yolo 学习系列(五):K-means维度聚类
yolo 学习系列(五):K-means维度聚类
《深度学习:手把手教你做目标检测(YOLO、SSD)》视频教程
1. 维度聚类
1.1 聚类目的
在Ubuntu系统下运行voc_label.py生成训练集和测试集列表文件,在Windows下生成的会有编码错误
- 当使用自己的数据集进行 YOLO 训练时,首先要做的就是讲 anchors 更换为自己的宽高尺寸,默认的是 VOC/COCO 数据集中 20/80 类目标的宽高尺寸。
维度聚类就是利用训练集迭代找出该数据集的候选框宽高尺寸。 - 先放结果
*****************
n_anchors = 5
*****************
k-means result:
(9.503125000000356, 8.046875000000572)
k-means result:
(4.367264851484575, 6.158106435643181)
k-means result:
(7.935546874999882, 4.897786458333437)
k-means result:
(6.179457720588269, 7.807674632352704)
k-means result:
(3.7825989208630717, 3.5274280575536627)
*****************
n_anchors = 6
*****************
k-means result:
(6.195027372262894, 7.749087591240633)
k-means result:
(9.131578947368867, 9.546875000000345)
k-means result:
(4.324420103092257, 6.20972938144295)
k-means result:
(9.331640624999876, 5.898828124999875)
k-means result:
(3.7665307971012534, 3.5264945652170954)
k-means result:
(7.337187499999761, 4.57375000000048)
*****************
n_anchors = 9
*****************
k-means result:
(2.6570723684221056, 3.3848684210523685)
k-means result:
(3.6341911764701336, 5.45174632352828)
k-means result:
(5.790958737863881, 8.205703883494753)
k-means result:
(7.290719696969482, 4.354640151515531)
k-means result:
(5.568824404761428, 5.959821428571835)
k-means result:
(9.106445312500655, 9.826171875000409)
k-means result:
(9.356770833333087, 5.37803819444432)
k-means result:
(8.429036458334373, 7.22656250000046)
k-means result:
(4.455696202530808, 3.311313291139051)
1.2 源码
源码-Github
# coding=utf-8
# k-means ++ for YOLOv2 anchors
# 通过k-means ++ 算法获取YOLOv2需要的anchors的尺寸
import numpy as np
# 定义Box类,描述bounding box的坐标
class Box():
def __init__(self, x, y, w, h):
self.x = x
self.y = y
self.w = w
self.h = h
# 计算两个box在某个轴上的重叠部分
# x1是box1的中心在该轴上的坐标
# len1是box1在该轴上的长度
# x2是box2的中心在该轴上的坐标
# len2是box2在该轴上的长度
# 返回值是该轴上重叠的长度
def overlap(x1, len1, x2, len2):
len1_half = len1 / 2
len2_half = len2 / 2
left = max(x1 - len1_half, x2 - len2_half)
right = min(x1 + len1_half, x2 + len2_half)
return right - left
# 计算box a 和box b 的交集面积
# a和b都是Box类型实例
# 返回值area是box a 和box b 的交集面积
def box_intersection(a, b):
w = overlap(a.x, a.w, b.x, b.w)
h = overlap(a.y, a.h, b.y, b.h)
if w < 0 or h < 0:
return 0
area = w * h
return area
# 计算 box a 和 box b 的并集面积
# a和b都是Box类型实例
# 返回值u是box a 和box b 的并集面积
def box_union(a, b):
i = box_intersection(a, b)
u = a.w * a.h + b.w * b.h - i
return u
# 计算 box a 和 box b 的 iou
# a和b都是Box类型实例
# 返回值是box a 和box b 的iou
def box_iou(a, b):
return box_intersection(a, b) / box_union(a, b)
# 使用k-means ++ 初始化 centroids,减少随机初始化的centroids对最终结果的影响
# boxes是所有bounding boxes的Box对象列表
# n_anchors是k-means的k值
# 返回值centroids 是初始化的n_anchors个centroid
def init_centroids(boxes,n_anchors):
centroids = []
boxes_num = len(boxes)
centroid_index = np.random.choice(boxes_num, 1)
centroids.append(boxes[centroid_index])
print(centroids[0].w,centroids[0].h)
for centroid_index in range(0,n_anchors-1):
sum_distance = 0
distance_thresh = 0
distance_list = []
cur_sum = 0
for box in boxes:
min_distance = 1
for centroid_i, centroid in enumerate(centroids):
distance = (1 - box_iou(box, centroid))
if distance < min_distance:
min_distance = distance
sum_distance += min_distance
distance_list.append(min_distance)
distance_thresh = sum_distance*np.random.random()
for i in range(0,boxes_num):
cur_sum += distance_list[i]
