一起读论文 | Complex-order: 一种新的位置编码方式
导读:今天分享一篇华人学者发表在顶会ICLR 2020上的论文《Encoding Word Order in Complex Embeddings》,主要对序列建模的位置信息编码方法进行研究。可以阅读先前的文章《一文读懂Transformer模型中的位置编码》对其中的一种位置信息编码方式的深入分析。本文认为先前的方法需要独立训练每个位置向量,而且也不能建模序列的邻接或者优先关系。本文把这种问题称之为position independence problem。为此,本文提出了一种新颖的方法Complex-order来解决这样的问题。
点评:本文的idea非常简单清晰,带来的效果提升也非常明显,文中的证明推导也非常棒,研究工作非常具有创新性,值得一读。作者开源了实现代码,有兴趣的朋友可以跑一边实验。

研究背景及动机
语言是有顺序的。神经网络在建模这种顺序结构时,因为难以并行化处理,使得计算代价变得非常地高。通过在特征级别上添加position embeddings而不是在神经网络架构上对词的顺序进行建模已经可以减轻这样的问题(参考对位置编码的详细解读),比如Gehring等人的ConvSeq与Vaswani等人著名的Transformer模型。先前的研究工作通过引入额外的位置编码,在Embedding层将词向量与位置向量相加进行融合:
f ( j , p o s ) = f w e ( j ) + f p e ( p o s ) f(j, pos) = f_{we}(j)+f_{pe}(pos) f(j,pos)=fwe(j)+fpe(pos)
但是,这种方法只接受整型数值作为词索引或位置索引,每个词或位置都只能通过独立训练得到。这对每个词向量是合理的,因为词的索引是建立在给定的词典的顺序之上的。但这种方法不能捕捉 ordered relationship(邻接或优先关系),会导致每个位置上的位置向量是彼此独立的,作者称之为position independence problem。这种问题对于位置不敏感的神经网络(如FastText,ConvSeq及Transformer)来说变得尤为重要。
研究内容及方法
本文主要对序列建模的位置信息编码进行研究,针对先前的研究方法可能导致的position independence problem,本文提出了一种非常新颖的改进方法——Complex order——对词的这种全局绝对位置及它们的内在顺序及邻接关系进行建模。这样的话,Gehring等人提出的_position-independent_的位置向量可以被认为是该方法在独立变量上的特例。
作者将每个词嵌入扩展为一个自变量为位置 p o s pos pos 的一个连续函数,好处在于词表示可以随着位置的变化而平滑地移动,不同位置上的词表示就可以互相关联起来。函数定义如下:
f ( j , p o s ) = g j ( p o s ) ∈ R D f(j, pos)=\textbf{g}_j(pos)\in \mathbb{R}^D f(j,pos)=gj(pos)∈RD
其中, f ( j , p o s ) f(j,pos) f(j,pos) 表示此表中序号为 j j j 的单词在位置 p o s pos pos 上的单词向量, g j \mathbf{g}_j gj 是 g w e ( j ) ∈ ( F ) D \mathbf{g}_{we}(j)\in(\mathcal{F})^D gwe(j)∈(F)D 的缩写, D D D 表示函数集合, g w e ( ⋅ ) g_{we}(\cdot) gwe(⋅): N → ( F ) D \mathbb{N} \rightarrow \mathcal(F)^D N→(F)D表示单词索引到函数的映射。展开为:
[ g j , 1 ( p o s ) , g j , 2 ( p o s ) , ⋯ , g j , D ( p o s ) ] ∈ R D [g_{j,1}(pos),g_{j,2}(pos),\cdots,g_{j,D}(pos)] \in \mathbb{R}^D [gj,1(pos),gj,2(pos),⋯,gj,D(pos)]∈RD
