c++高级编程学习笔记4
C++运算符重载
运算符重载概述
根据第 1 章的描述,C++中的运算符是一些类似于+、<、*和<<的符号。这些运算符可应用于内建类型,例如 int 和 double,从而实现算术操作、逻辑操作和其他操作。还有->和*运算符可对指针进行解除引用操作。C++中运算符的概念十分广泛,甚至包含、(0)(函数调用)、类型转换以及内存分配和内存释放例程。
重载运算符的原因
在学习重载运算符前,首先需要了解为什么需要重载运算符。不同的运算符有不同的理由,但是基本指导原则是为了让自定义类的行为和内建类型一样。自定义类的行为越接近内建类型,就越便于这些类的客户使用。例如,如果要编写一个表示分数的类,最好定义+、- 、*和/运算符在应用于这个类的对象时的意义。
重载运算符的另一个原因是为了获得对程序行为更大的控制权。例如,可对自定义类重载内存分配和内存释放例程,以精确控制每个新对象的内存分配和内存回收。需要强调的一点是,运算符重载未必能给类的开发者带来便利;主要用途是给类的客户带来便利。
运算符重载的限制
下面列出了重载运算符时不能做的事情:不能添加新的运算符。只能重定义语言中已经存在的运算符的意义。后面的表 15-1 列出了所有可重载的运算符。
e 有少数运算符不能重载,例如.(对象成员访问运算符)、::(作用域解析运算符)、sizeof、?:(条件运算符)以及其他几个运算符。表 15-1 列出了所有可重载的运算符。不能重载的运算符通常是不需要重载的,因此这些限制应该不会令人感到受限。
e arity 描述了运算符关联的参数或操作数的数量。只能修改函数调用、new 和 delete 运算符的 arity。其他运算符的 arity 不能修改。一元运算符,例如++,只能用于一个操作数。二元运算符,例如/,只能用于两个操作数。这条限制会带来麻烦的主要情形是的重载,详见本章后面的讨论。e 不能修改运算符的优先级和结合性。这些规则确定了运算符在语句中的求值顺序。同样,这条限制对于大多数程序来说不是问题,因为改变求值顺序并不会带来什么好处。
e 不能对内建类型重定义运算符。运算符必须是类中的一个方法,或者全局重载运算符函数至少有一个参数必须是一种用户定义的类型(例如一个类)。这意味着不允许做一些荒唐的事情,例如将 int 类型的+运算符重定义为减法(尽管自定义的类可以这么做)。这条限制有一个例外,那就是内存分配和内存释放运算符,可蔡换程序中所有内存分配使用的全局运算符。有些运算符已经有两种不同的含义。例如,- 运算符可用作二元运算符,例如x = y- z,还可用作一元运算符,如 x = - y。*运算符可用作乘法操作,也可以用于解除指针的引用。根据上下文的不同,<<可以是插入运算符,也可以是左移运算符。可以重载具有双重意义的运算符。
运算符重载的选择
重载运算符时,需要编写名为 operatorX 的函数或方法,X 是表示这个运算符的符号,可以在 operator 和和之间添加空白字符。例如,第 8 章声明了 SpreadsheetCell 对象的 operator+运算符,如下所示:
SpreadsheetCell operator+(const SpreadsheetCell& lhs,const SpreadsheetCell& rhs);
下面描述了编写每个重载运算符函数或方法时需要做出的选择。
- 方法还是全局函数
首先,要决定运算符应该实现为类的方法还是全局函数(通常是类的友元)。如何做出选择? 你需要理解这两个选择之间的区别。当运算符是类的方法时,运算符表达式的左侧必须是这个类的对象。当编写全局函数时,运算符表达式的左侧可以是不同类型的对象。有 3 种不同类型的运算符;
e 必须为方法的运算符: C++语言要求一些运算符必须是类中的方法,因为这些运算符在类的外部没有意义。例如,operator=和类绑定得非常紧密,不能出现在其他地方。后面的表 15-1 列出了所有必须为方法的运算符。大部分运算符都没有施加这种要求。
e 必须为全局函数的运算符: 如果人允许运算符左侧的变量是除了自定义的类之外的任何类型,那么必须将这个运算符定义为全局函数。确切地讲,这条规则适用于 operator<<和 operator>>,这两个运算符的左侧是 iostream 对象,而不是自定义类的对象。此外,可交换的运算符(例如二元的+和 - )允许运算符左侧的变量不是自定义类的对象。第 9 章曾提及这个问题。
e 既可为方法又可为全局函数的运算符,有关编写方法重载运算符更好还是编写全局函数重载运算符更好的问题在 C++社区中有一些争议。不过建议遵循如下规则: 把所有运算符都定义为方法,除非根据以上描述必须定义为全局函数。这条规则的一个主要优点是,方法可以是虚方法,但全局函数不能是虚函数。因此,如果准备在继承树中编写重载的运算符,应尽可能将这些运算符定义为方法。
将重载的运算符定义为方法时,如果这个运算符不修改对象,应将整个方法标记为 const。这样,就可对const 对象调用这个方法。
-
选择参数类型
参数类型的选择有一些限制,因为如前所述,大多数运算符不能修改参数数量。例如,operator/在作为全局函数的情况下必须总是接收两个参数; 在作为类方法的情况下必须总是接收一个参数。如果不遵循这条规则,编译器会生成错误。从这个角度看,运算符函数和普通函数有区别,普通函数可使用任意数量的参数重载。此外,尽管可编写接收任何类型参数的运算符,但可选范围通常都受这个运算符所在的类的限制。例如,如果要为类工实现加法操作,就不能编写接收两个字符串的 operator+。真正需要选择的地方在于判断是按值还是按引用接收参数,以及是否需要把参数标记为 const。
按值传递还是按引用传递的决策很简单: 应按引用接收每一个非基本类型的参数。根据第 9 章和第 11 章的解释,如果能按引用传递,就永远不要按值传递对象。
const 决策也很简单: 除非要真正修改参数,否则将每个参数都设置为 const。后面的表 15-1 列出了所有运算符的示例原型,并根据需要将参数标记为 const 和引用。
引用和 const 决策也适用于返回类型。不过对返回值来说,这些决策要更困难一些。值还是引用的一般原则是: 如果可以,就返回一个引用,和否则返回一个值。如何判断何时能返回引用? 这个决策只能应用于返回对象的运算符: 对于返回布尔值的比较运算符、没有返回类型的转换运算符和函数调用运算符(可能返回所需的任何类型)来说,这个决策没有意义。如果运算符构造了一个新对象,那么必须按值返回这个新对象。如果不构造新对象, 可返回对调用这个运算符的对象的引用, 或返回对其中一个参数的引用。后面的表 15-1 中给出了示例。可作为左值(赋值表达式左侧的部分)修改的返回值必须是非 const。和否则,这个值应该是 const。大部分很容易想到的运算符都要求返回左值,包括所有赋值运算符(operator=、operator-=和 operator-=等)。
- 选择行为
在重载的运算符中,可提供任意需要的实现。例如,可编写一个启动 Serabble 拼字游戏的 operator+。然而根据第 6 章的描述,通常情况下,应将实现约束为客户期待的行为。编写 operator+时,使这个运算符能执行加法或其他类似加法的操作,例如字符串串联。这一章讲解应该如何实现重载的运算符。在特殊情况下,可以不采用这些建议,但一般情况下都应该遵循这些标准模式。
不应重载的运算符
有些运算符即使允许重载,也不应该重载。具体来说,取地址运算符(operator&)的重载一般没什么特别的用途,如果重载会导致混乱,因为这样做会以可能异常的方式修改基础语言的行为(获得变量的地址)。整个标准库大量使用了运算符重载,但从没有重载取地址运算符。
此外,还要避免重载二元布尔运算符 operator&&和 operator||,因为这样会使 C++的短路求值规则失效。最后, 不要重载逗号运算符。没错, C++中确实有一个逗号运算符, 也称为序列运算符(sequencing operaton),用于分隔一条语句中的两个表达式,确保求值顺序从左至右。几乎没有什么正当理由需要重载这个运算符。
-
可重载运算符小结
表 15-1 列出了所有可重载的运算符, 标明了运算符应该是类的方法还是全局函数, 总结了什么时候应该(或不应该)重载,并提供了示例原型,展示了正确的返回值。如果需要编写重载运算符,这个表是很好的参考资源。你肯定会忘了应该使用哪种返回类型,以及应该使用函数还是方法。
在表 15-1 中,T表示要编写重载运算符的类名,E 是一种不同的类型。注意给出的示例原型并不全面,给定的运算符常常可能有T和的其他组合。
| 运算符 | 名称和类别 | 方法还是全局函数 | 何时重载 | 实例原型 |
|---|---|---|---|---|
| operator+ | 二元算术运算符 | 建议使用全局函数 | 类需要提供这些操作时 | T operator+(const T&, const T&); T operator+(const T&, const E&); |
| operator- | ||||
| operator* | ||||
| operator/ | ||||
| operator% | ||||
| operator- | 一元算术运算符和按 位运算符 | 建议使用方法 | 类需要提供这些操作时 | T operator-() const; |
| operator+ | ||||
| operator~ | ||||
| operator++ | 前缀递增运算符 | 建议使用方法 | 重载了+=和-=时 | T& operator++(); |
| operator– | 前缀递减运算符 | |||
| operator++ | 后缀递增运算符 | 建议使用方法 | 重载了+=和-=时 | T operator++(int); |
| operator– | 后缀递减运算符 | |||
| operator= | 赋值运算符 | 必须使用方法 | 在类中动态分配了内存或资源,或者成员的引用时 | T& operator=(const T&); |
| operator+= | 算术运算符赋值的简写 | 建议使用方法 | 重载了二元算术运算符, 并 且类没有设计为不可变时 | T& operator+=(const T&);T& operator+=(const E&); |
| operator-= | ||||
| operator*= | ||||
| operator/= | ||||
| operator%= | ||||
| operator<< | 二元按位运算符 | 建议使用全局函数 | 需要提供这些操作时 | T operator<<(const T&,const T&); T operator<<(const T&,const E&); |
| operator>> | ||||
| operator& | ||||
| operator| | ||||
| operator^ | ||||
| operator< | 二元比较运算符 | 建议使用全局函数 | 需要提供这些操作时 | bool operator<(const T&, const T&); bool operator<(const T&, const E&); |
| operator> | ||||
| operator<= | ||||
| operator>= | ||||
| operator== | ||||
| operator!= | ||||
| operator<< | I/O 流运算符(插入操作和提取操作) | 建议使用全局函数 | 需要提供这些操作时 | ostream& operator<<(ostream&,const T&); istream& operator>>(istream&,T&); |
| operator! | 布尔非运算符 | 建议使用成员函数 | 很少重载; 应该改用 bool 或 void*类 | bool operator!() const; |
| operator&& | 二元布尔运算符 | 建议使用全局函数 | 很少重载,否则会失去短路能力。更好的做法是重载&和| 因为它们从不出现短路 | bool operator&&(const T&,const T&); |
| operator[] | 下标(数组索引)运算 | 必须使用方法 | 需要支持下标访问时 | E& operator[](size_t); |
| operator() | 函数调用运算符 | 必须使用方法 | 需要让对象的行为和函数指针一致时,或者是多维数 组访问,因为[]只能有一个索引 | 返回类型和参数可以多种多样,参 |
| operator type() | 转换(或强制类型转换)运算符(每种类 型有不同的运算符) | 必须使用方法 | 需要将自己编写 | operator type() const; |
| operator new | 内存分配例程 | 建议使用方法 | 需要控制类的内存分配时 (很少见) | void operator new(size_t size); |
| operator new[] | void operator new[] (size_t size); | |||
| operator delete | 内存释放例程 | 建议使用方法 | 重载了内存分配例程时(很少见) | void operator delete(void* ptr) noexcept; |
| operator delete[] | void operator delete[] (void* ptr) noexcept; | |||
| operator* | 解除引用运算符 | 对于 operator*建议使用方法 | 适用于智能指针 | E& operator*() const; |
| operator-> | 对于 operator->必须使用方法 | E& operator->() const; | ||
| operator& | 不可用 | |||
| operator->* | 不可用 | |||
| operator, | 不可用 |
右值引用
第 9 章讨论了右值rvalue)引用,和普通左值(value)引用的&不同,记为&&。第 9 章通过定义移动赋值运算符演示了这些概念,当第二个对象是赋值后需要销毁的临时对象时,编译器会使用移动赋值运算符。表 15-1列出的普通赋值运算符的原型如下所示:
T& operator=(const T&);
移动赋值运算符的原型几乎一致,但使用了右值引用。这个运算符会修改参数,因此不能传递 const 参数。第 9 章详细讨论了这些内容:
T& oprator=(T&&);
表 15-1 没有包含右值引用语义的示例原型。然而,对于大部分运算符来说,编写一个使用普通左值引用的版本以及一个使用右值引用的版本都是有意义的,但是否真正有意义取决于类的实现细节。operator-是第 9 章的一个例子。另一个例子是通过 operator+避免不必要的内存分配。例如标准库中的 std::string 类利用右值引用实现了 operator+,如下所示(已简化):
string operator+(string&& lhs,string&& rhs);
这个运算符的实现会重用其中一个参数的内存,因为这些参数是以右值引用传递的。也就是说,这两个参数表示的都是 operator+完成之后销毁的临时对象。上述 operator+的实现具有以下效果(具体取决于两个操作数的大小和容量):
return std::move(lhs.append(rhs));
或
return std::move(rhs.insert(0,lhs));
事实上,std::string 定义了几个具有不同左值引用和右值引用组合的重载的 operator+运算符。下面列出std::string 中所有接收两个字符串参数的 operator+运算符(已经简化):
string operator+(const string& lhs,const string& rhs);
string operator+(string&& lhs,const string& rhs);
string operator+(const string& lhs, string&& rhs);
string operator+(string&& lhs,string&& rhs);
这些函数模板根据= =和<运算符给任意类定义了运算符二、>、<=和>=。如果在类中实现 operator==和operator<,就会通过这些模板自动获得其他关系运算符。只要添加#include 和下面的 using 声明,就可将这些运算符用于自己的类:
using namespace std::rel_ops;
但是,这种技术带来的一个问题在于,现在可能为用于关系操作的所有类(而非只为自己的类)创建这些运算符。另一个问题是诸如 std::greater的实用工具模板(见第 18 章的讨论)不能用于这些自动生成的关系运算符。还有一个问题是隐式转换不可行。
注意:
建议自行为类实现所有关系运算符,不要依赖于 std::rel_ops。
”重载算术运算符
第 9 章讲解了如何编写二元算术运算符和简写的算术赋值运算符,但没有讲解如何重载其他算术运算符。15.2.1 ,重载一元负号和一元正号运算符
C++有几个一元算术运算符。一元负号和一元正号运算符是其中的两个。下面列出一些使用整数的运算符示例:
int i,j=4;
i = -j; // Unary minus
i = +i; // Unary Plus
j = +(-i); // Apply unary Plus to the result of applying unary minus to 1
j = -(-i); // Apply unary minus to the result of applying unary minus to 1
一元负号运算符对其操作数取反,而一元正号运算符直接返回操作数。注意,可以对一元正号或一元负号运算符生成的结果应用一元正号或一元负号运算符。这些运算符不改变调用它们的对象,所以应把它们标记为
下例将一元 operator-运算符重载为 SpreadsheetCell 类的成员函数。一元正号运算符通常执行恒等运算,因此这个类没有重载这个运算符
SpreadsheetCell SpreadsheetCell::operator-() const
{
return SpreadsheetCell(~getValue());
}
operator-没有修改操作数,因此这个方法必须构造一个新的带有相反值的 SpreadsheetCell 对象,并返回这个对象的副本。因此,这个运算符不能返回引用。可按以下方式使用这个运算符:
SpreadsheetCell c1(4);SpreadsheetCell c3 = -c1;
重载递增和递减运算符
可采用 4 种方法给变量加 1:
i = i + 1;i += 1;++i;i++;
后两种称为递增运算符。第一种形式是前绥递增,这个操作将变量增加 1,然后返回增加后的新值,供表达式的其他部分使用。第二种形式是后缀递增,返回旧值(增加之前的值),供表达式的其他部分使用。递减运算符的功能类似。 ,operatort+和 operator-的双重意义(前级和后缀)给重载带来了问题。例如,编写重载的 operator+时,怎样表示重载的是前缀版本还是后绥版本? C++引入了一种方法来区分: 前组版本的 operator++和 operator–不接收参数,而后绷版本的接收一个不使用的 int 类型参数。如果要为 SpreadsheetCell 类重载这些运算符,原型如下所示;
SpreadsheetCell& operator++(); //PrefixSpreadsheetCell operator++(int); //PostfixSpreadsheetCell& operator--(); //PrefixSpreadsheetCell operator--(int); //Postfix
前绥形式的结果值和操作数的最终值一致,因此前绥递增和前组递减返回被调用对象的引用。然而后绥版本的递增操作和递减操作返回的结果值和操作数的最终值不同,因此不能返回引用。
下面是 operator++运算符的实现:
SpreadsheetCell& SpreadsheetCell::operator++(){ set(getValue() + 1); return *this;}SpreadsheetCell SpreadsheetCell::operator++(int){ auto oldCell(*this) //Save current value ++(*this); //Increment using prefix ++ return oldCell; //Return the old value}
operator–的实现与此几乎相同。现在可随意递增和递减 SpreadsheetCell 对象了:
SpreadsheetCell c1(4);SpreadsheetCell c2(4);c1++;++c2;
递增和递减还能应用于指针。当编写的类是智能指针或欠代器时,可重载 operatorr+和 operator–,以提供指针的递增和递减操作。
重载插入运算符和提取运算符
在 C++中,不仅算术操作需要使用运算符,从流中读写数据都可使用运算符。例如,向 cout 写入整数和字符串时使用插入运算符<<:
int number = 10;cout<<"The number is "<<number<<endl;
从流中读取数据时,使用提取运算符>>:
int number;string str;cin>>number>>str;
还可为自定义的类编写合适的插入和提取运算符,从而可按以下方式进行读写:
SpreadsheetCell myCell,anotherCell,aThirdCell;cin>>myCell>>anotherCell>>aThirdCell;cout<<myCell<<" "<<anotherCell<<" "<<aThirdCell<<endl;
在编写插入和提取运算符前,需要决定如何将自定义的类向流输出,以及如何从流中提取自定义的类。在这个例子中,SpreadsheetCell 将读取和写入 double 值。插入和提取运算符左侧的对象是 istream 或 ostream(例如 cin 和 coub,而不是 SpreadsheetCell 对象。由于不能向 istream 类或 ostream 类添加方法,因此应将插入和提取运算符写为 SpreadsheetCell 类的全局函数。这些函数在 SpreadsheetCell 类中的声明如下所示:
class SpreadsheetCell
{
};
std::ostream& operator<<(std::ostream& ostr,const SpreadsheetCell& cell);
std::istream& operator>>(std::istream& istr,SpreadsheetCell& cell);
将插入运算符的第一个参数设置为 ostream 的引用,这个运算符就能应用于文件输出流、字符串输出流、cout、cerr 和 clog 等。详情参阅第 13 章。与此类似,将提取运算符的参数设置为 istream 的引用,这个运算符就能应用于文件输入流、字符串输入流和 cin。
operator<<和 operator>>的第二个参数是对要写入或读取的 SpreadsheetCell 对象的引用。插入运算符不会修改写入的 SpreadsheetCell 对象,因此这个引用可以是 const 引用。然而提取运算符会修改 SpreadsheetCell 对象,因此要求这个参数为非 const 引用。 这两个运算符返回的都是第一个参数传入的流的引用,所以这两个运算符的调用可以嵌套。记住,运算符的语法实际上是显式调用全局 operator>>函数或 operator<<函数的简写形式。例如下面这行代码;
cin>>myCell>>anotherCell>>aThirdCell
重载下标运算符
现在暂时假设你从未听说过标准库中的 vector 或 array 类模板,因此决定自行实现一个动态分配的数组类。这个类人允许设置和获取指定索引位置的元素,并会自动完成所有的内存分配操作。一个动态分配的数组类的定义可能是这样的:
template<typename T>
class Array
{
public:
//Creates an array with a default size that will grow as need
Array();
virtual ~Array();
//Disallow assignment and pass-by-value
Array<T>& oprator=(const Array<T>& rhs) = delete;
Array(const Array<T>& src) = delete;
//Returns the value at index x. Throws an exception of type
//out_of_range if index x does not exist in the array
const T& getElementAt(size_t x) const;
//Sets the value at index x,if index x is out of range
//allocates more space to make it in range
void setElementAt(size_t x,const T& value);
size_t getSize() const;
private:
static const size_t kAllocSize = 4;
void resize(size_t newSize);
T* mElements = nullptr;
size_t mSize = 0;
};
这个接口支持设置和访问元素。它为随机访问提供了保证: 客户可创建数组,并设置元素 1、100 和 1000,而不必考虑内存管理问题。下面是这些方法的实现:
template<typename T>Array<T>::Array()
{
mSize = kAllocSize;
mElements = new T[mSize]{};//Elements are zero-initialized!;
}
template<typename T>Array<T>::~Array()
