Java 定时任务详解
文章目录
- 单机定时任务技术选型
-
- Timer
- ScheduledExecutorService
- Spring Task
- 时间轮
- 分布式定时任务技术选型
-
- Quartz
- Elastic-Job
- XXL-JOB
实操参见Spring Job?Quartz?XXL-Job?年轻人才做选择,艿艿全莽~
单机定时任务技术选型
Timer
java.util.Timer是 JDK 1.3 开始就已经支持的一种定时任务的实现方式。
Timer 内部使用一个叫做 TaskQueue 的类存放定时任务,它是一个基于最小堆实现的优先级队列。TaskQueue 会按照任务距离下一次执行时间的大小将任务排序,保证在堆顶的任务最先执行。这样在需要执行任务时,每次只需要取出堆顶的任务运行即可!
Timer 使用起来比较简单,通过下面的方式我们就能创建一个 1s 之后执行的定时任务。
// 示例代码:
TimerTask task = new TimerTask() {
public void run() {
System.out.println("当前时间: " + new Date() + "n" +
"线程名称: " + Thread.currentThread().getName());
}
};
System.out.println("当前时间: " + new Date() + "n" +
"线程名称: " + Thread.currentThread().getName());
Timer timer = new Timer("Timer");
long delay = 1000L;
timer.schedule(task, delay);
//输出:
当前时间: Fri May 28 15:18:47 CST 2021n线程名称: main
当前时间: Fri May 28 15:18:48 CST 2021n线程名称: Timer
不过其缺陷较多,比如一个 Timer 一个线程,这就导致 Timer 的任务的执行只能串行执行,一个任务执行时间过长的话会影响其他任务(性能非常差),再比如发生异常时任务直接停止(Timer 只捕获了 InterruptedException )。
ScheduledExecutorService
ScheduledExecutorService 是一个接口,有多个实现类,比较常用的是 ScheduledThreadPoolExecutor 。
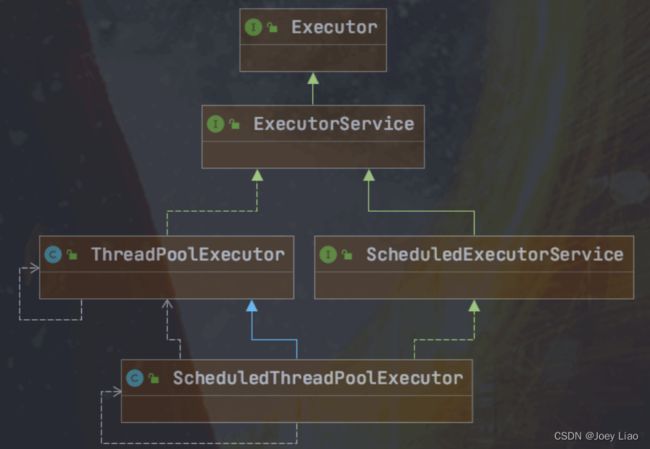
ScheduledThreadPoolExecutor 本身就是一个线程池,支持任务并发执行。并且,其内部使用 DelayQueue 作为任务队列。\
// 示例代码:
TimerTask repeatedTask = new TimerTask() {
@SneakyThrows
public void run() {
System.out.println("当前时间: " + new Date() + "n" +
"线程名称: " + Thread.currentThread().getName());
}
};
System.out.println("当前时间: " + new Date() + "n" +
"线程名称: " + Thread.currentThread().getName());
ScheduledExecutorService executor = Executors.newScheduledThreadPool(3);
long delay = 1000L;
long period = 1000L;
executor.scheduleAtFixedRate(repeatedTask, delay, period, TimeUnit.MILLISECONDS);
Thread.sleep(delay + period * 5);
executor.shutdown();
//输出:
当前时间: Fri May 28 15:40:46 CST 2021n线程名称: main
当前时间: Fri May 28 15:40:47 CST 2021n线程名称: pool-1-thread-1
当前时间: Fri May 28 15:40:48 CST 2021n线程名称: pool-1-thread-1
当前时间: Fri May 28 15:40:49 CST 2021n线程名称: pool-1-thread-2
当前时间: Fri May 28 15:40:50 CST 2021n线程名称: pool-1-thread-2
当前时间: Fri May 28 15:40:51 CST 2021n线程名称: pool-1-thread-2
当前时间: Fri May 28 15:40:52 CST 2021n线程名称: pool-1-thread-2
不论是使用 Timer 还是 ScheduledExecutorService 都无法使用 Cron 表达式指定任务执行的具体时间。
Spring Task
直接通过 Spring 提供的 @Scheduled 注解即可定义定时任务,非常方便!
