MySQL的SQL基础(五)
文章目录
-
- 1. 单表查询
-
- 1.1 having 语句
- 1.2 order by 应用
- 1.3 limit 应用
- 2. select 多表连接查询
-
- 2.1 多表连接查询作用
- 2.2 多表连接查询类型
-
- 2.2.1 笛卡尔乘积
- 2.2.2 内连接
- 2.2.3 外连接
- 2.3 内连接的使用技巧
- 2.4 多表连接查询例子
- 2.5 外连接应用
- 3. select知识点补充
-
- 3.1 别名应用
-
- 3.1.1 列别名
- 3.1.2 表别名
- 3.2 distinct 应用
- 3.3 union和union all
- 4. show 语句介绍
- 5. information_schema 元数据获取
-
- 5.1 元数据介绍
- 5.2 information_schema介绍
- 5.3 I_S.table常用信息介绍
- 5.4 I_S.table企业应用案例
1. 单表查询
1.1 having 语句
作用:与where子句类似,having属于后过滤
场景:需要在group by + 聚合函数后,再做判断过滤时使用
-- 例子15: 统计中国,每个省的总人口,只显示总人口数大于500w信息
SELECT district,SUM(population)
FROM world.`city`
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000;
1.2 order by 应用
-- 例子16: 统计中国,每个省的总人口,只显示总人口数大于500w信息,并且按照总人口从大到小排序输出
SELECT district,SUM(population)
FROM world.`city`
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC ;
小提示:
(1)limit一般配合order by一起使用的,不做order by的limit没有太大的意义
1.3 limit 应用
作用: 分页显示结果集
-- 例子17: 统计中国,每个省的总人口,只显示总人口数大于500w信息,并且按照总人口从大到小排序输出,只显示前五名
-- limit 5 等同于 limit 5 offset 0
SELECT district,SUM(population)
FROM world.`city`
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 5;
-- 例子18: 统计中国,每个省的总人口,只显示总人口数大于500w信息,并且按照总人口从大到小排序输出,只显示前6-10名
SELECT district,SUM(population)
FROM world.`city`
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 5,5;
-- 上下两种写法结果都一样
-- limit 5 offset 5 跳过前5行,显示5行(6~10行)
SELECT district,SUM(population)
FROM world.`city`
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 5 OFFSET 5;
3~5名:
limit 2,3
limit 3 offset 2
2. select 多表连接查询
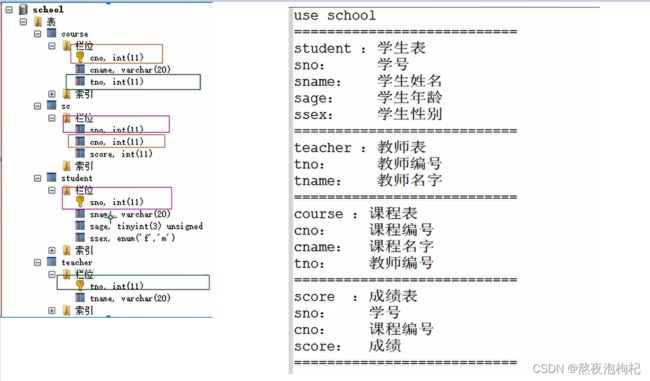
先创建一个school数据库并创建student、teacher、course、score表,并且插入数据,方便后续实验操作
use school
student :学生表
sno: 学号
sname:学生姓名
sage: 学生年龄
ssex: 学生性别
teacher :教师表
tno: 教师编号
tname:教师名字
course :课程表
cno: 课程编号
cname:课程名字
tno: 教师编号
score :成绩表
sno: 学号
cno: 课程编号
score:成绩
-- 项目构建
-- 建库建表并插入数据
CREATE DATABASE school CHARSET utf8mb4;
USE school
CREATE TABLE student(
sno INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(20) NOT NULL COMMENT '姓名',
sage TINYINT UNSIGNED NOT NULL COMMENT '年龄',
ssex ENUM('f','m') NOT NULL DEFAULT 'm' COMMENT '性别'
)ENGINE=INNODB CHARSET=utf8mb4;
CREATE TABLE course(
cno INT NOT NULL PRIMARY KEY COMMENT '课程编号',
cname VARCHAR(20) NOT NULL COMMENT '课程名字',
tno INT NOT NULL COMMENT '教师编号'
)ENGINE=INNODB CHARSET=utf8mb4;
CREATE TABLE sc (
sno INT NOT NULL COMMENT '学号',
cno INT NOT NULL COMMENT '课程编号',
score INT NOT NULL DEFAULT 0 COMMENT '成绩'