{
delete []mElements;
mElements = nullptr;
}
template<typename T> void Array<T>::resize(size_t newSize)
{
//Create new bigger array with zero-initialized elements
auto newArray = std::make_unique<T[]>(newSize);
//The new size is always bigger than the old size(m)
for(size_t i = 0; i < mSize; i++)
{
//Copy the elements from the old array to the new one
newArray[i] = mElements[i];
}
//Delete the old array,and set the new array
delete[] mElements;
mSize = newSize;
mElements = newArray.release();
}
template<typename T> const T& Array<T>::getElementAt(size_t x) const
{
if(x >= mSize)
{
throw std::out_of_range("");
}
return mElements[x];
}
template<typename T> void Array<T>::setElementAt(size_t x,const T& val)
{
if(x >= mSize)
{
//Allocate kAllocSize past the element the client wants
resize(x + kAllocSize);
}
mElements[x] = val;
}
template <typename T> size_t Array<T>::getSize() const
{
return mSize;
}
注意 resize()方法的异常安全实现。首先,它创建一个适当大小的新数组,将其存储在 unique_ptr 中。然后,将所有元素从旧数组复制到新数组。如果在复制值时任何地方出错,unique_ptr 会自动清理内存。最后,在成功分配新数组和复制所有元素后,即未抛出异常,我们才删除旧的 mElements 数组,并为其指定新数组。最后一行必须使用 release0来释放 unique_ptr 的新数组的所有权,和否则,在调用 unique_ptr 的析构函数时,将销毁这个数组。下面是使用这个类的简短示例;
Array<int> myArray;
for(size_t i = 0; i < 10; i++)
{
myArray.setElementAt(i,100);
}
for(size_t i = 0; i < 10; i++)
{
cout<<myArray.getElementAt(i)<<" ";
}
从中可以看出, 永远都不需要告诉数组需要多少空间。数组会分配保存给定元素所需要的足够空间。然而,总是使用 setElementAt()和 getElementAt()方法并不方便。 最好能像下面的代码一样使用方便的数组索引表示法:
Array<int> myArray;
for(size_t i = 0; i < 10;i++)
{
myArray[i] = 100;
}
for(size_t i = 0; i < 10;i++)
{
cout<<myArray[i]<<" ";
}
这里应该使用重载的下标运算符。通过以下方式给类添加 operator[];
template<typename T> T& Array<T>::operator[](size_t x)
{
if(x >= mSize)
{
//Allocate kAllocSize past the element the client wants
return(x + kAllocSize);
}
return mElements[x];
}
现在,上面使用数组索引表示法的示例代码可编译了。operator[]可设置和获取元素,因为它返回的是一个对位置 x 处的元素的引用。可通过这个引用对这个元素赋值。当 operator[]用在赋值语句的左侧时,赋值操作实际上修改了 mElements 数组中位置 x 处的值。
通过 operator[]提供只读访问
尽管有时 operator[]返回可作为左值的元素会很方便,但并非总是需要这种行为。最好还能返回 const 引用,提供对数组中元素的只读访问。理想情况下,可提供两个 operator[]; 一个返回引用,另一个返回 const 引用。为此,编写下面这样的代码:
T& operator[](size_t x);const T& operator[](size_t x) const;
记住,不能仅基于返回类型来重载方法或运算符,因此第二个重载返回 const 引用并被标记为 const。下面是 const operator[]的实现: 如果索引超出了范围,这个运算符不会分配新空间,而是抛出异常。如果只是读取元素值,那么分配新的空间就没有意义了:
void printArray(const Array<int>& arr)
{
for(size_t i = 0;i < arr.getSize();i++)
{
cout<<arr[i]<<" ";
//Calls the const operator[] because arr is a const object
}
cout<<endl;
}
int main()
{
Array<int> myArray;
for(size_t i = 0; i < 10; i++)
{
myArray[i] = 100; //Calls the non-const operator[] because myArray is a non-const object
}
printArray(myArray);
return 0;
}
注意,仅因为 arr 是 const,所以 printArray()中调用的是 const operator[]。如果 arr 不是 const,那么调用的是非 const 的 operator[],尽管事实上并没有修改结果。为 const 对象调用 const operator[],因此无法增加数组大小。当给定索引越界时,当前实现抛出异常。另一种做法是返回而非抛出零初始化元素。代码如下:
template<typename T> const T& Array<T>::operator[](size_t x) const
{
if(x >= mSize)
{
static T nullValue = T();
return nullValue;
}
return mElements[x];
}
使用零初始化语法了初始化静态变量 nullValue。可根据具体情况自行选用抛出版本或返回 null 值的版本。所谓“零初始化”,是指使用默认构造函数来构造对象,将基本的整数类型(如 char 和 int 等)初始化为 0,将基本的浮点类型初始化为 0.0,将指针类型初始化为 nullptr。
非整数数组索引
这是通过提供某种类型的键,对集合进行“索引”的范型的自然延伸,vector(或更广义的任何线性数组)是一种特例,其中的“键”只是数组中的位置。将 operator[]的参数看成提供的两个域之间的映射: 键域到值域藤映射。因此,可编写一个将任意类型作为索引的 operator[]。这种类型未必是整数类型。标准库的关联容器就是这么做的,例如第 17 章讨论的 std::map。例如,可创建一个关联数组,在其中使用字符串而不是整数作为键。下面是关联数组类的定义:
template<typename T>
class AssociativeArray
{
public:
virtual ~AssociativeArray() = default;
T& operator[](std::string_view key);
const T& operator[](std::string_view key) const;
private:
//Implementation detail omitted
}
重载函数调用运算符
C++允许重载函数调用运算符,写作 operator()。如果在自定义的类中编写了一个 operator(),那么这个类的对象就可以当成函数指针使用。包含函数调用运算符的类对象称为函数对象,或简称为仿函数(functor)。只能将这个运算符重载为类中的非静态方法。下例是一个简单的类,它带有一个重载的 operator()以及一个具有相同行为的类方法:
class FunctionObject
{
public:
int operator()(int param); //Function call operator
int doSquare(int param); //Normal method
};
//Implementation of overloaded function call operator
int FunctionObject::operator()(int param)
{
return doSquare(param);
}
//Implementation of normal method
int FunctionObject::doSquare(int param)
{
return param * param;
}
下面是使用函数调用运算符的代码示例,注意和类的普通方法调用进行比较;
int x = 3,xSquared,xSquaredAgain;
FunctionObject square;
xSquared = square(x); //Call the function call operator
xSquaredAgain = square.doSquare(x); //Call the normal method
一开始,函数调用运算符可能看上去有点怪。为什么要为类编写一个特殊方法,使这个类的对象看上去像函数指针? 为什么不直接编写一个函数或标准的类方法? 相比标准的对象方法,函数对象的好处很简单: 这些对象有时可以伪装成函数指针,可将这些函数对象当成回调函数传给其他函数。第 18 章将详细讨论这些内容。相比全局函数,函数对象的好处较为复杂。有两个主要好处:e, 对象可在函数对象运算符的重复调用之间,在数据成员中保存信息。例如,函数对象可用于记录每次通过函数调用运算符调用采集到的数字的连续总和。e 可通过设置数据成员来自定义函数对象的行为。例如,可编写一个函数对象,比较函数调用运算符的参数和数据成员的值。这个数据成员是可配置的,因此这个对象可自定义为执行任何比较操作。当然,通过全局变量或静态变量都可实现上述任何好处。然而,函数对象提供了一种更简洁的方式,而使用全局变量或静态变量在多线程应用程序中可能会产生问题。第 18 章通过标准库展示了函数对象的真正好处。通过遵循一般的方法重载规则,可为类编写任意数量的 operator()。例如,可向 FunctionObject 类添加一个带 std::string_view 参数的 operator():
int operator()(int param);void operator()(std::string_view str);
函数调用运算符还可用于提供多维数组的下标。只要编写一个行为类似于 operator[],但接收多个索引的operator()即可。这项技术的唯一问题是需要使用()而不是[]进行索引,例如 myArray(3, 4) = 6。
重载解除引用运算符
可重载 3 个解除引用运算符: *、->和->*。目前暂不考虑->*(之后详述),只考虑*和->的原始意义。*解除对指针的引用,人允许直接访问这个指针指向的值,->是使用*解除引用之后再执行.成员选择操作的简写。以下代码验证了这两者的一致性
SpreadsheetCell* cell = new SpreadsheetCell;(*cell).set(5); //Dereference plus member selectioncell->set(5); //Shorthand arrow dereference and member selection together
在类中重载解除引用运算符,可使这个类的对象行为和指针一致。这种功能的主要用途是实现智能指针,参见第 1 章。还能用于标准库广泛使用的迭代器,参见第 17 章。本章通过一个简单的智能指针类模板,讲解重载相关运算符的基本机制。
警告
C++有两个标准的智能指针: std::shared_ptr 和 std::unique_ptr。强烈建议使用这些标准的智能指针类而不是自己编写。这里列举的例子只是为了演示如何编写解除引用运算符。下面是这个智能指针类模板的定义,其中尚未填入解除引用运算符,
template<typename T>class Pointer
{
public:
Pointer(T* ptr);
virtual ~Pointer();
//Prevent assignment and pass by value
Pointer(const Pointer<T>& src) = delete;
Pointer<T>& operator=(const Pointer<T>& rhs) = delete;
//Dereferencing operators will go here
private:
T* mPtr = nullptr;
};
这个智能指针就像看上去那么简单。它只是保存了一个普通指针,在这个智能指针被销毁时,将删除它指向的存储空间。这个实现同样十分简单: 构造函数接收一个真正的指针(普通指针),将该指针保存为类中仅有的数据成员。析构函数释放这个指针引用的存储空间。
template <typename T> Pointer<T>::Pointer<T* ptr> : mPtr(ptr)
{
}
template <typename T> Pointer<T>::~Pointer()
{
delete mPtr;
mPtr = nullptr;
}
可采用以下方式使用这个智能指针类模板:
Pointer<int> smartInt(new int);*smartInt = 5; //Dereference the smart pointercout<<*smartInt< smartCell(new SpreadsheetCell);smartCell->set(5); //Dereference and member select the methodcout<getValue()<
从这个例子可看出,必须提供 operator*和 operator->的实现。
警告;
一般情况下,不要只实现 operator*和 operator->运算符中的一个。几乎总是应该同时实现这两个运算符。如果未同时提供这两个运算符的实现,类的用户可能会感到困惑。
实现 operator*
当解除对指针的引用时, 经常希望能访问这个指针指向的内存。如果那块内存包含一种简单类型, 例如 int,那么应该可直接修改这个值。如果内存中包含更复杂的类型,例如对象,那么应该能通过.运算符访问对象的数据成员或方法。为提供这些语义,operator+应该返回一个引用。在 Pointer 类中,声明和定义如下所示;
template<typename T> class Pointer{ public: //Omitted for brevity T& operator*(); const T& operator*() const; //Omitted for brevity};template T& Pointer::operator*(){ return *mPtr;}template const T& Pointer::operator*() const{ return *mPtr;}
从这个例子可看出,operator*返回的是底层普通指针指向的对象或变量的引用。与重载下标运算符一样,同时提供方法的 const 版本和非 const 版本也很有用,这两个版本分别返回 const 引用和非 const 引用 。
实现 operator->
箭头运算符稍微复杂一些。应用箭头运算符的结果应该是对象的成员或方法。然而,为实现这一点,应该能够实现 operator*和 operator.; 而 C++有充足的理由不允许重载 operator.一不可能编写单个原型来捕捉任何可能选择的成员或方法。因此,C++将 operator->当成一种特例。例如下面这行代码,
smartCell->set(5);
C++将这行代码解释为:
(smartCell.operator->())->set(5);
从中可看出,C++给重载的 operator->返回的任何结果应用了另一个 operator->。因此,必须返回一个指向对象的指针,如下所示:
template<typename T> class Pointer
{
public:
//Omitted for brevity
T* operator->();
const T* operator->() const;
//Omitted for brevity
};
template <typename T>T* Pointer<T>::operator->()
{
return mPtr;
}
template <typename T> const T* Pointer<T>::operator->() const
{
return mPtr;
}
operator*和 operator->是不对称的,这可能有点令人费解,但见过几次之后就会习惯了
operator*和 operator ->*的含义
在 C++中,获得类的数据成员和方法的地址,以获得指向这些数据成员和方法的指针是完全合法的。然而,不能在没有对象的情况下访问非静态数据成员或调用非静态方法。类的数据成员和方法的重点在于它们依附于对象。因此,通过指针调用方法或访问数据成员时,必须在对象的上下文中解除对指针的引用。下例演示了这一点。11.3.3 节“方法和数据成员的指针的类型别名”中详细讨论了语法细节。
SpreadsheetCell myCell;double (SpreadsheetCell::*methodPtr)()const = &SpreadsheetCell::getValue;cout<<(myCell.*methodPtr)()<<endl;
注意,*运算符解除对方法指针的引用并调用这个方法。如果有一个指向对象的指针而不是对象本身,那么还有一个等效的 operator->*可通过指针调用方法。这个运算符如下所示:
SpreadsheetCell* myCell = new SpreadsheetCell();double (SpreadsheetCell::*methodPtr)() const = &SpreadsheetCell::getValue;cout<<(myCell->*methodPtr)()<<endl;
编写转换运算符
回到 SpreadsheetCell 示例,考虑下面两行代码:
SpreadsheetCell cell(1.23);double d1 = cell; //DOES NOT COMPILE
SpreadsheetCell 包含 double 表达方式,因此将 SpreadsheetCell 赋值给 double 变量看上去是符合逻辑的。但不能这么做。编译器会表示不知道如何将 SpreadsheetCell 转换为 double 类型。你可能会通过下述方式迫使编译器进行这种转换:
double d1 = (double)cell;//STILL DOES NOT COMPILE!
首先,上述代码依然无法编译,因为编译器还是不知道如何将 SpreadsheetCell 转换为 double 类型。从这行代码中编译器已知你想让编译器做这种转换,所以编译器如果知道如何转换,就会进行转换。其次,一般情况下,最好不要在程序中添加这种无理由的类型转换。
如果想允许这类赋值,就必须告诉编译器具体如何执行。确切地讲,可编写一个将 SpreadsheetCell 转换为double 类型的转换运算符。原型如下所示:
operator double() const;
函数名为 operator double。它没有返回类型,因为返回类型是通过运算符的名称确定的: double。这个函数是 const,因为这个函数不会修改被调用的对象。实现如下所示:
SpreadsheetCell::operator double() const{ return getValue();}
这就完成了从 SpreadsheetCell 到 double 类型的转换运算符的编写。现在编译器可接受下面这行代码,并在运行时执行正确的操作。
SpreadsheetCell cell(1.23);double d1 = cell; //Works as expected
可用同样的语法编写任何类型的转换运算符。例如,下面是从 SpreadsheetCell 到 std::string 的转换运算符,
SpreadsheetCell::operator std::string() const{ return doubleToString(getValue());}
现在可编写以下代码;
SpreadsheetCell cell(1.23);
string str = cell;
使用显式转换运算符解决多义性问题
注意,为 SpreadsheetCell 对象编写 double 转换运算符时会引入多义性问题。例如下面这行加粗代码;
SpreadsheetCell cell(1.23);
double d2 = cell + 3.3; //DOES NOT COMPILE IF YOU DEFINE operator double()
现在这行代码无法成功编译。在编写 operator double()前,这行代码可编译,那么现在出了什么问题? 问题在于,编译器不知道应该通过 operator double()将 cell 对象转换为 double 类型,再执行 double 加法,还是通过double 构造函数将 3.3 转换为 SpreadsheetCell,再执行 SpreadsheetCell 加法。在编写 operator double()前,编译器只有一个选择: 通过 double 构造函数将 3.3 转换为 SpreadsheetCell,再执行 SpreadsheetCell 加法。然而,现在编译器可执行两种操作。编译器不想做出让人不喜欢的决定,因此拒绝做出任何决定。
在 C++11 之前, 通常解决这个难题的方法是将构造函数标记为 explicit,以避免使用这个构造函数进行自动转换(见第 9 章)。然而, 我们不想把这个构造函数标记为 explicit, 因为通常希望进行从 double 到 SpreadsheetCell
explicit operator double() const
下面的代码演示了这种方法的应用:
SpreadsheetCell cell = 6.6; //1
string str = cell; //2
double d1 = static_cast<double>(cell); //3
double d2 = static_cast<double>(cell + 3.3) //4
下面解释上述代码中的各行:
使用隐式类型转换从 double 转换到 SpreadsheetCell。 由于是在声明中, 因此这是通过调用接收 double参数的构造函数进行的。
使用 operator string()转换运算符。
使用 operator double()转换运算符。注意,由于这个转换运算符现在声明为 explicit,因此要求进行强制类型转换。
通过隐式类型转换将 3.3 转换为 SpreadsheetCell,再进行两个 SpreadsheetCell 对象的 operator+操作,之后进行必要的显式类型转换以调用 operator double()
用于布尔表达式的转换
有时,能将对象用在布尔表达式中会非常有有用。例如,程序员经常在条件语句中这样使用指针; |
if(ptr != nullptr) {/* Preform some dereferencing action */}
有时程序员会编写这样的简写条件:
if(ptr){/*Perform some dereferencing action*/}
有时还能看到这样的代码:
if(!ptr){/* Do something* /}
目前,上述任何表达式都不能和此前定义的 Pointer 智能指针类模板一起编译。然而,可给类添加一个转换运算符,将它转换为指针类型。然后,对这种类型和 nullptr 所做的比较操作,以及单个对象在 诈语句中的形式都会触发这个对象向指针类型的转换。转换运算符常用的指针类型为 void*,因为这种指针类型除了在布尔表达式中测试外,不能执行其他操作。
template<typename T> Pointer<T>::operator void*() const{ return mPtr;}
现在下面的代码可成功编译,并能完成预期的任务;
void process(Pointer<SpreadsheetCell>& p){ if(p != nullptr) {cout<<"not nullptr:"<<endl;} if(p != NULL){ cout<<"not NULL"<<endl;} if(p) {cout<<"not nullptr"<<endl;} if(!p){cout<<"nullptr"<<endl;}}int main(){ Pointer<SpreadsheetCell> smartCell(nullptr); process(smartCell); cout<<endl; Pointer<SpreadsheetCell> anotherSmartCell(new SpreadsheetCell(5.0)); process(anotherSmartCell);}
输出如下所示:
nullptrnot nullptrnot NULLnot nullptr
另一种方法是重载 operator bool()而非 operator void*()。上毕竟是在布尔表达式中使用对象,为什么不直接转换为 bool 类型呢?
