【Chinese Lexical Simplification 论文精读】
Chinese Lexical Simplification 论文精读
- Information
- Abstract
- 1 INTRODUCTION
- 2 RELATED WORK
- 3 A DATASET
- 4 BASELINES
-
- 4.1 Substitution Generation
- 4.2 Substitution Ranking
- 4.3 CLS System
- 5 EXPERIMENTS
-
- 5.1 Evaluation of the quality of the dataset HanLS
- 5.2 Evaluation of substitution generation
- 5.3 System Evaluation and Ablation Study
- 5.4 Error Analysis
- 6 CONCLUSION
- ACKNOWLEDGEMENT
- References
- 自结[^1]
Information
标题: 汉语词法简化
时间: 2020/10/14
会议: IEEE
作者: Jipeng Qiang, Xinyu Lu, Yun Li, Yunhao Yuan, Yang Shi, and Xindong Wu
链接: https://arxiv.org/pdf/2010.07048.pdf
Abstract
词汇简化在许多语言中都引起了广泛的关注,这是一种用较简单的等价词替换句子中的复杂词的过程。Q:虽然汉语词汇的丰富性使得文本对于儿童和非母语人士来说非常难读,但目前还没有针对汉语词语简化(CLS)任务的研究。 为了解决标注获取困难的问题,R:我们为CLS手工创建了第一个基准数据集,用于自动评估词法简化系统。为了获得更全面的比较,我们提出了五种不同类型的方法作为基线,包括基于同义词的方法、基于词嵌入的方法、基于预训练语言模型的方法、基于义素的方法和混合方法。最后,我们设计了这些基线的实验评估,并讨论了它们的优缺点。据我们所知,这是对CLS任务的第一次研究。
索引术语-词法简化,BERT,无监督,预训练语言模型。
1 INTRODUCTION
词汇简化 (Lexical simplified,LS) 旨在在不改变句子含义的情况下,用更简单的替代词代替复杂的单词,这可以帮助各种人群,包括儿童 [1] 、非母语人士 [2] 、认知障碍者 [3] 、 [4],更好地理解文本。例如,句子 “John composed these verses in 1995” 可以在词汇上简化为 “John wrote the poems in 1995”。LS任务已经被应用到不同的语言中,例如英语 [2] 、 [5]-[9] 、日语 [10] 、 [11] 、西班牙语 [12] 、 [13] 、瑞典语 [14] 和葡萄牙语 [15]。
汉语,现代世界现存唯一的象形语言,是最难学习的语言之一 [16],[17]。汉语中有200,000多个常用词是由5,000字组成的。例如,对于一个简单的中文单词 “qizi” (Wife),有几十个等效的含义,例如 “Lˇaopo”, “P´oni´ang”, “X´ıfu”, “Neir´en”, “H´ait¯ani´ang”, “Duıxiang”, “F¯ur´en”, “`Airen”, “Taitai” 等等。中文文字的复杂性和丰富性使这些人 (儿童,非母语人士等) 感到极为困难。这些表明,中文词汇简化系统是改善文本可访问性的宝贵工具。然而,到目前为止还没有关于汉语词汇简化的研究。因此,本文重点研究汉语词法简化 (CLS) 问题。
CLS的第一个挑战是缺乏人工标注。 我们首先为CLS构建一个基准数据集HanLS,该数据集既可用于训练又可用于评估,以加速该主题的研究。首先,我们要求两位具有教学经验的母语人士给出一些目标词作为内容词 (名词,动词,形容词和副词) 的列表,并搜索一些包含目标词的句子。给定一个句子和一个要简化的单词,然后我们请六个注释者给出该单词的更简单的变体,这些变体在句子的上下文中是合适的。
