计算机视觉框架OpenMMLab开源学习(六):语义分割基础
✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,通俗易懂,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。
语义分割
前言:本系列第六篇文章主要介绍语义分割知识,了解计算机视觉框架OpenMMLab的MMSegmentation工具基本原理及使用,为后续语义分割实战做铺垫。
本节内容:
• 语义分割的基本思路• 深度学习下的语义分割模型• 全卷积网络• 空洞卷积与 DeepLab 模型上下文信息与 PSPNet 模型• 分割模型的评估方法• 实践 MMSegmentation
语义分割概念
任务: 将图像按照物体的类别分割成不同的区域 等价于: 对每个像素进行分类。
语义分割应用:
无人驾驶汽车,人像分割,智能遥感,医疗影像分析

mmdet是实例分割,先做检测
- 语义分割 : 仅考虑像素的类别 不分割同一类的不同实体
- 实例分割 : 分割不同的实体 仅考虑前景物体
- 全景分割 : 背景仅考虑类别 前景需要区分实体
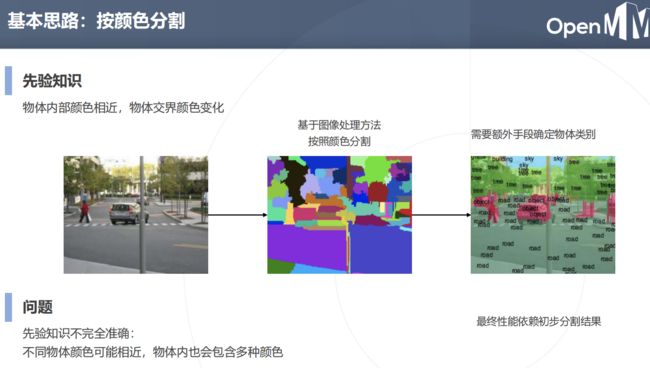
语义分割的基本思路

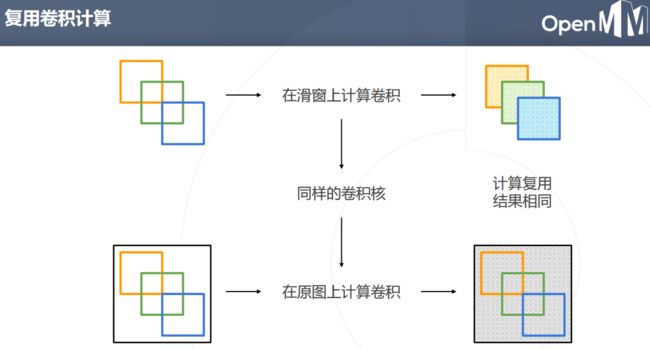
在原图上计算卷积,计算复用结果相同
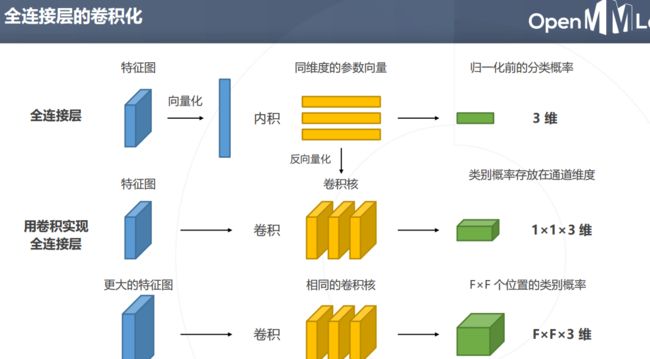
问题:全连接层要求固定输入大小

兼容任意尺寸的图,没有全连接层
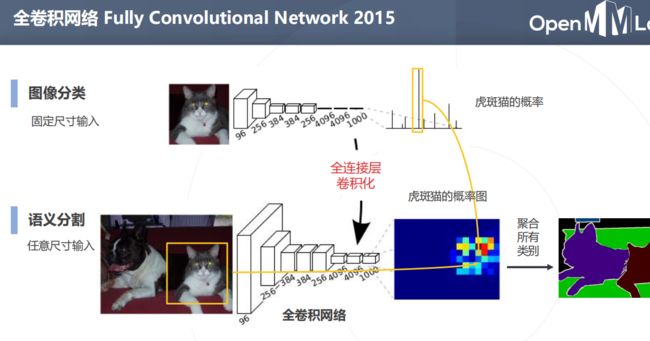
深度学习下的语义分割模型
升采样:双线性插值和转置卷积
池化,卷积降采样,语义分割需要升采样





卷积,空间语义会因为降采样逐渐丢失位置信息
问题:基于顶层特征预测,再升采样 32 倍得到的预测图较为粗糙
分析:高层特征经过多次降采样,细节丢失严重
解决思路: 结合低层次和高层次特征图

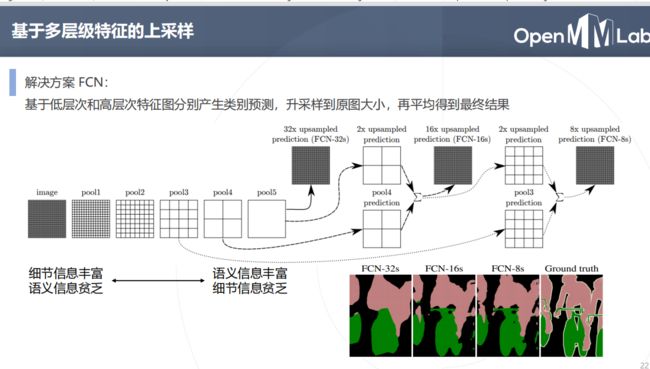
Unet 2015

上下文信息和PSPNet
图块周围的像素块,图像周围的内容:上下文
有歧义的区域:

