大模型相关技术综述
中文大模型、多模态大模型&大模型训练语料持续迭代
大模型演进历史
预训练模型
word2vec
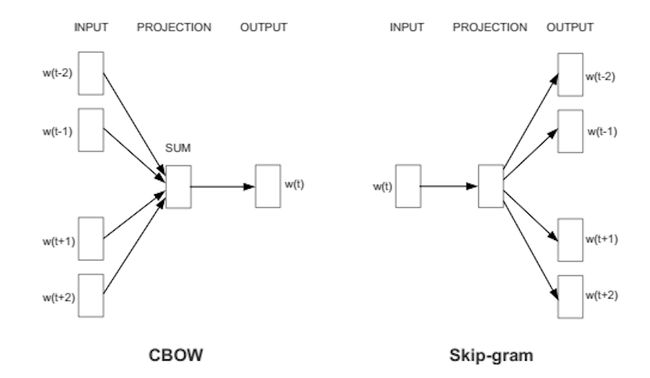
word2vec属于NLP领域无监督学习和比较学习的先祖。精髓在于可以用不带标签的文本语料输入神经网络模型,就可以学习到每个词的带语的词向量表示。它背后原理其实就是人类讲出来的话已经是带有信息量的,只要通过神经网络对语料批量处理词和上下文映射关系,就能学习到人类对某个词的上下文语意。
用一个向量来表示每个词汇,语义比较相近的词汇,它们的向量会比较接近。
词嵌入技术过去经常用到,但是它有一个很大的缺点。就是一词多义问题。每个词只有唯一的向量表示,所以一词多义的话,词意思就是训练语料里这个词出现最多词上下文的表示,会把其它次要上下文语意直接忘记
elmo
Word Embedding本质上是个静态的方式,即训练好之后每个单词的表达就固定住了,以后使用的时候,不论新句子上下文单词是什么,这个单词的Word Embedding不会跟着上下文场景的变化而改变,所以对于比如Bank这个词,它事先学好的Word Embedding中混合了几种语义 ,在应用中来了个新句子,即使从上下文中(比如句子包含money等词)明显可以看出它代表的是“银行”的含义,但是对应的Word Embedding内容也不会变,它还是混合了多种语义。
ELMO的本质思想是:先用语言模型学好一个单词的Word Embedding,此时多义词无法区分,不过这没关系。在实际使用Word Embedding的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以ELMO本身是个根据当前上下文对Word Embedding动态调整的思路。
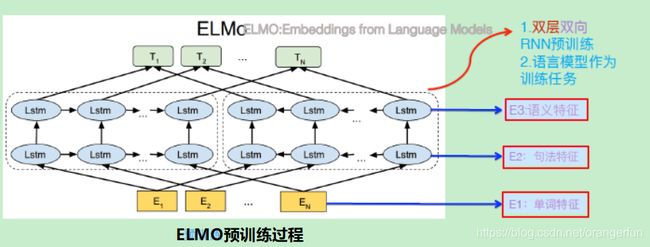
ELMO采用了典型的两阶段过程,第一个阶段是利用语言模型进行预训练;第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。
ELMO的网络结构采用了双层双向LSTM,目前语言模型训练的任务目标是根据单词 Wi 的上下文去正确预测单词 Wi ,Wi 之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。图中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词外 Wi 的上文Context-before和下文Context-after;右端的逆向双层LSTM代表反方向编码器,输入的是从右到左的逆序的句子上文和下文;每个编码器的深度都是两层LSTM叠加,而每一层的正向和逆向单词编码会拼接到一起;如下图所示
预训练好网络结构后,如何给下游任务使用呢?
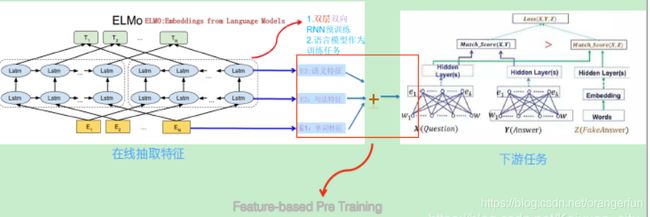
下图展示了下游任务的使用过程,比如我们的下游任务仍然是QA问题,此时对于问句X,我们可以先将句子X作为预训练好的ELMO网络的输入,这样句子X中每个单词在ELMO网络中都能获得对应的三个Embedding(单词的Embedding,句法层面的Embedding,语义层面的Embedding),之后给予这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个。然后将整合后的这个Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。对于上图所示下游任务QA中的回答句子Y来说也是如此处理。因为ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”
ELMO也存在一些缺点
(1)特征抽取器选择方面,ELMO使用了LSTM而不是Transformer;Transformer提取特征的能力是要远强于LSTM的
(2)ELMO采取双向拼接这种融合特征的能力可能比Bert一体化的融合特征方式弱,但是,这只是一种从道理推断产生的怀疑,目前并没有具体实验说明这一点。
Contextualized Word Embedding
transform
1.传统encode-decode模型的前步依赖,无法并行化计算,影响运算速度问题
2.如何通过位置向量解决句子有序性
3.为何要多头——解决自注意力机制单头过度关心自己问题
4.Decoder部分训练时候如何加速——Attention MASK+Decode输入
5.Decode时候如何把Encode作为memory字典来查
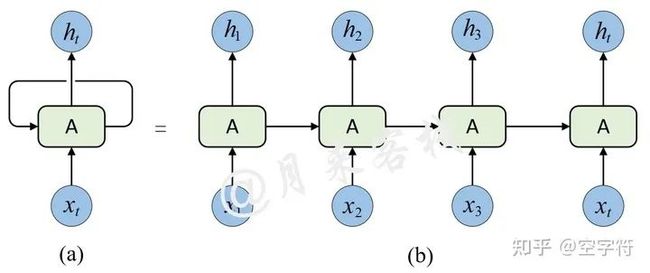
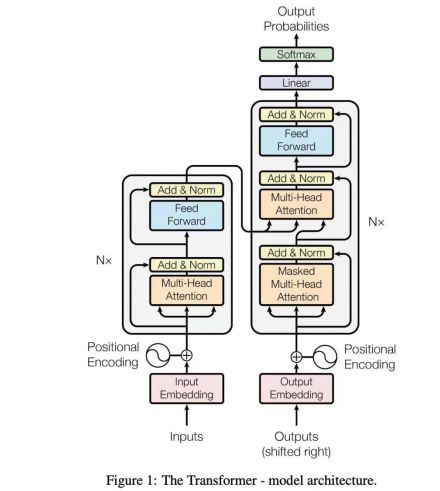
主流的序列模型都是基于复杂的循环神经网络或者是卷积神经网络构造而来的Encoder-Decoder模型,并且就算是目前性能最好的序列模型也都是基于注意力机制下的Encoder-Decoder架构。为什么作者会不停的提及这些传统的Encoder-Decoder模型呢?接着,作者在介绍部分谈到,由于传统的Encoder-Decoder架构在建模过程中,下一个时刻的计算过程会依赖于上一个时刻的输出,而这种固有的属性就限制了传统的Encoder-Decoder模型就不能以并行的方式进行计算,如图1-1所示。
如图1-2所示。当然,Transformer架构的优点在于它完全摈弃了传统的循环结构,取而代之的是只通过注意力机制来计算模型输入与输出的隐含表示,而这种注意力的名字就是大名鼎鼎的自注意力机制(self-attention),也就是图1-2中的Multi-Head Attention模块。

所谓自注意力机制就是通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重;然后再以权重和的形式来计算得到整个句子的隐含向量表示。最终,Transformer架构就是基于这种的自注意力机制而构建的Encoder-Decoder模型。

从图1-3可以看出,自注意力机制的核心过程就是通过Q和K计算得到注意力权重;然后再作用于V得到整个权重和输出。具体的,对于输入Q、K和V来说,其输出向量的计算公式为:
其中Q、K和V分别为3个矩阵,且其(第2个)维度分别为 (从后面的计算过程其实可以发现(1.1)中除以的过程就是图1-3中所指的Scale过程。
之所以要进行缩放这一步是因为通过实验作者发现,对于较大的来说在完成后将会得到很大的值,而这将导致在经过sofrmax操作后产生非常小的梯度,不利于网络的训练。
如果仅仅只是看着图1-3中的结构以及公式中的计算过程显然是不那么容易理解自注意力机制的含义,例如初学者最困惑的一个问题就是图1-3中的Q、K和V分别是怎么来的?下面,我们来看一个实际的计算示例。现在,假设输入序列“我 是 谁”,且已经通过某种方式得到了1个形状为的矩阵来进行表示,那么通过图1-3所示的过程便能够就算得到Q、K以及V[2]。
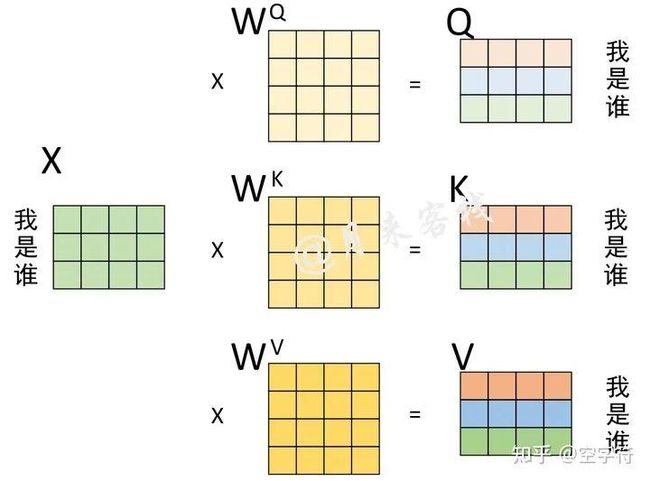
图 1-4. Q、K和V计算过程图
从图1-4的计算过程可以看出,Q、K和V其实就是输入X分别乘以3个不同的矩阵计算而来(但这仅仅局限于Encoder和Decoder在各自输入部分利用自注意力机制进行编码的过程,Encoder和Decoder交互部分的Q、K和V另有指代)。此处对于计算得到的Q、K、V,你可以理解为这是对于同一个输入进行3次不同的线性变换来表示其不同的3种状态。在计算得到Q、K、V之后,就可以进一步计算得到权重向量,计算过程如图1-5所示。

图 1-5. 注意力权重计算图(已经经过scale和softmax操作)
如图1-5所示,在经过上述过程计算得到了这个注意力权重矩阵之后我们不禁就会问到,这些权重值到底表示的是什么呢?对于权重矩阵的第1行来说,0.7表示的就是“我”与“我”的注意力值;0.2表示的就是“我”与”是”的注意力值;0.1表示的就是“我”与“谁”的注意力值。换句话说,在对序列中的“我“进行编码时,应该将0.7的注意力放在“我”上,0.2的注意力放在“是”上,将0.1的注意力放在谁上。
同理,对于权重矩阵的第3行来说,其表示的含义就是,在对序列中”谁“进行编码时,应该将0.2的注意力放在“我”上,将0.1的注意力放在“是”上,将0.7的注意力放在“谁”上。从这一过程可以看出,通过这个权重矩阵模型就能轻松的知道在编码对应位置上的向量时,应该以何种方式将注意力集中到不同的位置上。
不过从上面的计算结果还可以看到一点就是,模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置(虽然这符合常识)而可能忽略了其它位置[2]。因此,作者采取的一种解决方案就是采用多头注意力机制(MultiHeadAttention),这部分内容我们将在稍后看到。
在通过图1-5示的过程计算得到权重矩阵后,便可以将其作用于V ,进而得到最终的编码输出,计算过程如图1-6所示。
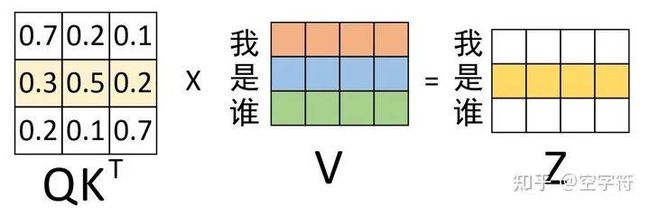
图 1-6. 权重和编码输出图
根据如图1-6所示的过程,我们便能够得到最后编码后的输出向量。当然,对于上述过程我们还可以换个角度来进行观察,如图1-7所示。

图 1-7. 编码输出计算图
从图1-7可以看出,对于最终输出“是”的编码向量来说,它其实就是原始“我 是 谁”3个向量的加权和,而这也就体现了在对“是”进行编码时注意力权重分配的全过程。
当然,对于整个图1-5到图1-6的过程,我们还可以通过如图1-8所示的过程来进行表示。
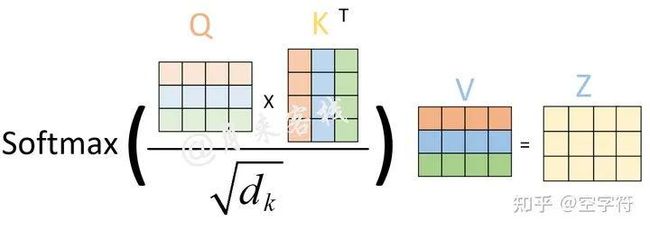
图 1-8. 自注意力机制计算过程图
可以看出通过这种自注意力机制的方式确实解决了作者在论文伊始所提出的“传统序列模型在编码过程中都需顺序进行的弊端”的问题,有了自注意力机制后,仅仅只需要对原始输入进行几次矩阵变换便能够得到最终包含有不同位置注意力信息的编码向量。
对于自注意力机制的核心部分到这里就介绍完了,不过里面依旧有很多细节之处没有进行介绍。例如Encoder和Decoder在进行交互时的Q、K、V是如何得到的?在图1-3中所标记的Mask操作是什么意思,什么情况下会用到等等?这些内容将会在后续逐一进行介绍。
下面,让我们继续进入到MultiHeadAttention机制的探索中。
1.2.2 为什么要MultiHeadAttention
经过上面内容的介绍,我们算是在一定程度上对于自注意力机制有了清晰的认识,不过在上面我们也提到了自注意力机制的缺陷就是:模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置, 因此作者提出了通过多头注意力机制来解决这一问题。同时,使用多头注意力机制还能够给予注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力。
在说完为什么需要多头注意力机制以及使用多头注意力机制的好处之后,下面我们就来看一看到底什么是多头注意力机制。