CLS任务的第二个挑战是提出与原目标词语义一致、符合上下文又能保持句子意义的替代词。 目前还没有关于CLS的方法发表。为了提供一个全面的比较,我们提出了五种不同类型的方法作为基线生成替代品。(1)基于同义词词典的方法:通过从人工策划的词汇词典中提取同义词来获取替代候选词。(2)基于词嵌入的方法:利用词嵌入的相似度生成替代词。(3)基于预训练语言模型的方法:我们采用预训练语言模型BERT[18],将原句的复杂词进行掩盖,然后将其输入BERT中预测被掩盖的词。(4)基于义素的词替换方法:我们设计了一种基于义素的词替换方法,义素是最小的语义单位,能够保留更多潜在的复杂词的有效替换。(5)一种混合方法:结合同义词词典和基于预训练语言模型的方法提取候选替换。在获得替代候选词后,我们利用以下四个特征来选择最佳替代词:基于BERT的语言建模、词频、词相似度和Hownet相似度,分别捕捉候选词替代复杂词的适用性的一个方面。
这项工作的贡献有两个方面:
(1) 我们专注于汉语词汇简化 (CLS) 任务,并为CLS手动创建第一个基准数据集HanLS,可用于自动评估CLS方法。
(2) 我们为CLS任务提出了五种不同的基准,其中包含两种经典方法 (同义词词典和单词嵌入) 和三种最新方法 (预训练的语言模型,义素和混合)。实验结果表明,这些基线 (同义词词典,预先训练的语言模型和混合) 输出的词法简化在语法上是正确的,并且在语义上适合HanLS。
加速这一主题研究的数据集和基线可在https://www.github.com/anonymous获得。
2 RELATED WORK
词汇简化 (LS) 作为文本简化的子任务,重点是使用更简单的变体简化一个句子的复杂单词。目前的研究大多集中在英语词汇简化上。我们将详细介绍英语LS方法,简要解释其他语言LS方法,最后介绍一些与中文LS相关的工作。此外,我们将为每种语言LS任务提供公共数据集。所有这些数据集都包含由句子,目标复杂单词以及人类就其简单性提供的一组合适的替换组成的实例。
英语LS及其基准: 目前流行的词汇简化方法是基于规则的,其中每个规则都包含一个复杂的单词及其简单的同义词 [19]-[21]。基于规则的系统通常从WordNet或其他语言数据库中识别出一组预定义的复杂单词的同义词,并根据单词的频率或单词的长度从这些同义词中选择 “最简单的” [1],[22]。一些LS系统试图从平行语料库 [23]-[25] 中提取规则。为了完全避免词汇资源或并行语料库的需求,提出了基于单词嵌入的LS系统 [6]-[8]。他们提取了顶部单词作为候选替换,其向量在与复杂单词的余弦相似性方面更接近。预训练语言模型 [18],[26] 引起了广泛的关注,并已证明对改善许多下游自然语言处理任务是有效的。最近的LS方法基于BERT [9],[27] 为复杂单词生成合适的简化。
英语LS有三个广泛使用的数据集,分别是LexMTurk[25]、BenchLS[2]和NNSeval[28]。LexMTurk由50个亚马逊机械 “turkers”注释的500个实例组成。BenchLS由英语的929个实例组成,这些实例来自LexMTurk和LSeval[1]。LSeval包含429个实例,其中每个复杂的单词都由46名turkers和9名博士生注释。NNSeval由239个英文实例组成,它是一个过滤版的BenchLS。
其他语言LS: 大多数其他语言LS方法通常基于语言数据库来寻找复杂单词的更简单的候选替代品。PorSimples项目为巴西葡萄牙语提供了一种LS方法,该方法使用数据库Tep 2.0和PAPEL [15] 提供的相关单词集。Bott等人 [12] 使用西班牙语的OpenTheaurus来寻找西班牙语中复杂词的同义词。Keskis-arkk-a [29] 使用瑞典语的词库SynLex来寻找复杂单词的同义词。Kajiwara等人 [10] 利用了提供单词描述的词典。该方法从复杂单词的定义中提取候选替换。他们从newswire语料库中构建了一个数据集,用于评估日语的词汇简化。之后,Kodaira等。[30] 提出了一种新的受控且平衡的数据集,用于日语词汇简化,与人类判断高度相关。
中文LS: 据我们所知,没有关于中国LS的工作。与中文LS最相关的工作是中文文本可读性评估 [31]。文本可读性评估用于衡量给定文本的难易程度,以辅助为学习者选择合适的阅读材料 [32]。自动文本可读性度量由基于公式的方法和使用各种特征 (包括单词特征,句子特征等) 的分类方法组成。当获得文本的难度等级时,下一步是简化原始文本,以降低文本的难度并满足不同用户的需求。但是,中文LS任务很少受到关注,并且我们无法获得公开可用的方法和数据集。因此,在本文中,我们将首先构建一个中文LS数据集进行评估,并提出一些不同的LS系统来简化中文句子。
