L1正则化和L2正则化
正则化
正则化可理解为一种“罚函数法”,即对不希望得到的结果施加惩罚,从而使得优化过程趋向于希望目标
从贝叶斯估计的角度来看,正则化项可认为是提供了模型的先验概率
B站视频讲解链接
为什么加正则化项可以防止过拟合?
从数学的角度来说,加正则化项就相当于加约束条件,加了约束条件使很多的参数分量 w i = 0 w_i=0 wi=0(相当于特征选择)从而降低模型复杂度,也就是防止因为参数过多导致的过拟合现象
机器学习内容
L p L_p Lp范数 ( n o r m ) (norm) (norm)
L p L_p Lp范数 ( n o r m ) (norm) (norm)是常用的正则化项,其中 L 2 L_2 L2范数 ∣ ∣ \mid\mid ∣∣ w 2 w_2 w2 ∣ ∣ \mid\mid ∣∣倾向于 w ⃗ \vec w w的分量取值尽量均衡,即非零分量个数尽量稠密,而 L 0 L_0 L0范数 ∣ ∣ \mid\mid ∣∣ w 0 w_0 w0 ∣ ∣ \mid\mid ∣∣和 L 1 L_1 L1范数 ∣ ∣ \mid\mid ∣∣ w 1 w_1 w1 ∣ ∣ \mid\mid ∣∣则倾向于 w w w的分量尽量稀疏,即非零向量个数尽量少。
与闵可夫斯基距离的定义一样, L p L_p Lp范数不是一个范数,而是一组范数,其定义如下:
———————————————————————————————————
L p = p ∑ i = 1 n x i p ( x = x 1 , x 2 , . . . , x n ) L_p=p\sqrt {\sum_{i=1}^{n}{x_i^p}} \space\space (x = x_1,x_2,...,x_n) Lp=pi=1∑nxip (x=x1,x2,...,xn)
———————————————————————————————————
L 0 L_0 L0范数
当 p = 0 p=0 p=0时,也就是 L 0 L_0 L0范数, L 0 L_0 L0范数并不是一个真正的范数,它主要被用来度量向量中非零元素的个数。用 L p L_p Lp定义可以得到的 L 0 L_0 L0的定义为:
L 0 = 0 ∑ i = 1 n x i 0 ( x = x 1 , x 2 , . . . , x n ) L_0=0\sqrt {\sum_{i=1}^{n}{x_i^0}} \space\space (x = x_1,x_2,...,x_n) L0=0i=1∑nxi0 (x=x1,x2,...,xn)
这里就有点问题了,我们知道非零元素的零次方为1,但零的零次方为0,非零数开零次方都是什么鬼,很不好说明 L 0 L_0 L0的意义,所以在通常情况下,大家都用的是 ∥ x ∥ 0 = # ( i ∣ x i ≠ 0 ) {\|x\|_0}=\#(i|x_i \neq 0) ∥x∥0=#(i∣xi=0)来表示,对于 L 0 L_0 L0,其优化问题为
m i n ∥ x ∥ 0 s . t . A x = b min\|x\|_0\\s.t.\space Ax=b min∥x∥0s.t. Ax=b
在实际应用中,由于 L 0 L_0 L0范数本身不容易有一个好的数学表示形式,给出上面问题的形式化表示是一个很难的问题,故被人认为是一个NP难问题。所以在实际情况中, L 0 L_0 L0的最优问题会被放宽到 L 1 L_1 L1或 L 2 L_2 L2下的最优化。
L 1 L_1 L1范数和 L 0 L_0 L0都范数可以实现稀疏, L 1 L_1 L1范数因具有比 L 0 L_0 L0范数更好的优化求解特性而被广泛应用。
机器学习中的正则化应用
给定数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } D = \lbrace(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\rbrace D={(x1,y1),(x2,y2),...,(xm,ym)},其中 x ∈ R d , y ∈ R x \in \Bbb R^d,y \in \Bbb R x∈Rd,y∈R