template<typename T> Pointer<T>::operator bool() const{ return mPtr != nullptr;}
下面的比较仍可以运行;
if(p != NULL) {cout<<"not NULL"<<endl;}if(p){cout<<"not nullptr"<<endl;}if(!p){cout<<"nullptr"<<endl;}
然而,使用 operator bool()时,下面和 nullptr 的比较会导致编译错误:
if(p != nullptr){cout<<"not nullptr"<<endl;}
这是正确的行为,因为 nullptr 有自己的类型 nullptr_t,这种类型没有自动转换为整数 0 (false)。编译器找不到接收 Pointer 对象和 nullptr_ t 对象的 operator!=。可将这样的 operator=实现为 Pointer 类的友元:
template<typename T>class Pointer{ public: //Omitted for brevity template; friend bool operator!=(const Pointer lhs,std::nullptr rhs); //Omutted for brevity };templatebool operator!=(const Pointer& lhs,std::nullptr_t rhs){ return lhs.mPtr != rhs;}
然而,实现这个 operatort!=后,下面的比较会无法工作,因为编译器不知道该用哪个 operator!=
if(p!=NULL){cout<<"not NULL"<<endl;}
通过这个例子,你可能得出以下结论: operator bool()从技术上看只适用于不表示指针的对象,以及转换为指针类型并没有意义的对象。遗憾的是,添加转换至 bool 类型的转换运算符会产生其他一些无法预知的后果。当条件允许时,C++会使用“类型提升”规则将 bool 类型自动转换为 nt 类型。因此,采用 operator bool()时,下面的代码可编译运行:
Pointer<SpreadsheetCell> anotherSmartCell(new SpreadsheetCell(5.0));int i = anotherSmartCell; //Converts Pointer to bool to int
这通常并不是期望或需要的行为。为阻止此类赋值,通常会显式删除到 int、long 和 long long 等类型的转换运算符。但这显得十分凌乱。因此,很多程序员更偏爱使用 operator void*()而不是 operator bool()。从中可以看出,重载运算符时需要考虑设计因素。哪些运算符需要重载的决策会直接影响到客户对类的使用方式。
重载内存分配和内存释放运算符
C++人允许重定义程序中内存的分配和释放方式。既可在全局层次也可在类层次进行这种自定义。这种功能在可能产生内存碎片的情况下最有用,当分配和释放大量小对象时会产生内存碎片。例如,每次需要内存时,不使用默认的 C++内存分配,而是编写一个内存池分配器,以重用固定大小的内存块。本节详细讲解内存分配和内存释放例程,以及如何定制化它们。有了这些工具,就可以根据需求编写自己的分配器。
警告:
除非十分了解内存分配的策略,否则尝试重载内存分配例程通常都不值得。 不要仅因为看上去不错,就重载它们。只有在真正需要且掌握足够的知识后才这么做。_
new 和 delete 的工作原理
C++最复杂的地方之一就是new 和 delete 的细节。考虑下面这行代码:
SpreadSheetCell* cell = new SpreadsheetCell();
new SpreadsheetCell()这部分称为 new 表达式。它完成了两件事情。首先,通过调用 operator new 为SpreadsheetCell 对象分配了空间。然后,为这个对象调用构造函数。只有这个构造函数完成了,才返回指针。
delete 的工作方式与此类似。考虑下面这行代码:
delete cell
这一行称为 delete 表达式。它首先调用 cell 的析构函数,然后调用 operator delete 来释放内存。可重载 operator new 和 operator delete 来控制内存的分配和释放,但不能重载 new 表达式和 delete 表达式。因此,可自定义实际的内存分配和释放,但不能自定义构造函数和析构函数的调用。
- new 表达式和 operator new
有 6 种不同形式的 new 表达式,每种形式都有对应的 operator new。前面的章节已经展示了 4 种 new 表达式: new、new[]、new(nothrow)和 new(nothrow)[]。下面列出了头文件中对应的 4 种 operator new 形式: .
void* operator new(size_t size);void* operator new[](size_t size);void* operator new(size_t size,const std::nothrow_t&) noexcept;void* operator new[](size_t size,const std::nothrow_t&) noexcept;
有了两种特殊的 new 表达式,它们不进行内存分配, 而在已有存储段上调用构造函数这种操作称为 placement new 运算符(包括单对象和数组形式)。它们在已有的内存中构造对象,如下所示:
void* ptr = allocateMemorySomehow();SpreadsheetCell[] *cell = new (ptr) SpreadsheetCall();
这个特性有点儿偏门,但知道这项特性的存在非常重要。如果需要实现内存池,以便在不释放内存的情况下重用内存,这项特性就非常方便。对应的 operator new 形式如下,但 C++标准禁止重载它们:
void* operator new(size_t size,void* p) noexcept;
void* operator new[](size_t size,void* p) noexcept
\2. delete 表达式和 operator delete
只可调用两种不同形式的 delete 表达式: delete 和 delete[],没有 nothrow 和 placement 形式。然而,operator delete 有 6 种形式。为什么有这种不对称性? nothrow 和 placement 形式只有在构造函数抛出异常时才会使用。这种情况下,匹配调用构造函数之前分配内存时使用的 operator new 的 operator delete 会被调用。然而,如果正常地删除指针,delete 会调用 operator delete 或 operator delete[] (绝不会调用 nothrow 或 placement 形式)。在实际中,这并没有关系: C++标准指出,从 delete 抛出异常的行为是未定义的。也就是说,delete 永远都不应该抛出异常。因此 nothrow 版本的 operator delete 是多余的,而 placement 版本的 delete 应该是一个空操作,因为在placement new 中并没有分配内存,因此也不需要释放内存。下面是 operator delete 各种形式的原型:
void operator delete(void* ptr) noexcept;
void operator delete[](void* ptr) noexcept;
void operator delete(void* ptr, const std::nothrow_t&) noexcept;
void operator delete[](void* ptr,const std::nothrow_t&) noexcept;
void operator delete(void* p,void*) noexcept;
void operator delete[](void* p, void*) noexcept;
重载 operator new 和 operator delete
如有必要,可替换全局的 operator new 和 operator delete 例程。这些函数会被程序中的每个 new 表达式和delete 表达式调用, 除非在类中有更特别的版本。然而,引用 Bjame Stroustrup 的一句话:“用替换全局的 operator new 和 operator delete 是需要胆量的。”。我们不建议替换。
警告:
如果没有听取我们的建议并决定替换全局的 operator new,一定要注意在这个运算符的代码中不要对 new进行任何调用,否则会产生无限循环。 例如,不能通过 cout 向控制台写入消息。更有用的技术是重载特定类的 operator new 和 operator delete。仅当分配或释放特定类的对象时,才会调用这些重载的运算符。下面这个类重载了 4 个非 placement 形式的 operator new 和 operator delete:
#include 下面是这些运算符的简单实现,这些实现将参数传递给这些运算符全局版本的调用。注意 nothrow 实际上是一个 nothrow_t类型的变量:
void* MemoryDemo::operator new(size_t size)
{
cout<<"operator new"<<endl;
return ::operator new(size);
}
void MemoryDemo::operator delete(void* ptr) noexcept
{
cout<<"operator delete"<<endl;
::operator delete(ptr);
}
void* MemoryDemo::operator new[](size_t size)
{
cout<<"operator new[]"<<endl;
return ::operator new[](size);
}
void Memory::operator delete[](void* ptr) noexcept
{
cout<<"operator delete[]"<<endl;
::operator delete[](ptr);
}
void* MemoryDemo::operator new(size_t size, const nothrow_t&) noexcept
{
cout<<"operator new nothrow "<<endl;
return ::operator new(size,nothrow);
}
void MemoryDemo::operator delete(void* ptr,const nothrow_t&) noexcept
{
cout<<"operator delete nothrow"<<endl;
::operator delete(ptr,nothrow);
}
void* MemoryDemo::operator new[](size_t size,const nothrow_t&) noexcept
{
cout<<"operator new[] nothrow"<<endl;
return ::operator new[](size,nothrow);
}
void MemoryDemo::operator delete[](void* ptr, const nothrow_t&) noexcept
{
cout<<"operator delete[] nothrow"<<endl;
::operator delete[](ptr,nothrow);
}
下面的代码以不同方式分配和释放这个类的对象;
MemoryDemo* mem = new MemoryDemo();delete mem;mem = new MemoryDemo[10];delete[] mem;mem = new (nothrow) MemoryDemo();delete mem;mem = new (nothrow) MemoryDemo[10];delete[] mem;
operator new 和 operator delete 的这些实现非常简单,但作用不大。它们旨在呈现语法形式,以便在实现真正版本时参考。
警告:
当重载 operator new 时,要重载对应形式的 operator delete。和否则,内存会根据指定的方式分配,但是根据内建的语义释放,这两者可能不兼容。重载所有不同形式的 operator new 看上去有点过分。但一般情况下最好这么做,从而避免内存分配的不一致。如果不想提供任何实现,可使用=delete 显式地删除函数,以避免别人使用。
警告:
重载所有形式的 operator new,或显式删除不想使用的形式,以免内存分配中出现不一致情形。显式地删除/默认化 operator new 和 operator delete ”展示了如何删除或默认化构造函数或赋值运算符。显式地删除或默认化并不局限于构造函数和赋值 运算符。例如,下面的类删除了 operator new 和 new[]。也就是说,这个类不能通过 new 或 new[]动态创建:
class MyClass
{
public:
void* operator new(size_t size) = delete;
void* operator new[](size_t size) = delete;
};
按以下方式使用这个类会生成编译错误:
int main()
{
MyClass* p1= new MyClass;
MyClass* pArray = new MyClass[2];
return 0;
}
重载带有额外参数的 operator new 和 operator delete
除了重载标准形式的 operator new 外,还可编写带额外参数的版本。这些额外参数可用于向内存分配例程传递各种标志或计数器。例如,一些运行时库在调试模式中使用这种形式, 在分配对象的内存时提供文件名和行号,这样在发生内存泄漏时,便可识别出发生问题的分配内存的那行代码。
下面是 MemoryDemo 类中带有额外整数参数的 operator new 和 operator delete 原型:
void* operator new(size_t size,int extra);void operator delete(void* ptr,int extra) noexcept;
实现如下所示:
void* MemoryDemo::operator new(size_t size,int extra){ cout<<"operator new with extra int: "<<extra<<endl; return ::operator new(size);}void MemoryDemo::operator delete(void* ptr,int extra) noexcept{ cout<<"operator delete with extra int "<<extra<<endl; return ::operator delete(ptr)}
编写带有额外参数的重载 operator new 时,编译器会自动允许编写对应的 new 表达式。new 的额外参数以函数调用的语法传递(和 nothrow new 一样)。因此,可编写这样的代码:
MemoryDemo* memp = new(5) MemoryDemo();
delete memp;
定义带有额外参数的 operator new 时,还应该定义带有额外参数的对应 operator delete。不能自己调用这个带有额外参数的 operator delete,只有在使用了带有额外参数的 operator new 且对象的构造函数抛出异常时,才调用这个 operator delete。
重载带有内存大小参数的 operator delete
另一种形式的 operator delete 提供了要释放的内存大小和指针。只需要声明带有额外大小参数的 operator delete 原型。
警告;
如果类声明了两个一样版本的 operator delete,只不过一个接收大小参数,另一个不接收,那么不接收大小参数的版本总是会被调用。如果需要使用带有大小参数的版本,请只编写那个版本。可独立地将任何版本的 operator delete 替换为接收大小参数的 operator delete 版本。 下面是 MemoryDemo 类的定义,将其中的第一个 operator delete 改为接收要释放的内存大小作为参数:
class MemoryDemo
{
public:
//Omitted for brevity
void* operator new(size_t size);
void operator delete(void* ptr, size_t size) noexcept;
//Omitted for brevity
};
这个 operator delete 实现调用没有大小参数的全局 operator delete,因为并不存在接收这个大小参数的全局operator delete。
作为一名 C++程序员,使用的最重要的库就是 C++标准库。顾名思义,这个库是 C++标准的一部分,因此任何符合标准的编译器都应该带有这个库。标准库并不是一体性库,而是包含一些完全不同的组件,有些组件你可能已经正在使用了 。你甚至可能认为那些部分就是核心语言的一部分。所有标准库类和函数都在 std 名称空间或其子名称空间中声明。
C++标准库的核心是泛型容器和泛型算法。该库中的这一子集通常称为标准模板库(Standard Template Library,STL),因为它最初基于第三方库“标准模板库?,该库大量使用了模板。但 STL 并非由 C++标准本身定义的术语,因此本书不使用该术语。标准库的威力在于提供了泛型容器和泛型算法,使大部分算法可用于大部分容器,无论容器中保存的数据类型是什么。性能是标准库中非常重要的一部分。标准库的目标是要让标准库容器和算法与手工编写的代码速度相当甚至更快。
C++17 标准库也包含 C11 标准中的大多数 C 头文件,但使用了新名称(C11 头文件、
注意:
优先使用 C++功能,尽量不要使用 C 头文件中包含的功能。致力于成为语言专家的 C++程序员应当熟悉标准模板库。如果在自己的程序中整合使用标准库容器和算法,而不是编写和调试自己的容器和算法,那么节省的时间是不可估量的。下面开始深入介绍标准库。
编码原则
标准库大量使用了 C++的模板功能和运算符重载功能。16.1.1 使用模板
模板用于实现泛型编程。通过模板,才能编写适用于所有类型对象的代码,模板甚至可用于编写代码时未知的对象。编写模板代码的程序员负责指定定义这些对象的类的需求,例如,这些类要有用于比较的运算符,或者要有复制构造函数,或者要满足其他任何必要条件,然后要确保编写的代码只使用必需的功能。创建对象的程序员负责提供模板编写者要求的那些运算符和方法。
遗憾的是,很多程序员认为模板是 C++中最难的部分,因此试图避免使用模板。不过,即使永远也不会编写自己的模板,也需要了解模板的语法和功能,以使用标准库。
C++标准库大量使用了运算符重载。第 9 章的 9.7 节专门介绍了运算符重载。在阅读这一章和后续各章时一定要首先阅读那一节的内容。此外,第 15 章讲解了运算符重载的更多细节。
C++标准库概述
本节从设计角度介绍标准库中的几个组件,学习有哪些可供使用的工具,但不会学习编码细节。这些细节在其他章节介绍。C++在头文件提供内建的 string 类。尽管仍可使用 C 风格的字符数组字符串,但 C++的 string 类几乎在每个方面都比字符数组好。string 类处理内存管理,提供一些边界检查、赋值语义以及比较操作;还支持一些操作,例如串联、子字符串提取以及子字符串或字符的替换。
注意:
从技术角度看,std::string 是对 std::basic_string 模板进行 char 实例化的类型别名。然而,不需要关注这些细节; 只要像非模板类那样使用 string 类即可。标准库还提供在
”正则表达式
头文件提供了正则表达式。正则表达式简化了文本处理中常用的模式匹配任务。通过模式匹配可在字符串中搜索特定的模式,还能酌情将搜索到的模式替换为新模式。第 19 章将讨论正则表达式。
I/O 流
C++引入了一种新的使用流的输入输出模型。C++库提供了能在文件、控制台/键盘和字符串中读写内建类型的例程。C++提供的工具还可编写读写自定义对象的例程。IO 功能在如下几个头文件中定义: 、,,,,,,,和;
智能指针
编写健壮程序时需要面对的一个问题就是要知道何时删除对象。有几种可能发生的故障。第一个问题是根本没有删除对象(没有释放存储)。这称为内存泄漏,发生这种问题时对象越积越多,占用空间,但并未使用空间。另一个问题是一段代码删除了存储,而另一段代码仍然引用了这个存储,导致指向那个存储的指针不再可用或已重新分配用作他用。这称为悬挂指针(dangling pointerm)。还有一个问题是一段代码释放了一块存储,而另一段代码试图释放同一块存储。这称为双重释放(double freeing)。所有这些问题都会导致程序发生某种故障。有些故障很容易检测出来,而有些故障会导致程序产生错误结果。这些错误大多很难发现和修复。
C++用智能指针 unique_ptr、shared_ptr 和 week ptr 解决了这些问题。shared_ptr 和 week_ptr 是线程安全的,它们都在头文件中定义。这些智能指针在第 1 章介绍,在第 7 章详述。
在 C++11 之前,unique_ptr 的功能由名为 auto_ptr 的类型完成,C++17 废弃了 auto_ptr,不应再使用这种类型。在之前的标准库中没有 shared_ptr 的对应功能,不过很多第三方库(例如 Boost提供了这项功能。
异常
C++语言支持异常,函数和方法能通过异常将不同类型的错误向上传递至调用的函数或方法。C++标准库提供了异常的类层次结构,在程序中可使用这些类,也可通过继承方式创建自己的异常类型。异常支持在如下几个头文件中定义:; 、和
数学工具
C++标准库提供了一些数学工具类和函数。
有一组完整上且常见的数学函数可供使用,如 abs()、remainder()、fma()、exp()、log()、pow()、sqrt()、sin()、atan2()、sinh()、erf()、tgamma()、ceil()和 floor()等。C++17 增加了大量的特殊数学函数,以处理勒让德多项式、函数、椭圆积分、贝塞尔函数、柱函数和诺伊曼函数等。标准库在头文件中提供了一个复数类,名为 complex,这个类提供了对包含实部和虚部的复数的操作抽象。
编译时有理数运算库在头文件中提供了 ratio 类模板。这个 ratio 类模板可精确表示任何由分子和分母定义的有限有理数。这个库参见第 20 章。
标准库还在头文件中包含一个 valarray 类,这个类和 vector 类相似,但对高性能数值应用做了特别优化。这个库提供了一些表示矢量切片概念的相关类。通过这些构件,可构建执行矩阵数学运算的类。没有内建的矩阵类,但像 Boost 这样的第三方库提供了矩阵支持。本书不详细讨论 valarray 类。C++还提供了一种获取数值极限的标准方式,例如当前平台允许的整数的最大值。在 C 语言中,可以通过访问#define 来获得这些信息,例如 INT_MAX。尽管在 C++中仍可使用这种方法,但建议使用定义在头文件中的 numeric_limits 类模板。这个类模板的使用非常简单,如下所示:
cout<<"int: "<<endl;cout<<"Max int value: "<<numeric_limits<int>::max()<<endl;cout<<"Min int value: "<<numeric_limits<int>::min()<<endl;cout<<"Lowest int value: "<<numeric_limits<int>::lowest()<<endl;cout<<endl<<"double:"<<endl;cout<<"Max double value: "<<numeric_limits<double>::max()<<endl;cout<<"Min double value: "<<numeric_limits<double>::min()<<endl;cout<<"Lowest double value: "<<numeric_limits<double>::lowest()<<endl;
在笔者的系统上,这段代码的输出如下所示:
int:Max int value: 2147483647Min int value: -2147483648Lowest int value: -2147483648double:Max double value: 1.79769e+308Min double value: 2.22507e-308Lowest double value: -1.79769e+308
注意 min()和 lowest()之间的差异。对于整数而言,min 值等于 lowest 值。但对于浮点类型而言,min 值等于可表示的最小正值,而 lowest 值等于可表示的最大负值,即 - max()。
时间工具
C++在头文件中包含了 Chrono 库。这个库简化了与时间相关的操作,例如特定时间间隔的定时操作和定时相关的操作。第 20 章将详细讨论 Chrono 库。头文件中还提供了其他时间和日期工具。
随机数
C++很久以前就支持使用 srand()和 rand()函数生成随机数,但这些函数只提供非常初级的随机数。例如,无法修改生成的随机数的分布。自 C++11 以后,在标准库中添加了一个完善的随机数库,这个新库在头文件中定义,带有随机数引擎、随机数引擎适配器以及随机数分布。通过这些组件可以生成更适合特定问题域的随机数,如正态分布、负指数分布等。
初始化列表
初始化列表在
pair 和tuple
头文件定义了 pair 模板,用于存储两种不同类型的元素。这称为存储异构元素。本章后面讨论的所有标准库容器都只能存储同构元素。也就是说,容器中的所有元素都必须具有相同的类型。pair 允许在一个对象中保存类型毫不相关的元素。
中定义的 tuple 是 pair 的一种泛化,它是固定大小的序列,元组的元素可以是异构的,tuple 实例化的元素数目和类型在编译时固定不变。关于 tuple 的详情参见第 20 章。
optional、variant 和 any
C++17 引入了以下几个新类:
optional,在中定义,要么存储指定类型的值,要么什么都不存储。如果人允许值是可选的,这可用于函数的参数或返回类型。
variant,在中定义,可存储单个值(属于一组给定类型中的一种类型),或什么都不存储。
any,在中定义,可包含单个值,值可以是任何类型。
讨论这些类型
函数对象
实现函数调用运算符的类称为函数对象。函数对象可用作某些标准库算法的谓词。头文件定义了一些预定义的函数对象,支持根据已有的函数对象创建新的函数对象。
函数对象参见第 18 章。第 18 章还将详细论述标准库算法。
文件系统
C++17 引入了文件系统支持库。所有内容都在头文件中定义,位于 std::filesystem 名称空间。它人允许编写可用于文件系统的可移植代码。可以使用它确定是目录还是文件,和迭代目录内容,操纵路径,以及检索有关文件的信息(如文件大小、扩展名和创建时间等)。第 20 章将讨论文件系统支持库。
多线程
所有主流 CPU 经销商都销售多核处理器,它们用于从服务器到用户计算机等所有设备,甚至还用于智能手机。如果和希望软件利用所有这些核,就需要编写多线程代码。标准库提供了几个基本的构件块来编写这种代码。单个线程可以用头文件中的 thread 类创建。
在多线程代码中,需要考虑如下问题: 几个线程不能同时读写同一个数据段。为避免这种情形发生,可使用定义的原子性,它提供了对一段数据的线程安全的原子访问。
如果只需要计算某个数据(可能在不同线程上),得到结果,并有具有相应的异常处理,可使用头文件中定义的 async 和 future,这些比直接使用 thread 类更容易。有关编写多线程代码的内容.
