【tomcat】5、源码解析
- Tomcat系列文章专栏:https://blog.csdn.net/hancoder/category_11180472.html
- 0 sevlet的知识,从上面目录中找
- 1 tomcat的安装与目录结构:https://blog.csdn.net/hancoder/article/details/106765035
- 2 tomcat源码环境搭建: https://blog.csdn.net/hancoder/article/details/113064325
- 4、tomcat架构:https://blog.csdn.net/hancoder/article/details/118466983
- 3 tomcat架构与参数:https://blog.csdn.net/hancoder/article/details/113065917
- 4 tomcat源码分析:https://blog.csdn.net/hancoder/article/details/113062146
- 5 tomcat调优:https://blog.csdn.net/hancoder/article/details/113065948
一、tomcat结构
上篇介绍了tomcat的结构:https://blog.csdn.net/hancoder/article/details/118466983
tomcat由两大部分组成:
- 连接器:处理Socket连接,接收请求,负责网络字节流与Request和Response对象的转化。
- servlet容器:加载和管理Servlet,以及具体处理Request请求。

对应到源码类上的结构为:
介绍过,tomcat里可以有多个service
每个service可以有多个连接器
注意是连接器,不是连接数,连接器获取连接后交给容器,但在这两者内有肯定逻辑

连接器与容器的关系
连接器用于获取连接,由tcp协议封装成http,生成request请求,然后用适配器把request请求转成servlet request请求,交给容器
coyote就是连接器的封装- Coyote 丛林狼,草原狼(犬科动物,分布于北美); 英[kaɪˈəʊti]
catalina就是servlet container容器- 美[ˌkætəˈlinə] 卡特琳娜

二、连接器:Coyote
1、概述
Coyote 是Tomcat的连接器的总称,我们要访问tomcat必须经过连接器。
每个连接器在源码里也被称为protocolHandler(协议处理器),源码中有很多协议处理器,ProtocolHandler只是接口,具体实现类稍后介绍
下面的话随便看看,无所谓的
Coyote 封装了底层的网络通信(Socket 请求及响应处理),为Catalina 容器提供了统一的接口,使Catalina 容器与具体的请求协议及IO操作方式完全解耦。Coyote 将Socket 输入转换封装为 Request 对象,交由Catalina 容器进行处理,处理请求完成后, Catalina 通过Coyote 提供的Response 对象将结果写入输出流 。
Coyote 作为独立的模块,只负责具体协议和IO的相关操作, 与Servlet 规范实现没有直接关系,因此即便是 Request 和 Response 对象也并未实现Servlet规范对应的接口, 而是在Catalina 中将他们进一步封装为
ServletRequest和ServletResponse。
2、IO模型与协议
在Coyote中 , Tomcat支持的多种I/O模型和应用层协议,具体包含哪些IO模型和应用层协议,请看下表:
Tomcat 支持的IO模型
| IO模型 | 描述 |
|---|---|
| BIO | 自8.5/9.0 版本起,已被移除 |
| NIO | 非阻塞I/O,采用Java NIO类库实现。 |
| NIO2 | 异步I/O,采用JDK 7最新的NIO2类库实现。 |
| APR | 采用Apache可移植运行库实现,是C/C++编写的本地库。如果选择该方案,需要单独安装APR库。 |
在 8.0 之前 , Tomcat 默认采用的I/O方式为 BIO , 之后改为 NIO。 无论 NIO、NIO2还是 APR, 在性能方面均优于以往的BIO。 如果采用APR, 甚至可以达到 Apache HTTP Server 的影响性能。
Tomcat 支持的应用层协议 :
| 应用层协议 | 描述 |
|---|---|
| HTTP/1.1 | 这是大部分Web应用采用的访问协议。 |
| AJP | 用于和Web服务器集成(如Apache),以实现对静态资源的优化以及集群部署,当前支持AJP/1.3。 |
| HTTP/2 | HTTP 2.0大幅度的提升了Web性能。下一代HTTP协议 , 自8.5以及9.0版本之后支持。 |
实现类
通过协议和通信方式的组合,我们可以又把连接器分得更细了,也就是Tomcat中有6个实现类
Http11Protocol:11代表是http1.1Http11NioProtocol- Http11Nio2Protocol
- AjpNioProtocol
- AjpAprProtocol
- AjpNio2Protocol
tomcat在默认启动时,也是开启了2个连接器,每个连接器可以设置处理不同的协议。如图

Tomcat为了实现支持多种I/O模型和应用层协议,一个容器可能对接多个连接器,就好比一个房间有多个门。但是单独的连接器或者容器都不能对外提供服务,需要把它们组装起来才能工作,组装后这个整体叫作Service组件。这里请你注意,Service本身没有做什么重要的事情,只是在连接器和容器外面多包了一层,把它们组装在一起。Tomcat内可能有多个Service,这样的设计也是出于灵活性的考虑。通过在Tomcat中配置多个Service,可以实现通过不同的端口号来访问同一台机器上部署的不同应用。
3、连接器组件

0) ProtocolHandler
协议处理器
Connector就是使用ProtocolHandler来处理请求的,它是EndPoint和Process的组合,分别处理TCP/IP和HTTP/AJP协议。
通过两两组合就是前面实现类写的那几个,如Http11Protocol使用的是普通BIO Socket处理HTTP,Http11NioProtocol使用的是NioSocket处理http。
其中ProtocolHandler由包含了三个部件:Endpoint、Processor、Adapter。
(1)Endpoint用来处理底层Socket的网络连接,Processor用于将Endpoint接收到的Socket封装成Request,Adapter用于将Request交给Container进行具体的处理。
(2)Endpoint由于是处理底层的Socket网络连接,因此Endpoint是用来实现TCP/IP协议的,而Processor用来实现HTTP协议的,Adapter将请求适配到Servlet容器进行具体的处理。
(3)Endpoint的抽象实现类AbstractEndpoint里面定义了Acceptor和AsyncTimeout两个内部类和一个Handler接口。
- Acceptor用于监听请求,
- AsyncTimeout用于检查异步Request的超时,
- Handler用于处理接收到的Socket,在内部调用Processor进行处理。
Container是如何进行处理的以及处理完之后是如何将处理完的结果返回给Connector的?

