Pytorch ----- 数据集 (dataset) 数据加载器 (dataloader) num_workeres工作原理 及调整方法 ~~学习笔记
num_workeres 的工作原理及调整方法在最后。
数据集 (dataset): 应该支持索引取数据
数据加载器 (dataloader):主要用于拿出mini_batch
前几节使用数据直接将数据用文件加载,然后将所有数据都放进去。像这样。。。。。。

- 所有数据都放进去 叫batch。可以最大化向量计算优势(并行),提高计算速度。
- 只用一个样本, 随机梯度下降,帮助克服鞍点问题。但训练时间过长
- 常用Mini_batch 均衡训练时间和性能的需求。
Mini-batch 循环使用:
嵌套循环,外层循环次数控制,内层每一次执行一个Mini_batch。每一次循环跑一边所有的Mini_batch.

几个名词。。
- Epoch:全部样本进行一次 前馈、反向传播。叫一个Epoch。
- Batch_Size:每次训练使用的样本数量。
- Iteration:Batch_Size分了多少个。
比如有一万个样本,Batch有一千个(Batch_Size),则Iteration就是10。
打乱->分组 分成若干个batch。之后可以通过迭代拿出来每一个Batch,然后遍历Batch拿出其中数据。
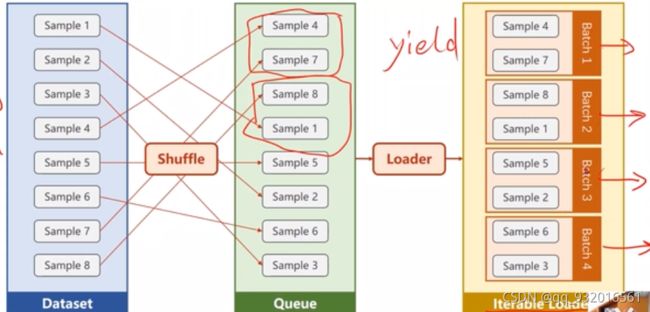
dataset和dataloader类的使用:
Dataset是抽象类,不能实例化,只能被子类继承使用。
Dataloader 可以实例化
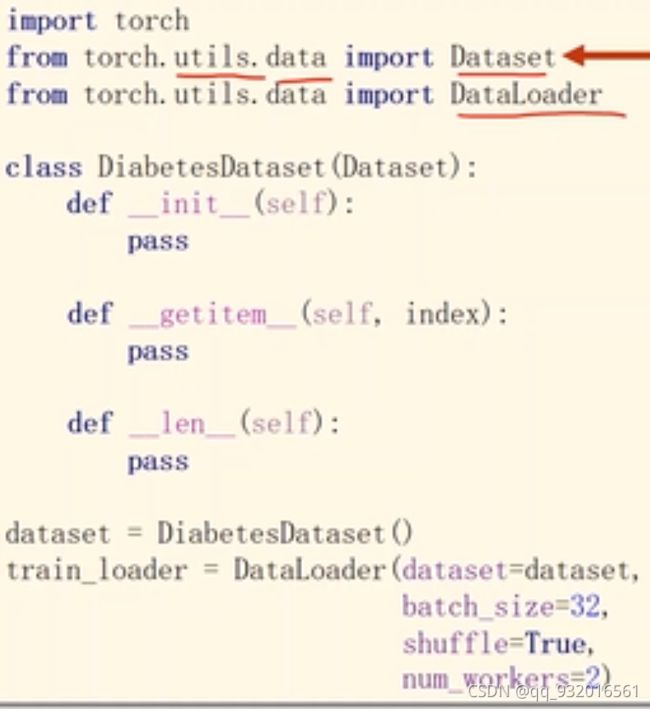
魔法方法 getitem 为了 实现下标索引功能。
魔法方法 len 显然是实现求长度或者数据条数的功能。
DataLoader 中的参数:
dataset=dataset 传递数据集对象。
batch_size = 32 指定batch_size大小。
shuffle = True 打乱样本顺序 。
num_workers = 2 读数据构成Mini_batch时,使用几个进程进行多线程处理。
Pytorch 0.4版本在window中可能遇到多线程系统内核调用报错问题。 解决:将两层循环放到 main函数里。
数据集的整体实现:

filepath 文件路径
![]()
xy是一个矩阵,shape方法返回xy有几行几列(元组)。取其[0],则self.len 得到 xy中的行数,即有多少个数据样本。
![]()
构造数据对象,传路径过去。
最后 加上数据加载器。
后面训练循环的变化:

epoch 所有数据都跑100遍。
内层循环对前面数据加载器对象做迭代,用enumerate仅仅是想看到现在是第几次迭代了。
从train_loader里拿出x[i] y[i]数据放到了 inputs和labels里。loader自动将xy变成Tensor类型。所以 inputs和labels都是张量。
后面不变,损失和函数,梯度清零,反向传播,更新权重。
数据依旧使用上次糖尿病人的数据,
完整代码:
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import numpy as np
import time
# 数据准备
filepath = './diabetes.csv'
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy = np.loadtxt(filepath,delimiter = ',',dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
def __getitem__(self, index):
return self.x_data[index] , self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset(filepath)
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=0)
# 训练模型
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
# 维度变化
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
# 加入激活因子
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
# 多层神经网络传递
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
time_ll = []
loss_ll = []
model = Model()
# 损失函数
criterion = torch.nn.BCELoss(reduction='mean')
# 优化器
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
if __name__ == '__main__':
start_time = time.time()
for epoch in range(10):
for i,data in enumerate(train_loader):
x, y = data
# 前馈
y_pre = model.forward(x)
# 损失
loss = criterion(y_pre,y)
loss_ll.append(loss.item())
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新
optimizer.step()
# print("当前正在训练第"+ str(i) +"块batch")
end_time = time.time()
print("程序运行时间为:",end_time-start_time)
print("损失值",loss_ll[-1])
在使用了mini_batch分块 操作之后可以看到cpu多核心都工作起来了。

而在之前的模型训练中将全部的数据都直接扔进函数,只有几个cpu核心在工作。

后续不断更改 num_workers后发现 只有在0的时候 即仅使用主进程的情况下 时间是最短的 ,大概训练10次的时间为1秒,将num_workers改为1后 时间直增到七秒。更改为2之后的时间大概为8秒。
在增加到三个核心时分页区报错,可以直接去你装pycharm的盘,设置一下该盘的虚拟内存分配就可以了。
我设置完成之后,直接从0-8设置 num_workers 发现每多一个核心进程,运行时间就多大概一秒钟。
关于 num_workers的工作原理:
- 开启num_workers个子进程(worker)。
- 每个worker通过主进程获得自己需要采集的ids。
ids的顺序由采样器(sampler)或shuffle得到。然后每个worker开始采集一个batch的数据。(因此增大num_workers的数量,内存占用也会增加。因为每个worker都需要缓存一个batch的数据) - 在第一个worker数据采集完成后,会卡在这里,等着主进程把该batch取走,然后采集下一个batch。
- 主进程运算完成,从第二个worker里采集第二个batch,以此类推。
- 主进程采集完最后一个worker的batch。此时需要回去采集第一个worker产生的第二个batch。如果第一个worker此时没有采集完,主线程会卡在这里等。(这也是为什么在数据加载比较耗时的情况下,每隔num_workers个batch,主进程都会在这里卡一下。)
所以:
- 如果内存有限,过大的num_workers会很容易导致内存溢出。
- 可以通过观察是否每隔num_workers个batch后出现长时间等待来判断是否需要继续增大num_workers。如果没有明显延时,说明读取速度已经饱和,不需要继续增大。反之,可以通过增大num_workers来缓解。
- 如果性能瓶颈是在io上,那么num_workers超过(cpu核数*2)是有加速作用的。但如果性能瓶颈在cpu计算上,继续增大num_workers反而会降低性能。(因为现在cpu大多数是每个核可以硬件级别支持2个线程。超过后,每个进程都是操作系统调度的,所用时间更长)