类型特质
类型特质在
标准整数类型
头文件定义了大量标准整数类型,如 int8_t 和 int64_t 等,还包含多个宏(指定这些类型的最小值和最大值)。第 30 章在讲述如何编写跨平台代码时,将讨论这些整数类型。
容器
标准库提供了常用数据结构(例如链表和队列)的实现。使用 C++时,不需要自己编写这类数据结构了。数据结构的实现使用了一个称为容器的概念,容器中保存的信息称为元素,保存信息的方式能够正确地实现数据结构(链表和队列等)。不同数据结构有不同的插入、删除和访问行为,性能特性也不同。重要的是要熟悉可用的数据结构,这样才能在面对特定任务时选择最合适的数据结构。标准库中的所有容器都是类模板,因此可通过这些容器保存任意类型的数据,从内建的 int 和 double 等类型到自定义的类。每个容器实例都只能保存一种类型的对象,也就是说,这些容器都是同构集合。如果需要大小可变的异构集合,可将每个元素包装在 std::any 实例中,并将这些实例存储在容器中。另外,可在容器中存储 std::variant 实例如果所需的不同类型的数量受限, 在编译时已知, 可使用 variantsany 和 variant 都是在 C++17中引入的,详见第 20 章。如果需要 C++17 之前的异构集合,可创建具有多个派生类的类,每个派生类可包装所需类型的对象。
注意:
C++标准库容器是同构的: 在每个容器中只允许一种类型的元素。注意,C++标准定义了每个容器和算法的接口(interface),而没有定义实现。因此, 不同的供应商可以自由提供不同的实现。然而,作为接口的一部分,标准还定义了性能需求,实现必须满足性能需求。下面概述标准库中可用的几个容器。
\1. vector
头文件定义了 vector,vector 保存了元素序列,提供对这些元素的随机访问。可将 vector 想象为一个元素的数组,当插入元素时,这个数组会动态增长,还提供了一些边界检查功能。与数组一样,vector 中的元素保存在连续内存中。
注意:
C++中的 vector 相当于动态数组: 这个数组会随着所保存元素数目的变化自动增长或收缩。vector 能够在 vector 尾部快速地插入和删除元素(摊还常量时间, amortized constant time)。摊还常量时间指的是大部分插入操作都是在常量时间内完成的(0(1),第 4 章解释了大 O 表示法)。然而,有时 vector 需要增长大小以容纳新元素,此时的复杂度为 O(1)。这个结果的平均复杂度为 O(1),或称为摊还常量时间。第 17 章将讲解详情。vector 其他部位的插入和删除操作比较慢(线性时间),因为这种操作必须将所有元素向上或向下挪动一个位置,为新元素腾出空间,或填充删除元素后留下的空间。与数组一样,vector 提供对任意元素的快速访问(常量时间)。虽然在 vector 中插入和删除元素需要上下移动其他元素,但应将 vector 用作默认容器! 即使在中部插入和删除元素,vector 也比链表等更快。原因在于,vector 在内存中连续存储,而链表却分散在内存中。计算机可极快地处理连续数据,这样,vector 操作的速度更快。仅当性能分析器(见第 25 章)告诉你链表比 vector 更快时,才应当使用链表。
注意:
应将 vector 用作默认容器。
对于在 vector中保存布尔值有一个专门的模板。这个特制模板特别对布尔元素进行空间分配的优化,然而标准并未规定 vector的实现应该如何优化空间。vector和本章后面要讨论的 bitset 之间的区别在于,bitset 容器的大小是固定的。
list
标准库 list 是一种双向链表数据结构,在中定义。与数组和 vector 一样,list 保存了元素的序列。然“而,与数组或 vector 的不同之处在于,list 中的元素不一定保存在连续内存中。相反,list 中的每个元素都指定了如何在 list 中找到前一个和后一个元素(通常是通过指针),所以得名双向链表。list 的性能特征和 vector 完全相反。list 提供较慢的元素查找和访问(线性时间),而找到相应的位置之后,元素的插入和删除却很快(常量时间)。然而,vector 通常比 list 更快。可使用性能分析器确认这一点。
forward ist
中定义的 forward_list 是一种单向链表, 而 list 容器是双向链表。 forward_list 只支持前向迭代,需要的内存比 list 少。与list 类似,一旦找到相关位置,forward_list 允许在任何位置执行插入和删除操作(常量时间); 与list 一样,不能快速地随机访问元素。
deque
deque 是双头队列(double-ended queue)的简称。deque 在中定义, 能实现快速的元素访问(常量时间)。在序列的两端还实现了快速插入和删除(摊还常量时间), 但在序列中间插入和删除的速度较慢(线性时间)。deque中的元素在内存中的存储不连续,速度可能比 vector 慢。如果需要在序列两头快速插入或删除元素,还要求快速访问所有元素,那么应该使用 deque 而不是 vector。然而,很多编程问题并不满足这个要求,因此在大部分情况下,vector 或list 都足以满足需求。
array
头文件定义了 array,这是标准 C 风格数组的替代品。有时可事先知道容器中元素的确切数量,因此不需要 vector 或list 提供的灵活性, vector 和 list 能动态增长以容纳新元素。array 特别适用于大小固定的集合,而且没有 vector 的开销,array 实际上是对 C 风格数组的简单包装。使用 array(而不是标准的 C 风格数组)有几点好处: array总能知道自己的大小; 不会自动转换为指针类型,从而避免了某些类型的 bug。array 没有提供插入和删除操作,但大小国定。大小固定的优点是,人允许 array 在堆栈上分配内存,而不总是像 vector 那样需要堆访问权限。与 vector 一样,对元素的访问速度极快(常量时间)。
注意;
Vector、list、deque、array 和 forward_list 容器都称为顺序容器(sequential container),因为它们保存的是元素的序列。
queue
queue的含义是一队人或一列对象.queue 容器在中定义, 提供标准的先入先出(First In First Out, FIFO)语义。在使用 queue 容器时,从一端插入元素,从另一端取出元素。插入元素(摊还常量时间)和删除元素(常量时间)的操作都很快。需要建模真实世界中的“先入先出”语义时,应该使用 queue 结构。以银行为例,随着顾客到达银行,顾客在队伍中等待。当柜员可提供服务时,柜员首先服务队伍中的下一位顾客,因此这是一种“先来先服务”的行为。在 queue 中保存 Customer 对象可实现对银行的模拟。随着顾客到达银行,将顾客添加到 queue 的尾部。当柜员服务顾客时,首先从队列头部的顾客开始服务。
priority_queue
priority_queue 也在中定义,提供与 queue 相同的功能,但其中的每个元素都有优先级。元素按优先顺序从队列中移除。在优先级相同的情况下,删除元素的顺序没有定义。对 priority_queue 的插入和删除一般比简单的队列插入和删除要慢,因为只有对元素重排序,才能支持优先级。通过 priority_queue 可建模“带有意外的队列”。例如,在前面的银行模拟中,假设带有企业账号的顾客比普通顾客的优先级高。很多银行都通过两个独立队列来实现这个行为: 一个队列用于企业账号顾客,另一个队列用于其他所有顾客。企业账号队列中的任何顾客都优先于其他队列中的顾客。不过,银行也提供单队列的行为,在这种行为中,企业顾客可转移到队列中所有非企业顾客前面的位置。在程序中,可使用 priority_queue,其中顾客具有两种优先级中的一种: 企业顾客和普通顾客。所有的企业顾客在所有普通顾客之前得到服务。
- stack
头文件定义了 stack,它提供标准的先入后出(First-In LastOut,FILO)语义,这种语义也称为后入先出(FILO)出(LastIn FirstOut,LIFO)语义。和 queue 一样,在容器中插入和删除元素。然而,在堆栈中,最新插入的元素第一个被移除。向堆栈中添加对象元素时,这个元素下面的所有对象都被种住了。stack 容器实现了元素的快速插入和删除(常量时间)。如果需要使用 FILO 语义,则应该使用 stack 结构。例如,错误处理工具可将错误保存在堆栈中,这样管理员可直接读到最新的一条错误。按 FILO 的顺序处理错误通常更有用,因为更新的错误可能会消除较老的错误。
set 和 multiset
set 类模板在头文件中定义。顾名思义,标准库中的 set 保存的是元素的集合,和数学概念中的集合比较类似: 每个元素都是唯一的,在集合中每个元素最多只有一个实例。标准库中的 set 和数学中集合的概念有一点区别: 在标准库中,元素按照一定的顺序保存。排序的原因是当客户枚举元素时,元素能够以这种类型的operator<运算符或用户自定义的比较器得到的顺序出现。set 提供对数时间的禁入、删除和查找操作。这意味着插入和删除操作比 vector 快,但比 list 慢。查找操作比 list 块,但比 vector 慢。与前面所讲的一样,在实际运用中,可使用性能分析器确定哪种容器更快。
当需要保证元素顺序,使插入/删除操作数目和查找操作数目接近,并且尽可能优化这两种操作的性能时,应该使用 set。例如,一家繁忙书店的库存跟踪程序可使用 set来保存图书。库存的图书列表必须在有图书进货或售出时更新,因此插入和删除操作应该快速。客户还需要能查找某本书,因此这个程序还应该提供快速查找功能。
注意:
如果需要保持顺序,而且要求插入、删除和查找操作的性能接近,那么应当优先使用 set 而不是 vector 或list。如果严禁出现重复元素,也应当使用 set。注意,set 不允许重复元素。也就是说,set 中的每个元素都必须唯一。如果要存储重复元素,必须使用头文件中定义的 multiset。
map 和 multimap
注意:
set 和 map 容器都是关联容器,因为它们关联了键和值。将 set 称为关联容器可能会难以理解,因为在 set中,键本身就是值。这些容器会对元素进行排序,因此将这些容器称为排序或有序关联容器。
无序关联容器/哈希表
标准库支持哈希表(hash table),哈希表也称为无序关联容器(unordered associative container)。有 4 个无序关联容器:
unordered_map
unordered_multimap
unordered_set
unordered_multiset
前两个在
这些无序关联容器在行为上和对应的有序关联容器是类似的。unordered_map 和标准的 map 类似,只不过标准的 map 会对元素排序,而 unordered_map 不会对元素排序。这些无序关联容器的插入、删除和查找操作能以平均常量时间完成。最坏情况是线性时间。在无序的容器中查找元素的速度比普通 map 或 set 中的查找速度快得多,在容器中元素数量特别大的情况下尤其如此。第 17 章将介绍这些无序关联容器的工作原理,还将介绍哈希表名称的来历。
bitset
C 和 C++程序员经常将一组标志位保存在单个 int 或 long 中,每个位对应一个标志。程序员通过按位运算符&、|、^、~、<<和>>设置和访问这些位。C++标准库提供了 bitset 类,这个类抽象了这些位操作,因此再也不需要使用这些位运算符了。
头文件定义了 bitset 容器,但是这个容器不是常规意义的容器,因为这个容器没有实现某种特定的可插入或删除元素的数据结构;bitset 有固定大小,不支持迭代器。可将 bitset 想象为可以读写的布尔值序列。然而,和 C 语言中常规的布尔值读写方法不同,bitset 不局限于 int 或其他基本数据类型的大小。因此,能操作40 位的 bitset,也能操作 213 位的 bitset。bitset 的实现会使用实现 N 个位所需的足够存储空间,通过 bitset声明 bitset 时指定 N。
标准库容器小结
总结了标准库提供的容器。表中使用第 4 章介绍的大 O 表示法来表示含 V 个元素的容器的性能特性。N/A 表示这个容器的语义中不存在这个操作。



注意,从技术角度看字符串也是容器。可将字符串想象为字符的容器。因此,下面要描述的一些算法也能用于字符串。注意;
vector 应是默认使用的容器。实际上,vector 中的插入和删除常常快于 list 或 forward list。这是因为现代CPU 上内存和缓存的工作方式,而list 或 forward_list需要先移动到要插入或删除元素的位置.list 或 forward list的内存可能是碎片化的,所以迭代慢于 vector。
算法
除容器外,标准库还提供了很多泛型算法的实现。算法指的是执行某项任务时采取的策略,例如排序任务和搜索任务。这些算法也是用函数模板实现的,因此可用于大部分不同类型的容器。注意,算法一般不属于容器的一部分。标准库采取了一种分离数据(容器)和功能(算法)的方式。尽管这种方式看上去违背了面向对象编程的思想, 但为了在标准库中支持泛型编程,有必要这么做。正交性(orthogonality)指导原则使算法和容器分离开,(几乎)所有算法都可以用于(几乎)所有容器。
注意:
尽管算法和容器在理论上是无关的,但有些容器以类方法的形式提供了某些算法,因为泛型算法在这些特定类型的容器上表现不出色。例如,set 提供了自己的find算法,这个算法比泛型的 find()算法要快。如果提供的话,应该使用容器特定的方法形式的算法,因为通常情况下这些算法更高效或更适合于当前容器。注意,泛型算法并不直接对容器操作。泛型算法使用一种称为迭代器(iterator)的中介。标准库中的每个容器都提供一个迭代器,通过和迭代器可以顺序遍历容器中的元素。不同容器中的不同先代器遵循标准接口,因此算法可以通过迭代器完成计算工作,而不需要关心底层容器的实现。头文件定义了如表 16-2 所示的一些辅助函数,以返回容器的特定迭代器。

注意:
迭代器是算法和容器之间的中介。和迭代器提供了顺序遍历容器中元素的标准接口,因此任何算法都可以操作任何容器。本节概述标准库中可用的算法,但没有给出所有细节。第 17 章将深入探讨迭代器,第 18 章将列举编码示例来演示如何选择算法。要了解所有可用算法的准确原型,请参阅标准库参考资源。
标准库中大约有 100 种算法,下面将这些算法分为不同的类别。除非特别说明,和否则这些算法都在头文件中定义。注意在将以下算法用于元素“序列”时,这个序列是通过迭代器向算法呈现的。
注意:
在查看算法列表时,要记住标准库在设计时考虑了一般性情况,这些一般性情况可能永远也用不到,但是一旦需要,就会非常重要。也许不需要每个算法,也不用担心那些比较迷糊的参数,因为那些参数是为了满足可能发生的一般性情况。重要的是了解哪些算法是可用的,以备不时之需。
- 非修改顺序算法
非修改类的算法查找元素的序列,返回一些有关元素的信息。因为是非修改类的算法,所以这些算法不会改变序列中元素的值或顺序。这类算法包含 3 种算法。表 16-3 列出了对不同非修改类算法的概述。有了这些算法后,几乎不再需要编写 for 循环来帮代值序列了。
| 算法名称 | 算法概要 | 复杂度 |
|---|---|---|
| adjacent_find | 查找有两个连续元素相等或匹配谓词的第一个实例 | O(N) |
| find(),find_if() | 查找第一个匹配值或使谓词返回 true 的元素 | O(N) |
| find_first_of() | 与 find()类似,只是同时搜索多个元素中的某个元素 | O(NM) |
| find_if_not() | 查找第一个使谓词返回 false 的元素 | O(N) |
| find_end() | 在序列中查找最后一个匹配另一个序列的子序列,这个子序列的元素和谓词指定的一致 | O(M*(N -M)) |
| search() | 在序列中查找第一个匹配另一个序列的子序列,这个子序列的元素和谓词指定的一 | O(NM)* |
| search_n() | 查找前n 个等于某个给定值或根据某个谓词和那个值相关的连续元素 | O(N) |
*从 C++17 开始,search()接收一个可选的附加参数,以指定要使用的搜索算法(default_searcher 、boyer_ moore_searcher 或boyer_moore_horspool_searchen。 使用 boyer_moore 搜索算法, 最坏情况下, 模式未找到时的复杂度是 O(N+M), 模式找到时的复杂度为 O(NM)。
搜索算法
这些算法不需要元素是有序的。N 是搜索的序列的大小,M 是要查找的模式的大小。
比较算法
标准库提供了表 16-4 中列出的比较算法。这些算法都不要求排序源序列。所有算法的最差复杂度都为线性复杂度。
| 算法名称 | 算法概要 |
|---|---|
| equal() | 检查相应元素是否相等或匹配谓词,以判断两个序列是否相等 |
| mismatch() | 返回每个序列中第一个出现的和其他序列中同一位置元素不匹配的元素 |
| lexicographical_compare() | 比较两个序列,判断这两个序列的“词典顺序”。将第一个序列中的每一个元素和第二个序列中对应的元素进行比较。如果一个元素小于另一个元素,那么这个序列按照词典顺序在前面。如果两个元素相等,则按顺序比较下一个元素 |
计数算法
| 算法名称 | 算法概要 |
|---|---|
| all_of() | 如果序列为空,或谓词对序列中所有的元素都返回 true,则返回 true,否则返回 false |
| any_off() | 如果谓词对序列中的至少一个元素返回 true,则返回 true;, 否则返回 false |
| none_of() | 如果序列为空,或谓词对序列中所有的元素都返回false,则返回 true; 否则返回 false |
| count(),count_if() | 计算匹配某个值或使谓词返回true 的元素个数 |
修改序列算法
修改算法会修改序列中的一些元素或所有元素。 有些修改算法在原位置修改元素, 因此原始序列发生变化。另一些修改算法将结果复制到另一个不同的序列,所以原始序列没有变化。所有这些修改算法的最坏复杂度都为线性复杂度。表 16-6 汇总了这些修改生法。
| 算法名称 | 算法概要 |
|---|---|
| copy(),copy_backward() | 将一个序列的元素复制到另一个序列 |
| copy_if() | 将一个序列中谓词返回 true 的元素复制到另一个序列 |
| copy_n() | 将一个序列中的所有元素设置为一个新值 |
| fill() | 将一个序列中的所有元素设置为一个新值 |
| fill_n() | 将一个序列中的前n 个元素设置为一个新值 |
| generate() | 调用指定函数,为一个序列中的每个元素生成一个新值 |
| generate_n() | 调用指定函数,为一个序列中的前n 个元素生成一个新值 |
| move(),move_backward() | 将一个序列的元素移到另一个序列。这两个算法使用了高效移动语义(见第9 章) |
| remove(),remove_if(),remove_copy,remove_copy_if() | 删除匹配给定值或使谓词返回 true 的元素,就地删除或将结果复制到另一个不同的序列 |
| replace(),replace_if(),replace_copy(),replace_copy_if | 将匹配给定值或导致谓词返回 true 的所有元素替换为新元素,在原位置蔡换或将结果复制到新序列 |
| rotate(),rotate_copy() | 交换序列的前半部分和后半部分,在原位置操作或将结果复制到另一个不同的序列。两个要交换的子序列不一定要、一样大 |
| sample() | 从序列中选择n 个随机元素 |
| shuffle() random_shuffle() | 随机重排元素, 打乱元素的顺序。可指定用于打乱元素顺序的随机数生成器的属性。random_shuffle()在C++ 14之后已经不赞成使用,在 C++17 中被删除 |
| transform() | 对序列中的每个元素调用一元函数,或对两个队列中的对应元素调用二元函数。这属于原位置转换 |
| unique(),unique_copy() | 在序列中删除连续出现的重复元素,在原位置删除或将结果复制到另一个不同的序列 |
操作算法
操作算法在单独的元素序列上执行函数。C++标准库提供了两种操作算法,如表 16-7 所示。它们的复杂度都是线性复杂度,不要求对原始序列进行排序。
| 算法名称 | 算法概要 |
|---|---|
| for_each() | 对序列中的每个元素执行函数。使用首尾迭代器指定该序列 |
| for_each_n() | 与 for_each()类似,但仅处理序列中的前n 个元素。用开始迭代器以及元素个数(n)指定该序列。 |
交换算法
C++标准库提供如表 16-8 所示的交换算法。
| 算法名称 | 算法概要 |
|---|---|
| iter_swap() swap_ranges() | 交换两个元素或两个元素序列 |
| swap() | 交换两个值,在头文件中定义 |
| exchange() | 用新值蔡换给定值,并返回旧值。在头文件中定义。 |
分区算法
如果谓词返回 true 的所有元素都在谓词返回 false 的所有元素的前面, 则按某个谓词对序列进行分区。 序列中不满足谓词的第一个元素称为分区点(partition poinb。C++标准库提供如表 16-9 所示的分区算法。
| 算法名称 | 算法概要 | 复杂度 |
|---|---|---|
| is_partitioned() | 如果谓词返回 true 的所有元素都在谓词返回 false 的所有元素的前面,就返回true | 线性复杂度 |
| partition() | 对序列进行排序, 使谓词返回 true 的所有元素在谓词返回 false 的所有元素之前,不能保留之前元素在每个分区中的顺序 | 线性复杂度 |
| stable_partition() | 对序列进行排序, 使谓词返回 true 的所有元素在谓词返回 false 的所有元素之前,保留之前元素在每个分区中的顺序 | 线性对数复杂度 |
| partition_copy() | 将一个序列中的元素复制到两个不同的序列中。目标序列的选择依据是谓词 返回的结果,即 true 和 false | 线性复杂度 |
| partition_point() | 返回一个迭代器,使谓词对所有在这个迭代器之前的元素都返回 tue,对所有在这个迭代器之后的元素都返回 false | 对数复杂度 |
排序算法
C++标准库提供了一些不同的排序算法,不同的排序算法有不同的性能保证,如表 16-10 所示。
| 算法名称 | 算法概要 | 复杂度 |
|---|---|---|
| is_sorted() is_sorted_until() | 检查一个序列是否已经排序,或检查哪个子序列已经排序 | 线性复杂度 |
| nth_element() | 重定位序列中的第 n 个元素,使第n 个位置的元素就是排好序之后第 n 个位置的元素。该算法会重新安排所有元素,使第 n 个元素前面的所有元素都小于新的第n 个元素,使第 n 个元素之后的所有元素都大于第 n 个元素 | 线性复杂度 |
| partial_sort() partial_sort_copy() | 只排序序列中的一部分元素,只有前 n 个元素(由迁代器指定)排序,其余元素不排序。在原位置排序,或者复制到新的序列 | 线性对数复杂度 |
| sort() 和 stable_sort() | 在原位置排序,保留重复元素的顺序或不保留 | 线性对数复杂度 |
二叉树搜索算法
下面的二又树搜索算法通常用于已排序的序列。从技术角度看,它们仅要求至少根据要搜索的元素进行分区。这可使用 std::partition()来完成。排好序的序列也满足这个要求。.所有这些算法都具有对数复杂度, 如表 16-11所示。
| 算法名称 | 算法概要 |
|---|---|
| lower_bound() | 查找序列中不小于(即大于或等于)给定值的第一个元素 |
| upper_bound() | 查找序列中大于给定值的第一个元素 |
| equal_range() | 返回 pair,其中包含 lower_bound()和 upper_bound()的结果 |
| binary_search() | 如果在序列中找到给定值,则返回 true,和否则返回 false |
集合算法
集合算法是特殊的修改算法, 对序列执行集合操作, 如表 16-12 所示。 这些算法最适合操作 set 容器的序列,但也能操作大部分容器的排序后序列。
| 算法名称 | 算法概要 | 复杂度 |
|---|---|---|
| inplace_merge() | 在原位置将两个排好序的序列合并 | 线性对数复杂度 |
| merge() | 合并两个排好序的序列,将两个序列复制到一个新的序列 | 线性复杂度 |
| includes() | 确定一个序列中的每个元素是否都在另一个序列中 | 线性复杂度 |
| set_union(),set_intersection(),set_difference(),set_symmetic_difference() | 在两个排好序的序列上执行特定的集合操作, 将结果复制到第三个排好序的序列中 | 线性复杂度 |
堆算法
