论文——Gao_Making Pre-trained Language Models Better Few-shot Learners
论文核心
围绕few-shot学习中的提示学习,提出自动化生成label和模板的方式,并比较了手动构建模板和自动化构建模板的优劣。当然,不同的 pretrain language model带来的影响也是不同的
论文背景
还是基于提示学习的小样本学习,在缩小范围,就是语言模型,怎么充分挖掘语言模型的潜力》
背景(1):GPT3模型
。
GPT3学习的范式是:GPT-3 朴素的“上下文学习”范式选取多达 32 个随机采样的示例,并将它们与输入连接起来。这种方法不能保证对信息量最大的演示进行优先排序,并且将来自不同类的随机示例混合在一起会产生难以学习的长上下文。并且,由于文本输入的最大长度的限制,这种方式会对长文本进行截断。(此外,可用演示的数量受模型的最大输入长度限制)
总之,感觉GPT3更适合讲故事。
它的结构是—encoder-decoder的模式。训练目标是给定一个词后,预测下一个词出现的概率
可参考文章:动画做的不错。
背景(2):T5模型
T5比较适合于填空、上下文等等多种任务。
文中使用的是T5模型。---------主要是用它的填空能力。
论文贡献
(1)发现提示学习下的微调的效果比常规范式下微调的效果好(我觉得是废话)
(2)自动化构建模板的方式相匹配或者优于手工构建的方式
(3)融入展示对提示学习是有效的,所以,对于每个输入,我们一次从每个类中随机抽取一个示例,以创建多个最小的演示集。还设计了一种新颖的采样策略,将input 与类似的示例配对,从而为模型提供更具区分性的比较。
补充,什么是展示?(如下),对于情感分类任务,我们为其添加了正例和负例,作为展示例子。
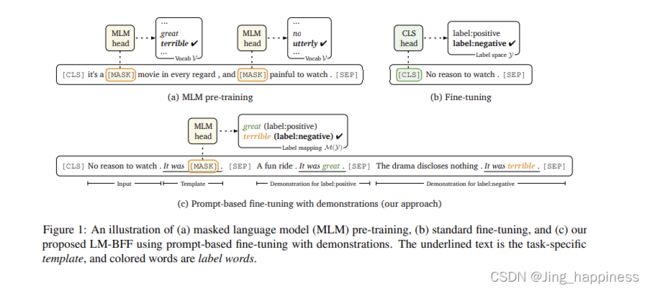
研究背景——小样本学习(学习人家的表述方式)
比较宽泛的,小样本学习,文中总结了三类:(1)半监督学习(Miyato et al., 2017; Xie et al., 2020; Chen et al., 2020),其中给出了一组未标记的示例; (2) 元学习(Yu et al., 2018; Han et al., 2018; Bansal et al., 2020a,b; Bao et al., 2020),其中给出了一组辅助任务; (3) 在中间训练中 (Phang et al., 2018; Yin et al., 2020),其中给出了相关的中间任务。但现在,是不是还有一类,就是基于提示学习的小样本学习。
文中最后,这句表示,简直绝了《We deviate from these settings by making minimal assumptions about available resources: we only assume a few annotated examples and a pre-trained language model. Our focus is on understanding how far we can push without any other advantages.》点到提示学习下的精髓。
补充(元学习——基于原型的方法):
原型网络的基本思路是对于每一个分类来创建一个原型表示(protoypicla representation)。并且对于一个需要分类的查询,采用计算分类的原型向量和查询点的距离来进行确定。
例子:https://blog.csdn.net/hei653779919/article/details/106595614
实验过程
任务形式:
这篇文章一共围绕14个任务展开的研究,8个单句和7个句对英语任务,包括GLUE基准(Wang等人,2019)、SNLI(Bowman等人,2015)和其他6个流行的句子分类任务(SST-5、MR、CR、MPQA、Subj、TREC)。
具体细分,可以分为单个句子和句子对的任务。单个句子如情感分析,句子对如判断两个句子之间的关系。
评估协议
在小样本学习中,每个实验设置下随机采样5次,报告5次实验的平均值作为模型表现。(We argue that sampling multiple splits gives a more robust measure of performance)
任务解决范式
(1)建模为回归问题,比如情感分类,0 为negative,1表示positive。(损失L=均方误差)
(2)建模为分类问题(损失L=交叉熵损失)
文章研究问题
(1) support set 和 train set的构建方式会影响模型的效果,也就是,Dtrain=kDdev时,两个数据集中包含的数据呈不同比例时, LM的效果不同
(2)手动构建模板下的LM效果
(3)自动生成模板的方式,Label生成、模板生成?
(4)展示怎么取?demonstration怎么采样的问题?