图 1-9. 多头注意力机制结构图
如图1-9所示,可以看到所谓的多头注意力机制其实就是将原始的输入序列进行多组的自注意力处理过程;然后再将每一组自注意力的结果拼接起来进行一次线性变换得到最终的输出结果。具体的,其计算公式为:
其中
同时,在论文中,作者使用了个并行的自注意力模块(8个头)来构建一个注意力层,并且对于每个自注意力模块都限定了。从这里其实可以发现,论文中所使用的多头注意力机制其实就是将一个大的高维单头拆分成了个多头。因此,整个多头注意力机制的计算过程我们可以通过如图1-10所示的过程来进行表示。
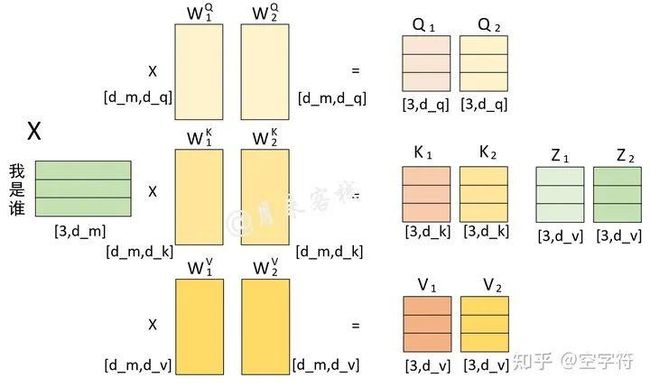
图 1-10. 多头注意力机制计算过程图
注意:图中的d_m 就是指
如图1-10所示,根据输入序列X和 我们就计算得到了,进一步根据公式就得到了单个自注意力模块的输出;同理,根据X和就得到了另外一个自注意力模块输出。最后,根据公式将水平堆叠形成,然后再用乘以便得到了整个多头注意力层的输出。同时,根据图1-9中的计算过程,还可以得到。
到此,对于整个Transformer的核心部分,即多头注意力机制的原理就介绍完了。
1.2.3 同维度中的单头与多头的区别
在多头注意力中,对于初学者来说一个比较经典的问题就是,在相同维度下使用单头和多头的区别是什么?这句话什么意思呢?以图1-10中示例为例,此时的自注意力中使用了两个头,每个头的维度为,即采用了多头的方式。另外一种做法就是,只是用一个头,但是其维度为,即采用单头的方式。那么在这两种情况下有什么区别呢?
首先,从论文中内容可知,作者在头注意力机制与多头个数之间做了如下的限制
从式可以看出,单个头注意力机制的维度乘上多头的个数就等于模型的维度。
注意:后续的d_m,以及都是指代模型的维度。
同时,从图1-10中可以看出,这里使用的多头数量,即。此时,对于第1个头来说有:

图 1-11. 头1注意力计算过程
对于第2个头来说有:
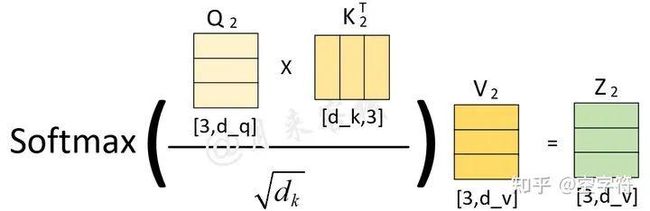
图 1-12. 头2注意力计算过程
最后,可以将在横向堆叠起来进行一个线性变换得到最终的。因此,对于图1-10所示的计算过程,我们还可以通过图1-13来进行表示。
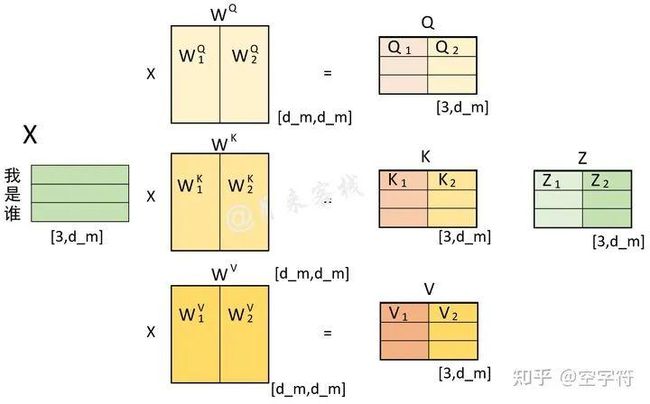
图 1-13. 多头注意力合并计算过程图
从图1-13可知,在一开始初始化这3个权重矩阵时,可以直接同时初始化个头的权重,然后再进行后续的计算。而且事实上,在真正的代码实现过程中也是采用的这样的方式,这部分内容将在3.3.2节中进行介绍。因此,对图1-13中的多头计算过程,还可以根据图1-14来进行表示。
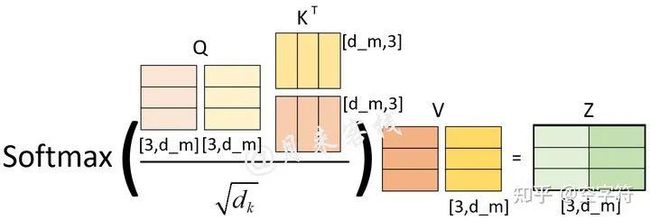
图 1-14. 多头注意力计算过程图
说了这么多,终于把铺垫做完了。此时,假如有如图1-15所示的头注意力计算过程:

图 1-15. 头注意力计算过程图
如图1-15所示,该计算过程采用了头注意力机制来进行计算,且头的计算过程还可通过图1-16来进行表示。
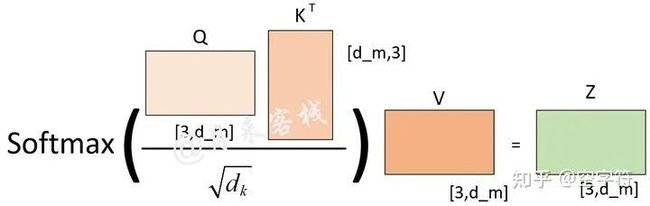
图 1-16. 头注意力机制计算过程题
那现在的问题是图1-16中的能够计算得到吗?答案是不能。为什么?因为我没有告诉你这里的等于多少。如果我告诉你多头,那么毫无疑问图1-16的计算过程就等同于图1-14的计算过程,即
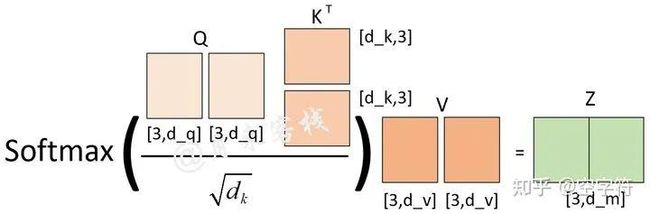
图 1-17. 当h=2时注意力计算过程图
且此时。但是如果我告诉你多头,那么图1-16的计算过程会变成
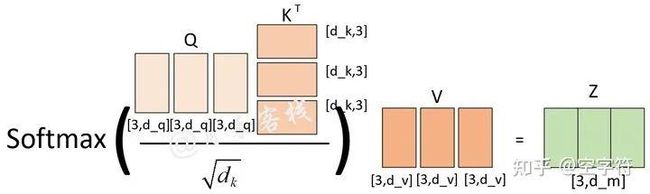
图 1-18. 当h=3时注意力计算过程图
那么此时则为。
现在回到一开始的问题上,根据上面的论述我们可以发现,在固定的情况下,不管是使用单头还是多头的方式,在实际的处理过程中直到进行注意力权重矩阵计算前,两者之前没有任何区别。当进行进行注意力权重矩阵计算时,越大那么就会被切分得越小,进而得到的注意力权重分配方式越多,如图1-19所示。

图 1-19. 注意力机制分配图
从图1-19可以看出,如果,那么最终可能得到的就是一个各个位置只集中于自身位置的注意力权重矩阵;如果,那么就还可能得到另外一个注意力权重稍微分配合理的权重矩阵;同理如此。因而多头这一做法也恰好是论文作者提出用于克服模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置的问题。这里再插入一张真实场景下同一层的不同注意力权重矩阵可视化结果图:
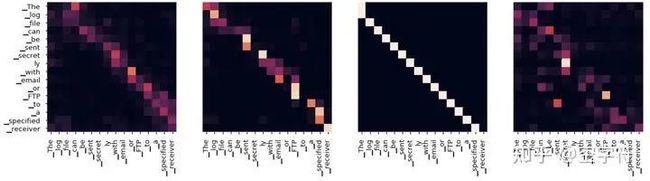
图1-20. 注意力机制分配图
同时,当不一样时,的取值也不一样,进而使得对权重矩阵的scale的程度不一样。例如,如果,那么当时,则;当时,则。
所以,当模型的维度确定时,一定程度上越大整个模型的表达能力越强,越能提高模型对于注意力权重的合理分配。
2. 位置编码与编码解码过程
2.1 Embedding机制
在正式介绍Transformer的网络结构之前,我们先来一起看看Transformer如何对字符进行Embedding处理。
2.1.1 Token Embedding
熟悉文本处理的读者可能都知道,在对文本相关的数据进行建模时首先要做的便是对其进行向量化。例如在机器学习中,常见的文本表示方法有one-hot编码、词袋模型以及TF-IDF等。不过在深度学习中,更常见的做法便是将各个词(或者字)通过一个Embedding层映射到低维稠密的向量空间。因此,在Transformer模型中,首先第一步要做的同样是将文本以这样的方式进行向量化表示,并且将其称之为Token Embedding,也就是深度学习中常说的词嵌入(Word Embedding)如图2-1所示。

图 2-1. Token Embedding
如果是换做之前的网络模型,例如CNN或者RNN,那么对于文本向量化的步骤就到此结束了,因为这些网络结构本身已经具备了捕捉时序特征的能力,不管是CNN中的n-gram形式还是RNN中的时序形式。但是这对仅仅只有自注意力机制的网络结构来说却不行。为什么呢?根据自注意力机制原理的介绍我们知道,自注意力机制在实际运算过程中不过就是几个矩阵来回相乘进行线性变换而已。因此,这就导致即使是打乱各个词的顺序,那么最终计算得到的结果本质上却没有发生任何变换,换句话说仅仅只使用自注意力机制会丢失文本原有的序列信息。
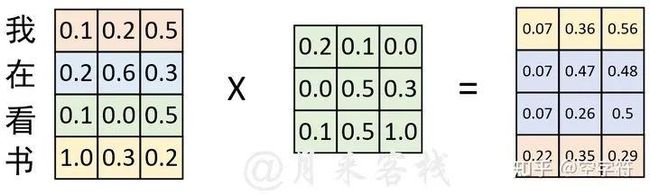
图 2-2. 自注意力机制弊端图(一)
如图2-2所示,在经过词嵌入表示后,序列“我 在 看 书”经过了一次线性变换。现在,我们将序列变成“书 在 看 我”,然后同样以中间这个权重矩阵来进行线性变换,过程如图2-3所示。

图 2-3. 自注意力机制弊端图(二)
根据图2-3中的计算结果来看,序列在交换位置前和交换位置后计算得到的结果在本质上并没有任何区别,仅仅只是交换了对应的位置。因此,基于这样的原因,Transformer在原始输入文本进行Token Embedding后,又额外的加入了一个Positional Embedding来刻画数据在时序上的特征。
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence.
2.1.2 Positional Embedding
说了这么多,那到底什么又是Positional Embedding呢?数无形时少直觉,下面我们先来通过一幅图直观看看经过Positional Embedding处理后到底产生了什么样的变化。