3 A DATASET
在参考了现有的英语和日语词汇简化数据集的构建之后,我们创建了一个由三名本科生和三名研究生注释的中文词汇简化任务的数据集HanLS。这些学生都是母语为汉语的人。我们遵循以下步骤。
(1) 提取句子: 在世界流行的汉语HSK词汇 [444] 中,我们将复杂词定义为 “高级” 词。600个高级词 (名词,动词,形容词和副词) 是由两位具有教学经验的母语人士根据他们的经验和直觉选择的。我们的目标是创建一个平衡的语料库和控制句子,使其只有一个复杂的单词。然后,从这两个来源中随机提取包含复杂单词的句子: 国家语言委员会的现代汉语语料库和中文翻译语料库1。根据先前的工作,收集了包括每个复杂单词在内的10个句子。注释者通过控制每个句子中复杂单词的数量,为每个POS标签下的每个复杂单词选择一个句子。
(2) 提供替代品: 简化候选人是从五个母语人士那里收集的。对于每个实例,注释者都写了不会改变句子含义的替换词。提供替换词时,注释者可以引用字典,但不应该询问其他注释者的意见。当注释者想不出释义时,他们被允许不提供词条。这些注释者根据上下文的简单程度对他们提供的几个替代词进行排序。
(3) 合并所有注释: 通过对所有注释器的注释进行平均,将所有注释合并到一个数据集中。下面解释这个数据集的一个例子。举一个例子,我们假设它有一个替代x。当从五个注释者获得以下排名 (1,2,2,4,1)时,x的平均排名为2。每个实例的最终综合排名是通过按升序重新排列这些替代品的平均排名而获得的。
合并数据集由新的注释者评估。注释者根据以下两个标准将替换物评为不合适:i)如果替换后的句子变得不自然,那么这个替代词就是不恰当的;ii)替换目标词后,如果句子的意思发生变化,替换词是不合适的。最后,数据集有524个实例,其中每个实例平均有8.51个替代品,表示为HanLS。HanLS中的复杂词包含名词166,动词160,形容词134和副词64,它们分别由一个字符9,两个字符472,三个字符13和四个字符30组成。图1显示了数据集的示例。在这里,复杂的单词有9个替代品,我们只展示其中的四个。

图1 数据集HanLS中的注释示例。红色的词是复杂词。
4 BASELINES
在英语词汇化简[6]、[28]步骤的基础上,汉语词汇化简系统还包括复杂词识别、替换生成、替换排序三个步骤。在复杂词识别(CWI)步骤中,目标是在给定的句子中选择需要简化的词。在管道的其他步骤中,我们隐式地执行CWI。我们认为句子中的所有单词都是简化的目标,但在简化过程中,我们抛弃了一些替换,这些替换在应用时(wi→wi)会用更复杂的替换替换单词wi。替代的目的是为复杂词生成替代候选词。我们提出了五种不同的SG方法。给出复杂词的替代候选词,词汇简化的替代排序(Substitution Ranking, SR)就是决定哪一个替代词最适合复杂词的上下文。我们采用四个高品质特征对替代品进行排序。我们的框架结构如图2所示。
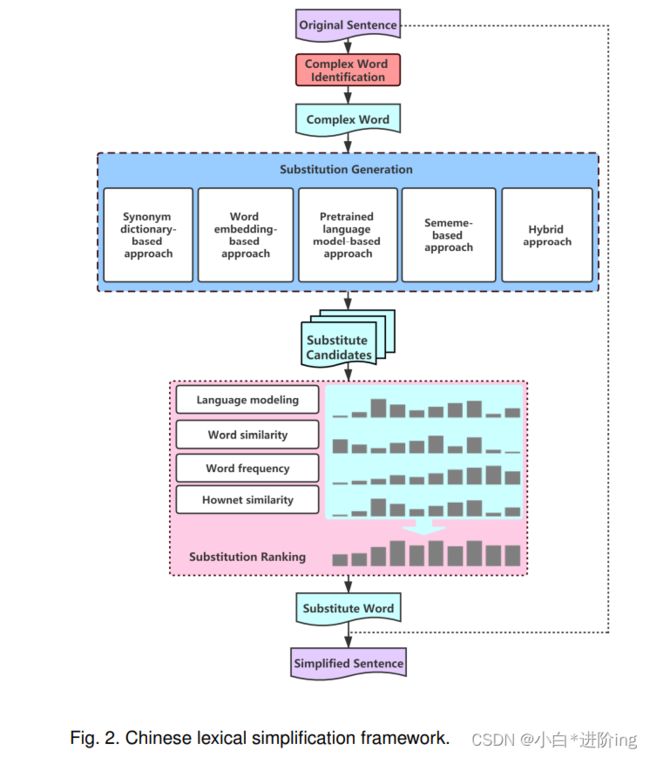
图2。汉语词法简化框架。
4.1 Substitution Generation
一个理想的SG策略将能够在可能出现的所有上下文中找到可以替换给定目标复杂单词的所有单词。为了提供一个全面的比较,我们提供了五种不同类型的方法来生成中文LS任务的替代词,并讨论了它们的优缺点。
(1) 基于同义词词典的方法: 大多数LS方法 [12],[15] 使用SG的同义词词典,例如英语的WordNet和西班牙语的OpenThesaurus。对于中文SG,我们选择同义词词库HIT-Cilin [34] 来生成替代品,其中包含77,371个不同的单词。该方法的优点是简单,易于实现。除了构建一个既昂贵又耗时的同义词词典之外,不可能涵盖所有单词。
(2)基于词嵌入的方法: 英语SG采用基于词嵌入的方法[2],该方法首先从预先训练好的词嵌入模型中获取每个词的向量表示,提取与复杂词向量余弦相似度最高的前k个词作为替代。在这里,我们使用Word2Vector算法[35],使用预先训练好的中文单词向量2,并提取前10个单词作为替代。该方法的优点是,只需要普通的大量文本语料库,训练好的词嵌入模型易于访问。替代词不仅包含相似词,还包含高度相关词和意义相反的词。