具体内容
(1)人工模板的构建

(2)自动模板的构建(以分类任务为例)
----------自动生成label words
我理解的是,使用T5预训练的损失作为损失,生成一个label set ,这个label set是由每个类型中出现的前k个词组成的。然后,在对这个初步修剪后的label set在dev数据集上实验,使用 Ddev 重新排名以找到最好的
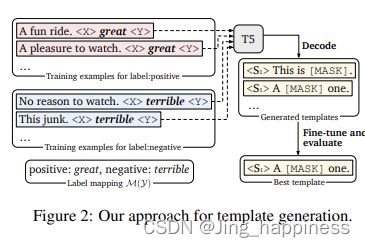
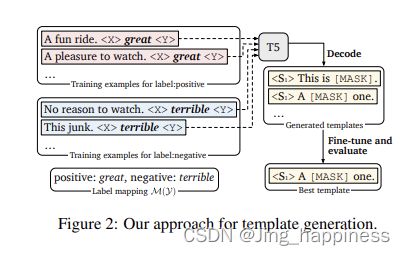
---------自动生成模板 templates
如下图,《X》、《Y》是要待生成的模板词,经过T5解码后,比如,生成的X为A,Y为one. 。
这里采用了波束搜索查找的方式。https://blog.csdn.net/weixin_39653948/article/details/109165934
(波束搜索(Beam Search)算法基于条件概率在每个时间步长为输入序列选择多个备选方案。多个备选方案的数量取决于一个称为波束宽度(Beam Width)的参数 B 。在每个时间步,波束搜索选择 B 个具有最高概率的最佳备选方案作为该时间步最可能的选择。让我们举个例子来理解这一点。
我们将选择 beam width=3;英语词汇有10000个。
第一步:给定输入句子,找出概率最高的前3个单词。最可能的单词数量基于波束宽度。
将编码后的输入句子输入到解码器;解码器将对词汇表中的所有10000个单词应用softmax函数。
从10000个概率得分中,选出概率最高的前3个单词。
考虑翻译单词的3个最可能的选择,因为波束宽度设置为3。如果波束宽度设置为10,则选择概率最高的前10个单词。
第二步,以这三个单词作为输出,找到三个单词的新的组合,比如第一步为:“I”,第二步,:“I will”可能会作为一个组合,然后在第二步,选择概率第一步中三个单词的最大的前三种组合,作为第三部的输入,依次做下去。)
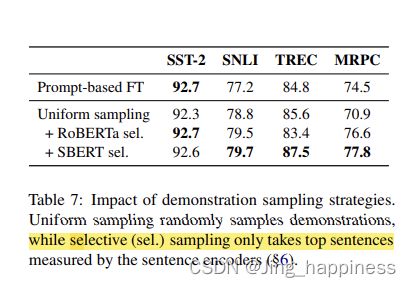
展示的采样
对比演示 x © in 的集合都显着不同——彼此不同,或者与查询 xin 不同——因此,语言模型破译有意义的模式变得具有挑战性。结果,模型可能会简单地忽略。我们设计了一个简单的策略,我们只对语义上接近 xin 的示例进行采样。具体来说,我们使用预训练的 SBERT (Reimers and Gurevych, 2019) 模型来获取所有输入句子的嵌入(对于句子对任务,我们使用两个句子的连接)。在这里,我们只是将没有模板的原始句子输入 SBERT。对于每个查询 xin 和每个标签 c ∈ Y,我们按照与查询 cos(e(xin), e(x)) 的相似度得分对所有带有标签 x ∈ Dc train 的训练实例进行排序,并且仅从顶部 r 中采样= 每个类 50% 的实例用作演示。
实验结果
单模板下的实验结果
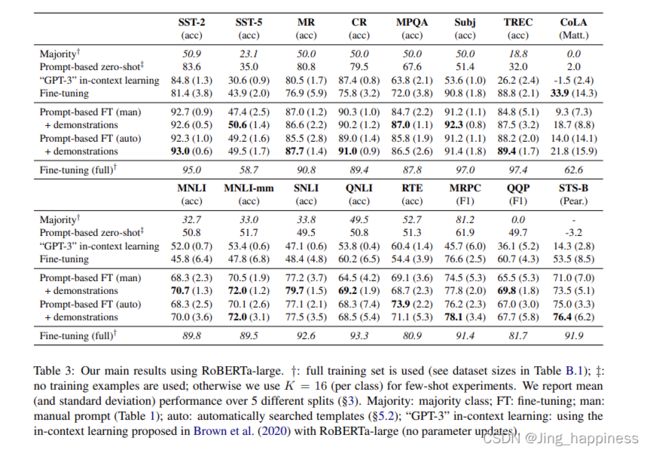
组合模板下的实验结果
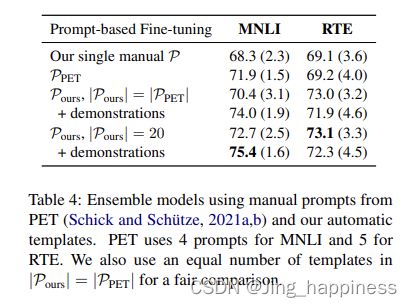
自动化模板下的实验结果
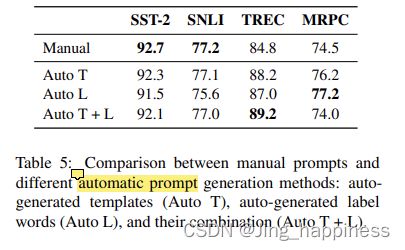
生成样例

展示采样方法