用正则匹配生成固定格式的随机文本python
用正则匹配生成固定格式的随机文本python
- 生成文本
-
- 导入python包
- 生成随机数字--年龄
- 生成随机英文名
- 生成随机城市名
- 正则匹配
-
- 构造重复字符串
生成文本
导入python包
import random
import string
import numpy as np
import pandas as pd
生成随机数字–年龄
age=[]
for i in range(10, 100):
num = random.randint(10,100)
age.append(num)
#age
生成随机英文名
name=[]
for i in range(100):
name_str = ''.join(random.sample(string.ascii_letters, random.randint(3, 5)))
name.append(name_str.capitalize())
#name
生成随机城市名
city=[]
for i in range(100):
city_str=''.join(random.sample(string.ascii_letters, random.randint(5,7)))
city.append(city_str.upper())
#city
#age
- age默认为2位数;
- name默认为首字母大写的3-5个英文字母;
- city默认为5-7个大写英文字母;
正则匹配
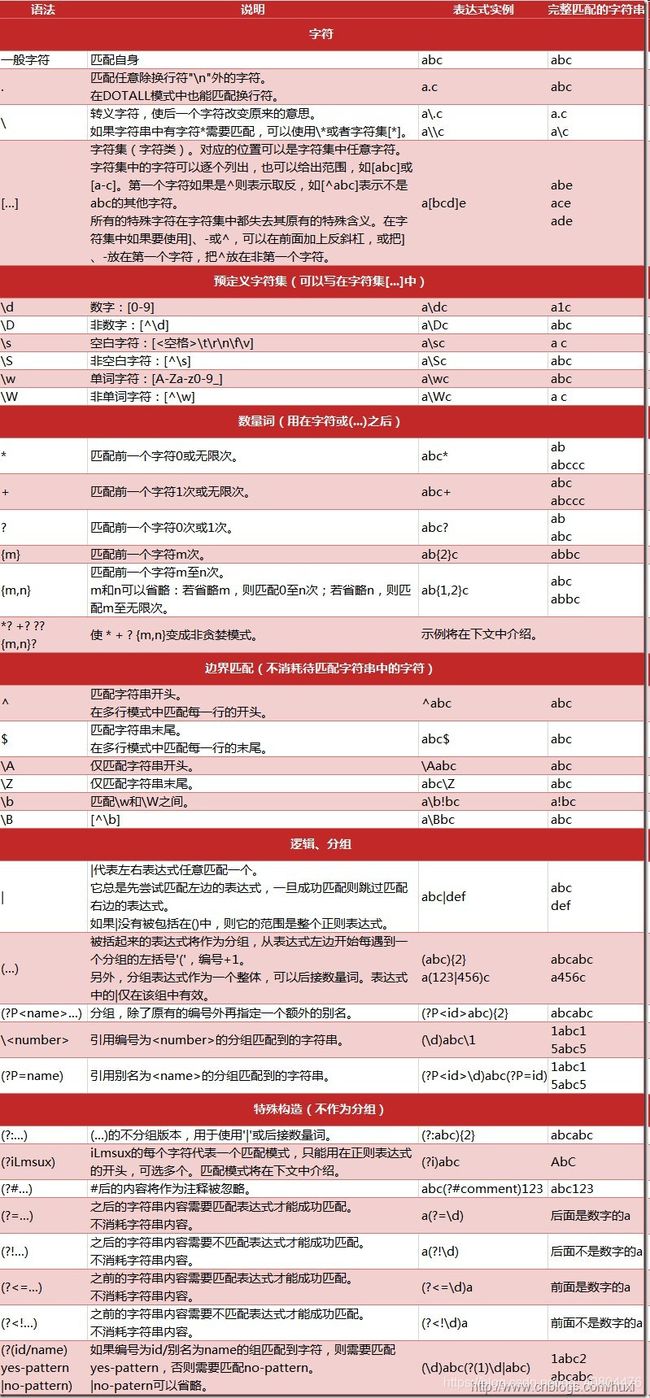
- 当你要匹配 一个/多个/任意个 数字/字母/非数字/非字母/某几个字符/任意字符,想要 贪婪/非贪婪 匹配,想要捕获匹配出来的 第一个/所有 内容的时候,python正则表达式小抄:
构造重复字符串
# data_raw
Hi, I'm [Bob] and I from {SZ}, I'm (18) years old.
Hello, I am [RPI], I'm (20) years old and I come from {GZ}.
I born in {YuLin}. I'm (24), just call me [ATA].
I don't want to tell you my name, but I from {ShangHai}.
Hey My name is [CZW], I live in {HangZhou}, what's your name?
Hi, I'm [Tom] and I from {RY}, I'm (78) years old.
Hello, I am [ABG], I'm (40) years old and I come from {HU}.
I born in {Liuzhou}. I'm (24), just call me [HYU].
I don't want to tell you my name, but I from {Nanchang}.
Hey My name is [YUN], I live in {WUHAN}, what's your name?
Hi, I'm [Lily] and I from {BJ}, I'm (6) years old.
Hello, I am [Yin], I'm (23) years old and I come from {guigang}.
## 构造重复字符串
with open('data_raw.txt') as f:
essay=f.read()
import re
sen=essay.strip().split('\n')
train_text=[]
for i in range(len(age)):
for row in sen:
str1=row
ages = re.sub(r'\(.*?\)','(%s)'%(random.choice(age)), str1)
names = re.sub(r'\[.*?\]',f'[{random.choice(name)}]', str1)
cities = re.sub(r'\{.*?\}','{%s}'%(random.choice(city)), str1)
train_text.append(str1)
#train_text
random.shuffle(train_text)
如此,便可自己构造数据来进行NLP处理。