)ENGINE=INNODB CHARSET=utf8mb4;
CREATE TABLE teacher(
tno INT NOT NULL PRIMARY KEY COMMENT '教师编号',
tname VARCHAR(20) NOT NULL COMMENT '教师名字'
)ENGINE=INNODB CHARSET=utf8mb4;
INSERT INTO student(sno,sname,sage,ssex)
VALUES (1,'zhang3',18,'m'),
(2,'zhang4',18,'m'),
(3,'li4',18,'m'),
(4,'wang5',19,'f'),
(5,'zh4',18,'m'),
(6,'zhao4',18,'m'),
(7,'ma6',19,'f'),
(8, 'oldboy', 20, 'm'),
(9, 'oldgirl', 20, 'f'),
(10, 'oldp', 25, 'm');
INSERT INTO teacher(tno,tname) VALUES
(101,'oldboy'),
(102,'hesw'),
(103,'oldguo');
INSERT INTO course(cno,cname,tno)
VALUES
(1001,'linux',101),
(1002,'python',102),
(1003,'mysql',103);
INSERT INTO sc(sno,cno,score)
VALUES
(1,1001,80),
(1,1002,59),
(2,1002,90),
(2,1003,100),
(3,1001,99),
(3,1003,40),
(4,1001,79),
(4,1002,61),
(4,1003,99),
(5,1003,40),
(6,1001,89),
(6,1003,77),
(7,1001,67),
(7,1003,82),
(8,1001,70),
(9,1003,80),
(10,1003,96);
SELECT * FROM student;
SELECT * FROM teacher;
SELECT * FROM course;
SELECT * FROM sc;
2.1 多表连接查询作用
为什么要使用多表连接查询?
我们的查询需求,需要的数据,来自于多张表,单张表无法满足。
2.2 多表连接查询类型
2.2.1 笛卡尔乘积
mysql> select * FROM teacher,course;
+-----+--------+------+--------+-----+
| tno | tname | cno | cname | tno |
+-----+--------+------+--------+-----+
| 101 | oldboy | 1001 | linux | 101 |
| 102 | hesw | 1001 | linux | 101 |
| 103 | oldguo | 1001 | linux | 101 |
| 101 | oldboy | 1002 | python | 102 |
| 102 | hesw | 1002 | python | 102 |
| 103 | oldguo | 1002 | python | 102 |
| 101 | oldboy | 1003 | mysql | 103 |
| 102 | hesw | 1003 | mysql | 103 |
| 103 | oldguo | 1003 | mysql | 103 |
+-----+--------+------+--------+-----+
-- 标准的写法
mysql> select * from teacher join course;
+-----+--------+------+--------+-----+
| tno | tname | cno | cname | tno |
+-----+--------+------+--------+-----+
| 101 | oldboy | 1001 | linux | 101 |
| 102 | hesw | 1001 | linux | 101 |
| 103 | oldguo | 1001 | linux | 101 |
| 101 | oldboy | 1002 | python | 102 |
| 102 | hesw | 1002 | python | 102 |
| 103 | oldguo | 1002 | python | 102 |
| 101 | oldboy | 1003 | mysql | 103 |
| 102 | hesw | 1003 | mysql | 103 |
| 103 | oldguo | 1003 | mysql | 103 |
+-----+--------+------+--------+-----+
9 rows in set (0.00 sec)
小提示:
(1)笛卡尔积没有什么意义,但是有助于我们理解多表连接工作的行为
2.2.2 内连接
内连接应用最广泛
- 语法形式
A join B
on A.xx=B.yy
-- teacher表和course表进行内连接
mysql> select * from teacher join course on teacher.tno=course.tno;
+-----+--------+------+--------+-----+
| tno | tname | cno | cname | tno |
