Linux内存管理第四章 -- 进程地址空间(Process Address Space)
文章目录
- Linux内存管理第四章 -- 进程地址空间(Process Address Space)
-
- Linear Address Space
- Managing the Address Space
- Process Address Space Descriptor
-
- Allocating a Descriptor
- Initialising a Descriptor
- Destroying a Descriptor
- Memory Regions
-
- Memory Region Operations
- File/Device backed memory regions
- Page Faulting
-
- Handling a Page Fault
- Demand Allocation
-
- Handling anonymous pages
- Handling file/device backed pages
- Demand Paging
- Copy On Write (COW) Pages
- Copying To/From Userspace
Linux内存管理第四章 – 进程地址空间(Process Address Space)
Linear Address Space
从user的观点来看,地址空间是一块平坦的线性地址空间,但可以预见的是从kernel的观点来看,地址空间却大有不同。虚拟地址空间被分割成两部分,userspace部分随着进程上下文的切换而改变但kernel space的部分始终保持不变。虚拟地址空间被切割的位置有宏PAGE_OFFSET决定,在x86上PAGE_OFFSET = 0xC0000000。即用户进程可用的虚拟地址空间是3GB,而另外1GB始终有kernel使用。kernel space的线性虚拟地址的概略图如下:
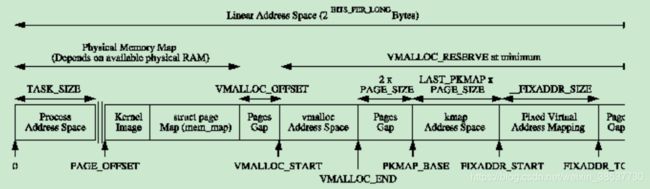
从PAGE_OFFSET开始的8MB(两个PGD所映射的内存空间)预留起来用于加载Linux内核镜像。对于UMA来说,在kernel image后有很短的间隔之后存放的是全局变量mem_map的地址。而mem_map的地址通常是16MB的位置从而避免使用ZONE_DMA,但也不是总是如此。而NUMA架构下,虚拟mem_map的部分内容将分散在该区域,其具体的位置有各架构决定。例如在X86下,硬件架构指定每个node的lmem_map的地址在数组node_remap_start_vaddr中,然后将node_remap_start_vaddr中的第一个地址赋值给mem_map。
Managing the Address Space
每个进程的进程描述符struct task_struct中的struct mm_struct用来管理用户虚拟地址空间。
每个地址空间有一系列页对齐的区域组成,这些区域不会重叠该区域代表一组地址,其中的page是相互关联的,这些区域用struct vm_area_struct来描述,一个region可能表示一个进程的堆供malloc()使用,也可能代表一个映射的文件如动态链接库。region中page仍然需要分配,设置active/resident/page out状态。
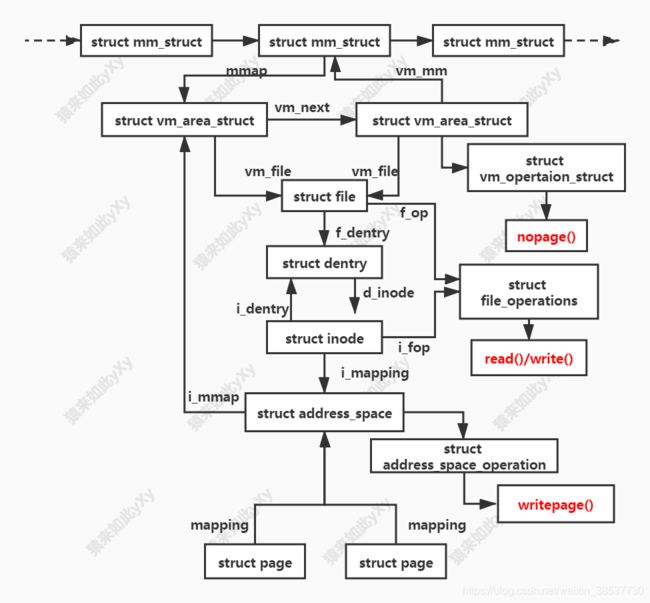
如果一个region代表一个映射文件,则它的vm_file字段将会被设置。通过遍历vm_file->f_dentry->d_inode->i_mapping,该region相关的address_space将被找到。address_space拥有磁盘上基于page操作所需要的所有信息。
以下是这些structures的关系:
Process Address Space Descriptor
一个进程的地址空间由struct mm_struct描述,这也就是说每个进程中只有一个mm_struct其它在用户线程中共享。
一个内核线程并不需要一个唯一的mm_struct,因为内核新城永远不会触发用户地址空间的缺页异常或者访问用户地址空间。但是有一个例外,当page fault发生在vmalloc虚拟地址段内,缺页异常的代码认为这是一个特殊的case,并使用master page table中的信息去更新当前进程的page table。由于内核线程并不需要mm_struct,所以内核线程的task_struct->mm字段总是NULL。
- lazy TLB
因为刷新TLB缓存代价非常昂贵,所以一种lazy TLB的技术被使用来避免不会访问用户地址空间的进程进行不必要的TLB刷新。因为内核地址空间的总是可见的。当调用switch_mm()会导致TLB刷新,但是它可以通过借用前一个task使用过的mm_struct,并把它放在task_struct->active_mm中来避免刷新TLB。这种技术极大提高了上下文切换的时间。
当要进入lazy TLB时,需要调用enter_lazy_tlb()来保证mm_struct不会再不同的处理器间共享。第二次需要使用lazy TLB的时候是当进程退出时等待其父进程的捕获会调用start_lazy_tlb().
mm_struct中有两种引用计数:mm_user和mm_count分别来表示两种类型的使用者。
- mm_user是指正在访问mm_struct中用户地址空间的进程数,如:page table和文件映射。用户空间的线程和swap_out()会增加mm_user的计数来保证mm_struct不会被提前销毁,当mm_user变成0之后,exit_mmap()会删除所有的映射和销毁所有的page table,然后再讲mm_count值减一。