连接器中的各个组件的作用如下:
1) EndPoint与TCP
- EndPoint : Coyote 通信端点,即通信监听的接口,是具体Socket接收和发送处理器,是对传输层(TCP)的抽象,因此EndPoint用来实现TCP/IP协议的。
- Tomcat 并没有EndPoint 接口,而是提供了一个抽象类AbstractEndpoint , 里面定义了两个内部类:
Acceptor和SocketProcessor。- Acceptor用于监听Socket连接请求。
- SocketProcessor用于处理接收到的Socket请求,它实现Runnable接口,在Run方法里调用协议处理组件Processor进行处理。为了提高处理能力,SocketProcessor被提交到线程池来执行。而这个线程池叫作执行器(
Executor),后面会详细介绍
EndPoint的实现类是
- NioEndpoint
- Nio2Endpoint
- APrEndpoint
Tomcat如何扩展原生的Java线程池。
2) Processor与HTTP
EndPoint接收了socket请求会把请求发送给processor。Processor处理HTTP或AJP协议
Processor : Coyote 协议处理接口 ,如果说EndPoint是用来实现TCP/IP协议的,那么Processor用来实现HTTP协议,Processor接收来自EndPoint的Socket,读取字节流解析成Tomcat Request和Response对象,并通过Adapter将其提交到容器处理,
Processor是对应用层协议的抽象。
3) Adapter
由于协议不同,客户端发过来的请求信息也不尽相同,Tomcat定义了自己的ServletRequest类来“存放”这些请求信息。ProtocolHandler接口负责解析请求并生成Request类。但是这个Request对象不是标准的ServletRequest,也就意味着,不能用Request作为参数来调用容器。Tomcat设计者的解决方案是引入CoyoteAdapter,这是适配器模式的经典运用,连接器调用CoyoteAdapter的Sevice方法,传入的是Request对象,CoyoteAdapter负责将Request转成ServletRequest,再调用容器的Service方法。

4、EndPoint详解
其中ProtocolHandler(连接器)又含了三个部件:Endpoint、Processor、Adapter。
Endpoint:用来处理底层Socket的网络连接。- Endpoint的抽象类AbstractEndpoint里面定义的
Acceptor和AsyncTimeout两个内部类和一个Handler接口。 - Acceptor用于监听请求,
- AsyncTimeout用于检查异步Request的超时,
- Handler(某种程度上是poller)用于处理接收到的Socket,在内部调用Processor进行处理。
- Endpoint的抽象类AbstractEndpoint里面定义的
Processor:用于将Endpoint接收到的Socket封装成Request。他是一个线程池,我们每个【发生事件的连接】去线程池里去执行Adapter:线程池里的连接为了去找container,他拿的是request,但是容器接收的是http request,那适配器就转一下- 将Request交给Container进行具体的处理。
5 NIO套娃到连接器
BIO的连接器
在BIO实现的Connector中,处理请求的主要实体是JIoEndpoint对象。JIoEndpoint维护了Acceptor和Worker:
- Acceptor接收socket,然后从Worker线程池中找出空闲的线程处理socket,如果worker线程池没有空闲线程,则Acceptor将阻塞。
- Worker是Tomcat自带的线程池,如果通过
NIO的连接器
在NIO实现的Connector中,处理请求的主要实体是NIoEndpoint对象。NIoEndpoint中除了包含Acceptor和Worker外,还使用了Poller,处理流程如下图所示

Acceptor接收socket后,不是直接使用Worker中的线程处理请求,而是先将请求发送给了Poller,而Poller是实现NIO的关键。Acceptor向Poller发送请求通过队列实现,使用了典型的生产者-消费者模式。在Poller中,维护了一个Selector对象;当Poller从队列中取出socket后,注册到该Selector中;然后通过遍历Selector,找出其中可读的socket,并使用Worker中的线程处理相应请求。与BIO类似,Worker也可以被自定义的线程池代替。
BIO与NIO对比
通过上述过程可以看出,在NIoEndpoint处理请求的过程中,无论是Acceptor接收socket,还是线程处理请求,使用的仍然是阻塞方式;但在“读取socket并交给Worker中的线程”的这个过程中,使用非阻塞的NIO实现,这是NIO模式与BIO模式的最主要区别(其他区别对性能影响较小,暂时略去不提)。而这个区别,在并发量较大的情形下可以带来Tomcat效率的显著提升:
但是BIO线程池的思想是主线程获取到一个连接后,交给线程池去处理,也就是主线程不断accept()阻塞,而每个线程对应一个连接,accept()获取到一个连接后,去线程池里去操作read操作,会阻塞,处理完read等操作后释放连接,这个线程给别的连接用。如果线程池满了,那么将由排队、拒绝策略等操作,那么连接数还是等于线程数
而对于NIO,accept()虽然是阻塞的,但是接收到连接后注册到了selector,selector采用事件机制,连接可以都注册到上面,有了事件才去线程池里处理。因为可以注册很多事件,所以连接数可以大于线程数
目前大多数HTTP请求使用的是长连接(HTTP/1.1默认keep-alive为true),而长连接意味着,一个TCP的socket在当前请求结束后,如果没有新的请求到来,socket不会立马释放,而是等timeout后再释放。如果使用BIO,“读取socket并交给Worker中的线程”这个过程是阻塞的,也就意味着在socket等待下一个请求或等待释放的过程中,处理这个socket的工作线程会一直被占用,无法释放;因此Tomcat可以同时处理的socket数目不能超过最大线程数,性能受到了极大限制。而使用NIO,“读取socket并交给Worker中的线程”这个过程是非阻塞的,当socket在等待下一个请求或等待释放时,并不会占用工作线程,因此Tomcat可以同时处理的socket数目远大于最大线程数,并发性能大大提高。
在这里我要用NIO的知识对应到连接器源码中
我在上篇文章说过bind(addr,backlog)的问题,backlog是阻塞的个数,在源码中叫Accept[backlog]
Acceptor接收socket
Acceptor定义在AbstractEndpoint类中,他实现了Runnable,是个线程
源码中Accept[backlog]什么意思:就是说创建几个线程执行accept(),serverSock.accept();这个逻辑可以在NioEndpoint的子类Acceptor.run()中看到【他继承了AbstractEndpoint中的Acceptor,实现了run()】
学过NIO的都知道他的意思吧,他是接收客户端的socket,然后去读数据。
与之前NIO有点不同的是,我们之前把serversocket注册到了selector,accept()方法也是selector通过事件知道,但tomcat中我看单独线程accept(),接收到后才注册到selector,selector只发送读写事件。
最大队列问题之前解释过了,达到最大连接数后,进去等待队列(这个等待队列有点线程池等待队列的意思,但因为有selector的关系,又感觉不全是)。等待队列满了之后再accept()到连接后,还没注册到selector上了,就阻塞了,不让注册了,直到等待队列空出来。所以说tomcat的最大连接数是maxConnections+maxAcceptors
Poller管理socket
poller对应在NIO中的selector,因为在Poller的构造器中有一句this.selector = Selector.open()
另外poller还是一个线程,实现了Runnable接口,也就是说让每个线程去执行select()操作,负责处理读写事件
从acceptor获取到的socket都注册到selector上,就是注册到了poller上,poller进行select()得到发生事件的key
另外,源码中poller也是有数组的,源码中默认是new Poller[2],对应到前面连接器的不同协议,如HTTP和AJP
processor处理事件
processor就是当select()得到发生事件的key后,比如有多个socket有read事件,我们不能让他们在一个线程里一次执行吧?我们把每个socket.read()放到线程池里执行。
这时候需要包装socket.read()这个操作,把每个任务包装为了processor线程。
processor线程包装的时候,是可以从缓存中拿别人用过的processor对象的。
让processor去线程池里执行processor.doRun(),里面会执行processor.process()
线程池Executor
在service标签中,配置了一个线程池参数,他是多个Poller共享的,也就是多个连接器共享的,然后我们可以自己写executor标签后,让connector标签引用它,这样每个连接器就有了自己的线程池。
三、容器Catalina
Tomcat是一个由一系列可配置的组件构成的Web容器,而Catalina是Tomcat的servlet容器。
Catalina 是Servlet 容器实现,包含了之前讲到的所有的容器组件,以及后续章节涉及到的安全、会话、集群、管理等Servlet 容器架构的各个方面。它通过松耦合的方式集成Coyote,以完成按照请求协议进行数据读写。同时,它还包括我们的启动入口、Shell程序等。
Tomcat 的模块分层结构图, 如下:他跟源码中的包一一对应


