想训练ChatGPT?得先弄明白Reward Model怎么训(附源码)

©作者 | 潘柯宇
研究方向 | 内容理解、信息抽取
随着最近 ChatGPT 的大火,越来越多人开始关注其中用到的 RLHF(Reinforcement Learning from Human Feedback)这一核心思想。
使用强化学习(而非监督学习)的方式更新语言模型,最大的优势是在于能够使得「模型更加自由的探索更新方向,从而突破监督学习的性能天花板」。
关于为什么使用 RL 技术能够达到更好的效果,可以参考下面这个视频中的例子(6:30 秒处):
在今天这篇文章中,我们将通过一个示例来完成利用「强化学习」更新「语言模型」的任务。

任务描述:利用RL训练一个好评生成器
我们设定一个任务目标:学习一个「好评生成器」。
模型接收一段 prompt,例如:刚收到货,感觉
随即,让模型将这段话补全,例如:有点不符合预期,货物很差
prompt: 刚收到货,感觉
output 1: 刚收到货,感觉 有 点 不 符 合 预 期 ,不 好
output 2: 刚收到货,感觉 挺 无 奈 的 送 货 速 度 不 太 行
..在初始状态下,模型将没有任何偏好的生成答案,这意味着有可能生成一些差评(如上述例子)。
现在,我们将利用强化学习(PPO)的方式来对生成模型进行「好评生成」的训练。
每当模型生成一个句子,我们就给出一个相应的得分(reward),用于表征该条生成评论是否是「正向好评」,如下所示:
output 1: 刚收到货,感觉有 点 不 符 合 预 期 ,不 好 -> 0.2 分
output 2: 刚收到货,感觉有 挺 无 奈 的 送 货 速 度 不 太 行 -> 0.1 分
output 3: 刚收到货,感觉有 些 惊 喜 于 货 物 质 量 -> 0.9 分
...随即,我们利用打出的 reward 对生成模型进行迭代。
整个流程如下图所示:

▲ 基于 RL 的 LM 更新流程
引入判别模型代替人工打分
如果依靠人工为每一个输出打分,这将是一个非常漫长的过程。
如果我们能找到一个判别模型:接收一个句子作为输入,输出这个句子是好评的概率。
那么我们就可以直接利用这个判别模型的输出作为生成句子的 reward。
因此,我们引入另一个「情绪识别模型」来模拟人工给出的分数。
「情绪识别模型」我们选用 transformers 中内置的 sentiment-analysis pipeline 来实现。
https://huggingface.co/uer/roberta-base-finetuned-jd-binary-chinese
该模型基于网络评论数据集训练,能够对句子进行「正向、负向」的情绪判别,如下所示:

▲ 「情绪识别」模型
我们利用该「情感识别模型」的判别结果(0.0~1.0)作为 GPT 生成模型的 reward,以指导 GPT 模型通过强化学习(PPO)算法进行迭代更新。

训练流程详解
2.1 生成采样(Rollout)
生成采样阶段的目的是为了让当前模型生成一些采样结果。

▲ 生成采样示意图
为了保证生成句子的多样性,我们设定了一个 prompt 池,模型会从中随机选择一个 prompt 来进行答案生成:
# prompt池
prompts = [
'刚收到货,感觉',
'这部电影很',
'说实话,真的很',
'这次购物总的来说体验很'
]
...
for _ in range(config['batch_size']):
random_prompt = random.choice(prompts) # 随机选择一个prompt
tokens = gpt2_tokenizer.encode(random_prompt)
batch['tokens'].append(tokens)
batch['query'].append(random_prompt)
query_tensors = [torch.tensor(t).long().to(device) for t in batch["tokens"]]
...
for i in range(config['batch_size']):
gen_len = config['gen_len']
response = gpt2_model.generate(query_tensors[i].unsqueeze(dim=0), # 利用当前选择的prompt生成句子
max_new_tokens=gen_len, **gen_kwargs)
response_tensors.append(response.squeeze()[-gen_len:])这一步之后,我们将获得一堆模型的生成结果:
[
'刚收到货,感觉 很 一 般',
'这部电影很 俗 而 且 很 无 趣',
'这次购物总的来说体验很 烂 不 是 我 想 要 的',
...
]
2.2 Reward 评估(Evaluation)
在获得了模型生成结果后,我们就可以利用「情感识别模型」进行打分了。
# 情绪识别模型初始化
senti_tokenizer = AutoTokenizer.from_pretrained('uer/roberta-base-finetuned-jd-binary-chinese')
senti_model = AutoModelForSequenceClassification.from_pretrained('uer/roberta-base-finetuned-jd-binary-chinese')
sentiment_pipe = pipeline('sentiment-analysis', model=senti_model, tokenizer=senti_tokenizer, device=pipe_device)
...
texts = [q + r for q,r in zip(batch['query'], batch['response'])] # 将 prompt 和生成的 response 做拼接
pipe_outputs = sentiment_pipe(texts) # 计算正向/负向情感得分
▲ Reward 评估示意图
执行上述代码后,得到每个句子的 reward 得分:
[
0.4,
0.3,
0.3,
...
]2.3 模型迭代(Optimization)
模型迭代阶段我们会利用 PPO 进行模型参数的更新,更新代码只用一行:
ppo_trainer.step(query_tensors, response_tensors, rewards) # PPO Update
▲ 模型迭代示意图
PPO 在更新时一共会计算 2 个 loss:pg_loss、value_loss:
loss_p, loss_v, train_stats = self.loss(logprobs, values, rewards, query, response, model_input)
loss = loss_p + loss_v
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
...pg_loss
pg_loss 是 PPO 中 actor 的 loss 函数,其通过 discount reward 和 importance ratio 来计算当前 step 的 reward 应该是多少:

其中,importance ratio 是指产生同样的 token,在 active actor model 和 reference actor model 下的概率比值,这也是 PPO 模型中的 Importance Sampling 系数。
for t in reversed(range(gen_len)):
nextvalues = values[:, t + 1] if t < gen_len - 1 else 0.0
delta = rewards[:, t] + self.ppo_params['gamma'] * nextvalues - values[:, t] # 优势函数:r + Vnext - V
lastgaelam = delta + self.ppo_params['gamma'] * self.ppo_params['lam'] * lastgaelam # GAE, 用于平衡 bias 和 variance
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1]).transpose(0, 1)
logits, _, vpred = self.model(model_input) # 跑一遍模型,得到句子中每个token被选择的概率
logprob = logprobs_from_logits(logits[:,:-1,:], model_input[:, 1:]) # 将概率取log对数
ratio = torch.exp(logprob - old_logprobs) # log相减,等同于概率相除
pg_losses = -advantages * ratiovalue_loss
value_loss 是 PPO 中 critic 的 loss 函数,其目的在于评判每一个 token 被生成后的 value 是多少。
这是因为在 PPO 中需要有一个 critic 网络,为了实现这个效果,我们需要对 GPT 模型进行改造。
我们在 GPT 中加入一个 Value Head,用于将 hidden_size 向量映射到一个 1 维的 value 向量:
class GPT2HeadWithValueModel(GPT2PreTrainedModel):
"""The GPT2HeadWithValueModel class implements a GPT2 language model with a secondary, scalar head."""
def __init__(self, config):
super().__init__(config)
config.num_labels = 1
self.transformer = GPT2Model(config)
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
self.v_head = ValueHead(config) # 添加 Value Head
self.init_weights()
...
class ValueHead(nn.Module):
"""The ValueHead class implements a head for GPT2 that returns a scalar for each output token."""
def __init__(self, config):
super().__init__()
self.summary = nn.Linear(config.hidden_size, 1) # (hidden_size -> 1)
...value_loss 就应该等于 Value Head 产生的预测值 v_pred 和真实值 r + v_next 之间的差值:

returns = advantages + values # r + v_next - v + v => r + v_next
logits, _, vpred = self.model(model_input) # 跑一遍语言模型,得到每个 token 的 v_pred
vf_losses1 = (vpred - returns) ** 2 # MSE
实验结果
训练曲线图如下所示,可以看到随着训练推进,模型的 reward 由最早的0.68 -> 0.85 左右:

▲ 训练曲线图
在模型刚开始训练的时候,GPT 会生成一些比较随机的答案,此时的平均 reward 也不会很高,会生成一些「负面」情绪的评论(如下所示):

▲ 训练初期模型的生成结果
随着训练,GPT 会慢慢学会偏向「正面」的情绪评论(如下所示):

▲ 训练后期模型的生成结果
完整源码在这里:
https://github.com/HarderThenHarder/transformers_tasks/tree/main/RLHF

Reward Model
在上面的内容中,我们已经讲解了如何将强化学习(Reinforcement Learning)和语言模型(Language Model)做结合。
但是,示例中我们是使用一个现成的「情绪识别模型」来作为奖励模型(Reward Model)。
在 ChatGPT 中,奖励模型是通过人工标注的「排序序列」来进行训练的,如下图所示:

▲ InstructGPT Reward Model 训练流程
这是什么意思呢?
如上图所示,ChatGPT 并不是直接让人工去标注每一句话的真实得分是多少(尽管模型最终要预测的就是每句话的得分),而是让人去对 4 句话按照好坏程度进行「排序」。
通过这个「排序序列」,模型将会学习如何为每一个句子进行打分。
听起来很绕对吧? 既然最终目的是训练一个句子打分模型,为什么不让人直接打分,而是去标排序序列呢?
今天我们就来好好聊一聊这个非常巧妙的思想。
视频讲解在这里:

「标注排序序列」替代「直接打分」
大家在曾经考语文的时候,都写过作文吧?
而作文的分数也成为了整个语文考试中不确定性最大的环节。因为「打分」这个行为的主观性太强,同一篇作文不同的老师可能会打出不同的分数。
为了统一打分标准,通常在阅卷的时候都会制定一系列的规则,例如:主题明确,语句通顺,句子优美等。但,即便如此,不同老师对「主题明确」和「句子优美」也有着不同的看法。这就导致我们很难统一所有老师的看法,使得不同人在看到同一篇作文时打出相同的分数。
而标注员在给 ChatGPT 进行标注的时候,就可以看做有很多个「老师」在给模型写的作文「打分」。因此我们可以看出,直接给生成文本进行打分是一件非常难统一的事情。如果对于同样的生成答案,有的标注员打 5 分,但有的标注员打 3 分,模型在学习的时候就很难明确这句话究竟是好还是不好。
既然打「绝对分数」很难统一,那我们转换成一个「相对排序」的任务是不是就容易许多呢?
举例来讲,假设今天模型生成了 2 句话:
1. 香蕉是一种黄色的水果,通常长在树上,是猴子非常喜爱的水果。
2. 香蕉很酸,富含矿物质元素。如果让作业员去打分,可能不同人打出来不同的分:

但如果我们只让标注员对这两个答案进行好坏排序,就能得到统一的结果:

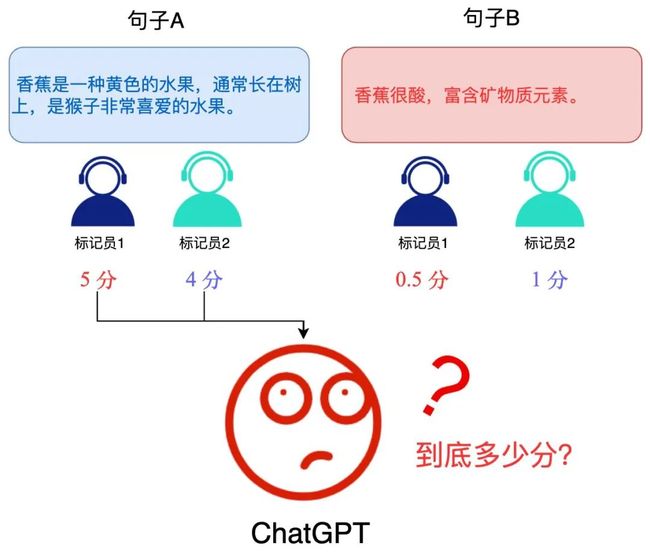
▲ 「绝对分数」难以统一

▲ 「相对排序」容易统一
不难看出,用「相对任务」替代「绝对任务」能够更方便标注员打出统一的标注结果。
那么,「统一」的问题解决了,我们怎么通过「排序序列」来教会模型「打分」呢?

Rank Loss —— 通过排序序列学会打分
假定现在有一个排好的序列:A > B > C >D。
我们需要训练一个打分模型,模型给四句话打出来的分要满足 r(A) > r(B) > r(C) > r(D)。
那么,我们可以使用下面这个损失函数:

其中,yw 代表排序排在 yl 的所有句子。
用上述例子(A > B > C > D)来讲,loss 应该等于:
loss = r(A) - r(B) + r(A) - r(C) + r(A) - r(D) + r(B) - r(C) + ... + r(C) - r(D)
loss = -loss为了更好的归一化差值,我们对每两项差值都过一个 sigmoid 函数将值拉到 0 ~ 1 之间。可以看到,loss 的值等于排序列表中所有「排在前面项的reward」减去「排在后面项的reward」的和。
而我们希望模型能够「最大化」这个「好句子得分」和「坏句子得分」差值,而梯度下降是做的「最小化」操作。因此,我们需要对 loss 取负数,就能实现「最大化差值」的效果了。
更详细的解释可以参考下面这个视频中(14:55 秒)的例子:

实验结果
这一小节中,我们将尝试通过「排序序列」来学习一个「打分模型」。首先我们会先准备一份数据集,每一行是一个排序序列(用 \t 符号隔开)。排在越前面的越偏「正向情绪」,排在越后面越「负向情绪」。
1.买过很多箱这个苹果了,一如既往的好,汁多味甜~ 2.名不副实。 3.拿过来居然屏幕有划痕,顿时就不开心了 4.什么手机啊!一台充电很慢,信号不好!退了!又买一台竟然是次品。
1.一直用沙宣的洗发露!是正品!去屑止痒润发护发面面俱到! 2.觉得比外买的稀,好似加了水的 3.非常非常不满意,垃圾。 4.什么垃圾衣服,买来一星期不到口袋全拖线,最差的一次购物
...我们期望通过这个序列训练一个 Reward 模型,当句子越偏「正向情绪」时,模型给出的 Reward 越高。在 backbone 上,我们选用 ERNIE 作为基准模型,将模型的 pooler_output 接一层 linear layer 以得到一维的 reward:
class RewardModel(nn.Module):
def __init__(self, encoder):
"""
init func.
Args:
encoder (transformers.AutoModel): backbone, 默认使用 ernie 3.0
"""
super().__init__()
self.encoder = encoder
self.reward_layer = nn.Linear(768, 1) # reward layer 用于映射到 1 维 reward
def forward(
self,
input_ids: torch.tensor,
token_type_ids: torch.tensor,
attention_mask=None,
pos_ids=None,
) -> torch.tensor:
"""
forward 函数,返回每句话的得分值。
Args:
input_ids (torch.tensor): (batch, seq_len)
token_type_ids (torch.tensor): (batch, seq_len)
attention_mask (torch.tensor): (batch, seq_len)
pos_ids (torch.tensor): (batch, seq_len)
Returns:
reward: (batch, 1)
"""
pooler_output = self.encoder(
input_ids=input_ids,
token_type_ids=token_type_ids,
position_ids=pos_ids,
attention_mask=attention_mask,
)["pooler_output"] # (batch, hidden_size)
reward = self.reward_layer(pooler_output) # (batch, 1)
return reward计算 rank_loss 函数如下,因为样本里的句子已经默认按从高到低得分排好,因此我们只需要遍历的求前后项的得分差值加起来即可:
def compute_rank_list_loss(rank_rewards_list: List[List[torch.tensor]], device='cpu') -> torch.Tensor:
"""
通过给定的有序(从高到低)的ranklist的reward列表,计算rank loss。
所有排序高的句子的得分减去排序低的句子的得分差的总和,并取负。
Args:
rank_rewards_list (torch.tensor): 有序(从高到低)排序句子的reward列表,e.g. ->
[
[torch.tensor([0.3588]), torch.tensor([0.2481]), ...],
[torch.tensor([0.5343]), torch.tensor([0.2442]), ...],
...
]
device (str): 使用设备
Returns:
loss (torch.tensor): tensor([0.4891], grad_fn=)
"""
if type(rank_rewards_list) != list:
raise TypeError(f'@param rank_rewards expected "list", received {type(rank_rewards)}.')
loss, add_count = torch.tensor([0]).to(device), 0
for rank_rewards in rank_rewards_list:
for i in range(len(rank_rewards)-1): # 遍历所有前项-后项的得分差
for j in range(i+1, len(rank_rewards)):
diff = F.sigmoid(rank_rewards[i] - rank_rewards[j]) # sigmoid到0~1之间
loss = loss + diff
add_count += 1
loss = loss / add_count
return -loss 最终训练结果如下:
...
global step 10, epoch: 1, loss: -0.51766, speed: 0.21 step/s
global step 20, epoch: 1, loss: -0.55865, speed: 0.22 step/s
global step 30, epoch: 1, loss: -0.60930, speed: 0.21 step/s
global step 40, epoch: 1, loss: -0.65024, speed: 0.21 step/s
global step 50, epoch: 1, loss: -0.67781, speed: 0.22 step/s
Evaluation acc: 0.50000
best F1 performence has been updated: 0.00000 --> 0.50000
global step 60, epoch: 1, loss: -0.69296, speed: 0.20 step/s
global step 70, epoch: 1, loss: -0.70710, speed: 0.20 step/s
...
▲ loss、acc 曲线图
我们输入两个评论句子:
texts = [
'买过很多箱这个苹果了,一如既往的好,汁多味甜~',
'一台充电很慢,信号不好!退了!又买一台竟然是次品。。服了。。'
]
>>> tensor([[10.6989], [-9.2695]], grad_fn=) 可以看到「正向评论」得到了 10.6 分,而「负向评论」得到了 -9.26 分。

标注平台
在 InstructGPT 中是利用对语言模型(LM)的输出进行排序得到排序对从而训练 Reward Model。如果想获得实现论文中类似的数据,在该项目中我们也提供了标注平台,可标注 rank_list 数据:

▲ Rank List 标注平台(详情可参考源码仓库)
好啦,以上就是 Reward Model 的全部内容,感谢观看。
完整源码在这里:
https://github.com/HarderThenHarder/transformers_tasks/tree/main/RLHF
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
