
背景
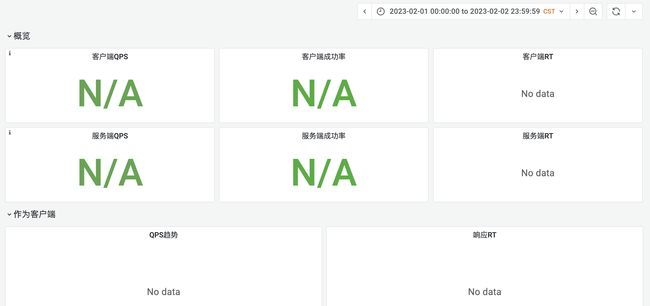
前段时间我们将 istio 版本升级到 1.12 后导致现有的应用监控有部分数据丢失(页面上显示不出来)。
- 一个是应用基础信息丢失。
- 再一个是应用 JVM 数据丢失。
- 接口维度的监控数据丢失。

修复
基础信息
首先是第一个基础信息丢失的问题,页面上其实显示的是我们的一个聚合指标istio_requests_total:source:rate1m。
聚合后可以将多个指标合并为一个,减少系统压力
具体可以参考 Istio 的最佳实践 Observability Best Practices 有详细说明。
spec:
groups:
- interval: 30s
name: istio.service.source.istio_requests_total
rules:
- expr: |
sum(irate(istio_requests_total{reporter="source"}[1m]))
by (
destination_app,
source_workload_namespace,
response_code,
source_app
)
record: istio_requests_total:source:rate1m本质上是通过以上四个维度进行统计 istio_requests_total;但在升级之后查看原始数据发现丢失了 destination_app, source_app 这两个 tag。
至于为啥丢失,查了许久,最后在升级后的资源文件 stats-filter-1.12.yaml 中找到了答案: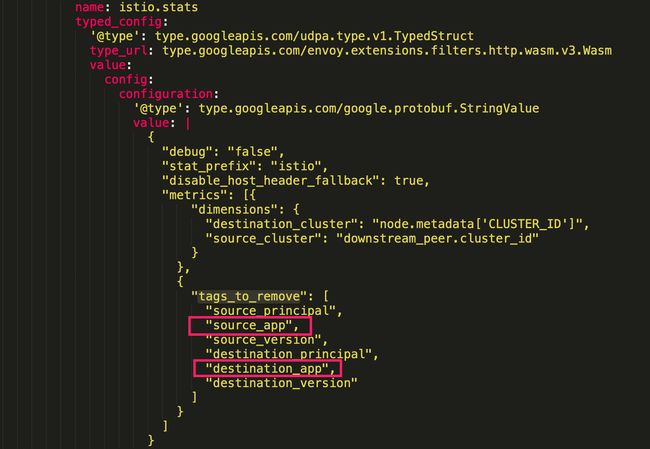
升级后新增了 tags_to_remove 标记,将我们所需要的两个 tag 直接删掉了。
后续在当前 namespace 下重新建一个 EnvoyFilter 资源覆盖掉默认的便能恢复这两个 tag,修复后监控页面也显示正常了。
EnvoyFilter 是实时生效的,并不需要重建应用 Pod。
JVM 监控
JVM 数据丢失的这个应用,直接进入 Pod 查看暴露出的 metric,发现数据都有,一切正常。
jvm_memory_pool_bytes_used{pool="Code Cache",} 1.32126784E8
jvm_memory_pool_bytes_used{pool="Metaspace",} 2.74250552E8
jvm_memory_pool_bytes_used{pool="Compressed Class Space",} 3.1766024E7
jvm_memory_pool_bytes_used{pool="G1 Eden Space",} 1.409286144E9
jvm_memory_pool_bytes_used{pool="G1 Survivor Space",} 2.01326592E8
jvm_memory_pool_bytes_used{pool="G1 Old Gen",} 2.583691248E9说明不是数据源的问题,那就可能是数据采集节点的问题了。
进入VictoriaMetrics 的 target 页面发现应用确实已经下线,原来是采集的端口不通导致的。
我们使用 VictoriaMetrics 代替了 Prometheus。