/**
* cron:使用Cron表达式。 每分钟的1,2秒运行
*/
@Scheduled(cron = "1-2 * * * * ? ")
public void reportCurrentTimeWithCronExpression() {
log.info("Cron Expression: The time is now {}", dateFormat.format(new Date()));
}
Spring Task 还是支持 Cron 表达式 的。Cron 表达式主要用于定时作业(定时任务)系统定义执行时间或执行频率的表达式,非常厉害,你可以通过 Cron 表达式进行设置定时任务每天或者每个月什么时候执行等等操作。咱们要学习定时任务的话,Cron 表达式是一定是要重点关注的。推荐一个在线 Cron 表达式生成器:
推荐一个在线Cron表达式生成器:http://cron.qqe2.com/
但是,Spring 自带的定时调度只支持单机,并且提供的功能比较单一
这里推荐《5 分钟搞懂如何在 Spring Boot 中 Schedule Tasks》
Spring Task 底层是基于 JDK 的 ScheduledThreadPoolExecutor 线程池来实现的
- 优点:简单,轻量级,支持Cron表达式
- 缺点:功能单一
时间轮
Kafka、Dubbo、ZooKeeper、Netty 、Caffeine 、Akka 中都有对时间轮的实现。
时间轮简单来说就是一个环形的队列(底层一般基于数组实现),队列中的每一个元素(时间格)都可以存放一个定时任务列表。
下图是一个有 12 个时间格的时间轮,转完一圈需要 12 s。当我们需要新建一个 3s 后执行的定时任务,只需要将定时任务放在下标为 3 的时间格中即可。当我们需要新建一个 9s 后执行的定时任务,只需要将定时任务放在下标为 9 的时间格中即可。
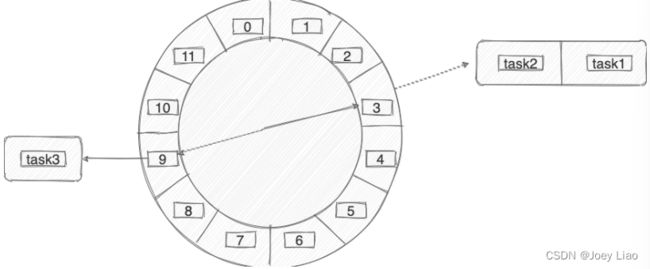
那当我们需要创建一个 15s 后执行的定时任务怎么办呢?这个时候可以引入一叫做 圈数/轮数 的概念,也就是说这个任务还是放在下标为 3 的时间格中, 不过它的圈数为 2 。
除了增加圈数这种方法之外,还有一种 多层次时间轮 (类似手表),Kafka 采用的就是这种方案。
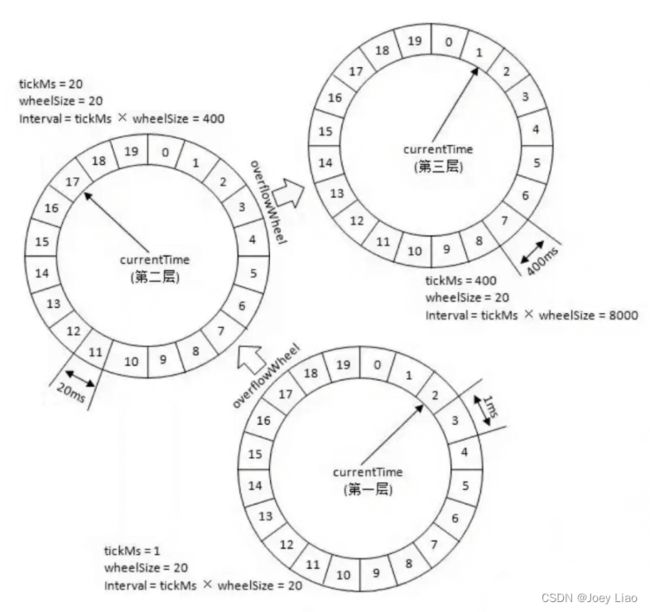
上图的时间轮,第 1 层的时间精度为 1 ,第 2 层的时间精度为 20 ,第 3 层的时间精度为 400。假如我们需要添加一个 350s 后执行的任务 A 的话(当前时间是 0s),这个任务会被放在第 2 层(因为第二层的时间跨度为 20*20=400>350)的第 350/20=17 个时间格子。
当第一层转了 17 圈之后,时间过去了 340s ,第 2 层的指针此时来到第 17 个时间格子。此时,第 2 层第 17 个格子的任务会被移动到第 1 层。
任务 A 当前是 10s 之后执行,因此它会被移动到第 1 层的第 10 个时间格子。
这里在层与层之间的移动也叫做时间轮的升降级。参考手表来理解就好!