图 2-4. Positional Embedding
如图2-4所示,横坐标表示输入序列中的每一个Token,每一条曲线或者直线表示对应Token在每个维度上对应的位置信息。在左图中,每个维度所对应的位置信息都是一个不变的常数;而在右图中,每个维度所对应的位置信息都是基于某种公式变换所得到。换句话说就是,左图中任意两个Token上的向量都可以进行位置交换而模型却不能捕捉到这一差异,但是加入右图这样的位置信息模型却能够感知到。例如位置20这一处的向量,在左图中无论你将它换到哪个位置,都和原来一模一样;但在右图中,你却再也找不到与位置20处位置信息相同的位置。
下面,笔者通过两个实际的示例来进行说明。
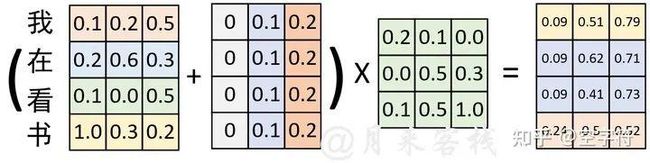
图 2-5. 常数Positional Embedding(一)
如图2-5所示,原始输入在经过Token Embedding后,又加入了一个常数位置信息的的Positional Embedding。在经过一次线性变换后便得到了图2-5左右边所示的结果。接下来,我们再交换序列的位置,并同时进行Positional Embedding观察其结果。
图 2-6. 常数Positional Embedding(二)
如图2-6所示,在交换序列位置后,采用同样的Positional Embedding进行处理,并且进行线性变换。可以发现,其计算结果同图2-5中的计算结果本质上也没有发生变换。因此,这就再次证明,如果Positional Embedding中位置信息是以常数形式进行变换,那么这样的Positional Embedding是无效的。
在Transformer中,作者采用了如公式所示的规则来生成各个维度的位置信息,其可视化结果如图2-4右所示。
其中就是这个Positional Embedding矩阵,表示具体的某一个位置,表示具体的某一维度。
最终,在融入这种非常数的Positional Embedding位置信息后,便可以得到如图2-7所示的对比结果。
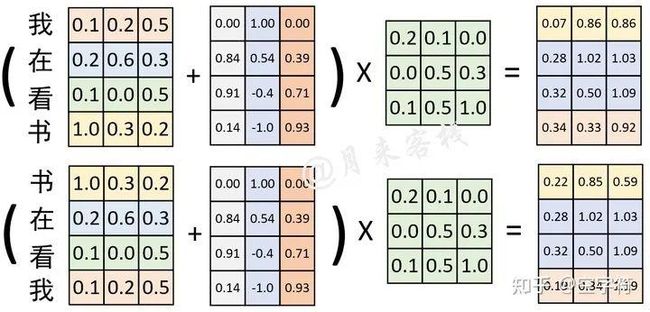
图 2-7. 非常数Positional Embedding
从图2-7可以看出,在交换位置前与交换位置后,与同一个权重矩阵进行线性变换后的结果截然不同。因此,这就证明通过Positional Embedding可以弥补自注意力机制不能捕捉序列时序信息的缺陷。
说完Transformer中的Embedding后,接下来我们再来继续探究Transformer的网络结构。
2.2 Transformer网络结构
如图2-8所示便是一个单层Transformer网络结构图。
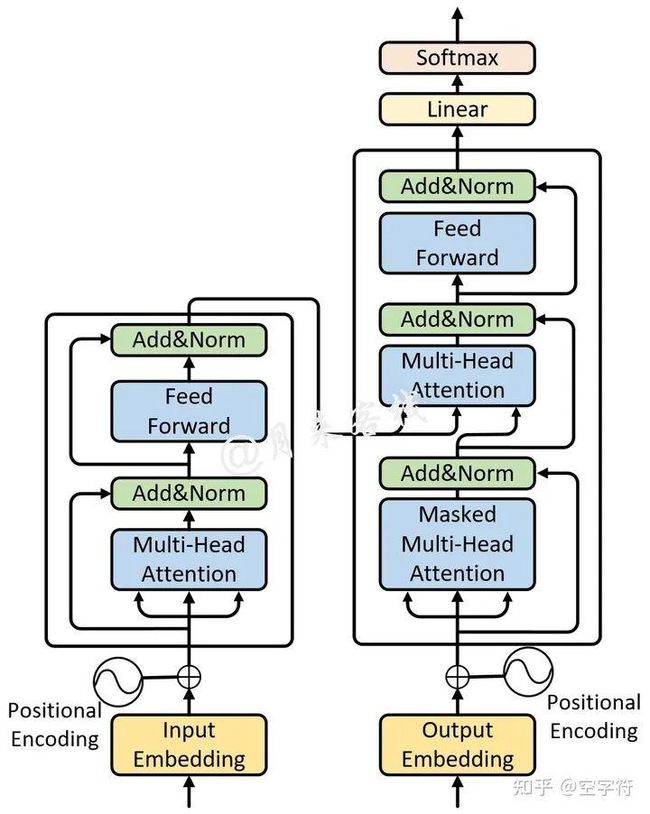
图 2-8. 单层Transformer网络结构图
如图2-8所示,整个Transformer网络包含左右两个部分,即Encoder和Decoder。下面,我们就分别来对其中的各个部分进行介绍。
2.2.1 Encoder层
首先,对于Encoder来说,其网络结构如图2-8左侧所示(尽管论文中是以6个这样相同的模块堆叠而成,但这里我们先以堆叠一层来进行介绍,多层的Transformer结构将在稍后进行介绍)。
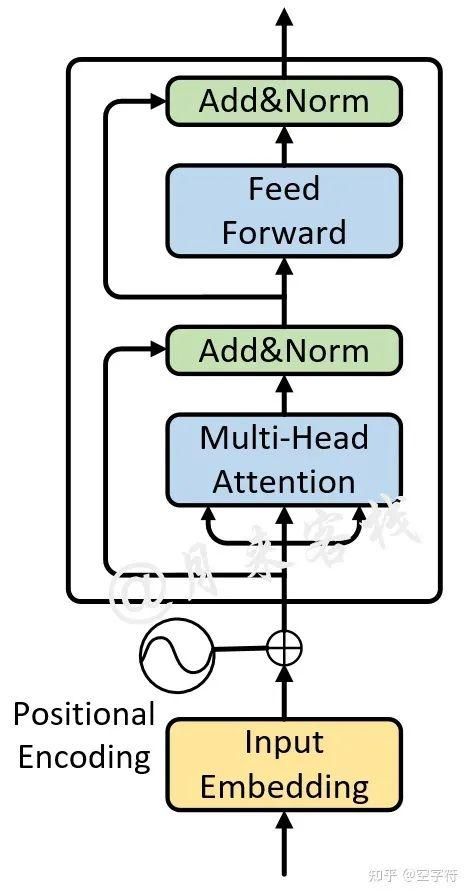
图 2-9. Encoder网络结构图
如图2-9所示,对于Encoder部分来说其内部主要由两部分网络所构成:多头注意力机制和两层前馈神经网络。
同时,对于这两部分网络来说,都加入了残差连接,并且在残差连接后还进行了层归一化操作。这样,对于每个部分来说其输出均为,并且在都加入了Dropout操作。
进一步,为了便于在这些地方使用残差连接,这两部分网络输出向量的维度均为。
对于第2部分的两层全连接网络来说,其具体计算过程为
其中输入的维度为,第1层全连接层的输出维度为,第2层全连接层的输出为,且同时对于第1层网络的输出还运用了Relu激活函数。
到此,对于单层Encoder的网络结构就算是介绍完了,接下来让我们继续探究Decoder部分的网络结构。
2.2.2 Decoder层
同Encoder部分一样,论文中也采用了6个完全相同的网络层堆叠而成,不过这里我们依旧只是先看1层时的情况。对于Decoder部分来说,其整体上与Encoder类似,只是多了一个用于与Encoder输出进行交互的多头注意力机制,如图2-10所示。
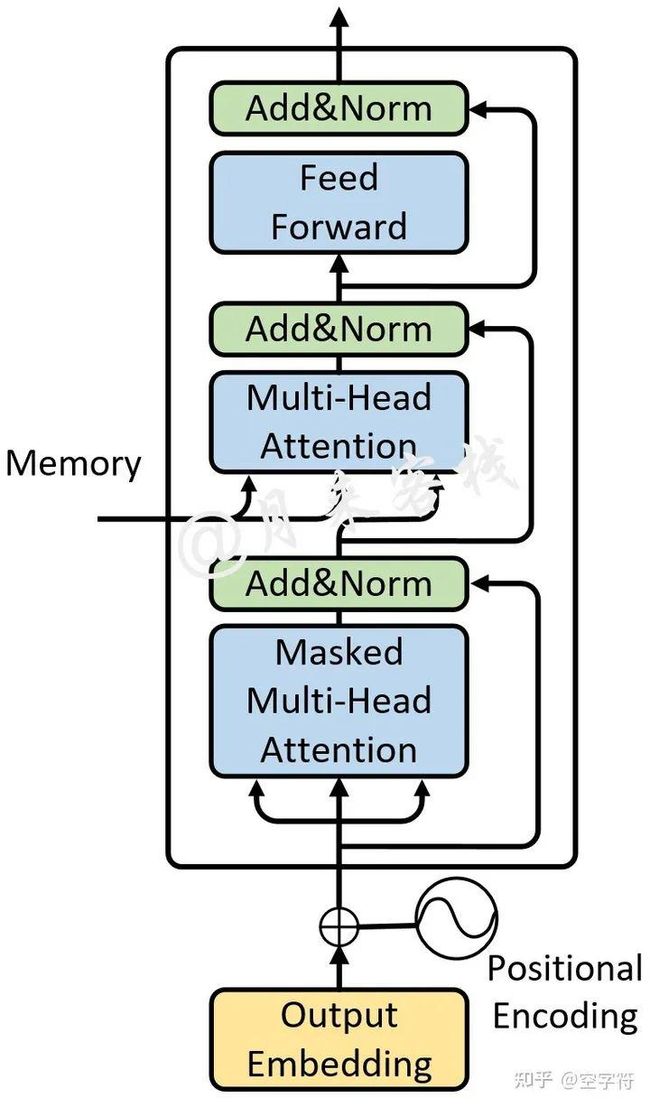
图 2-10. Decoder网络结构图
不同于Encoder部分,在Decoder中一共包含有3个部分的网络结构。最上面的和最下面的部分(暂时忽略Mask)与Encoder相同,只是多了中间这个与Encoder输出(Memory)进行交互的部分,作者称之为“Encoder-Decoder attention”。对于这部分的输入,Q来自于下面多头注意力机制的输出,K和V均是Encoder部分的输出(Memory)经过线性变换后得到。而作者之所以这样设计也是在模仿传统Encoder-Decoder网络模型的解码过程。
为了能够更好的理解这里Q、K、V的含义,我们先来看看传统的基于Encoder-Decoder的Seq2Seq翻译模型是如何进行解码的,如图2-11所示。

图 2-11. 传统的Seq2Seq网络模型图
如图2-11所示是一个经典的基于Encoder-Decoder的机器翻译模型。左下边部分为编码器,右下边部分为解码器,左上边部分便是注意力机制部分。在图2-11中,表示的是在编码过程中,各个时刻的隐含状态,称之为每个时刻的Memory;表示解码当前时刻时的隐含状态。此时注意力机制的思想在于,希望模型在解码的时刻能够参考编码阶段每个时刻的记忆。
因此,在解码第一个时刻""时,会首先同每个记忆状态进行相似度比较得到注意力权重。这个注意力权重所蕴含的意思就是,在解码第一个时刻时应该将的注意力放在编码第一个时刻的记忆上(其它的同理),最终通过加权求和得到4个Memory的权重和,即context vector。同理,在解码第二时刻"我"时,也会遵循上面的这一解码过程。可以看出,此时注意力机制扮演的就是能够使得Encoder与Decoder进行交互的角色。
回到Transformer的Encoder-Decoder attention中,K和V均是编码部分的输出Memory经过线性变换后的结果(此时的Memory中包含了原始输入序列每个位置的编码信息),而Q是解码部分多头注意力机制输出的隐含向量经过线性变换后的结果。在Decoder对每一个时刻进行解码时,首先需要做的便是通过Q与 K进行交互(query查询),并计算得到注意力权重矩阵;然后再通过注意力权重与V进行计算得到一个权重向量,该权重向量所表示的含义就是在解码时如何将注意力分配到Memory的各个位置上。这一过程我们可以通过如图2-12和图2-13所示的过程来进行表示。
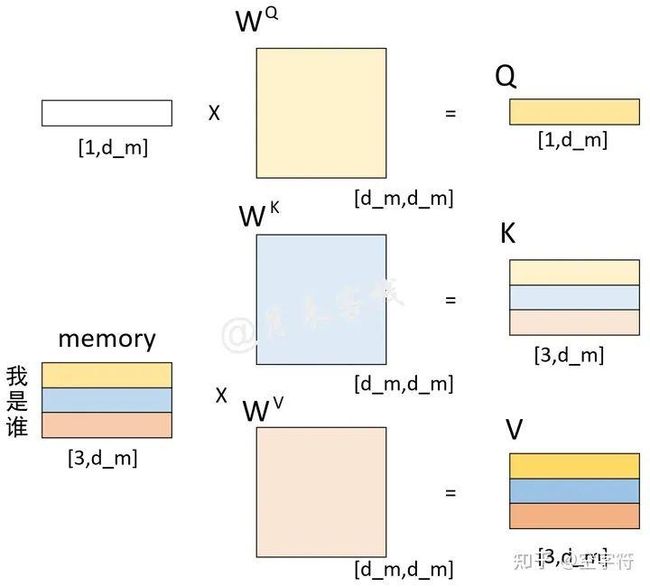
图 2-12. 解码过程Q、K、V计算过程图
如图2-12所示,待解码向量和Memory分别各自乘上一个矩阵后得到Q、K、V。