而这个端口 15020 之前并未使用,我们使用的是另外一个自定义端口和端点来采集数据。
经过查阅发现 15020 是 istio 默认的端口: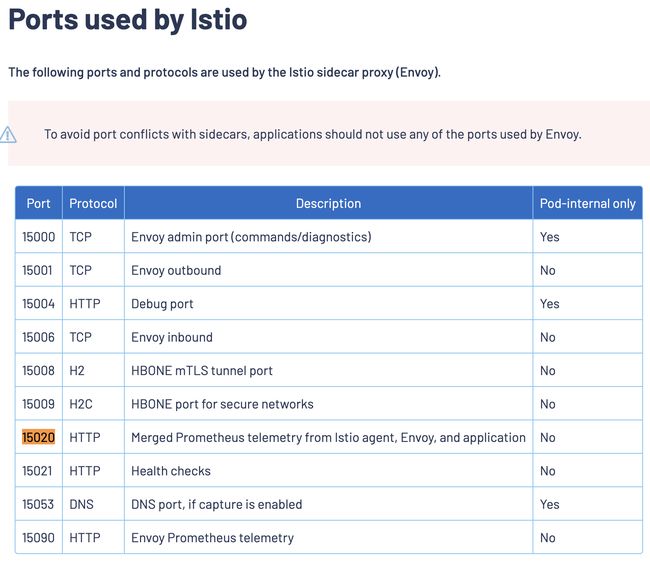
原来在默认情况下 Istio 会为所有的数据面 Pod 加上:
metadata:
annotations:
prometheus.io/path: /stats/prometheus
prometheus.io/port: "15020"这个注解用于采集数据,由于我们是自定义的端点,所以需要修改默认行为:
在控制面将 --set meshConfig.enablePrometheusMerge=false 设置为 false,其实官方文档已经说明,如果不是使用的标准 prometheus.io 注解,需要将这个设置为 false。
修改后需要重建应用 Pod 方能生效。
有了 url 这个 tag 后,接口监控页也恢复了正常。
接口维度
接口维度的数据丢失和基本数据丢失的原因类似,本质上也是原始数据中缺少了 url 这个 tag,因为我们所聚合的指标使用了 url:
- interval: 30s
name: istio.service.source.url.istio_requests_total
rules:
- expr: |
sum(irate(istio_requests_total{reporter="source"}[1m]))
by (
destination_app,
source_workload_namespace,
response_code,
source_app,
url
)最终参考了 MetricConfig 自定义了 URL 的tag.
{
"dimensions": {
"url": "request.url_path"
},
但这也有个大前提,当我们 tag 的指标没有在默认 tag 列表中时,需要在 Deployment 或者是 Istio 控制面中全局加入我们自定义的 tag 声明。
比如这里新增了 url 的 tag,那么就需要在控制面中加入:
meshConfig:
defaultConfig:
extraStatTags:
- url修改了控制面后需要重新构建 Pod 后才会生效。
EnvoyFilter的问题
查看MetricConfig的配置后发现是可以直接去掉指标以及去掉指标中的 tag ,这个很有用,能够大大减低指标采集系统 VictoriaMetrics 的系统负载。
于是参考了官方的示例,去掉了一些 tag,同时还去掉了指标:istio_request_messages_total。
{
"tags_to_remove": [
"source_principal",
"source_version",
"destination_principal",
"destination_version",
"source_workload",
"source_cluster",
]
},
{
"name": "istio_request_messages_total",
"drop": true
}但并没有生效,于是换成了在 v1.12 中新增的 Telemetry API。
使用 Telemetry API

apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: mesh-istio-test
namespace: istio-test
spec:
# no selector specified, applies to all workloads
metrics:
- overrides:
- match:
metric: GRPC_REQUEST_MESSAGES
mode: CLIENT_AND_SERVER
disabled: true但是参考了官方文档后发现依然不能生效,GRPC_REQUEST_MESSAGES 所对应的 istio_request_messages_total 指标依然存在。
接着在我领导查看 Istio 源码以及相关 issue 后发现 Telemetry API 和 EnvoyFilter 是不能同时存在的,也就是说会优先使用 EnvoyFilter;这也就是为什么我之前配置没有生效的原因。
后初始化 EnvoyFilter

正如这个 issue 中所说,需要删掉现在所有的 EnvoyFilter;删除后果然就生效了。
新的 Telemetry API 不但语义更加清晰,功能也一样没少,借助他我们依然可以自定义、删除指标、tag 等。
apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: mesh-istio-telemetry-test
namespace: test
spec:
metrics:
- overrides:
- match:
metric: GRPC_RESPONSE_MESSAGES
mode: CLIENT_AND_SERVER
disabled: true
- tagOverrides:
url:
value: "request.url_path"
- match:
metric: ALL_METRICS
tagOverrides:
source_workload:
operation: REMOVE比如以上配置便可以删除掉 GRPC_RESPONSE_MESSAGES 指标,新增一个 url 的指标,同时在所有指标中删除了 source_workload 这个 tag。
借助于这一个声明文件便能满足我们多个需求。
裁剪指标
后续根据我们实际需求借助于 Telemetry API 裁剪掉了许多指标和 tag,使得指标系统负载下降了一半左右。
效果相当明显。
总结
本次定位修复 Istio 升级后带来的指标系统问题收获巨大,之前对 Istio 一直只停留在理论阶段,只知道他可以实现传统微服务中对接口粒度的控制,完美弥补了 k8s 只有服务层级的粗粒度控制;
这两周下来对一个现代云原生监控系统也有了系统的认识,从 App->Pod->sidecar->VictoriaMetrics(Prometheus)->Grafana 这一套流程中每个环节都可能会出错;
所以学无止境吧,幸好借助公司业务场景后续还有更多机会参与实践。