自然语言处理NLP——中文抽取式自动文摘(包括中文语料库处理、三种方法实现自动文摘、Rouge评价方法对自动文摘进行打分)
利用三种方法实现抽取式自动摘要,并给摘要结果打分(一、textrank 二、word2vec+textrank 三、MMR 四、Rouge评测)
具体代码我上传到了Github上,其中有45篇小论文(包括三种摘要方法生成的摘要、标准摘要和各摘要方法生成的摘要的p、r、f值),地址如下:
https://github.com/God-Fish-X/Extractable-automatic-Text
-
网上有很多关于自动文摘的博客和资料,我主要参考自ReignsDu作者,原文地址为https://blog.csdn.net/reigns_(在作者博客的最下方)
-
此篇博客也是我参考的重点https://blog.csdn.net/qq_22636145/article/details/75099792?locationNum=5&fps=1
-
写这篇博客的目的主要是记录一下在学习过程中遇到的一些问题,和这些问题的解决方案。
前期准备工作(包括下载中文语料库、提取正文、繁简转化、jieba分词、训练模型)
-
首先是中文语料库的下载,我使用的是维基百科的中文语料,下载地址是https://dumps.wikimedia.org/zhwiki/
选择最新的即可
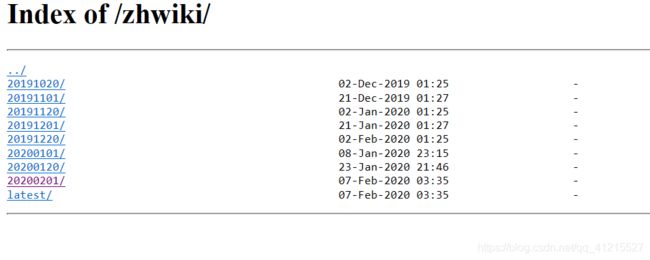
选择较大的文件下载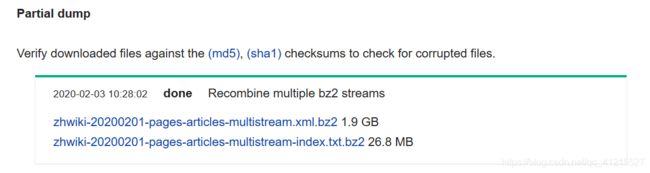
-
接着下载意大利程序员用python研发的维基百科抽取器,可抽取出维基百科中文语料库的内容并输出。
下载地址为:https://github.com/attardi/wikiextractorwin下需要更改文件中的input行,如下图,并用如下语句提取内容(我将分割的数值设置到2048m,把所有内容提取到一个文档中)

-
抽取出来的内容是繁体,用opencc对语料库进行繁简转换
-
使用pip install opencc安装opencc包,遇到的错误无法解决,在查找资料后选择用如下新包,无法安装的问题得以解决

但此时又遇到了新的问题,在win下安装好后仍报错找不到opencc,即使将opencc的地址添加到path中后问题仍然得不到解决 -
此处我的解决方法是把提取出的内容拷到ubuntu系统下,在ubuntu系统下重新安装opencc,完成繁简转换
-
将ubuntu下处理好的语料库重新拷贝到win下,开始jieba分词以及去除停用词(网上有很多停用词文档,自行下载即可)
import jieba
import codecs
import re
file_chinese_one = codecs.open('cut_zh_wiki.txt',"a+",'utf-8')
#file_chinese_two = codecs.open('cut_zh_wiki_01.txt',"a+",'utf-8')
stopwordslist = [line.strip() for line in open('stopwords.txt',encoding='utf-8').readlines()] #创建停用词列表
for line in open("chinese_corpus/zh_wiki_00",'r',encoding='utf-8'):
for i in re.sub('[a-zA-Z0-9]', '', line).split(' '):
if i != '':
data = list(jieba.cut(i, cut_all = False))
readline = ' '.join(data) + '\n'
file_chinese_one.write(readline)
file_chinese_one.close()
#去除停用词
for line in open("zh_wiki","r",encoding='utf-8'):
for i in re.sub('[a-zA-Z0-9]','',line).split(' '):
if i != '':
data = list(jieba.cut(i,cut_all=False))
outstr = ''
for word in data:
if word not in stopwordslist:
if word != '\t':
outstr += word
outstr += " "
file_chinese_one.write(outstr + '\n')
file_chinese_one.close()- 这一步是模型训练,在此处我踩坑无数,浪费了将近20个小时
此处用word2vec进行模型训练
代码如下
from gensim.models import word2vec
import logging
logging.basicConfig(format = '%(asctime)s : %(levelname)s : %(message)s',level=logging.INFO)
sentences_one = word2vec.LineSentence(u'./cut_zh_wiki.txt')
#sentences_two = word2vec.LineSentence(u'./cut_zh_wiki_01.txt')
