集成学习05-Bagging
集成学习属于模型融合的一部分,常见的集成学习包括Bagging、Boosting、Stacking等。
| 集成学习 | Bagging | bootstrap自助采样 |
| Boosting | 叠加式算法 | |
| Stacking | 一个学习器输出作为下一个学习器输入 |
1. 什么是模型融合
模型融合: 先产生一组”个体学习器” ,再用某种策略将它们结合起来,加强模型效果。
模型融合策略: 基本学习器学习完后,需要将各个模型进行融合,常见的策略有:
(1)平均法: 平均法有一般的评价和加权平均,这个好理解。对于平均法来说一般用于回归预测模型中,在Boosting系列融合模型中,一般采用的是加权平均融合。
(2)投票法:有绝对多数投票(得票超过一半),相对多数投票(得票最多),加权投票。这个也好理解,一般用于分类模型。在bagging模型中使用。
(3)学习法:一种更为强大的结合策略是使用”学习法”,即通过另一个学习器来进行结合,把个体学习器称为初级学习器,用于结合的学习器称为次级学习器或元学习器。常见的有Stacking和Blending两种。
- Stacking方法: Stacking 先从初始数据集训练出初级学习器,然后”生成”一个新数据集用于训练次级学习器。在这个新数据集中,初级学习器的输出被当作样例输入特征,而初始样本的标记仍被当作样例标记。
- Blending方法: Blending与Stacking大致相同,只是Blending的主要区别在于训练集不是通过K-Fold的CV策略来获得预测值从而生成第二阶段模型的特征,而是建立一个Holdout集,例如说10%的训练数据,第二阶段的stacker模型就基于第一阶段模型对这10%训练数据的预测值进行拟合。说白了,就是把Stacking流程中的K-Fold CV 改成 HoldOut CV。
2. 投票法
投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。
(1)投票法在回归模型与分类模型上均可使用:
- 回归投票法:预测结果是所有模型预测结果的平均值。
- 分类投票法:预测结果是所有模型种出现最多的预测结果。
(2)分类投票法又可以被划分为硬投票与软投票:
- 硬投票:预测结果是所有投票结果最多出现的类。
- 软投票:预测结果是所有投票结果中概率加和最大的类。
在投票法中,我们还需要考虑到不同的基模型可能产生的影响。理论上,基模型可以是任何已被训练好的模型。但在实际应用上,想要投票法产生较好的结果,需要满足两个条件:1)基模型之间的效果不能差别过大。当某个基模型相对于其他基模型效果过差时,该模型很可能成为噪声。2)基模型之间应该有较小的同质性。例如在基模型预测效果近似的情况下,基于树模型与线性模型的投票,往往优于两个树模型或两个线性模型。
当投票合集中使用的模型能预测出清晰的类别标签时,适合使用硬投票。当投票集合中使用的模型能预测类别的概率时,适合使用软投票。软投票同样可以用于那些本身并不预测类成员概率的模型,只要他们可以输出类似于概率的预测分数值(例如支持向量机、k-最近邻和决策树)。
投票法的局限性在于,它对所有模型的处理是一样的,这意味着所有模型对预测的贡献是一样的。如果一些模型在某些情况下很好,而在其他情况下很差,这是使用投票法时需要考虑到的一个问题。
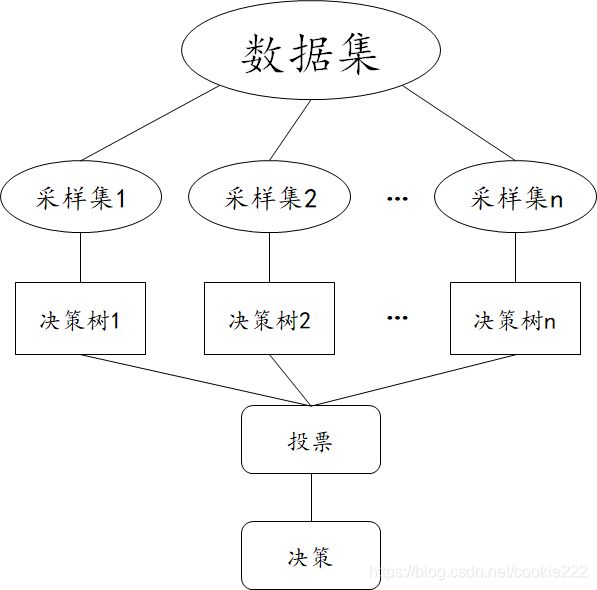
3. Bagging
与投票法不同的是,Bagging不仅仅集成模型最后的预测结果,同时采用一定策略来影响基模型训练,保证基模型可以服从一定的假设。在上一章中我们提到,希望各个模型之间具有较大的差异性,而在实际操作中的模型却往往是同质的,因此一个简单的思路是通过不同的采样增加模型的差异性。
原理:采用自助采样法(Bootstap sampling),即对于m个样本的原始训练集,我们每次先随机采集一个样本放入采样集,接着把该样本放回,也就是说下次采样时该样本仍有可能被采集到,这样采集m次,最终可以得到m个样本的采样集,由于是随机采样,这样每次的采样集是和原始训练集不同的,和其他采样集也是不同的,这样得到多个不同的弱学习器。