+-----+--------+------+--------+-----+
| 101 | oldboy | 1001 | linux | 101 |
| 102 | hesw | 1002 | python | 102 |
| 103 | oldguo | 1003 | mysql | 103 |
+-----+--------+------+--------+-----+
3 rows in set (0.00 sec)
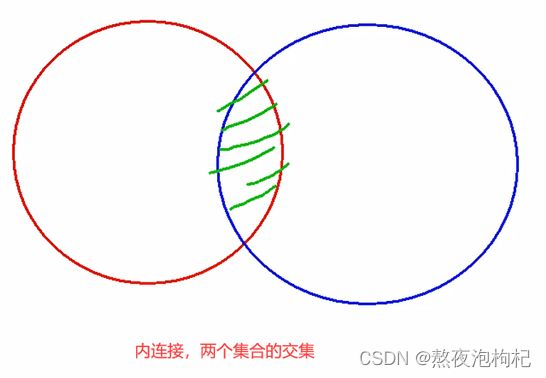
2.2.3 外连接
-- join左边的是左表,join右边的是右表
-- left join : 左表所有数据,右表满足条件的数据(左外连接)
SELECT
city.`Name`,
country.`Name`,
city.`Population`
FROM city
LEFT JOIN country
ON city.`CountryCode` = country.`Code`
AND city.`Population` < 100
ORDER BY city.`Population` DESC;
-- right join:右表所有数据,左表满足条件的数据(右外连接)
简单理解:多表连接实际上是将多张表中,有关联的部分数据,合并成一张新表,在新表中再去做where 、group 、having、 order by、limit
2.3 内连接的使用技巧
内连接的使用技巧(方法)
-- 例子1: 查询人口数量少于100人的城市: 国家名 城市名 城市人口数 国土面积
1. 涉及到的表:
city :
城市名(name)
城市人口数(population)
国家代号(countrycode)
country :
国家名(name)
国土面积(SurfaceArea)
国家代号(Code)
2. 找关联条件
from city
join country
on city.countrycode = country.code
3. 罗列其他查询条件
mysql> SELECT country.`Name`,city.name,city.population,country.`SurfaceArea`
-> FROM city
-> JOIN country
-> ON city.`CountryCode` = country.`Code`
-> WHERE city.`Population`<100;
+----------+-----------+------------+-------------+
| Name | name | population | SurfaceArea |
+----------+-----------+------------+-------------+
| Pitcairn | Adamstown | 42 | 49.00 |
+----------+-----------+------------+-------------+
1 row in set (0.00 sec)
2.4 多表连接查询例子
-- 例子1: 查询一下wuhan这个城市: 国家名 城市名 城市人口数 国土面积
1. 涉及到的表:
city :
城市名(city.name)
城市人口数(city.population)
国家代号(city.countrycode)
country :
国家名(country.name)
国土面积(country.SurfaceArea)
国家代号(country.Code)
from city join country
2. 找关联条件
mysql> desc city;
---> city.CountryCode
mysql> desc country;
---> country.Code
3. 罗列其他查询条件
mysql> SELECT country.`Name`,city.name,city.population,country.`SurfaceArea`
-> FROM city
-> JOIN country
-> ON city.`CountryCode` = country.`Code`
-> WHERE city.`name`='wuhan';
练习题:
--例子1: 统计zhang3,学习了几门课?
1. 找关联表:
student : student.sname
sc : count(sc.cno)
from student join sc
2. 找关联关系
from student join sc
on student.sno=sc.sno
3. 罗列其他条件(考虑重名的情况,所以group by strdent.sno比较严谨)
mysql> select student.sno,student.sname,count(sc.cno)
from student
join sc
on student.sno=sc.sno
where student.sname='zhang3'
group by student.sno,student.sname;
+-----+--------+---------------+
| sno | sname | count(sc.cno) |
+-----+--------+---------------+
| 1 | zhang3 | 2 |
+-----+--------+---------------+
--例子2: 查询zhang3,学习的课程名称有哪些?