model_one = word2vec.Word2Vec(sentences_one,size=200,window=10,min_count=64,sg=1,hs=1,iter=10,workers=25)
#model_two = word2vec.Word2Vec(sentences_two,size=200,window=10,min_count=64,sg=1,hs=1,iter=10,workers=25)
model_one.save(u'./train_test_x/word2vec2')
#model_one.wv.save_word2vec_format(u'./w2v',binary=False)
#model_two.save(u'./word2vec2')(此处遇到的问题是,训练后的模型在pycharm中打开是乱码,导致我以为是我文档的编码有问题,导致训练出错;1、我更改了编码方式再次进行训练,结果仍是乱码;2、用别的代码进行模型训练,结果仍是乱码;3、这次我尝试直接测试模型,发现虽然文档打开是乱码,但是测试模型输出是并非乱码;4、于是我重新用上面的代码进行了最后一次训练,训练完成后文档打开虽然是乱码,但可以正常的进行模型测试)
我训练模型用的是笔记本,配置为 7代i5(HQ)、16G内存、2.50GHz四核,每次训练的时间大概在5到6个小时
以下是测试代码和测试结果
from gensim.models import word2vec
model = word2vec.Word2Vec.load(u'./train_test_x/word2vec2')
similar = model.wv.similarity(u'南京',u'上海')
print("南京与上海的相似度为:",similar)
similar = model.wv.similarity(u'太原',u'上海')
print("太原与合肥的相似度为:",similar)
print("与'计算机'最相近的单词")
result = model.wv.most_similar(u'地点',topn=20)
for each in result:
print(each)
print()
接下来的内容且等日后再更新
核心部分(一、textrank 二、word2vec+textrank 三、MMR )
一、textrank
- 需要用到的库
import jieba
import math
from string import punctuation
from heapq import nlargest
from itertools import product, count
from gensim.models import word2vec
import numpy as np
import sklearn.metrics.pairwise
import paddle.fluid as fluid- cut_sentences()函数:将一篇文章分割成一个个句子
def cut_sentences(sentence):
#以。!?.为结束符,对文章进行分割
puns = frozenset(u"'。") #返回一个冻结的集合
tmp = []
for ch in sentence:
tmp.append(ch) #逐字遍历文章并添加到tmp中
if puns.__contains__(ch): #如果遇到句子结束符
yield ''.join(tmp) #将结束符拼接到tmp,并返回
tmp = []
yield ''.join(tmp)- create_stopwords()函数:创建停用词列表
def create_stopwords():
stop_list = [line.strip() for line in open("stopwords.txt", 'r', encoding='utf-8').readlines()] #去除首尾空格,创建停用词列表
return stop_list- compute_similarity_by_avg(word_list1,word_list2)函数:使用TextRank算法中计算相似度的方法得出两个向量之间的相似度
def compute_similarity_by_avg(word_list1,word_list2):
#两个向量之间的相似度
words = list(set(word_list1 + word_list2))
vector1 = [float(word_list1.count(word)) for word in words]
vector2 = [float(word_list2.count(word)) for word in words]
vector3 = [vector1[x] * vector2[x] for x in range(len(vector1))]
vector4 = [1 for num in vector3 if num > 0.]
co_occur_num = sum(vector4)
if abs(co_occur_num) <= 1e-12:
return 0.
denominator = math.log(float(len(word_list1))) + math.log(float(len(word_list2))) # 分母
if abs(denominator) < 1e-12:
return 0.