堆(heap)是一种标准的数据结构,数组或序列中的元素在其中以半排序的方式排序,因此能够快速找到“项部”元素。例如,堆数据结构通常用于实现 priority_queue。通过使用 6 种算法可以对序列进行堆排序,如表 16-13 所示。
| 算法名称 | 算法概要 | 复杂度 |
|---|---|---|
| is_heap() | 检查某个范围内的元素是不是堆 | 线性复杂度 |
| is_heap_until() | 在给定范围的元素堆中查找最大的子范围 | 线性复杂度 |
| make_heap() | 从某个范围的元素中创建堆 | 线性复杂度 |
| push_heap()和pop_heap() | 在堆中添加或删除元素 | 对数复杂度 |
| Sort_heap() | 把堆转换到升序排列的元素范围内 | 线性对数复杂度 |
最大/最小算法
| 算法名称 | 算法概要 |
|---|---|
| clamp() | 确保一个值(y)在给定的最小值to和最大值(ni)之间。如果 v< lo,则返回对 lo 的引用; 如果v> hi,则返回对i 的引用,理则返回对 v的引用 |
| min()和max() | 返回两个或多个值中的最小值或最大值 |
| minmax() | 以 pair方式返回两个或多个值中的最小值和最大值 |
| min_element() max_element() | 返回序列中的最小或最大元素 |
| minmax_element() | 找到序列中的最小和最大元素,把结果返回为 pair |
数值处理算法
头文件提供了下述数值处理算法。这些算法都不要求排序原始序列。所有算法的复杂度都为线性复杂度,如表 16-15 所示。
| 算法名称 | 算法概要 |
|---|---|
| iota() | 用连续递增的值(以给定值开头)填充序列 |
| gcd() | 返回两种整数类型的最大公约数 |
| lcm() | 返回两种整数类型的最小公倍数 |
| adjacent_difference() | 生成一个新的序列, 其中每一个元素都是原始序列中相邻元素对的后一个与前一个之差(或其他二元操作) |
| partial_sum() | 生成一个新的序列, 这个序列中的每个元素是对应元素和原始序列中之前的所有元素的和(或其他二元操作) |
| exlusive_scan() inclusive_scan() | 类似于 partial sum()。如果给定的求和操作具有关联性,则 inclusive 扫描与 partial 扫描相同。但是,inclusive_scan()以不确定的顺序求和,而 partial_sum()从左到右求和,因此对于非关联求和操作,前者的结果不是确定的。exclusive_scan()算法也以不确定顺序求和对于 inclusive_scan(),第 i 个元素包含在第 i 个和值中,与 partial_ sum()相同。对于exclusive scan(),第i 个元素未包含在第i个和值中 |
| transform_exclusive_scan() transform_inclusive_scan() | 对序列中的每个元素应用转换,然后执行 exclusivelinclusive 扫描 |
| accumulate() | “累加”一个序列中所有元素的值。默认行为是计算元素的和,但调用者可以提供不同的二元函数 |
| inner_product() | 与 accumulate()类似,但对两个序列操作。对序列中的并行元素调用二元函数(默认做乘法),通过另一个二元函数(默认做加法)累加结果值。如果序列表示数学矢量,那么这个算法计算矢量的点积 |
| reduce() | 与 accumulate()类似,但支持并行执行。reduce()的计算顺序是不确定的,而 accumulate()是从左到右计算。这意味着如果给定的二元操作是非关联的或不可交换的,则前者的行为是不确定的 |
| transform_reduce() | 对序列中的每个元素应用转换,然后执行 reduce() |
置换算法
序列的置换包含相同的元素,但顺序变了。表 16-16 列出了用于置换的算法。
| 算法名称 | 算法概要 | 复杂度 |
|---|---|---|
| is_permutation() | 如果某个范围内的元素是另一个范围内元素的转换,就返回 | 二次复杂度 |
| next_permutation() prev_permutation() | 修改序列,将序列转换为下一个或前一个排列。如果从正确排序的序列开始,则连续调用其中一个或另一个可以获得元素的所有可能的排列。如果没有更多排列,则返回 | 线性复杂度 |
选择算法
一下子出现这么多种不同功能的算法可能让人难以接受。一开始可能还很难知道如何应用这些算法。不过,既然已经了解有哪些选择,就应能更好地处理程序设计了。后续章节将详细讲解如何在代码中使用这些算法。
标准库中还缺什么
” 尽管标准库非常强大,但并不完美。下面列出了标准库缺乏的内容和不支持的功能:在通过多线程同时访问容器时,标准库不能保证任何线程安全。e ”标准库没有提供任何泛型的树结构或图结构。尽管 map 和 set 通常都实现为平衡二又树,但标准库没有在接口中公开该实现。如果在任务中需要树结构或图结构,例如编写解析器,就需要自己实现或寻找其他库的实现。记住,标准库是可扩展的。可以编写适用于现有算法和容器的容器及算法。因此,如果标准库没有提供需要的内容,可考虑编写兼容标准库的代码。第 21 章将讲解如何自定义和扩展标准库。
理解容器与迭代器
容器概述
标准库中的容器是泛型数据结构,特别适合保存数据集合。使用标准库时,几乎不需要使用标准 C 风格数组、编写链表或者设计堆栈。容器被实现为类模板,因此可利用任何满足以下基本条件的类型进行实例化。除array 和 bitset 外,大部分标准库容器的大小灵活多变,都能自动增长或收缩,以容纳更多或更少的元素。和固定大小的旧的标准 C 风格数组相比,这有着巨大优势。由于本质上标准 C 风格数组的大小是固定的,因此容易受到溢出的破坏。如果数据溢出,轻则导致程序崩溃(因为数据被破坏了),重则导致某些类型的安全攻击。使用标准库容器,程序遇到这种问题的可能性就会小得多。标准库提供了 16 个容器,分为4大类。
顺序容器
vector(动态数组)
deque
list
forward_list
array
关联容器
map
multimap
set
multiset
无序关联容器或哈希表
unordered_map
unordered_multimap
unordered_set
unordered_ multiset
容器适配器
queue
priority_queue
stack
此外,C++的 string 和流也可在某种程度上用作标准库容器,bitset 可以用于存储固定数目的位。标准库中的所有内容都在 std 名称空间中。本书中的例子通常都在源文件中使用 using namespace std;语名覆盖所有范围(干万不要在头文件中使用! ),也可以在自己的程序中更有选择性地选择使用 std 中的哪些符号。
对元素的要求
标准库容器对元素使用值语义(value semantic)。也就是说,在输入元素时保存元素的一份副本,通过赋值运算符给元素赋值,通过析构函数销毁元素。因此,编写要用于标准库的类时,一定要保证它们是可以复制的。请求容器中的元素时,会返回所存副本的引用。如果喜欢引用语义,可存储元素的指针而非元素本身。当容器复制指针时,结果仍然指向同一元素。另一种方式是在容器中存储 std::reference_wrapper。可使用 std::ref()或 std::cref()创建 reference_ wrapper,使引用变得可以复制。reference_wrapper 类模板以及ref和 cref()函数模板在头文件中定义。在容器中,可能存储“仅移动”类型,这是非可复制类型,但当这么做时,容器上的一些操作可能无法编译。“仅移动”类型的一个例子是 std::unique_ptr。
警告:
如果要在容器中保存指针,应该使用 unique_ptr, 使容器成为指针所指对象的拥有者,或者使用 shared_ptr,使容器与其他拥有者共享拥有权。不要在容器中使用 auto_ptr 类(C++17 删除了该类),因为这个类没有正确实现复制操作(就标准库而言)。
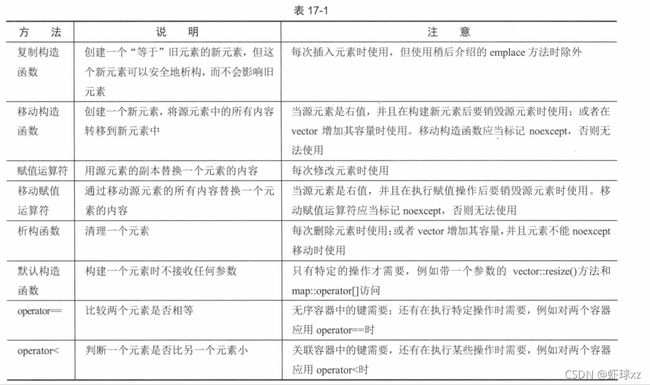
标准库容器的一个模板类型参数是所谓的分配器(allocator)。标准库容器可使用分配器为元素分配或释放内存。分配器类型参数具有默认值,因此几乎总是可以忽略它。有些容器(例如 map)也允许将比较器(comparator)作为模板类型参数。比较器用于排序元素,具有默认值,通常不需要指定。有关使用默认内存分配器和比较器的容器中元素的特别需求在表 17-1 中列出。
第 9 章讲解了如何编写这些方法,并讨论了移动语义。移动语义要正确地用于标准库容器,必须把移动构造函数和移动复制运算符标记为 noexcept。
警告;
标准库容器经常会调用元素的复制构造函数和赋值运算符,因此要保证这些操作的高效性。实现元素的移动语义也可以提高性能,详见第9章。
标准库容器提供非常有限的错误检查功能。客户应确保使用正确。然而,一些容器方法和函数会在特定条件下抛出异常,例如越界索引。不可能全面包罗这些方法抛出的异常,因为这些方法操作的用户自定义类型没有已知的异常特征。本章在恰当的地方提到了异常。可参阅标准库资料,以了解每个方法可能抛出的异常列表。
迭代器
标准库通过迭代器模式提供了访问容器元素使用的泛型抽象。每个容器都提供了容器特定的迭代器,迭代器实际上是增强版的智能指针,这种指针知道如何遍历特定容器的元素。所有不同容器的迭代器都遵循 C++标准中定义的特定接口。因此,即使容器提供不同的功能,访问容器元素的代码也可以使用迭代器的统一接口。可将和迭代器想象为指向容器中特定元素的指针。与指向数组元素的指针一样,迭代器可以通过 operator++移到下一个元素。与此类似,通常还可在迭代器上使用 operator*和 operator->来访问实际元素或元素中的字段。一些和迭代器支持通过 operator==和 operator!=进行比较,还支持通过 operator–转移到前一个元素。所有迭代器都必须可通过复制来构建、赋值,且可以析构。从代器的左值必须是可以交换的。不同容器提供的迭代器具有略微不同的功能。C++标准定义了 5 大类迭代器,如表 17-2 所示。
| 迭代器类别 | 要求的操作 | 注释 |
|---|---|---|
| 输入迭代器(也称为“读”迭代器) | operator++ operator* operator-> 复制构造函数operator= operator== operator!= | 提供只读访问,只能前向访问(没有 operator–提供的后向访问功能)。这个迭代器可以赋值和复制,可以比较判等 |
| 输出迭代器(也称为“写”和迭代器) | operator++ operator* 复制构造函数 operator= | 提供只写访问,只能前向访问。这个迭代器只赋值,不能比较判等输出迭代器的特有操作是*iter = value注意此类和迭代器缺少 operator->提供前缀和后缀 operator++ |
| 前向和迭代器 | 输入和迭代器的功能加上默认构造函数 | 提供读写访问,只能前向访问。这个迭代器可以赋值、复制和比较判等 |
| 双向迭代器 | 前向迭代器的功能加上 operator– | 提供前向迭代器的一切功能。此类迭代器还可以后退到前一个元素提供前级和后组 operator– |
| 随机访问迭代器 | 双向迭代器的功能加上:operator+ operator- operator+= operator-=operator< operator> operator<= operator>= operator[] | 等同于普通指针:此类迭代器支持指针运算、数组索引语法以及所有形式的比较 |
另外,满足输出迭代器要求的迭代器称为“可变迭代器”,和否则称为“不变迭代器”。还可使用 std::distance()计算容器的两个欠代器之间的距离。和迭代器的实现类似于智能指针类,因为它们都重载了特定的运算符。运算符重载详见第 15 章。基本的欠代器操作类似于普通指针(dumb pointer支持的操作,因此普通指针可以合法用作特定容器的迭代器。事实上,vector 迭代器在技术上就是通过简单的普通指针实现的。然而,作为容器的客户,不用关心实现细节;, 只要使用迭代器的抽象就可以了。
注意;
迭代器在内部可能不是实现为指针,因此本书在讨论通过迭代器访问元素时,使用的是“引用”而不是“指向”。本章讲解每个容器使用欠代器的基础知识。第 18 章将深入讨论欠代器和使用欠代器的标准库算法。
注意:
只有顺序容器、有序关联容器和无序关联容器提供了和迭代器。容器适配器和 bitset 类都不支持迭代元素
标准库中每个支持欠代器的容器类都为其从代器类型提供了公共类型别名,名为iterator和const_iterator。例如,整数矢量的const帮代器类型是std::vector::const_iterator。人允许反向和迭代元素的容器还提供了名为reverse_iterator和const_reverse_iterator的公共类型别名。通过这种方式,客户使用容器迭代器时不需要关心实际类型
注意:
const_iterator 和 const_reverse_iterator 提供对容器元素的只读访问。
容器还提供了 begin()和 end()方法。begin()方法返回引用容器中第一个元素的迭代器, end()方法返回的迭代器等于在引用序列中最后一个元素的迭代器上执行 operator+后的结果。begin()和 end()一起提供了一个半开区间,包含第一个元素但不包含最后一个元素。采用这种看似复杂方式的原因是为了支持空区间(不包含任何元素的容器),此时 begin()等于 end()。由 begin()和 end()限定的半开区间常写成数学形式: [begin, end]。
注意:
当为 insert()和 erase()这类容器方法传入迭代器范围时,也采用半开区间的概念。详见本章后面对特定容器的描述。与此类似,还有:返回 const 迭代器的 cbegin()和 cend()方法 返回反向迭代器的 rbegin()和 rend()方法返回 const 反向迭代器的 crbegin()和 crend()方法
注意:
标准库还支持全局非成员函数 std::begin()、end()、cbegin()、cend0、rbegin()、rend()、crbegin0和 crend()。建议使用这些非成员未数而不是其成员版本。本章后面以及后续章节将穿插列举迭代器示例。
顺序容器
vector、deque、list、forward_list 和 array 都称为顺序容器。学习顺序容器的最好方法是学习一个 vector 示例,vector 是默认容器。本节首先详细描述 vector,然后简要描述 deque、list、forward_ list 和 array。熟悉了顺序容器后,就可以很方便地在其中进行切换。
vector
标准库容器 vector 类似于标准 C 风格数组; 元素保存在连续的内存空间中,每个元素都有自己的“模”。可以在 vector 中建立索引,还可以在尾部或任何位置添加新的元素。向 vector 插入元素或从 vector 删除元素通常需要线性时间,但这些操作在 vector 尾部执行时,实际运行时间为摊还常量时间。本节后面的“vector 内存分配方案”部分会详细介绍。随机访问单个元素的复杂度为常量时间。
- vector 概述
vector 在头文件中被定义为一个带有两个类型参数的类模板: 一个参数为要保存的元素类型,另一个参数为分配器(allocaton)类型 。
template<class T,class Allocator = allocator<T>> class Vector;
Allocator 参数指定了内存分配器对象的类型,客户可设置内存分配器,以便使用自定义的内存分配器。这个模板参数具有默认值。
注意:
Allocator 类型参数的默认值足够大部分应用程序使用。本章假定总是使用默认分配器。 第 21 章将提供更多你可能感兴趣的细节。
固定长度的 vector
使用 vector 的最简单方式是将其用作固定长度的数组。vector 提供了一个可以指定元素数量的构造函数,还提供了一个重载的 operator[]以便访问和修改这些元素。C++标准指出: 通过 operator[]访问 vector 边界之外的元素时, 得到的结果是未定义的。也就是说, 编译器可以自行决定如何处理这种情况。 例如, Microsoft Visual C++的默认行为是,在调试模式下编译程序时,会给出运行时错误消息。在发布模式中,出于性能原因这些检查都被禁用了。可以修改这些默认行为。
警告;
与真正的数组索引一样,vector 上的 operator[]没有提供边界检查功能。
除使用 operator[]运算符外,还可通过 at0、front0和 back(0)访问 vector 元素。at()方法等同于 operator[]运算符,区别在于 at()会执行边界检查,如果索引超出边界,at()会抛出 out_of_range 异常。front()和 back()分别返回vector 的第一个元素和最后一个元素的引用。在空的容器上调用 front()和 back()会引发未定义的行为。
警告;
所有 vector 元素访问操作的复杂度都是常量时间。
下面是一个用于“标准化”考试分数的小程序,经过标准化后,最高分设置为 100,其他所有分数都依此进行调整。这个程序创建了一个带有 10 个 double 值的 vector,然后从用户那里读入 10 个值,将每个值除以最高分(再乘以 100),最后打印出新值。为简单起见,这个程序略去了错误检查部分。
vector<double> doubleVector(10); //create vector of 10 doubles//Initialize max to smallest numberdouble max = -numeric_limits::infinity();for(size_t i = 0; i < doubleVector.size();i++){ cout<<"Enter score "<>doubleVector[i]; if(doubleVector[i] > max) { max = doubleVector[i]; }}max /= 100.0;for(auto& element : doubleVector){ element /=; cout<
从这个例子可以看出,可以像使用标准 C 风格数组一样使用 vector。注意第一个 for 循环使用 size()方法确定容器中的元素个数。本例还演示了如何给 vector 使用基于区间的 for 循环。在本例中,基于区间的 for 循环使用的是 auto&而不是 auto,因为这里需要一个引用,才能在每次迭代时修改元素。
注意:
对 vector 应用 operator[]运算符通常会返回一个对元素的引用,可将这个引用放在赋值语句的左侧。如果对const Vector 对象应用 operator[]运算符,就会返回一个对 const 元素的引用,这个引用不能用作赋值的目标。第15 章详细讲解了这个技巧的实现细节。
动态长度的 vector
vector 的真正强大之处在于动态增长的能力。例如,考虑前面的测试分数标准化程序,对这个程序再添加一项要求, 处理任意数量的测试分数。下面是这个程序的新版本:
#include 这个新版本的程序使用默认的构造函数创建了一个不包含元素的 vector。每读取一个分数,便通过push_back()方法将分数添加到 vector 中,push_back()方法能为新元素分配空间。基于区间的 for 循环不需要做任何修改。
vector 详解
前面初步介绍了 vector,下面将深入讲解 vector 的细节。默认的构造函数创建一个不包含元素的 vector。
vector<int> intVector; //Create a vector of ints with zero elements;
可指定元素个数,还可指定这些元素的值,如下所示:
vector<int> intVector(10,100); //Create vector of 10 ints with value 100
如果没有提供默认值,那么对新对象进行 0 初始化。0 初始化通过默认构造函数构建对象,将基本的整数类型(例如 char 和 int 等)初始化为0,将基本的浮点类型初始化为 0.0,将指针类型初始化为 nullptr。还可创建内建类的 vector,如下所示:
vector<string> stringVector(10,"hello");
用户自定义的类也可以用作 vector 元素:
class Element{ public: Element(){}; virtual ~Element() = default;};...vector<int> elementVector;
可以使用包含初始元素的 initializer_list 构建 vector:
vector<int> intVector({1,2,3,4,5,6});
initializer_list 还可以用于第 1 章提到的统一初始化。统一初始化可用于大部分标准库容器。例如:
vector<int> intVector1 = {1,2,3,4,5,6};vector<int> intVector2{1,2,3,4,5,6};
还可以在堆上分配 vector:
auto elementVector = make_unique<vector<Element>>(10);
vector 的复制和赋值
vector 存储对象的副本,其析构函数调用每个对象的析构函数。vector 类的复制构造函数和赋值运算符对vector 中的所有元素执行深度复制。因此,出于效率方面的考虑,应该通过引用或 const 引用向函数和方法传递 vector。有关编写接收模板实例化作为参数的函数的详细信息,请参阅第 12 章。除普通的复制和赋值外,vector 还提供了 assign()方法,这个方法删除所有现有的元素,并添加任意数目的新元素。这个方法特别适合于 vector 的重用。下面是一个简单的例子。intVector 包含 10 个默认值为 0 的元素。然后通过 assign()删除所有 10 个元素,并以 5 个值为 100 的元素代之。
vector<int> intVector(10);//Other codeintVector.assign(5,100);
如下所示,assign()还可接收 initializer_list。intVector 现在有 4 个具有给定值的元素。
intVector.assign({1,2,3,4,5});
vector 还提供了 swap()方法,这个方法可交换两个 vector 的内容,并且具有常量时间复杂度。下面举一个简单示例;
vector<int> vectorOne(10);vector<int> vectorTwo(5,100);vectorOne.swap(vectorTwo);//vectorOne now has 5 elements with the value 100//vectorTwo now has 10 elements with the value 0
vector 的比较
标准库在 vector 中提供了 6 个重载的比较运算符: 和==、!=、<、>、<=和>=。如果两个 vector 的元素数量相等,而且对应元素都相等,那么这两个 vector 相等。两个 vector 的比较采用字典顺序: 如果第一个 vector 中从0到i- 1的所有元素都等于第二个vector中从0到i- 1的所有元素,但第一个vector中的元素i小于第二个 vector中的元素i,其中i在0到n之间,且n 必须小于 size(),那么第一个 vector “小于”第二个 vector; 其中的 size()是指两个 vector 中较小者的大小。
注意;
通过 operator和 operator!=比较两个 vector 时,要求每个元素都能通过 operator运算符进行比较。通过operator<、operator>、operator<=或 operator>=比较两个 vector 时,要求每个元素都能通过 operator<运算符进行比较。如果要在 vector 中保存自定义类的对象,务必编写这些运算符。下面是一个比较元素类型为 int 的两个 vector 的简单程序,
vector<int> vectorOne(10);
vector<int> vectorTwo(10);
if(vectorOne == vectorTwo)
{
cout<<"equal!"<<endl;
}
else
{
cout<<"not equal!"<<endl;
}
vectorOne[3] = 50;
if(vectorOne < vectorTwo)
{
cout<<"vectorOne is less than vectorTwo "<<endl;
}
else
{
cout<<"vectorOne is not less than vectorTwo"<<endl;
}
这个程序的输出为:
equal!vectorOne is not less than vectorTwo
vector 迭代器
节讲解了容器迭代器的基础知识。那一节的讨论比较抽象,因此看一下代码示例会有帮助。下面还是那个将测试分数标准化的程序,将前面基于区间的 for 循环替换成使用迭代器的 for 循环:
for(vector<double>::iterator iter = begin(doubleVector); iter!=end(doubleVector);++iter){ *iter /= max; cout<<*iter<<" "}
首先,看一下 for 循环的初始化语句:
vector<double>::iterator iter = begin(doubleVector);
前面提到,每个容器都定义了一种名为 iterator 的类型,以表示那种容器类型的迭代器。begin()返回引用容器中第一个元素的相应类型的迭代器。因此,这条初始化语句在 iter 变量中获取了引用 doubleVector 中第一个元素的迭代器。下面看一下 for 循环的比较语句:
iter != end(doubleVector);
这条语句检查迭代器是否超越了 vector 中元素序列的尾部。当到达这一点时,循环终止。递增语句++iter;递增迭代器,以引用 vector 中的下一个元素。
注意:
只要可能,尽量使用前递增而不要使用后递增,因为前递增至少效率不会差,一般更高效。iter++必须返回一个新的选代器对象,而++iter 只是返回对 iter 的引用。operator++运算符的实现详见第 15 章。
for 循环体包含以下两行;
*iter /= max;cout<<*iter<<" ";
从中可以看出,这段代码可以访问和修改所迭代的元素。第一行通过*解除引用 iter,从而获得 iter 引用的元素,然后给这个元素赋值。第二行再次解除引用 iter,这次将元素流式输出到 cout。上述使用欠代器的 for 循环可通过 auto 关键字简化:
for(auto iter = begin(doubleVector); iter != end(doubleVector);++iter) { *iter/=max; cout<<*iter<<" "; }
有了 auto,编译器会根据初始化语句右侧的内容自动推导变量 iter 的类型,在这个例子中,初始化语句右侧的内容是调用 begin()得到的结果。访问对象元素中的字段
如果容器中的元素是对象,那么可对迭代器使用->运算符,调用对象的方法或访问对象的成员。例如,下面的小程序创建了包含 10 个字符串的 vector,然后遍历所有字符串,给每个字符串追加一个新的字符串:
vector<string> stringVector(10,"hello");for(auto it = begin(stringVector);it != end(stringVector);++it){ it->append(" there");}
使用基于区间的 for 循环,这段代码可以重写为
vector<string> stringVector(10,"hello");
for(auto & str : stringVector)
{
str.append(" there");
}
const_iterator
普通的迭代器支持读和写。然而,如果对 const 对象调用 begin()和 end(),或调用 cbegin()和 cend(),将得有有到 const_iterator。const_ iterator 是只读的,不能通过 const_iterator 修改元素。iterator 始终可以转换为 const_iterator,因此下面这种写法是安全的:
vector<type>::const_iterator it = begin(myVector);
然而,const_iterator 不能转换为 iterator。如果 myVector 是 const_iterator,那么下面这行代码无法编译:
vector<type>::iterator it = begin(myVector);
注意:
如果不需要修改 vector 中的元素,那么应该使用 const_iterator。遵循这条原则,将更容易保证代码的正确性,还允许编译器执行特定的优化。
在使用 auto 关键字时,const_iterator 的使用看上去有一点区别。假设有以下代码,
vector<string> stringVector(10,"hello");for(auto iter = begin(stringVector);iter != end(stringVector);++iter){ cout<<*iter<<endl;}
由于使用了auto关键字, 编译器会自动判定iter变量的类型,然后将其设置为普通的iterator, 因为stringVector不是 const iterator。 如果需要结合 auto 使用只读的 const_iterator, 那么需要使用 cbegin()和 cend(), 而不是 begin()
vector<string> stringVector(10,"hello");for(auto iter = cbegin(stringVector);iter!=cend(stringVector);++iter){ cout<<*iter<<endl;}
现在编译器会将 iter 变量的类型设置为 const_iterator,因为 cbegin()返回的就是 const_iterator。基于区间的 for 循环也可用于强制使用 const_iterator,如下所示:
vector<string> stringVector(10,"hello");for(const auto& element : stringVector){ cout<<element<<endl;}
迭代器的安全性
通常情况下,和迭代器的安全性和指针接近: 非常不安全。例如,可以编写如下代码:
vector<int> intVector;auto iter = end(intVector);*iter = 10; //BUG! iter doesn't refer to a valid element
此前提到过,end()返回的迭代器越过了 vector 尾部。不是引用最后一个元素的迭代器。试图解除引用这个迭代器会产生不确定的行为。然而,并没有要求欠代器本身执行任何验证操作。如果使用了不匹配的欠代器, 则会引发另一个问题。 例如, 下面的 for 循环初始化 vectorTwo 的一个迭代器,然后试图和 vectorOne 的 end 迭代器进行比较。毫无疑问,这个循环不会按照预想的行为执行,可能永远都不会终止。在循环中解除引用迭代器可能产生不确定的后果。
vector<int> vectorOne(10);vector<int> vectorTwo(10);//Fill in the vectors.//BUG possible infinite loopfor(auto iter = begin(vectorTwo);iter !=end(vectorOne);++iter){ //Loop body}
其他迭代器操作
vector 迭代器是随机访问的,因此可以向前或向后移动,还可以随意跳跃。例如,下面的代码最终将 vector中第 5 个元素(索引为 4)的值改为 4;
vector<int> intVector(10);auto it = begin(intVector);it += 5;--it;*it = 4;
和迭代器还是索引?
既然可以编写 for 循环,使用简单索引变量和 size()方法遍历 vector 中的元素,为什么还要使用友代器? 这问题提得好,主要有 3 个原因,
使用迭代器可在容器的任意位置插入、删除元素或元素序列。详见后面的“添加和删除元素”部分。使用和迭代器可使用标准库算法,详见第 18 章的讨论。通过迭代器顺序访问元素,通常比编制容器索引以单独检索每个元素的效率要高。这种特性不适用于vector,但适用于 list、map 和 set。
在 vector 中存储引用
如本章开头所述, 可在诸如 vector 的容器中存储引用。 为此, 在容器中存储 std::reference_wrapper。std::ref()和 cref()函数模板用于创建非 const 和 const reference_wrapper 实例。需要包含头文件。示例如下:
string str1 = "Hello";string str2 = "World";//Create a vector of references of stringsvector> vec{ref(str1)};vec.push_back(ref(str2)); //push_back() works as well as//Modify the string referred to by the second reference int the vectorvec[1].get() += "!";//The end result is that str2 is actuall modifiedcout<
添加和删除元素
根据前面的描述,通过 push_back()方法可向 vector 追加元素。vector 还提供了删除元素的对应方法:
pop_back()
警告:
pop_back()不会返回已删除的元素。如果要访问这个元素,必须首先通过 back()获得这个元素。通过 insert()方法可在 vector 中的任意位置插入元素,这个方法在迭代器指定的位置添加一个或多个元素,将所有后续元素向后移动,给新元素腾出空间。insert()有 5 种不同的重载形式:
插入单个元素。
插入单个元素的n 份副本。
从某个迭代器范围插入元素。回顾一下,和代器范围是半开区间,因此包含起始欠代器所指的元素,但不包含末尾欠代器所指的元素。
使用移动语义,将给定元素转移到 vector 中,插入一个元素。
向 vector 中插入一列元素,这列元素是通过 initializer_list 指定的。
注意;
push_back()和 insert()还有把左值或右值作为参数的版本。两个版本都根据需要分配内存,以存储新元素。左值版本保存新元素的副本。右值版本使用移动语义,将给定元素的所有权转移到 vector,而不是复制它们。通过 erase()可在 vector 中的任意位置删除元素,通过 clear()可删除所有元素。erase()有两种形式: 一种接收单个迭代器,删除单个元素,另一种接收两个迭代器,删除迭代器指定的元素范围。要删除满足指定条件的多个元素,一种解决方法是编写一个循环来遍历所有元素,然后删除每个满足条件的元素。然而,这种方法具有二次(平方)复杂度,对性能有很大影响。这种情况下,可使用删除-擦除惯用法(remove-erase-idiom),这种方法的复杂度为线性复杂度。第 18 章将讨论删除-擦除惯用法。
-下面的小程序演示了添加和删除元素的方法。它使用一个辅助函数模板 printVector(),将 vector 的内容打印到 cout。第 13 章详细讲解了如何编写函数模板。
template<typename T>
void printVector(const vector<T>& v)
{
for(auto& element : v){ cout<<element<<" ";}
cout<<endl;
}
这个例子还演示了 erase()的双参数版本和 insert()的以下版本:
insert(const_iterator pos,const T& x):将值 x 插入位置 pos。
insert(const_iterator pos,size_type n,const T& x):值x在位置 pos 插入n次。
insert(const_iterator pos,InputIterator first,InputIterator last):将范围[first, last)内的元素插入位置 pos。
该例的代码如下:
vector<int> vectorOne = {1,2,3,5};
vector<int> vectorTwo;
//Oops,we forgot to add 4,Insert it in the correct place
vectorOne.insert(cbegin(vectorOne)+3,4);
//Add elements 6 through 10 to vectorTwo
for(int i = 6;i<=10;i++)
{
vectorTwo.push_back(i);
}
printVector(vectorOne);
printVector(vectorTwo);
//Add all the elements from vectorTwo to the end of vectorOne
vectorOne.insert(cend(vectorOne),cbegin(vectorTwo),cend(vectorTwo));
printVector(vectorOne);
//Now erase the numbers 2 through 5 in vectorOne
vectorOne.erase(cbegin(vectorOne) + 1,cbegin(vectorOne) + 5);
printVector(vectorOne);
//Clear vectorTwo entirely
vectorTwo.clear();
//And add 10 copies of the value 100
vectorTwo.insert(cbegin(vectorTwo),10,100);
//Decide we only want 9 elements
vectorTwo.pop_back();
printVector(VectorTwo);
输出
1 2 3 5
1 2 3 4 5
6 7 8 9 10
1 2 3 4 5
1 2 3 4 5 6 7 8 9 10
1 6 7 8 9 10
100 100 100 100 100 100 100 100 100
回顾一下,和迭代器对表示的是半开区间,而 insert(0将元素添加在和迭代器位置引用的元素之前。因此,可按以下方法将 vectorTwo 的完整内容插入 vectorOne 尾部:
vectorOne.insert(cend(vectorOne),cbegin(vectorTwo),cend(vectorTwo));
把 vector 范围作为参数的 insert() 和 erase()等方法做了如下假定: 头尾迭代器引用的是同一个容器中的元素,尾和迭代器引用头迭代器所在的元素或其后面的元素。如果这些前提条件不满足,这些方法就不能正常工作。
移动语义
所有的标准库容器都包含移动构造函数和移动赋值运算符,从而实现了移动语义(详见第 9 章)。这带来的一大好处是可以通过传值的方式从函数返回标准库容器,而不会降低性能。分析下面这个函数:
vector<int> createVectorOfSize(size_t size){ vector<int> vec(size); int contents = 0; for(auto& i : vec) { i = contents++; } return vec;}vector<int> myVector;myVector = createVectorOfSize(123);
如果没有移动语义,那么将 createVectorOfSize()的结果赋给 myVector 时,会调用复制赋值运算符。有了标准库容器中支持的移动语义后,就可避免这种 vector 复制。相反,对 myVector 的赋值会触发调用移动赋值运算符。
与此类似,push 操作在某些情况下也会通过移动语义提升性能。例如,假设有一个类型为字符串的 vector,如下所示:
string myElement(5,'a'); //Constructs the string "aaaa"vec.push_back(myElement);
然而,由于 myElement 不是临时对象,因此 push_back0O)会生成 myElement 的副本,并存入 vector。vector 类还定义了 push_back(T&& va),这是 push_back(const T& vab)的移动版本。如果按照下列方式调用push_back()方法,则可以避免这种复制:
vec.push_back(move(myElement));
现在可以明确地说,myElement 应移入 vector。 注意在执行这个调用后,myElement 处于有效但不确定的状态。不应再使用 myElement,除非通过调用 clear(0)等使其重返确定状态。也可以这样调用 push_back():
vec.push_back(string(5,'a'));
上述 vec.push_back()调用会触发移动版本的调用,因为调用 string 构造函数后生成的是一个临时 string 对象。push_back()方法将这个临时 string 对象移到 vector 中,从而避免了复制。
emplace 操作
C++在大部分标准库容器(包括 vectoc中添加了对 emplace 操作的支持。emplace 的意思是“放置到位”emplace 操作的一个示例是 vector 对象上的 emplace_back(),这个方法不会复制或移动任何数据,而是在容器中分配空间,然后就地构建对象。例如:
vec.emplace_back(5,'a');
emplace 操作以可变参数模板的形式接收可变数目的参数。第 22 章将讨论可变参数模板(variadic template),但理解如何使用 emplace_back()不需要这些细节。emplace_back()和使用移动语义的 push_back()之间的性能差异取决于特定编译器实现这些操作的方式。大部分情况下,可根据自己喜好的语法来选择。
vec.push_back(string(5,'a'));//Orvec.emplace_back(5,'a');
从 C++17 开始,emplace_back()方法返回已插入元素的引用。在 C++17 之前,emplace_ back()的返回类型是void还有一个 emplace()方法,可在 vector 的指定位置就地构建对象,并返回所插入元素的迭代器。
算法复杂度和迭代器失效
在 vector 中插入或删除元素,会导致后面的所有元素向后移动(给插入的元素腾出空间)或向前移动(将删除元素后空出来的空间填满)。因此,这些操作都采用线性复杂度。此外,引用插入点、删除点或随后位置的所有迭代器在操作之后都失效了。和迭代器并不会自动移动,以便与 vector 中向前或向后移动的元素保持一致, 这项工作需要由你来完成。
还要记住,vector 内部的重分配可能导致引用 vector 中元素的所有迭代器失效,而不只是那些引用插入点或删除点之后的元素的迭代器。
vector 内存分配方案
vector 会自动分配内存来保存插入的元素。回顾一下,vector 要求元素必须放在连续的内存中,这与标准 C风格数组类似。由于不可能请求在当前内存块的尾部添加内存,因此每次 vector 申请更多内存时,都一定要在另一个位置分配一块新的更大的内存块,然后将所有元素复制/移动到新的内存块。这个过程非常耗时,因此vector 的实现在执行重分配时,会分配比所需内存更多的内存,以尽量避免这个复制转移过程。通过这种方式,vector 可避免在每次插入元素时都重新分配内存。
现在,一个明显的问题是,作为 vector 的客户,为什么要关心 vector 内部是如何管理内存的。你也许会认为,抽象的原则应该允许不用考虑 vector 内部的内存分配方案。遗憾的是,必须理解 vector 内部的内存工作原理有两个原因:
(1) 效率。vector 分配方案能保证元素插入采用摊还常量时间复杂度: 也就是说,大部分操作都采用常量时间,但是也会有线性时间(需要重新分配内存时)。如果关注运行效率,那么可控制 vector 执行内存重分配的时机。
(2) 返代器失效。重分配会使引用 vector 内元素的所有迭代器失效。
因此,vector 接口允许查询和控制 vector 的重分配。如果不显式地控制重分配,那么应该假定每次插入都会导致重分配以及所有迭代器失效。
大小和容量
vector 提供了两个可获得大小信息的方法: size()和 capacity()。size()方法返回 vector 中元素的个数,而capacity()返回的是 vector 在重分配之前可以保存的元素个数。因此,在重分配之前还能插入的元素个数为capacity() - Size()。
注意:
通过 empty()方法可以查询 vector 是否为空。vector 可以为空,但容量不能为 0。 C++17 引入了非成员的 std::size()和 std::empty()全局函数。这些与用于获取迭代器的非成员函数(如 std:begin() 和 std::end()等)类似。非成员函数 size()和 empty()可用于所有容器,也可用于静态分配的 C 风格数组(不通过指针访问)以及 initializer_list。下面是一个将它们用于 vector 的例子:
vector<int> vec{1,2,3};cout<<size(vec)<<endl;cout<<empty(vec)<<endl;
预留容量
如果不关心效率和迭代器失效,那么也不需要显式地控制 vector 的内存分配。然而,如果希望程序尽可能高效,或要确保迭代器不会失效,就可以强迫 vector 预先分配足够的空间,以保存所有元素。当然,需要知道vector 将保存多少元素,但有时这是无法预测的。一种预分配空间的方式是调用 reserve()。这个方法负责分配保存指定数目元素的足够空间。稍后将列举使用 reserve()方法的示例。
警告;
为元素预留空间改变的是容量而非大小。也就是说,这个过程不会创建真正的元素。不要越过 vector 大小访问元素。
另一种预分配空间的方法是在构造函数中,或者通过 resize()或 assign()方法指定 vector 要保存的元素数目。这种方法会创建指定大小的 vector(容量也可能就是这么大)。
直接访问数据
vector 在内存中连续存储数据,可使用 data()方法获取指向这块内存的指针。中 C++17 引入了非成员的 std::data()全局函数来获取数据的指针。它可用于 array、vector 容器、字符串、静态分配的 C 风格数组(不通过指针访问)和 initializer_lists 。下面是一个用于 vector 的示例:
vector<int> vec{1,2,3};
int* data1 = vec.data();
int* data2 = data(vec);
- vector 示例: 一个时间片轮转类
计算机科学中的一个常见问题是在有限的资源列表中分配请求。例如,一个简单的操作系统可能保存了一个进程列表,然后给每个进程分配一个时间片(例如 100ms),进程在自己的时间片内完成一些工作。当时间片用完时,操作系统挂起当前进程,然后把时间片给予列表中的下一个进程,让那个进程执行一些操作。这个问题的一种最简单解决方法是时间片轮转调度(round-robin)。当最后一个进程的时间片用完时,调度器返回并开始执行第一个进程。例如,在一个 3 进程的例子中,将第 1 个时间片分配给第 1 个进程,将第 2 个时间片分配给第 2 个进程,将第 3 个时间片分配给第 3 个进程,第 4 个时间片则又回到第 1 个进程。这个循环按照这种方式无限继续下去。假设编写一个通用的时间片轮转调度类,以用于任何类型的资源。这个类应该支持添加和删除资源,还要支持循环遍历资源,以便获得下一资源。尽管可以直接使用 vector,但是通常最好编写一个包装类,以更直接地提供特定应用所需的功能。下例展示了一个 RoundRobin 类模板,其中带有解释代码的注释。首先给出类
定义:
//class template RoundRobin
//Provides simple round-robin semantics for a list of element
template <typename T>
class RoundRobin
{
public:
//Client can give a hint as to the number of expected elements for
//increased efficiency
RoundRobin(size_t numExpected = 0);
virtual ~RoundRobin() = default;
//Prevent assignemnt and pass-by-value
RoundRobin(const RoundRobin& src) = delete;
RoundRobin& operator=(const RoundRobin& rhs) = delete;
//Explicity default a move constructor and move assignment operator
RoundRobin(RoundRobin&& src) = default;
RoundRobin& operator=(RoundRobin&& rhs) = default;
//Appends element to the end of the list, may be called between calls to getNext()
void add(const T& element);
//Removes the first (and only the first) element
//in the list that is equal (with operator==) to element
//May be called between calls to getNext()