Tomcat 本质上就是一款 Servlet 容器, 因此Catalina 才是 Tomcat 的核心 , 其他模块都是为Catalina 提供支撑的。 比如 : 通过Coyote 模块提供链接通信,Jasper 模块提供JSP引擎,Naming 提供JNDI 服务,Juli 提供日志服务。
Catalina 结构
Catalina 的主要组件结构如下:
- Server:Catalina负责管理Server,而Server表示着整个服务器。
- Service:Server下面有多个服务Service,每个服务都包含着多个连接器组件Connector(Coyote 实现)和一个容器组件Container。在Tomcat 启动的时候, 会初始化一个Catalina的实例。

Catalina 各个组件的职责:
| 组件 | 职责 |
|---|---|
| Catalina | 负责解析Tomcat的配置文件 , 以此来创建服务器Server组件,并根据命令来对其进行管理 |
| Server | 服务器表示整个Catalina Servlet容器以及其它组件,负责组装并启动 Servlet引擎,Tomcat连接器。Server通过实现Lifecycle接口,提供了一种优雅的启动和关闭整个系统的方式 |
| Service | 服务是Server内部的组件,一个Server包含多个Service。它将若干个 Connector组件绑定到一个Container(Engine)上 |
| Connector | 连接器,处理与客户端的通信,它负责接收客户请求,然后转给相关的容器处理,最后向客户返回响应结果 |
| Container | 容器,负责处理用户的servlet请求,并返回对象给web用户的模块 |
如下Service的源码,可以获取其中的容器

Container 结构
Tomcat设计了4种容器,分别是Engine、Host、Context和Wrapper。这4种容器不是平行关系,而是父子关系。, Tomcat通过一种分层的架构,使得Servlet容器具有很好的灵活性。
| 容器 | 描述 |
|---|---|
| Engine | 表示整个Catalina的Servlet引擎,用来管理多个虚拟站点,一个Service最多只能有一个Engine,但是一个引擎可包含多个Host |
| Host | 代表一个虚拟主机,或者说一个站点,可以给Tomcat配置多个虚拟主机地址,而一个虚拟主机下可包含多个Context |
| Context | 表示一个Web应用程序, 一个Web应用可包含多个Wrapper |
| Wrapper | 表示一个Servlet,Wrapper 作为容器中的最底层,不能包含子容器 |
可以看看Tomcat的server.xml。Tomcat采用了组件化的设计,它的构成组件都是可配置的,其中最外层的是Server,其他组件按照一定的格式要求配置在这个顶层容器中。
<Server>
<Service>
<Connector/>
<Connector/>
<Engine>
<Host>
<Context>Context>
Host>
Engine>
Service>
Server>
这些容器具有父子关系,形成一个树形结构(设计模式中的组合模式)。没错,Tomcat就是用组合模式来管理这些容器的。具体实现方法是,所有容器组件都实现了Container接口,因此组合模式可以使得用户对单容器对象和组合容器对象的使用具有一致性。这里单容器对象指的是最底层的Wrapper,组合容器对象指的是上面的Context、Host或者Engine。(而调用时使用的是责任链模式)

Container 接口中提供了以下方法(截图中知识一部分方法) :

在上面的接口看到了getParent、SetParent、addChild和removeChild等方法。
Container接口扩展了LifeCycle接口,LifeCycle接口用来统一管理各组件的生命周期
三、线程池Executor
Executor元素代表Tomcat中的线程池,可以由其他组件共享使用;要使用该线程池,组件需要通过executor属性指定该线程池。
Executor是Service元素的内嵌元素。一般来说,使用线程池的是Connector组件;为了使Connector能使用线程池,Executor元素应该放在Connector前面。Executor与Connector的配置举例如下:
<Executor name="tomcatThreadPool" namePrefix ="catalina-exec-" maxThreads="150" minSpareThreads="4" />
<Connector executor="tomcatThreadPool" port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" acceptCount="1000" />
Executor的主要属性包括:
- name:该线程池的标记
- maxThreads:线程池中最大活跃线程数,默认值200(Tomcat7和8都是)
- minSpareThreads:线程池中保持的最小线程数,最小值是25
- maxIdleTime:线程空闲的最大时间,当空闲超过该值时关闭线程(除非线程数小于minSpareThreads),单位是ms,默认值60000(1分钟)
- daemon:是否后台线程,默认值true
- threadPriority:线程优先级,默认值5
- namePrefix:线程名字的前缀,线程池中线程名字为:namePrefix+线程编号
四、查看当前状态
上面介绍了Tomcat连接数、线程数的概念以及如何设置,下面说明如何查看服务器中的连接数和线程数。
查看服务器的状态,大致分为两种方案:(1)使用现成的工具,(2)直接使用Linux的命令查看。
现成的工具,如JDK自带的jconsole工具可以方便的查看线程信息(此外还可以查看CPU、内存、类、JVM基本信息等),Tomcat自带的manager,收费工具New Relic等。下图是jconsole查看线程信息的界面:
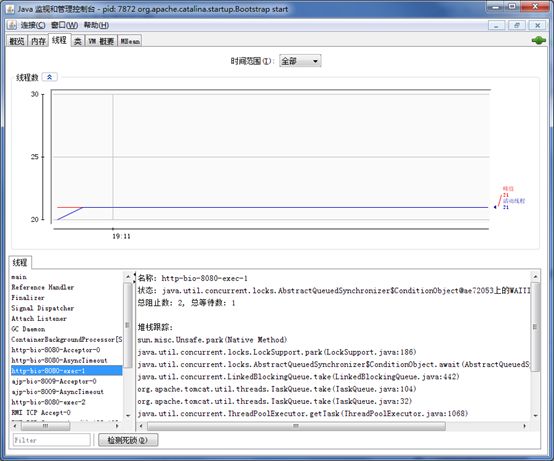
下面说一下如何通过Linux命令行,查看服务器中的连接数和线程数。
四、Tomcat源码