滑动窗口会丢失上下文信息,并且低效,需要更大范围的信息
图像周围的内容(也称上下文)可以帮助我们做出更准确的判断。
方案:增加感受野更大的网络分支,将上下文信息导入局部预测中

PSPNet2016
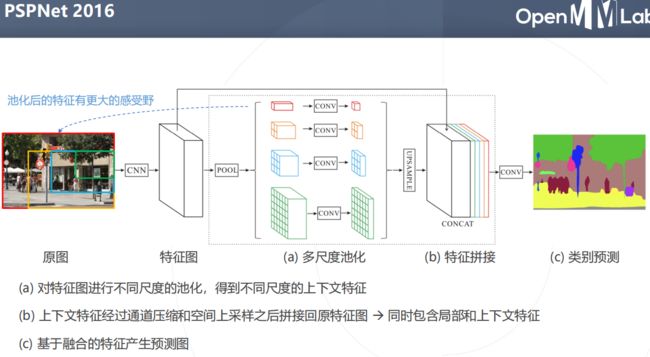
不同感受野的上下文信息
空洞卷积与DeepLab系列算法
DeepLab 是语义分割的又一系列工作,其主要贡献为:
- 使用空洞卷积解决网络中的下采样问题
- 使用条件随机场 CRF 作为后处理手段,精细化分割图
- 使用多尺度的空洞卷积(ASPP 模块)捕上下文信息
DeepLab v1
发表于2014 年,后于 2016、2017、2018 年提出 v2、v3、v3+ 版本


空洞卷积解决下采样问题
问题:图像分类模型中的下采样层使输出尺寸变小
- 如果将池化层和卷积中的步长去掉
- 可以减少下采样的次数;
- 特征图就会变大,需要对应增大卷积核,以维持相同的感受野,但会增加大量参数
解决方案:
使用空洞卷积(Dilated Convolution/Atrous Convolution),在不增加参数的情况下增大感受野

下采样加标准卷积等价于空洞卷积

使用空洞卷积可以得到相同分辨率的特征图,且无需额外插值操作

- 去除分类模型中的后半部分的下采样层
- 后续的卷积层改为膨胀卷积,并且逐步增加rate来维持原网络的感受野
条件随机场Conditional Random Field,CRF
问题:模型直接输出的分割图较为粗糙,尤其在物体边界处不能产生很好的分割结果
一种后处理,使得语义边界分割精确


能量函数,可以看做一种损失函数

ASPP 空间金字塔池化 Atrous Spatial Pyramid Pooling
 PSPNet 使用不同尺度的池化来获取不同尺度的上下文信息
PSPNet 使用不同尺度的池化来获取不同尺度的上下文信息
DeepLab v2&v3 使用不同尺度的空洞卷积达到类似的效果
更大膨胀率的空洞卷积--->>>更大的感受野--->>>更多的上下文特征
DeepLab v3+

- DeepLab v2 / v3 模型使用 ASPP 捕捉上下文特征
- Encoder / Decoder 结构(如 UNet) 在上采样过程中融入低层次的特征图,以获得更精细的分割图
DeepLab v3+ 将两种思路融合,在原有模型结构上增加了一个简单的 decoder 结构
- Encoder 通过ASPP 产生多尺度的高层语义信息
- Decoder 主要融合低层特征产生精细的分割结果

经典语义分割算法

语义分割模型的评估

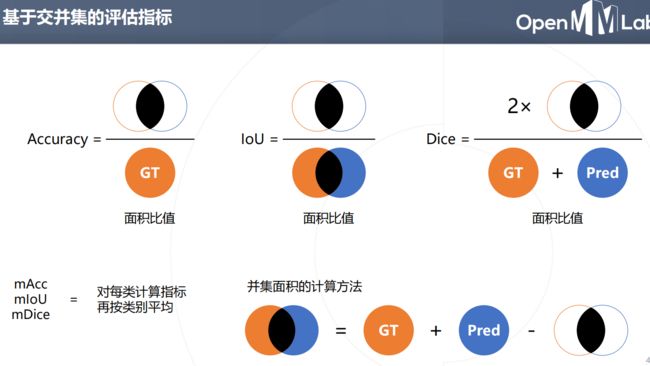
在机器学习分类项目中,我们一般:
用precision来评估某类别分类的准确性; 用accuracy来评估总体分类的准确性。
recall与precision区别:
(1)recall,召回率又名查全率,与漏报率有关,(漏报率,FN,即错误的预测为负样本,换句话说,将实际为正的样本预测为负),详情参照混淆矩阵,如下。
| 预测为正样本(positive,P) | 预测为负样本(negative,N) | |
|---|---|---|
| 实际为正样本 (True, T) | TP | FN |
| 实际为负样本 (False, F) | FP | TN |
其中,T指预测正确(预测为正样本,实际也为正样本的情况),F指预测错误。
recall=TP/(TP+FN),可理解为,实际为正的样本中,预测正确的样本的比例。
应用于,医生预测病人癌症的情况,病人更关注的是是否漏报,漏报会导致病被忽略,延误治疗。
通过记忆漏报率,可清晰理解recall的概念。
(2)precision,精准率又名查准率,与误报率有关,(误报率,FP,即错误的预测为正样本,换句话说,将实际为负的样本预测为正)。
precision=TP/(TP+FP),可理解为,在预测为正的样本集合中,预测正确的样本的比例。
总结:
本系列第六篇文章主要介绍语义分割知识,了解计算机视觉框架OpenMMLab的MMSegmentation工具基本原理及使用,为后续语义分割实战做铺垫。