A Spatio-temporal Transformer for 3D Human Motion Prediction
A Spatio-temporal Transformer for 3D Human Motion Prediction
Author: Emre Aksan、Peng Cao
Chinese Title: 《用于3D人体运动预测的时空Transformer》
Classification: Motion Prediction
Progress: Finished
Publication: ArXiv 2020
Reading Date: October 15, 2021
Intro:
短范围预测已经取得了很多进步,但是长范围预测仍然非常具有挑战性。
目前的大多数工作通常存在奔溃成静态姿势的情况,这表明缺乏捕捉长期依赖性的能力。
常用的方法随着时间积累,误差不断增大,最终导致奔溃变成一个非正常姿态,可能是因为数据与模型之间的分布差异导致的。
本文提出包含两个块的时空transformer,空间注意力块从当前时刻戳的关节特征中提取信息。时间注意力块侧重从单个关节的先前记录中提取信息。对序列的双重自我关注允许模型直接访问过去信息,从而明确地捕捉依赖关系。

Contributions:
- 有能力生成真实的长范围预测结果(可达到20s)且打败了短范围预测的SoTA记录
Related Works:
非循环模型: 通过用密集层的滑动窗口在运动序列上。Li 等人在seq2seq框架中使用卷积代替RNN来提升长期依赖性。后来提出的GCN是对姿态的时序猖狂进行操作,并一次性产生整个输出。本文的模型完全是最回归,因此很容易部署来生成任意长的序列。
循环模型: RNNs之前主宰了3D动作的建模任务。ERD则采用了LSTM控制门在隐空间。后来也有了在解码器的输出输出上应用seq2seq和跳跃连接来解决种子和预测之间的过渡问题,同时也提出用预测值来训练模型以缓解暴露偏差的问题。
Methods:
大致方法流程为:将骨架分解成关节点,把所有关节投影到更高维空间,自注意力块识别关节间和关节内的关系,最后把预测出的关节组装回骨架。
- Spatial-temporal Transformer

**关节点映射:**通过一个线性层把所有节点映射到n维空间,再通过正弦位置编码对节点映射进行编码。
**Temporal Attention:**根据同一节点的历史信息来更新特征信息,通过多头注意力进行计算,其中在缩放点乘的结果后需要加入一个M掩码来防止信息泄漏到后面,最后每个头经过softmax以及多头加权后投影回表示空间。
A t t e n t i o n ( Q , K , V , M ) = s o f t m a x ( Q K T D + M ) V = A V Attention(Q,K,V,M)=softmax(\frac{QK^T}{\sqrt{D}}+M)V = AV Attention(Q,K,V,M)=softmax(DQKT+M)V=AV
**Spatial Attention:**引入空间注意力来学习动态和关节点之间的依赖性。
**Aggregation:**两个Transformer块是平行计算的,最后结果进行加和喂入前馈网络,再跟一个Dropout和LN。把这部分堆了L层用于联系更新和修正预测。
**Joint Predictions:**最后把经过L个注意力层的D维映射投影回M维关节角表示空间。
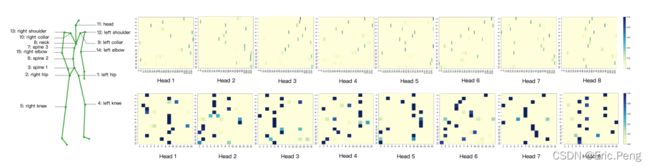
Results:
Datasets: AMASS
-
Quantitative Evaluation
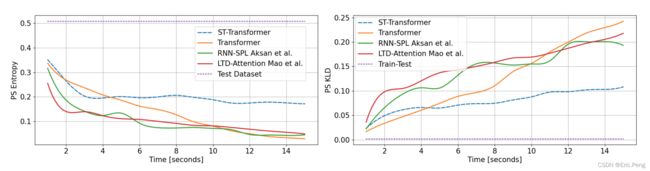

短期预测的结果效果基本还是很不错的,尤其在Euler指标下的改进最大。
长期预测采用了新的评估方法:PS度量,用来衡量预测分布和测试分布之间的差异性以及功率谱的熵, 结果显示也是很不错的。
-
Qualitive Evaluation
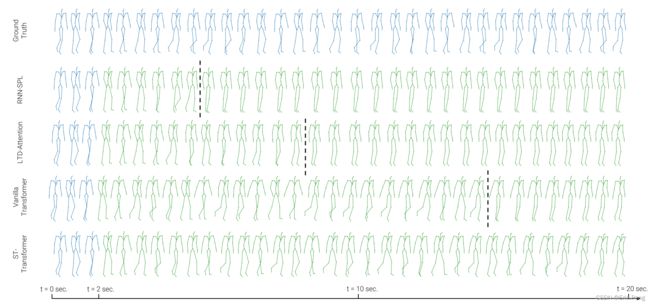
在长周期运动上表现良好,可以预测18s的序列,而在非周期运动会局限在几秒内。
Conclusion:
- 提出一个st-tansformer网络用于3D人体运动的生成式建模任务。
- 提出一个创新框架可以学习节点内和节点间的依赖性通过其解耦的时空注意力块。
- 结果表明了自注意力概念对于长短期预测都是非常有效的
- 同样也表明了注意力机制可以用于获取模型的行为。
- 最后消融实验正面其模型可以用于长序列的数据集,例如AMASS。