步骤 :
启动tomcat , 需要调用 bin/startup.bat (在linux 目录下 , 需要调用 bin/startup.sh), 在startup.bat 脚本中, 调用了catalina.bat。
在catalina.bat 脚本文件中,调用了BootStrap中的main()方法。
3)在BootStrap 的main 方法中调用了 init方法 , 来创建Catalina 及 初始化类加载器。
4)在BootStrap 的main 方法中调用了 load方法 , 在其中又调用了Catalina的load方法。
5)在Catalina 的load 方法中 , 需要进行一些初始化的工作, 并需要构造Digester 对象, 用于解析 XML。
6) 然后在调用后续组件的初始化操作 。。。
加载Tomcat的配置文件,初始化容器组件 ,监听对应的端口号, 准备接受客户端请求。
Lifecycle接口
由于所有的组件均存在初始化、启动、停止等生命周期方法,拥有生命周期管理的特性, 所以Tomcat在设计的时候, 基于生命周期管理抽象成了一个接口 Lifecycle ,而组件 Server、Service、Container、Executor、Connector 组件 , 都实现了一个生命周期的接口,从而具有了以下生命周期中的核心方法:
-
- init():初始化组件
- 2) start():启动组件
- 3) stop():停止组件
- 4) destroy():销毁组件
各组件的默认实现
上面我们提到的Server、Service、Engine、Host、Context都是接口, 下图中罗列了这些接口的默认实现类。


当前对于 Endpoint组件来说,在Tomcat中没有对应的Endpoint接口, 但是有一个抽象类 AbstractEndpoint,其下有三个实现类:
NioEndpoint:连接器的NIO模型(Tomcat8.5默认)Nio2Endpoint:连接器的NIO2模型AprEndpoint:连接器的APR模型
ProtocolHandler : Coyote协议接口,通过封装Endpoint和Processor ,实现针对具体协议的处理功能。
Tomcat按照协议和IO提供了6个实现类。
AJP协议:
- AjpNioProtocol:采用NIO的IO模型。
- AjpNio2Protocol:采用NIO2的IO模型。
- AjpAprProtocol:采用APR的IO模型,需要依赖于APR库。
HTTP协议:
- Http11NioProtocol:采用NIO的IO模型,(默认)(如果服务器没有安装APR)。
- Http11Nio2Protocol:采用NIO2的IO模型。
- Http11AprProtocol :采用APR的IO模型,需要依赖于APR库。
在init的过程中,init是LigecycleBase实现的,而initInternal是具体子类实现的。模板方法设计模式
源码流程
从哪看起:org.apache.catalina.startup.BootStrap.java ‐‐‐‐>main()
从启动流程图中以及源码中,我们可以看出Tomcat的启动过程非常标准化, 统一按照生命周期管理接口Lifecycle的定义进行启动。首先调用init() 方法进行组件的逐级初始化操作,然后再调用start()方法进行启动。
每一级的组件除了完成自身的处理外,还要负责调用子组件响应的生命周期管理方法,组件与组件之间是松耦合的,因为我们可以很容易的通过配置文件进行修改和替换。
1 Bootstrap主类的流程
- 创建catalina对象
- 解析xml
- 初始化server
- 在初始化server里面初始化多个service
- 依次类推。。。
- 在service里初始化engine、host、context、
- 又去初始化executor
- 又去初始化connector、protocolhandler、endpoint
- endpoint里有
serverSocket.socket().bind()逻辑
- 启动start
2 init
connector.init
- new CoyotaAdapter适配器,被设置到protocolhandler
- protocolhandler.init
- endpoint.init
- endpoint.bind在里面能看到NIO的逻辑
- endpoint.init
3 start
// 调用start方法,一次次调用catalina.start、server、service、engine、host、context... 又去调用executor,connector、protocolHandler
在endpoint最后调用startAcceptorThread()开启接口线程;
// AbstractEndpoint.java
protected final void startAcceptorThreads() {
int count = getAcceptorThreadCount();
// 接收。实现了Runnable。
acceptors = new Acceptor[count];
// 创建accept线程并启动
for (int i = 0; i < count; i++) {
acceptors[i] = createAcceptor();
String threadName = getName() + "-Acceptor-" + i;
acceptors[i].setThreadName(threadName);
// 开启线程,线程里面会调用serverSocket.accept()
Thread t = new Thread(acceptors[i], threadName);
t.setPriority(getAcceptorThreadPriority());
t.setDaemon(getDaemon());
t.start();
}
}
4 endpoint
- startInternal()里面有创建线程池
new ThreadPoolExecutor( - acceptor的run方法是
serverSock.accept();
每个连接器对应一个线程池,连接器指定了端口
appbase是webapps目录
里面包含Acceptor
public void bind(SocketAddress endpoint,//绑定到的IP地址和端口号。 int backlog);//请求进入连接队列的最大长度。 // 将ServerSocket绑定到特定地址(IP地址和端口号)。 如果地址为null ,则系统将接收临时端口和有效的本地地址来绑定套接字。 // backlog参数是套接字上请求的最大挂起连接数。 其确切语义是实现具体的。 特别地,实现可以施加最大长度,或者可以选择忽略参数altogther。 提供的价值应大于0 。 如果小于或等于0 ,则将使用实现特定的默认值。
里面的设计模式:
- 上面多个组件都有init方法,所以tomcat定义了一个Lifecycle接口抽取这些生命周期
- 模板方法模式:LifecycleBase是抽象类,实现了init(),但是init()里面会调用initInternal()方法,initInternal()需要子类实现。
- 适配器模式:转换request和servlet request请求,适配连接器和容器
servlet
直接在webapps里新建目录然后开始注意格式编写
创建servlet,修改web.xml:
为了排序chrome浏览器还会请求一次图标,所以我们用火狐浏览器
Tomcat 请求处理流程
请求流程
设计了这么多层次的容器,Tomcat是怎么确定每一个请求应该由哪个Wrapper容器里的
Servlet来处理的呢?答案是,Tomcat是用Mapper组件来完成这个任务的。
Mapper组件的功能就是将用户请求的URL定位到一个Servlet,它的工作原理是:
Mapper组件里保存了Web应用的配置信息,其实就是容器组件与访问路径的映射关系,比如Host容器里配置的域名、Context容器里的Web应用路径,以及Wrapper容器里
Servlet映射的路径,你可以想象这些配置信息就是一个多层次的Map。
当一个请求到来时,Mapper组件通过解析请求URL里的域名和路径,再到自己保存的Map里去查找,就能定位到一个Servlet。请你注意,一个请求URL最后只会定位到一个Wrapper容器,也就是一个Servlet。
下面的示意图中 , 就描述了 当用户请求链接 http://www.itcast.cn/bbs/findAll 之后, 是如何找到最终处理业务逻辑的servlet
http://www.itcast.cn/bbs/findAll
- www.itcast.cn主机
- bbs项目名
- add对应的servlet