return co_occur_num / denominator- calculate_score(weight_graph,scores,i)函数:使用TextRank算法的公式计算句子分数
def calculate_score(weight_graph,scores,i):
#句子权重计算
length = len(weight_graph)
d = 0.85
added_score = 0.0
for j in range(length):
fraction = 0.0
denominator = 0.0
#计算分子
fraction = weight_graph[j][i] * scores[j]
#计算分母
for k in range(length):
denominator += weight_graph[j][k]
if denominator == 0:
denominator = 1
added_score += fraction / denominator
#计算最终分数
weighted_score = (1 - d) + d * added_score
return weighted_score- weight_sentences_rank(weight_graph)函数:迭代计算句子的分数,直至趋于稳定
def weight_sentences_rank(weight_graph):
#句子排序
#初始分数设置为0.5
scores = [0.5 for _ in range(len(weight_graph))]
old_scores = [0.0 for _ in range(len(weight_graph))]
#开始迭代
while different(scores,old_scores):
for i in range(len(weight_graph)):
old_scores[i] = scores[i]
for i in range(len(weight_graph)):
scores[i] = calculate_score(weight_graph,scores,i)
return scores- def different(scores,old_scores)函数:当句子分数前后相差不到0.0001时迭代结束
def different(scores,old_scores):
#判断前后分数有无变化
flag = False
for i in range(len(scores)):
if math.fabs(scores[i] - old_scores[i]) >= 0.0001:
flag = True
break
return flag- filter_model(sents,model)函数:过滤掉文章中的停用词
def filter_model(sents):
#过滤停用词
stopwords = create_stopwords() + ['。', ' ', '.']
_sents = []
for sentence in sents:
for word in sentence:
if word in stopwords:
sentence.remove(word)
if sentence:
_sents.append(sentence)
return _sents- create_graph(word_sent)函数:建图函数
def create_graph(word_sent):
#传入句子链表 返回句子之间相似度的图
num = len(word_sent[0])
board = [[0.0 for _ in range(num)] for _ in range(num)]
for i, j in product(range(num), repeat=2):
if i != j:
compute_similarity = compute_similarity_by_avg(word_sent[0][i],word_sent[0][j])
board[i][j] = compute_similarity
return board- summarize(text,n)函数:主函数
def summarize(text,n):
tokens = cut_sentences(text)
sentences = []
sents = []
for sent in tokens:
sentences.append(sent)
sents.append([word for word in jieba.cut(sent) if word])
#sents = filter_model(sents,model)
sents = filter_model(sents)
graph = create_graph(sents)
scores= weight_sentences_rank(graph)
sent_selected = nlargest(n,zip(scores,count()))
sent_index = []
for i in range(n):
sent_index.append(sent_selected[i][1])
return [sentences[i] for i in sent_index]- 展示界面函数
from tkinter import *
import textrank
def run():
txt = txtone.get("0.0",'end')
with open("test.txt","w",encoding = 'utf-8') as f :
f.write(txt)
with open("test.txt", "r", encoding='utf-8') as njuptcs:
txt = [line.strip() for line in open("test.txt", "r",encoding='utf-8').readlines()]
text = njuptcs.read().replace('\n', '')
print ('原文为:')
for i in txt:
print (i)
summarize_text = textrank.summarize(text,3)
#summarize_text = textrank.summarize(text,5)
print ('摘要为:')
#ing = 0
for i in summarize_text:
#ing += 1
#txttwo.insert('end',ing)
#txttwo.insert('end','、')
txttwo.insert('end',i)
txttwo.insert('end','\n')
#print (ing,i)
txttwo.insert('end','\n')
#初始化Tk()
myWindow = Tk()
myWindow.minsize(830,480)
#设置标题
myWindow.title('论文摘要自动生成系统(Textrank)')
#标签控件布局
Label(myWindow, text = "输入文本",font = ('微软雅黑 12 bold')).grid(row = 0,column = 0)
Label(myWindow, text = "输出摘要",font = ('微软雅黑 12 bold')).grid(row = 0,column = 2)
#Entry控件布局
