数据挖掘流程-HCIE-BigData
机器学习流程
- 机器学习流程
-
- 1. 了解需求,确认目标
- 2. 获取数据
- 3. 审阅数据
- 4. 数据分析
-
- 4.1 统计分析
- 4.2 相关性分析
- 4.3 图形分析
-
- 1. 散点图
- 2. 热力图
- 3. 直方图
- 4. 统计图
- 5. 柱状图
- 6. 饼图
- 7. 综合绘图
- 5. 数据处理
-
- 5.1. 数据类型处理
- 5.2. 缺失值分析
- 5.3. 缺失值处理
- 5.4. 异常值检测
- 5.5. 异常值处理
- 6. 特征编码
-
- 6.1. 独热编码
- 6.2. 类别编码
- 7. 特征构造与变换
-
- 7.1 特征构造
- 7.2 删除多余数据
- 8. 数值离散化
- 9. 特征选择
-
- 9.1. 过滤法Filter
- 9.2. 嵌入法Embedding
- 9.3. 包装法Wrapper
- 10. 降维
-
- 10.1 PCA
- 10.2 LDA
- 11. 数据训练及预测
-
- 1. 划分数据集
- 2. 特征缩放
- 3. 算法训练
- 4. 算法预测
- 12. 模型评估
-
- 12.1 分类
- 12.2 回归
- 12.3 聚类
- 13. 模型优化
-
- 13.1 网格搜索/随机搜索
- 13.2 交叉验证
- 14. 模型保存于加载
机器学习流程
1. 了解需求,确认目标
说一下几点思考方法:
- 做什么?目的是什么?目标是什么?
- 为什么要做?有什么价值和意义?
- 如何去做?完整解决方案是什么?
2. 获取数据
- pandas读取数据
pd.read.csv(),pd.read_excel() - open读取数据
with open("ONE.TXT",mode="r+",encoding="utf-8") as f:
data = f.read()
3. 审阅数据
包括但不限于:数据大小、维度、类型、含义、排序、索引等
1. data.info()
2. data.head()
3. data.loc[]
4. data.shape
5. data.dtype
6. data.sort_values(by=["A"],ascending=False)
7. data.reset_index(drop=True,inplace=True)
8. data["F"].values
9. data["F"].value_counts()
4. 数据分析
统计分析、相关性分析、图形分析(散点图、直方图、计数图、柱状图、热力图)等
4.1 统计分析
- 数字统计分析:
data.describe() - 非数字变量分析:
data.describe(include="O")
4.2 相关性分析
data.corr() #method = 'pearson', 'spearman', 'kendall'
4.3 图形分析
1. 散点图
seaborn.scatterplot(x=None, y=None, hue=None, style=None, size=None,
data=None)
2. 热力图
mask = np.zeros_like(data.corr())
mask[np.tril_indices_from(mask)]=True
seaborn.heatmap(data.corr(),mask=mask,annot=True,fmt=".2f")

3. 直方图
seaborn.distplot(x=data["A"])
4. 统计图
seaborn.countplot(X="G",data=data)

5. 柱状图
x是名称,y是数量
plt.bar(x,y)
6. 饼图
plt.pie(data["A"])
7. 综合绘图
绘制成一张图
import seaborn
import matplotlib.pyplot as plt
plt.style.use("seaborn-whitegrid")
fig = plt.figure(figsize=(20,10))
fig.subplots_adjust(wspace=0.5,hspace=0.5)
for i,column in enumerate (data.columns):
ax = fig.add_subplot(3,5,i+1)
ax.set_title(column)
if data.dtypes[column] == np.object:
g = seaborn.countplot(y=column,data=data)
plt.xticks(rotation=25)
else:
g = seaborn.distplot(data[column])
plt.xticks(rotation=25)
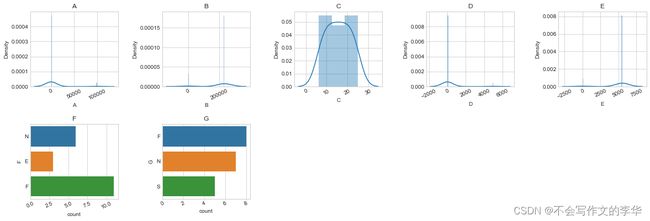
更多绘图请看Seaborn常见绘图总结
5. 数据处理
5.1. 数据类型处理
data.replace("XXX",np.NaN,inplace=True)
data.loc[data["G"]=="F","G"] = "K"
5.2. 缺失值分析
使用pandas模块
data.isnull().any() #查看那些列存在缺失
data.isnull().sum() #统计缺失值数量
data[data.isnull().values==True] #筛选出所有的缺失值
data.isnull().sum()/data.shape[0] #计算缺失值比例
(data.isnull().sum()/data.shape[0]).plot.bar() #缺失值比例柱状图
使用missingno
#安装
pip install missingno
