python协程(超详细)
1、迭代
1.1 迭代的概念
使用for循环遍历取值的过程叫做迭代,比如:使用for循环遍历列表获取值的过程
# Python 中的迭代
for value in [2, 3, 4]:
print(value)
1.2 可迭代对象
标准概念:在类里面定义
__iter__方法,并使用该类创建的对象就是可迭代对象简单记忆:使用for循环遍历取值的对象叫做可迭代对象, 比如:列表、元组、字典、集合、range、字符串
1.3 判断对象是否是可迭代对象
# 元组,列表,字典,字符串,集合,range都是可迭代对象
from collections import Iterable
# 如果解释器提示警告,就是用下面的导入方式
# from collections.abc import Iterable
# 判断对象是否是指定类型
result = isinstance((3, 5), Iterable)
print("元组是否是可迭代对象:", result)
result = isinstance([3, 5], Iterable)
print("列表是否是可迭代对象:", result)
result = isinstance({"name": "张三"}, Iterable)
print("字典是否是可迭代对象:", result)
result = isinstance("hello", Iterable)
print("字符串是否是可迭代对象:", result)
result = isinstance({3, 5}, Iterable)
print("集合是否是可迭代对象:", result)
result = isinstance(range(5), Iterable)
print("range是否是可迭代对象:", result)
result = isinstance(5, Iterable)
print("整数是否是可迭代对象:", result)
# 提示: 以后还根据对象判断是否是其它类型,比如以后可以判断函数里面的参数是否是自己想要的类型
result = isinstance(5, int)
print("整数是否是int类型对象:", result)
class Student(object):
pass
stu = Student()
result = isinstance(stu, Iterable)
print("stu是否是可迭代对象:", result)
result = isinstance(stu, Student)
print("stu是否是Student类型的对象:", result)
1.4 自定义可迭代对象
在类中实现
__iter__方法
自定义可迭代类型代码
from collections import Iterable
# 如果解释器提示警告,就是用下面的导入方式
# from collections.abc import Iterable
# 自定义可迭代对象: 在类里面定义__iter__方法创建的对象就是可迭代对象
class MyList(object):
def __init__(self):
self.my_list = list()
# 添加指定元素
def append_item(self, item):
self.my_list.append(item)
def __iter__(self):
# 可迭代对象的本质:遍历可迭代对象的时候其实获取的是可迭代对象的迭代器, 然后通过迭代器获取对象中的数据
pass
my_list = MyList()
my_list.append_item(1)
my_list.append_item(2)
result = isinstance(my_list, Iterable)
print(result)
for value in my_list:
print(value)
执行结果:
Traceback (most recent call last):
True
File "/Users/hbin/Desktop/untitled/aa.py", line 24, in
for value in my_list:
TypeError: iter() returned non-iterator of type 'NoneType'
通过执行结果可以看出来,遍历可迭代对象依次获取数据需要迭代器
总结
在类里面提供一个__iter__创建的对象是可迭代对象,可迭代对象是需要迭代器完成数据迭代的
2、迭代器
2.1 自定义迭代器对象
自定义迭代器对象: 在类里面定义
__iter__和__next__方法创建的对象就是迭代器对象
from collections import Iterable
from collections import Iterator
# 自定义可迭代对象: 在类里面定义__iter__方法创建的对象就是可迭代对象
class MyList(object):
def __init__(self):
self.my_list = list()
# 添加指定元素
def append_item(self, item):
self.my_list.append(item)
def __iter__(self):
# 可迭代对象的本质:遍历可迭代对象的时候其实获取的是可迭代对象的迭代器, 然后通过迭代器获取对象中的数据
my_iterator = MyIterator(self.my_list)
return my_iterator
# 自定义迭代器对象: 在类里面定义__iter__和__next__方法创建的对象就是迭代器对象
class MyIterator(object):
def __init__(self, my_list):
self.my_list = my_list
# 记录当前获取数据的下标
self.current_index = 0
# 判断当前对象是否是迭代器
result = isinstance(self, Iterator)
print("MyIterator创建的对象是否是迭代器:", result)
def __iter__(self):
return self
# 获取迭代器中下一个值
def __next__(self):
if self.current_index < len(self.my_list):
self.current_index += 1
return self.my_list[self.current_index - 1]
else:
# 数据取完了,需要抛出一个停止迭代的异常
raise StopIteration
my_list = MyList()
my_list.append_item(1)
my_list.append_item(2)
result = isinstance(my_list, Iterable)
print(result)
for value in my_list:
print(value)
运行结果:
True
MyIterator创建的对象是否是迭代器: True
1
2
2.2 iter()函数与next()函数
- iter函数: 获取可迭代对象的迭代器,会调用可迭代对象身上的
__iter__方法 - next函数: 获取迭代器中下一个值,会调用迭代器对象身上的
__next__方法
# 自定义可迭代对象: 在类里面定义__iter__方法创建的对象就是可迭代对象
class MyList(object):
def __init__(self):
self.my_list = list()
# 添加指定元素
def append_item(self, item):
self.my_list.append(item)
def __iter__(self):
# 可迭代对象的本质:遍历可迭代对象的时候其实获取的是可迭代对象的迭代器, 然后通过迭代器获取对象中的数据
my_iterator = MyIterator(self.my_list)
return my_iterator
# 自定义迭代器对象: 在类里面定义__iter__和__next__方法创建的对象就是迭代器对象
# 迭代器是记录当前数据的位置以便获取下一个位置的值
class MyIterator(object):
def __init__(self, my_list):
self.my_list = my_list
# 记录当前获取数据的下标
self.current_index = 0
def __iter__(self):
return self
# 获取迭代器中下一个值
def __next__(self):
if self.current_index < len(self.my_list):
self.current_index += 1
return self.my_list[self.current_index - 1]
else:
# 数据取完了,需要抛出一个停止迭代的异常
raise StopIteration
# 创建了一个自定义的可迭代对象
my_list = MyList()
my_list.append_item(1)
my_list.append_item(2)
# 获取可迭代对象的迭代器
my_iterator = iter(my_list)
print(my_iterator)
# 获取迭代器中下一个值
# value = next(my_iterator)
# print(value)
# 循环通过迭代器获取数据
while True:
try:
value = next(my_iterator)
print(value)
except StopIteration as e:
break
2.3 for循环的本质
遍历的是可迭代对象
- for item in Iterable 循环的本质就是先通过iter()函数获取可迭代对象Iterable的迭代器,然后对获取到的迭代器不断调用next()方法来获取下一个值并将其赋值给item,当遇到StopIteration的异常后循环结束。
遍历的是迭代器
- for item in Iterator 循环的迭代器,不断调用next()方法来获取下一个值并将其赋值给item,当遇到StopIteration的异常后循环结束。
2.4 迭代器的应用场景
我们发现迭代器最核心的功能就是可以通过next()函数的调用来返回下一个数据值。如果每次返回的数据值不是在一个已有的数据集合中读取的,而是通过程序按照一定的规律计算生成的,那么也就意味着可以不用再依赖一个已有的数据集合,也就是说不用再将所有要迭代的数据都一次性缓存下来供后续依次读取,这样可以节省大量的存储(内存)空间。
举个例子,比如,数学中有个著名的斐波拉契数列(Fibonacci),数列中第一个数为0,第二个数为1,其后的每一个数都可由前两个数相加得到:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, …
现在我们想要通过for…in…循环来遍历迭代斐波那契数列中的前n个数。那么这个斐波那契数列我们就可以用迭代器来实现,每次迭代都通过数学计算来生成下一个数。
class Fibonacci(object):
def __init__(self, num):
# num:表示生成多少fibonacci数字
self.num = num
# 记录fibonacci前两个值
self.a = 0
self.b = 1
# 记录当前生成数字的索引
self.current_index = 0
def __iter__(self):
return self
def __next__(self):
if self.current_index < self.num:
result = self.a
self.a, self.b = self.b, self.a + self.b
self.current_index += 1
return result
else:
raise StopIteration
fib = Fibonacci(5)
# value = next(fib)
# print(value)
for value in fib:
print(value)
执行结果:
0
1
1
2
3
小结
迭代器的作用就是是记录当前数据的位置以便获取下一个位置的值
3、生成器
3.1 生成器的概念
生成器是一类特殊的迭代器,它不需要再像上面的类一样写
__iter__()和__next__()方法了, 使用更加方便,它依然可以使用next函数和for循环取值
3.2 创建生成器方法1
- 第一种方法很简单,只要把一个列表生成式的 [ ] 改成 ( )
my_list = [i * 2 for i in range(5)]
print(my_list)
# 创建生成器
my_generator = (i * 2 for i in range(5))
print(my_generator)
# next获取生成器下一个值
# value = next(my_generator)
#
# print(value)
for value in my_generator:
print(value)
执行结果:
[0, 2, 4, 6, 8]
at 0x101367048>
0
2
4
6
8
3.3 创建生成器方法2
在def函数里面看到有yield关键字那么就是生成器
def fibonacci(num):
a = 0
b = 1
# 记录生成fibonacci数字的下标
current_index = 0
print("--11---")
while current_index < num:
result = a
a, b = b, a + b
current_index += 1
print("--22---")
# 代码执行到yield会暂停,然后把结果返回出去,下次启动生成器会在暂停的位置继续往下执行
yield result
print("--33---")
fib = fibonacci(5)
value = next(fib)
print(value)
value = next(fib)
print(value)
value = next(fib)
print(value)
# for value in fib:
# print(value)
在使用生成器实现的方式中,我们将原本在迭代器__next__方法中实现的基本逻辑放到一个函数中来实现,但是将每次迭代返回数值的return换成了yield,此时新定义的函数便不再是函数,而是一个生成器了。
简单来说:只要在def中有yield关键字的 就称为 生成器
3.4 生成器使用return关键字
def fibonacci(num):
a = 0
b = 1
# 记录生成fibonacci数字的下标
current_index = 0
print("--11---")
while current_index < num:
result = a
a, b = b, a + b
current_index += 1
print("--22---")
# 代码执行到yield会暂停,然后把结果返回出去,下次启动生成器会在暂停的位置继续往下执行
yield result
print("--33---")
return "嘻嘻"
fib = fibonacci(5)
value = next(fib)
print(value)
# 提示: 生成器里面使用return关键字语法上没有问题,但是代码执行到return语句会停止迭代,抛出停止迭代异常
# return 和 yield的区别
# yield: 每次启动生成器都会返回一个值,多次启动可以返回多个值,也就是yield可以返回多个值
# return: 只能返回一次值,代码执行到return语句就停止迭代
try:
value = next(fib)
print(value)
except StopIteration as e:
# 获取return的返回值
print(e.value)
提示:
- 生成器里面使用return关键字语法上没有问题,但是代码执行到return语句会停止迭代,抛出停止迭代异常
3.5 yield和return的对比
- 使用了yield关键字的函数不再是函数,而是生成器。(使用了yield的函数就是生成器)
- 代码执行到yield会暂停,然后把结果返回出去,下次启动生成器会在暂停的位置继续往下执行
- 每次启动生成器都会返回一个值,多次启动可以返回多个值,也就是yield可以返回多个值
- return只能返回一次值,代码执行到return语句就停止迭代,抛出停止迭代异常
3.6 使用send方法启动生成器并传参
send方法启动生成器的时候可以传参数
def gen():
i = 0
while i<5:
temp = yield i
print(temp)
i+=1
执行结果:
In [43]: f = gen()
In [44]: next(f)
Out[44]: 0
In [45]: f.send('haha')
haha
Out[45]: 1
In [46]: next(f)
None
Out[46]: 2
In [47]: f.send('haha')
haha
Out[47]: 3
In [48]:
**注意:如果第一次启动生成器使用send方法,那么参数只能传入None,一般第一次启动生成器使用next函数
小结
- 生成器创建有两种方式,一般都使用yield关键字方法创建生成器
- yield特点是代码执行到yield会暂停,把结果返回出去,再次启动生成器在暂停的位置继续往下执行
4、协程
4.1 协程的概念
协程,又称微线程,纤程,也称为用户级线程,在不开辟线程的基础上完成多任务,也就是在单线程的情况下完成多任务,多个任务按照一定顺序交替执行 通俗理解只要在def里面只看到一个yield关键字表示就是协程
协程是也是实现多任务的一种方式
协程yield的代码实现
简单实现协程
import time
def work1():
while True:
print("----work1---")
yield
time.sleep(0.5)
def work2():
while True:
print("----work2---")
yield
time.sleep(0.5)
def main():
w1 = work1()
w2 = work2()
while True:
next(w1)
next(w2)
if __name__ == "__main__":
main()
运行结果:
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
...省略...
小结
协程之间执行任务按照一定顺序交替执行
5、greenlet
5.1 greentlet的介绍
为了更好使用协程来完成多任务,python中的greenlet模块对其封装,从而使得切换任务变的更加简单
使用如下命令安装greenlet模块:
pip3 install greenlet
使用协程完成多任务
import time
import greenlet
# 任务1
def work1():
for i in range(5):
print("work1...")
time.sleep(0.2)
# 切换到协程2里面执行对应的任务
g2.switch()
# 任务2
def work2():
for i in range(5):
print("work2...")
time.sleep(0.2)
# 切换到第一个协程执行对应的任务
g1.switch()
if __name__ == '__main__':
# 创建协程指定对应的任务
g1 = greenlet.greenlet(work1)
g2 = greenlet.greenlet(work2)
# 切换到第一个协程执行对应的任务
g1.switch()
运行效果
work1...
work2...
work1...
work2...
work1...
work2...
work1...
work2...
work1...
work2...
6、gevent
6.1 gevent的介绍
greenlet已经实现了协程,但是这个还要人工切换,这里介绍一个比greenlet更强大而且能够自动切换任务的第三方库,那就是gevent。
gevent内部封装的greenlet,其原理是当一个greenlet遇到IO(指的是input output 输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。
由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO
安装
pip3 install gevent
6.2 gevent的使用
import gevent
def work(n):
for i in range(n):
# 获取当前协程
print(gevent.getcurrent(), i)
g1 = gevent.spawn(work, 5)
g2 = gevent.spawn(work, 5)
g3 = gevent.spawn(work, 5)
g1.join()
g2.join()
g3.join()
运行结果
0
0
0
1
1
1
2
2
2
3
3
3
4
4
4
可以看到,3个greenlet是依次运行而不是交替运行
6.3 gevent切换执行
import gevent
def work(n):
for i in range(n):
# 获取当前协程
print(gevent.getcurrent(), i)
#用来模拟一个耗时操作,注意不是time模块中的sleep
gevent.sleep(1)
g1 = gevent.spawn(work, 5)
g2 = gevent.spawn(work, 5)
g3 = gevent.spawn(work, 5)
g1.join()
g2.join()
g3.join()
运行结果
0
0
0
1
1
1
2
2
2
3
3
3
4
4
4
6.4 给程序打补丁
import gevent
import time
from gevent import monkey
# 打补丁,让gevent框架识别耗时操作,比如:time.sleep,网络请求延时
monkey.patch_all()
# 任务1
def work1(num):
for i in range(num):
print("work1....")
time.sleep(0.2)
# gevent.sleep(0.2)
# 任务1
def work2(num):
for i in range(num):
print("work2....")
time.sleep(0.2)
# gevent.sleep(0.2)
if __name__ == '__main__':
# 创建协程指定对应的任务
g1 = gevent.spawn(work1, 3)
g2 = gevent.spawn(work2, 3)
# 主线程等待协程执行完成以后程序再退出
g1.join()
g2.join()
运行结果
work1....
work2....
work1....
work2....
work1....
work2....
6.5 注意
- 当前程序是一个死循环并且还能有耗时操作,就不需要加上join方法了,因为程序需要一直运行不会退出
示例代码
import gevent
import time
from gevent import monkey
# 打补丁,让gevent框架识别耗时操作,比如:time.sleep,网络请求延时
monkey.patch_all()
# 任务1
def work1(num):
for i in range(num):
print("work1....")
time.sleep(0.2)
# gevent.sleep(0.2)
# 任务1
def work2(num):
for i in range(num):
print("work2....")
time.sleep(0.2)
# gevent.sleep(0.2)
if __name__ == '__main__':
# 创建协程指定对应的任务
g1 = gevent.spawn(work1, 3)
g2 = gevent.spawn(work2, 3)
while True:
print("主线程中执行")
time.sleep(0.5)
执行结果:
主线程中执行work1....work2....work1....work2....work1....work2....主线程中执行主线程中执行主线程中执行..省略..
-
如果使用的协程过多,如果想启动它们就需要一个一个的去使用join()方法去阻塞主线程,这样代码会过于冗余,可以使用gevent.joinall()方法启动需要使用的协程
实例代码
import time
import gevent
def work1():
for i in range(5):
print("work1工作了{}".format(i))
gevent.sleep(1)
def work2():
for i in range(5):
print("work2工作了{}".format(i))
gevent.sleep(1)
if __name__ == '__main__':
w1 = gevent.spawn(work1)
w2 = gevent.spawn(work2)
gevent.joinall([w1, w2]) # 参数可以为list,set或者tuple
7、进程、线程、协程对比
7.1 进程、线程、协程之间的关系
- 一个进程至少有一个线程,进程里面可以有多个线程
- 一个线程里面可以有多个协程
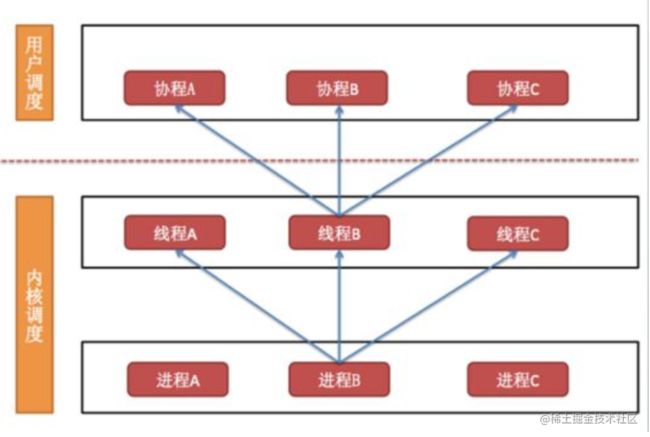
7.2 进程、线程、线程的对比
- 进程是资源分配的单位
- 线程是操作系统调度的单位
- 进程切换需要的资源最大,效率很低
- 线程切换需要的资源一般,效率一般(当然了在不考虑GIL的情况下)
- 协程切换任务资源很小,效率高
- 多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中 所以是并发
小结
-
进程、线程、协程都是可以完成多任务的,可以根据自己实际开发的需要选择使用
-
由于线程、协程需要的资源很少,所以使用线程和协程的几率最大
-
开辟协程需要的资源最少
本文转自 https://juejin.cn/post/6971037591952949256,如有侵权,请联系删除。