那上面这幅图只是描述了根据请求的URL如何查找到需要执行的Servlet , 那么下面我们再来解析一下 , 从Tomcat的设计架构层面来分析Tomcat的请求处理。
endpoint流程
- 接收请求,解析协议
- 通过管道
- 执行过滤器
- 执行servlet
endpoint接收到请求
accept()到之后,交给poller注册,poller发送事件后交给processor进行read
processKey()在他里面创建成processor线程对象然后提交交给线程池

步骤如下:
- Connector组件Endpoint中的Acceptor监听客户端套接字连接并接收Socket。
- 将连接交给线程池
Executor处理,开始执行请求响应任务。 - Processor组件读取消息报文,解析请求行、请求体、请求头,封装成
Request对象。 - Mapper组件根据请求行的URL值和请求头的Host值匹配由哪个Host容器、Context容器、Wrapper容器处理请求。
- CoyoteAdaptor组件负责将Connector组件和Engine容器关联起来,把生成的Request对象和响应对象Response传递到Engine容器中,调用
Pipeline。 - Engine容器的管道开始处理,管道中包含若干个Valve、每个
Valve负责部分处理逻辑。执行完Valve后会执行基础的 Valve–StandardEngineValve,负责调用Host容器的Pipeline。 - Host容器的管道开始处理,流程类似,最后执行 Context容器的
Pipeline。 - Context容器的管道开始处理,流程类似,最后执行 Wrapper容器的
Pipeline。 - Wrapper容器的管道开始处理,流程类似,最后执行 Wrapper容器对应的Servlet对象的
处理方法。
// HttpService
protected void service(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
String method = req.getMethod();
if (method.equals(METHOD_GET)) {
long lastModified = getLastModified(req);
if (lastModified == -1) {
// servlet doesn't support if-modified-since, no reason
// to go through further expensive logic
doGet(req, resp);
} else {
long ifModifiedSince;
try {
ifModifiedSince = req.getDateHeader(HEADER_IFMODSINCE);
} catch (IllegalArgumentException iae) {
// Invalid date header - proceed as if none was set
ifModifiedSince = -1;
}
if (ifModifiedSince < (lastModified / 1000 * 1000)) {
// If the servlet mod time is later, call doGet()
// Round down to the nearest second for a proper compare
// A ifModifiedSince of -1 will always be less
maybeSetLastModified(resp, lastModified);
doGet(req, resp);
} else {
resp.setStatus(HttpServletResponse.SC_NOT_MODIFIED);
}
}
} else if (method.equals(METHOD_HEAD)) {
long lastModified = getLastModified(req);
maybeSetLastModified(resp, lastModified);
doHead(req, resp);
} else if (method.equals(METHOD_POST)) {
doPost(req, resp);
} else if (method.equals(METHOD_PUT)) {
doPut(req, resp);
} else if (method.equals(METHOD_DELETE)) {
doDelete(req, resp);
} else if (method.equals(METHOD_OPTIONS)) {
doOptions(req,resp);
} else if (method.equals(METHOD_TRACE)) {
doTrace(req,resp);
} else {
//
// Note that this means NO servlet supports whatever
// method was requested, anywhere on this server.
//
String errMsg = lStrings.getString("http.method_not_implemented");
Object[] errArgs = new Object[1];
errArgs[0] = method;
errMsg = MessageFormat.format(errMsg, errArgs);
resp.sendError(HttpServletResponse.SC_NOT_IMPLEMENTED, errMsg);
}
}
请求流程源码解析

在前面所讲解的Tomcat的整体架构中,我们发现Tomcat中的各个组件各司其职,组件之间松耦合,确保了整体架构的可伸缩性和可拓展性,那么在组件内部,如何增强组件的灵活性和拓展性呢? 在Tomcat中,每个Container组件采用责任链模式来完成具体的请求处理。
在Tomcat中定义了Pipeline和 Valve两个接口,Pipeline 用于构建责任链, 后者代表责任链上的每个处理器。Pipeline 中维护了一个基础的Valve,它始终位于Pipeline的末端(最后执行),封装了具体的请求处理和输出响应的过程。当然,我们也可以调用addValve()方法, 为Pipeline 添加其他的Valve, 后添加的Valve 位于基础的Valve之前,并按照添加顺序执行。Pipiline通过获得首个Valve来启动整合链条的执行 。
但是!Pipeline-Valve使用的责任链模式和普通的责任链模式有些不同!区别主要有以下两点:
(1)每个Pipeline都有特定的Valve,而且是在管道的最后一个执行,这个Valve叫做BaseValve,BaseValve是不可删除的;
(2)在上层容器的管道的BaseValve中会调用下层容器的管道。
我们知道Container包含四个子容器,而这四个子容器对应的BaseValve分别在:StandardEngineValve、StandardHostValve、StandardContextValve、StandardWrapperValve。
Pipeline的处理流程图如下(图D):