对于任意的 g j , d ( ⋅ ) ∈ F g_{j,d}(\cdot) \in \mathcal{F} gj,d(⋅)∈F : N → R \mathbb{N} \rightarrow \mathbb{R} N→R, d ∈ { 1 , 2 , ⋯ , D } d \in \{1, 2, \cdots, D\} d∈{1,2,⋯,D},都是关于位置索引 p o s pos pos的一个函数。在无需改变函数 g j \mathbf{g}_j gj 的情况下,只需要替换一下变量 p o s pos pos 就可以实现把词 w j w_j wj 从当前位置 p o s pos pos 移动到另一个位置 p o s ′ pos^{\prime} pos′。
为了达到上述要求,函数需要满足以下两条性质:
Property 1. Position-free offset transformation:
存在变换函数Transform : N × C → C \mathbb{N}\times \mathbb{C} \rightarrow \mathbb{C} N×C→C,使得对于任意位置 p o s ∈ N pos \in \mathbb{N} pos∈N 和 n > 1 n > 1 n>1,Transform n ( ⋅ ) _n(\cdot) n(⋅)=Transform ( n , ⋅ ) (n, \cdot) (n,⋅)满足:
g ( p o s + n ) = Transform n ( g ( p o s ) ) g(pos+n) = \text{Transform}_n(g(pos)) g(pos+n)=Transformn(g(pos))
作者把这样的函数Transform称之为witness。论文只考虑线性变换,即每个Transform n _n n是一个线性函数。
Property 2. Boundedness:
关于位置变量的函数应该是有界的,也就是:
∃ δ ∈ R + , ∀ pos ∈ N , ∣ g ( pos ) ∣ ≤ δ \exist\delta \in \mathbb{R}^+, \forall \text{pos} \in \mathbb{N}, |g(\text{pos})| \leq \delta ∃δ∈R+,∀pos∈N,∣g(pos)∣≤δ
作者给出了满足上述两条性质的解函数的形式:
g ( p o s ) = z 2 z 1 p o s f o r z 1 , z 2 ∈ C w i t h ∣ z 1 ∣ ≤ 1 g(pos) = z_2z_1^{pos} \ for \ z_1,z_2 \in \mathbb{C} \ with |z_1| \leq 1 g(pos)=z2z1pos for z1,z2∈C with∣z1∣≤1
证明如下:
对于任意位置 n 1 , n 2 ∈ N n_1,n_2 \in \mathbb{N} n1,n2∈N,有
w ( n 1 ) w ( n 2 ) g ( p o s ) = w ( n 2 ) g ( p o s + n 1 ) = g ( p o s + n 1 + n 2 ) = Transform n 1 + n 2 ( g ( p o s ) ) = w ( n 1 + n 2 ) g ( p o s ) \begin{array}{l} w(n_1)w(n_2)g(pos) &= &w(n_2)g(pos+n_1) \\ & = & g(pos+n_1+n_2) \\ & = & \text{Transform}_{n_1+n_2}(g(pos)) \\ & = & w(n_1+n_2)g(pos) \end{array} w(n1)w(n2)g(pos)====w(n2)g(pos+n1)g(pos+n1+n2)Transformn1+n2(g(pos))w(n1+n2)g(pos)
因此有 w ( n 1 + n 2 ) = w ( n 1 ) w ( n 2 ) w(n_1+n_2) = w(n_1)w(n_2) w(n1+n2)=w(n1)w(n2)。令 w ( 1 ) = z 1 w(1) = z_1 w(1)=z1, g ( 0 ) = z 2 g(0) = z_2 g(0)=z2,因为 n 1 n_1 n1, n 2 n_2 n2 是任意的,因此对于所有的 n ∈ N n \in \mathbb{N} n∈N,都有
