KubeEdge SIG AI 进展与规划
在2022云原生边缘计算峰会KubeEdge Summit上,德国HPI研究院多媒体与机器学习科研组负责人杨浩进介绍了边缘AI的现状和趋势,KubeEdge SIG AI的进展和规划。

01
边缘AI现状与趋势
在介绍场景之前,杨浩进老师提供给大家两个统计数据。第一个数字是关于AI发展到目前阶段所遇到的算力瓶颈问题。由于在过去10年云计算和高性能计算硬件的蓬勃发展,我们都普遍认为AI计算的算力瓶颈已经被解决了。但实际上,随着目前最前沿的AI大模型的快速发展,它已经成为自然语言处理和计算机视觉两大领域的重要发展方向。自 2018 年 语言模型BERT 诞生,到 GPT-3、ViT 等拥有数以亿计的参数规模的模型不断涌现。与此同时, 大模型对计算和内存资源提出了巨大的挑战, 比如用一个NVIDIA A100 GPU 训练千亿参数模型的 GPT-3,需要用时 100 多年。根据 OpenAI 的报告,模型大小的增长速度是每 3.5 月翻一倍。因此,业内不得不将计算扩展到多个和多种类的设备上,分布式计算成为了未来的必然选择。
此外,AI计算带来的碳排放量是巨大的,对碳中和战略也带来了额外挑战,不应被忽视。例如使用神经架构搜索训练一次transformer模型所需的碳排放量约等于300人次往返于纽约和旧金山的飞行。另一个例子是openAI的GPT3模型,它的一次训练所消耗的电能和碳排放相当于43辆车或24个美国家庭一年的排放量。而这些挑战和问题,都可以通过分布式的边缘AI计算范式来解决。
根据 Gartner 的预测,到 2020 年,全球物联网设备的数量将超过 200 亿台。同时,设备本身也变得越来越智能化。因此,Edge AI 在过去几年成为了一个快速发展的领域。它可能在未来3年内达到顶峰。到 2022 年,50% 的企业生成数据将在传统数据中心或云之外处理,而这一数字在 2018 年还不到 10%。
此外,根据全球技术市场咨询公司ABI Research的报告,预计到2025年,边缘AI芯片组市场收入将达到122亿美元,云端AI芯片组市场收入将达到119亿美元。边缘 AI 芯片组市场将超过云端 AI 芯片组市场。
在边缘计算的浪潮中,AI是边缘云乃至分布式中最重要的应用
随着边缘设备的广泛使用和性能提升,将人工智能相关的部分任务部署到边缘设备已经成为必然趋势,而基于边缘设备、边缘服务器、云服务器利用分布式乃至协同方式实现人工智能的技术就是我们所说的分布式协同AI技术。
分布式协同AI核心驱动力:“数据首先在边缘”,边侧逐步具备AI能力。这让我们有理由相信虽然分布式协同AI还是发展初期,但已经是大势所趋,能够走得更远。随着边侧算力逐步强化,边缘AI模式正在持续演变从当前“云上训练、边侧推理”模式,向边云协同乃至分布式协同演进。

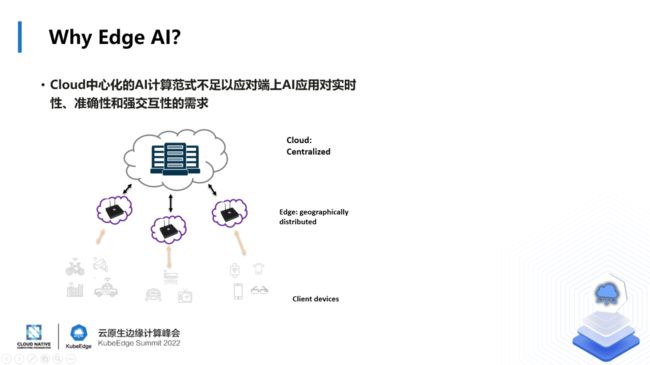
边缘AI的另一个核心驱动力是我们可以看到AI正在逐步渗透到越来越多的边缘场景。从传统的工业制造、农业、交通以及零售行业,到新兴的智慧城市,智能医疗、家居。设备从汽车,飞机,甚至卫星,到手机、手表、头显眼镜。可以肯定的是,Edge AI 时代即将到来。它将改变人工智能模式,改变边缘计算软硬件生态,让我们的生活更加舒适和智能。
那么边缘人工智能面临哪些挑战?首先,Edge AI 的一个重大挑战是每个边缘节点的异构性。我们必须处理大量的硬件架构、操作系统和不同的人工智能软件框架。我们可以看到,三个不同维度的异质性显着增加了实现的难度。