我们考虑最简单的线性回归模型,以平方误差为损失函数,则优化目标为:
m i n w ∑ i = 1 m ( y i − w ⃗ T x i ) 2 min_{w}\sum_{i=1}^{m}{({y_i}-{\vec w}^T{x_i})}^2 minwi=1∑m(yi−wTxi)2
当样本特征很多,而样本数相对较少时,上式很容易陷入过拟合。为了缓解过拟合问题,可以引入正则化项。若使用 L 2 L_2 L2范数正则化,则有:
m i n w ∑ i = 1 m ( y i − w ⃗ T x i ) 2 + λ ∥ w ∥ 2 2 min_{w}\sum_{i=1}^{m}{({y_i}-{\vec w}^T{x_i})}^2 + \lambda\|w\|_2^2 minwi=1∑m(yi−wTxi)2+λ∥w∥22
其中正则化参数 λ \lambda λ>0.上式称为“岭回归”(ridge regression),通过引入 L 2 L_2 L2范数正则化,确能显著降低过拟合得风险。
下面来将正则化项中的 L 2 L_2 L2范数替换为 L p L_p Lp范数,令 p = 1 p=1 p=1,即采用 L 1 L_1 L1范数,则有:
m i n w ∑ i = 1 m ( y i − w ⃗ T x i ) 2 + λ ∥ w ⃗ ∥ 1 min_{w}\sum_{i=1}^{m}{({y_i}-{\vec w}^T{x_i})}^2 + \lambda\|{\vec w}\|_1 minwi=1∑m(yi−wTxi)2+λ∥w∥1
其中正则化参数 λ \lambda λ>0.该式称为LASSO(Least Absolute Shrinkage and Selection Operator)(最小绝对收缩选择算子)
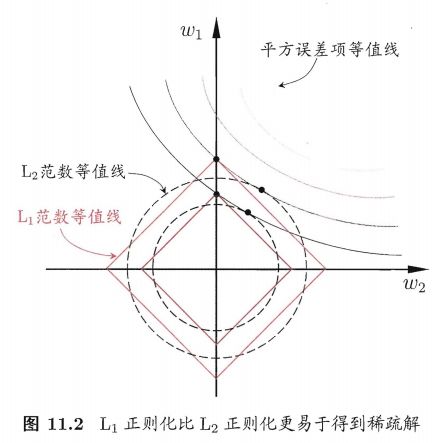
L 1 L_1 L1范数和 L 2 L_2 L2范数正则化都有助于降低过拟合风险,但前者还会带来一个额外的好处: L 1 L_1 L1范数比 L 2 L_2 L2范数更易于获得“稀疏解”即求得的 w ⃗ \vec w w会有更少的非零分量
对 w ⃗ \vec w w添加“稀疏约束”(即希望 w ⃗ \vec w w的非零分量尽可能少)最自然的是使用 L 0 L_0 L0范数,但 L 0 L_0 L0范数不连续,难以优化求解,因此常使用 L 1 L_1 L1范数来近似
举个例子:
假定 x ⃗ \vec x x仅有两个属性,那么上述两个公式都解出的 w ⃗ \vec w w都只有两个分量,即 w 1 , w 2 , w_1,w_2, w1,w2,我们将其作为两个坐标轴,画出公式前半部分 ∑ i = 1 m ( y i − w ⃗ T x i ) 2 \sum_{i=1}^{m}{({y_i}-{\vec w}^T{x_i})}^2 ∑i=1m(yi−wTxi)2的等值线,即在 ( w 1 , w 2 ) (w_1,w_2) (w1,w2)空间中平方误差项取值相同的点的连线,再分别绘制出 L 1 L_1 L1范数和 L 2 L_2 L2范数的等值线,即在 ( w 1 , w 2 ) (w_1,w_2) (w1,w2)空间中 L 1 L_1 L1范数取值相同的点的连线,以及 L 2 L_2 L2范数取值相同的点的连线, L 1 L_1 L1范数和 L 2 L_2 L2范数公式的解 w ⃗ \vec w w需要在平方误差项和正则化项之间折中,即出现在图中平方误差项等值线与正则化项等值线的相交处。从图中可以看出,采用 L 1 L_1 L1范数时平方误差项等值线与正则化项等值线的交点常出现在坐标轴上,即 w 1 w_1 w1或 w 2 w_2 w2为0;采用 L 2 L_2 L2范数时平方误差项等值线与正则化项等值线的交点常出现在某个象限中,即 w 1 w_1 w1或 w 2 w_2 w2均非0,换句话说,采用 L 1 L_1 L1范数比 L 2 L_2 L2范数更易于得到稀疏解。