void remove(const T& element);
//Returns the next element in the list ,starting with the first
//and cycling back to the first when the end of the list is reached,
//taking into account elements that are added or removed
T& getNext();
private:
std::vector<T> mElements;
typename std::vector<T>::iterator mCurrentElement;
};
从中可以看出,这个公共接口非常简单明了: 只有 3 个方法,再加上构造函数和析构函数。资源都保存在名为 mElements 的 vector 中。和迭代器 mCurrentElement 总是指向下次调用 getNext()返回的元素。如果还没有调用 getNext(),mCurrentElement 就等于 begin(mElements)。注意声明 mCurrentElement 那一行前面的 typename 关键字。目前,该关键字只用于指定模板参数,但它还有另一个用途。当访问基于一个或多个模板参数的类型时,必须显式地指定 typename。在这个例子中,模板参数用于访问和迭代器类型。因此,必须指定 typename。因为 mCurrentElement 数据成员的存在,这个类还避免了赋值和按值传递操作。为了让赋值和按值传递操作能正常工作,应该实现赋值运算符和复制构造函数,并确保 mCurrentElement 在目标对象中是可用的。下面是RoundRobin 类的实现代码, 其中带有解释代码的注释。注意构造函数中 reserve()的使用, 以及add()、remove()和 getNext(中迭代器的大量使用。最有技巧的部分是在 add()和 remove()方法中处理 mCurrentElement。
template<typename T> RoundRobin<T>::RoundRobin(size_t numExpected)
{
//if the client gave a guidelines,reserve that much space
mElements.reserve(numExpected);
//Initialize mCurrentElement event though it isn't used until
//there's at least one element
mCurrentElement = begin(mElements);
}
//Always add the new element at the end
template<typename T>void RoundRobin<T>::add(const T& element)
{
//Event through we add the element at the end ,the vector could
//reallocate and invalite the mcurrentElement iterator with
//the push back() call, Takes advantage of the random-access
//iterator features to save out spot
int pos = mCurrentElement - begin(mElements);
//Add the element
mElements.push_back(element);
//Reset our iterator to make sure it is valid
mCurrentElement = begin(mElements) + pos;
}
template<typename T> void RoundRobin<T>::remove(const T& element)
{
for(auto it = begin(mElements); it != end(mElements);++it)
{
if(*it == element)
{
//Removing an element invalidates the mCurrentElement iterator
//if it refers to an element past the point of the removal
//Take advantage of the random-access features of the iterator
//to track the position of the current element after removal
int newPos;
if(mCurrentElement == end(mElements) - 1 && mCurrentElement == it)
{
//mCurrentElement refers to the last element in the list
//and we are removing that last element,so wrap back to
//the beginning
newPos = 0;
}
else if(mCurrentElement <= it)
{
//Otherwise,if mCurrentElement is before or at the one
//we're removing,the new position is the same as before
newPos = mCurrentElement - begin(mElements);
}
//Erase the element (and ignore the return value)
mElements.erase(it);
//Now reset our iterator to make sure it is valid
mCurrentElement = begin(mElements)+newPos;
return ;
}
}
}
template<typename T>T& RoundRobin<T>::getNext()
{
//First,make sure there are elements
if(mElements.empty())
{
throw std::out_if_range("No elements in the list");
}
//Store the current element which we need to return
auto& toReturn = *mCurrentElement;
//Increment the iterator modulo the number of elements
++mCurrentElement;
if(mCurrentElement == end(mElements))
{
mCurrentElement = begin(mElements);
}
//Return a reference to the element
return toReturn;
}
下面是使用这个 RoundRobin 类模板的调度器的简单实现,其中包含解释代码的注释。
//Simple Process class
class Process final
{
public:
//Contructor accepting the number of the process
//Implementation of doWorkDuringTimeSlice() would let the process
//perform its work for the duration of a time slice
//Actual implementation omitted
void doWorkDuringTimeSlice()
{
cout<<"Process "<<mName<<" performing work during time slice "<<endl;
}
//Needed for the RoundRobin::remove() method to work
bool operator==(const Process& rhs)
{
return mName == rhs.mName;
}
private:
string mName;
};
//Simple round-robin based process schedule
class Schedular final
{
public:
//Contructor takes a vector of processes
Scheduler(const vector<Process>& processes);
//Selects the next process using a round-robin scheduling
//algorithm and allows it to perform some work during
//this time slice
void scheduleTimeSlice();
//Removes the given process from the list of processes
void removeProcess(const Process& process);
private:
RoundRobin<Process> mProcesses;
};
Scheduler::Scheduler(const vector<Process>& processes)
{
//Add the processes
for(auto & process : processes)
{
mProcesses.add(process);
}
}
void Scheduler::scheduleTimeSlice()
{
try
{
mProcesses.getNext().doWorkDuringSlice();
}
catch(const out_of_range&)
{
cerr<<"No more processes to schedule "<<endl;
}
}
void Scheduler::removeProcess(const Process& process)
{
mProcesses.remove(process);
}
int main()
{
vector<Process> processes = (Process("1"),Process("2"),Process("3"));
scheduler scheduler(processes);
for(int i = 0;i<4;++i)
scheduler.scheduleTimeSlice();
scheduler.removeProcess(processes[1]);
cout<<"Removed second process"<<endl;
for(int i = 0; i < 4;++i)
{
scheduler.scheduleTimeSlice();
}
return 0;
}
vector特化
C++标准要求对布尔值的 vector 进行部分特化,目的是通过“打包”布尔值的方式来优化空间分配。布尔值要么是 true,要么是 false,因此可以通过一个位来表示,一个位正好可以表示两个值。C++没有正好保存一个位的原始类型。一些编译器使用和 char 大小相同的类型来表示布尔值。其他一些编译器使用 int 类型。vector特化应该用单个位来存储“布尔数组” 从而节省空间。
注意:
可将 vector表示为位字段(bitfield)而不是 vector。本章后面介绍的 bitset 容器是比 vector功能更全面的位字段实现。然而,vector的优势在于可以动态改变大小。
作为向 vector提供一些位字段例程的非专门性尝试,有一个额外的方法 flip()。这个方法可在容器上调用,此时对容器中的所有元素取反,还可在 operator[]或类似方法返回的单个引用上调用,此时对单个元素取反。那么,可以对布尔值的引用调用方法吗? 答案是不可以。vector特化实际上定义了一个名为 reference的类,用作底层布尔(或位)值的代理。当调用 operator[]、at()或类似方法时,vector返回 reference 对象,这个对象是实际布尔值的代理。
警告;
由于 vector返回的引用实际上是代理,因此不能取地址以获得指向容器中实际元素的指针。在实际应用中,通过包装布尔值而节省一点空间似乎得不偿失。更糟糕的是,访问和修改 vector中的元素比访问 vector中的元素慢得多。很多 C++专家建议,应该避免使用 vector,而是使用 bitset。如果确实需要动态大小的位字段,建议使用 vector
deque
deque(double-ended queue 的简称)几乎和 vector 是等同的,但用得更少。deque 定义在头文件中。 主要区别如下:
不要求元素保存在连续内存中。deque 支持首尾两端常量时间的元素插入和删除操作(vector 只支持尾端的摊还常量时间)。
deque 提供了 push_front()、pop_front()和 emplace_front(),而 vector 没有提供。从 C++17 开始,emplace _front()返回已插入元素的引用而非 void。在开头和末尾插入元素时,deque未使迭代器失效。deque 没有通过 reserve()和 capacity()公开内存管理方案。与 vector 相比,deque 用得非常少。因此,这里不详细讨论。要了解详细的受支持方法,可参阅标准库参
list
list 定义在头文件中, 是一种标准的双链表。list 支持链表中任意位置常量时间的元素插入和删除操作,但访问单独元素的速度较慢(线性时间)。事实上,list 根本没有提供诸如 operator[]的随机访问操作。只有通过和迭代器才能访问单个元素。list 的大部分操作都和 vector 的操作一致,包括构造函数、析构函数、复制操作、赋值操作和比较操作。本节重点介绍那些和 vector 不同的方法。
访问元素
list 提供的访问元素的方法仅有 front()和 back(),这两个方法的复杂度都是常量时间。这两个方法返回链表中第一个元素和最后一个元素的引用。对所有其他元素的访问都必须通过和迭代器进行。list 支持 begin()方法,这个方法返回引用链表中第一个元素的迭代器; 还支持 end()方法,这个方法返回引用链表中最后一个元素之后那个元素的迭代器。与 vector 类似,list 还支持 cbegin()、cend()、rbegin()、rend()、crbegin()和 crend()。
警告
list 不支持元素的随机访问。
迭代器
list 迭代器是双向的,不像 vector 迭代器那样提供随机访问。这意味着 list 迭代器之间不能进行加减操作和其他指针运算。例如,如果 p 是一个 list 迭代器,那么可以通过++p 或–p 遍历链表元素,但是不能使用加减运算符,p+n 和p-n 都是不行的。
添加和删除元素
和 vector 一样,list 也支持添加和删除元素的方法, 包括 push_back()、pop_back()、emplace()、emplace_back()、5 种形式的 insert()以及两种形式的 erase()和 clear()。和 deque 一样,list 还提供了 push_front()、emplace_front()和 pop_front()。list 的奇妙之处在于,只要找到正确的操作位置,所有这些方法(clear()除外)的复杂度都是常量时间。因此, list 适用于要在数据结构上执行很多插入和删除操作, 但不需要基于索引快速访问元素的应用程序。此时,vector 可能更快。可使用性能分析器进行确定。
list 大小
与 deque 一样,但和 vector 不同,list 不公开底层的内存模型。因此,list 支持 size()、empty()和 resize(),但不支持 reserve()和 capacity()。注意,list 的 size()方法具有常量时间复杂度,而 forward_list 的 size()方法不是这样(见稍后的讨论)。
list 特殊操作
list 提供了一些特殊操作, 以利用其元素插入和删除很快这一特性。下面对这些操作进行概述并举一些例子。标准库参考资源提供了所有方法的全面参考。
串联
由于 list 类的本质是链表,因此可在另一个 list 的任意位置串联(splice)或插入整个 list,其复杂度是常量时间。此处要使用的 splice()方法的最简单版本如下,
//Store the a words in the main dictionarylist dictionary{"aardvark","ambulance"};//Stored the b wordslist bWords{"bathos","balderdash"};//Add the c words to the main dictionarydictionary.push_back("canticle");dictionary.push_back("consumerism"); //Splice the b words into the main dictionaryif(!bWords.empty()){ //Get an iterator to the last b word auto iterLastB = --(cend(bWords)); //Iterate up to the spot where we want to insert b words auto it = cbegin(dictionary); for(;it!=cend(dictionary);++it) { if(*it > *iterLastB) break; } //Add in the b words.this action removes the elements from bWords dictionary.splice(it,bWords);}//Print out the dictionaryfor(const auto & word : dictionary){ cout<
运行这个程序的结果如下所示:
aardvarkambulancebathosbalderdashcanticle
splice()还有其他两种形式: 一种是插入其他 list 中的某个元素, 另一种是插入其他 list 中的某个范围。 另外,splice()方法的所有形式都可以使用指向源 list 的普通引用或右值引用。
警告;
串联操作对作为参数传入的 list 来说是破坏性的: 从一个 list 中删除要插入另一个 list 的元素。
更高效的算法版本
除 splice()外,list 类还提供了一些泛型标准库算法的特殊实现。第 18 章将描述泛型算法。这里只讨论 list提供的特殊版本。
注意:
如果可以选择,请使用 list 方法而不是泛型标准库算法,因为前者更高效。有时不必选择,必须使用 list特定方法。例如,泛型算法 std::sort()需要使用 list 没有提供的 RandomAccessJterator。表 17-3 总结了 list 以方法形式提供特殊实现的算法。算法详见第 18 章。
| 方法 | 说明 |
|---|---|
| remove() remove_if() | 从list 中删除特定元素 |
| unique() | 根据 operator==运算符或用户提供的二元谓词,从 list 中删除连续重复元素 |
| merge() | 合并两个 list。在开始前,两个list 都必须根据 operator<运算符或用户定义的比较器排序。与splice(0)类似,merge()对作为参数传入的 list 也具有破坏性 _ |
| sort() | 对 list 中的元素执行稳定排序操作 |
| reverse() | 翻转 list 中元素的顺序 |
list 示例: 确定注册情况
假设要为一所大学编写一个计算机注册系统。要提供的一项功能是从每个班的学生列表中生成大学录取学生的完整列表。 在这个例子中,假定只编写一个方法,这个方法接收以学生姓名(用字符串表示)的 list 为元素的vector,以及因为没有支付学费而退学的学生 list。这个方法应该生成所有课程中所有学生的完整 list,其中没有重复的学生,也没有退学的学生。注意学生可能选择一门以上的课程。下面是这个方法的代码,带有代码注释。由于标准库 list 的巨大威力,这个方法本身比描述信息还要短!注意,在标准库中允许容器嵌套: 在本例中,使用了元素为 list 的 vector。
//courseStudents is a vector of lists,one for each course,The lists
//contain the students enrolled in those cources, They are not sorted
//droppedStudents is list of students who failed to pay thier
//tuition and so where dropped from their courses
//The function returns a list of every enrolled (non-dropped) student in
//all the courses
list<string> getTotalEnrollment(const vector<list<string>>& courseStudents,const list<string>& droppedStudents)
{
list<string> allStudents;
//Concatenate all the course lists onto the master list
for(auto & lst : courseStudents)
{
allStudents.insert(cend(allStudents),cbegin(lst),cend(lst));
}
//Sort the master list
allStudents.sort();
//Remove duplicate student names (those who are in multiple courses)
allStudents.unique();
//Remove student who are on the dropped list
//Iterate through the dropped list,calling remove on the
//master list for each student in the dropped list
for(auto &str : droppedStudents)
{
allStudents.remove(str);
}
//done
return allStudents;
}
注意;
这个示例演示了 list 特定算法的使用。如前所述,vector 通常比 list 更快。因此,对于学生注册问题,建议只使用 vector,并将这些与泛型标准库算法结合在一起。
forward_list
forward_list 在
array
array 类定义在头文件中,和 vector 类似,区别在于 array 的大小是固定的,不能增加或收缩。这个类的目的是让 array 能分配在栈上,而不是像 vector 那样总是需要访问堆。和 vector 一样,array 支持随机访问友代器,元素都保存在连续内存中。array 支持 front()、back()、at()和 operator[],还支持使用 fill()方法通过特定元素将 array 填满。由于 array 大小固定,因此不支持 push_back()、pop_back()、insert()、erase()、clear()、resize()、reserve()和 capacity()。与 vector 相比,array 的缺点是,array 的 swap()方法具有线性时间复杂度, 而 vector 的 swap()方法具有常量时间复杂度。array 的移动不是常量时间,而 vector 是。array 有 size()方法,显然是优于 C 风格数组的。下例展示了如何使用 array 类。注意 array 声明需要两个模板参数,第一个参数指定元素类型,第二个参数指定 array 中元素的固定数量。
//Create an array of 3 integers and initialize them//with the given initialize_list using uniform initializationarrayarr = {9,8,7};//Output the size of the arraycout<<"Array size = "<
可使用 std::get()函数模板,从 std::array 检索位于索引位置 n 的元素。索引必须是常量表达式,不能是循环变量等。使用 std::get()的优势在于编译器在编译时检查给定索引是有效的,否则将导致编译错误,如下所示:
array<int,3> myArray{11,22,33};cout<<std::get<1>(myArray)<<endl;cout<<std::get<10>(myArray)<<endl; //Compilation error!