1. 找关联表:
student : student.cname
sc :
course : course.cname
from student
join sc
on
join course
on
2. 找关联关系
student : student.sno
sc : sc.sno,sc.cno
course : course.cno
from student
join sc
on student.sno = sc.sno
join course
on sc.cno = course.cno
3. 罗列其他条件
mysql> select student.sno,student.sname,group_concat(course.cname)
from student
join sc
on student.sno = sc.sno
join course
on sc.cno = course.cno
where student.sname='zhang3'
group by student.sno , student.sname;
+-----+--------+----------------------------+
| sno | sname | group_concat(course.cname) |
+-----+--------+----------------------------+
| 1 | zhang3 | python,linux |
+-----+--------+----------------------------+
--例子3: 查询oldguo老师教的学生名.
--例子4: 查询oldguo所教课程的平均分数
--例子5: 每位老师所教课程的平均分,并按平均分排序
--例子6: 查询oldguo所教的不及格的学生姓名
--例子7: 查询所有老师所教学生不及格的信息
--例子8: 查询平均成绩大于60分的同学的学号和平均成绩;
--例子9: 查询所有同学的学号、姓名、选课数、总成绩;
--例子10: 查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分 ***
--例子11: 统计各位老师,所教课程的及格率
--例子12: 查询每门课程被选修的学生数
--例子13: 查询出只选修了一门课程的全部学生的学号和姓名
--例子14: 查询选修课程门数超过1门的学生信息
--例子15: 统计每门课程:优秀(85分以上),良好(70-85),一般(60-70),不及格(小于60)的学生列表 ***
--例子16: 查询平均成绩大于85的所有学生的学号、姓名和平均成绩
2.5 外连接应用
作用: 强制驱动表(增加查询效率)
驱动表是什么?
在多表连接当中,承当for循环中外层循环的角色。
此时,MySQL会拿着驱动表的每个满足条件的关联列的值,去找到循环中的关联值一一进行判断和匹配。
书写建议:(可以增加查询效率)
(1) 多表连接把小表(小的结果集的表,看下面的栗子深度分析)作为驱动表,降低next loop次数(将结果集小的表设置为驱动表更加合适。可以降低next loop(内循环)的次数。)
(2) left join可以强制左表为驱动表(对于内连接来讲,我们是没法控制驱动表是谁,完全由优化器决定。如果需要人为干预,需要将内连接写成外连接的方式。)
强制驱动表的理解:
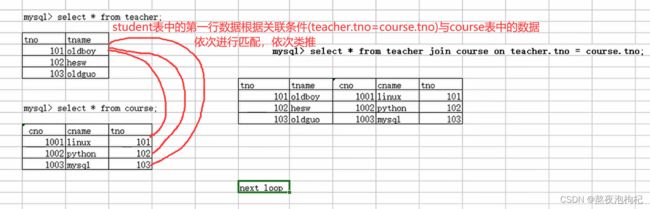
Next loop嵌套循环的多表连接的方法
Teacher表中拿出第一行值与course中的值逐一匹配,直到teacher.tno=course.tno相同,则匹配成功,以此类推。因为teacher拿着值去跟course表中的值进行匹配,所以teacher是强制驱动表
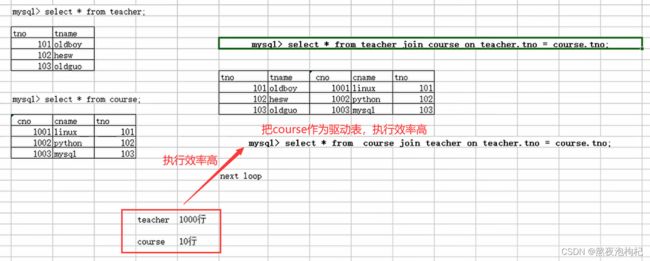
如果teacher表的数据为1000行,course表的数据为10行,把courser作为驱动表,执行效率提高(在join前面加left)。看下面的栗子深度分析更清楚,有where的多表连接,使用强制驱动表增加效率,更好理解为什么增加效率。
小栗子:
-- 下面这两种写法结果相同
mysql> SELECT country.`Name`,city.name,city.population,country.`SurfaceArea`
-> FROM city
-> JOIN country
-> ON city.`CountryCode` = country.`Code`
-> WHERE city.`name`='wuhan';
-- 改写为:强制驱动表的left join
mysql> SELECT country.`Name`,city.name,city.population,country.`SurfaceArea`
-> FROM city LEFT
-> JOIN country
-> ON city.`CountryCode` = country.`Code`
-> WHERE city.`name`='wuhan';
深度解释:
-- city和country的结果集
mysql> select count(*) from world.city;
+----------+
| count(*) |
+----------+
| 4079 |
+----------+
1 row in set (0.13 sec)
mysql> select count(*) from world.country;