一个重要的问题是如何在 Edge AI 场景中更好地保护数据隐私。我认为这应该是 EdgeAI 技术栈的一个优势。但是,从另一个角度来看,更严格的数据隐私政策可能会导致数据孤岛问题。通常,由于隐私保护和其他原因,它们无法共享。因此,AI 算法无法将每个边缘节点的数据有效地结合在一起使用。
传统的集中式 AI 方法带来了显着的性能下降,例如在边缘场景下收敛速度较低,模型精度较差。在传统的监督学习研究中,IID(独立同分布)是一个重要的假设。通常,当我们做机器学习任务时,我们假设我们的训练数据和测试数据具有相同的分布。样本彼此独立。比如 CIFAR 数据集,因为训练集和测试集是平分的,如果你从这两组中随机选择一个样本,它属于其中一个类的概率是 10%。这是 IID。在实践中,Edge 节点的数据分布存在相当大的差异。另外,预训练模型的数据分布和边缘节点的测试数据分布也可能相差很大,所以我们面临的是一个 Non-IID 问题。这个问题在学界仍然是研究的重点问题
另外一个问题是边缘节点通常只有有限的资源。例如,它的电源、计算和存储资源远低于云端设备。此外,带宽也是一个可能的瓶颈。我们在设计算法和软件时需要考虑这些问题。除了边缘数据分布不均,我们还可能面临样本太少的问题,无法有效进行模型训练。此外,我们可能会遇到未知的数据类,这将导致监督学习方法的彻底失败。
02
KubeEdge SIG AI 进展
KubeEdge是业界首个云原生边缘计算框架、云原生计算基金会内部唯一孵化级边缘计算开源项目。KubeEdge在全球已拥有900+贡献者和70+贡献组织,在GitHub获得5.7k+Stars和1.7k+Forks。
近年来,KubeEdge社区持续开拓创新,完成业界最大规模云原生边云协同高速公路项目(统一管理10万边缘节点/50万边缘应用)、业界首个云原生星地协同卫星、业界首个云原生车云协同汽车、业界首个云原生油田项目,开源业界首个分布式协同AI框架Sedna及业界首个边云协同终身学习范式。
并且,在本次峰会上KubeEdge SIG AI还发布了开源业界首个分布式协同AI基准测试套件Ianvs,面向分布式协同AI的算法和服务开发者在单机层面快速孵化算法及解决方案,有开箱即用安装简单、工具链开放可扩展、全场景灵活切换和低代码生成测试用例等优点。

分布式协同AI框架 Sedna无疑是目前SIG AI最核心最重要的工作。它可以说是业界首个专注云边协同分布式AI的开源项目。
Sedna的核心理念是基于KubeEdge提供的边云协同基础框架,打造中间服务以支持现有AI应用无缝下沉到边缘。Sedna的使命是打通AI应用和云边协同计算能力的通路。让边缘计算和AI社区的开发者们都能够获益。它降低了分布式协同机器学习服务构建与部署成本、提升模型性能、保护数据隐私等。
更具体来说,Sedna提供为AI应用提供数据处理和模型管理的基础架构。它基于重要场景,推出了实用性强的特性,例如协同推理,联邦学习,增量学习终身学习等等。这些特性都是针对边缘AI的优势以及要解决的技术难点,结合场景需求而开发的。我想实用性强是这些特性非常重要的特点。
下面给大家介绍两个场景:
一个是基于Sedna多边协同特性实现了目标追踪和再识别。并且这个新的技术特性有效支持了前不久的新冠流调,在这个有挑战性的场景中进行了验证。
目前常规的流调方法是完全基于人工筛查的方式,在新冠传染性极强,传播速度快的背景下,常规流调可以说是费时费力。目标是寻找传播途径、提供隔离依据。为此可能需要人工逐个打电话问询,要回忆14天去过什么地方接触过谁。但实际情况是根本难以回忆14天接触过什么人,而且无法锁定陌生人。
