作者:京东科技 李杰
联邦学习和GNN都是当前AI领域的研究热点。联邦学习的多个参与方可以在不泄露原始数据的情况下,安全合规地联合训练业务模型,目前已在诸多领域取得了较好的结果。GNN在应对非欧数据结构时通常有较好的表现,因为它不仅考虑节点本身的特征还考虑节点之间的链接关系及强度,在诸如:异常个体识别、链接预测、分子性质预测、地理拓扑图预测交通拥堵等领域均有不俗表现。
那么GNN与联邦学习的强强组合又会擦出怎样的火花?
通常一个好的GNN算法需要丰富的节点特征与完整的连接信息,但现实场景中数据孤岛问题比较突出,单个数据拥有方往往只有有限的数据、特征、边信息,但我们借助联邦学习技术就可以充分利用各方数据安全合规地训练有强劲表现的GNN模型。
读罢此文,您将获得如下知识点:
•GNN经典算法原理及计算模型
•联邦学习定义与分类
•联邦GNN的两种分类方法及细节
•基于横向联邦的FedGNN模型(微软亚研,2021)、基于纵向联邦的VFGNN模型(浙大+蚂蚁,2022)
一、GNN原理
1.1 图场景及数据表示
能用图刻画的场景很多,比如:社交网络、生物分子、电商网络、知识图谱等。
 []()
[]()
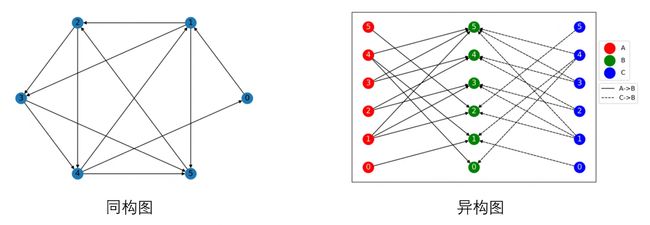
图最基础且通用的分类是将其分为:同构图(一种节点+一种边)与异构图(节点类型+边类型>2),相应的示意图如下。
 []()
[]()
一般来说,原始的图数据由两部分组成:节点数据(节点类型+节点ID+节点特征)、边数据(边类型+起点+终点)。原始数据经过解析处理后载入图存储模块,图存储的基本形式为邻接矩阵(COO),但一般出于存储与计算开销考虑采用稀疏存储表示(CSC/CSR)。
1.2 GNN任务分类
 []()
[]()
GNN任务一般分为如下四类:
•节点/边分类:异常用户识别。
•链接预测:user-item购物倾向、知识图谱补全。
•全图分类:生物分子性质预测。
•其他:图聚类、图生成。
1.3 GNN算法原理
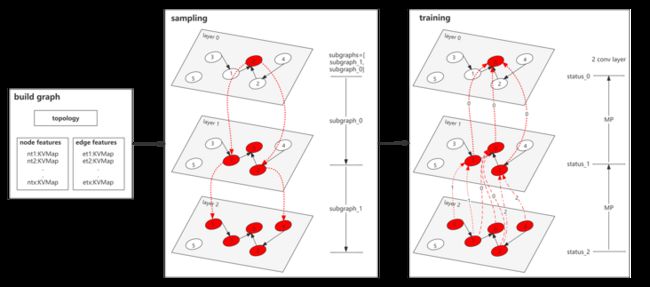
我们以GraphSAGE为例讲解GNN的计算原理[1],大致包含三个过程:采样、聚合、拟合目标。GraphSAGE示意图如下:
 []()
[]()
GraphSAGE算法的伪代码如下:
 []()
[]()
下面我们给合实例与公式详细说明其计算过程,下图先给出采样过程与消息传递过程的框架原理。
 []()
[]()
下图给出了具体的消息传递执行过程。
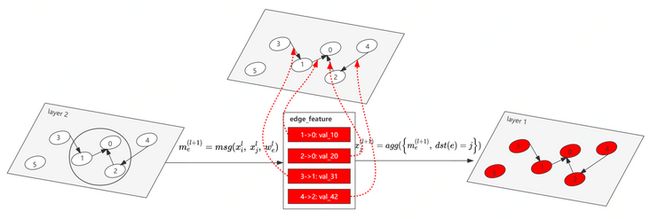 []()
[]()
二、联邦学习
之前机器学习模型训练的经典架构是:数据中心从各客户端或机构收集原始数据后,在数据中心对收集的全体数据进行模型训练。近年来随着数据隐私保护法规的颁布和数据安全意识的提升,机构间交换明文数据就不可行了。如何综合多个用户或机构间数据来训练模型?联邦学习技术应运而生。联邦学习一般分为如下两大类[2]:
•联邦学习(横向):两个机构拥有较多相同特征,但是重合样本ID很少。比如:北京医院和上海医院的病人数据。
•联邦学习(纵向):两个机构拥有较多相同样本ID,但是机构间重合特征较少。比如:北京银行和北京保险公司的客户数据。
2.1 横向联邦学习
 []()
[]()
如上图所示,左边红虚线框内是数据表示,即重合样本较少,但特征相同。右边是经典的横向FedAvg算法,每个客户端拥有同样的模型结构,初始权重由server下发至客户端,待各客户端更新本地模型后,再将梯度/权重发送至server进行聚合,最后将聚合结果下发给各客户端以更新本地模型。
2.2 纵向联邦学习