missingno.matrix(df1, labels=True) # 无效数据密度显示
missingno.bar(df1) # 条形图显示
missingno.heatmap(df1) # 热图相关性显示
5.3. 缺失值处理
使用pandas模块
- 删除缺失值
data.dropna(axis=0,subset=["A"])
- 填充缺失值
data["A"].fillna(data["A"].mean())
# mean、median、mode().iloc[0]
使用sklearn.impute.SimpleImputer模块
simple = SimpleImputer(missing_values=nan, strategy=’mean’, fill_value=None)
# strategy = mean、median、most_frequent、constant
simple.fit_transform(data)
5.4. 异常值检测
- 3σ原理:数据服从正态分布,采用3σ原则
seaborn.kdeplot(data["A"]) #绘制核密度图查看数据分布
def xigema(X):
lower = X.mean() - 3 * X.std()
upper = X.mean() + 3 * X.std()
X = (X < lower) | (X > upper)
return X
#查看那些列存在缺失
data[xigema(data)==True].any()
#查看所有缺失的数据
data[data[xigema(data)==True].any(1)]
- 四分位原理:数据不服从正太分布,采用箱线图检验
seaborn.boxplot(data["A"]) #绘制箱线图查看数据分布
def box(X,IQR):
lower = X.quantile(0.25) - IQR * (X.quantile(0.75) - X.quantile(0.25))
upper = X.quantile(0.75) + IQR * (X.quantile(0.75) - X.quantile(0.25))
X = (X < lower) | (X > upper)
return X
#查看那些列存在缺失
data[box(data,1.5)==True].any()
#查看所有缺失的数据
data[box(data,1.5)==True].any(1)]
5.5. 异常值处理
- 置空
# 异常值会被NaN代替,然后当作缺失值处理
data[xigema(data)==False]
- 填充
# 使用mask判断
data.mask(xigema(data),np.NaN)
6. 特征编码
6.1. 独热编码
pd.get_dummies(data,columns=["F","G"])
#使用sklearn
sklearn.preprocessing.OneHotEncoder(sparse=False).fit_transform(data["F"].values.reshape(-1,1))
6.2. 类别编码
# 全量替换(包括数值),注意记得只编码非数值有序变量
labelencoder = LabelEncoder()
data[["G","F"]].apply(labelencoder.fit_transform)
7. 特征构造与变换
7.1 特征构造
加、减、乘、除、取对数、构造多项式等
data["K"] = data["A"] + data["B"]
data["M"] = np.log10(data["A"])
7.2 删除多余数据
data.drop(index=data[data['G']==0].index) #默认删除包含0的行,axis=1,删除列
del data["K"]
8. 数值离散化
在不改变数据相对大小的情况下,只关心元素之间的大小关系
from sklearn.preprocessing import KBinsDiscretizer
# strategy=quantile-等频,uniform-等宽,kmeans-聚类
kbins = KBinsDiscretizer(n_bins=10, encode="ordinal", strategy="quantile")
pd.DataFrame(kbins.fit_transform(data),columns=data.columns)
9. 特征选择
9.1. 过滤法Filter
- 方差过滤
from sklearn.feature_selection import VarianceThreshold,chi2,mutual_info_classif
X_var=VarianceThreshold(threshold=0.5).fit_transform(X, y) #使用阈值0.5 进行选择
- 相关性过滤
X_chi2 = SelectKBest(chi2, k=2).fit_transform(X, y)
- 互信息过滤
X_mut = SelectKBest(mutual_info_classif, k=2).fit_transform(X, y)
9.2. 嵌入法Embedding
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier as RFC
RFC_ = RFC(n_estimators =10,random_state=0) #先随机森林的实例化
X_embedded = SelectFromModel(RFC_,threshold=0.005).fit_transform(X,y) #在这里我只想取出来有限的特征。
X_embedded.shape #(42000,47)#模型的维度明显被降低了