(3) 基于预先训练的语言模型方法: 最近的英语LS方法 [9],[27] 采用预先训练的语言模型BERT来产生替代。BERT是有两个训练目标训练的双向语言模型:掩码语言建模 (MLM) 和下一个句子预测 (NSP)。与传统的语言建模目标不同,该目标是在给定历史的序列中预测下一个单词,MLM在给定其左右上下文的序列中预测缺失的标记。与英语LS任务不同,我们不能直接将汉语预先训练的BERT模型用于汉语SG。由于英语具有自然空间作为分隔符,因此我们仅使用一个特殊符号 “[mask]” 来掩盖句子S的单词w,以获得与该MASK单词相对应的词汇的概率分布。
在汉语中,一个词是由一个或多个汉字组成的。对于一个由四个字组成的复杂词,可能的替代词可以是一个字、两个字、三个字和四个字。我们需要使用不同数量的[MASK]符号来替换复杂的单词。因此,预测[MASK]符号不仅是一个完形任务,也是一个生成任务。
具体来说,对于一个复杂的单词,我们使用小于或等于[MASK]符号的数量来替换它,并将所有结果合并为替代词。用[MASK]符号替换原句S,记为S’。考虑到BERT擅长处理句子对,我们将句子对{S, S’}输入到BERT中。假设S’包含两个[MASK]符号。我们首先获得第一个[MASK]符号的前n个候选字符。对于每个候选字符,我们将S’对应的[MASK]替换为候选字符,并将新的句子对{S, S’}输入BERT,得到第二个[MASK]符号的前n个候选字符。我们将第二个候选字与第一个候选字组合在一起,过滤出这些不在现代汉语词汇表[36]中的词。与同时预测两个[MASK]符号的候选字符相比,该方法获得了更好的结果。
这个方法是唯一一个在生成替代候选时利用更广泛上下文的方法。在所有的实验中,我们使用BERT-Base,中文预训练模型3。
(4)基于义素的方法: 一个词的意义可以用其义素的组合来表示,语言学家定义义素为[37]人类语言的最小不可分割的语义单位。义素已成功应用于许多自然语言处理任务,包括语义组合[38]、预训练语言模型[39]等。这是第一次尝试用义素来简化词汇。
在实际的自然语言处理应用中,义素知识库是基于义素建立的,知网就是其中最著名的一个[40]。在知网中,一个词的义素可以准确地描述该词的意思。因此,具有相同义素注释的词应该具有相同的含义,它们可以作为彼此的替代候选词。在我们基于义素的方法中,只有当w的一个义素注释与w∗的一个义素注释相同时,一个单词w才能被另一个单词w∗代替。
与基于词嵌入和语言模型的替代方法相比,基于义素的替代方法不能生成许多不恰当的替代,如反义词和语义相关但不相似的词。与基于同义词的方法相比,基于义素的方法产生了更多的替代词。
(5)混合方法: 我们设计了一种简单的混合方法,将基于同义词词典的方法和基于预训练语言模型的方法相结合。具体来说,如果HIT-Cilin同义词词典中包含复杂词,则使用基于同义词词典的方法生成替换词,否则使用基于预先训练的语言模型的方法生成替换词。
对于上述替换生成方法,我们在实验中过滤了字典(现代汉语词汇表)中没有的替换。
4.2 Substitution Ranking
我们为SR选择了四个不同的特征,个特征都捕获了候选单词适合替换复杂单词的一个方面。除了其他语言LS方法中常用的词频、词频相似度和语言模型特征外,我们还考虑了一个高质量的Hownet相似度特征。我们根据他们对每个特征的得分计算出各种各样的排名。
(1) 语言建模: 该功能的目的是评估给定句子中替代词的流畅性。我们不选择传统的n-gram语言建模,而是选择预先训练的语言模型BERT来计算句子或单词序列的概率。由于BERT的MLM,我们不能直接用BERT计算句子的概率。令W = w − m,…,w − 1,W,w1,…,wm为原词w的上下文。我们采用了一种新的策略来计算W的可能性。我们首先用替换候选替换原始单词w。然后,我们从前到后掩码W的一个单词,然后输入Bert来计算掩码单词的交叉熵损失。最后,我们根据w的平均损失对所有替代候选人进行排名。损失越低,替代候选是对原始单词的良好替代。我们使用复杂单词周围大小为5的对称窗口作为上下文。
(2) 单词相似度: 我们使用预先训练的单词嵌入模型获得每个单词的向量表示,并计算复杂单词与每个替换词之间的相似度。相似度值越高,排名越高。
