tf1.md 和 tf1_detection_zoo.md
tf1.md
tf1.md 中先介绍了 object_detection API 的安装(我没安装啦,也能通过测试)。然后关于本篇主题使用 object detection API 训练自己的模型相关信息如下:
Training and Evaluation:
To train and evaluate your models either locally or on Google Cloud see instruction ->tf1_training_and_evaluation.md.
Guides:
Configuring an object detection pipeline ->configuring_jobs.md
Preparing inputs ->preparing_inputs.md
Defining your own model architecture ->defining_your_own_model.md
Bringing in your own dataset ->using_your_own_dataset.md
Supported object detection evaluation protocols ->evaluation_protocols.md
TPU compatible detection pipelines ->tpu_compatibility.md
Training and evaluation guide (CPU, GPU, or TPU) ->tf1_training_and_evaluation.md
所以需要跳转参考文件 tf1_training_and_evaluation.md。同时,训练自己的模型用于自定义任务,不可避免地想对训练数据、训练过程、模型结构、前后处理等细节进行修改,而这些就可以参考 configuring_jobs.md 等文件。
tf1_detection_zoo.md
其中介绍了 tf1 支持的各种 detection 模型,这些模型或基于不同的模型骨架,或使用不同的数据集训练。在文档的前面部分还重点介绍了 examples 项目下移动端部署 object detection demo 中的默认自带模型,即 ssd_mobilenet_v1_coco。模型比较多,只截取了前面一点:
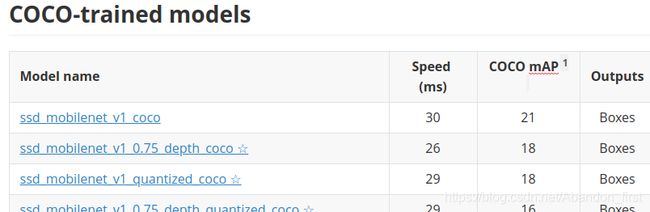
历史原因,之前做这部分工作时更看重速度,所以我们选择了 ssd 系列而非 faster rcnn 等系列。
我们选择了 ssd_mobilenet_v2_coco 来训练自己的模型。在训练过程中,和常见训练方式一样,可以选择完全从头训,也可以利用预训练好的模型初始化 feature extractor 部分的参数,然后再 finetuning。预训练好的模型就可以在这里找,如果要用 ssd_mobilenet_v2_coco 就应该在这里找 ssd_mobile_v2_coco 对应的模型下载下来供训练用(后面还会再谈)。
插播:可以继续向下查看,就能找到 demo 中更换的模型即 ssd_mobilenetv2_oid4 ,它在 tf1 支持的模型类型中,而不在 tf2 中。
tf1_training_and_evaluation.md
本文档主要讲述有关训练和验证的内容,包括目录结构、训练和验证数据、模型的 configuration 等,针对训练方式有本地训练和使用 Google Cloud AI 平台,也包括 GPU 和 TPU 训练等,我选择的 local 本地 GPU 训练。
文档建议 data 和 models 分开放置,数据使用 tfrecords 格式,模型中 train 存储模型,eval 为验证记录。
- 关于如何准备 tfrecords 的训练和验证数据,参考
preparing_inputs.md; - 关于如何配置模型训练和验证各个细节参数,参考
configuring_jobs.md,在此处重点强调了,建议使用预训练模型的参数来初始化,然后针对自己的任务进行 finetuning,提供的预训练模型可以在tf1_detection_zoo.md中来找。
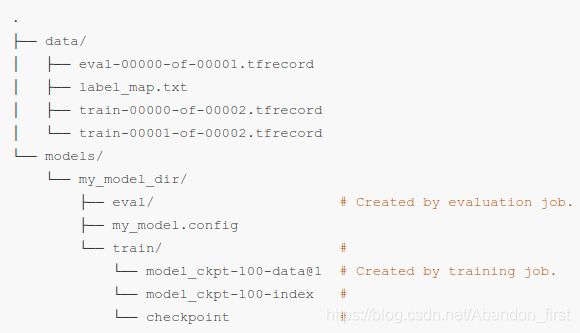
Local Traing
训练过程必须给定配置文件 pipeline config,文档直接给了训练代码:
# From the tensorflow/models/research/ directory
PIPELINE_CONFIG_PATH={path to pipeline config file}
MODEL_DIR={path to model directory}
NUM_TRAIN_STEPS=50000
SAMPLE_1_OF_N_EVAL_EXAMPLES=1
python object_detection/model_main.py \
--pipeline_config_path=${PIPELINE_CONFIG_PATH} \
--model_dir=${MODEL_DIR} \
--num_train_steps=${NUM_TRAIN_STEPS} \
--sample_1_of_n_eval_examples=${SAMPLE_1_OF_N_EVAL_EXAMPLES} \
--alsologtostderr
那么训练的细节过程就需要参考上面的 model_main.py 了。
Tensorboard
训练过程中,你可以查看已经写好的 tensorboard 文件,来查看模型的训练效果:
tensorboard --logdir=${MODEL_DIR}
API 已经向 tensorboard 写入了较为详细的信息,比如这是我之前训练中的一个剪影:

model_main.py 和 pipeline config
model_main.py 主要任务就是根据 pipeline config 中指定的信息,使用 tf.estimator 来训练和验证模型。
先说 pipeline config
根据需要修改 config 中的信息,以 SSD_Mobielnet_v2 为例,config 中包含的信息以及需要修改或注意的最基本信息如下:
(1) model/ssd
- num_classes
- box_coder
- matcher
- similarity_calculator
- anchor_generator
- image_resizer
- box_predictor
- feature_extractor
- loss
- normalize_loss_by_num_matches
- post_processing
(2) train_config
- batch_size
- optimizer
- fine_tune_checkpoint 推荐迁移训练节省时间
- fine_tune_checkpoint_type
- num_steps 默认给了 200,000
- data_augmentation_options
(3) train_input_reader
- tf_record_input_reader
- label_map_path
(4) eval_config
- num_examples
- max_evals
(5) eval_input_reader
- tf_record_input_reader
- label_map_path
- shuffle
- num_readers
再说 model_main.py
tf.estimator 是 tensorflow 的一个高级 API,能大大简化多平台训练、模型共享等多个方面的复杂程度。但是无论 API 如何高级,训练和验证过程中所需要的参数设定、模型结构、数据准备等也都是需要指定的,只不过 tf.estimator 能让这个过程更“优雅”~
可以先一睹为快 model_main.py 中如何优雅地完成训练和验证,核心代码就一行:
tf.estimator.train_and_evaluate(estimator, train_spec, eval_specs[0])
这一行根据训练规范 tf.estimator.TrainSpec 的实例 train_spec 和验证规范 tf.estimator.EvalSpec 的实例 eval_spec ,使用 tf.estimator.train_and_evaluate 对 tf.estimator.Estimator 的实例 estimator 进行训练和验证。所以可以先按照创建实例分为 3 个部分,分别是:
- 实例 estimator;
- 实例 train_spec;
- 实例 eval_spec。
(1)实例 estimator
那么想要用 tf.estimator 来训练和验证,首先你要实例化一个 tf.estimator.Estimator 类,这个类可以使用 tf 预定义好的,也可以自己定义。这个对象包装一个由 model_fn 指定的模型,该模型在给定输入和许多其他参数的情况下,返回执行训练、评估或预测所需的操作。实例化一个 estimator 如下:
tf.estimator.Estimator(
model_fn, model_dir=None, config=None, params=None, warm_start_from=None
)
也就是你必须提供这个描述模型的 model_fn 才可以完成实例化,此部分先说到这里。
(2)实例 train_spec
TrainSpec 包含了训练过程中的各种配置信息,通过以下代码可以得到 TrainSpec 的一个实例:
tf.estimator.TrainSpec(
input_fn, max_steps=None, hooks=None, saving_listeners=None
)
其中的 input_fn 为训练过程提供训练数据的一个 batch,可以是 tf.data.Dataset' 的对象,肯定会包含 features 和 labels;max_stpes 就是训练的步数,如果不加设置默认为 None 意味着训练永不停止。
(3)实例 eval_spec
EvalSpec 包含了验证性能以及存储模型的各种配置信息,通过以下代码可以得到 EvalSpec 的实例:
tf.estimator.EvalSpec(
input_fn, steps=100, name=None, hooks=None, exporters=None,
start_delay_secs=120, throttle_secs=600
)
这里的 input_fn 和 train_spec 里的类型一样,也包含 features 和 labels,只不过是用来验证的。而另一个需要特别指出的是 exporter 负责导出模型,需要设置为 tf.estimator.FinalExporter。
tf.estimator.FinalExporter(
name, serving_input_receiver_fn, assets_extra=None, as_text=False
)
这里的 serving__input_receiver_fn 就只产生 features (待预测),没有 labels 信息。
上面 3 个实例的源信息哪里来?
先简答:pipeline config。
然后再细看下 model_main.py 如何一步步从 pipeline_config 拿到训练和验证需要的信息。其实这部分内容非常多细节,顺着细节一步步爬下去就能找到这个 object detection API 给的很多最基本的定义。比如构建模型、构建过程中使用的各种工具函数。但是实际记录的过程感觉不能再写下去了(捂脸,已经又臭又长没有阅读性了/(ㄒoㄒ)/~~
model_main.py 直接调用 model_lib.py 文件,也就是几乎所有处理所需信息的工具函数都在 model_lib.py 中。
from object_detection import model_lib
接着,model_main.py 定义了多个命令行参数,其中有多个仅仅与 “单独验证” 模型有关,此处不聊~我关注的只有其中 3 个也是前 3 个,如下:
flags.DEFINE_string(
'model_dir', None,
'Path to output model directory where event and checkpoint files will be written.')
flags.DEFINE_string(
'pipeline_config_path', None,
'Path to pipeline config file.')
flags.DEFINE_integer(
'num_train_steps', None,
'Number of train steps.')
FLAGS = flags.FLAGS
其中 num_train_steps 如果不设定,就会从 pipeline_config 当中读取。
接下来,model_main.py 就真的开始干活儿了。
创建 RunConfig 实例
包含训练过程的配置信息:
config = tf.estimator.RunConfig(model_dir=FLAGS.model_dir)
tf.estimator.RunConfig 的使用如下。可以看到 save_checkpoints_steps 和 save_checkpoints_secs 均被设置为 _USE_DEFAULT,此时每隔 600s 就会保存一次模型。keep_checkpoint_max 为 5 也就是最多就保存最新的 5 个模型。
tf.estimator.RunConfig(
model_dir=None, tf_random_seed=None, save_summary_steps=100,
save_checkpoints_steps=_USE_DEFAULT, save_checkpoints_secs=_USE_DEFAULT,
session_config=None, keep_checkpoint_max=5, keep_checkpoint_every_n_hours=10000,
log_step_count_steps=100, train_distribute=None, device_fn=None, protocol=None,
eval_distribute=None, experimental_distribute=None,
experimental_max_worker_delay_secs=None, session_creation_timeout_secs=7200,
checkpoint_save_graph_def=True
)
创建实例 estimator 以及各种 input_fn
train_and_eval_dict = model_lib.create_estimator_and_inputs(
run_config=config,
pipeline_config_path=FLAGS.pipeline_config_path,
train_steps=FLAGS.num_train_steps,
sample_1_of_n_eval_examples=FLAGS.sample_1_of_n_eval_examples,
sample_1_of_n_eval_on_train_examples=(FLAGS.sample_1_of_n_eval_on_train_examples))
estimator = train_and_eval_dict['estimator']
train_input_fn = train_and_eval_dict['train_input_fn']
eval_input_fns = train_and_eval_dict['eval_input_fns']
eval_on_train_input_fn = train_and_eval_dict['eval_on_train_input_fn']
predict_input_fn = train_and_eval_dict['predict_input_fn']
train_steps = train_and_eval_dict['train_steps']
创建实例 train_spec 和 eval_spec
train_spec, eval_specs = model_lib.create_train_and_eval_specs(
train_input_fn,
eval_input_fns,
eval_on_train_input_fn,
predict_input_fn,
train_steps,
eval_on_train_data=False)
训练
回到最开始的“先睹为快”,一行核心代码训练:
tf.estimator.train_and_evaluate(estimator, train_spec, eval_specs[0])
去输出路径拿到训练的模型,再把它 froze、convert 再添加 metadata 就可以放在移动端了。