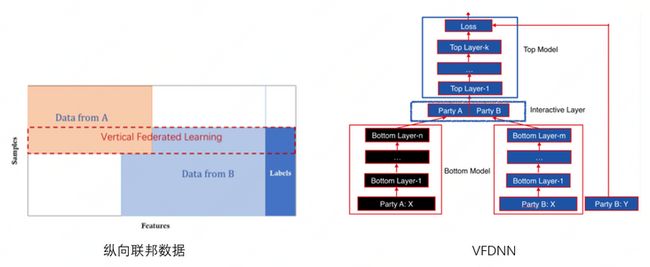 []()
[]()
如上图所示,左边红虚线框内代表数据表示,即两方拥有较多相同样本ID,但是重合特征较少。右边是经典的两方纵向DNN模型训练架构[3],其中A方bottom层结果要发送至B方,而B方拥有label,用来计算loss及梯度,详细过程参考[4]。
三、联邦GNN
3.1 联邦GNN分类
3.1.1 图对象+数据划分
根据图数据在客户端的分布规则,具体以图对象(图、子图、节点)与数据划分(横向、纵向)角度来看,可以将联邦GNN分为四类[5]:
1)inter-graph FL
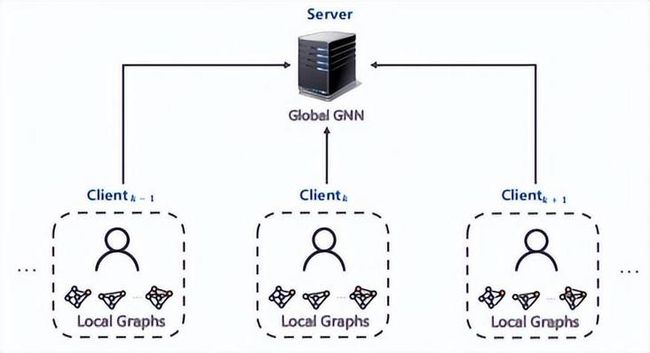 []()
[]()
在此分类中,客户端的每条样本是图数据,最终的全局模型处理图级别的任务。此架构广泛应用在生物工程领域,通常用图来表示分子结构,其中节点表示原子,边表示原子间的化学键。在药物特性研究方面可以应用此技术,每个制药厂k都维护了自己的分子-属性数据集
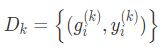 []()
[]()
,但都不想分享给竞争对手。借助inter-graph FL技术,多家药厂就可以合作研究药物性质。在此例中,全局模型为:
![]() []()
[]()
2)horizontal intra-graph FL
 []()
[]()
上图中全部客户端拥有的数据构成完整的图,其中虚线表示本应存在但实际不存在的边。此类架构中,每个客户端对应的子图拥有相同的特征空间和标签空间但拥有不同的ID。在此设置下,全局GNN模型一般处理节点类任务和边任务:
![]() []()
[]()
 []()
[]()
3)vertical intra-graph FL
 []()
[]()
此类架构中,客户端共享相同的ID空间,但不共享特征和标签空间。上图中的垂直虚线代表拥有相同ID的节点。在此架构中全局模型不唯一,这取决于多少客户端拥有标签,同时也意味着此架构可进行multi-task learning。此架构主要用来以隐私保护的方式聚合各客户端相同节点的特征,共享相同节点的标签。如果不考虑数据对齐和数据共享问题,则相应的目标函数定义为:
 []()
[]()
此架构一般应用在机构间合作,如反洗钱。犯罪分子采用跨多个机构的复杂策略进行洗钱活动,这时可应用此架构,通过机构间合作识别出洗钱行为。
4)graph-structured FL
 []()
[]()
此架构用来表示客户端之间的拓扑关系,一个客户端相当于图中一个节点。此架构会基于客户端拓扑聚合本地模型,全局模型可以处理联邦学习领域的各种任务和目标函数。全局GNN模型旨在通过客户端之间的拓扑关系挖掘背后的隐含信息。此架构的经典应用是联邦交通流量预测,城市中的监控设备分布在不同的地方,GNN用来描述设备间的空间依赖关系。以上图为例全局GNN模型的聚合逻辑如下:
![]() []()
[]()
本节总结
 []()
[]()
3.1.2 二维分类法
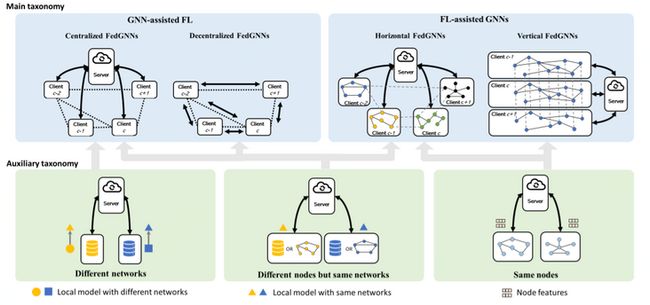
根据参考文献[6],我们可以从2个维度对FedGNNs进行分类。第一个维度为主维度,聚焦于联邦学习与GNN如何结合;第二个维度为辅助维度,聚焦于联邦学习的聚合逻辑,用来解决不同level的图数据异构性。其分类汇总图大致如下:
 []()
[]()
1)GNN-assisted FL
借助结构化的客户端来提升联邦学习训练效果,用虚线来表示客户端之间的网络拓扑关系。此架构一般分为两种形式:
•中心化架构:拥有客户端间的全局网络拓扑。可训练GNN模型提升联邦聚合效果,也可帮助客户端更新本地模型。