#通过学习曲线来找最佳阈值
import numpy as np
import matplotlib.pyplot as plt
threshold = np.linspace(0,(RFC_.fit(X,y).feature_importances_).max(),20)
#0到feature_importances_最大值平均取20个
score = []
for i in threshold:
X_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(X,y)
once = cross_val_score(RFC_,X_embedded,y,cv=5).mean()
score.append(once)
plt.plot(threshold,score)
plt.show()
9.3. 包装法Wrapper
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
x_rfe = RFE(estimator=LogisticRegression(), n_features_to_select=3).fit(X, y)
print(x_rfe.n_features_ ) # 所选特征的数量
print(x_rfe.support_ ) # 按特征对应位置展示所选特征,True 表示保留,False 表示剔除。
print(x_rfe.ranking_ ) # 特征排名,使得 ranking_[i]对应于第 i 个特征的排名位置,1 表示最优特征。
x_rfe.transform(X)
10. 降维
10.1 PCA
降维训练前需要对数据标准化
from sklearn.decomposition import PCA
from sklearn import preprocessing # 调用预处理模块
X_std = preprocessing.scale(X)# 降维训练前需要对数据标准化
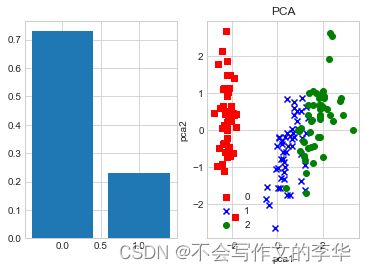
pca = PCA(n_components=2).fit(X_std) # 保留 2 个主成分
X_pca =pca.transform(X_std)
print(pca.explained_variance_ratio_) # 查看利用 PCA 方法降维后保留的 2 个维度的信息量大小
plt.subplot(1,2,1)
plt.bar(range(0, pca.explained_variance_ratio_.size), pca.explained_variance_ratio_)
#绘制 LDA 降维后不同簇与 y 的散点图
colors = ['r', 'b', 'g']
markers = ['s', 'x', 'o']
plt.subplot(1,2,2)
for l, c, m in zip(np.unique(y), colors, markers):
plt.scatter(X_pca[y==l, 0], X_pca[y==l,1], c=c, label=l, marker=m) # 散点图
plt.xlabel('pca1')
plt.ylabel('pca2')
plt.title("PCA")
plt.legend(loc='lower left')
plt.show()
10.2 LDA
一般在有标签的分类问题上,对数据降维,建议优先考虑有监督的 LDA 降维方法,结果一般会更加准确。
#此处与 PCA 方法不同,不必对原始数据进行标准化就能有较好的降维效果
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
lda = LDA(n_components=2).fit(X,y)
print(lda.explained_variance_ratio_) # 查看利用 LDA 方法降维后保留的 2 个维度的信息量大小
plt.subplot(1,2,1)
plt.bar(range(0, lda.explained_variance_ratio_.size), lda.explained_variance_ratio_)
X_lda =lda.transform(X)
#绘制 LDA 降维后不同簇与 y 的散点图,通过两种降维后的散点图对比不同方法的效果。
colors = ['r', 'b', 'g']
markers = ['s', 'x', 'o']
plt.subplot(1,2,2)
for c,l,m in zip(colors, np.unique(y), markers):
plt.scatter(X_lda[y == l, 0], X_lda[y == l, 1], c=c, label=l, marker=m)
plt.xlabel('lda1')
plt.ylabel('lda2')
plt.title("LDA")
plt.legend(loc='lower left')
plt.show()

11. 数据训练及预测
1. 划分数据集
from sklearn.model_selection import train_test_split
# 30%数据用于测试,70%用于训练,42是随机种子
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3,random_state=420)
2. 特征缩放
- 标准化
那些算法需要标准化:PCA、聚类算法、神经网络、逻辑回归、SVM等。
from sklearn.preprocessing import StandardScaler,MinMaxScaler
