【读文献笔记】图神经网络加速结构综述
【读文献笔记】图神经网络加速结构综述
- 前言
- 一、图神经网络来源
-
- 1.图神经网络用途
- 2.图神经网络特点
- 3.图神经网络主要阶段
- 4.图神经网络加速面临的挑战
- 5.本笔记内容包含内容
- 二、图与图神经网络
-
- 1.图数据结构
- 2.图神经网络模型
- 二、图神经网络编程模型与框架
-
- 主流的图神经网络框架与扩展库
- 三、图神经网络加速的挑战
- 四、图神经网络加速结构分类方案
-
- 1.支持算法方面
- 2.支持阶段方面
- 3.加速平台方面
- 4.关键优化技术方面
- 五、图神经网络加速结构整体分析
- 六、图神经网络关键优化技术
-
- 1.计算优化层次
- 2.片上访存优化层次
- 3.片外访存优化层次
- 七、总结与展望
-
- 1.大规模多节点加速结构
- 2.异质图神经网络加速结构
- 3.算法与阶段支持灵活化.
- 4.图神经网络加速结构产业化落地.
文章目录
- 前言
- 一、图神经网络来源
-
- 1.图神经网络用途
- 2.图神经网络特点
- 3.图神经网络主要阶段
- 4.图神经网络加速面临的挑战
- 5.本笔记内容包含内容
- 二、图与图神经网络
-
- 1.图数据结构
- 2.图神经网络模型
- 二、图神经网络编程模型与框架
-
- 主流的图神经网络框架与扩展库
- 三、图神经网络加速的挑战
- 四、图神经网络加速结构分类方案
-
- 1.支持算法方面
- 2.支持阶段方面
- 3.加速平台方面
- 4.关键优化技术方面
- 五、图神经网络加速结构整体分析
- 六、图神经网络关键优化技术
-
- 1.计算优化层次
- 2.片上访存优化层次
- 3.片外访存优化层次
- 七、总结与展望
-
- 1.大规模多节点加速结构
- 2.异质图神经网络加速结构
- 3.算法与阶段支持灵活化.
- 4.图神经网络加速结构产业化落地.
前言
对图神经网络进行一些关注。
提示:以下是本篇文章正文内容。
一、图神经网络来源
受到传统神经网络与图计算应用的双重启发,图神经网络(graph neural networks, GNNs)应运而生。
1.图神经网络用途
图神经网络使得机器学习能够应用于非欧几里得空间的图结构中,具备对图进行学习的能力.目前图神经网络已经广泛应用到节点分类、风控评估、推荐系统等众多场景中.并且图神经网络被认为是推动人工智能从“感知智能”阶段迈入“认知智能”阶段的核心要素,具有极高的研究和应用价值.
2.图神经网络特点
图神经网络的执行过程混合了传统图计算和神经网络应用的不同特点.
3.图神经网络主要阶段
图神经网络通常包含图聚合和图更新2个主要阶段:
1)图聚合阶段的执行行为与传统图计算相似,需要对邻居分布高度不规则的图进行遍历,为每个节点进行邻居信息的聚合,因此这一阶段具有极为不规则的计算和访存行为特点.
2)图更新阶段的执行行为与传统神经网络相似,通过多层感知机(multi-layer perceptrons, MLPs)等方式来进行节点特征向量的变换与更新,这一阶段具有规则的计算和访存行为特点.
4.图神经网络加速面临的挑战
图神经网络的混合执行行为给应用的加速带来极大挑战,规则与不规则的计算与访存模式共存使得传统处理器结构设计无法对其进行高效处理.图聚合阶段高度不规则的执行行为使得 CPU 无法从其多层次缓存结构与数据预取机制中获益.主要面向密集规则型计算的 GPU 平台也因图聚合阶段图遍历的不规则性、图更新阶段参数共享导致的昂贵数据复制和线程同步开销等因素无法高效执行图神经网络.而已有的面向传统图计算应用和神经网络应用的专用加速结构均只关注于单类应用,无法满足具有混合应用特征的图神经网络加速需求.
5.本笔记内容包含内容
本文首先对图神经网络应用的基础知识、常见算法、应用场景、编程模型以及主流的基于通用平台的框架与扩展库等进行介绍.然后以图神经网络执行行为带来的加速结构设计挑战为出发点,从整体结构设计以及计算、片上访存、片外访存多个层次对该领域的关键优化技术进行详实而系统的分析与介绍.最后还从不同角度对图神经网络加速结构设计的未来方向进行了展望,期望能为该领域的研究人员带来一定的启发.