对回归问题的预测是通过预测取平均值来进行的。对于分类问题的预测是通过对预测取多数票预测来进行的。
Bagging方法之所以有效,是因为每个模型都是在略微不同的训练数据集上拟合完成的,这又使得每个基模型之间存在略微的差异,使每个基模型拥有略微不同的训练能力。Bagging同样是一种降低方差的技术,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效果更加明显。在实际的使用中,加入列采样的Bagging技术对高维小样本往往有神奇的效果。
4. 随机森林
随机森林是一种bagging算法的应用。“森林”是由许多“树”bagging组成的。在具体实现上,用于每个决策树训练的样本和构建决策树的特征都是通过随机采样得到的,随机森林的预测结果是多个决策树输出的组合(投票)。
对bagging算法的改进包括:改进一:基本学习器限定为决策树,改进二:除了bagging的在样本上加上扰动,同时在属性上也加上扰动,即是在决策树学习的过程中引入了随机属性选择,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。
作业:(任选四道题目)
1.什么是bootstraps?
bootstrap(自助采样)指有放回的从数据集中进行采样,也就是说,同样的一个样本可能被多次进行采样。
2.bootstraps与bagging的联系。
bootstraps是Bagging从数据集中进行采样的方式,通过不同的采样增加各个样本形成模型的差异性,降低了整体模型的方差。
3.什么是bagging?
Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。
4.随机森林与bagging的联系与区别。
联系:随机森林使用了bagging的自助采样方法,“森林”是由许多“树”bagging组成的。
区别:1)随机森林的基本学习器限定为决策树,2)随机森林除了bagging的在样本上加上扰动,同时引入了随机属性选择,进一步降低模型的误差方差。
5.使用偏差与方差理论阐述为什么bagging能提升模型的预测精度?
bagging通过有放回的多次取样,抽样的样本数量越多,样本均值的方差越低,降低的误差方差>增加的误差偏差平方,所以bagging能提升模型的预测精度。
6.请尝试使用bagging与基本分类模型或者回归模型做对比,观察bagging是否相对于基础模型的精度有所提高?(必做)
使用bagging与逻辑回归处理分类问题,bagging的精度稍高。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
# plt.show()
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
# 使用bagging+决策树分类
bagging_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500, max_samples=200,
bootstrap=True)
bagging_clf.fit(X_train, y_train)
score1 = bagging_clf.score(X_test, y_test)
print("使用Bagging分类的准确率:", score1)
# 使用逻辑回归分类
logreg_clf = LogisticRegression(C=1e5)
logreg_clf.fit(X_train, y_train)
score2 = logreg_clf.score(X_test, y_test)
print("使用逻辑回归分类的准确率:",score2)
7.假如让你来实现bagging,你会使用python+numpy+sklearn的基础模型来实现bagging吗?(拓展)
参考链接:
https://github.com/datawhalechina/ensemble-learning
https://blog.csdn.net/u014248127/article/details/78993753