python数据分析项目实战波士顿房价预测——手写梯度下降法
导入所需要的库
import numpy as np
import pandas as pd
from matplotlib import font_manager as fm, rcParams
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split # 用于分割数据集
将sklearn中的data数据转换成csv
import pandas as pd
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['MEDV'] = boston['target']
df.to_csv('./boston.csv', index=None) # 存储为csv文件
读取csv文件
data = pd.read_csv(r'./boston.csv')
梯度缩放
提高梯度下降的收敛速度,使得data处于[0, 1]之间
data = (data - data.mean()) / data.std() # 特征放缩 (x-平均值)/标准差
公式如下:
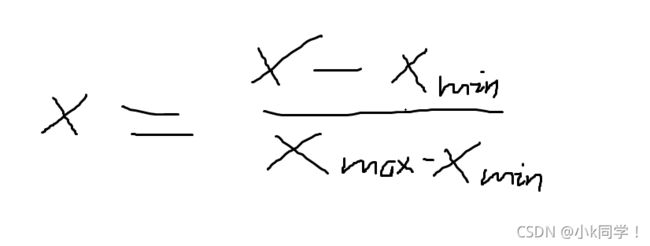
将X和y从数据集中分离出来
cols = data.shape[1] # 表示data的列数
X = data.iloc[:,0:cols-1]
y = data.iloc[:,cols-1:cols]
数据集的分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
梯度下降
将数据转换成矩阵
# 将数据转换成numpy矩阵
X_train = np.matrix(X_train.values)
y_train = np.matrix(y_train.values)
X_test = np.matrix(X_test.values)
y_test = np.matrix(y_test.values)
初始化θ矩阵
theta = np.matrix([0,0,0,0,0,0,0,0,0,0,0,0,0,0])
添加偏置列
# 添加偏置列,值为1,axis=1 添加列
X_train = np.insert(X_train,0,1,axis=1)
X_test = np.insert(X_test,0,1,axis=1)
构建代价函数
# 代价函数
def CostFunction(X, y, theta):
inner = np.power(X*theta.T-y,2)
return np.sum(inner)/(2*len(X))
公式如下:
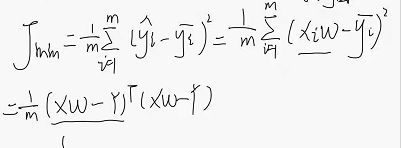
构建正则化代价函数
# 正则化代价函数
def regularizedcost(X, y, theta, l):
reg = (l/(2*len(X))) * (np.power(theta, 2).sum())
return CostFunction(X,y,theta) + reg
公式如下:
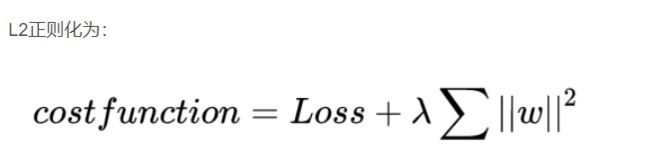
设置相关函数
alpha = 0.01 # 设置学习率
epoch = 1000 # 设置迭代步数
l = 50 # 正则化参数
构建梯度下降函数
# 梯度下降
def GradientDescent(X, y, theta, l, alpha, epoch):
temp = np.matrix(np.zeros(np.shape(theta))) # 定义临时矩阵存储theta
parameters = int(theta.flatten().shape[1]) # 参数θ的数量
cost = np.zeros(epoch) # 初始化一个ndarray,包含每次epoch的cost
m = X.shape[0] # 样本数量m
for i in range(epoch):
# 利用向量化一步求解
temp = theta - (alpha / m) * (X * theta.T - y).T * X - (alpha * l / m) * theta
theta = temp
cost[i] = regularizedcost(X, y, theta, l) # 记录每次迭代后的代价函数值
return theta, cost
θ的更新函数:

预测模型
# 运行梯度下降算法,并得出最终拟合的theta值 代价函数J(θ)
final_theta, cost = GradientDescent(X_train, y_train, theta, l, alpha, epoch)
print(final_theta)
模型评估
y_hat_train = X_train * final_theta.T
y_hat_test = X_test * final_theta.T
mse = np.sum(np.power(y_hat_test - y_test, 2)) / len(X_test)
rmse = np.sqrt(mse)
R2_train = 1 - np.sum(np.power(y_hat_train - y_train,2)) / np.sum(np.power(np.mean(y_train) - y_train,2))
R2_test = 1 - np.sum(np.power(y_hat_test - y_test,2)) / np.sum(np.power(np.mean(y_test) - y_test,2))
print('MSE = ',mse)
print('RMSE = ',rmse)
print('R2_train = ',R2_train)
print('R2_test = ',R2_test)
Result:

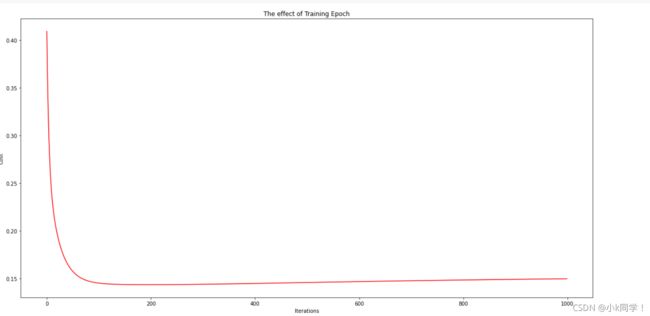
绘制图形观察梯度下降的情况
fig, ax = plt.subplots(figsize=(20,10))
ax.plot(np.arange(epoch), cost, 'r') # np.arange()返回等差数组
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('The effect of Training Epoch')
plt.show()
Result:
希望这篇文章对大家的学习有所帮助!