时间轮比较适合任务数量比较多的定时任务场景,它的任务写入和执行的时间复杂度都是 0(1)。
分布式定时任务技术选型
上面提到的一些定时任务的解决方案都是在单机下执行的,适用于比较简单的定时任务场景比如每天凌晨备份一次数据。
如果我们需要一些高级特性比如支持任务在分布式场景下的分片和高可用的话,我们就需要用到分布式任务调度框架了。
通常情况下,一个定时任务的执行往往涉及到下面这些角色:
- 任务:首先肯定是要执行的任务,这个任务就是具体的业务逻辑比如定时发送文章。
- 调度器:其次是调度中心,调度中心主要负责任务管理,会分配任务给执行器。
- 执行器:最后就是执行器,执行器接收调度器分派的任务并执行。
Quartz

一个很火的开源任务调度框架,完全由Java写成。Quartz 可以说是 Java 定时任务领域的老大哥或者说参考标准,其他的任务调度框架基本都是基于 Quartz 开发的,比如当当网的elastic-job就是基于quartz二次开发之后的分布式调度解决方案。
使用 Quartz 可以很方便地与 Spring 集成,并且支持动态添加任务和集群。但是,Quartz 使用起来也比较麻烦,API 繁琐。
并且,Quzrtz 并没有内置 UI 管理控制台,不过你可以使用 quartzui 这个开源项目来解决这个问题。
另外,Quartz 虽然也支持分布式任务。但是,它是在数据库层面,通过数据库的锁机制做的,有非常多的弊端比如系统侵入性严重、节点负载不均衡。有点伪分布式的味道。
优缺点总结:
- 优点:可以与Spring集成,并且支持动态添加任务和集群
- 缺点:分布式支持不友好,无内置UI,使用麻烦
Elastic-Job

Elastic-Job 是当当网开源的一个基于Quartz和ZooKeeper的分布式调度解决方案,由两个相互独立的子项目 Elastic-Job-Lite 和 Elastic-Job-Cloud 组成,一般我们只要使用 Elastic-Job-Lite 就好。
ElasticJob 支持任务在分布式场景下的分片和高可用、任务可视化管理等功能。

ElasticJob-Lite 的架构设计如下图所示:
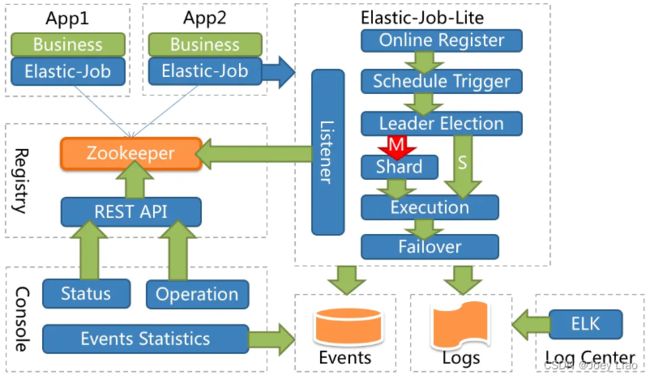
从上图可以看出,Elastic-Job 没有调度中心这一概念,而是使用 ZooKeeper 作为注册中心,注册中心负责协调分配任务到不同的节点上。
Elastic-Job 中的定时调度都是由执行器自行触发,这种设计也被称为去中心化设计(调度和处理都是执行器单独完成)。
@Component
@ElasticJobConf(name = "dayJob", cron = "0/10 * * * * ?", shardingTotalCount = 2,
shardingItemParameters = "0=AAAA,1=BBBB", description = "简单任务", failover = true)
public class TestJob implements SimpleJob {
@Override
public void execute(ShardingContext shardingContext) {
log.info("TestJob任务名:【{}】, 片数:【{}】, param=【{}】", shardingContext.getJobName(), shardingContext.getShardingTotalCount(),
shardingContext.getShardingParameter());
}
}
相关地址:
- Github 地址:https://github.com/apache/shardingsphere
- elasticjob。官方网站:https://shardingsphere.apache.org/elasticjob/index_zh.html 。
优缺点总结:
- 优点 :可以与 Spring 集成、支持分布式、支持集群、性能不错
- 缺点 :依赖了额外的中间件比如 Zookeeper(复杂度增加,可靠性降低、维护成本变高)
XXL-JOB

XXL-JOB 于 2015 年开源,是一款优秀的轻量级分布式任务调度框架,支持任务可视化管理、弹性扩容缩容、任务失败重试和告警、任务分片等功能

根据 XXL-JOB 官网介绍,其解决了很多 Quartz 的不足。

XXL-JOB 的架构设计如下图所示:
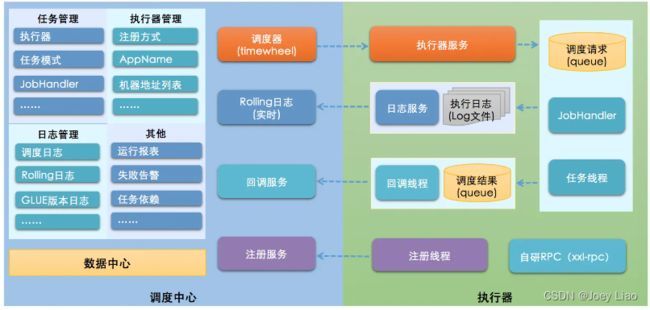
从上图可以看出,XXL-JOB 由 调度中心 和 执行器 两大部分组成。调度中心主要负责任务管理、执行器管理以及日志管理。执行器主要是接收调度信号并处理。另外,调度中心进行任务调度时,是通过自研 RPC 来实现的。
不同于 Elastic-Job 的去中心化设计, XXL-JOB 的这种设计也被称为中心化设计(调度中心调度多个执行器执行任务)。
和 Quzrtz 类似 XXL-JOB 也是基于数据库锁调度任务,存在性能瓶颈。不过,一般在任务量不是特别大的情况下,没有什么影响的,可以满足绝大部分公司的要求。
不要被 XXL-JOB 的架构图给吓着了,实际上,我们要用 XXL-JOB 的话,只需要重写 IJobHandler 自定义任务执行逻辑就可以了,非常易用!
@JobHandler(value="myApiJobHandler")
@Component
public class MyApiJobHandler extends IJobHandler {
@Override
public ReturnT<String> execute(String param) throws Exception {
//......
return ReturnT.SUCCESS;
}
}
还可以直接基于注解定义任务。
@XxlJob("myAnnotationJobHandler")
public ReturnT<String> myAnnotationJobHandler(String param) throws Exception {
//......
return ReturnT.SUCCESS;
}
相关地址:
- Github 地址:https://github.com/xuxueli/xxl-job/。
- 官方介绍:https://www.xuxueli.com/xxl-job/ 。
优缺点总结:
- 优点:开箱即用(学习成本比较低)、与 Spring 集成、支持分布式、支持集群、内置了 UI 管理控制台。
- 缺点:不支持动态添加任务