(3)词频: 基于词频的替代排序策略是英语词汇简化最常用的选择之一。一般来说,一个词使用的频率越高,读者越熟悉。在本文中,我们采用了从一个包含超过2.5亿字符的大型语料库4中计算出来的词频。我们对不同语料库中的多个词频文件进行了测试,结果表明,我们采用的这个文件是最好的。
(4) 知网相似度: 除了采用单词嵌入的单词相似度外,我们选择了一种新的基于知网的单词相似度方法,该方法在反义词和同义词相似度计算中具有良好的性能 [41]。基于sememes的基于Hownet的相似性计算出复杂单词和替代词之间的相似性,这为接下来的情形提供了很好的补充。当替代候选人是反义词且语义相关但不相似的单词时,这两个特征 (语言模型和单词相似性) 可能会失去其有效性。
4.3 CLS System
整个CLS系统如算法1所示。我们试图简化句子S中的每个实义词(名词、动词、形容词和副词)(第1行)。我们首先从上述五种方法中选择一种替换生成方法来生成复数词w的替换(第2行)。然后,我们利用每个特征为每个简化候选词计算各种排名,然后通过平均所有排名对每个候选词打分(第4-12行)。我们选择在所有特征中具有平均排名分数的前两名替换对象(第13行)。如果第一个替换不是复单词w,我们将把复杂词w替换为第一个替换(第14-15行)。否则,如果第一个替换是复杂词w,只有当第二个替换的频率高于复杂词时,我们才会选择第二个替换(第17-18行)。

5 EXPERIMENTS
我们设计实验来回答以下三个问题:
Q1. 创建的中文词汇数据集HanLS的质量: 人工评估的结果与注释数据集HanLS的结果一致吗?
Q2. 提出的五种替代生成方法的差异: 使用先前的英语LS任务的评估指标来验证这些不同的SG方法对HanLS的有效性。
Q3.影响CLS系统的因素: 我们在HanLS上进行了实验,以验证一些关键参数 (替代生成方法和替代排序特征) 对整个CLS系统的影响。
在这里,提出的CLS方法被称为基于同义词词典的方法 (同义词),基于单词嵌入的方法 (嵌入),基于预训练的语言模型的方法 (预训练),基于义素的方法 (义素) 和混合方法 (混合)。
5.1 Evaluation of the quality of the dataset HanLS
考虑到汉语词汇的丰富性,我们计划在HanLS中验证注释的合理替代词的全面性。我们设计了一个实验来比较人工评价结果和使用带注释的代用品的自动评价结果之间的差异。我们采用以下度量标准。应该注意的是,我们只考虑这些由系统更改复杂单词的实例,而不考虑HanLS中的所有实例,因为如果没有替换,我们就不能对这些实例计算带注释的替换。
Changed: 系统更改复杂单词的实例数。
手动: 复杂单词被手动计算正确替换的实例比例。
Auto: 复杂单词被数据集中任何替换词替换的实例比例。
结果如表1所示。从这五种方法的排序可以看出,人工评价的结果与自动评价的结果是一致的。人工评估结果与自动评估结果相同的实例平均比例在85%以上。同义词使用“手动”和“自动”实现最佳值。但它只生成379个实例的替代词,这也意味着许多复杂的单词被原始单词本身所取代。我们认为,HanLS是一个高质量的数据集,其中标注的替代品是合理和全面的。下面,我们将详细比较我们使用HanLS提出的基线。
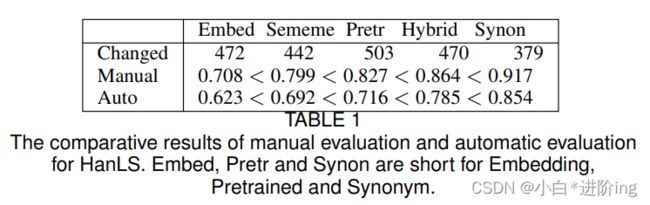
表1 人工评价与自动评价的比较结果。Embed、Pretr和Synon是嵌入、预训练和同义词的缩写。
5.2 Evaluation of substitution generation
我们使用之前的英语LS任务[9],[28]的以下四个指标来评估SG方法的性能。
潜在的: 至少有一个替代品生成的实例的比例是黄金标准。
精确性: 生成的替代候选在带注释的替代中的比例。
查准率: 在生成的替换候选中包含的带注释的替换的比例。
F1: 精度和召回之间的调和均值。
结果如表2所示。我们可以看到,同义词法和预训练法比嵌入法和义素法更有效。嵌入具有最低的Precision值,因为生成的替换包含许多语义相关但不相似的词。对于基于义素的方法,它会为许多实例生成数十甚至数百个替代品,这将导致最糟糕的Recall值。基于同义词的方法是一种简单而强大的方法,易于理解并可部署到不同的语言中。但同义词和义素都有一个很大的局限性,那就是它们的覆盖范围。例如,我们可以发现很多常用词没有出现在本词典中,如同义词词典中的“yuanzhu(Assistance)”、“xingnang(Luggage)”、“kepo(break up)”,义素词典中的“xianyou(rare)”、“chunshu(purely)”、“huangman(wild)”等。在不依赖语言数据库的情况下,预先训练的方法可以获得令人印象深刻的结果,这主要是因为它在生成替代候选词时考虑了复杂词的上下文。混合方法具有最高的潜力和精度。