entry1=Entry(myWindow)
txtone = Text(entry1)
txtone.pack()
entry2=Entry(myWindow)
txttwo = Text(entry2)
txttwo.pack()
entry1.grid(row = 0, column = 1)
entry2.grid(row = 0, column = 3)
#Quit按钮退出;Run按钮打印计算结果
Button(myWindow, text='退出',command = myWindow.quit, font = ('微软雅黑 12 bold')).grid(row = 1, column = 3,sticky = S,padx = 20,pady = 20)
Button(myWindow, text='运行',command = run, font = ('微软雅黑 12 bold')).grid(row = 1, column = 1, sticky = S, padx = 20,pady = 20)
#进入消息循环
myWindow.mainloop()textrank结果展示

二、TextRank+Word2vec
- 需要用到的库
import jieba
import math
from string import punctuation
from heapq import nlargest
from itertools import product, count
from gensim.models import word2vec
import numpy as np- def cut_sentences(sentence)函数、def create_stopwords()函数、def calculate_score(weight_graph,scores,i)函数、def different(scores,old_scores)函数、def weight_sentences_rank(weight_graph)函数、def create_graph(word_sent)函数、def summarize(text,n)函数与上面TextRank模块中的函数一样
- def cosine_similarity(vec1, vec2)函数:计算两个向量间的余弦相似度
def cosine_similarity(vec1, vec2):
#计算两个向量之间的余弦相似度
tx = np.array(vec1)
ty = np.array(vec2)
cos1 = np.sum(tx * ty)
denom = np.linalg.norm(tx) * np.linalg.norm(ty)
cosine_value = cos1/denom
#print(vec1+vec2+cosine_value)
return cosine_value- def compute_similarity_by_avg(sents_1,sents_2)函数:利用cosine_similarity()函数计算两个向量之间的相似度,向量的初始值由Word2vec训练得到的模型给出,若向量中的词没有出现在模型中,则该词赋值为0,如果出现在模型中,则按模型中的值计算。
def compute_similarity_by_avg(sents_1,sents_2):
#两个向量之间的相似度
if len(sents_1) == 0 or len(sents_2) == 0:
return 0.0
if sents_1[0] not in model:
vec1 = 0
else:
vec1 = model[sents_1[0]]
for word1 in sents_1[1:]:
if word1 in model:
vec1 = vec1 + model[word1]
if sents_2[0] not in model:
vec2 = 0
else:
vec2 = model[sents_2[0]]
for word2 in sents_2[1:]:
if word2 in model:
vec2 = vec2 + model[word2]
similarity = cosine_similarity(vec1 / len(sents_1), vec2 / len(sents_2))
return similarity- def filter_model(sents)函数:过滤函数
def filter_model(sents):
_sents = []
for sentence in sents:
for word in sentence:
if word not in model:
sentence.remove(word)
if sentence:
_sents.append(sentence)
return _sents- 展示界面函数
from tkinter import *
import word2vec_textrank_test
def run():
txt = txtone.get("0.0",'end')
with open("test.txt","w",encoding = 'utf-8') as f :
f.write(txt)
with open("test.txt", "r", encoding='utf-8') as njuptcs:
txt = [line.strip() for line in open("test.txt", "r",encoding='utf-8').readlines()]
text = njuptcs.read().replace('\n', '')
print ('原文为:')
for i in txt:
print (i)
summarize_text = word2vec_textrank_test.summarize(text,3)
#summarize_text = textrank.summarize(text,5)
print ('摘要为:')
#ing = 0
for i in summarize_text:
#ing += 1
#txttwo.insert('end',ing)
#txttwo.insert('end','、')
txttwo.insert('end',i)
txttwo.insert('end','\n')
#print (ing,i)
txttwo.insert('end','\n')
#初始化Tk()
myWindow = Tk()
myWindow.minsize(830,480)
#设置标题
myWindow.title('论文摘要自动生成系统(Word2vec+Textrank)')
#标签控件布局
Label(myWindow, text = "输入文本",font = ('微软雅黑 12 bold')).grid(row = 0,column = 0)
Label(myWindow, text = "输出摘要",font = ('微软雅黑 12 bold')).grid(row = 0,column = 2)
#Entry控件布局
entry1=Entry(myWindow)
txtone = Text(entry1)
txtone.pack()
entry2=Entry(myWindow)
txttwo = Text(entry2)
txttwo.pack()
entry1.grid(row = 0, column = 1)