w ( n ) = ( w ( 1 ) ) n = z 1 n w(n) = (w(1))^n = z_1^n w(n)=(w(1))n=z1n
g ( p o s + n ) = w ( n ) g ( p o s ) = z 1 n g ( p o s ) g(pos+n) = w(n)g(pos) = z_1^ng(pos) g(pos+n)=w(n)g(pos)=z1ng(pos)
而且,当 p o s ≥ 1 pos \geq 1 pos≥1,我们有 g ( p o s ) = g ( 1 + p o s − 1 ) = w ( p o s ) g ( 0 ) = z 1 p o s z 2 = z 2 z 1 p o s g(pos) = g(1+pos - 1) = w(pos)g(0) = z_1^{pos}z_2=z_2z_1^{pos} g(pos)=g(1+pos−1)=w(pos)g(0)=z1posz2=z2z1pos。对于 p o s = 0 pos=0 pos=0, g ( 0 ) = z 2 = z 2 z 1 0 g(0)=z_2=z_2z1^0 g(0)=z2=z2z10,因此有 g ( p o s ) = z 2 z 1 p o s g(pos) = z_2z_1^{pos} g(pos)=z2z1pos。
当 ∣ z 1 ∣ > 1 |z_1| > 1 ∣z1∣>1, g ( p o s ) g(pos) g(pos) 就不是有界函数,因此限制 ∣ z 1 ∣ ≤ 1 |z_1| \leq 1 ∣z1∣≤1,此时, ∣ g ( p o s ) ∣ ≤ ∣ z 2 z 1 p o s ∣ ≤ ∣ z 2 ∣ ∣ z 1 p o s ∣ ≤ ∣ z 2 ∣ |g(pos)| \leq |z_2z_1^{pos}| \leq |z_2||z_1^{pos}| \leq |z_2| ∣g(pos)∣≤∣z2z1pos∣≤∣z2∣∣z1pos∣≤∣z2∣,函数 g g g 就是有界的。
又由 w ( n ) = z 1 n w(n) = z_1^n w(n)=z1n 和 Transform n ( p o s ) = w ( n ) p o s _n(pos)=w(n)pos n(pos)=w(n)pos,对所有的位置 p o s pos pos,得
g ( p o s + n ) = z 2 z 1 p o s + n = z 2 z 1 p o s z 1 n = g ( p o s ) z 1 n = Transform n ( g ( p o s ) ) g(pos + n) = z_2z_1^{pos + n} = z_2z_1^{pos}z_1^n = g(pos)z_1^n = \text{Transform}_n(g(pos)) g(pos+n)=z2z1pos+n=z2z1posz1n=g(pos)z1n=Transformn(g(pos))
得证。
对于任意的 z ∈ C z \in \mathbb{C} z∈C,我们可以写成 z = r e i θ = r ( cos θ + i sin θ ) z = r e^{i\theta} = r(\cos\theta + i \sin\theta) z=reiθ=r(cosθ+isinθ)。因此,可以简化为
g ( p o s ) = z 2 z 1 p o s = r 2 e i θ 2 ( r 1 e i θ 1 ) p o s = r 2 r 1 p o s e i ( θ 2 + θ 1 p o s ) s u b j e c t t o ∣ r 1 ∣ ≤ 1 g(pos) = z_2z_1^{pos} = r_2 e^{i\theta_2}(r_1e^{i\theta_1})^{pos} = r_2r_1^{pos}e^{i(\theta_2+\theta_1pos)} \quad subject \ to \ |r_1| \leq 1 g(pos)=z2z1pos=r2eiθ2(r1eiθ1)pos=r2r1posei(θ2+θ1pos)subject to ∣r1∣≤1