+----------+
| count(*) |
+----------+
| 239 |
+----------+
1 row in set (0.00 sec)
-- 如果时下面的语句,因为country表的结果集比city表小,所以选择country作为驱动表。但是这种情况很少。
mysql> SELECT country.`Name`,city.name,city.population,country.`SurfaceArea`
-> FROM city
-> JOIN country
-> ON city.`CountryCode` = country.`Code`
-- 如果时下面的语句,因为是left join先去做where过滤,把wuhan过滤出来(只有一条结果集),然后在和country进行匹配。因为city的结果集小,所以把city作为驱动表(这种情况较多)
mysql> SELECT country.`Name`,city.name,city.population,country.`SurfaceArea`
-> FROM city
-> JOIN country
-> ON city.`CountryCode` = country.`Code`
-> WHERE city.`name`='wuhan';
小提示:
(1) 多表连接时,如果时left join先去做where条件,然后在进行left join的操作。where优先于left join的操作。
(2)多表连接时,如果所有表上都没有索引的情况下,又是内连接的话,先进性join的操作,在进行where的过滤。很多时候也是取决于索引的一些设计,会使得sql执行的方式或者执行的计划发生一些变化。取决于优化的过程,会发生执行的计划发生变化
(3)join左边的是左表,join右边的是右表
(4)left join强制左表作为驱动表 right join强制右表作为驱动表
3. select知识点补充
3.1 别名应用
3.1.1 列别名
mysql> select student.sno,student.sname,group_concat(course.cname)
from student
join sc
on student.sno = sc.sno
join course
on sc.cno = course.cno
where student.sname='zhang3'
group by student.sno , student.sname;
-- 设置列别名,注意:列别名在可以在group by后可以调用(按执行循序来说,因为select之后才可以调用)
-- AS可以省略不写
mysql> select student.sno AS '学号',student.sname AS '姓名',group_concat(course.cname) '课程列表'
from student
join sc
on student.sno = sc.sno
join course
on sc.cno = course.cno
where student.sname='zhang3'
group by student.sno , student.sname;
列别名作用:
(1) 可以定制显示的列名
(2) 可以在having order by 子句中调用
-- 举个例子,设置列别名,having语句调用列别名
SELECT district ,SUM(population)
FROM world.`city`
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 5 OFFSET 0;
-- 设置列别名,having语句调用列别名
SELECT district AS 省,SUM(population) AS 总人口
FROM world.`city`
WHERE countrycode='CHN'
GROUP BY district
HAVING 总人口>5000000
ORDER BY 总人口 DESC
LIMIT 5 OFFSET 0;
3.1.2 表别名
mysql> select student.sno,student.sname,group_concat(course.cname)
from student
join sc
on student.sno = sc.sno
join course
on sc.cno = course.cno
where student.sname='zhang3'
group by student.sno , student.sname;
-- 将表student、sc、 course分别设置别名为a、b、c
mysql> select a.sno,a.sname,group_concat(c.cname)
from student AS a
join sc AS b
on a.sno = b.sno
join course AS c
on b.cno = c.cno
where a.sname='zhang3'
group by a.sno , a.sname;
作用:
全局调用定义的别名
3.2 distinct 应用
作用: 去重
mysql> select distinct(countrycode) from world.city;
3.3 union和union all
-- 例子:查询中国或美国的城市信息;