if cur_sum > distance_thresh:
centroids.append(boxes[i])
print(boxes[i].w, boxes[i].h)
break
return centroids
# 进行 k-means 计算新的centroids
# boxes是所有bounding boxes的Box对象列表
# n_anchors是k-means的k值
# centroids是所有簇的中心
# 返回值new_centroids 是计算出的新簇中心
# 返回值groups是n_anchors个簇包含的boxes的列表
# 返回值loss是所有box距离所属的最近的centroid的距离的和
def do_kmeans(n_anchors, boxes, centroids):
loss = 0
groups = []
new_centroids = []
for i in range(n_anchors):
groups.append([])
new_centroids.append(Box(0, 0, 0, 0))
for box in boxes:
min_distance = 1
group_index = 0
for centroid_index, centroid in enumerate(centroids):
distance = (1 - box_iou(box, centroid))
if distance < min_distance:
min_distance = distance
group_index = centroid_index
groups[group_index].append(box)
loss += min_distance
new_centroids[group_index].w += box.w
new_centroids[group_index].h += box.h
for i in range(n_anchors):
new_centroids[i].w /= len(groups[i])
new_centroids[i].h /= len(groups[i])
return new_centroids, groups, loss
# 计算给定bounding boxes的n_anchors数量的centroids
# label_path是训练集列表文件地址
# n_anchors 是anchors的数量
# loss_convergence是允许的loss的最小变化值
# grid_size * grid_size 是栅格数量
# iterations_num是最大迭代次数
# plus = 1时启用k means ++ 初始化centroids
def compute_centroids(label_path,n_anchors,loss_convergence,grid_size,iterations_num,plus):
boxes = []
label_files = []
f = open(label_path)
for line in f:
label_path = line.rstrip().replace('images', 'labels')
label_path = label_path.replace('JPEGImages', 'labels')
label_path = label_path.replace('.jpg', '.txt')
label_path = label_path.replace('.JPEG', '.txt')
label_files.append(label_path)
f.close()
for label_file in label_files:
f = open(label_file)
for line in f:
temp = line.strip().split(" ")
if len(temp) > 1:
boxes.append(Box(0, 0, float(temp[3]), float(temp[4])))
if plus:
centroids = init_centroids(boxes, n_anchors)
else:
centroid_indices = np.random.choice(len(boxes), n_anchors)
centroids = []
for centroid_index in centroid_indices:
centroids.append(boxes[centroid_index])
# iterate k-means
centroids, groups, old_loss = do_kmeans(n_anchors, boxes, centroids)
iterations = 1
while (True):
centroids, groups, loss = do_kmeans(n_anchors, boxes, centroids)
iterations = iterations + 1
print("loss = %f" % loss)
if abs(old_loss - loss) < loss_convergence or iterations > iterations_num:
break
old_loss = loss
for centroid in centroids:
print(centroid.w * grid_size, centroid.h * grid_size)
# print result
for centroid in centroids:
print("k-means result:\n")
print(centroid.w * grid_size, centroid.h * grid_size)
label_path = "/home/chris/workspace/2007_train.txt"
n_anchors = 5
loss_convergence = 1e-6
grid_size = 13
iterations_num = 100
plus = 0
compute_centroids(label_path,n_anchors,loss_convergence,grid_size,iterations_num,plus)
1.3 运行结果
k-means result:
(8.979910714285644, 5.140624999999976)
k-means result:
(4.5747282608690005, 7.813858695652043)
k-means result:
(2.2546296296290005, 7.7939814814810005)
k-means result:
(11.235351562499998, 9.699218750000407)
k-means result:
(2.442095588236353, 3.5698529411762943)
1.4 参考资源
YOLOv2通过k-means来获取anchor boxes
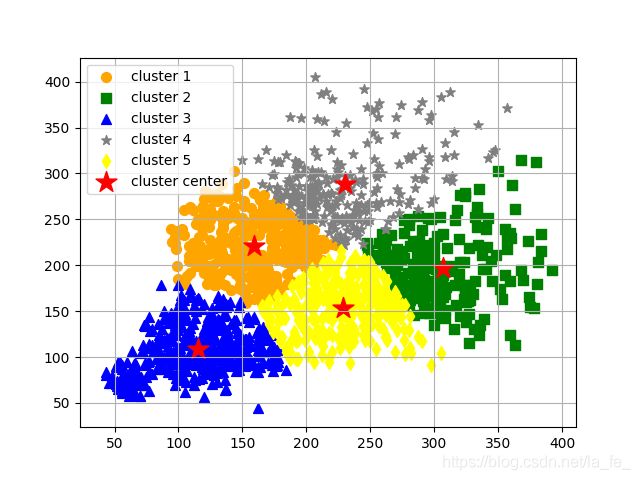
2.Caffe-SSD长宽比聚类
k-means 计算voc2012数据集的检测anchors的长宽聚类结果
本文用到了两个程序,一个是 get_w_h.py 用于获取数据集目标的宽和高(原因是参考程序该部分功能有问题),第二个是参考链接里的聚类绘图程序。
通过 get_w_h.py 分别获取目标的宽和高,并通过 excel 制作成第一列为宽,第二列为高的 data1.txt 文件,并将其与 K-means.py 文件存放在同一目录下,运行该 py 文件即可。
# 第67行
# print(ob_w)
print(ob_h)