图 2-13. 解码第1个时刻输出向量计算过程
如图2-13所示,在解码第1个时刻时,首先Q通过与K进行交互得到权重向量,此时可以看做是Q(待解码向量)在K(本质上也就是Memory)中查询Memory中各个位置与Q有关的信息;然后将权重向量与V进行运算得到解码向量,此时这个解码向量可以看作是考虑了Memory中各个位置编码信息的输出向量,也就是说它包含了在解码当前时刻时应该将注意力放在Memory中哪些位置上的信息。
进一步,在得到这个解码向量并经过图2-10中最上面的两层全连接层后,便将其输入到分类层中进行分类得到当前时刻的解码输出值。
2.2.3 Decoder预测解码过程
当第1个时刻的解码过程完成之后,解码器便会将解码第1个时刻时的输入,以及解码第1个时刻后的输出均作为解码器的输入来解码预测第2个时刻的输出。整个过程可以通过如图2-14所示的过程来进行表示。
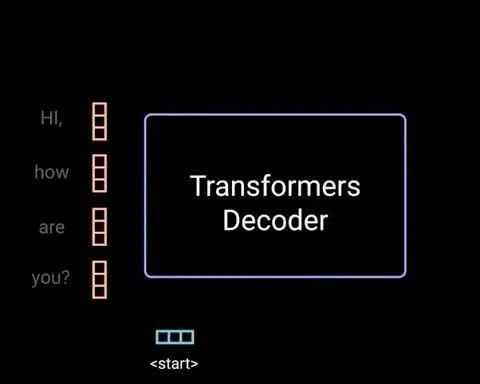
图 2-14. Decoder多时刻解码过程图(图片来自[3])
如图2-14所示,Decoder在对当前时刻进行解码输出时,都会将当前时刻之前所有的预测结果作为输入来对下一个时刻的输出进行预测。假设现在需要将"我 是 谁"翻译成英语"who am i",且解码预测后前两个时刻的结果为"who am",接下来需要对下一时刻的输出"i"进行预测,那么整个过程就可以通过图2-15和图2-16来进行表示。
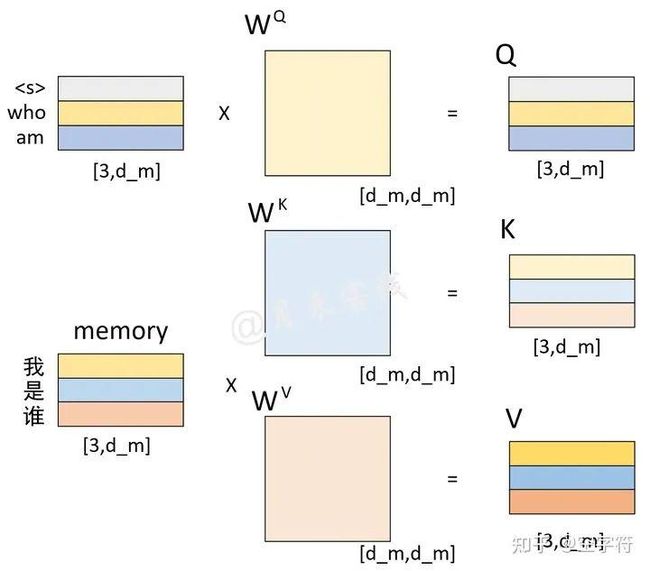
图 2-15. 解码过程中Q、K、V计算过程图
如图2-15所示,左上角的矩阵是解码器对输入" who am"这3个词经过解码器中自注意力机制编码后的结果;左下角是编码器对输入"我 是 谁"这3个词编码后的结果(同图2-12中的一样);两者分别在经过线性变换后便得到了Q、K和V这3个矩阵。此时值得注意的是,左上角矩阵中的每一个向量在经过自注意力机制编码后,每个向量同样也包含了其它位置上的编码信息。
进一步,Q与K作用和便得到了一个权重矩阵;再将其与V进行线性组合便得到了Encoder-Decoder attention部分的输出,如图2-16所示。
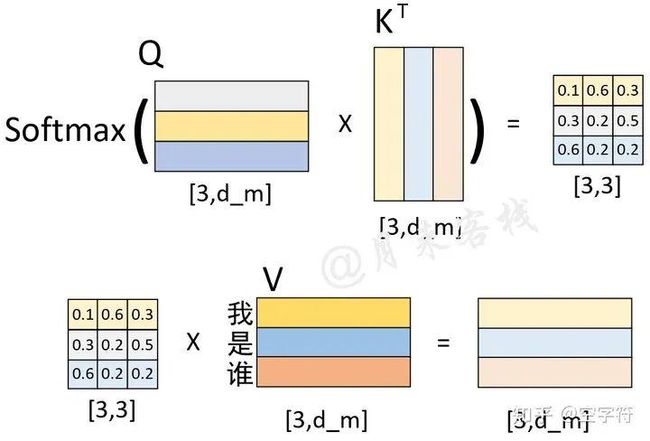
图 2-16. 解码第3个时刻输出向量计算过程
如图2-16所示,左下角便是Q与K作用后的权重矩阵,它的每一行就表示在对Memory(这里指图2-16中的V)中的每一位置进行解码时,应该如何对注意力进行分配。例如第3行的含义就是在解码当前时刻时应该将的注意力放在Memory中的"我"上,其它同理。这样,在经过解码器中的两个全连接层后,便得到了解码器最终的输出结果。接着,解码器会循环对下一个时刻的输出进行解码预测,直到预测结果为"
同时,这里需要注意的是,在通过模型进行实际的预测时,只会取解码器输出的其中一个向量进行分类,然后作为当前时刻的解码输出。例如图2-16中解码器最终会输出一个形状为[3,tgt_vocab_len]的矩阵,那么只会取其最后一个向量喂入到分类器中进行分类得到当前时刻的解码输出。具体细节见后续代码实现。
2.2.4 Decoder训练解码过程
在介绍完预测时Decoder的解码过程后,下面就继续来看在网络在训练过程中是如何进行解码的。从2.2.3小节的内容可以看出,在真实预测时解码器需要将上一个时刻的输出作为下一个时刻解码的输入,然后一个时刻一个时刻的进行解码操作。显然,如果训练时也采用同样的方法那将是十分费时的。因此,在训练过程中,解码器也同编码器一样,一次接收解码时所有时刻的输入进行计算。这样做的好处,一是通过多样本并行计算能够加快网络的训练速度;二是在训练过程中直接喂入解码器正确的结果而不是上一时刻的预测值(因为训练时上一时刻的预测值可能是错误的)能够更好的训练网络。
例如在用平行预料"我 是 谁"<==>"who am i"对网络进行训练时,编码器的输入便是"我 是 谁",而解码器的输入则是" who am i",对应的正确标签则是"who am i
假设现在解码器的输入" who am i"在分别乘上一个矩阵进行线性变换后得到了Q、K、V,且Q与K作用后得到了注意力权重矩阵(此时还未进行softmax操作),如图2-17所示。
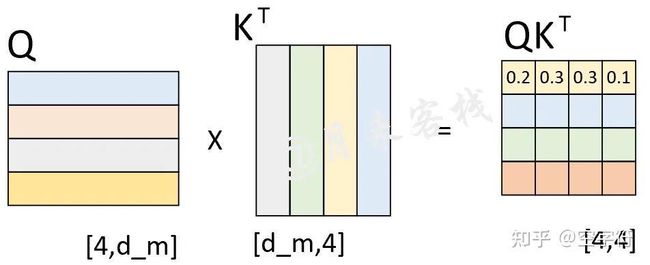
图 2-17. 解码器输入权重矩阵计算过程图
从图2-17可以看出,此时已经计算得到了注意力权重矩阵。由第1行的权重向量可知,在解码第1个时刻时应该将(严格来说应该是经过softmax后的值)的注意力放到""上,的注意力放到"who"上等等。不过此时有一个问题就是,在2.2.3节中笔者介绍到,模型在实际的预测过程中只是将当前时刻之前(包括当前时刻)的所有时刻作为输入来预测下一个时刻,也就是说模型在预测时是看不到当前时刻之后的信息。因此,Transformer中的Decoder通过加入注意力掩码机制来解决了这一问题。
如图2-18所示,左边依旧是通过Q和K计算得到了注意力权重矩阵(此时还未进行softmax操作),而中间的就是所谓的注意力掩码矩阵,两者在相加之后再乘上矩阵V便得到了整个自注意力机制的输出,也就是图2-10中的Masked Multi-Head Attention。
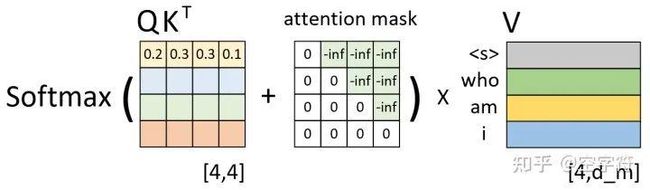
图 2-18. 注意力掩码计算过程图
那为什么注意力权重矩阵加上这个注意力掩码矩阵就能够达到这样的效果呢?以图2-18中第1行权重为例,当解码器对第1个时刻进行解码时其对应的输入只有"",因此这就意味着此时应该将所有的注意力放在第1个位置上(尽管在训练时解码器一次喂入了所有的输入),换句话说也就是第1个位置上的权重应该是1,而其它位置则是0。从图2-17可以看出,第1行注意力向量在加上第1行注意力掩码,再经过softmax操作后便得到了一个类似的向量。那么,通过这个向量就能够保证在解码第1个时刻时只能将注意力放在第1个位置上的特性。同理,在解码后续的时刻也是类似的过程。
到此,对于整个单层Transformer的网络结构以及编码解码过程就介绍完了,更多细节内容见后续代码实现。
2.2.5 位置编码与Attention Mask
在刚接触Transformer的时候,有的人会认为在Decoder中,既然已经有了Attention mask那么为什么还需要Positional Embedding呢?如图2-18所示,持这种观点的朋友认为,Attention mask已经有了使得输入序列依次输入解码器的能力,因此就不再需要Positional Embedding了。这样想对吗?
根据2.2.4节内容的介绍可以知道,Attention mask的作用只有一个,那就是在训练过程中掩盖掉当前时刻之后所有位置上的信息,而这也是在模仿模型在预测时只能看到当前时刻及其之前位置上的信息。因此,持有上述观点的朋友可能是把“能看见”和“能看见且有序”混在一起了。
虽然看似有了Attention mask这个掩码矩阵能够使得Decoder在解码过程中可以有序地看到当前位置之前的所有信息,但是事实上没有Positional Embedding的Attention mask只能做到看到当前位置之前的所有信息,而做不到有序。前者的“有序”指的是喂入解码器中序列的顺序,而后者的“有序”指的是序列本身固有的语序。
如果不加Postional Embedding的话,那么以下序列对于模型来说就是一回事:
→ 北 → 京 → 欢 → 迎 → 你 →
→ 北 → 京 → 迎 → 欢 → 你 →
→ 北 → 京 → 你 → 迎 → 欢 →
虽然此时Attention mask具有能够让上述序列一个时刻一个时刻的按序喂入到解码器中,但是它却无法识别出这句话本身固有的语序。
2.2.6 原始Q、K、V来源
在Transformer中各个部分的Q、K、V到底是怎么来的一直以来都是初学者最大的一个疑问,并且这部分内容在原论文中也没有进行交代,只是交代了如何根据Q、K、V来进行自注意力机制的计算。虽然在第2部分的前面几个小节已经提及过了这部分内容,但是这里再给大家进行一次总结。
根据图2-8(Transformer结构图)可知,在整个Transformer中涉及到自注意力机制的一共有3个部分:Encoder中的Multi-Head Attention;Decoder中的Masked Multi-Head Attention;Encoder和Decoder交互部分的Multi-Head Attention。
① 对于Encoder中的Multi-Head Attention来说,其原始q、k、v均是Encoder的Token输入经过Embedding后的结果。q、k、v分别经过一次线性变换(各自乘以一个权重矩阵)后得到了Q、K、V(也就是图1-4中的示例),然后再进行自注意力运算得到Encoder部分的输出结果Memory。
② 对于Decoder中的Masked Multi-Head Attention来说,其原始q、k、v均是Decoder的Token输入经过Embedding后的结果。q、k、v分别经过一次线性变换后得到了Q、K、V,然后再进行自注意力运算得到Masked Multi-Head Attention部分的输出结果,即待解码向量。
对于Encoder和Decoder交互部分的Multi-Head Attention,其原始q、k、v分别是上面的带解码向量、Memory和Memory。q、k、v分别经过一次线性变换后得到了Q、K、V(也就是图2-12中的示例),然后再进行自注意力运算得到Decoder部分的输出结果。之所以这样设计也是在模仿传统Encoder-Decoder网络模型的解码过程。
3. 网络结构与自注意力实现
在通过前面几部分内容详细介绍完Transformer网络结构的原理后,接下来就让我们来看一看如何借用Pytorch框架来实现MultiHeadAttention这一结构。同时,需要说明的一点是,下面所有的实现代码都是笔者直接从Pytorch 1.4版本中torch.nn.Transformer模块里摘取出来的简略版,目的就是为了让大家对于整个实现过程有一个清晰的认识。并且为了使得大家在阅读完以下内容后也能够对Pytorch中的相关模块有一定的了解,所以下面的代码在变量名方面也与Pytorch保持了一致。
3.1 多层Transformer
在第2部分中,笔者详细介绍了单层Transformer网络结构中的各个组成部分。尽管多层Transformer就是在此基础上堆叠而来,不过笔者认为还是有必要在这里稍微提及一下。