•非中心化架构:客户端间的全局网络拓扑必须提前给定,这样拥有子图的客户端就可以找到它在图中的邻居。
2)FL-assisted GNN
借助分散的图数据孤岛来提升GNN模型效果,具体通过联邦学习把图数据孤岛组织起来训练一个全局GNN模型。根据客户端是否有相同节点,此架构可分为如下两类:
•horizontal FedGNN:各客户端拥有的重叠节点不多,有可能会丢失跨客户端的链接,通常需要较复杂的处理方法。
•vertical FedGNN:各客户端拥有相同的节点集合,但持有的特征不相同。根据特征的分区方式不同,相应的处理方法也随之变化。
3)Auxiliary taxonomy
辅助分类聚焦于解决联邦学习客户端之间的异构性问题。具体可以分为三类:
•客户端拥有相同ID:可将节点特征或中间表征上传至联邦服务器进行联邦聚合。常用于vertical FedGNN和有部分重复节点的水平FedGNN。
•客户端拥有不同节点但相同网络结构:联邦聚合对象主要是模型权重和梯度。常用于GNN-assisted FL和无重复节点的horizontal FedGNN。
•客户端拥有不同网络结构:先把本地模型做成图,然后将GNN作用于图之上。联邦聚合对象是GNN权重和梯度,常用于centralized FedGNN。
3.2 FedGNN
3.2.1 问题定义
 []()
[]()
3.2.2 FedGNN原理与架构
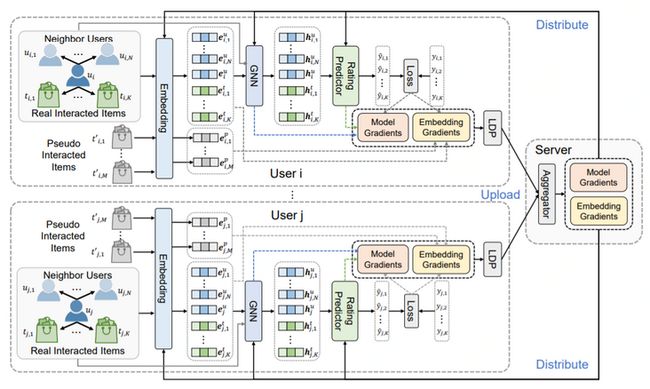 []()
[]()
如上图,FedGNN[7]由一个中心服务器和大量客户端组成。客户端基于其用户交互物品与邻居客户端在本地维护了一个子图。客户端基于本地子图学习user/item embedding,以及GNN模型,然后将梯度上传给中心服务器。中心服务器用来协调客户端,具体是在训练过程中聚合从多个客户端收集的梯度(基于FedAvg算法),并将聚合后的梯度回传给客户端。如下我们将依次介绍一些技术细节。
 []()
[]()
FedGNN的完整算法流程见下述Algorithm1,其中有两个隐私保护模块:其一是隐私保护模型更新(Algorithm1的9-11行),用来保护梯度信息;其二是隐私保护user-item图扩充模块(Algorithm1中第15行),用来对user和item的高阶交互进行建模。
 []()
[]()
3.2.3 隐私保护模型更新
embedding梯度和模型梯度(GNN+rating predictor)直接传输会泄露隐私,因此需要对此进行安全防护。因为每个客户端维护了全量item的embedding表,通过同态加密保护梯度就不太现实(大量的存储和通信开销),文献[7]提出两个机制来保护模型更新过程中的隐私保护。
1)伪交互物品采样
随机采样M个用户并未交互过的物品,根据交互物品embedding梯度分布随机生成伪交互物品embedding梯度。于是第i个用户的模型和embedding梯度修改为
![]() []()
[]()
2)采用LDP(本地差分隐私)护本地梯度
首先通过梯度的无穷范数和阈值 δ 对梯度进行截断,然后基于LDP思想采用0均值拉普拉斯噪声对前述梯度进行扰动,从而实现对用户隐私的保护。相应的公式表达为:
g i=clip(g i,δ)+Laplace(0,λ)。受保护的梯度再上传到中心服务器进行聚合。
3.2.4 隐私保护图扩充
客户端本地user-item图以隐私保护方式找到邻居客户端,以达到对本地图自身的扩充。在中心化存储的GNN场景中,user与item的高阶交互可通过全局user-item图方便获取。但非中心化场景中,在遵守隐私保护的前提下要想求得user-item高阶交互不是易事。文章提出通过寻找客户端的匿名邻居以提升user和item的表征学习,同时用户隐私不泄露,详细过程如下:
 []()
[]()
首先,中心服务器生成公钥并分发给各客户端。客户端收到公钥后,利用同态加密技术对交互物品ID进行加密处理。前述加密ID和用户embedding被上传至第三方服务器(不需要可信),通过PSI技术找到有相同交互物品的用户,然后为每个用户提供匿名邻居embedding。最后,我们把用户的邻居用户节点连接起来,这样就以隐私保护的方式添加了user-item的高阶交互信息,丰富了客户端的本地user-item子图。
3.3 VFGNN
3.3.1 数据假设
训练一个好的GNN模型通常需要丰富的节点特征和完整的连接信息。但是节点特征和连接信息通常由多个数据方拥有,也就是所谓的数据孤岛问题。下图我们给出图数据纵向划分的例子[8],其中三方各自拥有节点不同的特征,各方拥有不同类型的边。
 []()
[]()
3.3.2 算法架构及流程
安全性假设:数据拥有方A,B,C和服务器S都是半诚实的,并且假定服务器S和任一数据拥有方不会合谋。这个安全假设符合大多数已有工作,并且和现实场景比较契合。
 []()
[]()
上图即为VFGNN的架构图,它的计算分为两大部分:
•隐私数据相关计算:一般在数据拥有方本地进行。在GNN场景中,隐私数据有:节点特征、label、边信息。
•非隐私数据相关计算:一般将计算权委托给半诚实server,主要是出于计算效率的考虑。
考虑到数据隐私性的问题,上述计算图分为如下三个计算子图,且各自承担的工作如下:
•CG1:隐私特征和边相关计算。 先利用节点隐私特征生成initial node embedding,这个过程是多方协同工作的。接着通过采样找到节点的多跳邻居,再应用聚合函数生成local node embedding。
•CG2:非隐私数据相关计算。 出于效率考虑,作者把非隐私数据相关计算委托给半诚实服务器。此服务器把从各方收集的local node embedding通过不同的COMBINE策略处理生成global node embedding。接着可以进行若干明文类的操作,比如max-pooling、activation(这些计算在密文状态下不友好)。进行一系列明文处理后,我们得到最后一个隐层输出ZL,然后把它发送给拥有label的数据方计算预测值。
•CG3:隐私标签相关计算。 以节点分类任务为例 ,当收到ZL后可以快速计算出预测值,具体通过softmax函数进行处理。
3.3.3 重要组件
Generating Initial Node Embedding
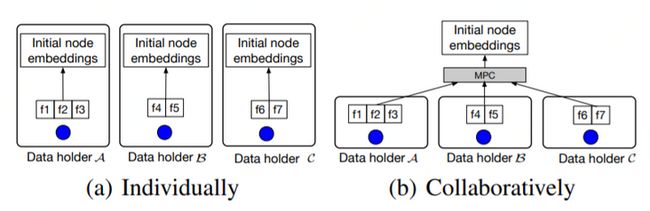 []()
[]()
如果各方独立生成initial node embedding(上图a),则遵循如下计算公式:
![]() []()
[]()
如果各方协同生成initial node emb,则可按上图b中应用MPC技术进行处理。
Generating Local Node Embedding
基于前述生成的initial node embedding,及节点的多跳邻居节点,应用聚合函数可以生成local node embedding。邻居节点的聚合操作必须在本地进行而不需要多方协同,目的是保护隐私的边信息。一个节点的邻居节点聚合操作和常规GNN一样,以GraphSAGE为例节点的聚合操作是通过采样和聚合特征形成了local node embedding,具体公式如下:
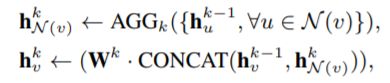 []()
[]()
GraphSAGE中,常用的聚合函数有:Mean、LSTM、Pooling。接着数据拥有方把local node embedding发送给半诚实服务器,以进行COMBINE操作及后续的非隐私数据计算逻辑。