在实现过程中,由于上述 ∣ r 1 ∣ ≤ 1 |r_1| \leq 1 ∣r1∣≤1的限制,函数 g g g的上述定义会导致优化问题,因此一种自然而简单的避免这个问题的方法就是固定 r 1 = 1 r_1 = 1 r1=1,那么 ∣ e i x ∣ ≡ 1 |e^{ix}|\equiv1 ∣eix∣≡1,上式就可以简化为:
g ( p o s ) = r e i ( w pos + θ ) g(pos) = r e^{i(\mathcal{w} \text{pos} + \theta)} g(pos)=rei(wpos+θ)
最终的embedding表示为:
f ( j , p o s ) = g j ( p o s ) = r j e i ( w j p o s + θ j ) = [ r j , 1 e i ( w j , 1 p o s + θ j , 1 ) , ⋯ , r j , 2 e i ( w j , 2 p o s + θ j , 2 ) , ⋯ , r j , D e i ( w j , D p o s + θ j , D ) ] \begin{array}{c} f(j, pos) &=& \mathbf{g}_j(pos) = \mathbf{r}_je^{i(w_j \ pos+\theta_j)} \\ &=& [r_{j,1}e^{i(w_{j,1} \ pos +\theta_{j,1})}, \cdots,r_{j,2}e^{i(w_{j,2} \ pos + \theta_{j,2})}, \cdots, r_{j,D}e^{i(w_{j,D} \ pos + \theta_{j, D})}] \end{array} f(j,pos)==gj(pos)=rjei(wj pos+θj)[rj,1ei(wj,1 pos+θj,1),⋯,rj,2ei(wj,2 pos+θj,2),⋯,rj,Dei(wj,D pos+θj,D)]
其中,每个坐标点 d ( 1 ≤ d ≤ D ) d (1 \leq d \leq D) d(1≤d≤D)都有各自的参数:振幅 r j , d r_{j,d} rj,d 、周期 p j , d p_{j,d} pj,d 、初相 θ j , d \theta_{j,d} θj,d ,这三个参数都是需要学习的参数。表示作者将这种新的编码方式称为 general complex-valued embedding (通用复数值嵌入)。
实验及结果
作者主要在文本分类、机器翻译及语言建模三个任务上对这种新的位置编码进行了评估。
1. 文本分类
实验设置
数据集:采用CR、MPQA、SUBJ、MR、SST、TREC等五个常用数据集,数据集统计如下:

基准方法:选择Fasttext、CNN、LSTM、Transformer等四种神经网络模型,为每个模型分别进行以下四种配置:(1)不使用位置编码;(2)Gehring等人的Vanilla Position Embeddings (PE);(3)Vaswani等人的Trigonometric Position Embeddings (TPE);(4)Wang等人的Complex-vanilla word embeddings;(5)本文提出的位置感应的复数值词嵌入Complex-order。
实验结果如下:

时间消耗对比结果如下:

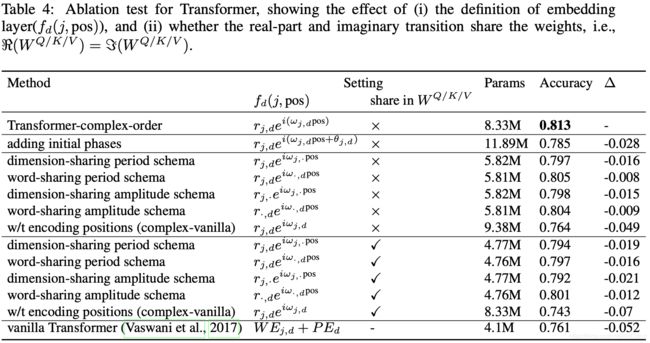
作者还在Transformer模型上进行了消融性测试,结果如下表所示:
2. 机器翻译
数据集:WMT 2016 English-German数据集
基准方法:(1)basic Attentional encoder-decoder (AED);(2)AED with Byte-pair encoding (BPE) subword segmentation for open-vocabulary translation;(3)AED with extra linguistic features;(4)本文的Transformer Complex-order

3. 语言建模
数据集:text8(English Wikipedia articles)
基准方法:BN-LSTM,LN HM-LSTM RHN,Large mLSTM
实验结果如下:

想要了解更多的自然语言处理最新进展、技术干货及学习教程,欢迎关注微信公众号“语言智能技术笔记簿”或扫描二维码添加关注。