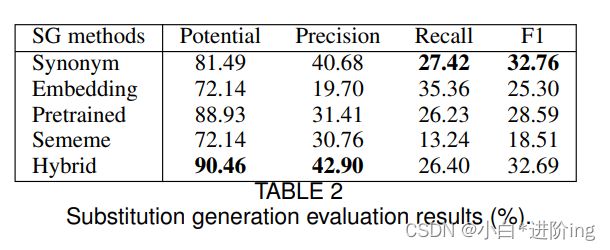
替换生成评价结果(%)。
5.3 System Evaluation and Ablation Study
此外,我们使用前面的两个度量来评估整个流程的性能。为了确定每个排序特征的重要性,我们通过依次删除一个特征进行消融研究。结果如表3所示。
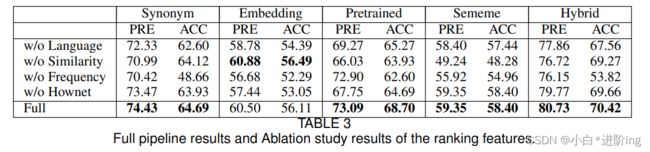
全管道结果和消融研究结果的排名特征。
精确度(PRE): 替代原词的比例,要么是原词本身,要么是黄金标准。
准确性(ACC): 替换原词的比例不是原词,而是黄金标准。
我们首先分析了每个特征对每种词法简化方法性能的影响。我们可以看到,结合这四种特征的方法效果最好,除了相似性特征用于嵌入外,这意味着所有的特征都有积极的效果。相似性特征结合所有特征进行嵌入可以得到几乎相同的结果。基于词嵌入的方法已经使用词嵌入生成替代候选词,这些替代候选词产生的相似度特征对替换排序没有影响。
然后,比较了五种方法的全流水线结果。混合能达到最高的精确度和精度。预训练也取得了满意的实验结果。尽管Synonym的结果非常令人鼓舞,但它的主要缺点是其覆盖范围。在基准数据集NNSeval上,英语LS方法[9]的精度得分为0.526,精度得分为0.436。与英语LS任务相比,汉语LS任务的同义词、预训练方法和混合方法可以作为很强的基线。
5.4 Error Analysis
在这一小节中,我们将分析所有提出的方法来理解其误差的来源。我们使用PLUMBErr工具[7]来评估LS系统所采取的所有步骤,并确定五种类型的错误。
1)简化无错误。
2)没有产生候选替代者。
3)没有更简单的候选人。
4)替换会破坏句子的语法或意义。替换并不能简化单词。
5) 替换不会简化单词。
在替代生成过程中会出现类型2和3的错误,而在替代排序过程中会出现错误4和5。表4显示了在HanLS中发生每个错误的实例的计数和比例 (在括号中)。它表明,正确的预训练可以简化最大数量的问题,同时使错误最少的3型和5型。但是,可以注意到预训练会产生4的许多错误。混合使类型2和4的误差最少。与其他方法相比,嵌入每个步骤的错误最多是最糟糕的方法。通过分析每个步骤之后产生的输出,我们发现这是由于产生了许多语义相关但不相似的单词作为替代候选词而引起的。同义词和义素很少出现类型3和5的错误,但是它们会出现许多类型2和4的错误。它们基于语言数据库,在该数据库中找不到许多复杂的单词。总体而言,结果与上述实验结论一致。
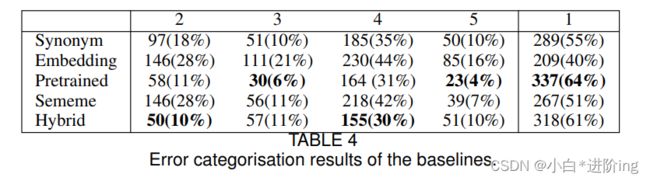
基线的错误分类结果。
6 CONCLUSION
在本文中,我们手动构建了一个数据集,用于自动评估中文词法简化 (CLS) 系统的性能。我们提出了五种不同的方法来生成替代候选人,并引入了四种高质量的功能来对替代候选人进行排名。实验结果表明,基于同义词的方法,基于预训练语言模型的方法和混合方法取得了较好的效果。我们相信,提出的CLS系统将成为强大的基线,并且创建的数据集可以加速对该主题的研究,以用于未来的研究。尽管在一项艰巨的任务上取得了一些初步的积极结果,但我们注意到CLS系统的性能可能会受到替代生成和替代排名的影响。NQ:将来,我们将一些先验知识纳入CLS的预训练语言模型中。
ACKNOWLEDGEMENT
本研究部分由国家自然科学基金资助61703362和91746209; 国家重点研究发展计划资助2016YFB1000900; 中国教育部长江学者和大学创新研究团队计划 (PCSIRT) 资助,IRT17R32;和中国江苏省自然科学基金赠款BK20170513。
References
[1] J. De Belder, M.-F. Moens, Text simplification for children, in: SIGIR Workshop, 2010, pp. 19–26.