- mm_count是指“匿名使用者”的引用计数。其初始化值为1。一个匿名使用者是指该使用者并不关心mm_struct用户地址空间的部分而仅仅是借用mm_struct.匿名使用者如使用lazy TLB的内核线程。当mm_count变成了0,该mm_struct才可以被安全地销毁。
使用两种引用计数的原因是当用户空间的映射全部被销毁后,匿名使用者仍然需要mm_struct的情况。没有一个位置可以延时销毁page tables。
struct mm_struct的定义如下,下面来看看重点字段的含义:
struct mm_struct {
struct vm_area_struct * mmap; /* list of VMAs */
struct rb_root mm_rb;
struct vm_area_struct * mmap_cache; /* last find_vma result */
unsigned long (*get_unmapped_area) (struct file *filp,unsigned long addr,
unsigned long len,unsigned long pgoff, unsigned long flags);
void (*unmap_area) (struct vm_area_struct *area);
unsigned long mmap_base; /* base of mmap area */
unsigned long free_area_cache; /* first hole */
pgd_t * pgd;
atomic_t mm_users; /* How many users with user space? */
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
int map_count; /* number of VMAs */
struct rw_semaphore mmap_sem;
spinlock_t page_table_lock; /* Protects task page tables and mm->rss */
struct list_head mmlist; /* List of all active mm's. These are globally strung
* together off init_mm.mmlist, and are protected by mmlist_lock */
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long rss, total_vm, locked_vm, shared_vm;
unsigned long exec_vm, stack_vm, reserved_vm, def_flags;
unsigned long saved_auxv[42]; /* for /proc/PID/auxv */
unsigned dumpable:1;
cpumask_t cpu_vm_mask;
/* Architecture-specific MM context */
mm_context_t context;
/* Token based thrashing protection. */
unsigned long swap_token_time;
char recent_pagein;
/* coredumping support */
int core_waiters;
struct completion *core_startup_done, core_done;
/* aio bits */
rwlock_t ioctx_list_lock;
struct kioctx *ioctx_list;
struct kioctx default_kioctx;
};
- mmap:用户地址空间中所有VMA的链表表头
- mm_rb:VMA结构形成的红黑树的跟节点,用于快速查找。
- mmap_cache:调用find_vma()后找到的VMA会放置在该字段,其目的是假想该VMA会快被再次使用。
- pgd:当前进程的PGD
- mm_count,mm_user:详细解释见上小节。
- mmlist:mm_struct通过此字段连接在一起。
- start_code, end_code:当前进程的代码段的起始地址和结束地址
- start_data, end_data:当前进程的数据段的起始地址和结束地址
- start_brk, brk:当前进程堆的起始地址和结束地址
- start_stack:当前进程栈的起始地址
- arg_start, arg_end:当前进程命令行参数的起始地址和结束地址
- env_start, env_end:当前进程环境变量的起始地址和结束地址
- rss:Resident Set Size是指当前进程中存在的page的个数,不包括global zero page。
- total_vm:当前进程所有VMA region所占用的总内存空间大小
- locked_vm:resident page中被lock的个数
- swap_address:当一个进程被全部被换出时,pageout守护进程用来记录上一个被换出的地址
Allocating a Descriptor
有两个函数用来分配一个mm_struct.
- allocate_mm()该宏函数用来从slab allocator中分配一个mm_struct
- mm_alloc()从slab中分配mm_struct后再调用mm_init()将其初始化
Initialising a Descriptor
系统中最初始的mm_struct 叫init_mm,它使用宏INIT_MM()来静态地初始化:
struct mm_struct init_mm = INIT_MM(init_mm);
#define INIT_MM(name) \
{ \
.mm_rb = RB_ROOT, \
.pgd = swapper_pg_dir, \
.mm_users = ATOMIC_INIT(2), \
.mm_count = ATOMIC_INIT(1), \
.mmap_sem = __RWSEM_INITIALIZER(name.mmap_sem), \
.page_table_lock = SPIN_LOCK_UNLOCKED, \
.mmlist = LIST_HEAD_INIT(name.mmlist), \
.cpu_vm_mask = CPU_MASK_ALL, \
.default_kioctx = INIT_KIOCTX(name.default_kioctx, name), \
}
当初始的mm_struct初始化完成后,新的mm_struct会以它们的父mm_struct为模板而被创建。copy_mm()就是用来复制mm_struct,然后条用mm_init()来初始化进程特殊的字段。
Destroying a Descriptor
使用atomic_inc(&mm->mm_users)来增加mm_struct用户空间的引用计数,相对应的使用mmput()来减少引用计数。如果mm_users的引用计数到达0,exit_mmap()会销毁所有被映射的VMA regions和销毁page tables因此此时已经没有用户空间的使用者了。
此时再来使用mmdrop()来讲mm_count减一,因为所有用户空间的使用者被当成是mm_count中的一个计数。当mm_count变为0后,便可销毁mm_struct 了。
void mmput(struct mm_struct *mm)
{
if (atomic_dec_and_lock(&mm->mm_users, &mmlist_lock)) {
list_del(&mm->mmlist);
mmlist_nr--;
spin_unlock(&mmlist_lock);
exit_aio(mm);
exit_mmap(mm);
put_swap_token(mm);
mmdrop(mm);
}
}
Memory Regions
进程地址空间中全部的地址很少被使用,只有很少的regions被使用。Linux用struct vm_area_struct来描述一个VMA。下面来看看VMA的结构和重要字段的含义:
struct vm_area_struct {
struct mm_struct * vm_mm; /* The address space we belong to. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* Flags, listed below. */
struct rb_node vm_rb;
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap prio tree, or
* linkage to the list of like vmas hanging off its node, or
* linkage of vma in the address_space->i_mmap_nonlinear list.
*/
union {
struct {
struct list_head list;
void *parent; /* aligns with prio_tree_node parent */
struct vm_area_struct *head;
} vm_set;
struct prio_tree_node prio_tree_node;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_node; /* Serialized by anon_vma->lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
struct vm_operations_struct * vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE units, *not* PAGE_CACHE_SIZE */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
};
- vm_mm:当前VMA所属的mm_struct
- vm_start,vm_end:当前VMA的起始和结束地址
- vm_next:地址空间中所有的VMA按照地址大小排序通过此字段单向连接起来
- vm_page_prot:VMA中所有PTE的保护标志位
- vm_flags:一组标志位用来保护和控制VMA的属性
- vm_rb:所有VMA构成的红黑树,用于快速查找
- vm_next_share,vm_ppre_share:基于文件映射的共享VMA使用此字段连接在一起
- vm_ops:此字段包含的函数指针有:open(),close(),nopage()。它们用作与磁盘同步信息。
- vm_pgoff:当一个文件有内存映射时,该字段表示该region中的内容在整个文件中的偏移
- vm_file:此字段指向一个内存映射的struct file结构
Memory Region Operations
我们来看下vm_operations_struct的定义:
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);
void (*close)(struct vm_area_struct * area);
struct page * (*nopage)(struct vm_area_struct * area, unsigned long address, int unused);
};
其中open()和close()每次在region被创建和被删除时被调用。这两个函数只有被很少的设备和一个文件系统以及SystemV使用。其中SystemV共享内存使用open()回调函数来增加VMA的个数。
其中最主要的回调函数是nopage()。当page fault产生是do_no_page()会调用nopage()这个回调函数,该函数的目的是从page cache中拿到page或者分配一个新的page然后返回地址。
大多数的内存映射的文件对应的vma会注册一个vm_opetaionts_struct叫做generic_file_vm_ops,它注册了一个nopage()回调:
struct vm_operations_struct generic_file_vm_ops = {
.nopage = filemap_nopage,
.populate = filemap_populate,
};
我们来看看share memory VMA的operation:
static struct vm_operations_struct shm_vm_ops = {
.open = shm_open, /* callback for a new vm-area open */
.close = shm_close, /* callback for when the vm-area is released */
.nopage = shmem_nopage,
#ifdef CONFIG_NUMA
.set_policy = shmem_set_policy,
.get_policy = shmem_get_policy,
#endif
};
File/Device backed memory regions
如果一个VMA对应了一个文件映射,那么通过vm_file字段会找到一个对应的address_space的结构,该结构包含文件系统相关的信息如需要回写到磁盘的脏页。
首先来看下address_space的定义:
struct address_space {
struct inode *host; /* owner: inode, block_device */
struct radix_tree_root page_tree; /* radix tree of all pages */
spinlock_t tree_lock; /* and spinlock protecting it */
unsigned int i_mmap_writable;/* count VM_SHARED mappings */
struct prio_tree_root i_mmap; /* tree of private and shared mappings */
struct list_head i_mmap_nonlinear;/*list VM_NONLINEAR mappings */
spinlock_t i_mmap_lock; /* protect tree, count, list */
atomic_t truncate_count; /* Cover race condition with truncate */
unsigned long nrpages; /* number of total pages */
pgoff_t writeback_index;/* writeback starts here */
struct address_space_operations *a_ops; /* methods */
unsigned long flags; /* error bits/gfp mask */
struct backing_dev_info *backing_dev_info; /* device readahead, etc */
spinlock_t private_lock; /* for use by the address_space */
struct list_head private_list; /* ditto */
struct address_space *assoc_mapping; /* ditto */
};
struct address_space_operations {
int (*writepage)(struct page *page, struct writeback_control *wbc);
int (*readpage)(struct file *, struct page *);
int (*sync_page)(struct page *);
/* Write back some dirty pages from this mapping. */
int (*writepages)(struct address_space *, struct writeback_control *);
/* Set a page dirty */
int (*set_page_dirty)(struct page *page);
int (*readpages)(struct file *filp, struct address_space *mapping,
struct list_head *pages, unsigned nr_pages);
/*
* ext3 requires that a successful prepare_write() call be followed
* by a commit_write() call - they must be balanced
*/
int (*prepare_write)(struct file *, struct page *, unsigned, unsigned);
int (*commit_write)(struct file *, struct page *, unsigned, unsigned);
/* Unfortunately this kludge is needed for FIBMAP. Don't use it */
sector_t (*bmap)(struct address_space *, sector_t);
int (*invalidatepage) (struct page *, unsigned long);
int (*releasepage) (struct page *, int);
ssize_t (*direct_IO)(int, struct kiocb *, const struct iovec *iov,
loff_t offset, unsigned long nr_segs);
};
- writepage:写一个page到磁盘,每个page所对应的文件偏移可以在struct page中找到。
- readpage:从磁盘中读取一个page
- sync_page:将脏页同步到磁盘
- prepare_write:将用户空间的数据copy到要回写磁盘的一个page之前,调用这个函数。
- commit_write:从用户空间copy数据后,该函数用于提交信息到磁盘
- bmap:操作raw IO
- flushpage:保证在释放一个page前没有pending的IO
- releasepage:在释放一个page前,尝试刷新一个page对应的所有buff
- direct_IO:This function is used when performing direct IO to an inode
- direct_fileIO:Used to perform direct IO with a struct file
我们来看看共享内存文件系统的address_space operations:
static struct address_space_operations shmem_aops = {
.writepage = shmem_writepage,
.set_page_dirty = __set_page_dirty_nobuffers,
#ifdef CONFIG_TMPFS
.prepare_write = shmem_prepare_write,
.commit_write = simple_commit_write,
#endif
};
Page Faulting
进程线性地址空间中的页不一定要驻留在内存中。例如,进程中的内存分配内核不会立即满足分配对应的物理内存而是将线性地址使用vm_area_struct预留。还比如被交换到磁盘上的page。
Linux和其他大多数操作系统一样,拥有按需获取内存的策略,具体的做法是处理不再内存中的page。这就说明仅当硬件触发缺页异常操作系统捕获异常后并分配页,然互才会从磁盘上读取page到内存中。在Linux中,当一个page从交换区置换到主内存中,其后面的多个page页会被同时读入到swap_cache中。
当前主要有两种类型的page fault:major fault 和minor fault。
- major fault是指当执行数据从不得不从磁盘中读取的这种昂贵操作时发生的缺页异常
- minor fault是指除了major fault的缺页异常都是minor fault.
Linux中处理以下异常的方式:
| Exception | Type | Action |
|---|---|---|
| vma region合法但page没有分配 | Minor | 从物理地址分配器中分配一个页框 |
| vma region不合法但在可扩展region的边上如stack | Minor | 扩展该region并且分配page |
| page被换出但在swap缓存中 | Minor | 在进程页表中重新创建page并且丢弃对swap缓存的引用 |
| page被换出到磁盘介质上了 | Major | 使用PTE中的信息从磁盘上读回page |
| 写只读页 | Minor | 如果该page是一个COW页,则copy一份并置为可写映射到进程当前地址空间,如果是非法写,则发送SIG_SEGV |
| region不合法或者进程没有访问权限 | Error | 发送SIG_SEGV |
| 缺页异常发生在内核地址空间 | Minor | 如果发生缺页异常的地址是在vmalloc地址空间,那么当前进程的页表将会被主内核页表swapper_pg_dir中的内容更新,这是内核唯一合法的缺页异常 |
| 缺页异常发生在用户地址空间但当前处于内核模式 | Error | 如果缺页异常发生,这就意味着内核系统并没有从用户空间拷贝并且引发缺页异常,这是内核的一个bug |
每种架构都会注册自己的处理缺页异常的函数。虽然这个函数的名称是任意的,但通常的选择是do_page_fault(),其调用草图如下:
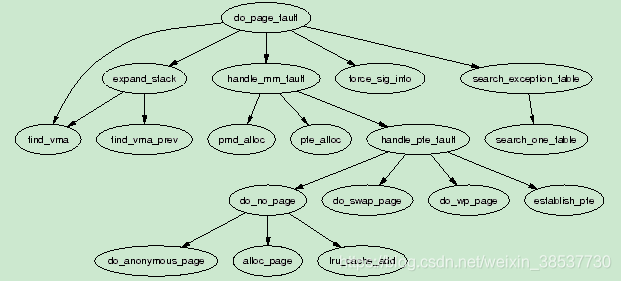
该函数中提供了丰富的信息,如发生缺页异常的地址,是简单的地找到不到page还是访问权限的问题,或者是读或者写错误,再或者该地址是用户空间还是内核空间。该函数的作用是要决定当前发生的是哪种错误并如何处理。其流程如下:
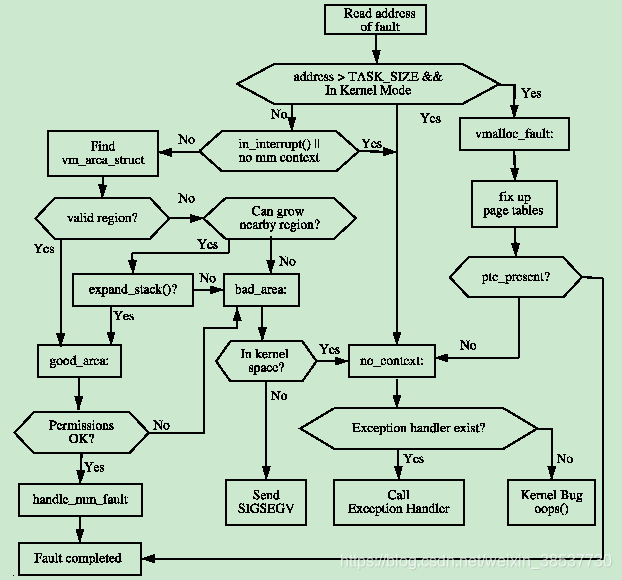
handle_mm_fault()函数来处理用户空间的缺页异常如:COW page,swapped out page等。其返回值的含义:
- 1,minor fault
- 2,major fault
- 0,错误
- other, 则会触发out of memory处理函数
Handling a Page Fault
一旦缺页处理函数决定当前缺页异常是一个合法的缺页异常,handle_mm_fault()将会被执行。
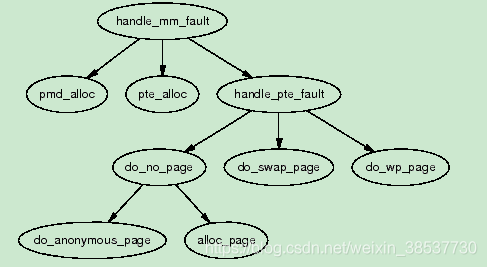
如下图所示handle_mm_fault()中会根据PTE的属性来选择调用另外三个函数。首先第一步的决定是通过检查PTE是否存在(pte_present())或者是否已分配(pte_none())。
- Demand Allocation:如果PTE没有被分配及pte_none()返回True,do_no_page() & do_file_page()将被调用来处理Demand Allocation。
- Demend Paging:如果是一个被交换到磁盘中的page,则调用do_swap_page()处理Demend Paging
- COW page:如果是一个写保护的page,且要发生写的动作,则调用do_wp_page()来处理COW page.一个COW page是指被多个进程共享的page直到一个写事件发生然后就copy这个page到写进程的地址空间。一个COW page能够被识别是因为即使PTE有写保护,VMA也会被标记为可写。如果不是一个COW page,因为有写入,该page将会标记为dirty。
- 最后如果一个page被读且存在但仍然发生错误,是因为有些架构没有三级页表。在这种case中,就直接新建PTE,然后标记为young。
Demand Allocation
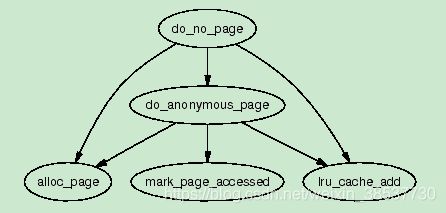
当一个进程在最开始的时候来访问一个page,系统将会通过do_no_page()函数来分配页并将数据填充到page中。如果当前vma->vm_ops为NULL,则是匿名page,如果不为NULL,则是file/device backed page。下面分别来看这两种情况:
Handling anonymous pages
当vm_area_struct->vm_ops字段为空或者没有提供nopage()函数,则调用do_anonymous_page()来处理这次匿名访问。在这种case下只有两种情况first read和first write
- first read:因为是第一次读所以是没有数据的,因此只要把全局的empty_zero_page映射到该地址对应的PTE上,并且该PTE注上写保护。因此当写事件发生时,因为写保护所以会再次发生page fault。在x86中全局empty_zero_page 是在mem_init()中定义的。
- first write:如果是第一次写,则会调用alloc_page()来分配一个空闲的page然后调用clear_user_highpage()将其填0。假设page被成功分配,则mm_struct中rss(Resident Set Size)字段将会加上一。在某些架构下当一个page插入到进程的用户地址空间中时会调用flush_page_to_ram()来保证缓存的相干性。然后将该page插入到LRU list中一边后续内存回收代码可以回收这个page。
Handling file/device backed pages
如果一个地址有映射一个file或者device,vm_operation_struct中的vm_ops必须提供nopage()函数。nopage()函数负责分配一个page并从磁盘中读出一个page的数据到该内存中。
当返回page之后,首先检查page分配过程中是否出错,再来检查是否有early COW break发生。如果此次的page fault是以此写操作并且VMA的flag中并未设置VM_SHARED,此时即表明一个early COW break发生了。early COW break是在减少该page的引用计数之前,分配一个新page并复制数据。(不太理解…)
然后再检查该PTE是否存在,如果不存在生成PTE并映射到page table中。
Demand Paging
当一个page被交换到磁盘中时,do_swap_page()函数负责将该page再读回来。通过PTE中的信息就可以找到该page在swap_cache中的位置。因为一个page可能在多个进程中被共享,所以他们不可能立即被换出到磁盘上,而是把他们放置在swap cache中。
因为有了swap cache的存在,因此当一个page fault发生的时候,该page可能存在于swap cache中。如果确实如此,则增加该page的引用计数然后把它放置到进程的page table中,然后注册一个minor page fault。
如果该page在磁盘上,则调用read_swap_cache_async()将数据读回,然后再将该page重新放置在进程的page table中。
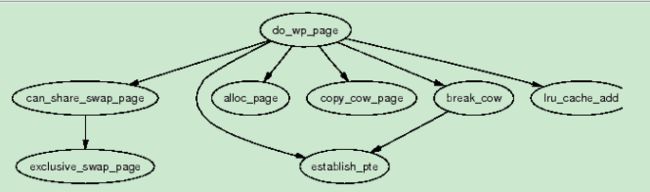
Copy On Write (COW) Pages
当fork一个进程的时候,子进程会全部复制父进程的地址空间。但这是一种非常昂贵的操作,因此COW计数被用上了。
在fork的过程中,两个进程的PTE全部标记为只读,因此当有一个写动作发生时,提供会产生一个page fault。Linux之所以能识别COW page是因为尽管PTE是写保护但是其对应的VMA region是可以写的。然后调用do_wp_page()函数来赋值一个page然后将其填充到写进程的地址空间中。使用COW进行fork的时候,page table需要拷贝,而对应的数据不用拷贝。
Copying To/From Userspace
在进程地址空间中直接访问物理内存时不安全的因为没有办法快速检查地址对应的page是否存在。当进程访问不合法的地址时,Linux依赖MMU上报异常然后通过page fault处理函数来处理异常。在x86 case下,当遇到一个完全无法使用的地址时,有提供一个汇编函数__copy_usr()来追踪异常。当调用search_exception_table()函数时就可以找到对应修复代码的位置。Linux提供了一些宏函函数供内核态程序安全地从用户空间拷贝数据或者拷贝数据到用户空间,常见的有:
unsigned long copy_from_user(void *to, const void *from, unsigned long n);
unsigned long copy_to_user(void *to, const void *from, unsigned long n);
在编译阶段,链接器会在内核代码段__ex_table中创建exception_table,__ex_table段的起始地址为__start___ex_table,结束地址为__stop___ex_table.。exception table中的每一项对应一个结构struct exception_table_entry
struct exception_table_entry {
unsigned long insn, fixup;
};
当遇到真正非法的地址,page fault handler会通过search_exception_table()来查找该地址是否有对应的修复代码,如果有就执行修复代码。
其核心步骤分为三步:
- first:汇编函数负责从用户空间拷贝实际需要size的数据,如果page不存在,page fault将会发生,如果地址合法,则page fault函数会自动处理好
- second:修复代码
- third:通过_ex_table的映射关系,找到修复代码,执行修复代码