基于以上传统流调手段效率低的难点,我们开发了基于视频分析的自动化目标追踪和再识别的方案。首先希望有效支持园区、商超范围内的病例密接以及次密接的快速筛查。
这个方案有以下几个特点,首先,它具备极高的效率,9小时的视频在单卡节点分析耗时仅10分钟,相比较人工筛查的方式节约了90%的时间。同时,它具备非常高的重识别准确性,相比较传统的基于全监督学习最好的ReID模型,我们的域泛化模型可提升约38%的准确率。在新冠流调数据集上实现了90%以上的重识别准确率。最后,边缘数据收集边缘处理和多边交互的特性使其具有更好的数据隐私保护能力。
另外一个是基于Sedna的终身学习特性实现多联机空调舒适度预测。概括来说,要解决的问题是,根据多联机空调系统的设定参数,温湿度和所处地区等环境特征。预测人体舒适程度,预测结果比如过冷、舒适或过热)然后基于这个预测结果进而给出符合舒适度约束下的最佳节能空调设定。
当前市场上智慧楼宇、空调群控系统及相关硬件设备天然位于边缘。新园区系统启用需冷启动能力实现快速交付个性化空调控制,实现一楼一策略甚至一房一策略。期望目标是边缘AI模型能根据季节变换持续迭代园区设备智能服务,并实现离线自治。
这个场景的技术挑战主要包括小样本问题:如传感器覆盖不全、出现数据丢失,采样规模小。还有数据异构问题:不同城市中特征分布差异大、单一模型性能波动可能会很大。
目前Sedna的方案是基于多个历史任务在云端对知识库建模,并以此为初始化。然后,基于云端知识库进而对边侧数据和任务进行学习,再反馈给云端知识库并更新,这样形成了一个循环链路,我们重复这个过程将获得更健壮的知识库,用来处理未来的边侧任务。
基于以上的方案,实现了精度,抗遗忘能力以及未来任务处理能力的全面大幅提升。
另外,SIG AI当前也发布了业界首个分布式协同AI基准测试套件 -- Ianvs(读音:雅努斯),这个套件将面向分布式协同AI的开发者,通过提供数据集和配套算法测试用例、仿真工具、排行榜等帮助开发者更高效地进行分布式协同AI解决方案的研发。
03
KubeEdge SIG AI 规划
社区经过积极的讨论,认为下一步的规划应该重点在三个方向。首先,还是专注边云协同AI框架Sedna的发展,完善以及积极开发新的特性,扩大在社区的影响力。
同时,重点推出协同测试框架 Ianvs ( 雅努斯 ),它关注我们的合作伙伴应用上的痛点问题,如边缘AI关键特性的全面基准规格,边缘AI典型场景的测试用例;边缘AI端到端测试床。
当然,以上两个部分成功的必要条件是能够打造一个蓬勃的生态和社区,我们将更加积极的发展合作伙伴,不论是技术特性层面还是应用开发。我们除了基础设施的合作伙伴如深度学习框架,联邦学习研究团队,也非常欢迎更多业界的伙伴们积极合作,用Edge AI技术帮助解决业务中的难题。

不论是从技术层面,还是从应用开发层面,除了基础设施合作伙伴,比如像深度学习框架,我们支持后端框架,还有包括联邦学习研究团队,我们支持的联邦学习的库,也非常欢迎更多的业界伙伴,根据业务需求,提出自己的场景。我们也非常希望期待你来加入我们的社区,来进行积极合作,让用我们用EdgeAI的技术和相应的框架来帮助解决你业务当中的难题。
关于具体项目的规划和路标,我们从两个方面介绍。一个是Ianvs,下面这是它的底座Sedna,他们两个用另一种协同的方式来进行规划。详细特性的内容可以见下图。
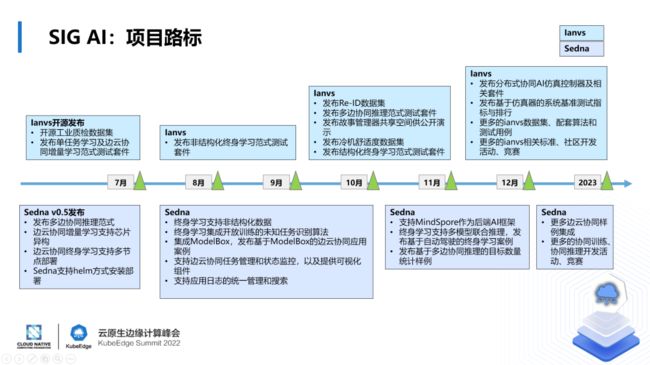
这是未来的半年到一年的这个时间维度上,SIG AI的项目路标。欢迎大家积极的关注,更加欢迎大家能够加入我们的社区,一起加入到KubeEdge这个大的家庭,我们一起来推动Edge AI领域的发展。