(1)Connector在接收到请求后会首先调用最顶层容器的Pipeline来处理,这里的最顶层容器的Pipeline就是EnginePipeline(Engine的管道);
(2)在Engine的管道中依次会执行EngineValve1、EngineValve2等等,最后会执行StandardEngineValve,在StandardEngineValve中会调用Host管道,然后再依次执行Host的HostValve1、HostValve2等,最后在执行StandardHostValve,然后再依次调用Context的管道和Wrapper的管道,最后执行到StandardWrapperValve。
(3)当执行到StandardWrapperValve的时候,会在StandardWrapperValve中创建FilterChain,并调用其doFilter方法来处理请求,这个FilterChain包含着我们配置的与请求相匹配的Filter和Servlet,其doFilter方法会依次调用所有的Filter的doFilter方法和Servlet的service方法,这样请求就得到了处理!
(4)当所有的Pipeline-Valve都执行完之后,并且处理完了具体的请求,这个时候就可以将返回的结果交给Connector了,Connector在通过Socket的方式将结果返回给客户端。
Jasper
Jasper 简介
对于基于JSP 的web应用来说,我们可以直接在JSP页面中编写 Java代码,添加第三方的标签库,以及使用EL表达式。但是无论经过何种形式的处理,最终输出到客户端的都是标准的HTML页面(包含js ,css…),并不包含任何的java相关的语法。 也就是说, 我们可以把jsp看做是一种运行在服务端的脚本。 那么服务器是如何将 JSP页面转换为HTML页面的呢?
Jasper模块是Tomcat的JSP核心引擎,我们知道JSP本质上是一个Servlet。Tomcat使用Jasper对JSP语法进行解析,生成Servlet并生成Class字节码,用户在进行访问jsp时,会访问Servlet,最终将访问的结果直接响应在浏览器端 。另外,在运行的时候,Jasper还会检测JSP文件是否修改,如果修改,则会重新编译JSP文件。
JSP 编译方式
运行时编译
Tomcat 并不会在启动Web应用的时候自动编译JSP文件, 而是在客户端第一次请求时,才编译需要访问的JSP文件。
创建一个web项目, 并编写JSP代码 :
3.2.1.1 编译过程
Tomcat 在默认的web.xml 中配置了一个org.apache.jasper.servlet.JspServlet,用于处理所有的.jsp 或 .jspx 结尾的请求,该Servlet 实现即是运行时编译的入口。
JspServlet 处理流程图:

编译结果
如果在 tomcat/conf/web.xml 中配置了参数scratchdir , 则jsp编译后的结果,就会存储在该目录下 。
如果没有配置该选项, 则会将编译后的结果,存储在Tomcat安装目录下的work/Catalina(Engine名称)/localhost(Host名称)/Context名称 。 假设项目名称为jsp_demo 01。
如果使用的是 IDEA 开发工具集成Tomcat 访问web工程中的jsp , 编译后的结果,存放在 :
C:\Users\Administrator.IntelliJIdea2019.1\system\tomcat_project_tomcat\work\Catalina\localhost\jsp_demo_01_war_exploded\org\apache\jsp
3.2.2 预编译
除了运行时编译,我们还可以直接在Web应用启动时, 一次性将Web应用中的所有的JSP页面一次性编译完成。在这种情况下,Web应用运行过程中,便可以不必再进行实时编译,而是直接调用JSP页面对应的Servlet 完成请求处理, 从而提升系统性能。
Tomcat 提供了一个Shell程序JspC,用于支持JSP预编译,而且在Tomcat的安装目录下提供了一个 catalina-tasks.xml 文件声明了Tomcat 支持的Ant任务, 因此,我们很容易使用 Ant 来执行JSP 预编译 。(要想使用这种方式,必须得确保在此之前已经下载并安装了Apache Ant)。
3.3 JSP编译原理
3.3.1 代码分析
编译后的.class 字节码文件及源码 :
编译后的.class 字节码文件及源码 :
public final class index_jsp extends org.apache.jasper.runtime.HttpJspBase
implements org.apache.jasper.runtime.JspSourceDependent,org.apache.jasper.runtime.Js pSourceImports {
private static final javax.servlet.jsp.JspFactory _jspxFactory = javax.servlet.jsp.JspFactory.getDefaultFactory();
private static java.util.Map<java.lang.String,java.lang.Long>
_jspx_dependants;
static {
_jspx_dependants = new java.util.HashMap<java.lang.String,java.lang.Long>(2);
_jspx_dependants.put("jar:file:/D:/DevelopProgramFile/apache‐tomcat‐ 8.5.42‐windows‐x64/apache‐tomcat‐8.5.42/webapps/jsp_demo_01/WEB‐ INF/lib/standard.jar!/META‐INF/c.tld", Long.valueOf(1098682290000L));
_jspx_dependants.put("/WEB‐INF/lib/standard.jar", Long.valueOf(1490343635913L));
}
private static final java.util.Set<java.lang.String>
_jspx_imports_packages;
private static final java.util.Set<java.lang.String>
_jspx_imports_classes;
static {
_jspx_imports_packages = new java.util.HashSet<>();
_jspx_imports_packages.add("javax.servlet");
_jspx_imports_packages.add("javax.servlet.http");
_jspx_imports_packages.add("javax.servlet.jsp");
_jspx_imports_classes = new java.util.HashSet<>();
_jspx_imports_classes.add("java.util.Date");
_jspx_imports_classes.add("java.text.SimpleDateFormat");
_jspx_imports_classes.add("java.text.DateFormat");
}
private volatile javax.el.ExpressionFactory _el_expressionfactory;
private volatile org.apache.tomcat.InstanceManager
_jsp_instancemanager;
public java.util.Map<java.lang.String,java.lang.Long>getDependants() { return _jspx_dependants;
}
public java.util.Set<java.lang.String>getPackageImports() { return _jspx_imports_packages;
}
public java.util.Set<java.lang.String>getClassImports() { return _jspx_imports_classes;
}
public javax.el.ExpressionFactory _jsp_getExpressionFactory() { if (_el_expressionfactory == null) {
synchronized (this) {
if (_el_expressionfactory == null) {
_el_expressionfactory =
_jspxFactory.getJspApplicationContext(getServletConfig().getServletContex t()).getExpressionFactory();
}
}
}
return _el_expressionfactory;
}
public org.apache.tomcat.InstanceManager _jsp_getInstanceManager() { if (_jsp_instancemanager == null) {
synchronized (this) {
if (_jsp_instancemanager == null) {
_jsp_instancemanager = org.apache.jasper.runtime.InstanceManagerFactory.getInstanceManager(getSe rvletConfig());
}
}
}
return _jsp_instancemanager;
}
public void _jspInit() {
}
public void _jspDestroy() {
}
public void _jspService(final javax.servlet.http.HttpServletRequest request, final javax.servlet.http.HttpServletResponse response)
throws java.io.IOException, javax.servlet.ServletException {
final java.lang.String _jspx_method = request.getMethod();
if (!"GET".equals(_jspx_method) && !"POST".equals(_jspx_method) &&
!"HEAD".equals(_jspx_method) &&
!javax.servlet.DispatcherType.ERROR.equals(request.getDispatcherType()))
{
response.sendError(HttpServletResponse.SC_METHOD_NOT_ALLOWED, "JSPs only permit GET POST or HEAD");
return;
}
final javax.servlet.jsp.PageContext pageContext; javax.servlet.http.HttpSession session = null; final javax.servlet.ServletContext application; final javax.servlet.ServletConfig config; javax.servlet.jsp.JspWriter out = null;
final java.lang.Object page = this; javax.servlet.jsp.JspWriter _jspx_out = null; javax.servlet.jsp.PageContext _jspx_page_context = null;
try {
response.setContentType("text/html;charset=UTF‐8");
pageContext = _jspxFactory.getPageContext(this, request, response, null, true, 8192, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext(); config = pageContext.getServletConfig(); session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;
out.write("\n");
out.write("\n");
out.write("\n");
out.write("\n");
out.write("\n"); out.write("\n"); out.write(" \n");
out.write(" $Title$ \n"); out.write(" \n");
out.write(" \n"); out.write(" ");
DateFormat dateFormat = new SimpleDateFormat("yyyy‐MM‐dd HH:mm:ss");
String format = dateFormat.format(new Date());
out.write("\n");
out.write(" Hello , Java Server Page 。。。。\n"); out.write("\n");
out.write("
\n"); out.write("\n");
out.write(" "); out.print( format ); out.write("\n");
out.write("\n"); out.write(" \n"); out.write("\n");
} catch (java.lang.Throwable t) {
if (!(t instanceof javax.servlet.jsp.SkipPageException)){ out = _jspx_out;
if (out != null && out.getBufferSize() != 0) try {
if (response.isCommitted()) { out.flush();
} else { out.clearBuffer();
}
} catch (java.io.IOException e) {} if (_jspx_page_context != null)
_jspx_page_context.handlePageException(t); else throw new ServletException(t);
由编译后的源码解读, 可以分析出以下几点 :
1) 其类名为 index_jsp , 继承自 org.apache.jasper.runtime.HttpJspBase , 该类是
HttpServlet 的子类 , 所以jsp 本质就是一个Servlet 。
2) 通过属性 _jspx_dependants 保存了当前JSP页面依赖的资源, 包含引入的外部的JSP页面、导入的标签、标签所在的jar包等,便于后续处理过程中使用(如重新编译检测,因此它以Map形式保存了每个资源的上次修改时间)。
3) 通过属性 _jspx_imports_packages 存放导入的 java 包, 默认导入 javax.servlet ,
javax.servlet.http, javax.servlet.jsp 。
4) 通过属性 _jspx_imports_classes 存放导入的类, 通过import 指令导入的
DateFormat 、SimpleDateFormat 、Date 都会包含在该集合中。
_jspx_imports_packages 和 _jspx_imports_classes 属性主要用于配置 EL 引擎上下文
。
5) 请求处理由方法 _jspService 完成 , 而在父类 HttpJspBase 中的service 方法通过模板方法模式 , 调用了子类的 _jspService 方法。
1) _jspService 方法中定义了几个重要的局部变量 : pageContext 、Session、
application、config、out、page。由于整个页面的输出有 _jspService 方法完成,因此这些变量和参数会对整个JSP页面生效。 这也是我们为什么可以在JSP页面使用这些变量的原因。
2) 指定文档类型的指令 (page) 最终转换为 response.setContentType() 方法调用。
3) 对于每一行的静态内容(HTML) , 调用 out.write 输出。
1) 对于 <% … %>中的java 代码 , 将直接转换为 Servlet 类中的代码。 如果在 Java代码中嵌入了静态文件, 则同样调用 out.write 输出。
3.3.1 编译流程
JSP 编译过程如下:
Compiler 编译工作主要包含代码生成 和 编译两部分 :代码生成
1) Compiler 通过一个 PageInfo 对象保存JSP 页面编译过程中的各种配置,这些配置可能来源于 Web 应用初始化参数, 也可能来源于JSP页面的指令配置(如 page ,
include)。
2) 调用ParserController 解析指令节点, 验证其是否合法,同时将配置信息保存到
PageInfo 中, 用于控制代码生成。
3) 调用ParserController 解析整个页面, 由于 JSP 是逐行解析, 所以对于每一行会创建一个具体的Node 对象。如 静态文本(TemplateText)、Java代码(Scriptlet)、定制标签(CustomTag)、Include指令(IncludeDirective)。
4) 验证除指令外其他所有节点的合法性, 如 脚本、定制标签、EL表达式等。