二、图与图神经网络
1.图数据结构
由于图结构的不规则性,其邻接矩阵通常为稀疏矩阵.有3种主流格式常用以存储稀疏图邻接矩阵:坐标列表格式(coordinate list, COO)(COO 是最简单的一种存储稀疏矩阵的方式,它通过3个一一对应的数组记录矩阵中所有非零的元素,3个数组分别记录非零元素在矩阵中的行号、列号及节点特征.COO 的方式简单直观,但记录信息较多存在冗余)、压缩稀疏行格式(compressed sparse row, CSR)以及压缩稀 疏 列 格 式 (copressed sparse column, CSC)(CSR和 CSC格式进一步对矩阵的存储进行压缩.CSR格式同样通过3个数组对稀疏矩阵进行存储,但对行数组进行了压缩,具体方法是行数组中的每个元素依次记录稀疏矩阵中每行第1个非零元素在列数组中的偏移位置,因此也被称为偏移数组.列数组依次记录对应行的非零元素列号,也即单跳(1-hop)邻居(目标节点)的编号,该数组也被称为边数组,用以存储出边.最后通过属性数组记录节点的特征.CSC格式与 CSR 形式相似,不同的是进行列的压缩,其边数组用以存储入边)

现实世界中的图具有3个显著特征:
1)规模大.除边和节点规模外,用于表征现实图中节点和边属性的特征向量维度常常也数以千计,进一步扩大了图的规模.
2)幂律分布.少数节点会与大部分节点之间具有相连关系,而大多数节点仅与少量其他节点之间存在边相连.
3)动态多样性..现实场景中的图往往具有动态变化且邻居节点分布不规则的特征.另外,现实图的种类多变,在不同的应用场景中,根据不同节点之间是否有指向性要求,分为有向图或无向图;根据不同节点的类型是否相同,分为同质图和异质图;根据处理过程中图结构是否发生变化,分为动态图和静态图.
2.图神经网络模型
尽管传统的神经网络在人工智能领域取得了巨大成功,但它只能应用于欧几里得空间的分布规整且结构固定的数据.为使更多现实应用场景智能化,图神经网络应运而生.图神经网络同时受到传统图计算和神经网络的启发,扩宽和加深了神经网络的应用范围和学习能力.图神经网络利用图结构,对节点的属性与相连关系进行建模与学习,通过对输入的节点、边、特征属性等信息进行逐层的迭代处理,最终对指定节点的特征向量进行更新,实现分类、预测、推荐、识别等不同的执行目的.
现有的主流图神经网络算法可以统一抽象为模型:
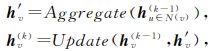
执行过程为:,图神经网络首先遍历整张图(或采样后的子图),对每个节点进行邻居信息的聚合(aggregate)获得该节点在本层的中间特征h′v,该过程与传统图计算相似;
其后对聚合了邻居信息的中间特征与节点在上一层得到的特征进行组合,更新(update)获得本层该节点的输出特征向量h(k)v ,该过程与传统神经网络相似.
另外,为了简化执行过程,图神经网络算法通常可以在图聚合阶段增加自环(self-loop)也就是将节点自身的特征与其邻居节点特征同时进行聚合,进而在图更新阶段不区分自身节点特征和由邻居节点聚合形成的中间特征的神经网络参数.该方法尽管会损失部分模型表达能力,但执行过程简单并可从一定程度上缓解图神经网络可能存在的过拟合(over-fitting)现象.
增加自环的图神经网络可抽象为模型:

与神经网络类似,为获得对知识进行学习和预测的能力,一个完整的图神经网络包含训练(train)和推断(inference)两个主要部分.
1)训练过程:图神经网络通常可以通过反向传播(back propagation)的过程对损失函数进行训练.其中损失函数用于衡量图神经网络中最终得到的节点预测值与其真实值的差距,训练的目的是通过不断降低损失函数梯度以期模型对数据的预测更为准确,该过程通常可以采用随机梯度下降或其变形方法实现.
2)推断过程:通过训练过程对知识进行学习并不断对网络模型进行调整后,图神经网络具备了一定的推断能力,此时可执行推断过程,针对不同需求,对新知识进行推断.此 过 程 主 要 包 含 图 聚 合 (aggregate)和 图 更 新(update)两大主要阶段.
典型图神经网络算法
分为卷积图神经网络(convolutional graph neural net works)、循环图神经网络(recurren graph neural networks)、图自编码器(graph autoencoders)和时空图神经网络(spatial-temporal graph neural networks)四大类.
图神经网络与传统应用的比较
1)与图计算应用的比较:① 数据类型.图神经网络与图计算均针对非欧几里得空间的不规则图结构数据进行处理.② 执行行为:图神经网络的图聚合阶段行为与传统图计算应用类似,均为通过逐跳(hop)遍历图中节点收集并聚合邻居信息.图神经网络相较图计算而言,具备较高的数据空间局部性.③ 学习能力.图计算应用不具备知识学习的能力,执行过程较为简单,通常应用于路径规划、页面排序、网络分析等场景.而图神经网络集成神经网络的行为,具备知识学习和推断的能力,适用场景更为广泛.