select * from world.city where countrycode='CHN' or countrycode='USA';
select * from world.city where countrycode in ('CHN','USA');
-- 上面和下面两条sql结果都是一样的,但是执行效率可能不一样
select * from world.city where countrycode='CHN'
union all
select * from world.city where countrycode='USA';
面试题:
union 和 union all 区别
union:聚合两个结果集,会自动进行结果集去重复
union all:聚合两个结果集,不会去重复
4. show 语句介绍
show databases; # 查询所有的库
show tables; # 查询use到库下的所有表明
show tables from world; # 查询world库下的表名
show processlist; # 查询所有用户连接情况
show full processlist; # 查询所有用户连接情况详细信息
show charset; # 查看支持的字符集
show collation; # 查看支持的校对规则
show engines; # 查看支持的引擎信息
show privileges; # 查看支持的权限信息
show grants for # 查看某用户的权限
show create database # 查看建库语句
show create table # 查看建表语句
===============================
show index from # 查看表的索引信息
show engine innodb status; # 查询innodb引擎状态
show status; # 查看数据库状态信息
show status like '%%' # 模糊查询数据库状态
show variables # 查看所有数据库参数
show variables like '%%' # 模糊查询部分参数
show binary logs # 查询所有二进制日志文件信息
show binlog events in # 查询二进制日志事件
show master status # 查询二进制日志的位置点信息
show slave status # 查询从库状态信息
show relaylog events in # 查看中继日志事件
小提示:
-- 查看show相关的命令(show 大多数查询的是元数据范畴的)
mysql> help show
5. information_schema 元数据获取
5.1 元数据介绍
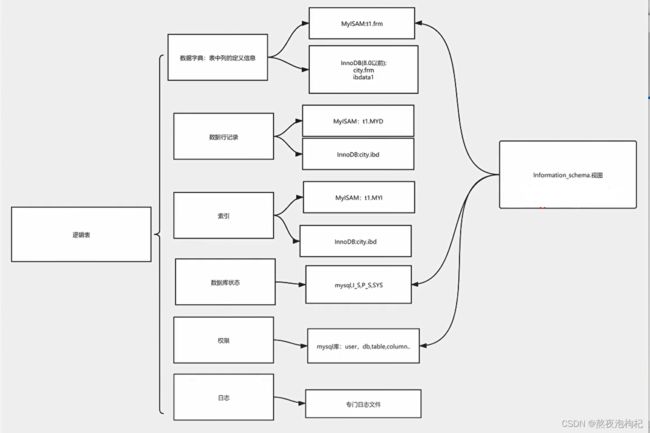
元数据: 下图所示内容,一类是数据行,真实的数据,其他部分都是数据元数据类别。
元数据中数据字典、数据库状态、权限关注比较多
小提示:
(1) 8.0以后 在ibdata1中就没有数据字典信息了
(2)I_S:information_schema.里面有视图的东西(自带的视图)–> 可以帮助我们查询数据字典的信息、数据库状态的信息,权限各方面也能查询到,功能很强,一般作为数据库的诊断时用的挺多,日常的维护工作也会用到它
(3)P_S,SYS属于问题诊断类的
5.2 information_schema介绍
information_schema: 每次数据库启动,会自动在内存中生成I_S,生成查询MySQL部分元数据信息视图。里面有视图的东西(自带的视图),可以帮助我们查询数据字典的信息、数据库状态的信息,权限各方面也能查询到,功能很强,一般作为数据库的诊断时用的挺多,日常的维护工作也会用到它
视图: sql语句的执行方法(封装好的sql语句,起了个别名,直接使用它)。不保存数据本身。I_S中的视图,保存的就是查询元数据的方法。
-- 视图深度理解
SELECT district ,SUM(population)
FROM world.`city`
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 5 OFFSET 0;
+--------------+-----------------+
| district | SUM(population) |
+--------------+-----------------+
| Liaoning | 15079174 |
| Shandong | 12114416 |
| Heilongjiang | 11628057 |
| Jiangsu | 9719860 |
| Shanghai | 9696300 |
+--------------+-----------------+
-- 如果经常要使用上面的语句,sql语句太复杂了,应用上调用太不方便了。
-- 所以上面的sql语句可以定义成一个视图,相当于定义一个别名就是视图了。视图里保存的就是查询的方法
-- 创建v_select视图
CREATE VIEW v_select AS SELECT district ,SUM(population)
FROM world.`city`
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 5 OFFSET 0;
-- 开始调用v_select视图
select * from v_select;