entry2.grid(row = 0, column = 3)
#Quit按钮退出;Run按钮打印计算结果
Button(myWindow, text='退出',command = myWindow.quit, font = ('微软雅黑 12 bold')).grid(row = 1, column = 3,sticky = S,padx = 20,pady = 20)
Button(myWindow, text='运行',command = run, font = ('微软雅黑 12 bold')).grid(row = 1, column = 1, sticky = S, padx = 20,pady = 20)
#进入消息循环
myWindow.mainloop()word2vec+textrank展示界面

三、MMR
- 需要用到的库
import jieba
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import operator- 创建停用词列表
stopwords = [line.strip() for line in open("stopwords.txt", 'r', encoding='utf-8').readlines()]- def cut_sentences(sentence)函数与上文中的一样
- def cleanData(name)函数:
def cleanData(name):
setlast = jieba.cut(name, cut_all=False)
seg_list = [i.lower() for i in setlast if i not in stopwords]
return " ".join(seg_list)- def calculateSimilarity(sentence, doc)函数:计算句子和句子,句子和文档的余弦相似度
def calculateSimilarity(sentence, doc): # 根据句子和句子,句子和文档的余弦相似度
if doc == []:
return 0
vocab = {}
for word in sentence.split():
vocab[word] = 0 # 生成所在句子的单词字典,值为0
docInOneSentence = '';
for t in doc:
docInOneSentence += (t + ' ') # 所有剩余句子合并
for word in t.split():
vocab[word] = 0 # 所有剩余句子的单词字典,值为0
cv = CountVectorizer(vocabulary=vocab.keys())
docVector = cv.fit_transform([docInOneSentence])
sentenceVector = cv.fit_transform([sentence])
return cosine_similarity(docVector, sentenceVector)[0][0]- 定义空数组
sentences = []
clean = []
originalSentenceOf = {}
scores = {}
alpha = 0.7
summarySet = []- def dic (texts)函数:
def dic (texts):
parts = cut_sentences(texts)
#print(parts)
for part in parts:
cl = cleanData(part) # 句子切分以及去掉停止词
# print (cl)
sentences.append(part) # 原本的句子
clean.append(cl) # 干净有重复的句子
originalSentenceOf[cl] = part # 字典格式
setClean = set(clean) # 干净无重复的句子
return setClean- def summarize(text,n)函数
def summarize(text,n):
sent_index = []
setClean = dic(text)
for data in clean:
temp_doc = setClean - set([data]) # 在除了当前句子的剩余所有句子
score = calculateSimilarity(data, list(temp_doc)) # 计算当前句子与剩余所有句子的相似度
scores[data] = score
while n > 0:
mmr = {}
# kurangkan dengan set summary
for sentence in scores.keys():
if not sentence in summarySet:
mmr[sentence] = alpha * scores[sentence] - (1 - alpha) * calculateSimilarity(sentence, summarySet) # 公式
selected = max(mmr.items(), key=operator.itemgetter(1))[0]
summarySet.append(selected)
#print (summarySet)
n -= 1
# rint str(time.time() - start)
i = 1
for sentence in summarySet:
print(i,end='')
print('、',end='')
print(originalSentenceOf[sentence])
i += 1
sent_index.append(originalSentenceOf[sentence])
return sent_index- 展示界面函数
from tkinter import *
import MMR
def run():
txt = txtone.get("0.0",'end')
with open("test.txt","w",encoding = 'utf-8') as f :
f.write(txt)
with open("test.txt", "r", encoding='utf-8') as njuptcs:
txt = [line.strip() for line in open("test.txt", "r",encoding='utf-8').readlines()]
text = njuptcs.read().replace('\n', '')
print ('原文为:')
for i in txt:
print (i)
summarize_text = MMR.summarize(text,3)
#summarize_text = textrank.summarize(text,5)
print ('摘要为:')
#ing = 0
for i in summarize_text:
#ing += 1
#txttwo.insert('end',ing)
#txttwo.insert('end','、')
txttwo.insert('end',i)
txttwo.insert('end','\n')
#print (ing,i)
txttwo.insert('end', '\n')
#初始化Tk()
myWindow = Tk()
myWindow.minsize(830,480)