scaler = StandardScaler().fit(Xtrain)
X_train_std = scaler.transform(Xtrain)
X_test_std = scaler.transform(Xtest)
- MinMaxScaler
最小-最大规范化对原始数据进行线性变换,变换到[0,1]区间
from sklearn.preprocessing import MinMaxScaler
minmax = MinMaxScaler().fit(Xtrain)
X_train_std = minmax.transform(Xtrain)
X_test_std = minmax.transform(Xtest)
3. 算法训练
rfc = RandomForestClassifier(random_state=42) #建立模型: 随机森林
rfc = rfc.fit(Xtrain, Ytrain) # 训练模型: 随即森林
print(rfc.feature_importances_) #特征重要性
4. 算法预测
rfc.predict(Xtest)
12. 模型评估
12.1 分类
| 类 | 含义 |
|---|---|
sklearn.metrics.confusion_matrix |
混淆矩阵 |
sklearn.metrics.accuracy_score |
准确率accuracy |
sklearn.metrics.precision_score |
精确度precision |
sklearn.metrics.recall_score |
召回率recall |
sklearn.metrics.precision_recall_curve |
精确度-召回率平衡曲线 |
sklearn.metrics.f1_score |
F1-Score |
sklearn.metrics.roc_auc_score |
ROC |
sklearn.metrics.plot_roc_curve |
ROC绘图 |
sklearn.metrics.plot_precision_recall_curve |
P-R曲线绘图 |
sklearn.metrics.plot_confusion_matrix |
混淆举证绘图 |
from sklearn.metrics import accuracy_score, precision_score, f1_score, roc_auc_score, recall_score
recall_score(y_true, y_pred, average='micro')
绘图
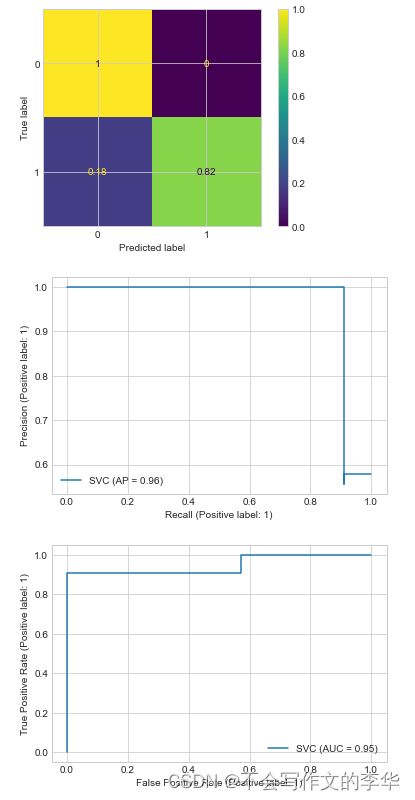
from sklearn.metrics import plot_confusion_matrix,plot_precision_recall_curve,plot_roc_curve
from sklearn.svm import SVC
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
clf = SVC(random_state=42)
clf.fit(X_train, y_train)
#混淆举证
plot_confusion_matrix(clf, X_test, y_test,normalize='true')
#P-R曲线
plot_precision_recall_curve(clf, X_test, y_test)
#ROC曲线
plot_roc_curve(clf, X_test, y_test)
12.2 回归
12.3 聚类
13. 模型优化
13.1 网格搜索/随机搜索
from sklearn.model_selection import GridSearchCV,RandomizedSearchCV
param_grid = {'n_estimators' : np.arange(100,200,10),
'max_depth' : np.arange(1, 20, 1),
'max_features' : np.arange(5,30,1),
'criterion' : ['gini', 'entropy']
}
rfc = RandomForestClassifier(random_state=42)
GS = GridSearchCV(rfc,param_grid,cv=10,scoring='roc_auc')
GS.fit(X,y)
print(GS.best_params_) # 最优参数
print(GS.best_score_) # 最优得分
print(GS.best_estimator_) # 最有分类器
13.2 交叉验证
from sklearn.model_selection import cross_val_score
cross_val_score(rfc, X, y, cv=5,scoring='roc_auc')
14. 模型保存于加载
from sklearn import svm
from sklearn import datasets
import joblib
# sklearn.externals.joblib函数是用在0.21及以前的版本中,在最新的版本中,该函数应被弃用改为直接导入joblib
# from sklearn.externals import joblib
clf = svm.SVC()
clf.fit(X,y)
# 保存训练好的clf模型
joblib.dump(clf,'clf.pkl')
# 重新加载训练好的clf模型
clf = joblib.load('clf.pkl')
# 打印预测值
print(clf.predict(X[0:1000]))