+--------------+-----------------+
| district | SUM(population) |
+--------------+-----------------+
| Liaoning | 15079174 |
| Shandong | 12114416 |
| Heilongjiang | 11628057 |
| Jiangsu | 9719860 |
| Shanghai | 9696300 |
+--------------+-----------------+
5.3 I_S.table常用信息介绍
作用: information_schema.table视图保存了所有表的数据字典信息
-- 进入use information_schema库
mysql> use information_schema;
-- 查看information_schema中的视图
mysql> show tables;
-- 查看table视图的结构(跟查看表方式类似)
mysql> desc tables;
常用的table视图功能
TABLE_SCHEMA # 表所在的库
TABLE_NAME # 表名
ENGINE # 表的引擎
TABLE_ROWS # 表的数据行(不是特别实时)
AVG_ROW_LENGTH # 平均行长度
DATA_LENGTH # 表使用的存储空间大小(不是特别实时)
INDEX_LENGTH # 表的索引占用空间大小
DATA_FREE # 表中是否有碎片
5.4 I_S.table企业应用案例
-- 例子1:数据库资产统计--统计每个库,所有表的个数,表名
SELECT table_schema,COUNT(table_name),GROUP_CONCAT(table_name)
FROM information_schema.`TABLES`
GROUP BY table_schema;
-- 例子2:统计每个库的占用空间总大小(MB为单位)
方法1:(相比方法2准确一点)
一张表大小公式 = AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH
方法2:
一张表大小公式 = DATA_LENGTH
SELECT table_schema,SUM(AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH)/1024/1024
FROM information_schema.`TABLES`
GROUP BY table_schema;
SELECT table_schema,SUM(DATA_LENGTH)/1024/1024
FROM information_schema.`TABLES`
GROUP BY table_schema;
-- 例子3: 查询业务数据库(系统数据库除外),所有非InnoDB表。
SELECT table_schema,table_name
FROM information_schema.`TABLES`
WHERE ENGINE != 'InnoDB'
AND table_schema NOT IN ('sys','performance_schema','information_schema','mysql');
-- 例子4: 查询业务数据库(系统数据库除外),所有非InnoDB表。批量将非InnoDB表转换为InnoDB
SELECT CONCAT("alter table ",table_schema,".",table_name," engine=innodb;" )
FROM information_schema.`TABLES`
WHERE ENGINE != 'InnoDB'
AND table_schema NOT IN ('sys','performance_schema','information_schema','mysql')
INTO OUTFILE '/tmp/alter.sql';
-- 批量将非InnoDB表转换为InnoDB(mysql -uroot -p123456 < /tmp/alter.sql)
mysql> source /tmp/alter.sql
-- INTO OUTFILE '/tmp/alter.sql'将结果集放到/tmp/alter.sql文件里(alter.sql里面都是alter table 库.表 engine=innodb; 格式 ),然后source alter.sql,就可以批量进行修改
-- 关于INTO OUTFILE '/tmp/alter.sql'报错
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
-- 解决: 在my.cnf配置文件中添加
[mysqld]
secure-file-priv=/tmp # 表明这个目录是安全的,INTO OUTFILE '/tmp/alter.sql'可以把结果集,以文件的方式放在/tmp下
[mysql]
socket=/tmp/mysql.sock
-- 重启数据库
[root@db01 database]# /etc/init.d/mysqld restart
Shutting down MySQL..... SUCCESS!
Starting MySQL.. SUCCESS!
小提示:
-- 单表修改引擎
alter table world.myt1 engine innodb;