#设置标题
myWindow.title('论文摘要自动生成系统(MMR)')
#标签控件布局
Label(myWindow, text = "输入文本",font = ('微软雅黑 12 bold')).grid(row = 0,column = 0)
Label(myWindow, text = "输出摘要",font = ('微软雅黑 12 bold')).grid(row = 0,column = 2)
#Entry控件布局
entry1=Entry(myWindow)
txtone = Text(entry1)
txtone.pack()
entry2=Entry(myWindow)
txttwo = Text(entry2)
txttwo.pack()
entry1.grid(row = 0, column = 1)
entry2.grid(row = 0, column = 3)
#Quit按钮退出;Run按钮打印计算结果
Button(myWindow, text='退出',command = myWindow.quit, font = ('微软雅黑 12 bold')).grid(row = 1, column = 3,sticky = S,padx = 20,pady = 20)
Button(myWindow, text='运行',command = run, font = ('微软雅黑 12 bold')).grid(row = 1, column = 1, sticky = S, padx = 20,pady = 20)
#进入消息循环
myWindow.mainloop()MMR展示界面

Rouge评价部分
#首先使用pip安装rouge
from pprint import pprint
import perl
from pyrouge import Rouge155
from rouge import Rouge
from rouge import FilesRouge
import os,json
#将语料文件中的数据转换成[中文:ID]的形式存储到json文件中
from tqdm import tqdm
min_count = 0
if os.path.exists('seq2seq_config.json'):
chars,id2char,char2id = json.load(open('seq2seq_config.json'))
# id2char = {int(i):j for i,j in id2char.items()}
else:
with open("train_test_old/word2vec2",'r',encoding='utf-8') as f:
titleList = f.readlines()
chars = {}
for singleTitle in titleList:
for w in tqdm(list(singleTitle)): # 纯文本,不用分词
chars[w] = chars.get(w,0) + 1
#字符:数量
chars = {i:j for i,j in chars.items() if j >= min_count}
id2char = {i:j for i,j in enumerate(chars)}
char2id = {j:i for i,j in id2char.items()}
json.dump([chars,id2char,char2id], open('seq2seq_config.json', 'w'))
def str2id(s):
#char2id 字符-id
# 文字转整数id
maxlen = len(s);
ids = [char2id.get(c, 1) for c in s[:maxlen]]
return ids
#将语料转成ID的形式
def dealData(hyp_path,ref_path,new_hyp_path,new_ref_path):
with open(hyp_path,'r',encoding='utf-8') as f:
data = f.readlines();
charIDs = list();
for item in data:
charID = str2id(item);
charID = [str(x) for x in charID]
charIDs.append(charID);
with open(new_hyp_path,'a',encoding='utf-8') as f:
for item in charIDs:
f.write(" ".join(item)+"\n");
with open(ref_path,'r',encoding='utf-8') as f:
data = f.readlines();
charIDs = list();
for item in data:
charID = str2id(item);
charID = [str(x) for x in charID];
charIDs.append(charID);
with open(new_ref_path,'a',encoding='utf-8') as f:
for item in charIDs:
f.write(" ".join(item)+"\n");
#hyp_path是程序给出的摘要,ref_path是标准的摘要
def getRouge(hyp_path,ref_path):
files_rouge = FilesRouge()
rouge = Rouge()
#files_rouge = Rouge155()
# or
#scores = rouge.get_scores(hyp_path,ref_path,avg=True)
scores = files_rouge.get_scores(hyp_path,ref_path,avg=True)
pprint(scores)
if __name__ == '__main__':
f1 = open('system1.txt', "r+")
f1.truncate()
f1.close()
f2 = open('reference1.txt', "r+")
f2.truncate()
f2.close()
dealData('system.txt','reference.txt','system1.txt','reference1.txt')
getRouge('system1.txt','reference1.txt')
# 存有中文的文件
# system.txt
# reference.txt
# 中文转存为ID的文件
# system1.txt
# reference1.txtRouge结果展示
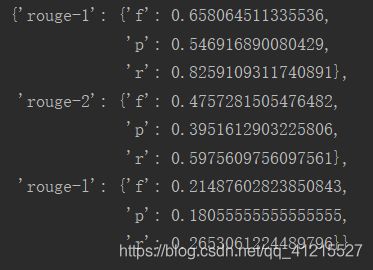
关于本摘要系统,有一个改进的方向,即Word2vec+TextRank算法是基于TextRank算法的,而TextRank算法有其自身的缺陷,那就是提取摘要句时,只关注分数的大小,而不关注提取出的摘要句之间有何种联系,这也就导致提取出的摘要句虽然分数高,但很可能说的是同一个意思,这就大大降低了提取出的摘要的多样性,而本文中的MMR算法考虑到了摘要多样性这一问题,所以如果可以将MMR算法的思想加入到Word2vec+TextRank的算法中,将会提高Word2vec+TextRank算法提取摘要的多样性。