TensorFlow实战:LSTM的结构与cell中的参数
一些参数
-
训练的话一般一批一批训练,即让batch_size 个句子同时训练;
-
每个句子的单词个数为num_steps,由于句子长度就是时间长度,因此用num_steps代表句子长度。
-
在NLP问题中,我们用词向量表示一个单词(一个数基本不能表示一个词,大家应该都知道的吧,可以去了解下词向量),我们设定词向量的长度为wordvec_size。
-
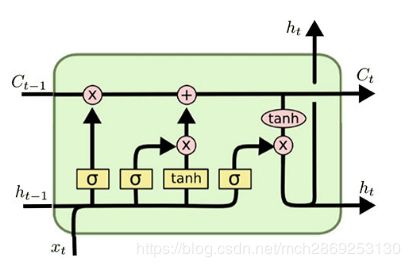
LSTM结构中是一个神经网络,即下图的结构就是一个LSTM单元,里面的每个黄框是一个神经网络,这个网络的隐藏单元个数我们设为hidden_size,那么这个LSTM单元里就有4*hidden_size个隐藏单元。
-
每个LSTM输出的都是向量,包括CtC_{t}Ct和hth_{t}ht,它们的长度都是当前LSTM单元的hidden_size(后面会解释到)。
-
语料库中单词的个数是vocab_size
单层LSTM
我们结合具体代码来讲,以下是一个单层的LSTM的最基本结构
cell = tf.contrib.rnn.LSTMBlockCell(hidden_size, forget_bias=0.0)
outputs = []
state = self._initial_state # state
with tf.variable_scope("RNN"):
for time_step in range(num_steps):
if time_step > 0: tf.get_variable_scope().reuse_variables()
# cell_output: [batch_size,hidden_size]
(cell_output, state) = cell(inputs[:,time_step,:], state)
# outputs: a list: num_steps elements of shape [batch_size,hidden_size]
outputs.append(cell_output)
# output: first to shape:[batch_size,num_steps*hidden_size] and the first row is the data of the first sentense
# and then reshpae to shape: [batch_size*num_steps,hidden_size], first num_steps rows is a sentense
output = tf.reshape(tf.concat(outputs,1), [-1, hidden_size])
# 7.Softmax: convert wordvec to probability for each word in vocab and calculate cross_entropy loss
# used to find which word in vocab the wordvec is like
softmax_w = tf.get_variable("softmax_w", [hidden_size, vocab_size], dtype=data_type())
softmax_b = tf.get_variable("softmax_b", [vocab_size], dtype=data_type())
用LSTMBlockCell构造了一个LSTM单元,单元里的隐藏单元个数是hidden_size,有四个神经网络,每个神经网络的输入是ht−1h_{t-1}ht−1和xtx_{t}xt,将它们concat到一起,维度为hidden_size+wordvec_sizehidden\_size+wordvec\_sizehidden_size+wordvec_size,所以LSTM里的每个黄框的参数矩阵的维度为 [hidden_size+wordvec_size,hidden_sizehidden\_size+wordvec\_size, hidden\_sizehidden_size+wordvec_size,hidden_size]
需要注意的是,num_steps个时刻的LSTM都是共享一套参数的,说是有num_steps个LSTM单元,其实只有一个,只不过是对这个单元执行num_steps次。
上面的代码中有个for循环,是以时间进行展开,在循环里执行当前时刻下的单词。
例子
举个例子,比如一条语句有20个单词,每个词向量长度为200,隐藏层单元个数为128。
那么训练这条语句,输入的tensor维度是[20,200][20,200][20,200],hth_{t}ht 和 ctc_{t}ct的维度是[128][128][128],那么LSTM单元参数矩阵的维度是[128+200,4∗128128+200,4*128128+200,4∗128],
在时刻2,把这句话的第二个单词作为输入,即输入一个[200][200][200]维的向量,由于会和h1h_{1}h1 进行concat,输入矩阵变成了[200+128][200+128][200+128],输入矩阵会和参数矩阵[200+128,4∗128][200+128,4*128][200+128,4∗128]相乘,输出为[4∗128][4*128][4∗128],也就是每个黄框的输出为[128][128][128],黄框之间会进行一些操作,但不改变维度,输出依旧是[128][128][128],即这条语句经过LSTM单元后,输出的C2C_{2}C2, h2h_{2}h2的维度是128,所以上一章节的每个LSTM输出的都是向量,它们的长度都是当前LSTM单元的hidden_size 得到了解释。
但是这样每次只训练一句话效率太低,实际的神经网络采用批量训练的方法,比如每次输入64条语句。那么训练这64条语句,输入的张量维度是[64,20,200][64,20,200][64,20,200],hth_{t}ht 和 ctc_{t}ct的维度是[128],那么LSTM单元参数矩阵的维度是[128+200,4∗128128+200,4*128128+200,4∗128],
在时刻2,把64句话的第二个单词作为输入,即输入一个[64,200][64,200][64,200]的矩阵,由于会和h1h_{1}h1 进行concat,输入矩阵变成了[64,200+128][64, 200+128][64,200+128],输入矩阵会和参数矩阵[200+128,4∗128200+128,4*128200+128,4∗128]相乘,输出为[64,4∗128][64,4*128][64,4∗128],也就是每个黄框的输出为[64,128][64,128][64,128],表示的是每个黄框对这64句话的第二个单词的参数,总共有4个黄框,故cell_output的维度为[64,4∗128][64, 4*128][64,4∗128]。这是在时刻2的输出,依次计算到时刻20,最后outputs的维度是[20,64,4∗128][20,64, 4*128][20,64,4∗128].