5) 收集除指令外其他节点的页面配置信息。
6) 编译并加载当前 JSP 页面依赖的标签
7) 对于JSP页面的EL表达式,生成对应的映射函数。
8) 生成JSP页面对应的Servlet 类源代码编译代码生成完成后, Compiler 还会生成 SMAP 信息。 如果配置生成 SMAP 信息,
Compiler 则会在编译阶段将SMAP 信息写到class 文件中 。
在编译阶段, Compiler 的两个实现 AntCompiler 和 JDTCompiler 分别调用先关框架的API 进行源代码编译。
对于 AntCompiler 来说, 构造一个 Ant 的javac 的任务完成编译。
对于 JDTCompiler 来说, 调用 org.eclipse.jdt.internal.compiler.Compiler 完成编译
websocket
websocket是HTML5新增的协议,它的目的是在浏览器和服器之间建立一个不受限的双向通信的通道,比如说。服箬器可以在任意时刻发送消息给浏览器。
为什么传统的http协议不能做到websocket实现的功能?这是因为http协议是一个请求-响应协议,请求必须先由浏览器发给服务器,服务器才能响应这个清求,再把数据发送给浏览器。换句话说,浏览器不主动话求,服务器是没法主动发数据名浏览器的。
这样一来,要在浏览器中搞一个实时聊天,或者在线多人游戏的话就没法实现了,只能借助flash这些插件。也有人说,http协议实也能实现啊,比如用轮询或者comet。轮询是指浏览器通过js启动一个定时器,然后以固定的间隔给服务器发请求,询问服务器有没有新港息。这个机制的骁点一是实时性不够,一是频繁的求会给报务器带来极大的压力。
comet本质上也是轮询,但是在没有消息的情况下,服务器先拖一段时间,等到有消息了再回复。这个机制暫时地解决了实时性问题,但是它带来了新的问题:以多线程式运行的服器会让大部分线程大部分时间都处于扌圭起状态,极大地浪报箬器资源。另外,一个http连接在长时间没有数据传输的情况下,链路上的任何一个网关都可能关闭这个连接,而网矢是我们不可控的,这就要求comet连接必须定期发一些ping数据表示连接”正常工作“。
websocket不是全新的协议,而是利用了HTTP协议来建立连接。
websocket必须由浏览器发起,因为请求协议是一个标准的HTTP请求,ws://localhost:8080
connection:upgrade
upgrade:websocket
伴随着HTML5推出的WebSocket,真正实现了Web的实时通信,使B/S模式具备了C/S模式的实时通信能力。WebSocket的工作流程是这 样的:浏览器通过JavaScript向服务端发出建立WebSocket连接的请求,在WebSocket连接建立成功后,客户端和服务端就可以通过 TCP连接传输数据。因为WebSocket连接本质上是TCP连接,不需要每次传输都带上重复的头部数据,所以它的数据传输量比轮询和Comet技术小 了很多。本文不详细地介绍WebSocket规范,主要介绍下WebSocket在Java Web中的实现。
JavaEE 7中出了JSR-356:Java API for WebSocket规范。不少Web容器,如Tomcat,Nginx,Jetty等都支持WebSocket。Tomcat从7.0.27开始支持 WebSocket,从7.0.47开始支持JSR-356,下面的Demo代码也是需要部署在Tomcat7.0.47以上的版本才能运行。
- 第一种是编程式,即继承类
javax.websocket.Endpoint - 第二种是注解式,朗定义一个POJO并添加
@ServerEndpoint相关注解。
依赖
fastjson tomcat-websocket websocket-api
tomcat中有上面的包
<dependency>
<groupId>javax.servletgroupId>
<artifactId>javax.servlet-apiartifactId>
<version>3.1.0version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-webmvcartifactId>
<version>4.1.5.RELEASEversion>
dependency>
<dependency>
<groupId>jstlgroupId>
<artifactId>jstlartifactId>
<version>1.2version>
dependency>
<dependency>
<groupId>taglibsgroupId>
<artifactId>standardartifactId>
<version>1.1.2version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-messagingartifactId>
<version>4.1.7.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-websocketartifactId>
<version>4.1.7.RELEASEversion>
dependency>
<dependency>
<groupId>javax.websocketgroupId>
<artifactId>javax.websocket-apiartifactId>
<version>1.0version>
<scope>providedscope>
dependency>
@ServerEndpoint
package me.gacl.websocket;
import java.io.IOException;
import java.util.concurrent.CopyOnWriteArraySet;
import javax.websocket.*;
import javax.websocket.server.ServerEndpoint;
/**
@ServerEndpoint 注解是一个类层次的注解,
它的功能主要是将目前的类定义成一个websocket服务器端,
注解的值将被用于监听用户连接的终端访问URL地址,客户端可以通过这个URL来连接到WebSocket服务器端
*/
@ServerEndpoint("/websocket")
public class WebSocketTest {
//静态变量,用来记录当前在线连接数。应该把它设计成线程安全的。
private static AtomicInteger onlineCount = 0;
// 线程安全Set,用来存放每个客户端对应的MyWebSocket对象。
// 若要实现服务端与单一客户端通信的话,可以使用Map来存放,其中Key可以为用户标识
private static CopyOnWriteArraySet<WebSocketTest> webSocketSet = new CopyOnWriteArraySet<WebSocketTest>();
// Map页面
配置类
registerWebSocketHandlers:这个方法是向spring容器注册一个handler地址,我把他理解成requestMapping
addInterceptors:拦截器,当建立websocket连接的时候,我们可以通过继承spring的HttpSessionHandshakeInterceptor来搞事情。
setAllowedOrigins:跨域设置,*表示所有域名都可以,不限制, 域包括ip:port, 指定*可以是任意的域名,不加的话默认localhost+本服务端口
withSockJS: 这个是应对浏览器不支持websocket协议的时候降级为轮询的处理。
@Configuration
@EnableWebSocket
public class SpringWebSocketConfig implements WebSocketConfigurer {
public void registerWebSocketHandlers(WebSocketHandlerRegistry registry) {
// 注册拦截器
registry.addHandler(webSocketHandler(),"/websocket/socketServer")
.addInterceptors(new SpringWebSocketHandlerInterceptor()).setAllowedOrigins("*");
// 注册拦截器
registry.addHandler(webSocketHandler(), "/sockjs/socketServer").setAllowedOrigins("http://localhost:28180")
.addInterceptors(new SpringWebSocketHandlerInterceptor()).withSockJS();
}
// 注入handler
@Bean
public TextWebSocketHandler webSocketHandler(){
return new SpringWebSocketHandler();
}
}
这个是创建websocket连接是的拦截器,记录建立连接的用户的session以便根据不同session来通信
每个客户端在握手的时候都会创建endpoint实例
public class SpringWebSocketHandlerInterceptor
extends HttpSessionHandshakeInterceptor {
@Override
public boolean beforeHandshake(ServerHttpRequest request, ServerHttpResponse response,
WebSocketHandler wsHandler,
Map<String, Object> attributes) throws Exception {
System.out.println("Before Handshake");
if (request instanceof ServletServerHttpRequest) {
ServletServerHttpRequest servletRequest = (ServletServerHttpRequest) request;
HttpSession session = servletRequest.getServletRequest().getSession(false);
if (session != null) {
//使用userName区分WebSocketHandler,以便定向发送消息
String userName = (String) session.getAttribute("SESSION_USERNAME"); //一般直接保存user实体
if (userName!=null) {
attributes.put("WEBSOCKET_USERID",userName);
}
}
}
return super.beforeHandshake(request, response, wsHandler, attributes);
}
@Override
public void afterHandshake(ServerHttpRequest request,
ServerHttpResponse response,
WebSocketHandler wsHandler,
Exception ex) {
super.afterHandshake(request, response, wsHandler, ex);
}
}
boot下的websocket
自动配置
给内嵌Tomcat, Jetty or Undertow的websocket servlet自动配置
需要在类路径下放置相关websocket的模块
如果tomcat的WebSocket支持在类路径下被检测到,我们添加一个customizer,这个东西安装了tomcat websocket initializer初始化器
同理,如果Jetty的websocket模块被检测到,。。。。
同理Undertow。。。
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ Servlet.class, ServerContainer.class })
@ConditionalOnWebApplication(type = Type.SERVLET)
@AutoConfigureBefore(ServletWebServerFactoryAutoConfiguration.class)
public class WebSocketServletAutoConfiguration {
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ Tomcat.class, WsSci.class })
static class TomcatWebSocketConfiguration {
@Bean
@ConditionalOnMissingBean(name = "websocketServletWebServerCustomizer")
TomcatWebSocketServletWebServerCustomizer websocketServletWebServerCustomizer() {
return new TomcatWebSocketServletWebServerCustomizer();
}
}
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(WebSocketServerContainerInitializer.class)
static class JettyWebSocketConfiguration {
@Bean
@ConditionalOnMissingBean(name = "websocketServletWebServerCustomizer")
JettyWebSocketServletWebServerCustomizer websocketServletWebServerCustomizer() {
return new JettyWebSocketServletWebServerCustomizer();
}
}
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(io.undertow.websockets.jsr.Bootstrap.class)
static class UndertowWebSocketConfiguration {
@Bean
@ConditionalOnMissingBean(name = "websocketServletWebServerCustomizer")
UndertowWebSocketServletWebServerCustomizer websocketServletWebServerCustomizer() {
return new UndertowWebSocketServletWebServerCustomizer();
}
}
}