2)与神经网络应用的比较:① 数据类型.神经网络只能处理欧几里得空间的规整数据,而图神经网络面向的是现实生活中更广泛存在的非欧几里得空间的不规则且动态变化的图结构数据.② 执行行为.图神经网络的图更新阶段与传统神经网络应用相似.但传统神经网络中,依赖信息仅能以节点的属性形式存在,而图神经网络能够通过聚合过程,将图节点间的依赖关系在图中进行传播.③ 学习能力.④ 可解释性.
二、图神经网络编程模型与框架
主流的图神经网络框架与扩展库
1)PyG:是目前最常用的通用图神经网络扩展库,它基于PyTorch框架扩展而成,同时支持在 CPU 和 GPU 平台上运行,已开源.除了常见的图结构数 据 处 理 方 法 外,PyG还 提 供 对 关 系 学 习(relational learning)和3D数据处理等方法的支持.PyG 为 用 户 提 供 通 用 的 消 息 传 递 (message passing)接口.在此接口下,用户只需要分别定义 message 和 update函数以及选择节点聚合模式,即可完成一个图神经网络算法的构建,实现对节点进行邻居聚合以及对节点进行更新的操作.
2)DGL:DGL基于多种已有的神经网络框架扩展实现,目前已支持 Tensonflow,PyTorch和MXNet,并最小化用户跨平台迁移图神经网络模型时的工作量.DGL将图神经网络计算过程抽象为用户可配置的消息传递单元,并提取图神经网络中的稀疏矩阵乘与消息传递机制间的联系,将计算操作整合为泛化 的 稀 疏 稠 密 型 矩 阵 乘 (generalized sparse-dense matrix multiplication, g-SpMM)与泛化的采样稠密 稠密型矩阵乘(generalized sampled dense-dense matrix multiplication, g-SDDMM).另 外,DGL 还 引 入 了 不 同 类 别 的 并 行 策 略,通 过 对 g-SpMM 采用节点级并行,对g-SDDMM采用边级并行的方式,使其具备高执行速度和访存效率.
3)AliGraph:AliGraph 的 系 统 分 为 算 子 (operator)、采 样(sampling)和数据存储(storage)这3个层次.算子层将不同的图神经网络算法拆解为系统中的采样(sample)、聚合(aggregate)和组合(combine)三个算子,并进行优化计算;采样层集成多种不同的采样策略,使其能够快速准确地生成训练样本;数据存储层通过灵活的图划分、对图中不同属性进行分别存储以及缓存热点数据等策略来实现高效的数据组织和存储.
三、图神经网络加速的挑战
1)图聚合阶段:现实世界的图往往具有极高的稀疏性,其邻接矩阵的稀疏度高达99%.且图中节点之间的连接分布不规则,每个节点的邻居节点的数量和位置均不固定.上述行为和特性导致图神经网络的图聚合阶段存在大量的动态计算与不规则访存,受内存约束.
2)图更新阶段:因此图更新阶段具有静态的计算和规则的访存,受计算约束.

不规则访存使得传统通用处理器的数据预取机制失效
图神经网络的混合执行行为,导致通用平台均无法为图神经网络的执行提供专属且高效的算力.对于 CPU 平台来说,它们缺少计算资源,并且图聚合阶段的遍历不规则性会导致频繁的数据替换.对于 GPU 来说,其结构本质上是面向类似神经网络的具有规则执行行为且计算密集型的应用进行加速,缺少应对不规则性的能力.
神经网络加速结构不具备应对不规则访存和不规则计算的能力,无法高效执行图神经网络的图聚合阶段.另外,图计算加速结构和神经网络加速结构均只能针对图神经网络中的单一阶段进行加速,无法融合2个阶段的执行,不足以应对图神经网络应用的加速需求.
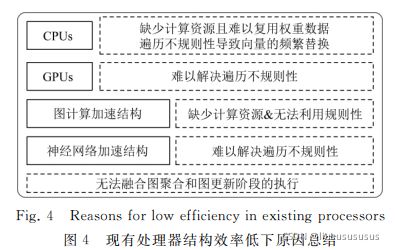
***挑战主要可以分为计算和访存2个方面:***.计算方面:图神经网络加速结构需要同时能够高效应对不规则和密集规则型算.由于图中节点具有极高的不规则性并服从幂律分布,图聚合阶对邻居节点的遍历会导致严重的负载不均衡,为图神经网络加速结构的设计带来更多挑战.另外,图神经网络的执行过程中还潜藏着不同级别的并行性待加速结构挖掘.
访存方面:图神经网络加速结构需要同时能够高效应对不规则和规则的粗粒度访存以及高带宽需求.同时如何充分地进行图数据复用也为图神经网络加速结构的设计提出更高要求.
