76、One is All: Bridging the Gap Between Neural Radiance Fields Architectures with Progressive Volume
简介
github:https://github.com/megvii-research/AAAI2023-PVD
神经辐射场(Neural Radiance Fields, NeRF)方法被证明是一种紧凑、高质量和通用的3D场景表示,并支持诸如编辑、检索、导航等下游任务。基于哈希表的表示承认更快的训练和渲染,但它们缺乏明确的几何含义,阻碍了下游任务,如空间关系感知编辑。文章提出了渐进体积蒸馏(PVD),这是一种系统的蒸馏方法,允许在不同的架构之间进行任何到任何的转换,包括MLP、稀疏或低秩张量、哈希表及其组成。PVD使下游应用程序能够以一种事后的方式为手头的任务优化调整神经表示。
转换是快速的,因为蒸馏是逐步执行在不同水平的体积表示,从浅到深。
采用密度的特殊处理方法来处理其特定的数值不稳定性问题
从基于哈希表的Instant-NGP模型中提取出基于mlp的NeRF模型,速度比从头开始训练原始NeRF快10 ~ 20倍,同时实现更高水平的合成质量
 左边是在1.5小时内通过PVD从INGP老师那里提取的NeRF模型的结果。右边是NeRF从零开始训练25小时的结果。PVD提高了合成质量,减少了训练时间。
左边是在1.5小时内通过PVD从INGP老师那里提取的NeRF模型的结果。右边是NeRF从零开始训练25小时的结果。PVD提高了合成质量,减少了训练时间。
贡献点
- 提出了PVD,这是一种蒸馏框架,允许在不同的NeRF架构之间进行转换,包括MLP、稀疏张量、低秩张量和哈希表架构。这是对这种转换的第一次系统尝试。
- 在PVD中,构建了基于不同NeRF架构的统一视图的分段蒸馏策略来加速训练过程。还通过剪切对动态密度体积范围进行了特殊处理,提高了训练的稳定性,显著提高了合成质量
- 作为具体的例子,发现从哈希表和vm分解结构中蒸馏通常有助于提高学生模型合成的质量,并且比从头开始训练花费的时间更少。
实现流程
旨在实现不同结构的神经辐射场之间的相互转换。首先以统一的形式制定典型的架构,然后基于统一的视图设计一个系统的蒸馏方案
NeRF

**Tensors and Low-rank Tensors **

Multi-resolution Hash Encoding

PVD
给定一个经过训练的模型,任务是将其提取到其他模型中,可能具有不同的架构。在PVD中,设计了一个体积对齐的损失,并构建了一个分段蒸馏策略,以加速基于不同NeRF架构的统一视图的训练过程。还通过剪切对动态密度体积范围进行了特殊处理,提高了训练的稳定性,显著提高了合成质量

在PVD中,给定一个训练好的NeRF模型,通过蒸馏可以快速获得不同的NeRF结构,如稀疏张量、MLP、低秩张量和哈希表。中间体积表示中的损失(如 ϕ ∗ 1 \phi^1_∗ ϕ∗1 的输出),颜色和密度与最终渲染的RGB体积一起使用,以加速蒸馏。
Loss
不仅使用RGB,还使用密度、颜色和一个额外的中间特征来计算不同结构之间的损失。观察到混合表示中的内隐结构和外显结构是自然分离的,并对应于不同的学习目标。将一个模型分割成这种相似的表达形式,以便在蒸馏过程中不同的部分可以对齐。
给定一个模型 ϕ ∗ \phi_* ϕ∗,将其表示为两个模块的级联

其中 k = 4
对于混合表示,直接将显式部分看作 ϕ ∗ 1 \phi^1_∗ ϕ∗1,将隐式部分看作 ϕ ∗ 2 \phi^2_∗ ϕ∗2。
对于纯隐式表示,将网络按照深度分为层数相近的两部分,将前一部分表示为 ϕ ∗ 1 \phi^1_∗ ϕ∗1,后一部分表示为 ϕ ∗ 2 \phi^2_∗ ϕ∗2
对于纯显式表示Plenoxels,仍然把它分成两部分,让 ϕ ∗ 2 \phi^2_∗ ϕ∗2 作为恒等式,尽管它可以不分裂地变换
volume-aligned losses
![]()
从本质上讲,设计这种损失的原因是,不同形式的模型可以映射到代表场景的相同空间,体积定向损失可以显著提高蒸馏速度和质量。
总损失为
![]()
L σ 、 L c 、 L r g b L^σ、L^c、L^{rgb} Lσ、Lc、Lrgb 分别表示密度损失、颜色损失和RGB损失。其中 L c L^c Lc 表示每个采样点的颜色损失, L r g b L^{rgb} Lrgb 表示体渲染颜色损失。 L r e g L_{reg} Lreg 表示正则化项,它取决于学生模型的形式。对于Plenoxels 和 vm分解,添加 L 1 L_1 L1 稀疏性损失和总变分(TV)正则化损失。只在Plenoxels上执行密度、颜色、RGB和正则化损失来进行显式表示
Density Range Constrain
密度损失 σ 很难直接优化,归结为它特定的数值不稳定性,密度反映了空间中某一点的透光率。当σ大于或小于某一值时,其物理意义是一致的(即完全透明或完全不透明)。σ的取值范围对于教师来说可能太宽了,但事实上,只有一个密度值区间起着关键作用。将 σ 的数值范围限定为[a, b]。
L σ L^σ Lσ 为
![]()
根据实验,这种限制对教师的表现影响不大,却给蒸馏带来了巨大的好处。也考虑直接在 e x p ( − σ i δ i ) exp(−σ_iδ_i) exp(−σiδi) 上执行密度损失,但发现这是一种低效率的方法,因为exp的梯度更容易饱和,并且它需要计算一个指数,这增加了块实现时的计算量。
Block-wise Distillation
在体绘制过程中,大部分计算发生在每个采样点的MLP转发中,并对每条射线的输出进行积分。如此繁重的过程大大减慢了训练和蒸馏的速度。由于 L 2 v L_2^v L2v 的设计,可以实现块策略来解决这个问题。
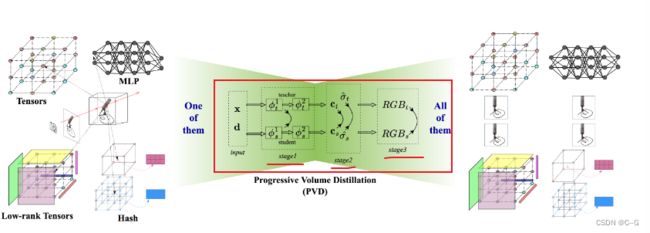
在训练开始时只转发stage1,然后依次运行stage2和stage3。学生和老师不需要在训练的早期阶段转发完整的网络并渲染RGB
训练细节
采用adam优化器,学习率为0.02,训练迭代20k步,每个batc采样4096条射线,对于蒸馏,分别用2e-3、2e-3、2e-3和1初始化体积对齐、密度、颜色和RGB的损失率。第一阶段消耗3k步,第二阶段消耗5k步,第三阶段将消耗所有剩余的步骤。代码运行在NVIDIA V100 GPU上
实验



Limitations
也有一些从蒸馏继承来的局限性。例如,学生模型的性能通常受教师模型性能的上限,在这种情况下,进一步的微调可能是有益的。类似地,学生模型的建模能力可能会限制其最终性能。此外,由于教师模型和学生模型在训练过程中都需要处于活动状态,内存和计算成本也会相应增加。