图 3-1. 单层Transformer网络结构图
如图3-1所示便是一个单层Transformer网络结构图,左边是编码器右边是解码器。而多层的Transformer网络就是在两边分别堆叠了多个编码器和解码器的网络模型,如图3-2所示。
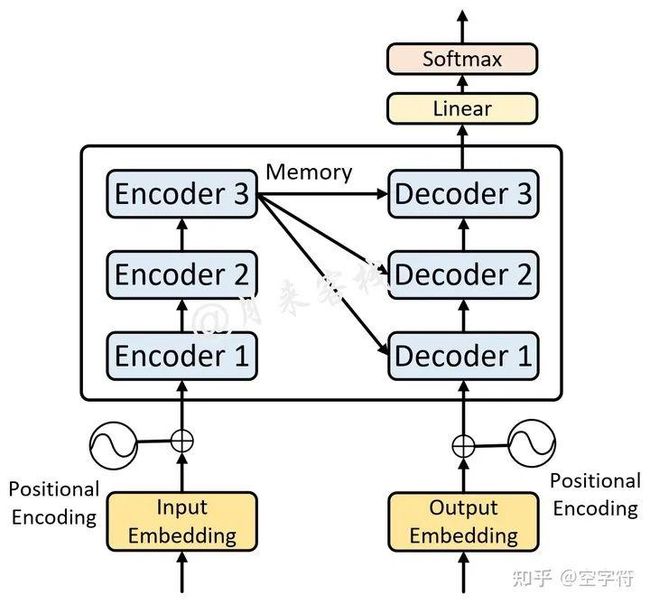
图 3-2. 多层Transformer网络结构图
如图3-2所示便是一个多层的Transformer网络结构图(原论文中采用了6个编码器和6个解码器),其中的每一个Encoder都是图3-1中左边所示的网络结构(Decoder同理)。可以发现,它真的就是图3-1堆叠后的形式。不过需要注意的是其整个解码过程。
在多层Transformer中,多层编码器先对输入序列进行编码,然后得到最后一个Encoder的输出Memory;解码器先通过Masked Multi-Head Attention对输入序列进行编码,然后将输出结果同Memory通过Encoder-Decoder Attention后得到第1层解码器的输出;接着再将第1层Decoder的输出通过Masked Multi-Head Attention进行编码,最后再将编码后的结果同Memory通过Encoder-Decoder Attention后得到第2层解码器的输出,以此类推得到最后一个Decoder的输出。
值得注意的是,在多层Transformer的解码过程中,每一个Decoder在Encoder-Decoder Attention中所使用的Memory均是同一个。
3.2 Transformer中的掩码
由于在实现多头注意力时需要考虑到各种情况下的掩码,因此在这里需要先对这部分内容进行介绍。在Transformer中,主要有两个地方会用到掩码这一机制。第1个地方就是在2.2.4节中介绍到的Attention Mask,用于在训练过程中解码的时候掩盖掉当前时刻之后的信息;第2个地方便是对一个batch中不同长度的序列在Padding到相同长度后,对Padding部分的信息进行掩盖。下面分别就这两种情况进行介绍。
3.2.1 Attention Mask
如图3-3所示,在训练过程中对于每一个样本来说都需要这样一个对称矩阵来掩盖掉当前时刻之后所有位置的信息。
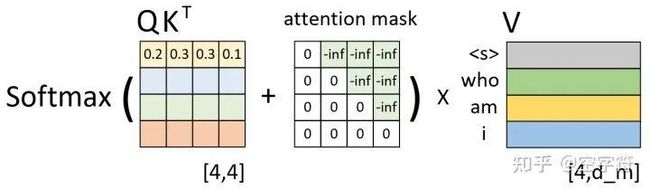
图 3-3. 注意力掩码计算过程图
从图3-3可以看出,这个注意力掩码矩阵的形状为[tgt_len,tgt_len],其具体Mask原理在2.2.4节中笔者已经介绍过l,这里就不再赘述。在后续实现过程中,我们将通过generate_square_subsequent_mask方法来生成这样一个矩阵。同时,在后续多头注意力机制实现中,将通过attn_mask这一变量名来指代这个矩阵。
3.2.2 Padding Mask
在Transformer中,使用到掩码的第2个地方便是Padding Mask。由于在网络的训练过程中同一个batch会包含有多个文本序列,而不同的序列长度并不一致。因此在数据集的生成过程中,就需要将同一个batch中的序列Padding到相同的长度。但是,这样就会导致在注意力的计算过程中会考虑到Padding位置上的信息。
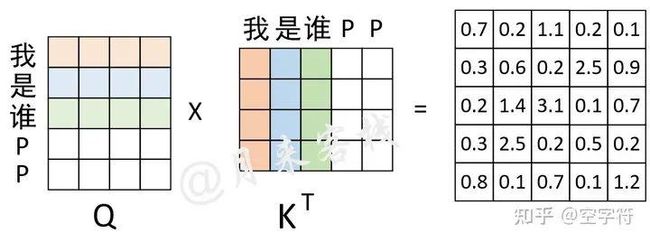
图 3-4. Padding时注意力计算过程图
如图3-4所示,P表示Padding的位置,右边的矩阵表示计算得到的注意力权重矩阵。可以看到,此时的注意力权重对于Padding位置山的信息也会加以考虑。因此在Transformer中,作者通过在生成训练集的过程中记录下每个样本Padding的实际位置;然后再将注意力权重矩阵中对应位置的权重替换成负无穷,经softmax操作后对应Padding位置上的权重就变成了0,从而达到了忽略Padding位置信息的目的。这种做法也是Encoder-Decoder网络结构中通用的一种办法。

图 3-5. Padding掩码计算过程图
如图3-5所示,对于"我 是 谁 P P"这个序列来说,前3个字符是正常的,后2个字符是Padding后的结果。因此,其Mask向量便为[True, True, True, False, False]。通过这个Mask向量可知,需要将权重矩阵的最后两列替换成负无穷,在后续我们会通过torch.masked_fill这个方法来完成这一步,并且在实现时将使用key_padding_mask来指代这一向量。
到此,对于Transformer中所要用到Mask的地方就介绍完了,下面正式来看如何实现多头注意力机制。
3.3 实现多头注意力机制
3.3.1 多头注意力机制
根据前面的介绍可以知道,多头注意力机制中最为重要的就是自注意力机制,也就是需要前计算得到Q、K和V,如图3-6所示。
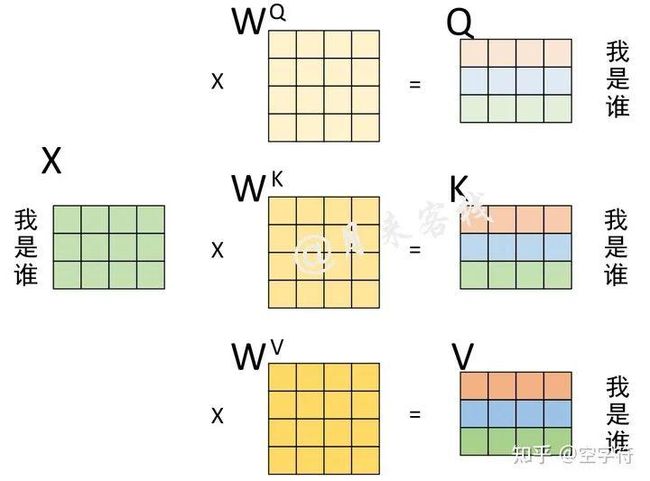
图 3-6. Q、K和V计算过程
然后再根据Q、K、V来计算得到最终的注意力编码,如图3-7所示:
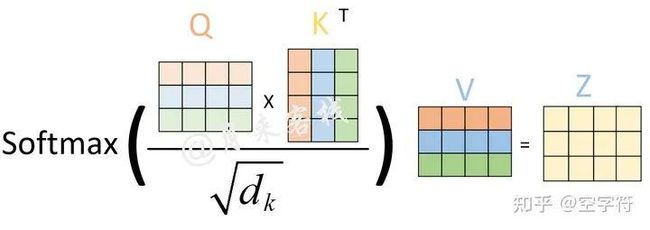
图 3-7. 注意力编码计算图
同时,为了避免单个自注意力机制计算得到的注意力权重过度集中于当前编码位置自己所在的位置(同时更应该关注于其它位置),所以作者在论文中提到通过采用多头注意力机制来解决这一问题,如图3-8所示。

图 3-8. 多头注意力计算图(2个头)
transformxl
1.训练长度固定,导致长文本需要分段训练,导致上下文割裂碎片化
2.模型训练好做inference时候,需要序列计算结果(后一个依赖于前一个生成结果)很费时
Transformer结构第一次提出来是用于机器翻译任务,提出后自然有个想法:「Transformer结构能不能用于训练语言模型?」 答案是肯定的。RNN、LSTM等网络结构训练语言模型的最大缺点在于容易梯度消失,难以学习长期依赖,但是Transformer没有合格缺点,因为它没有沿时间线进行横向传播的过程,这样来说,Transformer很适合训练语言模型。
怎么训练?很简单,举个例子,假如现在我们有一句话包含100个token,在预测第一个token的时候,我们把其它的99个token进行attention mask掉,只输入一个开始标记,让模型预测第一个token;在预测第二个token的时候,把剩下的98个token attention mask掉,只让模型看见开始标记和第一个token;在预测第三个token的时候,把剩下的97个token attention mask掉,只让模型看见开始标记和前两个token。。。损失函数为真实token和预测token的交叉熵,这样模型不断学习,不断更新参数,就训练得到一个语言模型了。
想想这样有个什么问题?问题就是真实的文本可没有只包含100个token这么少。举个例子,假设我现在手头有个文章是包含4000个token的,那我就要把这4000个token都作为输入,原理上可以这么做,但实际上,输入的token很多的情况下,中间层attention的计算资源会爆炸。
Vanilla Transformer的做法是「切片」,如把4000个token切成8段,每段包含500个token,再对每段进行独立的训练,也即在第二段训练的时候,是看不到第一段的信息的,这样导致的问题就是「上下文碎片问题(context fragmentation problem)」,由于切片长度限制,模型并不能学习到足够常的依赖信息,这样会大大损害学习出来的语言模型的性能。
在评估时,为了能利用训练时的最长上下文信息,是每个时间步向右移动一个token,导致的结构是评估耗费的计算资源很大。
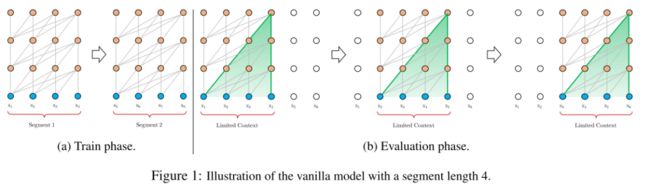
改进点
「改进点一:循环机制」
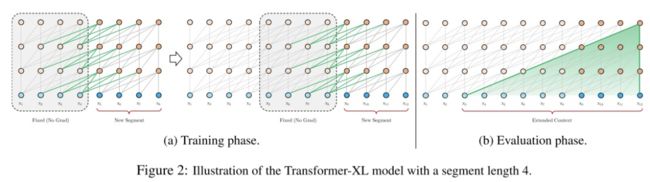
在计算每个segment的时候,通过缓存上一个segment的信息,把前面segment的信息也考虑进正向传播过程中(上一个segment的信息虽然参与正向传播,但上一个segment是不会参与反向传播的)。具体的看,下面的式子,
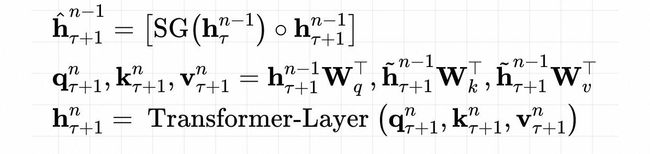
这里的 指的是Transformer第n-1层的第 个segmetn的Encoder的输出,把它与Transformer第n层的第 的encoder的输出沿着时间轴拼接在一起,SG表示stop-gradient,即前一个segmetn的信息只参与正向传播,并不会用到反向传。另外,在计算查询矩阵q时,只会用当前segmetn来计算得到;只有在计算键值向量时,才会用到拼接的segmetn向量。
这样的做法,能大大缓解上下文碎片的问题,举个例子,假设Transformer的encoder一共有4层,每个segment为500个token。根据循环机制的原理,第4层的第 T 个segmetn的输出不仅考虑了第三层encoder的第 T个encoder的输出,也考虑了第T-1 个encdoer的输出,而第 T-1 个encdoer的输出,不仅考虑了第二层encoder的第 T-1个encdoer的输出,也考虑了第 T-2 个encdoer的输出,也即,上下文的最大依赖长度是线性增加的,如O(N*L),如这里所说的例子,虽然,一个segmetn是500个token,但其实在最后输出时,足足考虑了4 * 500 = 2000个token这么多!上下文碎片的问题也就自然得到了大大的缓解了。
另外,在评估时,由于采用了循环机制,我们就不必每次只向右移动一步了,而且可以采用同训练时候差不多的片段机制,从而大大提高了评估效率。
「改进点二:相对位置编码」
上面所说的循环机制还有个问题待解决,就是位置编码,我们知道,原生的Transformer使用的是绝对位置编码,但绝对位置编码跟循环机制结合会导致一个问题,举个例子,我们在计算第 T的输出时,不仅考虑了第 T个片段的输入,还考虑了第 T-1个片段的输入,假设我们采用绝对位置编码,那第 T个片段和 T-1个片段的第1个token的位置编码是一样的,但这是明显的不合理的。因此,作者提出了一种相对位置编码的思想。
具体的,原生的绝对位置编码在计算attention时,如下式所示,
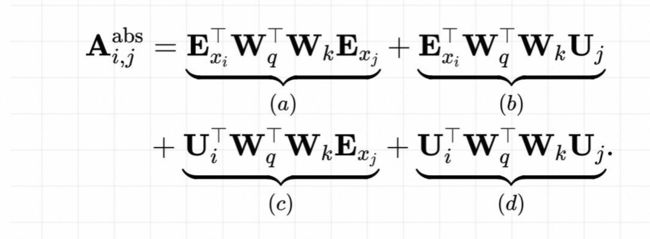
采用相对位置编码,
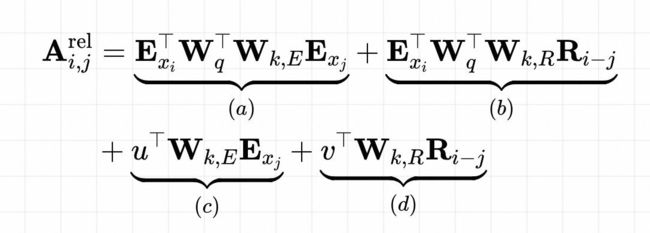

通常这样的变换,上面的每一项都有其相应的意义
(a)项为基于内容的寻址;
(b)项为基于内容的位置偏置;
(c)项为全局的内容偏置;
(d)为全局的位置偏置。
把循环机制和相对位置编码的信息合并后,Transformer-XL的最终形态
swith-Transform
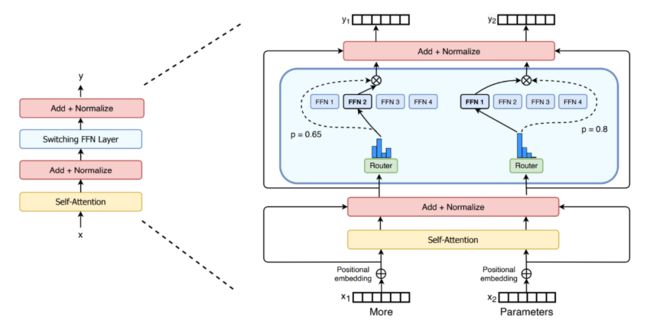
相比起 Sparse Attention 需要用到稀疏算子而很难发挥 GPU、TPU 硬件性能的问题。Switch Transformer 不需要稀疏算子,可以更好的适应 GPU、TPU 等稠密硬件。主要的想法是简化稀疏路由。
即在自然语言 MoE (Mixture of experts)层中,只将 token 表征发送给单个专家而不是多个的表现会更好。模型架构如上图,中间蓝色部分是比价关键的部分,可以看到每次 router 都只把信息传给分数 p 最大的单个 FFN。而这个操作可以大大降低计算量。
然后另一方面,其成功的原因是有一个很秀的并行策略,其同时结合了数据并行 + 模型并行 + expert 并行。具体如下图:

其实对应模型架构来看,experts 并行是算子间的并行,其对应的 FFN 内部有算子级的模型并行,而整个 experts 在计算图上又是个多并行 FFN 分支,这是算子间模型并行,所以能够获得更低的通信开销,提高并行的效率。
大模型当前主流架构
bert系列
Bert模型是在2018年由Google在《Pre-training of Deep Bidirectional Transformers for Language Understanding(2018)》一文中提出。(关于更详细的Bert模型介绍,可以查看张张旧文“深度学习基础算法系列(24)- Bert原理和结构详解”)
在Bert模型的基础上,有很多针对Bert的改进模型,这里介绍几种常见的改进模型。
(1)RoBERTa
RoBERTa是2019年在《 A Robustly Optimized BERT Pretraining Approach(2019)》一文中提出,在该文中细致的对Bert模型的训练方式进行了对比实验和分析,并基于此总结出了能够提升Bert效果的训练方法,主要包括以下几个方面:动态mask机制、移除了NSP任务、batch size更大、训练时间更长、训练数据更多、训练序列更长。
(2)ALBERT
ALBERT是在2020年《A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS(2020)》一文中提出,主要提出了一个轻量级的Bert模型,以此降低Bert的运行开销。为了减少Bert资源开销,该文主要提出了两个优化:Factorized embedding parameterization以及Cross-layer parameter sharing。其中Factorized embedding parameterization将嵌入矩阵分解为两个小的矩阵,Cross-layer parameter sharing是让跨ALBERT的每一层共享transformer权重,这将显着著减少参数。除了上述两个降低Bert运行开销的优化外,ALBERT提出了inter-senetnce loss这一新的优化目标。
(3)ELECTRA
ELECTRA是在2020年《PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS(ICLR 2020)》一文中提出,该方法的核心思路采用了GAN的思路。模型包括一个generator生成器 和一个discriminator判别器。生成器通常是一个小的MLM,可以学习预测被mask token的原始单词。 判别器被训练以鉴别输入token是否被生成器替换。通过对抗学习的方式,让模型从文本中提取信息的能力增强。
(4)ERNIE(THU)
清华版的ERNIE(THU),把知识图谱的信息整合进pre-train 的过程中,具体地,对于文本中的实体,在知识库中找到对应的entity,利用 transE 来进行表示之后,在 BERT 的 text encoder 之上再加一层 knowledge encoder。文章主要的 contribution 就在于想到把 KG 融合到预训练 language model 的过程中去。
(5)ERNIE(Baidu)
百度版的ERNIE(Baidu),重点在mask 的 level 上对中文文本做了调整,英文 mask 单词是很直接的想法,而中文的处理一般是以词为单位,因此会有 phrase mask 以及 entity mask,例如人名、地名的 mask。通过添加两种 mask 机制,来让 language model 隐式地学习到 entity 之间的关联。 比较有趣的一点是,作者还在 Pre-train 中加入了 Dialogue 语料,结果显示效果也会有一些提高。这指明了一个方向,在预训练阶段,除了修改模型、目标函数以外,选择高质量、特定 domain 的语料也是可行的方向。
Bert、GPT融合改进模型
基于Bert和GPT模型,后续研究者们又提出了很多改进模型,这里主要介绍UniLM、XLNet、BART这3种。
(1)UniLM
UniLM 是2019年在《Unified Language Model Pre-training for Natural Language Understanding and Generation(NIPS 2019)》一文中提出,融合了EMLo、BERT、GPT3种语言模型优化目标,通过精巧的控制mask方式在一个模型中同时实现了3种语言模型优化任务,在pretrain过程交替使用3种优化目标。下图比较形象的描述了UniLM是如何利用mask机制来控制3种不同的优化任务,核心思路是利用mask控制生成每个token时考虑哪些上下文的信息。
(2)XLNet
XLNet是2019年在《Generalized Autoregressive Pretraining for Language Understanding(NIPS 2019)》一文中提出,文中将无监督语言模型分成两类,一类是AR自回归模型,如GPT、ELMo这种使用单向语言模型建模概率分布的方法;另一类是AE自编码模型,如BERT这种通过预测句子中token的方法。XLNet融合了AR模型和AE模型各自的优点,既能建模概率密度,适用于文本生成类任务,又能充分使用双向上下文信息。XLNet实现AR和AE融合的主要思路为,对输入文本进行排列组合,然后对于每个排列组合使用AR的方式训练,不同排列组合使每个token都能和其他token进行信息交互,同时每次训练又都是AR的。
(3)BART
BART是2019年在《 Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension(2019)》一文中提出,其包括两个阶段:首先原文本使用某种noise function进行破坏,然后使用sequence-to-sequence模型还原原始的输入文本。下图中左侧为Bert的训练方式,中间为GPT的训练方式,右侧为BART的训练方式。首先,将原始输入文本使用某些noise function,得到被破坏的文本。这个文本会输入到类似Bert的Encoder中。在得到被破坏文本的编码后,使用一个类似GPT的结构,采用自回归的方式还原出被破坏之前的文本。
Gpt1到chatgpt技术演进路线
Generative Pre-trained Transformer(GPT)系列是由OpenAI提出的非常强大的预训练语言模型,这一系列的模型可以在非常复杂的NLP任务中取得非常惊艳的效果,例如文章生成,代码生成,机器翻译,Q&A等,而完成这些任务并不需要有监督学习进行模型微调。而对于一个新的任务,GPT仅仅需要非常少的数据便可以理解这个任务的需求并达到接近或者超过state-of-the-art的方法。
当然,如此强大的功能并不是一个简单的模型能搞定的,GPT模型的训练需要超大的训练语料,超多的模型参数以及超强的计算资源。GPT系列的模型结构秉承了不断堆叠transformer的思想,通过不断的提升训练语料的规模和质量,提升网络的参数数量来完成GPT系列的迭代更新的。GPT也证明了,通过不断的提升模型容量和语料规模,模型的能力是可以不断提升的。
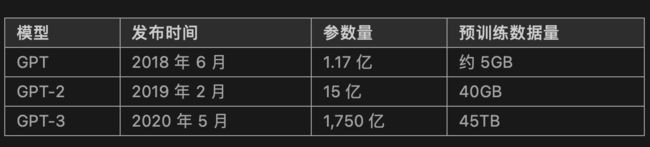
这篇文章会依次介绍GPT-1[1],GPT-2[2],GPT-3[3],并介绍它们基于上个版本的改进点,文章主要的介绍的包括四个主要方向:算法的思想和目标,使用的数据集和预处理方式,模型结构以及算法的性能。
1. GPT-1:无监督学习
在GPT-1之前(和ELMo同一年),传统的NLP模型往往使用大量的数据对有监督的模型进行任务相关的模型训练,但是这种有监督学习的任务存在两个缺点:
需要大量的标注数据,高质量的标注数据往往很难获得,因为在很多任务中,图像的标签并不是唯一的或者实例标签并不存在明确的边界;
根据一个任务训练的模型很难泛化到其它任务中,这个模型只能叫做“领域专家”而不是真正的理解了NLP。
这里介绍的GPT-1的思想是先通过在无标签的数据上学习一个通用的语言模型,然后再根据特定热任务进行微调,处理的有监督任务包括
自然语言推理(Natural Language Inference 或者 Textual Entailment):判断两个句子是包含关系(entailment),矛盾关系(contradiction),或者中立关系(neutral);
问答和常识推理(Question answering and commonsense reasoning):类似于多选题,输入一个文章,一个问题以及若干个候选答案,输出为每个答案的预测概率;
语义相似度(Semantic Similarity):判断两个句子是否语义上市是相关的;
分类(Classification):判断输入文本是指定的哪个类别。
将无监督学习左右有监督模型的预训练目标,因此叫做通用预训练(Generative Pre-training,GPT)。


1.1.3 任务相关的输入变换
在第1节的时候,我们介绍了GPT-1处理的4个不同的任务,这些任务有的只有一个输入,有的则有多组形式的输入。对于不同的输入,GPT-1有不同的处理方式,具体介绍如下:
分类任务:将起始和终止token加入到原始序列两端,输入transformer中得到特征向量,最后经过一个全连接得到预测的概率分布;
自然语言推理:将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开,两端加上起始和终止token。再依次通过transformer和全连接得到预测结果;
语义相似度:输入的两个句子,正向和反向各拼接一次,然后分别输入给transformer,得到的特征向量拼接后再送给全连接得到预测结果;
问答和常识推理:将
个选项的问题抽象化为
个二分类问题,即每个选项分别和内容进行拼接,然后各送入transformer和全连接中,最后选择置信度最高的作为预测结果。
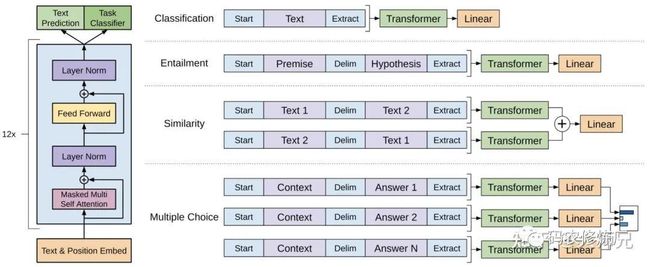
图2:(左):transformer的基本结构,(右):GPT-1应用到不同任务上输入数据的变换方式
1.2 GPT-1的数据集
GPT-1使用了BooksCorpus数据集[7],这个数据集包含本没有发布的书籍。作者选这个数据集的原因有二:1. 数据集拥有更长的上下文依赖关系,使得模型能学得更长期的依赖关系;2. 这些书籍因为没有发布,所以很难在下游数据集上见到,更能验证模型的泛化能力。
1.3 网络结构的细节
GPT-1使用了12层的transformer,使用了掩码自注意力头,掩码的使用使模型看不见未来的信息,得到的模型泛化能力更强。

1.4 GPT-1的性能
在有监督学习的12个任务中,GPT-1在9个任务上的表现超过了state-of-the-art的模型。在没有见过数据的zero-shot任务中,GPT-1的模型要比基于LSTM的模型稳定,且随着训练次数的增加,GPT-1的性能也逐渐提升,表明GPT-1有非常强的泛化能力,能够用到和有监督任务无关的其它NLP任务中。GPT-1证明了transformer对学习词向量的强大能力,在GPT-1得到的词向量基础上进行下游任务的学习,能够让下游任务取得更好的泛化能力。对于下游任务的训练,GPT-1往往只需要简单的微调便能取得非常好的效果。
GPT-1在未经微调的任务上虽然也有一定效果,但是其泛化能力远远低于经过微调的有监督任务,说明了GPT-1只是一个简单的领域专家,而非通用的语言学家。
2. GPT-2:多任务学习
GPT-2的目标旨在训练一个泛化能力更强的词向量模型,它并没有对GPT-1的网络进行过多的结构的创新与设计,只是使用了更多的网络参数和更大的数据集。下面我们对GPT-2展开详细的介绍。
2.1 GPT-2的核心思想
GPT-2的学习目标是使用无监督的预训练模型做有监督的任务。因为文本数据的时序性,一个输出序列可以表示为一系列条件概率的乘积:


GPT-2训练了4组不同的层数和词向量的长度的模型,具体值见表2。通过这4个模型的实验结果我们可以看出随着模型的增大,模型的效果是不断提升的。


3. GPT-3:海量参数
截止编写此文前,GPT-3是目前最强大的语言模型,仅仅需要zero-shot或者few-shot,GPT-3就可以在下游任务表现的非常好。除了几个常见的NLP任务,GPT-3还在很多非常困难的任务上也有惊艳的表现,例如撰写人类难以判别的文章,甚至编写SQL查询语句,React或者JavaScript代码等。而这些强大能力的能力则依赖于GPT-3疯狂的1750亿的参数量,45TB的训练数据以及高达1200万美元的训练费用。
3.1 In-context learning
In-context learning是这篇论文中介绍的一个重要概念,要理解in-context learning,我们需要先理解meta-learning(元学习)[9, 10]。对于一个少样本的任务来说,模型的初始化值非常重要,从一个好的初始化值作为起点,模型能够尽快收敛,使得到的结果非常快的逼近全局最优解。元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
这里的介绍使用的是MAML(Model-Agnostic Meta-Learning)算法[10],正常的监督学习是将一个批次的数据打包成一个batch进行学习。但是元学习是将一个个任务打包成batch,每个batch分为支持集(support set)和质询集(query set),类似于学习任务中的训练集和测试集。

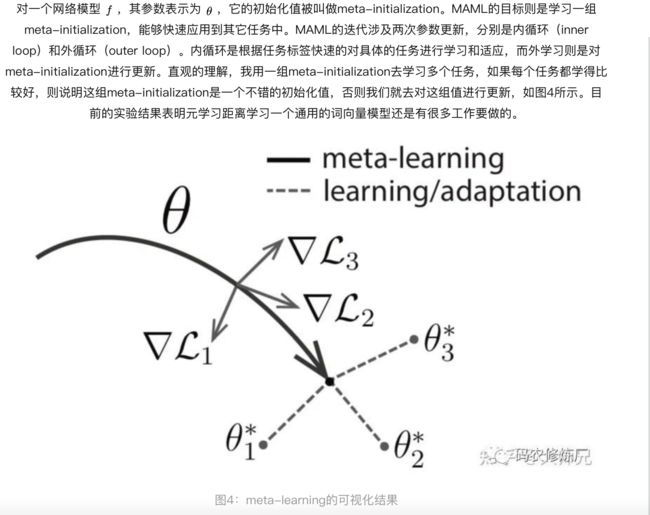
而GPT-3中据介绍的in-context learning(情境学习)则是元学习的内循环,而基于语言模型的SGT则是外循环,如图5所示。
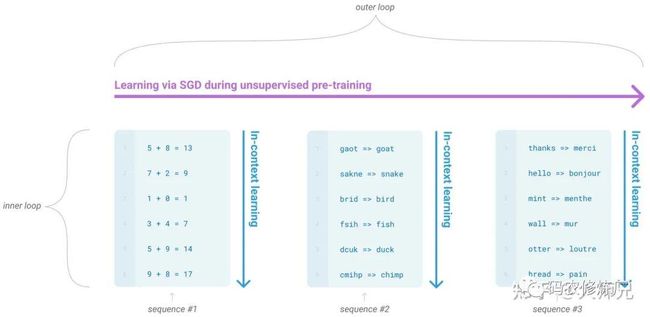
而另外一个方向则是提供容量足够大的transformer模型来对语言模型进行建模。而近年来使用大规模的网络来训练语言模型也成为了非常行之有效的策略(图6),这也促使GPT-3一口气将模型参数提高到1750亿个。
3.2 Few-shot,one-shot,zero-shot learning
在few-shot learning中,提供若干个(10-100个)示例和任务描述供模型学习。one-shot laerning是提供1个示例和任务描述。zero-shot则是不提供示例,只是在测试时提供任务相关的具体描述。作者对这3种学习方式分别进行了实验,实验结果表明,三个学习方式的效果都会随着模型容量的上升而上升,且few shot > one shot > zero show。
从理论上讲GPT-3也是支持fine-tuning的,但是fine-tuning需要利用海量的标注数据进行训练才能获得比较好的效果,但是这样也会造成对其它未训练过的任务上表现差,所以GPT-3并没有尝试fine-tuning。
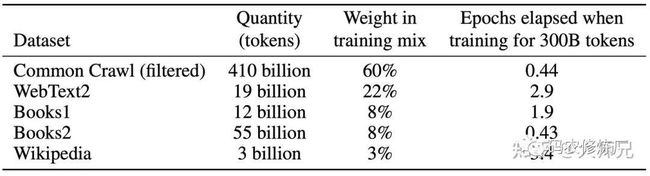
3.3 数据集
GPT-3共训练了5个不同的语料,分别是低质量的Common Crawl,高质量的WebText2,Books1,Books2和Wikipedia,GPT-3根据数据集的不同的质量赋予了不同的权值,权值越高的在训练的时候越容易抽样到,如表1所示。


InstrucGPT
论文名称:Training language models to follow instructions with human feedback
论文地址:https://arxiv.org/pdf/2203.02155.pdf
模型结构:
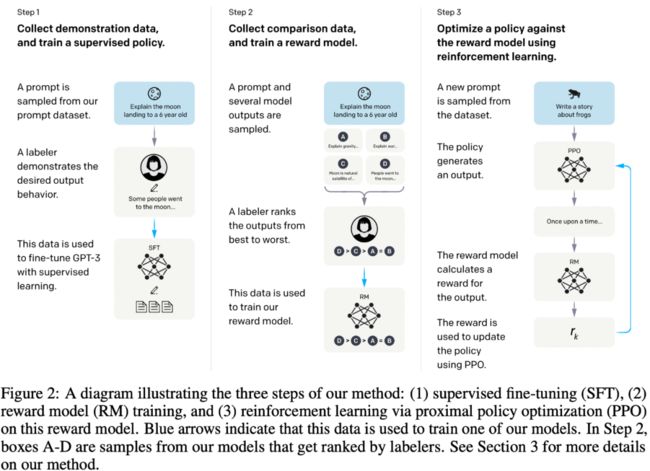
图9: Instruct GPT框架。
由于 GPT 3.0 会生成一些不真实、带攻击歧视的答案。GPT 团队主要认为问题源于数据不行。因此,
第一步:他们雇佣了一个 40 个人的团队,针对 prompt,写一些高质量的答案来 finetune GPT 3.0
第二步:采集来自不同模型的答案,同样由标注团队来选择他们的顺序。以此来训练一个 reward model
第三步:GPT 3.0 与 reward model 采取强化学习的策略迭代优化。
最终,Instruct GPT 相对于 GPT 3 生成的答案更为真实、准确。
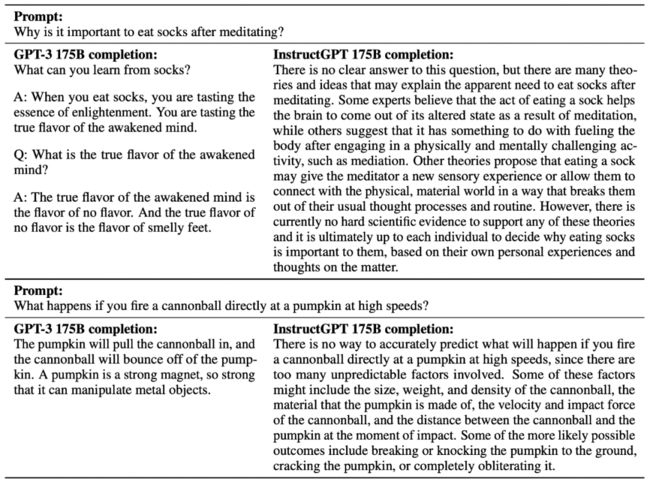
图 10, GPT 3 与 Instruct GPT 答案对比。
T5系列演进路线
T5全称是Text-to-Text Transfer Transformer,是一种模型架构或者说是一种解决NLP任务的一种范式。
如下图,就是把所有任务,如分类、相似度计算、文本生成都用一个Text-to-text(文本到文本)的框架里进行解决。

举个例子,现在要做一个英文转德文的机器翻译任务,输入"translate English to German: That is good.",目标输出是"Das ist gut.",再举个例子,现在做一个文本三分类任务,label为【entailment、contradiction、neutral】,输入""mnli premise: I hate pigeons. hypothesis: My feelings towards pigeons are filled with animosity.",目标输出是"entailment",注意哦,都是用"生成"的方式得到输出类(可以理解成sequence to sequence)。
这样的好处是可以把所有的问题都套进去一个统一的范式,从而可以采用同样的模型架构、同样的训练策略、同样的损失函数、同样的解码手段。
T5模型采用Transformer的encoder-decoder结构,之前介绍过GPT采用的是Transformer的decoder结构。
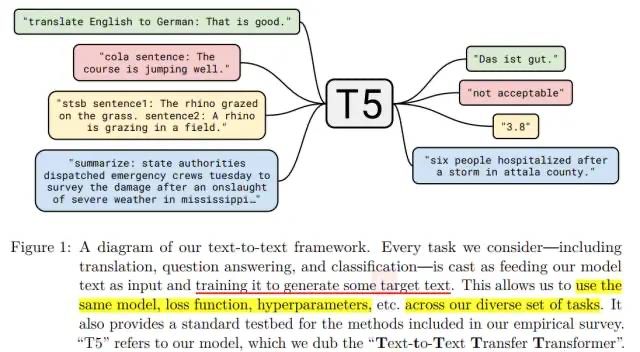
如图所示,T5(Text-to-Text Transfer Transformer)模型将翻译、分类、回归、摘要生成等任务都统一转成Text-to-Text任务,从而使得这些任务在训练(pre-train和fine-tune)时能够使用相同的目标函数,在测试时也能使用相同的解码过程。 注意这里回归任务对应的浮点数会被转成字符串看待,从而可以token by token的预测出来。虽然感觉奇怪,but anyway, it works。
T5模型采用Transformer的encoder-decoder结构,之前介绍过GPT采用的是Transformer的decoder结构。
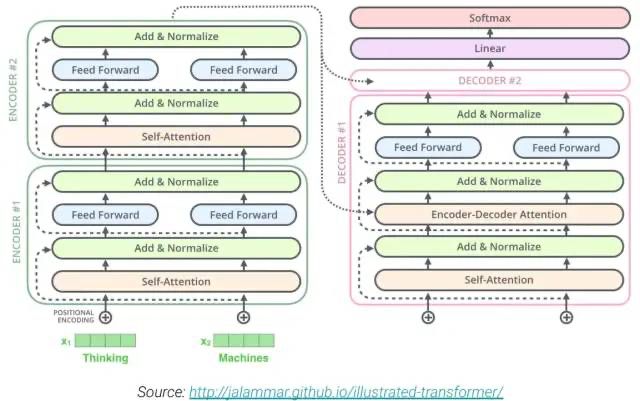
T5模型和原始的Transformer结构基本一致,除了做了如下几点改动:
remove the Layer Norm bias
place the Layer Normalization outside the residual path
use a different position embedding
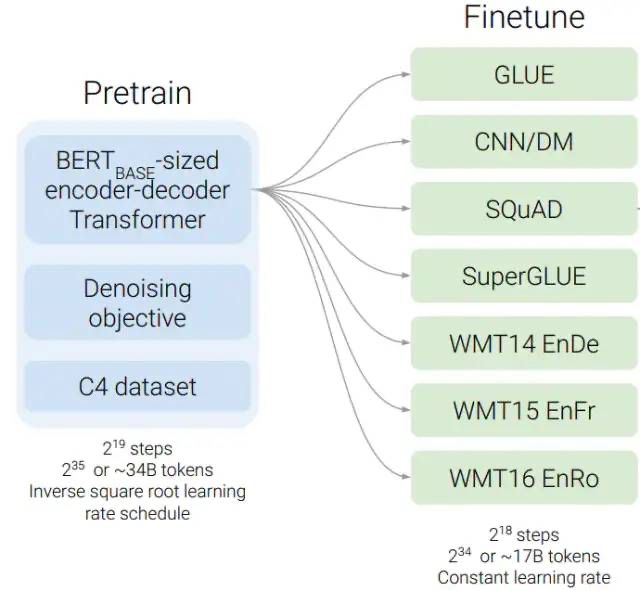
在下游任务上fine-tune,通过对各种对比实验的结果进行分析,作者最终确定了训练T5模型的较优方案,其中以下几点值得注意:
无监督训练目标:采用span-corruption目标,类似SpanBERT的做法。
预训练策略:采用multi-task预训练方式(即无监督任务和有监督任务一起预训练),在对比迁移方法一小节中我们发现Multi-task pretraining + fine-tuning的效果和Unsupervised pre-training + fine-tuning的效果差不多,但是前者在预训练过程还能够监控下游任务的性能,因此作者最后采用Multi-task pre-training。
Transformer architecture variants
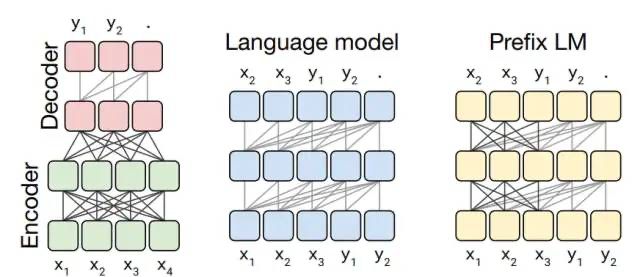
如图所示为Transformer结构的几种变种,主要区别在于模型中self-attention机制的可见范围。
fully-visible attention mask:输出序列的每个元素可以看见输入序列的每个元素。
causal attention mask:输出序列的每个元素只能看对应位置及之前的输入序列的元素,无法看见未来的元素。
causal with prefix attention mask:输入序列的一部分前缀采用fully-visible attention mask,其余部分采用 causal attention mask。
在最左侧的Encoder-Decoder结构中,Encoder部分采用fully-visible attention mask,而Decoder部分采用causal attention mask。
中间的Language model结构中,采用causal attention mask。
最右侧的Prefix LM结构中,采用causal with prefix attention mask。比如在翻译任务中,给定训练样本translate English to German: That is good. target: Das ist gut.,我们对translate English to German: That is good. target:采用fully-visible attention mask,对Das ist gut.采用causal attention mask。
transformer和GPT、BERT、T5上层模型之间的关系
前面章节已经详细介绍了Transformer的结构,包括了ENcode和Decode两大部分。同时也介绍了为了加快traning速度transformer模型增加了OutputEmbedding输入头+attentionMask来实现前向学习能力。所以可以看到transfomer可以作为一个很好的自监督、无监督的知识萃取器。实际上后续的更重大模型也就是如此操作。首先用transfomer架构批量的学习现有语料的得到一个强大的表现力极强的底座模型,你可以把这个阶段理解为一个人还没有出来做事前的博览群书增能力过程。然后又了一个底座模型后,用这个强大的底座模型在下游任务上做简单结构改造做finetune,你可以把这个过程看成是就事锻炼增强自己实际解决问题能力;要能够成功这是有前提的,就是你得有足够知识量(也就是pretraning底座模型要够强。至于后续出现的prompt、自动prompt、以及instruct和cot,其实都是fintune之后的或者平级事情,也就是既然这个底座模型如此博览群书牛逼无敌,那是否可以直接拿来用(zeroshot)或者我简单给他几个例子(fewshot)就可以为我所用,尽量减少finetune阶段出了学校还要经过公司实习半年一年的实习时间也是浪费,直接为我所用就好了。为了达到这个目的,就出现了prompt(在学校时候就让他按公司模式学习,或者出公司前有个懂学习校那套语言的人做工作-学校指令转换),这个既要懂学校又要懂公司的人太少了所以人工prompt太难了,有没办法有个自动翻译机器所以出现自动prompt阶段。最后一个就到了instruct阶段,这个底座这么牛逼翻译过来就是这个学校科研能力这么强,有没办法我们产学研结合:你学校负责研发就好负责底座牛逼就行,我们公司层面和你多交互给你时不时下一些指令instruct,经过这么个上下游一体化有反馈的结合就可以让学校科研为我所用,听懂人话了。对于一些复杂的任务如果只在一次研发任务很难一次性搞透,有没办法对任务拆解逐步推进得到更好效果,这对应的技术的技术就是Cot(思维链)其实个人觉得这部分更多是在训练数据上和工程链路上做文章,模型架构本身基本没变化。
Gpt,gpt2,gpt3,bert,roberta,t5模型区别分析
只有decoder:
这些模型也称为双向或自动编码,仅在预训练期间使用编码器,这通常是通过屏蔽输入句子中的单词并训练模型进行重构来完成的。在预训练的每个阶段,注意力层都可以访问所有输入词。该系列模型最适用于需要理解完整句子的任务,例如句子分类或提取式问答。
GPT:仅使用上文进行编码
GPT2:仍然仅使用上文进行编码(因为要处理生成任务)。但是模型更大,数据量更多。
GPT3:超大规模
对于不同的微调任务,我们需要对数据进行如下处理:
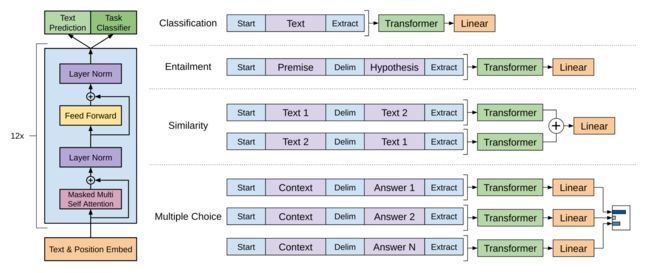
细节#
由于GPT仍然是一个生成式的语言模型,因此需要采用Mask Multi-Head Attention的方式来避免预测当前词的时候会看见之后的词,因此将其称为单向Transformer,这也是首次将Transformer应用于预训练模型,预测的方式就是将position-wise的前向反馈网络的输出直接送入分类器进行预测
此外整个GPT的训练包括预训练和微调两个部分,或者说,对于具体的下游任务,其模型结构也必须采用与预训练相同的结构,区别仅在于数据需要进行不同的处理
微调#
对于带有标签的监督数据[1,...,],我们直接将其输入到已经完成预训练的模型中,然后利用最后一个位置的输出对标签进行预测,即
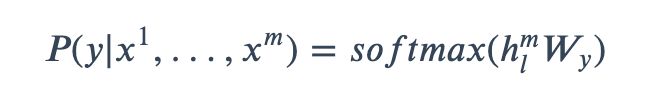
其中,为分类器的参数,ℎℎ为最后一层最后一个位置的输出。则最大化优化目标即为:
2()=∑(,) (|1,...,)
只有encoder:
解码器模型,通常称为自回归,在通常设计为强制模型预测下一个单词的预训练期间仅使用解码器。注意层只能访问句子中给定单词之前的单词。它们最适合涉及文本生成的任务。
Bert:同时使用上下文进行编码,通过mask方式实现
Roberta:相比bert主要是在训练参数上做了调整:batch size,adam参数,训练数据、nsp loss、epoch数,词表大小。
BERT的输入表征由三种Embedding求和而成:
Token Embeddings:即传统的词向量层,每个输入样本的首字符需要设置为[CLS],可以用于之后的分类任务,若有两个不同的句子,需要用[SEP]分隔,且最后一个字符需要用[SEP]表示终止
Segment Embeddings:为[0,1][0,1]序列,用来在NSP任务中区别两个句子,便于做句子关系判断任务
Position Embeddings:与Transformer中的位置向量不同,BERT中的位置向量是直接训练出来的
Fine-tunninng#
对于不同的下游任务,我们仅需要对BERT不同位置的输出进行处理即可,或者直接将BERT不同位置的输出直接输入到下游模型当中。具体的如下所示:
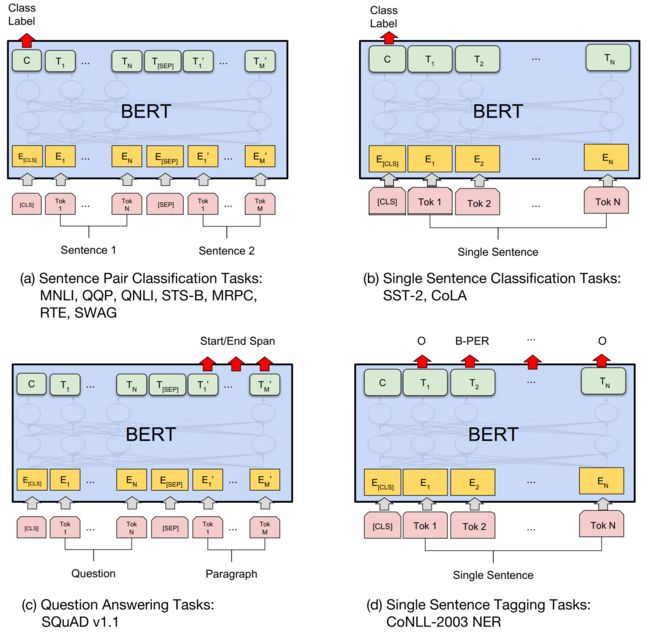
对于情感分析等单句分类任务,可以直接输入单个句子(不需要[SEP]分隔双句),将[CLS]的输出直接输入到分类器进行分类
对于句子对任务(句子关系判断任务),需要用[SEP]分隔两个句子输入到模型中,然后同样仅须将[CLS]的输出送到分类器进行分类
对于问答任务,将问题与答案拼接输入到BERT模型中,然后将答案位置的输出向量进行二分类并在句子方向上进行softmax(只需预测开始和结束位置即可)
对于命名实体识别任务,对每个位置的输出进行分类即可,如果将每个位置的输出作为特征输入到CRF将取得更好的效果。
缺点#
BERT的预训练任务MLM使得能够借助上下文对序列进行编码,但同时也使得其预训练过程与中的数据与微调的数据不匹配,难以适应生成式任务
另外,BERT没有考虑预测[MASK]之间的相关性,是对语言模型联合概率的有偏估计
由于最大输入长度的限制,适合句子和段落级别的任务,不适用于文档级别的任务(如长文本分类);
适合处理自然语义理解类任务(NLU),而不适合自然语言生成类任务(NLG)
同时有encoder-decoder:
编码器-解码器模型,也称为序列到序列,使用了 Transformer 架构的两个部分。编码器的注意层可以访问输入中的所有单词,而解码器的注意力层只能访问输入中给定单词之前的单词。预训练可以使用编码器或解码器模型的目标来完成,但通常涉及一些更复杂的东西。这些模型最适合围绕根据给定输入生成新句子的任务,例如摘要、翻译或生成式问答。
T5。encoder的hidden层输出用avgpooling,而不是像bert一样用的cls-token
在训练模型时,我们需要为模型定义一个任务来学习。上面已经提到了一些典型的任务,例如预测下一个词或学习重建掩码词。“自然语言处理的预训练模型:调查”包括一个相当全面的预训练任务分类,所有这些都可以被认为是自我监督的:
Language Modeling (LM): 预测下一个标记(在单向 LM 的情况下)或前一个和下一个标记(在双向 LM 的情况下)
Masked Language Modeling (MLM):从输入句子中屏蔽掉一些标记,然后训练模型通过其余标记预测被屏蔽的标记
Permuted Language Modeling (PLM): 与 LM 相同,但基于输入序列的随机排列。一个排列是从所有可能的排列中随机抽取的。然后选择一些标记作为目标,训练模型来预测这些目标。
Denoising Autoencoder (DAE):采用部分损坏的输入(例如,从输入中随机抽取标记并将其替换为 [MASK] 元素。从输入中随机删除标记,或以随机顺序打乱句子)并旨在恢复原始未失真的输入.
Contrastive Learning (CTL):文本对的得分函数是通过假设一些观察到的文本对在语义上比随机采样的文本更相似来学习的。它包括:Deep InfoMax (DIM): 最大化图像表示和图像局部区域之间的互信息; Replaced Token Detection (RTD): 根据周围环境预测令牌是否被替换; Next Sentence Prediction (NSP): 训练模型区分两个输入句子是否是来自训练语料的连续片段;和 Sentence Order Prediction(SOP): 类似于NSP,但使用两个连续的片段作为正例,使用相同的片段但顺序交换作为负例
对 Huggingface 中可用的63个transformer模型做了统计,按模型名称、属于哪类预训练模型架构(只用transformer的decode、只用transformer的encode、transformer)、预训练的任务、属于那个家族系(bert、bart、gpt、t5、transformer...)。
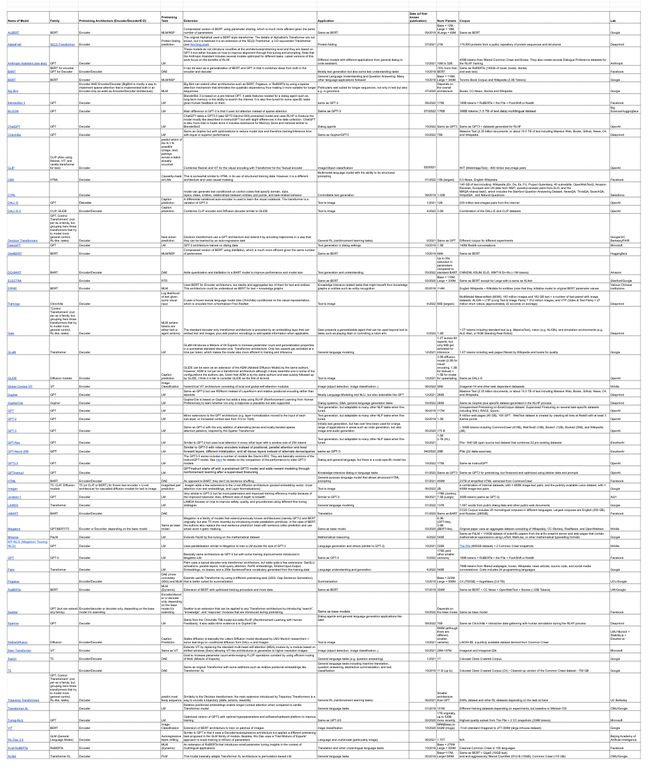
https://docs.google.com/spreadsheets/d/1ltyrAB6BL29cOv2fSpNQnnq2vbX8UrHl47d7FkIf6t4/edit#gid=0
体系树作图如下

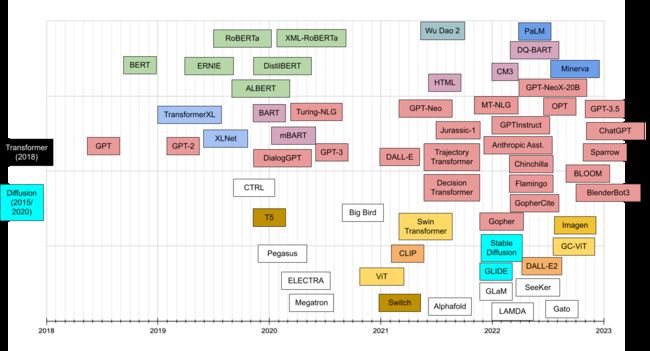
模型发展时间线
模型大小图
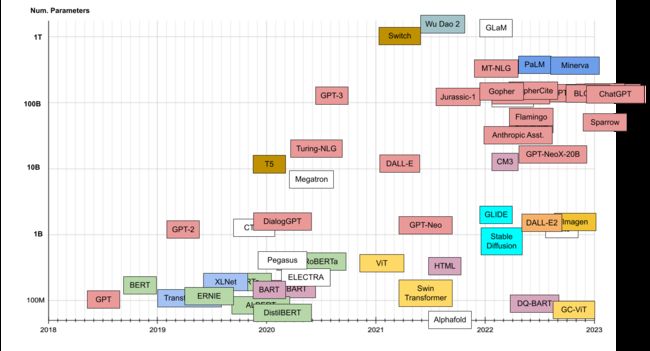
中文大模型介绍
2021年4月,华为云联合循环智能发布盘古NLP超大规模预训练语言模型,参数规模达1000亿;联合北京大学发布盘古α超大规模预训练模型,参数规模达2000亿。
阿里达摩院发布270亿参数的中文预训练语言模型PLUG,联合清华大学发布参数规模达到1000亿的中文多模态预训练模型M6。
2021年6 月,北京智源人工智能研究院发布了超大规模智能模型“悟道 2.0”,参数达到 1.75 万亿,成为当时全球最大的预训练模型。
2021年7月,百度推出ERNIE 3.0 知识增强大模型,参数规模达到百亿。10月,浪潮发布约2500亿的超大规模预训练模型“源1.0”。
2021年12月,百度推出ERNIE 3.0 Titan模型,参数规模达2600亿。而达摩院的M6模型参数达到10万亿,将大模型参数直接提升了一个量级。
到2022年,大模型继续火热。最开始,大模型是集中在计算语言领域,但如今也已逐渐拓展到视觉、决策,应用甚至覆盖蛋白质预测、航天等等重大科学问题,谷歌、Meta、百度等等大厂都有相应的成果。一时间,参数量低于 1 亿的 AI 模型已经没有声量。
清华GLM
清华CPM-BEE
梳理各模型大小、参数、训练数据
多模态大模型演进
多模态表示模型
CLIP
viT
SVIT
生成模型
VAE
GAN
discodiffusion
stablediffusion
大模型训练开源语料
Reference
[1] Radford, A., Narasimhan, K., Salimans, T. and Sutskever, I., 2018. Improving language understanding by generative pre-training.
[2] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. and Sutskever, I., 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8), p.9.
[3] Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. “Language models are few-shot learners.” arXiv preprint arXiv:2005.14165 (2020).
[4] Rei, M., 2017. Semi-supervised multitask learning for sequence labeling. arXiv preprint arXiv:1704.07156.
[5] Waswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L. and Polosukhin, I., 2017. Attention is all you need. In NIPS.
[6] medium.com/walmartgloba
[7] Zhu, Yukun, et al. "Aligning books and movies: Towards story-like visual explanations by watching movies and reading books." Proceedings of the IEEE international conference on computer vision. 2015.
[8] McCann, Bryan, et al. "The natural language decathlon: Multitask learning as question answering." arXiv preprint arXiv:1806.08730 (2018).
[9] Rajeswaran, Aravind, et al. "Meta-learning with implicit gradients." arXiv preprint arXiv:1909.04630 (2019).
[10] Finn, Chelsea, Pieter Abbeel, and Sergey Levine. "Model-agnostic meta-learning for fast adaptation of deep networks." International Conference on Machine Learning. PMLR, 2017.
[11] Child, Rewon, et al. "Generating long sequences with sparse transformers." arXiv preprint arXiv:1904.10509 (2019).
[12]https://amatriain.net/blog/transformer-models-an-introduction-and-catalog-2d1e9039f376/