[2] G. H. Paetzold, L. Specia, Unsupervised lexical simplification for nonnative speakers., in: AAAI, 2016, pp. 3761–3767.
[3] L. Feng, Automatic readability assessment for people with intellectual disabilities, ACM SIGACCESS accessibility and computing (93) (2009) 84–91.
[4] H. Saggion, Automatic text simplification, Synthesis Lectures on Human Language Technologies 10 (1) (2017) 1–137.
[5] J. Carroll, G. Minnen, Y. Canning, S. Devlin, J. Tait, Practical simplification of english newspaper text to assist aphasic readers, in: Proceedings of AAAI Workshop on Integrating Artificial Intelligence and Assistive Technology, 1998, pp. 7–10.
[6] G. Glavaˇs, S. Stajnerˇ , Simplifying lexical simplification: do we need simplified corpora?, in: ACL, 2015, pp. 63–68.
[7] G. Paetzold, L. Specia, Lexical simplification with neural ranking, in: Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, 2017, pp. 34–40.
[8] S. Gooding, E. Kochmar, Recursive context-aware lexical simplification, in: EMNLP-IJCNLP, 2019, pp. 4853–4863.
[9] J. Qiang, Y. Li, Y. Zhu, Y. Yuan, X. Wu, Lexical simplification with pretrained encoders, in: AAAI, 2020, pp. 8649–8656.
[10] T. Kajiwara, H. Matsumoto, K. Yamamoto, Selecting proper lexical paraphrase for children, in: ROCLING, 2013, pp. 59–73.
[11] T. Kajiwara, K. Yamamoto, Evaluation dataset and system for Japanese lexical simplification, in: Proceedings of the ACL-IJCNLP 2015 Student Research Workshop, 2015, pp. 35–40.
[12] S. Bott, L. Rello, B. Drndarevi´c, H. Saggion, Can spanish be simpler? lexsis: Lexical simplification for spanish, in: Proceedings of COLING 2012, 2012, pp. 357–374.
[13] L. Rello, R. Baeza-Yates, L. Dempere-Marco, H. Saggion, Frequent words improve readability and short words improve understandability for people with dyslexia, in: IFIP Conference on Human-Computer Interaction, 2013, pp. 203–219.
[14] E. Rennes, A. J¨onsson, A tool for automatic simplification of swedish texts, in: Proceedings of the 20th Nordic Conference of Computational Linguistics (NODALIDA 2015), 2015, pp. 317–320.
[15] S. M. Alu´ısio, C. Gasperin, Fostering digital inclusion and accessibility: the porsimples project for simplification of portuguese texts, in: Proceedings of the NAACL HLT 2010 Young Investigators Workshop on Computational Approaches to Languages of the Americas, Association for Computational Linguistics, 2010, pp. 46–53.
[16] J. Yang, What makes learning chinese characters difficult? the voice of students from english secondary schools, Journal of Chinese Writing Systems 2 (1) (2018) 35–41.
[17] S. W. Wong, P. P. Mok, K. K.-H. Chung, V. W. Leung, D. V. Bishop, B. W.-Y. Chow, Perception of native english reduced forms in chinese learners: Its role in listening comprehension and its phonological correlates, TESOL Quarterly 51 (1) (2017) 7–31.
[18] J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding, in: NAACL, 2018.
[19] M. Lesk, Automatic sense disambiguation using machine readable dictionaries: How to tell a pine cone from an ice cream cone, in: Proceedings of the 5th Annual International Conference on Systems Documentation, SIGDOC ’86, ACM, New York, NY, USA, 1986, pp. 24–26. doi:10.1145/318723.318728. URL http://doi.acm.org/10.1145/318723.318728
[20] E. Pavlick, C. Callison-Burch, Simple ppdb: A paraphrase database for simplification, in: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 2016, pp. 143–148.
[21] M. Maddela, W. Xu, A word-complexity lexicon and a neural readability ranking model for lexical simplification, in: EMNLP, 2018, pp. 3749– 3760.
[22] S. Devlin, J. Tait, The use of a psycholinguistic database in the simpli cation of text for aphasic readers, Linguistic Databases 1 (1998) 161–173.
[23] O. Biran, S. Brody, N. Elhadad, Putting it simply: a context-aware approach to lexical simplification, in: ACL, 2011, pp. 496–501.
[24] M. Yatskar, B. Pang, C. Danescu-Niculescu-Mizil, L. Lee, For the sake of simplicity: Unsupervised extraction of lexical simplifications from wikipedia, in: NAACL, 2010, pp. 365–368.
[25] C. Horn, C. Manduca, D. Kauchak, Learning a lexical simplifier using wikipedia, in: ACL (Short Papers), 2014, pp. 458–463.
[26] Y. Sun, S. Wang, Y. Li, S. Feng, X. Chen, H. Zhang, X. Tian, D. Zhu, H. Tian, H. Wu, ERNIE: enhanced representation through knowledge integration, CoRR abs/1904.09223. arXiv:1904.09223. URL http://arxiv.org/abs/1904.09223
[27] W. Zhou, T. Ge, K. Xu, F. Wei, M. Zhou, BERT-based lexical substitution, in: ACL, 2019, pp. 3368–3373.
28] G. H. Paetzold, L. Specia, A survey on lexical simplification, in: Journal of Artificial Intelligence Research, Vol. 60, 2017, pp. 549–593.
[29] R. Keskisarkka, Automatic text simplification via synonym replacement.
[30] T. Kodaira, T. Kajiwara, M. Komachi, Controlled and balanced dataset for Japanese lexical simplification, in: Proceedings of the ACL 2016 Student Research Workshop, Association for Computational Linguistics, Berlin, Germany, 2016, pp. 1–7. doi:10.18653/v1/P16-3001. URL https://www.aclweb.org/anthology/P16-3001
[31] H. Liu, S. Li, J. Zhao, Z. Bao, X. Bai, Chinese teaching material readability assessment with contextual information, in: International Conference on Asian Language Processing, 2017.
[32] K. Collinsthompson, Computational assessment of text readability: A survey of current and future research, ITL – International Journal of Applied Linguistics 165 (2) (2014) 97–135.
[33] J. Zhao, B. A. Zhang, J. Cheng, Some suggestions on the revision of the outline of the graded vocabulary for hsk, Chinese Teaching in the World.
[34] J. Mei, Y. Zhu, Y. Gao, et al., Tongyici cilin (extended), HIT IR-Lab.
[35] T. Mikolov, K. Chen, G. Corrado, J. Dean, Efficient estimation of word representations in vector space, arXiv preprint arXiv:1301.3781.
[36] L. Yuming, On green paper on language situation in china [j], Applied Linguistics 1.
[37] L. Bloomfield, A set of postulates for the science of language, Language 2 (3) (1926) 153–164.
[38] F. Qi, J. Huang, C. Yang, Z. Liu, X. Chen, Q. Liu, M. Sun, Modeling semantic compositionality with sememe knowledge, in: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 5706–5715.
[39] Y. Zhang, C. Yang, Z. Zhou, Z. Liu, Enhancing transformer with sememe knowledge, in: Proceedings of the 5th Workshop on Representation Learning for NLP, Association for Computational Linguistics, Online, 2020, pp. 177–184.
[40] Z. Dong, Q. Dong, C. Hao, Hownet and the computation of meaning.
[41] Q. Liu, Word similarity computing based on hownet, Computational linguistics and Chinese language processing 7 (2) (2002) 59–76.
自结1
本文为CLS手工创建了第一个基准数据集,提出基于同义词、词嵌入、预训练语言模型、义素和混合五种类型的方法,并对这些基线进行评估,讨论优缺点。这是对CLS任务的第一次研究。
两位具有教学经验的母语人士给出目标词,拿出句子和复杂词,请五个注释者给出简单替换词,一个人再进行整合去除不合适的替换词。再用五种方法生成简单替换词,再对其进行评估。
扬州大学研一在读学生,本篇笔记仅以帮助自己更好理解论文,也方便日后复查学习。 ↩︎