softmax相当于全连接层,将outputs映射到vocab_size个单词上,进行交叉熵误差计算。然后根据误差更新LSTM参数矩阵和全连接层的参数。
从上面可以看出,LSTM的
输入的tensor的维度是3维,分别是[batch_size,num_step,vector_size][batch\_size, num\_step, vector\_size][batch_size,num_step,vector_size],分别表示批量的大小、时间步长、输入向量的维度。
输出的tensor的维度是3维,分别是[num_step,batch_size,4∗hidden_size][num\_step, batch\_size, 4*hidden\_size][num_step,batch_size,4∗hidden_size],分别表示时间步长(其实这里理解为一句话的单词个数更好),批量的大小、参数的个数。
双/多层LSTM
双/多层LSTM 与单层的差不多,我们在刚才的例子上进行补充,如果要加上第二层LSTM怎么办,首先第一次的LSTM是不需要变得,第二层的LSTM的参数矩阵维度是多少呢?
我们刚才知道了第一层的LSTM的输出的维度是[128][128][128],这个输出需要作为第二层LSTM的输入xtx_{t}xt
,假如第二层的隐藏层单元个数为hidden_size2,那么第二层LSTM单元里每个黄框的参数矩阵维度为[hidden_size2+128,hidden_size2][hidden\_size2+128,hidden\_size2][hidden_size2+128,hidden_size2]。
softmax_w的维度也得修改成[hidden_size2,vocab_size][hidden\_size2, vocab\_size][hidden_size2,vocab_size]。
代码为:
cell = tf.nn.rnn_cell.BasicLSTMCell(hidden_size, forget_bias=0.0, state_is_tuple=True)
cell2 = tf.nn.rnn_cell.BasicLSTMCell(hidden_size2, forget_bias=0.0, state_is_tuple=True)
cell = tf.contrib.rnn.MultiRNNCell([cell,cell2], state_is_tuple=True)
outputs = []
state = self._initial_state # state
with tf.variable_scope("RNN"):
for time_step in range(num_steps):
if time_step > 0: tf.get_variable_scope().reuse_variables()
# cell_output: [batch_size,hidden_size]
(cell_output, state) = cell(inputs[:,time_step,:], state)
# outputs: a list: num_steps elements of shape [batch_size,hidden_size]
outputs.append(cell_output)
# output: first to shape:[batch_size,num_steps*hidden_size] and the first row is the data of the first sentense
# and then reshpae to shape: [batch_size*num_steps,hidden_size], first num_steps rows is a sentense
output = tf.reshape(tf.concat(outputs,1), [-1, hidden_size2])
# 7.Softmax: convert wordvec to probability for each word in vocab and calculate cross_entropy loss
# used to find which word in vocab the wordvec is like
softmax_w = tf.get_variable("softmax_w", [hidden_size2, vocab_size], dtype=data_type())
softmax_b = tf.get_variable("softmax_b", [vocab_size], dtype=data_type())
特别注意
如果一二两层的LSTM一样的话可以写成
cell = tf.contrib.rnn.MultiRNNCell([cell,cell], state_is_tuple=True)但千万不要写成
cell = tf.contrib.rnn.MultiRNNCell([cell]*2, state_is_tuple=True)多层的LSTM/RNN可能还需要dropout
dropout是一种非常efficient的regularization方法,在rnn中如何使用dropout和cnn不同,推荐大家去把recurrent neural network regularization看一遍。我在这里仅讲结论,
如下图所示,横向不进行dropout,也就是说从 t-1 时候的状态传递到 t 时刻进行计算时,这个中间不进行memory的dropout;仅在同一个 t 时刻对应的纵向进行dropout。也就是在纵向虚线所在的地方进行dropout。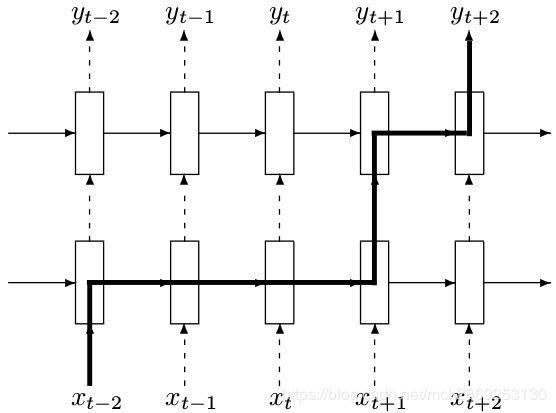
因此,我们在代码中定义完cell之后,在cell外部包裹上dropout,这个类叫DropoutWrapper,这样我们的cell就有了dropout功能!
可以从官方文档中看到,它有input_keep_prob 和 output_keep_prob,也就是说裹上这个DropoutWrapper之后,如果我希望是input传入这个 cell 时dropout掉一部分input信息的话,就设置input_keep_prob,那么传入到cell的就是部分input;如果我希望这个cell的output只部分作为下一层cell的input的话,就定义output_keep_prob。不要太方便。
根据Zaremba在paper中的描述,这里应该给cell设置output_keep_prob。
if is_training and config.keep_prob < 1:
lstm_cell = tf.nn.rnn_cell.DropoutWrapper(
lstm_cell, output_keep_prob=config.keep_prob)
转载自:
https://blog.csdn.net/wjc1182511338/article/details/79689409#commentBox
https://blog.csdn.net/mydear_11000/article/details/52414342
部分地方有补充
转载自:https://blog.csdn.net/mch2869253130/article/details/89156362