四、图神经网络加速结构分类方案
1.支持算法方面
2.支持阶段方面
3.加速平台方面
现有工作通常采用 CPU-FPGA 的异构平台、ASIC平台或存内计算平台实现硬件加速结构搭建.
4.关键优化技术方面
现有工作的关键优化技术可以归纳为计算、片上访存和片外访存这3个层次.
① 图神经网络加速结构在计算层次主要的优化目标是充分挖掘并行性,常见的优化方向包括负载均衡、脉动阵列、减少冗余计算与降低计算复杂度等.
② 目前片上访存层次主要的优化目标是深入挖掘粗粒度访存数据的空间局部性和时间局部性,尽可能减少片上数据的频繁替换.主要的解决思路是采用大容量片上存储和对图数据进行数据重排.另外还有新兴方法通过优化模型压缩图神经网络的模型参数数据,降低对片上存储空间的需求.
③ 现有的解决片外访存层次挑战的主要思路是基于特定的图数据划分方法提高预取效率和数据重用率,利用稀疏性消除、动态访存调度、数据结构重组提高带宽利用率,通过操作融合减少访存带宽需求等.
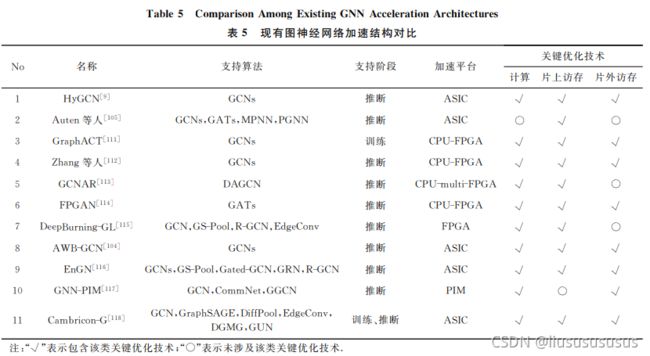
五、图神经网络加速结构整体分析
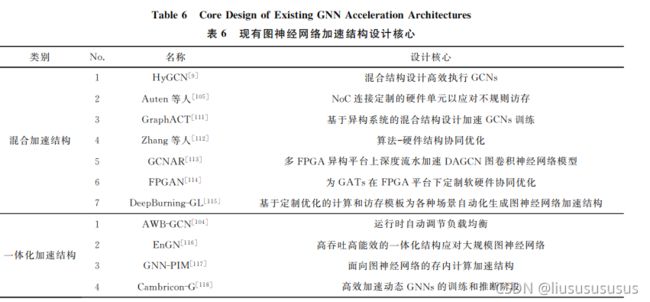
六、图神经网络关键优化技术
1.计算优化层次
从关键优化技术角度看,图神经网络芯片在计算层次主要的优化目标是充分挖掘并行性和提高计算部件的利用效率,常见的优化方向包括负载均衡、脉动阵列、减少冗余计算及降低计算复杂度等。
2.片上访存优化层次
图神经网络中节点的特征属性为高维数据,因此对节点属性的访问为粗粒度的不规则访问,这也是图神经网络与传统图计算执行过程的典型区别之一.不规则粗粒度访存导致的片上存储 Cache命中率低的问题,为图神经网络加速结构的设计在片上存储层次带来极大挑战.
解决这一挑战的主要思路分为2种::1)采用大容量的片上存储,并配合批量处理与数据分割等技术。2)对图数据进行数据重排.3)降低片上存储需求
3.片外访存优化层次
图神经网络加速结构设计在片外存储层次需要解决粗粒度不规则访存导致的片外访存效率和带宽利用率低下的问题.
目前主要的解决思路包括:基于特定的图数据划分方法提高预取效率和数据重用率;利用稀疏性消除、动态访存调度、数据结构重组提高带宽利用率;通过操作融合减少访存带宽需求.
1)图数据划分(为了提高片外带宽利用率,HyGCN借鉴文献中的Interval和 Shard的抽象概念来对图神经网络中的图数据进行划分)2)稀疏性消除(图神经网络的图数据具有很强的稀疏性,导致了很多无用的片外访存行为)3)动态访存调度4)数据结构重组(针对现实图数据的稀疏性问题,FPGAN提出一种数据结构重组的策略,在表示图结构的传统邻接列表基础上,对图数据进行向量化和对齐处理,从而实现更加高效的数据片外访存)5)操作融合(对于复杂的自注意力机制(self-attention mechanism),FPGAN通过操作融合(operation fusion)的方式剔除其中的存储同步过程,从而节省片外访存带宽)6)存内计算(为数据传输提供更高的带宽)
代码如下(示例):
七、总结与展望
由于图神经网络加速结构研究尚处于新兴初始研究阶段,其仍具备很大的发展优化空间: