好久不见!!菜鸟学习笔记之Scala学习笔记(部分),持续更新~~
文章目录
- Scala简介
- 快速入门之HelloWorld
- IDEA开发Scala
-
- 工程创建
- Scala开发规范
- Scala基础语言学习
-
- Chap01.内容输出与文档查看
- Chap02.变量
-
- 2.1 声明/定义
- 2.2 val与var
- 2.3 数据类型
-
- 2.3.1Char类型使用注意
- 2.3.2、Unit、Null和Nothing
- 2.3.3、类型转换
- Chap03.运算符
- Chap04.流程控制
- Scala函数式编程学习
-
- Chap05.函数编程入门
-
- 5.1、函数function 和 方法method
- 5.2、函数的定义
- 5.3、函数的使用注意
- 5.4、惰性函数
- 5.5、异常
- Chap06. Scala面向对象
-
- 6.1、面向对象基础要点
- 6.2、对象、属性定义的注意点
- 6.3、构造器
- 6.4、属性高级部分
- Chap07. Scala面向对象基础部分
-
- 7.1、Scala包基本介绍
- 7.2、Scala包的特点及注意事项
- 7.3、包对象package object
- 7.4、访问权限
- 7.5、高级版Import
- 7.6、封装与继承
- 7.7、方法重写
- 7.8、类型检查与转换
- 7.9、继承中构造器调用
- 7.10、Java字段隐藏与动态绑定
- 7.11、Scala字段覆写
- 7.12、抽象类
- Chap08.Scala面向对象高级特性
-
- 8.1、细说伴生类和伴生对象
- 8.2、伴生对象的Apply方法
- 8.3、Scala的“接口”—trait(特征、特质)
- 8.4、动态混入
- 8.5、动态混入的叠加机制
- 8.6、动态混入时抽象方法部分实现
- 8.7、动态混入的特质字段
- 8.8、Trait的混入构造顺序
- 8.9、使用Trait对类进行扩展
- 8.10、内部类
- 8.11、类型投影
- Chap09.隐式操作
-
- 9.1、隐式转换
- 9.2、隐式函数用于丰富类库
- 9.3、隐式值配合函数隐式形参
- 9.4、隐式类
- 9.5、隐式转换的触发时机和基本注意
- Scala数据结构
-
- Chap10.集合
-
- 10.1、Scala集合基本介绍
- 10.2、Scala集合类层次结构介绍(对比Java)
- 10.3、定长数组与可变数组
- 10.4、ArrayBuffer与Java中ArrayList相互转换
- 10.5、元组Tuple
- 10.6、Scala列表(List)
- 10.7、可变列表ListBuffer
- 10.8、队列Queue
- 10.9、Scala集合之Map
- 10.10、Scala集合之Set
- Chap11.集合操作
-
- 11.1、map映射操作
- 11.2、高阶函数入门
-
- 11.2.1、扁平化(flatmap)
- 11.2.2、过滤(filter)
- 11.2.3、化简(reduce)
- 11.2.4、折叠(fold)
- 11.2.5、扫描(scan)
- Scala练习
-
- Practice01
- Practice02
-
-
- 11.2.4、折叠(fold)
- 11.2.5、扫描(scan)
-
- Scala练习
-
- Practice01
- Practice02
Scala简介
面向对象编程结合函数式编程,运行在JVM上,吸取了Java的优点并对Java复杂的地方做了简化。
快速入门之HelloWorld
-
创建
HelloScala.scalaobject HelloScala { def main(args:Array[String]):Unit = { println("hello scala") } } -
scalac .\HelloScala.scala编译 -
scala HelloScala运行
也可以直接使用scala .\HelloScala.scala运行
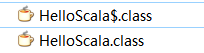
Java程序编译后,一般都是一个class文件,但是Scala编译后却有两个class文件:
反编译后,看看两个文件的内容吧:
HelloScala.class
import scala.reflect.ScalaSignature; public final class HelloScala { public static void main(String[] paramArrayOfString) { HelloScala$.MODULE$.main(paramArrayOfString); } }HelloScala$.class
import scala.Predef$; public final class HelloScala$ { public static final HelloScala$ MODULE$ = new HelloScala$(); public void main(String[] args) { Predef$.MODULE$.println("hello scala"); } }两者之间是一个相互调用的关系。HelloScala类的main中调用HelloScala$类中静态变量 MODULE$的main方法,
而HelloScala$类中 MODULE$是一个当前类的实例化对象,然后调用main方法,其main方法中又调用了Predef$类中MODULE$的println方法。
通过第一个快速入门程序做一下小分析:
def是定义方法的关键字main是方法名,main方法是程序的入口args是参数名Array[String]参数类型,表示参数是一个String类型的Array- Scala的特点,参数名在前,类型在后
:Unit=表示函数返回值为空 void- println("…")输出内容
IDEA开发Scala
工程创建
-
创建一个Maven工程
-
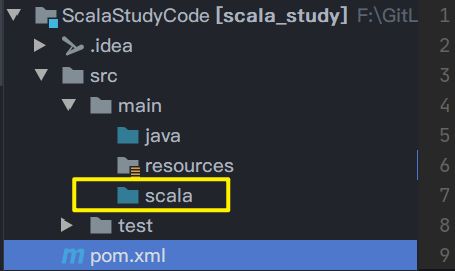
在src/main目录下创建一个scala文件夹。并标记为source文件夹
-
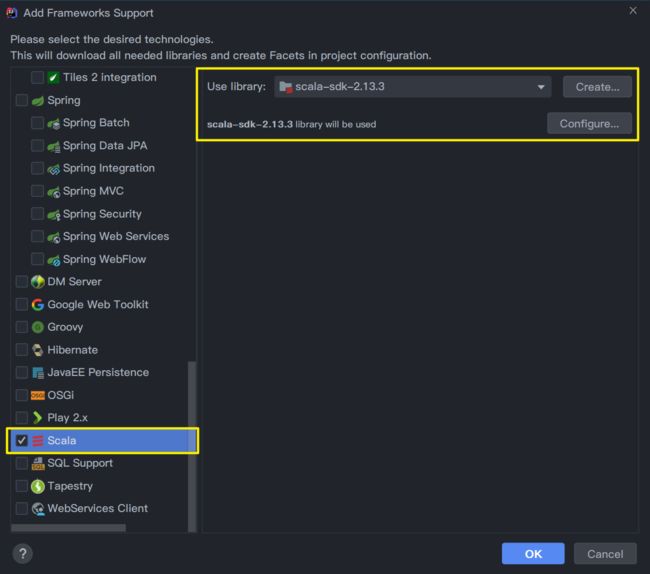
添加Scala框架支持
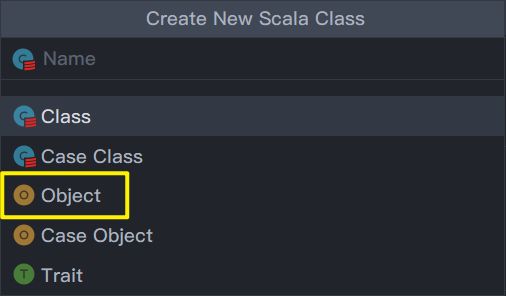
配置好Scala SDK,即可创建ScalaObject:
-
老规矩,先建包!!!然后创建Object
-
在IDEA中写代码不要太爽!!
可以直接运行!
Scala开发规范
- 源文件以
.scala作为文件后缀名 - 每条语句末尾可以不用分号,但是多条语句同行,需要使用分号分隔
- Scala严格区分大小写
Scala基础语言学习
Chap01.内容输出与文档查看
三种输出内容的方式
-
类似Java的输出方式
val str: String = "Hello" val str2: String = "World" println("-----以下是类Java方式输出-----") println(str + "," + str2) -
格式化输出,有点像c语言的
printfval name: String = "zhangsan" val age: Int = 22 val salary: Double = 10502.27 println("-----以下是格式化输出(printf)-----") printf("My name is %s. \nI am %d years old. \nmy salary is %.2f", name, age, salary)注意:这种输出方式只能使用printf!!!
-
使用类似EL表达的引用输出
val name: String = "zhangsan" val age: Int = 22 val salary: Double = 10502.27 println("-----以下是使用$ 引用输出-----") println(s"My name is $name. \nI am $age years old. \nmy salary is $salary") println("还可以引用表达式") println(s"My name is $name. \nI am ${age + 1} years old. \nmy salary is ${salary * 2}")千万不要以为括号里面那个s是你误敲的,不信你删了试试看。这个是这种输出方式的标志!!
官方API文档查阅
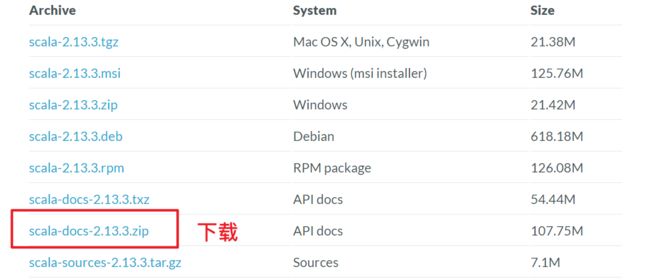
解压找到帮助文档所在目录
Chap02.变量
2.1 声明/定义
普通方式的变量声明:
var num:Int = 10
var num2:Double = 23.2
// 小数默认为 double
var num3:Float = 4.1f
var flag:Boolean = true
使用类型推导定义变量
/**
* 变量类型自动推导
* 与动态语言不同的是:类型一旦确定就不能再修改了(强类型语言)
*/
var i = 10
// i = 3.7 这样修改了变量类型,是不允许的!
var j = 4.56
var k = 2.4f
var m = false
不像动态语言,变量的类型能随着类型的变化而变化。Scala声明变量后,类型确定了就不能再赋值其他类型的值了!!
变量声明时,标识符和其他语言规则一样,不可以使用数字作为变量名开头。
2.2 val与var
虽然两者都可以用来声明变量,但是使用val声明的变量时赋值后,不可以再改变值。相当于Java中的final变量
var声明和定义的变量是可以修改值。
变量/对象声明时都需要初始化,要赋初始值!!
我们创建对象后,一般只是修改对象的属性值,而很少修改对象的引用。
我们就可以使用val来声明对象,用var声明对象的属性!!并且使用val的好处是:val声明的对象不存在线程安全的问题!!!
object VarAndVal {
def main(args: Array[String]): Unit = {
/**
* var:声明的变量可以修改值
* val:声明的变量不可以修改值 不存在线程安全的问题
*/
var i = 10
i = 28 // ok
val j = 17
// j = 23 这样是不允许的
val myDog = new Dog
// 修改属性
myDog.age = 2
myDog.name = "小花"
// 修改对象引用,不允许
// myDog = new Dog
}
}
class Dog {
var age:Int = _ //赋默认值
var name:String = _
}
2.3 数据类型
Scala完美诠释了什么是面向对象,在Scala中一切皆对象!!它拥有Java中所有的基本类型,Scala中使用基本类型定义的数据也是对象!
Scala所有对象都有同一个祖先对象Any,(相当于Java中的Object)。Any又有两个直接子类:AnyVal(值类型)、AnyRef(引用类型)
- AnyVal: 所有的基本类型(Int,Double,Float,Char,Boolean等)都是它的直接子类
- AnyRef: 所有的Java类,Scala的集合类,以及其他的自定义类属于AnyRef的子类
类型的结构图
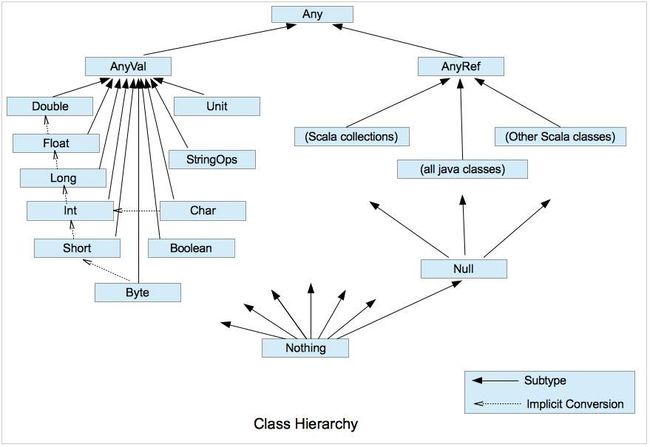
其中有两个特殊的类需要了解和区分一下:
- Null: 表示空值,null,是所有AnyRef类型的子类!
- Nothing:是任意类型的子类
两个类都属于底层类(BottomClass),Nothing常用于异常的抛出和处理,我们知道在Java中异常是区分范围大小的,只有范围更大的(父类,或间接父类)的异常才能接收比其范围小的异常类型。例如Exception类是可以接收和处理所有Exception类的,而IOException则能接收处理的异常就相对较小。那么如果将异常定义为Nothing类型,那么任何类都可以正常接收和处理到异常了!!
类型表
| 数据类型 | 描述 |
|---|---|
| Byte | 8位有符号补码整数。数值区间为 -128 到 127 |
| Short | 16位有符号补码整数。数值区间为 -32768 到 32767 |
| Int | 32位有符号补码整数。数值区间为 -2147483648 到 2147483647 |
| Long | 64位有符号补码整数。数值区间为 -9223372036854775808 到 9223372036854775807 |
| Float | 32 位, IEEE 754 标准的单精度浮点数 |
| Double | 64 位 IEEE 754 标准的双精度浮点数 |
| Char | 16位无符号Unicode字符, 区间值为 U+0000 到 U+FFFF |
| String | 字符序列 |
| Boolean | true或false |
| Unit | 表示无值,和其他语言中void等同。用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成()。 |
| Null | null 或空引用 |
| Nothing | Nothing类型在Scala的类层级的最底端;它是任何其他类型的子类型。 |
| Any | Any是所有其他类的超类 |
| AnyRef | AnyRef类是Scala里所有引用类(reference class)的基类 |
2.3.1Char类型使用注意
-
Char类型对象,存储空间为2个字节,赋值范围是(0~65535)。
-
输出Char类型的数据时,会默认将其转化为对应的Unicode字符,例如:
var ch:Char = 97 println("ch="ch) // ch=a -
但是一旦Char类型用于计算,就会隐式转化为其他数值类型,并且计算结果也会转化为对应的数值类型。另外Scala中所有的计算表达式都会做隐式类型转换!
var ch2:Char = 'a' println(s"$ch2 + 1 = " + {ch2+1}) // a + 1 = 98 println(s"$ch2 + 1.2 = " + {ch2+1.2}) // a + 1.2 = 98.2所以,这种 var ch:Char = 97+1,var ch:Char = ‘a’+1都是错误的写法!!!
2.3.2、Unit、Null和Nothing
-
Unit相当于其他语言中的void类型,其有唯一实例值
()object UnitAndNullAndNothing { def main(args: Array[String]): Unit = { var test = testUnit() println(test) // () } def testUnit(): Unit = { println("Hello Unit") } } -
Null类型也有唯一实例:
null,但是只能赋值给AnyRef类型。不能赋给AnyVal类型,运行时会报错。object NullTest { def main(args: Array[String]): Unit = { var test = null //test's type is Null var ch:Char = null // 运行报错 println(ch) } } -
Nothing是一切类的子类,且是一个不可实例化的抽象类,并且不可以被继承
2.3.3、类型转换
隐式类型转换
Scala中完全保留了Java的隐式类型转换机制。即更小范围的类型可以转化为更大范围的类型,反之则不行。(例如:Float转Double可以,反之不行)Byte、Short和Char类型的数据之间不会自动转换。三者类型的数据放在一起计算都先转为Int
当数据进行计算的时候,都会先进行类型隐式转换,先向上转换为最近的类型,然后计算。
var s:Short = 5
s = s+2 //error,计算时因为2是Int,所以都先转化为Int类型然后计算,结果为Int类型, 将Int类型赋值给Short类型(error)
强制类型转换
任何基本类型的数据,都有toInt,toDouble,toFloat这样的方法,使用这种方法可以进行强制类型转换!!强制类型转换就可能导致精度丢失或值溢出
String类型的数据,转数值类型的时候,确保数据的规范性以及类型的正确。否者会抛NumberFormatException异常
Chap03.运算符
取模运算的原则
- a%b <=> a - (a/b) * b
- 取模运算的结果,总与被取模数的符号一致!
++ 和 –
在Scala中不能使用++ 和 – 改而使用 += 和 -=
关系运算符
浮点型数据进行比较,哪怕值相同,类型不同结果也是false
var d:Double = 2.2
var f:Float = 2.2f
println(d==f) // false
赋值运算符
| 运算符 | |
|---|---|
| x >>= n | 右移n位后赋值 |
| x <<=n | 左移n位后赋值 |
| &=、|=、^= | … |
三目运算
Scala中不支持三目运算,改为if-else完成(Scala设计概念:同一件事情尽量只有一种解决方法,保证代码风格统一)
// var i = (5>3)?5:3
var i = if (5>3) 5 else 3
获取键盘输入
StdIn.readxxx (trait scala.io.StdIn的方法,拿来即用)
var age = StdIn.readInt()
var name = StdIn.readLine()
Chap04.流程控制
范围数据的for循环
for(item <- start to end){ … }
object ForDemo {
def main(args: Array[String]): Unit = {
for (i <- 1 to 10){
println(s"$i, hello world")
}
/**
* 1, hello world
* 2, hello world
* 3, hello world
* 4, hello world
* 5, hello world
* 6, hello world
* 7, hello world
* 8, hello world
* 9, hello world
* 10, hello world
*/
}
}
这种,类似于Java的增强for循环,可以用于对集合元素的遍历!!
var list = List("Hello","World",10,30,false)
for (item <- list){
println(item)
}
/**
* Hello
* World
* 10
* 30
* false
*/
范围数据循环2
for(item <- start until end){ … }
object ForDemo02 {
def main(args: Array[String]): Unit = {
for (i <- 1 until 6){
println(i)
}
/**
* 1
* 2
* 3
* 4
* 5
*/
}
}
For循环,循环守卫
案例:
object ForDemo03 {
def main(args: Array[String]): Unit = {
for (i <- 1 to 10 if i%2==0){
println(s"${i} is a even number")
}
/**
* 2 is a even number
* 4 is a even number
* 6 is a even number
* 8 is a even number
* 10 is a even number
*/
}
}
for循环中同行的if判断式,就是循环保卫式,为true时,执行循环中的语句,为false则跳过当前循环值(类似continue)
For循环 引入变量
可以直接在for循环的同行中,使用循环变量进行操作。
object ForDemo04 {
def main(args: Array[String]): Unit = {
for (i <- 1 to 10; j = 2 * i){
println(s"$i * 2 = $j")
}
/**
* 1 * 2 = 2
* 2 * 2 = 4
* 3 * 2 = 6
* 4 * 2 = 8
* 5 * 2 = 10
* 6 * 2 = 12
* 7 * 2 = 14
* 8 * 2 = 16
* 9 * 2 = 18
* 10 * 2 = 20
*/
}
}
嵌套For循环简写
object ForDemo05 {
def main(args: Array[String]): Unit = {
for (i <- 1 to 10; j <- 1 to i){
print(j+" ")
if (j==i){
println()
}
}
/**
* 1
* 1 2
* 1 2 3
* 1 2 3 4
* 1 2 3 4 5
* 1 2 3 4 5 6
* 1 2 3 4 5 6 7
* 1 2 3 4 5 6 7 8
* 1 2 3 4 5 6 7 8 9
* 1 2 3 4 5 6 7 8 9 10
*/
}
}
等价写法:
for (i <- 1 to 10) {
for (j <- 1 to i) {
print(j + " ")
if (j == i) {
println()
}
}
}
当i的for循环中有业务逻辑,就会出现问题,还是要使用传统的循环。
For循环 yield暂存
object ForDemo06 {
def main(args: Array[String]): Unit = {
var numbers = for (i <- 1 to 10) yield {
if (i % 2 == 0) 0 else math.pow(i, 2).toInt
}
println(numbers)
/**
* Vector(1, 0, 9, 0, 25, 0, 49, 0, 81, 0)
*/
}
}
for循环中的()可以使用{}替换
for循环,步长控制
Range(m,n,x)m到n,步长为x
object ForDemo07 {
def main(args: Array[String]): Unit = {
for (i <- Range(1,10,2)){
println(i)
}
/**
* 1
* 3
* 5
* 7
* 9
*/
}
}
Scala的设计者不推荐使用While循环,因为While循环是没有返回值的,不像for循环可以将循环中计算的结果返回出来直接使用,而While想要达到等同的效果就要在循环外额外定义变量,并在循环中修改。其作者认为循环内不应该影响的外部的变量,所以推荐使用for!例如递归的思想
Breakable 循环中断
// 需要手动导入此包!!
import util.control.Breaks._
object Breakable {
def main(args: Array[String]): Unit = {
var n = 1;
while (n < 20) {
if (n == 15) {
break()
}
println(n)
n += 1
}
println("hello world")
}
}
以上这种写法,执行break()后,程序会异常中断,后面的代码无法执行。我们需要使用breakable来包裹代码,来处理中断异常:
object Breakable {
def main(args: Array[String]): Unit = {
var n = 1;
breakable {
while (n < 20) {
if (n == 15) {
break()
}
println(n)
n += 1
}
}
println("hello world")
}
}
使用breakable包裹后的代码,能够处理中断异常,并且不影响后续的代码执行。其实breakable是一个高阶函数
scala中去除了break和continue!!
Scala函数式编程学习
Chap05.函数编程入门
scala中,将函数式编程和面向对象编程融为了一体
5.1、函数function 和 方法method
几乎可以等同,定义、使用、运行机制都是一样的。函数的使用更加灵活,方法也可以轻松转化为函数!
package com.sakura.chapter05
/**
* @author 5akura
* @create 2020/2020/8/14 20:28
* @description
**/
object MethodAndFunction {
def main(args: Array[String]): Unit = {
var calculator = new Calculator
// 方法的调用
println("calculator.add(1, 2) = " + calculator.add(1, 2)) // 3
// 方法转函数
val function1 = calculator.add _
// 函数的调用
println("function1(2,3) = " + function1(2, 3)) // 5
// 函数的定义
val function2 = (num1: Int, num2: Int) => {
// 函数体
num1 + num2
}
// 函数的使用
println("function2(3,4) = " + function2(3, 4))
}
}
class Calculator {
/**
* 类的一个方法
*
* @param num1
* @param num2
* @return
*/
def add(num1: Int, num2: Int): Int = {
num1 + num2
}
}
5.2、函数的定义
def 函数名(参数1:参数类型,参数2:参数类型,...)[:返回值类型 = ]{
/* 函数体 */
[return] 返回值
}
中间有连个部分需要注意:
- 函数的返回类型,有三种写法
:返回值类型=, 固定了返回值类型。=,直接使用等于, 返回值类型自动推断不可以使用return!!- 什么都不写, 表示没有返回值
- 函数体的返回值(在函数要求有返回值的情况下:)
- 使用return 则返回指定的值
- 不使用return 默认使用函数体中执行的最后一行代码的结果作为返回值!
- 如果函数不要求返回值,使用return也是白瞎
案例演示
def calculate(operand1: Int, operand2: Int, operator: Char) = {
if (operator == '+') {
operand1 + operand2
} else if (operator == '-') {
operand1 - operand2
} else if (operator == '*') {
operand1 * operand2
} else if (operator == '/') {
if (operand2 == 0) {
null
} else {
operand1 / operand2
}
} else {
null
}
}
5.3、函数的使用注意
-
单函数没有形参的时候,参数列表的括号可直接省略
-
函数的参数、返回值可以是值类型,也可以是引用类型!(即当传入一个对象时,用的是对象的引用,直接操作源对象!)
-
Scala的语法中,任何的结构都可以嵌套其他所有结构:类中可以再定义类,函数中可以再定义函数!同名函数在不同的位置,编译后修饰符不同罢了:
object FuncNotice02 { def main(args: Array[String]): Unit = { def func(msg: String): Unit = { // private static final func$1 println(msg) def func (msg:String): Unit = { // private static final func$2 println(msg) } } } def func(msg: String): Unit = { println(msg) } }编译后的:
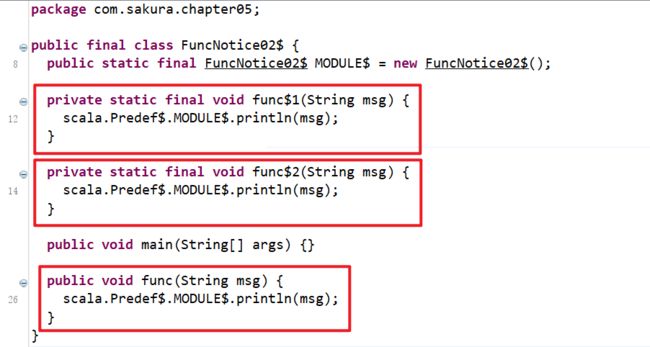
虽然三个位置的函数处于同等地位,都是此类的成员函数。
但是写在main方法中的函数变为了两个私有的静态不可变的函数,函数名分别加上了$1、$2
写在main方法外面的函数,成功成为了类的成员方法。 -
形参设置默认值!
函数的参数是可以设置默认值的,调用时不传参数的时候,使用默认值,但是没有设置默认值的参数仍需要传递参数
object FuncNotice03 { def main(args: Array[String]): Unit = { sayHi() // Bob: Hello sayHi("Sakura") // Sakura: Hello // say() 报错,需要指定msg } def sayHi(name:String = "Bob"): Unit = { println(s"$name: Hello") } def say(name:String = "Mike", msg:String): Unit ={ println(s"$name : $msg") } }对于上面的案例,如何为设置参数,请往下看
-
默认值覆盖顺序:
当参数中有很多默认值的时候,调用时传递的参数 从左到右依次覆盖默认值
object FuncNotice04 { def main(args: Array[String]): Unit = { connectMysql() // localhost:3306 root 123456 connectMysql("192.168.1.1",6666) // 192.168.1.1:6666 root 123456 //如果我只想改用户名和密码呢? //connectMysql("sakura","170312") ?因为是从左向右覆盖,,所以行不通 除非你把函数的后两个参数写到前面 } def connectMysql(host:String = "localhost", port:Int = 3306, username:String = "root", password:String = "123456"): Unit ={ println(s"$host:$port") println(s"username: $username") println(s"password: $password") } }如果遇到代码中的问题,多个默认参数我只想修改其中几个。
或者函数既有带默认值的参数,又有没有默认值的参数,怎么为不带默认值的参数设值?带名参数就是救世主! -
带名参数(对应上面两个案例的问题)
say(msg = "My name is mike!") connectMysql(username = "sakura",password = "170312") // 在调用的时候,用参数名指定值 -
函数的形参都是 val定义的,是不容修改的!!
-
递归在执行前无法自动推断返回值,所以递归函数不能使用自动推断返回值类型,必须指定返回值类型!!!
-
Scala函数支持可变参数(可变形参放在最后!!)
object FuncNotice05 { def main(args: Array[String]): Unit = { println(sum()) // 0 println(sum(1, 3, 5, 7, 9)) // 25 println(sub(19)) // 19 println(sub(19, 1, 3, 5, 7)) //3 // sub() 报错,缺少参数 } def sum(numbers:Int*): Int ={ var res:Int = 0 for (number <- numbers) { res += number } res } /** * * @param minuend 被减数(必须) * @param nums 减数(可变) * @return */ def sub(minuend:Int, nums:Int*):Int ={ var res:Int = minuend for (num <- nums){ res -= num } res } }可变形参,使用时是一个Sequence(序列)!!可以使用for来遍历!
-
过程(Procedure):没有返回值,或者返回值为Unit的函数称之为过程!!
5.4、惰性函数
==推迟计算,等到真正使用此函数的返回值的时候才临时开始执行函数。==联想单例模式中的懒汉式,在大数据场景中我们可以将一些不必要的计算放到用户需要的时候进行实时计算,在不必要的时候等待,以减少资源的浪费!
使用lazy关键字
object LazyFunc {
def main(args: Array[String]): Unit = {
lazy val res = sum(20,30)
println("--------")
println(res)
/**
* --------
* sum执行了。。。。
* 50
*/
}
def sum(num1:Int,num2:Int) = {
println("sum执行了。。。。")
num1 + num2
}
}
可以看到使用lazy定义了一个val变量res=sum(20,30); 但是并没有立即去执行sum函数,因为res变量被标记了懒加载(推迟赋值)。于是就往后执行,当输出的时候要用到res变量了,马上拎出来零时执行函数并赋值。典型的不见棺材不掉泪
注意:由于懒加载是将赋值推迟,那么定义变量只能是val类型,不允许中途变化!!
5.5、异常
Java中的编译时异常和运行时异常,被Scala统一为运行时异常!!
案例对比
Scala顺势沿用了Java所有的异常类型。
我们先来回顾一下Java中try…catch捕获异常的一些规则
public class ExceptionTest {
public static void main(String[] args) {
try {
// ...
} catch (ArithmeticException | NumberFormatException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
// ...
}
}
}
try中放可疑代码块,finally里面存放后续执行代码(例如资源释放等)无论如何都会运行。而在Catch中:每个Catch可以对没有子父类关系的多个异常进行同样的处理(例如上述代码中的第一个Catch)。Catch的异常范围必须按从小到大范围来写,否则直接报错!
现在我们来看看Scala捕获异常的代码:
object ExceptionDemo01 {
def main(args: Array[String]): Unit = {
try {
var i:Int = 10 / 0
} catch {
case exception: Exception => {
println("捕获到一个异常")
};
case exception: ArithmeticException|NumberFormatException => println("捕获到一个算数异常")
} finally {
// ...
}
try {
exceptionFunc()
} catch {
case ex: Exception => println("捕获到异常:" + ex.getMessage)
}
println("continue")
}
/**
* 模拟异常
*/
def exceptionFunc (): Unit = {
throw new Exception("异常出现~~~")
}
}
try和finally代码块都没有什么区别,对比一下Catch代码块就能看到不同。Scala可以直接使用一个Catch然后分多个case来代替Java中的多个Catch。并且case之间的异常范围顺序没有硬性要求,但是最终还是会模式匹配到最适合的case(例如上述代码还是走第二个case!),但是为了编码的规范性和代码的可读性,还是建议按照异常的范围来顺序设置case!!
异常处理的注意点
- 可疑代码块放在try代码块中!使用catch捕获可能出现的异常
- Catch中异常的case,最好按照编码规范:范围更大的异常放到最后
- finally代码块一般用于资源的释放,此外的代码是无论如何都会执行的!!
- 遇到不处理的异常可以继续使用throw继续向上抛出!
@throw注解
刚才在Scala的案例代码中,我们使用throw关键字手动抛出异常,我们还可以使用@throw注解告诉调用者这个方法会抛出的异常,需要调用者catch处理或者继续抛出!
@throws(classOf[ArithmeticException])
@throws(classOf[NumberFormatException])
def exceptionFunc02(): Unit = {
var i: Int = "abc".toInt
var a: Int = 10 / 0
}
Chap06. Scala面向对象
6.1、面向对象基础要点
前面我们创建的都是object,但是在面向对象编程过程中,我们使用的类都是使用class定义的。相比于Java而言Scala是纯面向对象的!但是两者的编码规范上还是稍有不同!
object TestOOP {
def main(args: Array[String]): Unit = {
val tom:Cat = new Cat
println(tom.name) // null
println(tom.age) // 0
tom.name = "tom"
tom.age = 3
tom.color = "orange"
println("----赋值后:----")
println(tom.name) // tom
println(tom.age) // 3
}
}
class Cat {
var name:String = _
var age:Int = _
var color:String = _
def speak (): Unit = {
println("miao~")
}
}
在class对象的定义的时候,==成员属性必须赋默认值!!==这里使用_表示赋对应值类型的空值。
问题:这种写法成员变量访问权限修饰是private还是public呢?
直接来看反编译文件:
通过编译的文件看出来,这个class对象单独生成了一个.class文件,而object对象编译后却有两个.class文件!
来看看这个class对象化为Java代码的样子吧
public class Cat {
private String name;
private int age;
private String color;
public String name() {
return this.name;
}
public void name_$eq(String x$1) {
this.name = x$1;
}
public int age() {
return this.age;
}
public void age_$eq(int x$1) {
this.age = x$1;
}
public String color() {
return this.color;
}
public void color_$eq(String x$1) {
this.color = x$1;
}
public void speak() {
Predef$.MODULE$.println("miao~");
}
}
- 所有的成员变量都是
private修饰的! - 每个成员变量貌似都对应两个public方法 xxx()和 xxx_$eq(…)(类似于JavaBean里面的getter和setter)
这种写法是规范的JavaBean定义方式
我们再来看看main方法中的对象赋值和取值是怎么实现的吧:

和前面设想的一致,成员变量都会自动生成“getter and setter”方法
class不添加修饰默认是public!
6.2、对象、属性定义的注意点
成员属性的定义标准语法:
[访问修饰符] var 属性名[:属性值类型] = 默认值
修饰符省略,默认为private!!
属性赋默认值时需要注意的问题
-
成员属性定义时必须设置默认值!
-
属性值类型可以省略,根据赋的默认值自动推断,但是不设置类型,赋值null的话,会将成员属性自动推导为Null类型对象,后续为此成员属性赋值的时候会出现麻烦!!
class Cat { var name = null } // name成员属性自动推断为Null类型,后续无法赋值! -
如果实在不想设置默认值,可以使用
_(系统默认值)类型 系统默认值( _ ) Short、Byte、Int、Long 0 Double、Float 0.0 String、其他引用类型 null Boolean false 使用这种方式赋默认值的话,就不能省略成员类型!!
对象创建注意点
-
var、val合理使用
-
当引用类型对象创建的时候,对象本身和创建的对象存在父子类关系或者多态关系,对象的类型必须带上。(当一个子类对象要赋值给一个父类引用时,想要保证引用的类型不变需要指定类型!)
-
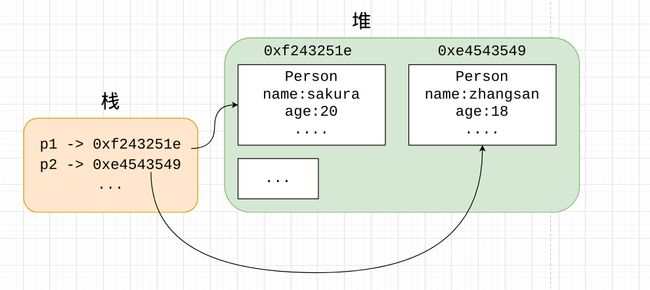
对象内存布局(与Java类似)
栈中只存放对象的引用,即对象在堆中的内存地址。访问对象时先获取对象所在的堆内存地址,然后到堆中找到对应内存取出对象数值。
6.3、构造器
在Scala中构建类对象一样需要使用构造器。
在Java中构造器的定义使用类名,并且不写返回值类型,支持重载!
但是在Scala中,构造器分为两种:
- 主构造器
- 辅助构造器
而且定义方式也与Java有些区别!
主构造器定义
直接在类定义时候,类名后用括号包裹主构造器的参数:
object TestConstructor {
def main(args: Array[String]): Unit = {
val p1:Person = new Person("sakura",20)
println(p1)
}
}
class Person (inName:String, inAge:Int) {
var name:String = inName
var age:Int = inAge
override def toString: String = {
"name: " + name + "; age: " + age
}
}
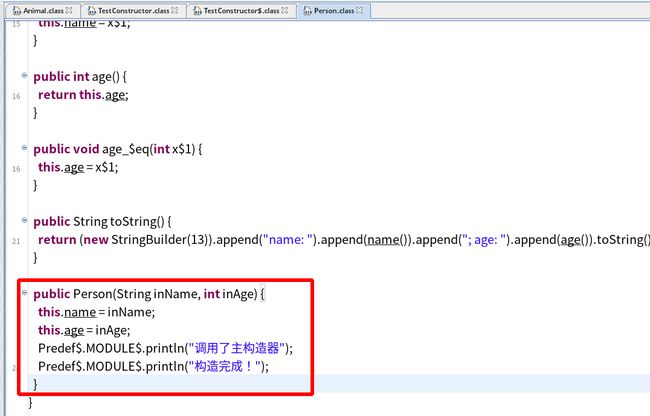
这里有点和Java不同,在Java中类中的代码都必须是在方法中或者静态代码块中的,,但是**Scala中的class里面,不在方法中的代码统统归为主构造器的执行代码!**例如:
class Person (inName:String, inAge:Int) {
var name:String = inName
var age:Int = inAge
println("调用了主构造器")
override def toString: String = {
"name: " + name + "; age: " + age
}
println("构造完成!")
}
这两句输出代码都是直接写在类中的,也就是说被归到了主构造器的执行代码中,每次调用主构造器都会执行!我们来看看反编译的Java代码=>
注意:当主构造器为空参的时候,括号可以省略,调用的时候也可以省略!=
辅助构造器
Scala允许一个类有多个辅助构造器,所有的构造器都是重载的关系。Java中重载构造器保证参数列表不同即可。但是Scala中辅助构造器有些需要注意的地方:
- 命名使用
this - 必须在第一行直接或者间接调用到主构造器!
- 调用主构造器需要显式调用!(主要是为了和父类建立联系,而Java的构造器基本都会默认隐式调用super!)
Java的类构造器中一般都会隐式调用父类的空参的构造,即super(),或者你也可以添加参数来指定调用父类的具体某个构造器,例如super(?,?,?) 这其实就是和父类建立起联系的方式! 但是当你在构造器的第一行调用了同类的其他重载构造即this(?,?,..),最终去执行这个重载的构造的时候第一行执行的还是父类构造的调用!
public class Person {
private int age;
private String name;
public Person (){
}
public Person (String inName){
// super(); 默认调用,可省略
this.name = inName;
this.age = 20;
}
public Person (String inName, int inAge) {
// 这里调用了同类的重载构造,最终还是会调用super();
this(inName);
this.age = inAge;
}
}
可是当调用了重载的构造,又紧接着调用super(),这样是不允许的:
public Person (String inName, int inAge) {
// 这里调用了同类的重载构造,最终还是会调用super();
this(inName);
super(); // 这里直接报错!!
this.age = inAge;
}
**因为对父类的构造调用必须在第一行执行!!**所以你这样写,无论是写在前面还是后面,总有一个super()不是第一行执行!
我们再说回Scala,在Scala中是没有这种默认隐式调用父类构造的,只有主构造器才能和父类联系!所以所有的辅助构造器就需要最终调到主构造器,否则无法和父类建立联系。
所以在Java中这种写法,在Scala中行不通=》
class Person (inName:String, inAge:Int) {
var name:String = inName
var age:Int = inAge
println("调用了主构造器")
override def toString: String = {
"name: " + name + "; age: " + age
}
println("构造完成!")
// 错误写法!!但是Java可以!对比上面Java案例代码的第二个构造器
def this(inName:String) {
name = inName
age = 18
}
}
究其原因就是没有调用主构造器和父类产生联系,所以正确写法应该是=》
class Person (inName:String, inAge:Int) {
var name:String = inName
var age:Int = inAge
println("调用了主构造器")
override def toString: String = {
"name: " + name + "; age: " + age
}
println("构造完成!")
// 正确写法,先调用主构造!
def this(inName:String) {
this(inName, 18)
}
}
或者这样:
class Person (inName:String, inAge:Int) {
var name:String = inName
var age:Int = inAge
println("调用了主构造器")
override def toString: String = {
"name: " + name + "; age: " + age
}
println("构造完成!")
def this() {
this("sakura",20)
println("空参构造")
}
def this(inName:String) {
// 调用了空参的辅助构造,间接调用主构造
this
name = inName
}
}
这种间接调用到主构造也是可以的!!反正目的只有一个:调到主构造,并且在第一行执行!!
其他注意点
构造器私有化
主构造器私有化:在参数列表之前加上private
class Person private(inName:String, inAge:Int){
// ...
}
辅助构造器私有化:def之前加上private
private def this() {
this("sakura",20)
println("空参构造")
}
辅助构造器不要出现与主构造器同参定义!!
6.4、属性高级部分
在Scala的主构造方法中,使用var(val)定义形参,可以将形参转化为类的成员变量(var定义的为可读可写 val定义的为只读)可以通过反编译验证。
// 将形参inName变为了Student的一个可读可写成员变量,inAge是只读的!
class Student (var inName:String,val inAge:Int) {
var name:String = inName
var age:Int = inAge
}
object TestConstructor {
def main(args: Array[String]): Unit = {
val s1:Student = new Student("sakura",20);
println(s1.inName)
s1.inName = "xiaohua"
// s1.inAge = 19 错误用法,用val定义的inAge为只读的
println(s1.inAge)
}
}
反编译的代码:

Getter和Setter
和Java的类成员变量一样,Scala的成员变量也可以写get和set方法,和默认生成的xxx()、xxx_$eq(..)互不影响。
Scala提供的是更便捷的方式——注解标注。@BeanProperty
class Student (var inName:String,val inAge:Int) {
@BeanProperty
var name:String = inName
@BeanProperty
var age:Int = inAge
}
@BeanProperty注解直接使用在成员变量上。就会自动生成get、set方法,在后续创建的对象中可以直接调用!我们通过反编译来验证:

其实发现最终还是调用默认生成的那两个方法!
Chap07. Scala面向对象基础部分
7.1、Scala包基本介绍
Scala和Java具有相同的包机制,但是Scala中包机制要较为复杂,并且功能也更强大!!
package的主要功能
说到底,包的作用大部分是为了区分同名的类,包名的存在就解决了项目中类同名的问题!就好像文件夹的出现,解决了文件系统的文件同名的问题。(同名文件在不同的文件夹中不会产生冲突!)
7.2、Scala包的特点及注意事项
特点一:包结构可以与文件结构不同
在Java中项目包的结构是对应文件系统的结构的!(例如:com.sakura.java包 对应到文件系统就是 …./com/sakura/java/文件夹)
而在Scala中就没有这么严格哦!!来看看例子吧
代码是这样的:
package com.sakura.chapter07.demo
/**
* @author sakura
* @date 2020/9/25 下午4:39
*/
object TestPackage {
def main(args: Array[String]): Unit = {
println("Hello World")
}
}
注意package是 com.sakura.chapter07.demo但是项目结构中根本就不存在这个包!!
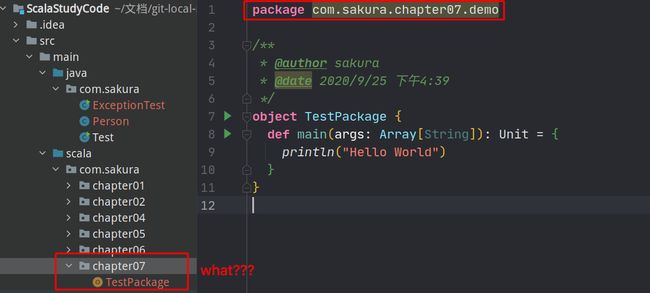
你敢在Java中这么写,编译器就直接报错给你看!但是Scala允许了,但是我们来看看文件系统的结构:
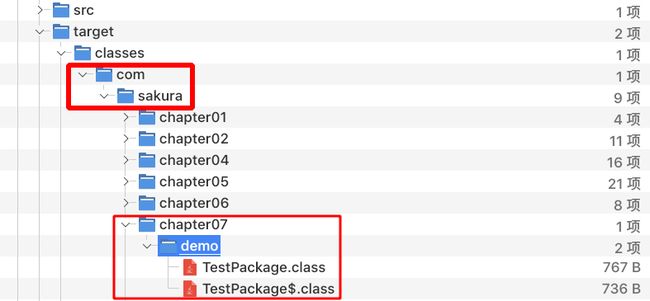
文件系统中还是老老实实创建了!!那我们改动一下代码上的package为com.sakura.chapter.demo02看看会发生什么?!
项目包结构还是那个样,但是文件系统中demo文件夹被删除,随之创建了demo2文件夹。
特点二:包的写法有多种
在Java中,包名都是写在文件的第一行的!
package xx.yy.zz
...
这种写法在Scala中也被保留了!但是扩展了另一种等价的写法:
package xx.yy
package zz
....
还有一种更特殊的写法,这种写法完全颠覆了传统Java包的书写规范!
居然可以在一个类文件中,同时存在多个包,并且分别编写各个包的类!!
package xx.yy {
class Car {
// ...
}
package zz {
class Car {
}
}
// ...
}
package aa.bb {
// ...
class Car {
}
}
包名后使用大括号包裹内容,划定包的内容范围。并且可以在同一个项目类中同时存在多个包(非嵌套式)!!但是通过编译之后,编译器会自动处理在文件系统中创建对应的包文件夹,每个类单独生成一个class文件!
7.3、包对象package object
刚才看完Scala包和Java包的区别,现在要学习一个Scala中特有的一个东西——包对象(package object)。这个包对象,和我们创建的包之间又有什么关系呢?!
为什么有包对象?有什么作用?
在Java中,所有的变量、方法都必须写在class中,而package里面只能有class的定义,package中是不能定义变量和方法的。当然scala中的package也是。于是Scala引出了包对象的概念。目的就是可以在package中定义变量和方法,并且这些变量和方法,是当前包下随处可用的!!
创建包对象
使用package object声明, 包对象的名字和与之作用的包名保持一致即可,例如
package sakura{
}
package object sakura {
}
当然在package下还是不能写变量和方法的。定义变量和方法都在package object下进行!
测试使用package object
package object sakura {
val name = "sakura"
var age = 20
def sayHi () = {
println("Hello World")
}
}
package sakura{
object TestSakura {
def main(args: Array[String]): Unit = {
// 直接使用package object中的方法和变量
println("info-> {" + s"name : $name" + s", age : $age}")
sayHi()
println("-----------")
val root:User = new User
println(s"username: ${root.username}" + s", age: ${root.user_age}")
print("User.sendMessage() => ")
root.sendMessage
}
}
// 包内随处可用
class User {
val username = name
var user_age = age
def sendMessage: Unit = {
sayHi()
}
}
}
上面这个例子中,在package object中定义的变量和方法,在其作用的package中随处可用,emmm,有点像java中class下定义的变量和方法,在class中也是随处可用!
反编译,查看实现过程
查看反编译的Java代码,看看是如何实现的:
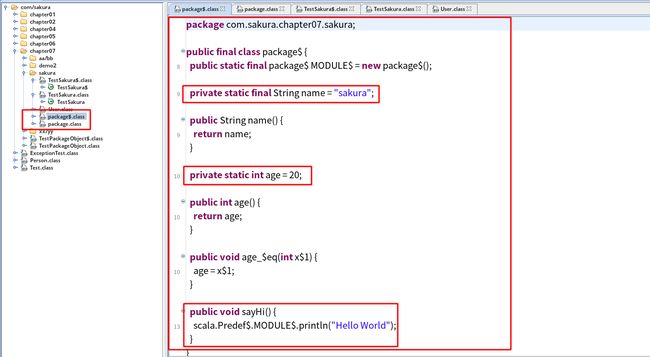
首先是创建了名为package$ 和 package的类
方法和变量定义都是在package$类中的,并且其给出了一个实例MODULE$便于其他位置调用类中的属性和方法。

可以看出,其底层的实现只是利用了一个类似于定义工具类的方式,并不高深。。
注意事项
- 每个package至多有一个package object
- package object的命名必须与包名一致!
- package和package object必须在同级包下定义!!(同一个父包)
7.4、访问权限
先回顾一下Java的访问权限修饰符:
| 访问权限 | 修饰符 | 同类 | 同包 | 子类 | 不同包 |
|---|---|---|---|---|---|
| 公共 | public | ✅ | ✅ | ✅ | ✅ |
| 受保护的 | protected | ✅ | ✅ | ✅ | ❌ |
| 不写,默认 | 无 | ✅ | ✅ | ❌ | ❌ |
| 似有 | private | ✅ | ❌ | ❌ | ❌ |
注意一下:这里的受保护的(protected)对子类是开放的!就算子类在不同包下也是可以的!
伴生对象和伴生类
在了解Scala的访问权限之前,有必要知道这两个东西。companion object和companion class。
例如:
object Test {
}
class Test {
}
这种情况,我们称object Test是class Test的伴生对象,编译后成为Test$.class文件。
class Test为object Test的伴生类,编译后为Test.class文件。
这俩东西出现的意义是什么呢?
在Scala设计过程中,抛弃了static关键字,但是静态成员、静态代码块又是常用的。于是规定将静态成员、方法、代码块都写在伴生对象中,实例成员写在伴生类中。
现在我们给出一段案例的Java代码:
class Student {
static {
System.out.println("创建了一个学生");
}
public static int count = 56;
private String name;
private String id;
public Student(String name,String id) {
this.name = name;
this.id = id;
}
public static void sayHi() {
System.out.println("你好,我是一名学生!");
}
public void introduce() {
System.out.println("My Name Is " + name + ", And My Id Is " + id);
}
}
像这样一个简单的Java类,其中包含了静态变量、静态代码块和静态方法,这些都隶属于这个class,而不属于某一个实例。同时还有两个成员变量以及一个成员方法,这些是与实例对象紧密关系的,只能通过实例化的对象调用或者修改。
现在我们要改写成scala代码,由于没有static关键字,所以静态部分要放到伴生对象中… 开干开干!!
object Student {
println("创建了一个学生")
var count:Int = 56
def sayHi: Unit = {
println("你好,我是一名学生!")
}
}
class Student(inName:String, inId:String) {
var name:String = inName
var id:String = inId
def introduce: Unit = {
println("My Name Is " + name + ", And My Id Is " + id)
}
}
注意!!这样改写,存在一个小小的点,就是在编译后会生成两个.class文件。
Student$.class和Studnet.class而我们在伴生对象(object Studnet)中写的那句输出,变成了Student$.class的静态代码块!
但是我们使用new创建Student对象的时候,并不涉及到静态部分的创建,所以理所当然也就摸不到
Student$.class,所以这句输出也就不会输出。但是在Java中,实例化类的时候第一件事就是执行静态代码块。所以你要是想看到这句输出,必须是在访问/修改静态部分的时候!例如:object Test { def main(args: Array[String]): Unit = { val s1:Student = new Student("Sakura","18130311") // 不输出 println(Student.count) // 输出,因为访问了静态变量count } }
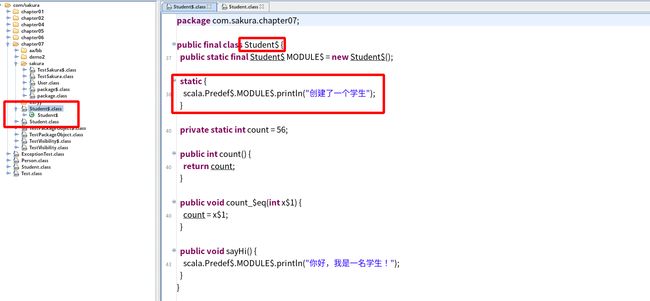
伴生类和伴生对象内容访问:
- 伴生类访问伴生对象中的内容,使用
类名.变量类名.方法。 - 伴生对象访问伴生类中的内容,必须通过实例化对象。
仔细体会一番,可以看出Scala中将类的静态部分和实例成员部分完完整整分离开来。但是使用起来还是和Java类似,当然也就牺牲了部分代码的易读性。我想可能这就是Scala作为纯面向对象语言做出的妥协和牺牲吧。
现在我们继续来学习Scala中的访问权限控制。。
学习了这么久的Scala,是不是发现我们已经很少写public、private这种访问权限关键字了?!这是因为Scala中变量、方法都是有默认的访问权限的!!
-
变量默认为private这里随说变量默认是private,但是默认生成了一套类似的getter/setter的方法,在外部依然可以通过这两个public方法访问/修改。
但是!!如果你显式使用private修饰,这一套getter/setter就变成了private的,也就保证了外部也调不到!
-
方法默认为public
还有几个特别重要的注意点!
- Scala中没有public关键字!!!
- Scala中的
protected相较于Java要更为严格!只允许同类、子类访问
在Scala中还有一个非常灵活的控制访问权限的方式,看代码!
package com.sakura.chapter07
class Student(inName:String, inId:String) {
private[aa] var name:String = inName
private var id:String = inId
def introduce: Unit = {
println("My Name Is " + name + ", And My Id Is " + id)
}
}
package aa {
object test {
val s1 = new Student("sakura", "18130311")
s1.name // 可以访问
s1.id // 拒绝访问
}
}
此处代码中Student是写在com.sakura.chapter07包下的,但是我们在写Student类的成员变量name的时候访问修饰使用的是private[aa]这种特殊写法。这中写法有什么特殊呢?我们继续往下看。
默认情况下private修饰的变量只能在同类下使用!也就是按理说name和id只能在Student这个class内部使用,外部是无法访问的!即s1.name和s1.id这种都是拒绝访问的。
但是!但是!偏偏就是private[aa]这种写法,让访问权限的控制更加灵活。在aa这个package下我们创建的Student对象,居然奇迹地访问到了对象内部的成员变量name!但是由于id并没有使用这种方式,被拒绝访问!**相当于是给某个包开了“后门”。**当然这种后门是可以延续到子包中的!
7.5、高级版Import
想比较Java的Import,在Scala中import的功能更加强大,使用起来也更加灵活便捷!
出现的位置更灵活
Java中import只能出现在package之后 class之前,但是在Scala中import出现的位置就比较随意,并且import是有作用范围的!上代码!
object TestImport {
object testA {
import java.util.HashMap
val map = new HashMap
}
object testB {
val map = new HashMap // 必须导包
}
}
很明显我们的import java.util.HashMap作用范围只在object testA这个大括号内!其他地方要用的话,就必须再导入一次。但是这样就方便一丢丢
object TestImport {
import java.util.HashMap
object testA {
// import java.util.HashMap
val map = new HashMap
}
object testB {
val map = new HashMap
}
}
所以说把握好import作用范围非常重要。
导入选择器
是不是很新鲜!!在Java中我们导入一个包下的某几个类的时候,需要写多个import,老烦了(好在IDEA可以自动导入。。)但是在Scala中我们可以使用导入选择器一个import就可以将一个包里的多个类同时导入!!
object TestImport {
object testA {
import java.util.{HashMap,ArrayList,HashSet} // 一个import导入三个类!
val map = new HashMap[Int,String]
val list = new ArrayList[String]
val set = new HashSet[String]
}
}
使用方式:import xx.xxx.{xxA, xxB, xxC, ...}大括号内写选择要导入的类。
导入时类重命名
我们偶尔在导包的时候会遇到要导入的类中存在类重名的情况。在使用的时候为了解决冲突前面还要加上包名。像这样=>
object TestImport {
object testA {
import java.util.HashMap
import scala.collection.mutable.HashMap
val map = new java.util.HashMap[Int, String]()
val map1 = new scala.collection.mutable.HashMap[Int, String]()
}
}
在Scala中,我们可以在import的时候使用重命名的方式来解决。
object TestImport {
object testA {
import java.util.{HashMap => MyMap}
import scala.collection.mutable.HashMap
val map = new MyMap[Int, String]()
val map2 = new HashMap[Int, String]()
}
}
对比上面可以看到在导入java.util.HashMap的时候,我们使用{HashMap => MyMap}将其重命名为MyMap。并且后续使用的时候,也将MyMap作为java.util.HashMap的别名使用。很好的解决了重名冲突的问题!
排除无用的冲突
在此之前有一个注意点!要导入某个包内的所有类不是像java中使用import xx.xx.*这种方式(用*表示通配所有)。而是使用import xx.xx._(使用_通配)。
回到正题,在解决上面说到的重名冲突的时候,我们会发现有些冲突是可以在导入时候通过排除无用类的导入避免掉的。比如我想用scala.collection.mutable.HashMap同时又要用到java.util包下的大部分类(除了HashMap)。那么我们这样写:
import java.util._
import scala.collection.mutable.HashMap
就会产生重名冲突,既然java.util.HashMap我们用不到,能不能在导入阶段就排除他不导入呢?当然是可以的!!写法如下:
object TestImport {
object testA {
import java.util.{HashMap => _, _} //导入java.util包下的所有成员类,但是排除java.util.HashMap类
import scala.collection.mutable.HashMap
val list = new ArrayList[Int]()
val map2 = new HashMap[Int, String]()
}
}
7.6、封装与继承
与Java大部分相同,但是还是存在小部分差异的!例如:Scala中移除了public关键字就会对其在封装的概念上与Java产生很大的不同!!
封装
由于Scala中的控制权限修饰符只剩下:private、protected、不写默认三种,少了public。那么它又是如何做到和Java一样的权限控制的呢?(其实我们在7.4的访问权限中已经说过了!)
当你在写Scala类的属性时候,三种访问修饰符最终影响的是这个属性对应的两个方法的访问权限!
例如:
class Person {
var name:String = "Sakura"
private var age:Int = 20
protected var sex:String = "Male"
}
看似三个属性使用的是不同的访问修饰,但是编译后的Java代码呢?!
public class Person {
// var name
private String name = "Sakura";
public String name() {
return this.name;
}
public void name_$eq(String x$1) {
this.name = x$1;
}
// private var age
private int age = 20;
private int age() {
return this.age;
}
private void age_$eq(int x$1) {
this.age = x$1;
}
// protected var sex
private String sex = "Male";
public String sex() {
return this.sex;
}
public void sex_$eq(String x$1) {
this.sex = x$1;
}
}
-
所有属性都是用
private修饰! -
既然都是private修饰,理论上外面都是访问不到的!但是实际上无论是对属性修改还是取值,都是依托其自动生成的
xxx()和xxx_$eq()两个方法。。 -
所以这两个方法的访问权限才是属性的“真正的访问权限”
例如:你看name我们没写使用默认的访问权限:其对应的两个方法就是public!
// var name private String name = "Sakura"; public String name() { return this.name; } public void name_$eq(String x$1) { this.name = x$1; }而相反,使用private修饰的age,对应的两个方法就是private,外部是无法调用的,自然就实现了无法访问无法修改!
那protected和默认情况下是一样的,但是外部依然是无法使用的,只能在子类或者同类下调用。为什么是这样?作为小白的我目前也不清楚。。
综上,总结出一句简单的话:
- Scala中所有对属性的访问,其实都是对方法的访问!
继承
这点和我们刚才讲的东西紧密相关!
我们先来尝试一个例子:
class HbuePerson {
var name:String = _
private var age:Int = _
var sex:String = _
private def showInfo: Unit = {
println(s"My name is $name, $age years old, a $sex")
}
def sayHi: Unit = {
println(s"Hi, my name is $name")
}
}
class HbueStudent extends HbuePerson {
var id:String = _
def introduce: Unit = {
println(s"I am a student, my name is $name, my id is $id")
}
}
object TestExtends {
def main(args: Array[String]): Unit = {
val student = new HbueStudent
student.id = "18130311"
student.name = "sakura"
student.sex = "boy"
student.introduce
student.sayHi
}
}
打断点debug一下:
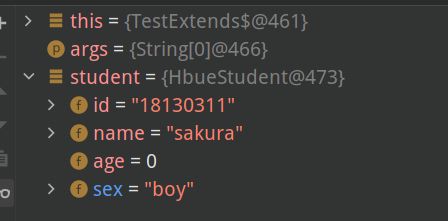
到这里不禁深思,不是说父类的私有属性是子类继承不到的吗?!所以就有了这个问题:
子类到底从父类那里继承到了什么?!
从语言的角度来讲:子类是不能使用父类中private属性,所以也就算不上对私有属性的继承。。
但是从内存的角度来讲:子类继承父类时是将子类和父类合成一个新的类,(如图,子父类的属性都在同一个对象的堆内存中)即子类在内存中拥有父类所有的方法和属性,只是父类的私有部分子类无法访问罢了!!
再看看编译后的Java代码:
属性全部都是private修饰,那是不是原理上所有的属性子类都访问不到呢?!当然不是,因为子类访问父类的属性还要通过那俩方法!!
所以说来说去还是那句话:在Scala中,访问对象的属性都要通过对应的方法完成!!
好好理解这句话,有助于我们后续学习属性覆盖重写。。
7.7、方法重写
使用到继承,那么就会涉及到对父类的方法进行重写这一重要步骤!总体上来说和Java中的方法重写区别不大,只需要注意两点:
- 子类中重写的方法要使用
override关键字修饰 - 在子类中重写了父类的方法后,要调用父类的方法要使用
super.MethodName方式调用。与子类中重写的方法加以区别!
用一个例子来描述一下:
class Person {
def showInfo: Unit = {
println("I am a Person")
}
}
class Student extends Person {
// 使用override修饰 表示对父类方法的重写
override def showInfo: Unit = {
// 使用super关键字调用父类的方法,以区别子类中重写的方法
super.showInfo
println("and I am a Student")
}
}
7.8、类型检查与转换
除了上面的方法重写的问题,再就是子类继承父类引出的多态的问题。
一个父类的引用是可以接受所有子类的引用的,而不同的子类内部结构不同,所以我们在使用的时候要做类型的检查和转换!!
Tip: Scala中可以使用
xx.getClass.getName获取对象的类型的全限定类名!
类型检查:isInstanceOf[]
类型转换:asInstanceOf[]
两者都不会改变对象的类型,后者类型转化只是暂时将对象转为xx类型,但是并不会改变对象本身。
object TypeConvert {
def main(args: Array[String]): Unit = {
val p1:Person = new Student
val p2:Person = new Coder
// 此时p1、p2都是Person类型 无法调用到其引用类型的独有方法!
// 例如:p1.study p2.coding 都是无法调用的
doSomething(p1)
doSomething(p2)
}
def doSomething (p:Person): Unit = {
if (p.isInstanceOf[Student]){ // 判断p是不是Student类型
p.asInstanceOf[Student].study
} else if (p.isInstanceOf[Coder]) { // 判断p是不是Coder类型
p.asInstanceOf[Coder].coding
} else {
println("类型转换失败...")
}
}
}
class Person {
def showInfo: Unit = {
println("I am a Person")
}
}
class Student extends Person {
override def showInfo: Unit = {
println("I am a Student")
}
def study: Unit = {
println("I am studying...")
}
}
class Coder extends Person {
override def showInfo: Unit = {
println("I am a Coder")
}
def coding: Unit = {
println("I am 996 working...")
}
}
可以发现在没有使用类型转换之前,在出现多态的情况下时,只能使用父类的方法,子类特有的方法是无法调用的!!但是使用了类型转换后,子类的方法再次出现。。
类型转换,不是你想转就能转!无法相互转化的类型,强制转换就会产生类型转换异常:
java.lang.ClassCastException所以在出现的多态的情况下:
一定要做类型检查,特别是做类型转化之前!!
7.9、继承中构造器调用
在前面的继承学习中,我们都没有涉及到对父类构造器的调用,其实在Scala中对父类的构造器调用是一件较为复杂的事情。不像Java那样,可以直接使用super(parameter..).
而且在前面学习构造器的时候就说到过,在构造器方面Java和Scala是有很大不同的!
先来看Java的示例代码:
public class TestConstractor {
public static void main(String[] args) {
}
}
class Person {
public String name;
public int age;
public Person (String inName, int inAge){
name = inName;
age = inAge;
}
public Person() {
name = "sakura";
age = 18;
}
}
class Student extends Person {
public String id;
public Student(String inName, int inAge, String inId) {
super(inName,inAge);
id = inId;
}
public Student(String inId) {
super();
id = inId;
}
}
Java中,子类可以使用super(…)任意调用父类的所有构造器。
但是在Scala中,辅助构造器必须间接/直接显式调用主构造器。而在Java中就知道,子类的所有构造器调用都必须先调用父类的构造与父类进行联系。(不写默认调用父类的空参构造,即super())。那么对父类构造器的调用这件事情就只好交给主构造器来做,那么辅助构造器在间接/直接调用主构造器时就必定会调用到父类的构造器!
那么所有的辅助构造器就无法自主选择调用那个父类构造器了,全由主构造器来选择。(而Java中使用super(),想调哪个就用哪个。。)
来猜猜看下面这段代码的输出:
object TestConstructor02 {
def main(args: Array[String]): Unit = {
val student = new Student()
}
}
class Person(inName:String, inAge:Int) {
var name:String = inName
var age:Int = inAge
println("Person(inName,inAge)")
def this(inName:String) {
this(inName,18);
println("Person this(inName)")
}
def this() {
this("sakura",18)
println("Person this()")
}
}
class Student(stuName:String, stuAge:Int, stuId:String) extends Person(stuName,stuAge) {
var id:String = stuId
println("Student(stuName, stuAge, stuId)")
def this (stuName:String, stuAge:Int) {
this(stuName,stuAge,"181303xx")
println("Student this(stuName, stuAge)")
}
def this() {
this("sakura",18,"18130311")
println("Student this()")
}
}
这是构造器的调用结构:
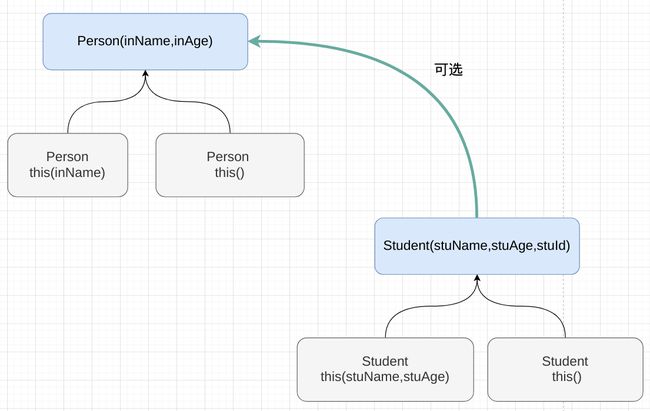
所以程序的调用顺序应该是:
Person(inName,inAge)Student(stuName,stuAge,stuId)Student this()
向上溯源到顶层父类然后向下依次执行。。
不管子类Student继承父类Person时使用的是那个父类的构造器,最终也还是会调用到父类的主构造器。(即那个绿色的线不管指向父类的哪个构造器,最终溯源都会到父类的主构造器上。)
总结一下就是:
子类调用父类的构造器只有一个“入口”,即子类的主构造器。子类的辅助构造器不能直接调用父类的构造器!
7.10、Java字段隐藏与动态绑定
在Java的学习过程中我们之了解过方法的覆写,并没有听说过字段的覆写。其实Java中存在一个字段隐藏的机制!
什么是字段隐藏呢?
我们先用个例子来试试:
public class FieldOverrideTest {
public static void main(String[] args) {
Super obj1 = new Super();
Super obj2 = new Sub();
Sub obj3 = new Sub();
System.out.println(obj1.str); // 父类的str
System.out.println(obj2.str); // 父类的str
System.out.println(obj3.str); // 子类的str
}
}
class Super {
public String str = "父类的str";
}
class Sub extends Super {
public String str = "子类的str";
}
是不是感觉有点匪夷所思?obj2明明创建的是一个Sub对象,但是输出的内容为什么是Super类中的内容呢?其实这就是字段隐藏。
当父类和子类拥有同名的public属性(字段)的时候,对字段取值的结果取决于你用什么引用去取。
如上这个例子:虽然obj2是一个Sub对象,但是它被交给了一个父类引用。所以取值就是取父类中的字段值。而子类中的同名字段就被“隐藏”。
那猜猜:
((Super)obj3).str = ?
((Sub)obj2).str = ?
答案是:
((Super)obj3).str = "父类的str"
((Sub)obj2).str = "子类的str"
说简单一些,即使子类和父类中存在了重名的字段。相互不会影响,取值方式不同取到的值也不同!!所以建议大家不要这样做,会提高代码的阅读难度!!
说到这里,那么就不得不谈Java的另一个重要机制了:动态绑定机制
动态绑定(auto binding):也叫后期绑定,在运行时,虚拟机根据具体对象的类型进行绑定,或者说是只有对象在虚拟机中创建了之后,才能确定方法属于哪一个对象。
与之对应的是
静态绑定(static binding):也叫前期绑定,在程序执行前,该方法就能够确定所在的类。
我们先给出两个类:
class A {
public int i = 10;
public int sum() {
return getI() + 10;
}
public int sum1() {
return i + 10;
}
public int getI() {
return i;
}
}
class B extends A {
public int i = 20;
@Override
public int sum() {
return getI() + 20;
}
@Override
public int sum1() {
return i + 10;
}
@Override
public int getI() {
return i;
}
}
来猜猜下面这段代码的结果:
public class AutoBindingTest {
public static void main(String[] args) {
A obj = new B();
System.out.println(obj.sum());
System.out.println(obj.sum1());
}
}
不要受刚才的字段隐藏的影响,虽然是一个B对象交给了A的引用,但是在对象装入JVM虚拟机的时候,由于B是继承于A的,所以他会拥有一个方法表,其中包含了所有他可以调用的方法(包括父类的!)
程序运行时,会先查方法表,若本类中有就直接调用,否则调用父类的。
所以结果显而易见:
40 // 20(B.getI) + 20
30 // 20(B.i) + 10
可是当我将B类中的sum()方法注释掉以后,结果奇迹般变成了
30 // 20(B.getI) + 10 (A.sum)
30
这不河里啊!!就算是调用父类的sum()那也应该是10+10=20啊!
难不成调用父类(A)的sum()的时候,getI取的是B中的i ??!
诶,你猜对了!!不妨对代码Debug一下吧!在执行obj.sum()的时候准确认无误跳转到了A的sum()这里,可以在执行其中的getI()的时候,鬼使神差去调用了B的!这是为什么?我们等下再说。。。
现在我们将B中的sum1()注释,将sum()还原:结果是
40
20
这个是我们能够预料到的,分别对应B.sum()和A.sum1(),getI和i都是使用的各自的。
现在我们将B中的sum()和sum1()都注释掉:结果是
30 // B.getI + 10 (A.sum)
20 // A.i + 10 (A.sum1)
总结前面两次的结果,这个应该也是在意料之中。说明在调用getI的时候,还是使用的B的getI()。
下面来对动态绑定机制做一个简单解释和小结:
- 当你在调用方法的时候,JVM会先去查找对象的方法列表,执行对应的方法(本类没有的 调父类的!)
- 但是当你直接调用属性的时候,(例如上面
sum1()直接使用i这个成员属性)没有动态绑定机制,在哪里调用就用哪个的。(比如你调用A的sum1(),要用到i这个属性,那就直接用A的。)
当然这只是一种便于理解的解释方式,更加严谨的解释可以查阅相关博客!!
7.11、Scala字段覆写
对比Java来说,Scala的字段覆写是一个全新的东西!
之前我们使用Java编写代码的时候,子类和父类下是允许有同名的字段的!!只不过使用了隐藏字段的方式解决了调用时可能出现的问题。
但是在Scala中,是不能子类和父类存在同名字段的,只能是子类覆写父类的字段!
代码:
object ScalaFieldOverride {
def main(args: Array[String]): Unit = {
val a = new A
val b = new B
println(a.str) // 我是A类
println(b.str) // 我是B类
}
}
class A {
val str:String = "我是A类"
}
class B extends A {
override val str:String = "我是B类"
}
==注意:var类型的字段是不能被覆写的!(mutable variable cannot be overridden)==其他的注意事项我们稍后再说。
前面讲Scala的字段调用的时候,我们就说过,对于属性的调用其实都是调用相关的方法即xx()。那么这里的字段覆写,我们可以猜到,那么也肯定生成了相应的取值方法,也就保证了调用的时候能够正确调到!
注意事项一:
val类型的字段必须使用val覆写。(若是使用var,都会改变字段的可操作范围!![只读变为了可读可写])
注意事项二:
每个def只能覆写另一个def!(即方法只能覆写另一个方法!)
注意事项三:
无参的方法可以使用val属性覆写!(方法的返回值类型 与 覆写字段的类型相同)
针对注意事项三,这里有个案例:
object ScalaFieldOverride {
def main(args: Array[String]): Unit = {
val a = new A
val b = new B
println(a.testA()) // 我是A类
println(b.testA) // Hello
}
}
class A {
val str:String = "我是A类"
def testA(): String = {
return str;
}
}
class B extends A {
override val str:String = "我是B类"
override val testA:String = "Hello";
}
为什么偏偏是无参的方法可以使用val属性的字段覆写呢?
想想看我们使用val进行字段覆写的时候,就自动生成了一个无参的、与字段同名、返回值类型与字段相同的方法!那这里也是同样的道理,所以你完全可以把那个无参的方法看作一个val类型的字段!
来看看反编译后的Java代码:
public class A {
private final String str = ";
public String str() {
return this.str;
}
public String testA() {
return str();
}
}
public class B extends A {
private final String str = ";
public String str() {
return this.str;
}
private final String testA = "Hello";
public String testA() {
return this.testA;
}
}
抽象类初见面
Scala中也是有抽象类的!不过现在我们要了解的东西叫做抽象属性!
在Scala中,之前我们说过**变量声明的时候就需要赋一个初始化值。但是抽象属性就不需要!但是抽象属性只能存在于抽象类中!!抽象类需要使用abstract关键字修饰!**抽先类中也可以存在普通字段。
abstract class MyAbstractClass {
// 这是一个抽象属性,没有初始值!
var str:String
// 这是一个普通属性
var num:Int = 10;
}
**抽象属性在编译后也会生成那两个方法,但是都是抽象的方法,也就意味着我们必须实现那俩方法才能使用这个属性!!**来看看反编译得到的Java代码:
public abstract class MyAbstractClass {
private int num = 10;
public abstract String str();
public abstract void str_$eq(String paramString);
public int num() {
return this.num;
}
public void num_$eq(int x$1) {
this.num = x$1;
}
}
Scala代码中我们貌似是声明了一个属性,实则是声明了两个抽象方法,**当子类继承抽象类的时候,必须实现这俩抽象方法!**我们现在用一个子类来实现一下:
class MySimpleClass extends MyAbstractClass {
override var str: String = "Hello World"
}
其实这算不上是方法覆写,应该只是对抽象的实现,所以override关键字是可以省略掉的!
查看反编译后的代码:
public class MySimpleClass extends MyAbstractClass {
private String str = "Hello World";
public String str() {
return this.str;
}
public void str_$eq(String x$1) {
this.str = x$1;
}
}
7.12、抽象类
抽象类是什么,什么作用 这些不用多说,Java中都多少有了解。在Scala中,抽象类可以包含抽象字段(属性),抽象方法,以及普通字段和方法。
由于Scala中abstract关键字只能用于修饰Class,所以**抽象方法不需要使用abstract关键字!只需要按照普通方法一样声明,省去方法体即可!**抽象字段不需要初始值!
abstract class MyAbstractClass {
// 这是一个抽象属性,没有初始值!
var str:String
// 这是一个普通属性
var num:Int = 10;
// 这是一个抽象方法
def abstractMethod(param:String)
}
注意点:
- 抽象类不一定有抽象方法,抽象属性
- 抽象类无法实例化
- 抽象属性和抽象方法不能使用
private、final关键字修饰,与继承实现违背!- 子类继承抽象类,必须实现抽象内容(抽象方法、抽象字段)
- 对抽象方法、抽象字段的实现可以省略
override
上面说抽象类不可以实现,确实如此,但是我们可以使用匿名子类来模拟一下抽象类的“实现”
object AbstractClassTest {
def main(args: Array[String]): Unit = {
val anonymousObj = new MyAbstractClass {
override var str: String = "Hello World"
override def abstractMethod(param: String): Unit = {
println(param + ", i am not a abstract method")
}
}
}
}
在创建对象的时候,同时完成对抽象部分的实现。这就是匿名子类,一次性使用。
Chap08.Scala面向对象高级特性
8.1、细说伴生类和伴生对象
在7.4节,我们简单接触了伴生类和伴生对象。现在我们来细节了解一些伴生类和伴生对象!
为什么出现这俩东西?!Scala的设计者不满意Java中将静态的内容写在类中,认为其破坏了面向对象的设计概念,于是在Scala中直接舍弃了static这个关键字!但是静态的内容,还是得用啊,又不能写在class里面,那咋办呢?于是伴生对象就出现了并担此重任!我们将以前所有写在类中的静态内容(静态成员、静态方法),现在全部写在伴生对象中!
伴生对象和伴生类基础模板:
// Student的伴生类
class Student {
// ...
}
// Student的伴生对象
object Student {
// ...
}
我们按照既定的规则,来写一个,看看反编译后的Java代码究竟长什么样!
object TestCompanion {
def main(args: Array[String]): Unit = {
val zs = new Student("张三", 18)
val ls = new Student("李四", 20)
zs.introduce()
Student.countStu()
}
}
class Student(inName:String, inAge:Int) {
var naem:String = inName
var age:Int = inAge
cnt = cnt + 1
def introduce(): Unit = {
println(s"My name is $naem, I am $age years old.")
}
}
object Student {
var cnt:Int = 0;
def countStu(): Unit = {
println(s"现在共有${cnt}个学生!")
}
}
这段代码中我们将实例成员都放在了class中,静态成员都放在object中。并对静态成员进行了调用,我们来看看反编译的Java代码吧!
Student
public class Student {
private String naem;
private int age;
public static void countStu() {
Student$.MODULE$.countStu();
}
public static void cnt_$eq(int paramInt) {
Student$.MODULE$.cnt_$eq(paramInt);
}
public static int cnt() {
return Student$.MODULE$.cnt();
}
public String naem() {
return this.naem;
}
public void naem_$eq(String x$1) {
this.naem = x$1;
}
public int age() {
return this.age;
}
public void age_$eq(int x$1) {
this.age = x$1;
}
public void introduce() {
Predef$.MODULE$.println((new StringBuilder(29)).append("My name is ").append(naem()).append(", I am ").append(age()).append(" years old.").toString());
}
public Student(String inName, int inAge) {
this.naem = inName;
this.age = inAge;
Student$.MODULE$.cnt_$eq(Student$.MODULE$.cnt() + 1);
}
}
Student$
public final class Student$ {
public static final Student$ MODULE$ = new Student$();
private static int cnt = 0;
public int cnt() {
return cnt;
}
public void cnt_$eq(int x$1) {
cnt = x$1;
}
public void countStu() {
scala.Predef$.MODULE$.println((new StringBuilder(8)).append(").append(cnt()).append(").toString());
}
}
请先好好看看这两个反编译出来的Java类。
你会发现Student类是完全符合我们Java写法的(除了静态变量没有体现),静态方法也有,这个类就是伴生类的反编译代码!
(可能你会疑问,不是说了静态内容写在伴生对象中的吗?!为什么这里面出现了static方法?!)
那你仔细看看会发现,这些个静态方法中,实际都用到了这样一个东西Student$.MODULE$.xxx,而这个本身没有其他实质性的内容,这下就引出了伴生对象!
Student$这个类就是伴生对象反编译出来的!而这个MODULE$则是这个类的一个static final实例(仅有一个,并且直接使用!)
你看这个类中,虽然方法都不是静态的,但是在Student的静态方法底层都是通过MODULE$这个唯一实例来调用的,所以对外部来说,感觉这些就是静态的!
所以Scala中都是依赖MODULE$来实现静态特性的!
看完上面的代码,注意几个点:
- 伴生对象中的内容,可以像Java中使用静态内容一样使用!用类名访问/调用
- 伴生对象和伴生类的声明必须写在同一个源码文件中!!
8.2、伴生对象的Apply方法
当定义了伴生类和伴生对象的时候,可以在伴生对象中定义apply方法,可以直接使用类名加参数创建对象,不必使用new关键字!
示例:
object TestApply {
def main(args: Array[String]): Unit = {
// 传统创建对象的方法
val cat1 = new Cat("来宝")
// 使用apply触发伴生类创建对象
val cat2 = Cat("书宝")
val cat3 = Cat()
println("cat1: " + cat1.name) // 来宝
println("cat2: " + cat2.name) // 书宝
println("cat3: " + cat3.name) // 无名猫
}
}
class Cat(inName:String) {
var name:String = inName
}
object Cat {
def apply(inName: String): Cat = new Cat(inName)
def apply(): Cat = new Cat("无名猫")
}
这种做法,便于我们将类的构造器设置为私有的!
8.3、Scala的“接口”—trait(特征、特质)
在Scala中,没有interface关键字,那么接口这么重要的东西就直接被移除了吗?!当然不行!全靠抽象类是解决不了问题的,在Scala中类还是只能单继承。所以必须要有一个东西来代替Java中的interface! 于是trait闪亮登场!
trait翻译意思为:特征、特质。很形象,就是将类的基本特征提取出来,然后用于给其他类继承实现!
trait的基本使用
-
使用
trait关键词声明创建一个特质 -
其他类使用
extends关键词继承/实现此特质注意:当类需要继承父类并同时实现多个特质的时候,使用
with关键词连接,继承的父类写在前面!例如:
class Son extends Father with Trait01 with Trait02 with ...
下面来一个最简单的示例:
object TraitDemo01 {
def main(args: Array[String]): Unit = {
val pig = new Pig
pig.snore()
pig.sleepTalk()
}
}
class Pig extends Sleep {
override def snore(): Unit = {
println("呼~~~~")
}
override def sleepTalk(): Unit = {
println("我要吃螃蟹~~吃披萨~~")
}
}
// 这是一个trait
trait Sleep {
// 下面是待实现的抽象方法
def snore()
def sleepTalk()
}
上面的代码反编译为Java代码后的样子:
trait:

实现类:

是不是一下就有内味了!
我们知道在Java中接口里面声明的变量都是常量(final修饰的)!!
而且之前在Java的接口中是不能写已经实现的方法的,后来出现了default关键字,用这个关键词在接口中声明方法可以有方法体,其他类实现接口的时候不要求重写实现,但是可以进行覆写!
trait中既有实现方法又有抽象方法的又成为 “富接口 ”
那么在trait中又是个什么情况呢?!来试试看吧:
首先来看trait中声明属性(var类型)
trait Sleep {
var name:String = "噜噜"
}
你会发现这个属性在其实现类中仍然可以修改值,这也在情理之中,毕竟Scala中属性的修改和调用都是通过方法来实现的。直接来看反编译的Java代码吧!!
public interface Sleep {
String name();
void name_$eq(String paramString);
static void $init$(Sleep $this) {
$this.name_$eq("噜噜");
}
}
public class Pig implements Sleep {
private String name;
public String name() {
return this.name;
}
public void name_$eq(String x$1) {
this.name = x$1;
}
public Pig() {
Sleep.$init$(this);
}
}
与7.11和7.12中我们讲的抽象类一样,看似是声明了一个属性,其实是声明了两个抽象方法留给实现类来实现!
仔细看看还有初始化的操作,实现类的构造器中调用接口中的静态方法$init$,静态方法直接使用xxx_$eq()的默认实现为属性赋值!与Java不同:这个属性不属于接口(Trait),而是属于每个实现此Trait的类!
下面是在Trait中写已实现的方法
class Dog extends Eat {
// override def findFood: Unit = {
// println("发现骨头!!汪汪汪~~")
// }
}
trait Eat {
def findFood: Unit = {
println("发现食物!!")
}
}
同样,不强制要求实现!但是也可以选择覆写。即使不覆写也能使用默认的方法体!
先来看看不覆写的时候的调用过程:反编译的代码:
trait:
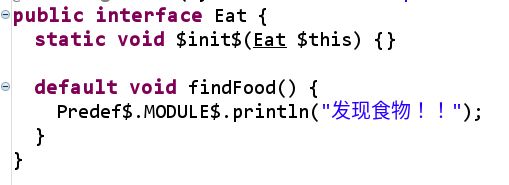
平平无奇,果真就是default关键字!
实现类:

直接使用接口中的default方法!!外界调用的时候相当于直接使用默认的实现(即接口中已实现的)
下面我们在实现类中,将方法覆写看看:
class Dog extends Eat {
override def findFood: Unit = {
println("发现骨头!!汪汪汪~~")
}
}
反编译后,可以看出只是将实现类中原来的调用接口默认实现换成了覆写的内容:

综上来看:Scala中Trait完成了Java中interface的几乎全部的功能!完全可以按照interface的使用方式来使用trait!!
8.4、动态混入
初次看到这个词可能会感到新鲜,“动态混入”的出现是为了优化Java中的接口实现,做到真正意义上的松散组合降低耦合!
回想一下Java中的接口实现,类实现接口后,是会永久性影响到类本身的内容的!但是利用动态混入后,可以在不改变类的声明的定义的情况,按需对类进行扩展!(是不是听起来就感觉很炫酷!)
初次尝试:
object DynamicMixinDemo01 {
def main(args: Array[String]): Unit = {
val animal_A = new Animal
animal_A.sayHi() // 普通对象,未进行扩展
// 动态混入 Hunt
val animal_B = new Animal with Hunt
animal_B.catchMice
// 动态混入 MakeNoise
val animal_C = new Animal with MakeNoise
animal_C.shout
// ...
val animal_D = new Animal with Hunt with MakeNoise
animal_D.catchMice
animal_D.shout
// 以上是使用动态混入 进行了扩展了对象
}
}
class Animal {
def sayHi(): Unit = {
println("我是一个动物!")
}
}
trait Hunt {
def catchMice: Unit = {
println("抓到一只耗子")
}
}
trait MakeNoise {
def shout: Unit = {
println("miao~~miao~~~")
}
}
你会发现,上面案例中我们动态混入的Trait(特制)都是只有实现方法的,其实一般情况下特制中都是抽象方法,那么在动态混入的时候,就要求对抽象方法进行实现!如下:
val animal_D = new Animal with Hunt with MakeNoise {
override def shout: Unit = {
println("......")
}
// ...其他抽象方法的实现
}
很容易看出来,我们在使用动态混入后,并没有修改主类(Animal类)中的任何内容,并没有涉及到对其的修改!单单使用with关键字在创建对象的时候对类进行扩展!!降低了trait和class之间的耦合!
8.5、动态混入的叠加机制
上面我们简单学习了动态混入,并且见识到了它所带来的便捷!但是在使用动态混入的时候我们还需要注意一些细节!
动态混入的混入顺序:
从左往右!
什么是混入顺序呢?有什么影响呢?
当我们同时混入多个特质,总该是有个混入的顺序吧!(Trait中的“静态代码”在混入的时候就会执行,所以混入的顺序会影响他们的执行顺序…)
示例:
object DynamicMixinDemo02 {
def main(args: Array[String]): Unit = {
val obj = new SimpleClass with MyTraitD with MyTraitC
}
}
class SimpleClass {
}
trait MyTraitA {
println("Mixin MyTraitA~")
def showInfo(): Unit = {
println("I mixed MyTraitA")
}
}
trait MyTraitB extends MyTraitA {
println("Mixin MyTraitB~")
override def showInfo(): Unit = {
super.showInfo()
println("I mixed MyTraitB")
}
}
trait MyTraitC extends MyTraitB {
println("Mixin MyTraitC~")
override def showInfo(): Unit ={
super.showInfo()
println("I mixed MyTraitC")
}
}
trait MyTraitD extends MyTraitB {
println("Mixin MyTraitD~")
override def showInfo(): Unit = {
super.showInfo()
println("I mixed MyTraitD")
}
}
代码案例中一共有有四个Trait:MyTraitA、MyTraitB、MyTraitC、MyTraitD,他们的关系如图:
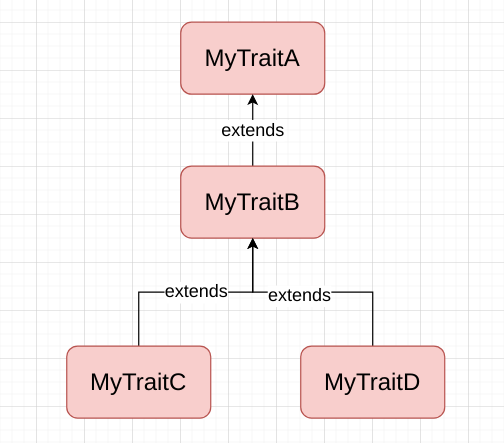
我们创建对象时候,同时混入了MyTraitC和MyTraitD:
val obj = new SimpleClass with MyTraitD with MyTraitC
但是程序运行的输出结果是:
Mixin MyTraitA~
Mixin MyTraitB~
Mixin MyTraitD~
Mixin MyTraitC~
解释这个输出就要用到动态混入的叠加机制,前面我们说了混入顺序是从左往右,所以代码的执行过程就是:
- 混入MyTraitD过程:
- 开始混入MyTraitD,发现其有父类,为MyTraitB
- 开始混入MyTraitB,同样发现父类MyTraitA
- 开始混入MyTraitA,执行静态代码块
- 执行MyTraitB的静态代码,执行MyTrait的静态代码…
- 混入MyTraitC过程:
- 开始混入MyTraitC,发现有父类MyTraitB
- 发现前面已经完成了MyTraitB、MyTraitA的混入,根据叠加机制,不必重复混入
- 执行MyTraitC的静态代码…
动态混入的Trait之间的“父子”关系
方法执行顺序从右往左(不完全正确!和混入顺序有关!)
为什么混入的顺序的不同,会影响Trait的父子关系?!
在使用动态混入的时候,父子关系取决于混入的顺序!
案例:还是上面的代码,现在我们执行
val obj = new SimpleClass with MyTraitD with MyTraitC
obj.showInfo();
按照上面的提示,方法执行是从右往左,那么就应该是执行MyTraitC中的showInfo(),若没有就执行MyTraitD中的,若还是没有再执行MyTraitB中的,然后逐级向上。。
输出结果是这样的:
I mixed MyTraitA
I mixed MyTraitB
I mixed MyTraitD
I mixed MyTraitC
!!可以看出在执行MyTraitC中showInfo()的时候,调用的super.showInfo()的时候是调到了MyTraitD的!可是MyTraitC声明的时候父类是MyTraitB啊!!
这就是刚才所说的使用动态混入,增加、改变了父子关系!
结合上面两个案例,可以看出使用动态混入时候,**一定要注意混入的顺序!!**否则直接影响到代码的运行结果,混入顺序决定了代码的执行顺序,并且可能增加/改变无关Trait之间的父子关系!
**&&*由于混入的顺序是严格按照父子继承顺序来的!所以是不会改变原有的父子关系的!但是会增加无关类之间的父子关系!!!
比如这个:
val obj2 = new SimpleClass with MyTraitB with MyTraitA obj2.showInfo()你觉得是先执行MyTraitA中的showInfo()吗?那么你猜的结果就是
I mixed MyTraitB
I mixed MyTraitA那你就错了!实际输出是:
I mixed MyTraitA
I mixed MyTraitB你推导推导混入的顺序。。
是不是MyTraitA -> MyTraitB。所以即使使用了动态混入,也不会改变MyTraitA是MyTraitB父类这个既定事实!!所以上面说的方法执行顺序从右到左 指的是混入顺序的从右到左!
总结一下!!!!
在动态混入没有继承关系的Trait的时候,会为他们附上父子关系!混入顺序将决定谁是子谁是父!!
8.6、动态混入时抽象方法部分实现
之前的案例二中,我们说过特质方法中的使用的super不一定就是调用声明时的父类方法!!而是参照混入的顺序来决定!实在混入顺序中没有了,才去真正的父类中去找!
**在特质方法实现的时候有个问题:如果在实现方法中调用super, 会如何?**Scala的神奇操作会让你大吃一惊!!
例如这样:
trait MyTrait1 {
def func()
}
trait MyTrait2 extends MyTrait1 {
override def func(): Unit = {
println("MyTrait2 func()")
super.func()
}
}
神奇的是,这样写没有语法报错!但是编译运行出错了!
method func in trait MyTrait1 is accessed from super. It may not be abstract unless it is overridden by a member declared abstract and override
它给出的解决方案就是,重写方法使用abstract override修饰!
当你给MyTrait2的func加上abstract之后,居然没有运行报错了!神了!
trait MyTrait1 {
def func()
}
trait MyTrait2 extends MyTrait1 {
abstract override def func(): Unit = {
println("MyTrait2 func()")
super.func()
}
}
以上这种做法,我们暂且称其为抽象方法的部分实现!因为它确实实现了部分,但是还是一个抽象方法,需要其他类来完全实现!而这里的super在碰上动态混入的时候就会变得很有灵性!(反正肯定不会指向MyTrait1!!)
当你创建一个类只混入MyTrait1的时候,会要求你实现func()!
当你创建一个类只混入MyTrait2的时候,会告诉你这个func()已经在MyTrait2中部分实现了(使用abstract override声明了),但是在使用了动态混入后的类中,找不到这个方法的完整实现!!
这两个错误都是一个原因!因为你使用了动态混入,那个时候是在创建一个对象!对象里面肯定是不能存在抽象方法的!!你要不给我实现,要不就不要混入进来!!
那么第二个错误,要如何解决呢?!
-
简单粗暴!去掉
abstract override告诉他:爷就是一个抽象方法的完整实现!并且去掉super或者去掉extends MyTrait1 -
再用若干个特质来完整实现这个func()!!
object DynamicaMixinDemo03 { def main(args: Array[String]): Unit = { val obj = new SimpleClass with MyTrait3 with MyTrait2 obj.func() } } trait MyTrait1 { def func() } trait MyTrait2 extends MyTrait1 { abstract override def func(): Unit = { println("MyTrait2 func()") super.func() } } trait MyTrait3 extends MyTrait1 { override def func(): Unit = { println("MyTrait3 func()") // super.func() 这行不能写!!为什么?! } }
以上的代码有几个注意点!!!
为什么MyTrait3是extends MyTrait1而不是MyTrait2?!
想想看,如果extends MyTrait2,那么混入的顺序按照父子关系是不是就是MyTrait1->MyTrait2->MyTrait3 ,那么MyTrait2中的func那行
super.func()还是调到了MyTrait1的脸上!!当然会报错~~可是如果extend MyTrait2,那么按照混入顺序(MyTrait1->MyTrait3->MyTrait2)原本毫无关系的MyTrait2和MyTrait3就带上了父子关系,那么MyTrait2中的super就指向了MyTrait3~~再一看MyTrait3中的func是一个已经实现的方法!!(可是如果MyTrait3这个杀千刀的没有实现func,或者只是部分实现,那就又会报错了!)
为什么这个混入顺序下,MyTrait3中func中最后一行super.func()不能写?!
和混入的顺序无关!因为从语法层面上你MyTrait3的父类还是MyTrait1,那么你就不能使用
super.func()!因为编译的时候,不能确保你的混入顺序。那么暂时就把MyTrait1当作super,当然就无法通过。混入顺序能不能先MyTrait2再MyTrait3
在不修改特质的代码的情况下,是不行的!因为按照修改后这个混入顺序,MyTrait2中func的super.func()会引起错误!!!
梳理一下后,来看看这段代码:猜猜看输出!
object DynamicaMixinDemo03 {
def main(args: Array[String]): Unit = {
val obj = new SimpleClass with MyTrait4 with MyTrait2 with MyTrait3
obj.func()
}
}
trait MyTrait1 {
def func()
}
trait MyTrait2 extends MyTrait1 {
abstract override def func(): Unit = {
println("MyTrait2 func()")
super.func()
}
}
trait MyTrait3 extends MyTrait1 {
abstract override def func(): Unit = {
println("MyTrait3 func()")
super.func()
}
}
trait MyTrait4 extends MyTrait1 {
override def func(): Unit = {
println("MyTrait4 func()")
}
}
先判断混入顺序:MyTrait1->MyTrait4->MyTrait2->MyTrait3
答案显而易见!!
MyTrait3 func()
MyTrait2 func()
MyTrait4 func()
总结一下!!!!
那些**对方法部分实现的特质,绝对不能最先混入!!**反而是对方法完全实现了的放在最先混入!
当实现抽象方法的时候,只要用了
super访问父类的东西,就要使用abstract override声明为部分实现!
8.7、动态混入的特质字段
当混入的特质带有字段的时候,那么字段会直接加入到对象中!不是通过继承!是直接加入!
object DynamicMixinDemo04 {
def main(args: Array[String]): Unit = {
val obj1 = new SimpleClass with SimpleTrait
obj1.num = 2000
println(obj1.num) // 2000
val obj2 = new SimpleClass with SimpleTrait
println(obj2.num) // 2020
}
}
trait SimpleTrait {
var num:Int = 2020
var str:String = "Hello World"
}
8.8、Trait的混入构造顺序
到目前为止,我们了解两种混入Trait的方式,一种是通过声明式混入,一种是通过创建对象时混入!
// 声明时混入
class MyClassA extends MyTraitD with MyTraitC {
println("MyClassA created")
}
// 对象创建时混入
val obj = new SimpleClass with MyTraitD with MyTraitC
现在new MyClassA,构造的顺序和下面的是一样的吗?!(代码参考8.5案例一)
创建时混入的构造顺序是:
先创建一个SimpleClass对象,然后混入Trait,依次MyTraitA->MyTraitB->MyTraitD->MyTraitC
而声明时混入的构造顺序是:
先混入Trait到MyClassA中,顺序也是MyTraitA->MyTraitB->MyTraitD->MyTraitC,最后混入完成后作为一个整体类创建出一个对象!!
关键就是在于前者是先创建对象然后进行混入,后者则是先混入形成整体然后创建对象!
8.9、使用Trait对类进行扩展
这里讲的扩展有别于前面的混入Trait,对类对象进行功能扩展,而是通过Trait继承已有的类,对原有类进行扩展!(是的!你没有听错!trait继承类!在Java中interface是不能extends类的哦!!!但是可以extends接口!)
object ExpandTest01 {
def main(args: Array[String]): Unit = {
val logger = new MyLogger
logger.showErrorMessage()
logger.debug("这是一条调试信息")
logger.warning("这是一条警告消息")
}
}
class Logger {
def debug(info:String): Unit = {
println("DEBUG:" + info)
}
def warning(info:String): Unit = {
println("WARNING:" + info)
}
def error(info:String): Unit = {
println("ERROR:" + info)
}
}
trait ErrorLogger extends Logger {
def showErrorMessage(): Unit = {
error("一条错误消息!!")
}
}
class MyLogger extends ErrorLogger {
}
原有类Logger,我们使用特质ErrorLogger extends Logger,为原有类扩展了新方法showErrorMessage并调用原有类中的error方法(但是这个方法并没有扩展加入到原有类中!!)要通过一个类(案例中的MyLogger)混入此特质,此时这个类同时继承了原有类Logger中的所有内容,并且同时拥有对原有类的扩展内容!
此时MyLogger则是Logger的一个子类!(所有混入了trait的类,都将成为trait的超类的子类!)
所以若MyLogger还有其他类要继承,必须保证那个类是Logger的子类,否则就会导致多继承的错误!!
例如:
class Logger {
// ...
}
trait ErrorLogger extends Logger {
// ...
}
class UnknownClass { // 非Logger子类
}
class SubLogger extends Logger { // Logger子类
}
// 同时继承UnknownClass和Logger! 多继承!错误!!
class MyLogger extends UnknownClass with ErrorLogger {
}
// MyLogger -> SubLogger -> Logger 合理,正确!!
class MyLogger extends SubLogger with ErrorLogger {
}
8.10、内部类
在此之前,先来回顾一下Java的内部类吧
public class InnerClassTest {
public static void main(String[] args) {
OuterClass outer = new OuterClass();
outer.showNumber(); // 20
outer.number = 30;
OuterClass.InnerClass inner = outer.new InnerClass();
inner.showNumber(); // 31
OuterClass.StaticInnerClass staticInnerClass = new OuterClass.StaticInnerClass();
staticInnerClass.showStaticNumber(); // 2020
}
}
class OuterClass {
public int number = 20;
public void showNumber() {
System.out.println(this.number);
}
class InnerClass {
private int number = OuterClass.this.number + 1;
public void showNumber(){
System.out.println(this.number);
}
}
static class StaticInnerClass{
public int staticNumber = 2020;
public void showStaticNumber(){
System.out.println(staticNumber);
}
}
}
下面再来看看Scala中是怎么写内部类的吧!
object InnerClassDemo01 {
def main(args: Array[String]): Unit = {
val outer = new OuterClass
outer.showNumber // 20
outer.number = 30
val inner = new outer.InnerClass
inner.showInnerNumber // 31
val staticInnerClass = new StaticInnerClass
staticInnerClass.showStaticInnerNumber // 2020
}
}
class OuterClass {
var number:Int = 20
def showNumber: Unit = {
println(number)
}
class InnerClass {
var innerNumber:Int = OuterClass.this.number + 1
def showInnerNumber: Unit = {
println(innerNumber)
}
}
}
object OuterClass {
class StaticInnerClass {
var staticInnerNumber:Int = 2020
def showStaticInnerNumber: Unit = {
println(staticInnerNumber)
}
}
}
Scala中,没有static关键字,故静态内部类就写在了伴生对象中!
不知道你们有没有注意到一个细节:
无论是Scala还是Java,内部类调用外部类的成员属性或者方法的时候都要用到OuterClass.this.xx来调用。而OuterClass.this则代表是一个外部类的实例!(因为想要创建内部类,是一定需要一个外部类实例的!)
在Scala中,我们就可以给这个外部类的实例“取别名”!
class OuterClass {
Outer =>
var number:Int = 20
def showNumber: Unit = {
println(number)
}
class InnerClass {
var innerNumber:Int = Outer.number + 1
def showInnerNumber: Unit = {
println(innerNumber)
}
}
}
格式如代码:Alias => 后面跟上外部类的内容,内部类的内容写在class中就行
内部类中想要引用外部类的东西的时候,可以直接使用Alias代替OuterClass.this作为外部类的实例名!
8.11、类型投影
在Java中,创建的外部类和内部类之间没有任何绑定关系(所有的内部类都一视同仁!)
public void fixInnerNumber(InnerClass inner) {
inner.number += 2000;
}
当在外部类中定义了这样一个方法,需要一个内部类作为参数,那么无论是哪个外部类来调用这个函数,任何一个内部类 都可以作为此方法的参数!!
可是在Scala中不一样!!
def fixInnerNumber(inner: InnerClass): Unit ={
inner.innerNumber += 2000
}
同样的方法定义,在Scala中,严格要求这个内部类参数实例必须是由调用此方法的外部类实例创建的!!**也就是是说Scala中外部类实例和其创建的内部类实例是一一绑定的!**如果外部类调用其方法需要内部类作为参数,那这个内部类实例只能是它亲自创建的!!
那么如何解决这个问题,达到和Java一样的效果(内部类之间以及外部类之间都不分你我)?
类型投影就是救星!所谓投影:就是大家说到底都是一样的,不用加以区别!
使用方法:
def fixInnerNumber(inner: OuterClass#InnerClass): Unit ={
inner.innerNumber += 2000
}
外部类#内部类这样所有的此类型内部类实例都可以作为此方法的参数!就屏蔽掉了外部类实例对方法参数的影响!!
Chap09.隐式操作
9.1、隐式转换
学习之前,我们先来看一下一句代码:
var number:Int = 3.5
这种写法,理所当然是会报错的!(你可能会想到用toInt方法) 但是在Scala中还有更高级的骚操作,结合隐式函数利用隐式转换就可以让其成为可能!(数据隐式地,自动地转化为对应的类型)
隐式函数
使用
implicit关键字定义,在指定类型的数据转换时,会自动应用!
来看看是怎么完成的吧!
object ImplicitConvertTest {
def main(args: Array[String]): Unit = {
// 隐式函数 在遇到要数据Double转换为Int的时候,自动应用!
implicit def intToDouble (value:Double) :Int = {
((value * 10 + 5) / 10 ).toInt // 四舍五入
}
// 自动调用隐式函数~
var number:Int = 3.7
println(number) // 4
// 使用常规的toInt~
var number2:Int = 3.7.toInt
println(number2) // 3
}
}
反编译的代码中,我们使用implicit定义的隐式函数,定义为static final方法,而且我们认为不可思议的隐式函数自动应用,在反编译的Java代码中就是一次方法调用而已!但是区别于普通的输出代码,这次用到了Scala中的BoxesRunTime这个类,这个类必定和我们定义隐式函数有关系!!
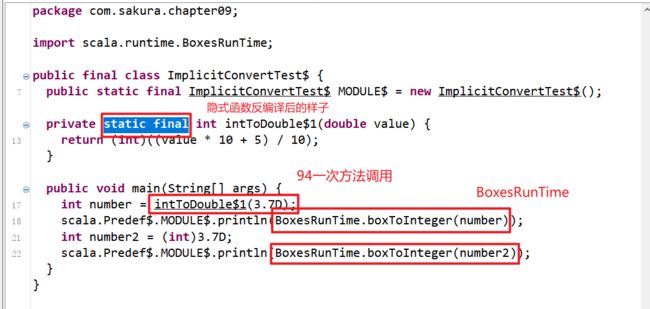
关于隐式函数使用和定义,这里还有几点要注意一下
隐式函数是与普通函数一样,拥有其作用域,超出作用域的类型转换是自动应用的!
在同一个作用域内,隐式函数是不可以进行重载的,并且“同类型”的隐式函数只能有一个!
这里所说的同类型是指,参数类型和返回值类型完全相同!如果同时定义了多个类型转换的隐式函数,那么在自动应用的时候,它就不知道到底用哪个了!
9.2、隐式函数用于丰富类库
直接上代码案例吧:
object ImplicitClass {
def main(args: Array[String]): Unit = {
implicit def trainDog(dog: Dog): Cat = {
new Cat
}
val rocket = new Dog
rocket.catchMouse()
rocket.eat()
}
}
class Dog {
def guard(): Unit = {
println("汪汪汪汪!!!")
}
def eat(): Unit = {
println("骨头~~骨头~~")
}
}
class Cat {
def catchMouse(): Unit = {
println("战利品:老鼠+1")
}
def eat(): Unit = {
printf("鱼~~鱼~~")
}
}
rocket明明是一只狗啊!!为什么他可以抓老鼠?!因为他经过了秘密训练~~
这里就是我们要学习的使用隐式函数来丰富类库!Dog和Cat类之间明明没有任何关联,但是通过一个隐式函数,来将一方中的方法加入到另一方中。完成类库的丰富作用。
首先我们要定义一个隐式函数,我们期望通过这个隐式函数来将丰富Dog的类库,使Dog能够使用Cat的内容!当我们new了一个Dog对象的时候,并试图去调用Cat类中的方法时,编译器会先检查有没有合适的隐式函数,可以将Dog“转换”为一个Cat,果不其然implicit def trainDog(dog: Dog): Cat就正合我意!于是就会使用这个隐式函数,并将Dog对象传入,得到一个Cat对象,这样就能理所当然调用Cat中的方法了!而这种“转换”只是临时的!对象本身还是一个Dog类!(就好像超能力,你需要的时候我就变身使用超能力,其他时候我都是一个普通人~~)
那我们来看看反编译得到的Java代码:
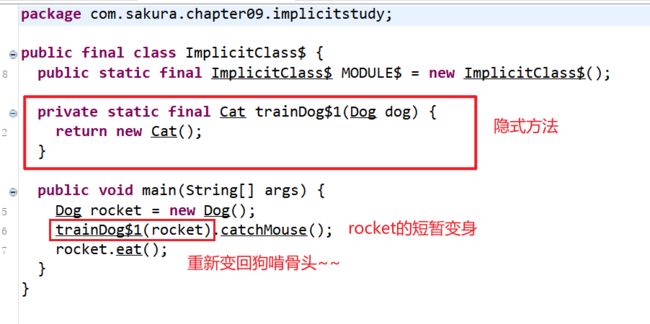
9.3、隐式值配合函数隐式形参
当你定义的函数使用了隐式参数,而刚刚好你又定义了一个隐式值且类型匹配,那么他们就会像磁铁一样,彼此“吸引”!直接看案例吧:
object ImplicitParam {
def main(args: Array[String]): Unit = {
implicit var str:String = "Hello World"
showMsg // info: Hello World
}
def showMsg(implicit msg:String): Unit = {
println("info: " + msg)
}
}
看到了吧,是不是很神奇!showMsg使用了隐式参数,而刚好我们定义了一个隐式值str。并且类型也能准确对上!所以我们就可以直接调用showMsg并且不用传参数,编译器会自动将隐式值str作为函数的实参!也就得到了最终的结果。。
同样,我们看一下反编译的Java代码吧:
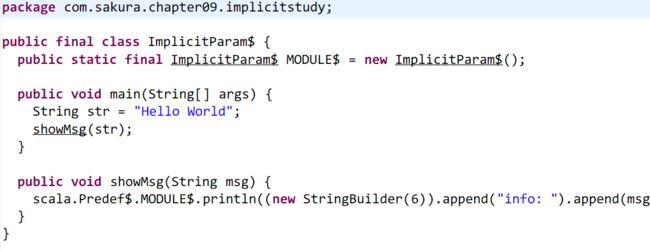
额。。。未免过于简单。。。
同样这种用法也有很多注意点!
- 最重要的就是不能有二义性!,当同一个范围内存在两个同类型的隐式值,函数调用时在参数自动应用的时候就会存在二义性!此时运行就会报错ambiguous implicit value
- 隐式值是不能使用前面的隐式转换的!!违反了隐式操作不能嵌套这一条例!
- 隐式值和函数参数默认值是存在优先级问题的!!
- 当使用隐式值作为带隐式形参函数的实参的时候,调用函数不要加
(),也不要传参!!- 一旦函数在参数列表中使用了
implicit,即表示所有参数都是隐式形参,可以自动应用合适的隐式值!- 当隐式值和隐式参数类型不匹配的时候,函数调用只能手动传参!
来测试一下,参数默认值和隐式值在函数调用时候的优先级!
object ImplicitParam {
def main(args: Array[String]): Unit = {
implicit var str:String = "Hello World"
showMsg // info: Hello World
}
def showMsg(implicit msg:String="Help!!"): Unit = {
println("info: " + msg)
}
}
在隐式值匹配参数类型时,参数优先级:隐式值>参数默认值
9.4、隐式类
描述起来有些困难,直接上案例吧!
object ImplicitClass {
def main(args: Array[String]): Unit = {
val laozhang = new Person("老张")
laozhang.start()
laozhang.drive()
laozhang.park()
laozhang.work()
/**
* 老张启动了ta的车~~
* 老张正在开车~~
* 老张停好了ta的车~~
* 老张开始上班了~~
*/
}
implicit class Car(p:Person){
private val owner:Person = p
def start(): Unit = {
println(owner.name + "启动了ta的车~~")
}
def drive(): Unit = {
println(owner.name + "正在开车~~")
}
def park(): Unit = {
println(owner.name + "停好了ta的车~~")
}
}
}
class Person(inName:String) {
val name:String = inName
def work(): Unit = {
println(name + "开始上班了~~")
}
}
你可能会疑问,我明明只创建了一个Person——laozhang,并且他是一个Person啊?!为什么能用Car的方法?!而且这个Car是哪来的?!(不好意思,老张生下来就含着车钥匙~~)
这就是隐式类,它会随着某个类的创建而随之生效!并且可以通过创建的类使用隐式类中的方法!在这个过程中,我们并察觉不到Cat类对象的创建!我们直接看反编译的代码吧!!
与之前不同,这次我们多了一个文件:ImplicitClass$Car.class:
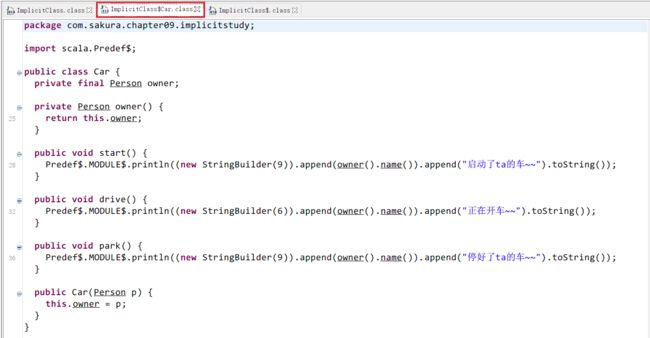
再来看看主要的代码反编译情况:
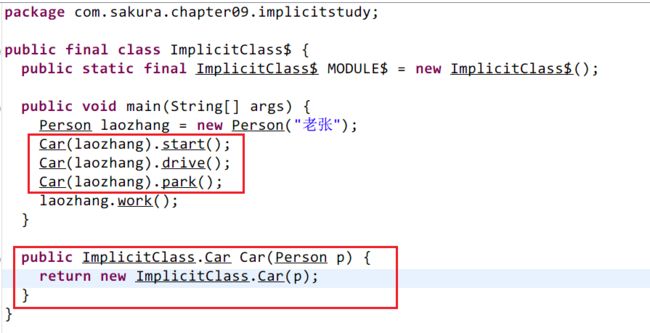
很容易看出来,很像我们使用隐式函数拓展类库的做法。一个方法,参数是某个类型的实例对象,返回值却是另一个类型的实例,区别于之前的做法,这里使用了参数的对象作为目标对象的构造参数。
关于隐式类定义的注意:
- 不能是顶级类!只能定义在伴生对象或者伴生类以及包对象中~
- 隐式类的构造参数有且只有一个,即那个触发隐式类创建的类实例对象
- 隐式类也是类,作用域内不能存在重名的情况!
9.5、隐式转换的触发时机和基本注意
一下几种情况下,会触发隐式转换:
- 当实际类型不匹配目标类型的时候,编译器会执行隐式转换~
- 当实例调用本类中不存在的方法或者成员时,会执行隐式转换~
这都是建立在存在类型匹配的隐式转换方式的前提下的!若没有类型匹配的转换方式,会直接报错
所有的隐式操作有两个基本的注意点:
-
不要嵌套使用隐式操作;例如:
implicit def doubleToInt(value:Double): Int = { val num:Int = 5.6 // 又涉及到隐式类型转换,要应用doubleToInt,没完没了~ value.toInt } -
不能存在二义性
隐式转换本身就是自动应用,如果存在二义性编译器是无法为我们做出选择的!
Scala数据结构
Chap10.集合
10.1、Scala集合基本介绍
在Scala中,有一个包scala.collection。这个包下涵盖了Scala中所有的集合类~
Scala中的集合首先分为两大类:可变(mutable)和不可变(immutable)
**注意!**这里的可变与不可变,指的是集合对象本身(不)可变(例如容量)。并不是指集合中的数据(不)可变~
不可变的集合天生适应并发情况~~
在没有指明的情况下,默认是使用不可变的集合的!
在(不)可变的集合中,又将集合分为三大类:Seq(Sequence),Set,Map
10.2、Scala集合类层次结构介绍(对比Java)
我们先来回顾一下Java的集合结构
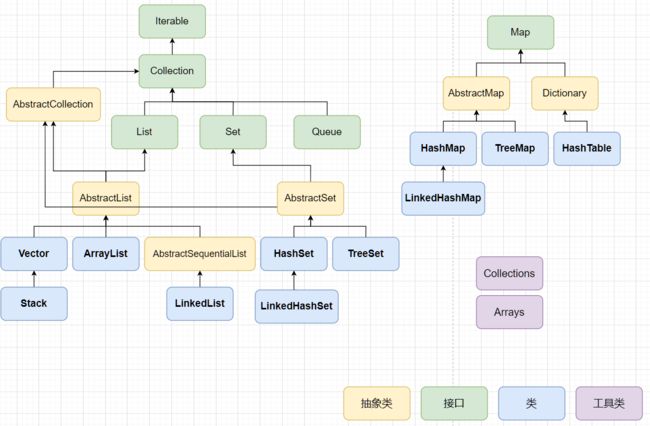
这里我们只列举了,我们常用常见的一些类,实际上远比这要复杂的多!
可以看出在Java中,Map貌似和List、Set“分家”了~~ 实则它们都是集合类中的一员,这种关系在Scala的集合类关系层级中,更好地表现了出来:
来看看Scala的集合类层级结构:
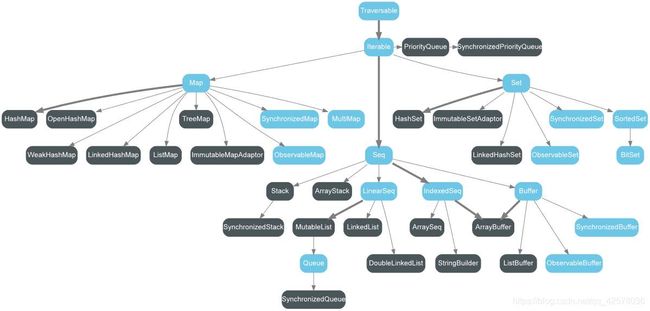
实在是难画, 我们就勉强看看这张图片吧~
其实这张图是把可变和不可变的集合放在了一起,在Scala中是由scala.collection.mutable和
scala.collection.immutable两个包分管理可变和不可变集合的!!
Seq部分
有三个主要的特质:LinearSeq、IndexedSeq、Buffer
LinearSeq:(这个是immutable包中特有的!!!)线性序列,最突出的类就链表,见名知意这个特质下的序列是不能通过下标来索引位置的~
IndexSeq:索引序列,最突出的就是数组,与前者相反,使用下标对序列数据进行索引
Buffer:(这个是mutable包中特有的!!!)缓冲?!这个设计是专门用于大数据场景的!有时候我们计算的数据需要及时返回的话,不能总是放入数据库,而这个Buffer的存在就可以用作计算结果的容器~~常用的有ArrayBuffer、ListBuffer
除了以上主要的三个内容以外,可以看到Stack、Queue也是属于这一部分的!
Set部分
常用的HashSet、TreeSet、BitSet,后两者同时继承SortedSet这一特质。除此以外还有很多适用于并发使用的Set。
LinkedHashSet和HashSet是mutable包中特有的~
Map部分
常用的HashMap、TreeMap(后者继承了SortedMap特质)。一样也有适用于并发操作的Map
以上三个部分中,以Sync开头的集合类都是适用于并发使用的集合!!都是线程安全的!
10.3、定长数组与可变数组
在Java中我们最常使用的集合,莫过于数组和List了,在Scala中也不会例外!只是他们换了名字:
- 定长数组
Array(相当于Java中的数组) - 可变长数组
ArrayBuffer(相当于Java中的List)
我们来看看他们的基本使用吧!
定长数组 Array
-
创建(两种方式)
new Array[]():方括号中填数据类型,填Any表示什么都能放~ 圆括号中填数组长度(容量)Array(xx1,xx2,xx3):使用Array的apply方法~
// 方式一 new Array[]() 默认使用类型默认值填充 val intArray = new Array[Int](4) // 方式二 Array() 利用Array的apply方法 val array = Array(3, 5, 9.2, "hello world") -
遍历(两种方式)
数组中使用
array(index)来访问数组元素内容for (index <- array.indices) {}下标索引for (elem <- array)元素遍历array.forEach(println)类似于Java中lambda表达式~
// 方式一: 元素索引 for ( elem <- xxx) for (elem <- array) { } // 方式二: 下标索引 for ( index <- 0 until array.length) { } for ( index <- 0 to array.length-1) { } // 等价于 for ( index <- array.indices ){ } // 方式三 高级用法以后再说... array.foreach(println) -
修改
在设计的时候就规定了Scala数组*(Array)是固定容量的,所以不存在增删操作~*
-
更新值(两种方式)
- 直接重新赋值:
array(1)="hello world" - 使用方法更新值:
array.update(1, "hello world")
array(1) = "sakura" array.update(2, false)注意!!更新值是会连同元素数据类型都会改变的!
- 直接重新赋值:
-
追加内容(并生成新的数组)
这里并不是对数据进行扩容追加,而是对现有数组追加数据并生成一个新的数组!原数组不发生变化!
appended(),如果方法接收的参数有多个,那么会将其自动封装为一个数组并将其作为一个元素加入新数组中~
-
可变长数组 ArrayBuffer
其用法和Array十分相似,但是唯一的不同是 ArrayBuffer是支持动态扩容的~
-
创建
new ArrayBuffer[]:同样方括号中填数据类型,你也可以补上圆括号设置初始化的Size,但是没有意义ArrayBuffer(xx1, xx2, xx3, ...):使用ArrayBuffer的apply方法创建、
val arrayBuffer = new ArrayBuffer[Any]() val arrayBuffer2 = ArrayBuffer(1, 3, "hello", 9.99) -
增加
addOne()/addAll():后者需要的是一个容器的迭代器append()/appendAll():前者可以接收多个参数,同时增加多个值,但是已经弃用,推荐使用后者来插入多个元素,同样也是需要一个迭代器insert()/insertAll():插入数据,需要指定插入的下标位置,并且是前插
arrayBuffer.addOne("hello") arrayBuffer.addAll((1,2,"world").productIterator) arrayBuffer.append("====") arrayBuffer.append(3,4,true,3.14) // 已经弃用,推荐使用下面这种方式 arrayBuffer.appendAll((3,4,true,3.14).productIterator) // 参数是一个迭代器 arrayBuffer.insert(2,"777") // 前插这里新增数据,底层实现上是创建一个更大的ArrayBuffer,copy原始数据进去,然后追加新元素。所以每次增加数据后,对象的hashcode都会变化~~
-
删除
remove(index):移除指定下标的元素remove(index, count):移除从指定下标起,往后count个元素(包括起始下标)arrayBuffer.remove(0) arrayBuffer.remove(0,2) -
修改(更新)数据
arrayBuffer(1) = true: 下标索引元素修改arrayBuffer.update(index, data):使用update方法,对下标指向的元素进行修改arrayBuffer.update(1,3) // 修改原始数据,没有返回值 arrayBuffer(1) = true -
遍历
参考上面Array的遍历方式,所有的遍历方式均适用~
相比较起来,两者的差距仅在于前者无法进行动态扩容,而后者可以!但是两者是可以进行相互转换的!!
Array 与 ArrayBuffer(Buffer) 相互转换
Array => ArrayBuffer : toBuffer()
ArrayBuffer => Array : toArray()
这两个方法的调用,并没有改变对象本身,其返回值才是我们需要的东西!
扩展:多维数组
学过C语言,你一定不陌生二维数组,这里的多维数组就与其类似!
-
创建
Array.ofDim[](int,int,...):后面圆括号的参数,有几个就是n维数组,它最多5个?!(五维?!)我们暂时只涉及二维数组val array = Array.ofDim[Any](3, 4)
其他使用,结合Array的用法、C中一维数组和二维数组的关系即可。
10.4、ArrayBuffer与Java中ArrayList相互转换
在实际的开发中,我们需要将Scala中的数组转换为Java中的List对象,这就涉及到这里的ArrayBuffer和ArrayList的相互转换!!Scala中已经为我们准备了相应的隐式转换函数!!
ArrayBuffer 转 ArrayList
旧版本中做法是:
import scala.collection.JavaConverters.bufferAsJavaListConverter // 新版本中已经弃用
def main(args: Array[String]): Unit = {
implicit val buffer = ArrayBuffer(1, "hello world", 3.14, true)
// ArrayBuffer to ArrayList
needArrayList(buffer.asJava)
}
def needArrayList(list: util.List[Any]): Unit = {
list.forEach(println)
}
}
而新版本中,已经说明了这个类已经弃用了。所以目前需要import的是
scala.jdk.CollectionConverters.BufferHasAsJava,这个类是一个隐式类,构造参数正是一个Buffer,回顾一下之前的隐式操作,此时new Buffer的对象,就可以直接使用这个隐式类中的asJava方法,然后得到一个util.List实例!!
ArrayList 转 ArrayBuffer
同样旧版本中做法是:
object Buffer2ListDemo {
def main(args: Array[String]): Unit = {
val list = new util.ArrayList[Any]
list.add(1)
list.add(9.99)
list.add("hi")
list.add(false)
import scala.collection.JavaConverters.asScalaBufferConverter // JavaConverters包已经弃用
needBuffer(list.asScala)
}
def needBuffer(buffer: mutable.Buffer[Any]): Unit = {
buffer.foreach(println)
}
}
新版本中,导入的类是:scala.jdk.CollectionConverters.ListHasAsScala,与上面ArrayBuffer转ArrayList利用的方式的一样——隐式类,调用asScala方法获得一个mutable.Buffer对象引用。
10.5、元组Tuple
学过Python,你一定对元组不陌生!**元组,相当于一个数据容器,可以放置任意类型的数据,便于我们将类型无关但是业务相关的数据封装在一起!**优点是灵活,对数据约束少!
但是这个容器是有容量限制的:最多放置22个元素,但是你的元素也可以是元组,也就是说可以无限套娃~~
当你正准备new一个Tuple的时候,你会发现从Tuple1~Tuple22,一共22中类型!我该选哪个呢?
**Tuple对象没有固定类型,对象类型取决于元组中数据的个数!!**并且实际上创建元组对象也不能使用apply()方法!这样会限制你元组数据数量,实际上创建元组的过程十分简单!!
object TupleDemo01 {
def main(args: Array[String]): Unit = {
val myTuple = (1, 4.7f, "hello", false, "world")
println(myTuple.getClass) // class scala.Tuple5
}
}
由于元组中元素是val定义的,所以元组是不支持修元素数据的!!也不能对元组进行添加、删除元素!
但是元组中访问元素却是十分方便:
// 方式一: tuple._n 访问第n个元素,从1开始
println(myTuple._1)
println(myTuple._4)
// 方式二:tuple.productElement(index) 访问下标为index的元素
println(myTuple.productElement(0))
println(myTuple.productElement(3))
元组遍历:for + 迭代器
// 迭代器遍历
myTuple.productIterator.foreach(println)
// 等价于:
for (elem <- myTuple.productIterator) {
println(elem)
}
10.6、Scala列表(List)
在Java中也有一个List(java.util.List),是一个接口,我们常用的实现类是ArrayList!
然而在Scala中,List是实类,属于immutable.Seq(不可变!它有一个兄弟是可变的=>ListBuffer)
先来看看基本的使用吧!
-
创建
同样是使用apply方法,没有容量限制
val list1 = List(1, 4, "hello", false) -
遍历
List访问元素也是使用
list(index)的形式。所以可以采用下标遍历,或者直接元素遍历for (elem <- list1) { println(elem) } for (index <- list1.indices) { println(list1(index)) } -
移除、增加
由于List是不可变的集合,那么集合的容量是不能改变的,所以不支持对元素的增删。但是可以最原有的List进行元素追加生成一个新的List。这就涉及到几个符号的使用了!!
在此之前,我们先认识一个集合中的特例:空集Nil,创建:val list2 = Nil,这样我们就得到了一个空集。
List 相关符号使用
-
+:或者:+将一个元素,追加到原有集合中。有几个注意点,可能稍有不慎就会导致预想结果和实际偏差很大!例如:
println("world" +: list1) // List(world, 1, 4, hello, false) println("world" :+ list1) // Vector(w, o, r, l, d, List(1, 4, hello, false)) println(list1 :+ "world") // List(1, 4, hello, false, world):侧是集合时,会将集合中的数据拆散,与+侧的数据进行组合成为新的集合!(这里要注意,字符串实际上也算作是集合,每一个字符算一个元素,可以参考示例代码第二行)+是一个集合时,那么这个集合会被当做一个完整元素,与其他元素组成新的集合。(参考第二行)- List是无序的,所以追加过程中,元素顺序决定了新集合中元素的顺序!(对比第一、三行)
那么就有人想问了,如果我想把两个集合中的元素全部拆出来,放在一个新集合中要怎么做呢?!
当然,使用
+:符号是无法完成,那么就要利用更加复杂的计算符号了::: -
::在接触
:::前,我们先学习::的使用吧,来看看使用过程:val list1 = List(1, 4, "hello", false) val list3 = List("A", "B", "C", 9.99) println( "Hello" :: 4 :: list1 :: list3 :: Nil ) // List(Hello, 4, List(1, 4, hello, false), List(A, B, C, 9.99))可以发现在这里并没有之前那么多约束,所有参与计算的元素统统都算作整体,没有高低贵贱之分。
这个符号也有使用的注意事项:
-
在使用
::进行多级运算时,集合对象(不包括字符串)一定放在靠右侧!!例如:
4 :: list1 :: list3 :: "Hello"是不合乎使用规范的!!
-
-
:::这个符号是专门针对集合元素混合的,方便将集合中的数据拆出来进行混合
例如上面这个例子,如果在list1和list3中间使用
:::是什么结果呢?!// List(Hello, 4, 1, 4, hello, false, List(A, B, C, 9.99))是不是有点疑惑,为什么list3没有被拆分呢?!
现在为了让你更清楚,简单,快速记下符号的使用,我们来重新整理一下:
你现在去尝试一下,将上面示例代码中
println( "Hello" :: 4 :: ...)中的::改成:::,编译器会提示你,Hello是一个字符串(:::只能对集合对象使用!!)
那么说明这个符号的作用对象处于符号的左侧!!即我们的计算根基应该是最右侧!!所以可以推出,这两个符号的计算顺序是从右向左。那么就很好解释了
"Hello" :: 4 :: list1 ::: list3 :: Nil中为什么list3没有被拆分了,首先我们来梳理下计算顺序:- 一个空集合Nil,
list3 ::,将list3作为一个完整的元素加入了空集合中,得到一个临时集合tempList list1 :::,将list1中元素拆分出来,并结合tempList中已有元素,生成新的临时集合tempList24 ::和"Hello" ::,都是作为单个元素加入集合的。
是不是感觉好懂了很多,那么如果我们要将list3也拆分的话要怎么写?
val list4 = "Hello" :: 4 :: list1 ::: list3 ::: Nil // List(Hello, 4, 1, 4, hello, false, A, B, C, 9.99)Bingo!!!
- 一个空集合Nil,
10.7、可变列表ListBuffer
上面我们学习的List是不可变的!现在我们来看一下可变的List=>ListBuffer
-
创建
依旧是使用apply方法val listBuffer1 = ListBuffer[Any]("Hello", 1, 3.14, true) -
遍历
依旧是两种选择,就不多说了
-
增加元素
这可是重头戏!有两种方式可选:
append()方法。方法支持可变参数,但是目前这种用法已经弃用,推荐使用appendAll()来代替。+=符号操作: 将元素加入到集合中,但是在面对集合的时候,使用这种方法,会将集合作为一个整体元素加入。- 于是针对集合有了升级版:
++=,可以将集合中的元素提取出来加入集合中!
- 于是针对集合有了升级版:
除了以上的几种方式外,List中所使用的元素追加符号也一样适用,但是本质还是一样:不改变集合本身,返回值才是目标结果~
-
移除元素
使用
remove()方法,和ArrayBuffer中remove使用方式一样,不多介绍。
10.8、队列Queue
记得在学习数据结构的时候,强调了队列的特点:先进先出,那么就涉及到队列的两个基本操作入队和出队。
在Scala中队列有可变的也有不可变的。但是常用的还是可变队列!!
来学习一下基本的使用吧:
-
创建(由于Scala的集合创建,默认是使用不可变的,所以这里要写明为可变包下的!)
val queue = new mutable.Queue[Any]可以加上
()填写参数控制队列初始化长度。(丝毫不影响后续的入队的元素数量) -
加入元素
++=和+=,在面对集合的时候,什么情况用哪个不用我说了吧,懂得都懂。。 -
入队、出队(重点)
分别使用方法:
enqueue()和dequeue()object QueueDemo01 { def main(args: Array[String]): Unit = { val queue = new mutable.Queue[Any] queue.enqueue(1).enqueue(2).enqueue(6).dequeue() println(queue) // Queue(2, 6) } }都是支持链式调用的哦!!(并且入队,可以一次性入多个值哦!)
-
取头、尾结点值
使用方法
head,last分别取头结点值、尾结点值queue.enqueue("A","B","C","D","E") println(queue.head) // A println(queue.last) // E -
特殊取值(取尾部)
在队列中,我们将由除了头结点以外的剩余结点组成的队列称为尾部,使用
tail()方法就可以取到当前队列的尾部!以上面ABCDE的队列作为初始队列:queue.tail // Queue(B,C,D,E) queue.tail.tail // Queue(C,D,E)tail是可以链式调用的!
10.9、Scala集合之Map
终于到Map啦,Scala中Map也分为可变Map和不可变Map。来说说他们之间的不同吧
mutable.Map与immutable.map之间的区别
-
默认使用
immutable.Map,使用可变的Map需要额外导入包 -
不可变的Map是有序的,可变的Map是无序的!!
**注意!!这里说的有序、无序并不是指 会对key进行排序,而是输出的顺序和声明的顺序是否一致!**不可变的Map输出顺序与声明顺序相同。可变的Map输出的顺序和声明顺序没有关系。
-
不可变Map不能对KV对进行增删操作
Map使用的要点
- 对KV的类型没有严格的要求,允许同一个Map下有多个类型的Key和Value。也支持在创建时指定KV的值类型!
- 每一个KV对在底层都被封装成为一个Tuple2类型的对象!
-
创建
-
apply方式创建,(创建可变Map需要额外导包,并指定为可变Map)
val map1 = Map[String,Int]("H" -> 1, "B" -> 2, "D" -> 3) // 使用[K,V]约束KV值类型 val map2 = mutable.Map("H" -> 1, "B" -> 2, "D" -> 3, "A" -> 0) -
二元组方式创建(由于KV在底层是被封装为二元组的,那么可以直接使用二元组创建)
val map3 = Map[String,Int](("H", 1), ("B", 2), ("D", 3)) // key -> value 替换为 (key, value)的形式
-
-
取值
Map取值就涉及到要取的key不存在的情况,在Java中直接返回null,在Scala中会直接抛出异常:
NoSuchElementException-
mapName(key)取值,会抛出key不存在的异常 -
mapName.get(key).get。当key不存在的时候,get(key)返回None,那么后面那个get执行就会抛异常:
NoSuchElementException:None.get
当key存在的时候,get(key)返回Some,然后后面get就能正常取出值来。
所以在使用的时候,先对mapName.get(key)的结果做一次判断!
-
mapName.getOrElse(key, default_value)这种方式容错性更高。若key存在,直接返回其对应的value;
若key不存在,则返回预先设置好的默认值:default_value;
为了避免key不存在导致的业务错误,建议在取值之前使用
contains(key)方法检查一下Map中是否有这个key; -
-
更新值(仅可变Map可用)
mapName(key) = newValue若没有找到对应的Key,则创建一个KV,并加入Map中!
-
添加KV
mapName += ((k1,v1), (k2, v2), k3 -> v3, ...)直接使用
+=符号,参数可以是一个或多个KV,KV的形式也没有固定。(但是!但是!这种一次性添加多个元素的方式被弃用了!!只适合用于添加单个KV)官方更推荐使用
++=或者addAll()来添加多个元素,参数都是map对象。例如:map1 ++= map3当添加的Key已存在,会直接更新原值!
-
删除KV
-=操作符!!使用:
mapName -= (k1, k2, k3, ...)和上面一样,这种方式只适合用于单个KV的删除,多个KV的删除官方更推荐使用
--=和subtractAll(),参数是key类型的集合。例如:mapName --= Array("A", "B", "C")key存在时,执行删除操作,不存在则操作无效,不会报错!
-
遍历
关于Map的遍历,方式有很多,而且可遍历的内容也很多!
-
for ((key,value) <- mapName)for ( (k,v) <- map2 ) { println(s"$k -> $v") } /** * H -> 1 * B -> 2 * Z -> 22 * D -> 3 */ -
for (k -> mapName)遍历key,那么想取出value不是轻而易举?! -
for (v -> mapName)只遍历value -
for (kv -> mapName)以二元组的方式遍历,遍历的单位是一个个KV对,说白了就是Tuple2对象for ( kv <- map2 ) { println(s"${kv._1} -> ${kv._2}") } // 效果同上
-
10.10、Scala集合之Set
在学习Java的时候,我们就知道Set是Map的“阉割版”,所以它最主要的特点就是元素不重复!同样也有可变和不可变。
创建就不多说了和Map类似,只不过不需要指定key而已!
增加和删除:有了add()和remove()方法,但是Map中使用的符号操作依旧可以使用!!
遍历:略。
会用Map,那Set其实不用说太多。。。
介绍完集合的基本操作,接下来就是集合的高级部分了——集合操作应用。
Chap11.集合操作
11.1、map映射操作
我们这里所说的集合操作,并非前面所学的集合元素增删改查。而是应用到实际开发中的集合高阶使用!例如:映射、扁平化、过滤、化简、折叠、扫描等…
话题引入
在实际开发的业务中,我们常需要对集合中的每个元素都要进行复杂的计算等操作,而且需要对集合中的元素进行过滤。而这种要求,我们使用Java也是可以轻易完成的!(遍历,然后挨个对集合元素进行业务操作…),但是当遇到非常复杂的业务的时候,就会导致代码臃肿,不够优雅。那么Scala的函数式编程就可以粗暴而不失优雅完成!
这就离不开Scala中的map映射操作了,这里的map并不是集合的Map哦!可以回想一下Java中Stream编程中的map(),可以将集合中的每一个元素通过某种函数映射成一个新值,这也就是函数式编程的特点!
入门基本操作
入门案例:将List中的每个元素都翻倍。
用Java的常规方法就是先遍历,然后每个元素都乘以2。
使用常规方法的好处是:代码易于理解。缺点是:代码不够简洁,在处理复杂计算的时候尤其明显!
下面来看看Scala中使用map映射是怎么完成的吧!
所有的集合都可以使用map()方法,但是这个参数是不是看的一愣一愣的。。。

来说明一下吧:
map[B](f: Int => B) List[B]
这里的B是泛型,不用多说吧,与返回值中集合中的元素类型相同。
map方法的参数f: Int => B,表示一个参数为Int类型、返回值为B(泛型,即处理后期望的元素类型)类型的函数。
其实这个Int是编译器通过类型推测推断出我们的list中都是Int类型的元素,所以这个f函数就是体现函数式编程的一重要标志:**函数接收一个函数作为参数。**而这个函数就用于将原集合中的元素映射成新值的函数。
用一张图来描述可能会更简单一些。可以看出使用map()函数就帮我们省去了遍历的过程,会自动调用函数f并将每个元素都作为函数f的参数。这个f函数就是我们针对每个元素要做的业务操作函数,所以需要我们自己来写,但是参数类型一定要严格按照map的函数参数规定!
案例代码:
object MapOpDemo01 {
def main(args: Array[String]): Unit = {
val list = List(8, 42, 27, 19, 34)
val list2 = list.map(multiplyBy2 _)
list2.map(println)
/**
* 16
* 84
* 54
* 38
* 68
*/
}
def multiplyBy2(item: Int):Int = {
item * 2
}
}
几个问题说明:
-
map()函数接收的是一个函数名!在Scala中,函数可以视为与变量相似,因为在Scala中可以直接将函数赋值给一个变量!!!因为函数在内存中还是以地址方式进行存取。
-
函数名后的
_,是大多开发者的习惯,意在告诉编译器只是进行赋值而不执行(在将函数赋值给变量时有效!)object MapOpDemo01 { def main(args: Array[String]): Unit = { val func = hello func // Hello World, func为赋值函数的返回值,类型为Unit val func2 = hello _ func2 // 无输出,func2此时代表一个函数 ()=>Unit func2() // Hello World 执行赋值的函数 } def hello (): Unit = { println("Hello World") } } -
list.map(println),在理解了map函数用法的基础上,这个应该很好懂,即将每个集合元素都作为println()的参数,并执行。是不是又学会一招遍历集合!!
以上就是map集合映射操作,这个操作将贯穿所有集合的操作!!
11.2、高阶函数入门
首先我们先要理清什么是高阶函数。
例如上面案例中我们学习使用map()对集合元素进行映射试,map函数接收一个函数作为参数。那么map就是一个高阶函数!
所以说简单来说:能接收一个函数的作为参数的函数就是高阶函数!
高阶函数定义与使用
高阶函数我们也可以自行定义,保证参数中有一个函数即可~ 函数参数如何声明呢?看示例:
object HighLevelFunc {
def main(args: Array[String]): Unit = {
val result = highLevelFunc(doubleOp _, 5.1, 4.7)
println(result) // 3.919999999999995
}
def highLevelFunc(func:(Double,Double) => Double, param:Double, param2:Double): Double = {
func(param,param2);
}
def doubleOp(num1:Double, num2:Double):Double = {
(num1 + num2) * (num1 - num2)
}
}
示例代码中:highLevelFunc即为高阶函数,他接收一个func: (Double, Double)=>Double函数(即2个Double类型的参数,返回值也为Double)。而这个函数“模板”刚好对得上下面的doubleOp函数!
高阶函数的函数体中则正好是调用参数中函数并将其他两个double参数传入。
使用时,由于doubleOp函数完全符合高阶函数中参数函数的模板,于是我们直接将其函数名传入即可!然后带上两个double值。
认识完高阶函数的定义和使用,我们正式进入集合操作的高阶部分吧!我们会认识很多高阶函数!
11.2.1、扁平化(flatmap)
常用于将集合中所有的子元素取出并进行相应操作将结果放入新集合中!!
object FlatMapDemo {
def main(args: Array[String]): Unit = {
val list = List("World", "Scala", "c++", "Java", "Python")
println(list) // List(W, O, R, L, D, S, C, A, L, A, C, +, +, J, A, V, A, P, Y, T, H, O, N)
val upperList = list.flatMap(toUpper)
println(upperList)
}
def toUpper(str: String) :String = {
str.toUpperCase
}
}
感觉有点像map()函数的升级版~ 其他细节的玩法,可以看一下其参数要求!
11.2.2、过滤(filter)
这个应该是我们在实际开发的最常碰到的业务!需要对不符合要求的数据进行过滤清洗…
filter()函数,需要一个f: B => Boolean类型的函数(B为集合中元素类型)。看案例:
object FilterDemo {
def main(args: Array[String]): Unit = {
val names = List("Lisa", "Laura", "Alice", "Jessica", "Daisy")
// 要求过滤出包含了字母l或者L的
val nameWithL = names.filter(containL)
println(nameWithL) // List(Lisa, Laura, Alice) Bingo!!
}
// 用于过滤的函数 String => Boolean
def containL(name: String):Boolean = {
name.contains('L') || name.contains('l')
}
}
这个应该挺好理解的吧,也不是第一次见到过滤器这个东西了~
11.2.3、化简(reduce)
看这个名字可能感觉有点难懂,而且你在调用的时候又会遇到没见过的符号了:

泛型的括号中这样写:B >: Int,其实>:符号是用于对泛型的限定!!这里的意思是说B的下界类型就是Int,不能比Int更低。。用于约定后面函数的模板! 他还有几个亲兄弟:
| 符号 | 作用 |
|---|---|
| [T <: UpperBound] | 上界 |
| [T >: LowerBound] | 下界 |
| [T <% ViewBound] | 视界 |
| [T : ContextBound] | 上下文界 |
| [+T] | 协变 |
| [-T] | 逆变 |
这下就明了了不少,reduce这个高阶函数需要的函数类型是:(B, B) => B。
到这里细心的人就会冒出一些疑问:前面的高阶函数接收的函数都是单参的,一般都是将每个集合元素作为参数,这里为啥有俩参数?还有一个是什么?我该怎么用?!
确实在不了解函数参数的情况下,我们是无法去定义和实现函数的!那么现在由我来为你解答这个问题吧:
假如这个函数名为f,第一次调用的时候会取集合的前两个元素作为f函数的参数,而从第二次开始,每次调用只会取集合的一个元素作为f的参数,另一个参数就是前一次f调用的返回值!
来张图演示一下吧:就以累加作为案例:
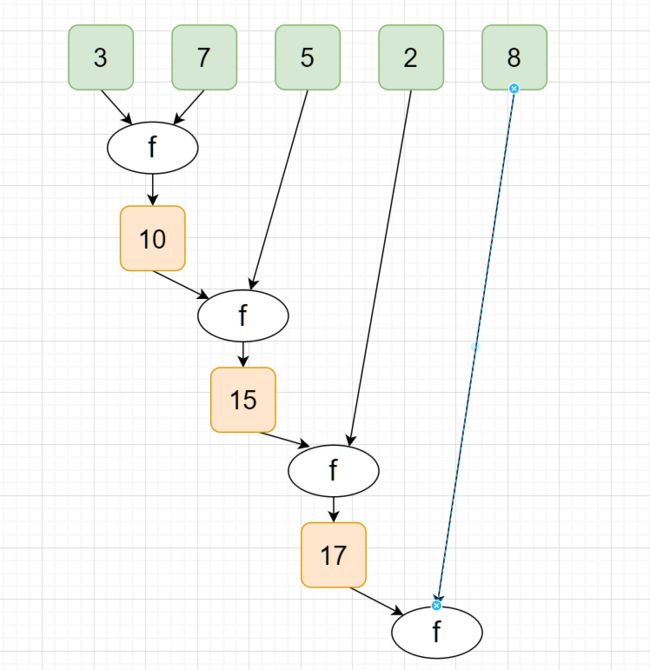
文字描述就是:((((3+7)+ 5)+2)+8…
即每次的结果都会参与下一次的函数计算。而且计算的顺序是从左向右!!
示例代码:
object ReduceDemo {
def main(args: Array[String]): Unit = {
val list = List(78, 92, 746, 1973, 879)
val result = list.reduce(add)
println("result = " + result) // result = 3768
}
def add(num1:Int, num2:Int):Int = {
num1 + num2
}
}
这么看来,化简的来意就是:将一个复杂的大型的操作,拆分成一个个小的简单的操作来完成!
我们继续,当我们点到reduce的源码部分的时候,发现了新大陆:
def reduce[B >: A](op: (B, B) => B): B = reduceLeft(op)
reduceLeft??原来默认是调用reduceLeft(),所以计算顺序是从左到右。那么肯定还有一个reduceRight
简单粗暴而高效的实现。。先将集合逆序,调用reduceLeft然后传了一个匿名函数,将原来的op(x,y)替换为了op(y,x)。
现在我们用累减的示例来猜测一下他reduceRight的执行过程吧:
object ReduceDemo {
def main(args: Array[String]): Unit = {
val list = List(78, 92, 746, 1973, 879)
list.reduceLeft(sub) // demo.1
println(list.reduceRight(sub)) // demo.2
}
def sub(num1:Int, num2:Int):Int = {
num1 - num2
}
}
先从reduceLeft练手:过程是 (((78-92)-746)-1973)-879。
按照代码逻辑来分析reduceRight:
- 先逆序(879, 1973, 746, 92, 78)
- 然后执行reduceLeft,不过op(x, y) 变为了 op(y, x) (即结果成为了第二参数。。。)
- 执行顺序是 78 - (92 - (746 -(1973 - 879)))
我们对比一下原数组,会发现**只是变化了计算的顺序罢了(由从左到右,变为了从右向左)**结合上面的图例,应该很容易还原出reduceRight的执行过程图!
11.2.4、折叠(fold)
特点是:将上一次函数的返回值作为下一步函数的参数,怎么样是不是有点耳熟?!对这刚好对的上reduce的特点,实际上reduce就是fold的简化版!!
那么fold有什么区别呢?!根据源码的注释就知道,fold函数在调用参数函数前拥有一个**初始值!**整个函数调用执行阶段都是基于这个初始值的!!
而且有点莫名奇妙的是:fold调用时有两个圆括号!?!fold[A >: xx](z:A)(op:(A,A)=>A) A
后面那个括号里面表示一个函数op,那么前面那个z呢?!z就是我们提到的初始值!其实这种写法叫做函数的柯里化
来看下和reduce的对比吧:
object FoldDemo {
def main(args: Array[String]): Unit = {
val list = List(5, 6, 19, 23, 82, 3, 36)
println(list.reduce(add)) // 174
println(list.fold(20)(add)) // 194
}
def add(num1:Int, num2:Int):Int = {
num1 + num2
}
}
说的没错吧,刚刚好结果相差就是这个初始值!!
同样fold也分为foldLeft和foldRight,默认使用是foldLeft。除此以外,折叠还支持符号缩写!!就以上面的代码为例:
// 常规写法
list.fold(20)(add)
// foldLeft符号缩写
5/:list
// foldRight符号缩写
list:/5
但是在2.13版本标注了此符号缩写将过时,推荐直接使用foldLeft或者foldRight!!
现在仔细想想,折叠这个词是非常形象了,一张纸,我们从头部开始折叠,每次折入一部分,然后在折完的基础上再折入一部分,一张纸最后就变成了一个纸条!纸条的大小刚好和我们每次折入的大小一样!
11.2.5、扫描(scan)
这个是fold的使用进阶版,使用此方法会对所有的集合元素进行折叠操作,并记录下,每次折叠后的结果!
就好像上面所说的折纸,每折一下就记录一下已折叠部分!
看代码,一目了然:
object FoldDemo {
def main(args: Array[String]): Unit = {
val list = List(5, 6, 19, 23, 82, 3, 36)
println(list.fold(20)(add)) // 194
println(list.scan(20)(add)) // List(20, 25, 31, 50, 73, 155, 158, 194)
}
def add(num1:Int, num2:Int):Int = {
num1 + num2
}
}
可以注意到,那个初始值也作为一次折叠结果被保存了起来!!
Scala练习
Practice01
-
求3开方后,再平方的值与3相差多少?
3 - math.pow(math.sqrt(3),2) // result: Double = 4.440892098500626E-16 -
用字符串乘以一个数字,效果如何?
可以查看官方文档的
StringOps的*方法描述:

返回一个原字符拼接n次后的字符串:
scala> "hello"*3 val res1: String = hellohellohello -
10 max 2的含义,max方法在哪个类中定义?scala> 10 max 2 val res2: Int = 10很多类中都有max方法。
-
用BigInt计算2的1024次方
scala> var num:BigInt = 2; > num.pow(1024); var num: BigInt = 2 val res5: scala.math.BigInt = 179769313486231590772930519078902473361797697894230657273430081157732675805500963132708477322407536021120113879871393357658789768814416622492847430639474124377767893424865485276302219601246094119453082952085005768838150682342462881473913110540827237163350510684586298239947245938479716304835356329624224137216 -
查找字符串的首位字符
scala> var str:String = "hello"; > println(str.charAt(0)); > println(str.charAt(str.length-1)) h o var str: String = hellotake(n),取出字符串的前n个字符!takeRight(n),从字符串右边开始,取出前n个字符!scala> "hello".take(1); val res18: String = h scala> "hello".takeRight(1); val res19: String = o
Practice02
-
将Java HashMap中的键值对,拷贝到Scala中的HashMap中。(导入时使用包重命名方式!)
package com.sakura.chapter07 /** * @author sakura * @date 2020/10/18 下午5:19 */ object TestHashMap { import java.util.{HashMap => JavaHashMap} import collection.mutable.{HashMap => ScalaHashMap} def main(args: Array[String]): Unit = { val javaHashMap = new JavaHashMap[Int,String]() // Scala中泛型使用[]包裹 javaHashMap.put(1,"one") javaHashMap.put(2,"two") javaHashMap.put(3,"three") javaHashMap.put(4,"four") val scalaHashMap = new ScalaHashMap[Int,String]() for (key <- javaHashMap.keySet().toArray()){ // key.asInstanceOf[Int] 将key转化为Int类型 // scalaHashMap += ... 将javaHashMap中取出的key->value 加入到scalaHashMap scalaHashMap += (key.asInstanceOf[Int] -> javaHashMap.get(key)) } // mkString 输出集合中所有成员,并使用指定的分隔符隔开 println(scalaHashMap.mkString(",")) } }
会取集合的前两个元素作为f函数的参数,而从第二次开始,每次调用只会取集合的一个元素作为f的参数,另一个参数就是前一次f调用的返回值!**
来张图演示一下吧:就以累加作为案例:
[外链图片转存中…(img-LctM7UW0-1607877344264)]
文字描述就是:((((3+7)+ 5)+2)+8…
即每次的结果都会参与下一次的函数计算。而且计算的顺序是从左向右!!
示例代码:
object ReduceDemo {
def main(args: Array[String]): Unit = {
val list = List(78, 92, 746, 1973, 879)
val result = list.reduce(add)
println("result = " + result) // result = 3768
}
def add(num1:Int, num2:Int):Int = {
num1 + num2
}
}
这么看来,化简的来意就是:将一个复杂的大型的操作,拆分成一个个小的简单的操作来完成!
我们继续,当我们点到reduce的源码部分的时候,发现了新大陆:
def reduce[B >: A](op: (B, B) => B): B = reduceLeft(op)
reduceLeft??原来默认是调用reduceLeft(),所以计算顺序是从左到右。那么肯定还有一个reduceRight
[外链图片转存中…(img-wrI1eXZd-1607877344265)]
简单粗暴而高效的实现。。先将集合逆序,调用reduceLeft然后传了一个匿名函数,将原来的op(x,y)替换为了op(y,x)。
现在我们用累减的示例来猜测一下他reduceRight的执行过程吧:
object ReduceDemo {
def main(args: Array[String]): Unit = {
val list = List(78, 92, 746, 1973, 879)
list.reduceLeft(sub) // demo.1
println(list.reduceRight(sub)) // demo.2
}
def sub(num1:Int, num2:Int):Int = {
num1 - num2
}
}
先从reduceLeft练手:过程是 (((78-92)-746)-1973)-879。
按照代码逻辑来分析reduceRight:
- 先逆序(879, 1973, 746, 92, 78)
- 然后执行reduceLeft,不过op(x, y) 变为了 op(y, x) (即结果成为了第二参数。。。)
- 执行顺序是 78 - (92 - (746 -(1973 - 879)))
我们对比一下原数组,会发现**只是变化了计算的顺序罢了(由从左到右,变为了从右向左)**结合上面的图例,应该很容易还原出reduceRight的执行过程图!
11.2.4、折叠(fold)
特点是:将上一次函数的返回值作为下一步函数的参数,怎么样是不是有点耳熟?!对这刚好对的上reduce的特点,实际上reduce就是fold的简化版!!
那么fold有什么区别呢?!根据源码的注释就知道,fold函数在调用参数函数前拥有一个**初始值!**整个函数调用执行阶段都是基于这个初始值的!!
而且有点莫名奇妙的是:fold调用时有两个圆括号!?!fold[A >: xx](z:A)(op:(A,A)=>A) A
后面那个括号里面表示一个函数op,那么前面那个z呢?!z就是我们提到的初始值!其实这种写法叫做函数的柯里化
来看下和reduce的对比吧:
object FoldDemo {
def main(args: Array[String]): Unit = {
val list = List(5, 6, 19, 23, 82, 3, 36)
println(list.reduce(add)) // 174
println(list.fold(20)(add)) // 194
}
def add(num1:Int, num2:Int):Int = {
num1 + num2
}
}
说的没错吧,刚刚好结果相差就是这个初始值!!
同样fold也分为foldLeft和foldRight,默认使用是foldLeft。除此以外,折叠还支持符号缩写!!就以上面的代码为例:
// 常规写法
list.fold(20)(add)
// foldLeft符号缩写
5/:list
// foldRight符号缩写
list:/5
但是在2.13版本标注了此符号缩写将过时,推荐直接使用foldLeft或者foldRight!!
现在仔细想想,折叠这个词是非常形象了,一张纸,我们从头部开始折叠,每次折入一部分,然后在折完的基础上再折入一部分,一张纸最后就变成了一个纸条!纸条的大小刚好和我们每次折入的大小一样!
11.2.5、扫描(scan)
这个是fold的使用进阶版,使用此方法会对所有的集合元素进行折叠操作,并记录下,每次折叠后的结果!
就好像上面所说的折纸,每折一下就记录一下已折叠部分!
看代码,一目了然:
object FoldDemo {
def main(args: Array[String]): Unit = {
val list = List(5, 6, 19, 23, 82, 3, 36)
println(list.fold(20)(add)) // 194
println(list.scan(20)(add)) // List(20, 25, 31, 50, 73, 155, 158, 194)
}
def add(num1:Int, num2:Int):Int = {
num1 + num2
}
}
可以注意到,那个初始值也作为一次折叠结果被保存了起来!!
Scala练习
Practice01
-
求3开方后,再平方的值与3相差多少?
3 - math.pow(math.sqrt(3),2) // result: Double = 4.440892098500626E-16 -
用字符串乘以一个数字,效果如何?
可以查看官方文档的
StringOps的*方法描述:
[外链图片转存中…(img-cLUxuHT8-1607877344265)]返回一个原字符拼接n次后的字符串:
scala> "hello"*3 val res1: String = hellohellohello -
10 max 2的含义,max方法在哪个类中定义?scala> 10 max 2 val res2: Int = 10很多类中都有max方法。
-
用BigInt计算2的1024次方
scala> var num:BigInt = 2; > num.pow(1024); var num: BigInt = 2 val res5: scala.math.BigInt = 179769313486231590772930519078902473361797697894230657273430081157732675805500963132708477322407536021120113879871393357658789768814416622492847430639474124377767893424865485276302219601246094119453082952085005768838150682342462881473913110540827237163350510684586298239947245938479716304835356329624224137216 -
查找字符串的首位字符
scala> var str:String = "hello"; > println(str.charAt(0)); > println(str.charAt(str.length-1)) h o var str: String = hellotake(n),取出字符串的前n个字符!takeRight(n),从字符串右边开始,取出前n个字符!scala> "hello".take(1); val res18: String = h scala> "hello".takeRight(1); val res19: String = o
Practice02
-
将Java HashMap中的键值对,拷贝到Scala中的HashMap中。(导入时使用包重命名方式!)
package com.sakura.chapter07 /** * @author sakura * @date 2020/10/18 下午5:19 */ object TestHashMap { import java.util.{HashMap => JavaHashMap} import collection.mutable.{HashMap => ScalaHashMap} def main(args: Array[String]): Unit = { val javaHashMap = new JavaHashMap[Int,String]() // Scala中泛型使用[]包裹 javaHashMap.put(1,"one") javaHashMap.put(2,"two") javaHashMap.put(3,"three") javaHashMap.put(4,"four") val scalaHashMap = new ScalaHashMap[Int,String]() for (key <- javaHashMap.keySet().toArray()){ // key.asInstanceOf[Int] 将key转化为Int类型 // scalaHashMap += ... 将javaHashMap中取出的key->value 加入到scalaHashMap scalaHashMap += (key.asInstanceOf[Int] -> javaHashMap.get(key)) } // mkString 输出集合中所有成员,并使用指定的分隔符隔开 println(scalaHashMap.mkString(",")) } }