Generating Global Node Embedding
对各方传来的local node embedding执行combine操作可以生成global node embedding。combine策略一般是可训练且高表达容量,文章给出了三种策略:
1)Concat
![]() []()
[]()
2)Mean
![]() []()
[]()
3)Regression
![]() []()
[]()
3.3.4 隐私保护DP
如果在前向过程中把local node embedding直接传给半诚实服务器,或在反向传播过程中直接传递梯度信息很可能造成信息泄露。本文提出了两种基于DP的方法用来保护信息发布过程,算法流程如下:
 []()
[]()
3.3.5 VFGNN前向算法
以GraphSAGE处理节点分类任务为例,VFGNN算法的前向过程描述如下:
 []()
[]()
3.4 其他算法及项目
最近四年出现的联邦GNN算法[9]:
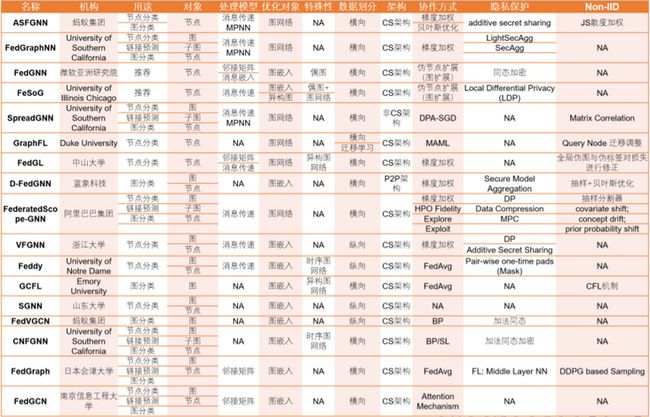 []()
[]()
开源项目有:FedGraphNN[10]。
参考资料
1.Hamilton W, Ying Z, Leskovec J. Inductive representation learning on large graphs[J]. Advances in neural information processing systems, 2017, 30.
2.Yang Q, Liu Y, Chen T, et al. Federated machine learning: Concept and applications[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2019, 10(2): 1-19.
4.Zhang Y, Zhu H. Additively homomorphical encryption based deep neural network for asymmetrically collaborative machine learning[J]. arXiv preprint arXiv:2007.06849, 2020.
5.Zhang H, Shen T, Wu F, et al. Federated graph learning--a position paper[J]. arXiv preprint arXiv:2105.11099, 2021.
6.Liu R, Yu H. Federated graph neural networks: Overview, techniques and challenges[J]. arXiv preprint arXiv:2202.07256, 2022.
7.Wu C, Wu F, Cao Y, et al. Fedgnn: Federated graph neural network for privacy-preserving recommendation[J]. arXiv preprint arXiv:2102.04925, 2021.
8.Chen C, Zhou J, Zheng L, et al. Vertically federated graph neural network for privacy-preserving node classification[J]. arXiv preprint arXiv:2005.11903, 2020.
9.《图联邦学习进展与应用》 史春奇