容器适配器
除标准的顺序容器外,标准库还提供了 3 种容器适配器: queue、priority_ queue 和 stack。每种容器适配器都是对一种顺序容器的包装。它们允许交换底层容器,无须修改其他代码。容器适配器的作用是简化接口,只提供那些 stack 和 queue 抽象所需的功能。例如,容器适配器没有提供迭代器,也没有提供同时插入或删除多个元素的功能。
queue
queue 容器适配器定义在头文件中, queue 提供了标准的“先入先出” 语义。与通常情况一样, queue也写为类模板形式,如下所示:
template<class T,class Container = deque<T>> class queue;
T 模板参数指定要保存在 queue 中的类型。另一个模板参数指定 queue 适配的底层容器。不过,由于 queue要求顺序容器同时支持 push_back()和 pop.front()两个操作,因此只有两个内建的选项: deque 和 list。大部分情况下,只使用默认的选项 deque 即可。
- queue 操作
queue 接口非常简单: 只有 8 个方法, 再加上构造函数和普通的比较运算符。 push()和 emplace()方法在 queue的尾部添加一个新元素,pop()从 queue 的头部移除元素。通过 front()和 back()可以分别获得第一个元素和最后一个元素的引用,而不会删除元素。与其他容器一样,在调用 const 对象时,front()和 back()返回的是 const引用; 调用非 const 对象时,这些方法返回的是非 const 引用(可读写)。
警告:
pop()不会返回弹出的元素。如果需要获得一份元素的副本,必须首先通过 front()获得这个元素。queue 还支持 size()、empty()和 swap()。
警告:
pop()不会返回弹出的元素。如果需要获得一份元素的副本,必须首先通过 front()获得这个元素。queue 还支持 size()、empty()和 swap()。
- queue 示例: 网络数据包缓冲
当两台计算机通过网络通信时,互相发送的信息被分割为离散的块,称为数据包(packe)。计算机操作系统的网络层必须捕捉数据包,并在数据包到达时将数据包保存起来。然而,计算机可能没有足够的带宽同时处理所有数据包。因此,网络层通常会将数据包缓存或保存起来,直到更高的层有机会处理它们。数据包应该以到达的顺序处理,因此这个问题特别适用于 queue 结构。下面是一个简单的 PacketBuffer 类,其中带有解释代码的注释,这个类将收到的数据包保存在 queue 中,直到数据包被处理。这是一个类模板,因此网络层中的不同层可以使用它处理不同类型的数据包,例如 瑟 包或 TCP 包。这个类允许客户指定最大大小,因为操作系统为避免使用过多内存,通常会限制可保存的数据包的数目。当缓冲区变满时,后续到达的数据包都被丢弃了。
#include mPackets; size_t mMaxSize;};template PacketBuffer::PacketBuffer(size_t maxSize) :mMaxSize(maxSize) { }template bool PacketBuffer::bufferPacket(const T& packet){ if(mMaxSize > 0 && mPackets.size() == mMaxSize) { //No more space,Drop the packet return false; } mPackets.push(packet); return true;}template T PacketBuffer::getNextPacket(){ if(mPackets.empty()) { throw std::out_of_range("Buffer is empty"); } //Retrieve the head element T temp = mPackets.front(); //Pop the head element mPackets.pop(); //Return the head element return temp;}class IPPacket final{ public: IPPacket(int id) : mID(id){} int getID() const { return mID; } private: int mID;};
这个类的实际应用需要使用多线程。C++提供了一些同步类,人允许对共享对象的线程进行安全访问。如果没有提供显式的同步, 那么当至少一个线程修改标准库对象时, 任何标准库对象都无法安全地用于多线程环境。第 23 章将讨论同步。本例的焦点是 queue 类,所以这是一个使用了 PacketBuffer 的单线程示例;
int main(){ PacketBuffer<IPPacket> ipPacket(3); //Add 4 packets for(int i = 1; i <= 4;++i) { if(!ipPacket.bufferPacket(IPPacket(i))) { cout<<"Packet "<
输出
Packet 4 dropped (queue is full)Processing packet 1Processing packet 2Processing packet 3Queue is empty
priority_queue
优先队列(priority queue)是一种按顺序保存元素的队列。优先队列不保证严格的 FIFO 顺序,而是保证在队列头部的元素任何时刻都具有最高优先级。这个元素可能是队列中最老的那个元素, 也可能是最新的那个元素。如果两个元素的优先级相等,那么它们在队列中的相对顺序是未确定的。
priority_ queue 容器适配器也定义在中。其模板定义如下(稍有简化):
template<class T,class Container = vector<T>,class Compare = less<T>>;
这个类没有看上去这么复杂。之前看到了前两个参数: T是 priority_queue 中保存的元素类型,Container 是priority queue 适配的底层容器。priority_queue 默认使用 vector,但是也可以使用 deque。这里不能使用 list,因为priority_ queue 要求随机访问元素。第 3 个参数 Compare 复杂一些。正如第 18 章将要介绍的,less 是一个类模板,支持两个类型为工的元素通过 operator<运算符进行比较。也就是说,要根据 operator<来确定队列中元素的优先级,可以自定义这里使用的比较操作,但这是第 18 章的内容。目前,只要保证为保存在 priority_queue 中的类型正确定义了 operator<即可。
priority_queue 的头元素是优先级最高的元素,默认情况下优先级是通过 operator<运算符来判断的,比其他元素“小”的元素的优先级比其他元素低。
\1. priority_queue 提供的操作
priority_queue 提供的操作比 queue 还要少。push()和 emplace()可以插入元素,pop()可以删除元素,top()可以返回头元素的 const 引用。
警告:
在非 const 对象上调用 top(),top()返回的也是 const 引用,因为修改元素可能会改变元素的顺序,所以不多许修改。priority_queue 没有提供获得尾元素的机制。
警告:
pop()不返回弹出的元素。如果需要获得一份副本,必须首先通过 top()获得这个元素。与 queue 一样,priority_queue 支持 size()、empty()和 swap()。然而,priority_queue 没有提供任何比较运算符。
\2. priority_queue 示例: 错误相关器
系统上的单个故障通常会导致不同组件生成多个错误。优秀的错误处理系统通过错误相关性首先处理最重要的错误。通过 priority_queue 可以编写一个非常简单的错误相关器(error correlation)。 假设所有的错误事件都编码了自己的优先级。下面这个类根据优先级对错误事件进行排序,因此优先级最高的错误总是最先处理。这个类的定义如下:
//Sample Error class with just a priority and a string error descriptionclass Error final{ public: Error(int priority,std::string_view errorString) :mPriority(priority),mErrorString(errorString){} int getPriority() const{ return mPriority;} std::string_view getErrorString() const { return mErrorString;} private: int mPriority; std::string mErrorString;};bool operator<(const Error& lhs,const Error& rhs);std::ostream& operator<<(std::ostream& os,const Error& err);//Simple ErrorCorrelation class that returns highest priority errors firstclass ErrorCorrelator final{ public: //Add an error to be correlated void addError(const Error& error); //Retrieve the next error to be processed Error getError(); private: std::priority_queuemErrors;};
下面是函数和方法的定义
bool operator<(const Error& lhs,const Error& rhs){ return (lhs.getPriority() < rhs.getPriority());}ostream& operator<<(ostream& os,const Error& err){ os<<err.getErrorString()<<" (priority "<<err.getPriority()<<")"; return os;}void ErrorCorrelator::addError(const Error& error){ mErrors.push(error);}Error ErrorCorrelator::getError(){ //If there are no more errors,throw an exception if(mErrors.empty()) { throw out_of_range("No more errors"); std::cout<<"\n-------------------------------------------------------\n"; } //Save the top element Error top = mErrors.top(); //Remove the top element mErrors.pop(); //Return the saved element return top;}
下面这个简单的单元测试展示了 ErrorCorrelator 的用法。在真实世界中,要求使用多线程,这样,一个线程添加错误,另一个线程处理错误。如之前的 queue 示例所示,这需要显式地提供同步,参见第 23 章。
int main(){ ErrorCorrelator ec; ec.addError(Error(3,"Unable to read file")); ec.addError(Error(1,"Incorrect entry from user")); ec.addError(Error(10,"Unable to allocate memory!")); while(true) { try { Error e = ec.getError(); cout<<e<<endl; } catch(const out_of_range&) { cout<<"Finished processing errors"<<endl; break; } } return 0;}
输出
xz@xiaqiu:~/study/test/test$ ./testUnable to allocate memory! (priority 10)Unable to read file (priority 3)Incorrect entry from user (priority 1)Finished processing errors
stack
stack 和 queue 几乎相同,区别在于 stack 提供先入后出(FILO)的语义,这种语义也称为后入先出,以区别于FIFO。stack 定义在头文件中。模板定义如下所示:
template<class T,class Container = deque<T>> class stack;
可将 vector、list 或 deque 用作 stack 的底层容器。
- stack 操作
与 queue 类似,stack 提供了 push()、emplace()和 pop()。区别在于: push()在 stack 顶部添加一个新元素,将之前插入的所有元素都“向下推” 而 pop()从 stack 顶部删除一个元素,这个元素就是最近插入的元素。如果在const 对象上调用,top()方法返回项部元素的 const 引用; 如果在非 const 对象上调用,top()方法返回非 const 引用。
警告;
pop()不返回弹出的元素。如果需要获得一份副本,必须首先通过 top()获得这个元素。stack 支持empty()、size()、swap()和标准的比较运算符。
- stack 示例: 修改后的错误相关器
可重写之前的 ErorCorrelator 类,使其给出最新错误而不是最高优先级的错误。唯一要修改的是将priority_queue 的 mErrors 替换为 stack,现在,错误以 LIFO 顺序而不是优先级顺序分发。方法定义不需要做任何修改,因为 priority_ queue 和 stack 中都有 push()、pop()、top()和 empty()方法。
#include 输出
xz@xiaqiu:~/study/test/test$ ./testUnable to allocate memory! (priority 10)Incorrect entry from user (priority 1)Unable to read file (priority 3)Finished processing errors
有序关联容器
与顺序容器不同,有序关联容器不采用线性方式保存元素。相反,有序关联容器将键映射到值。通常情况下,有序关联容器的插入、删除和查找时间是相等的。标准库提供的 4 个有序关联容器分别为 map、multimap、set 和 multiset。每种有序关联容器都将元素保存在类似于树的有序数据结构中。还有 4 个无序关联容器: unordered_map、unordered multimap、unordered_set和 unordered_multiset。它们在本章后面讨论。 .
pair 工具类
在学习有序关联容器之前,首先要熟悉 pair 类,这个类在头文件中定义。pair 是一个类模板,它将两个可能属于不同类型的值组合起来。通过 first 和 second 公共数据成员访问这两个值.Pair 类定义了 operator==和 operator<,用于比较 first 和 second 元素。下面给出了一些示例:
//Two-argument constructor and default constuctor
pair<string,int>myPair("hello",5);
pair<string,int>myOtherPair;
//Can assign directly to first and second
myOtherPair.first = "hello";
myOtherPair.second = 6;
//Copy constructor
pair<string,int>myThirdPair(myOtherPair);
//operator<
if(myPair < myOtherPair)
{
cout<<"myPair is less than myOtherPair"<<endl;
}
else
{
cout<<"myPair is greater than or equal to myOtherPair"<<endl;
}
//operator==
if(myOtherPair == myThirdPair)
{
cout<<"myOtherPair is equal to myThirdPair"<<endl;
}
else
{
cout<<"myOtherPair is not equal to myThirdPair"<<endl;
}
输出
myPair is less than myOtherPair
myOtherPair is equal to myThirdPair
这个库还提供了一个工具函数模板 make_pair(),用于从两个值构造一个 pair。例如;
pair<int,double>aPair = make_pair(5,10.10);
当然,在本例中,用两个参数的构造函数就可以了。然而,如果需要向函数传递 pair,或者把它赋予已有的变量,那么 make_pair()更有用。与类模板不同,函数模板可从参数中推导类型,因此可通过 make_pair()构建一个 pair,而不需要显式地指定类型。还可结合使用 make_pair()与 auto 关键字:
auto aSecondPair = make_pair(5,10.10)
如第 12 章所述,C++17 引入了构造函数的模板参数推导。这样就可以忘掉 make_pair(),只需要编写:
auto aThirdPair = pair(5,10.10);
结构化绑定是另一个 C++17 特性(在第 1 章中介绍过),可用于将 pair 的元素分解为单独的变量。下面是一个示例:
pair<string,int> myPair("hello",5);
auto[theString,theInt] = myPair;//Decompose using structured bindings
cout<<"theString: "<<theString<<endl;
cout<<"theInt: "<<theInt<<endl;
map
map 定义在头文件中,它保存的是键/值对,而不是只保存值。插入、查找和删除操作都是基于键的,值只不过是附属品。从概念上讲,map 这个术语源于容器将键“映射”到值。map 根据键对元素排序存储,因此插入、删除和查找的复杂度都是对数时间。由于排好了序,因此枚举元素时,元素按类型的 operator<或用户定义的比较器确定的顺序出现。通常情况下,map 实现为某种形式的平衡树,例如红黑树。不过,树的结构并没有向客户公开。当需要根据键保存和获取元素时,以及需要按特定顺序保存元素时,应该使用 map。
构建 map
map 类模板接收 4 种类型: 键类型、值类型、比较类型以及分配器类型。和以往一样,本章不考虑分配器。比较类型和之前描述的 priority_queue 中的比较类型类似, 允许提供与默认不同的比较类。本章只使用默认的less比较。使用默认的比较类型时,要确保键都支持 operator<运算符。第 18 章将解释如何编写自己的比较类。如果忽略比较参数和分配器参数,那么 map 的构建和 vector 或list 的构建是一样的,区别在于,在模板实例化中需要分别指定键和值的类型。例如,下面的代码构建了一个 map,它使用 int 值作为键,保存 Data 类的
class Data final
{
public:
explicit Data(int value = 0) : mValue(value){}
int getValue() const{ return mValue;}
void setValue(int value){mValue = value;}
private:
int mValue;
};
...
map<int,data> dataMap;
map 还支持统一初始化机制:
map<string,int>m =
{
{"Marc G",124},
{"Warren B",456},
{"Peter",786}
};
\2. 插入元素
向顺序容器(例如 vector 和 list插入元素时,总是需要指定要插入元素的位置,而 map 和其他关联容器不需要指定位置。map 的内部实现会判定要保存新元素的位置,只需要提供键和值即可。
注意:
map 和其他有序关联容器提供了接收选代器位置作为参数的 insert()方法。然而,这个位置只是容器找到正确位置的一种“提示” 。不强制容器在那个位置插入元素。在插入元素时,一定要记住 map 需要“唯一键” map 中的每个元素都要有不同的键。如果需要支持多个带有同一键的元素,有两个选择: 可使用 map,把另一个容器(如 vector 或 array)用作键的值,也可以使用后面描述的 multimap 。
insert()方法
可使用 insert()方法向 map 添加元素,它有一个好处: 允许判断键是否已经存在。insert()方法的一个问题是必须将键/值对指定为 pair 对象或 initializer_list。insert()的基本形式的返回类型是迭代器和布尔值组成的 pair。返回类型这么复杂的原因是,如果指定的键已经存在,那么 insert()不会改写元素值。返回的 pair 中的 bool 元素指出,insert0是否真的插入了新的键/值对。和迭代器引用的是 map 中带有指定键的元素(根据插入成功与否,这个键对应的值可能是新值或旧值)。继续前面的 map 示例,可采用以下方式使用 insert():
map<int,data> dataMap;
auto ret = dataMap.insert({1,Data(4)}); //Using an initializer_list
if(ret.second)
{
cout<<"Insert succeeded "<<endl;
}
else
{
cout<<"Insert failed!"<<endl;
}
ret = dataMap.insert(make_pair(1,Data(6))); //Using a pair object
if(ret.second)
{
cout<<"Insert succeeded!"<<endl;
}
else
{
cout<<"Insert failed!"<<endl;
}
ret 变量的类型是 pair,如下所示;
pair<map<int,Data>::iterator,bool>ret;
pair 的第一个元素是键类型为 int、值类型为 Data 的 map 和迭代器。该 pair 的第二个元素为布尔值。程序的输出如下所示
Insert succeeded!
Insert failed!
中 ”使用让语句的初始化器(C++17),只使用一条语句,即可将数据插入 map 并检查结果,如下所示;
if(auto result = dataMap,insert({1,Data(4)}) : result.second)
{
cout<<"Insert sucessed! "<<endl;
}
else
{
cout<<"Insert failed!"<<endl;
}
甚至可将其与 C++17 结构化绑定结合使用:
if(auto [iter,success] = dataMap,insert({1,Data(4)}):success)
{
cout<<"Insert successed!"<<endl;
}
else
{
cout<<"Insert failed!"<<endl;
}
insert_or_assign()方法
insert_or_assign()与 insert()的返回类型类似。但是,如果已经存在具有给定键的元素,insert_or_assign()将用新值重写旧值,而 insert()在这种情况下不重写旧值。与 insert()的另一个区别在于,insert_or_assign()有两个独立的参数: 键和值。下面是一个示例:
ret = dataMap.insert_or_assign(1,Data(7));
if(ret.second)
{
cout<<"Inserted "<<endl;
}
else
{
cout<<"Overwritten"<<endl;
}
operator[]
向 map 插入元素的另一种方法是通过重载的 operator[]。 这种方法的区别主要在于语法: 键和值是分别指定的。此外,operator[]总是成功。如果给定键没有对应的元素值,就会创建带有对应键值的新元素。如果具有给定键的元素已经存在,operator[]会将元素值蔡换为新指定的值。下例用 operator[]替代了 insert():
map<int,Data>dataMap;
dataMap[1] = Data(4);
dataMap[1] = Data(6); //Replaces the element with key 1
不过,operator[]有一点要注意: 它总会构建一个新的值对象,即使并不需要使用这个值对象也同样如此。因此,需要为元素值提供一个默认的构造函数,从而可能会比 insert()的效率低。如果请求的元素不存在,operator[]会在 map 中创建一个新元素,所以这个运算符没有被标记为 const。尽管这很明显,但有时可能会看上去违背常理。例如,假设有下面这个函数,
void func(const map<int,int>& m)
{
cout<<m[1]<<endl;//Error
}
。 这段代码无法成功编译,尽管看上去只是想读取 m[1]的值。这段代码编译失败的原因是: 变量 m 是对 map的 const 引用,而 operator[]没有被标记为 const。因此应该使用后面“查找元素”部分描述的 find()方法。
emplace 方法
map 支持 emplace()和 emplace_hint(),从而在原位置构建元素,这与 vector 的 emplace 方法类似。C++17 添加了try_emplace()方法,如果给定的键尚不存在,则在原位置插入元素, 如果 map 中已经存在相应的键,则什么都不做。
map 迭代器
map 迭代器的工作方式类似于顺序容器的迭代器。主要区别在于迭代器引用的是键值对,而不只是值。如果要访问值,必须通过 pair 对象的 second 字段来访问。下面展示了如何遍历前一个示例中的 map:
for(auto iter = cbegin(dataMap);iter != cend(dataMap);++iter)
{
cout<<iter->second.getValue()<<endl;
}
再来分析用于访问值的表达式:
iter->second.getValue();
iter 引用了一个键值对,因此可通过->运算符访问这个 pair 的 second 字段,这个字段是一个 Data 对象。然后调用这个 data 对象的 getValue()方法。
注意,下面的代码功能等效:
(*iter).second.getValue();
使用基于区间的 for 循环,可按如下更优美的方式编写循环:
for(const auto& p : dataMap)
{
cout<<p.second.getValue()<<endl;
}
结合使用基于范围的 for 循环与 C++17 结构化绑定,实现方式会更好;
for(const auto & [key,data] : dataMap)
{
cout<<data.getValue()<<endl;
}
警告;
可通过非 const 迭代器修改元素值,但是如果试图修改元素的键(即使通过非 const 迭代器来修改),编译器会生成错误,因为修改键会破坏 map 中元素的排序。
- 查找元素
map 可根据指定的键查找元素,复杂度为指数时间。如果知道指定键的元素存在于 map 中,那么查找它的最简单方式是,只要在非 const map 或对 map 的非 const 引用上调用,就通过 operator[]进行查找。operator[]的好处在于返回可直接使用和修改的元素引用,而不必考虑从 pair 对象中获得值。下面是对之前示例的扩展,这里对键为 1 的 Data 对象值调用了 setValue()方法。
map<int,Data> dataMap;
dataMap[1]= Data(4);
dataMap[1]= Data(6);
dataMap[1].setValue(100);
然而,如果不知道元素是否存在,就不能使用 operator[]。因为如果元素不存在,这个运算符会插入一个包含相应键的新元素。作为蔡换方案,map 提供了 find()方法。如果元素在 map 中存在,这个方法返回指向具有指定键的元素的欠代器;如果元素在 map 中不存在,则返回 end()和迭代器。下面的示例通过 find()方法对键为 1的 Data 对象执行同样的修改操作:
auto it = dataMap.find(1);
if(it != end(dataMap))
{
it->second.setValue(100);
}
从以上代码可以看出,使用 find()有点笨拙,但有时这是必要的。如果只想知道在 map 中是和否存在具有给定键的元素,那么可以使用 count()成员函数。这个函数返回 map中给定键的元素个数。对于 map 来说,这个函数返回的结果不是 0 就是 1,因为 map 中不允许有具有重复键的元素。
- 删除元素
map 允许在指定的迭代器位置删除一个元素或删除指定迭代器范围内的所有元素,这两种操作的复杂度分别为推还常量时间和对数时间。从客户的角度看,用于执行上述操作的两个 erase()方法等同于顺序容器中的erase()方法。而 map 的一项很好的功能是,它还提供了另一个 erase()版本,用于删除匹配键的元素。下面是一个示例:
map<int,Data> dataMap;
dataMap[1] = Data(4);
cout<<"There are "<<dataMap.count(1)<<" elements with key i"<<endl;
dataMap.erase();
cout<<"There are "<<dataMap.count(1)<<" elements with key 1"<<endl;
输出如下所示;
There are 1 elements with key 1
There are 0 elements with key 1
- 节点
所有有序和无序的关联容器都被称为基于节点的数据结构.从 C++17 开始, 标准库以节点句柄(node handle)的形式,提供对节点的直接访问。确切类型并未指定,但每个容器都有一个名为 node type 的类型别名,它指定容器节点句柄的类型。节点句柄只能移动,是节点中存储的元素的所有者。它提供对键和值的读写访问。可基于给定的迭代器位置或键,从关联容器(作为节点句柄)提取节点。从容器提取节点时,将其从容器中删除,因为返回的节点句柄是所提取元素的唯一拥有者。 ,
C++提供了新的 insert()重载,以允许在容器中插入节点句柄。使用 extract()来提取节点句柄,使用 insert()来插入节点句柄,可有效地将数据从一个关联容器传递给另一个关联容器,而不需要执行任何复制或移动。甚至可将节点从 map 移到 multimap,从 set 移到 multiset。继续刚才的示例,下面的代码片段将键为 1 的节点转到第二个 map:
map dataMap2;
auto extractedNode = dataMap.extract(1);
dataMap2.insert(std::move(extractedNode));
可将最后两行合并为一行;
dataMap2.insert(dataMap.extract(1));
还有一个操作 merge(),可将所有节点从一个关联容器移到另一个关联容器。无法移动的节点(因为会导致问题,比如在不允许复制的目标容器中进行复制)留在源容器中。一个示例如下:
map<int,int> src = {{1,11},{2,22}};
map<int,int> dest = {{2,22},{3,33},{4,44},{5,55}};
dst.merge(src);
完成合并操作后,src 仍然包含一个元素{2, 22},因为目标已经包含这个元素,所以无法移动。操作后,dst包含{1 11}、f2, 22}、{3,33}、{4, 44}和{5, 55}。
map 示例: 银行账号
通过 map 可实现一个简单的银行账号数据库。一种常用模式是使用类或结构体的一个字段作为保存在 map中的键。在本例中,这个键就是账号。下面是简单的 BankAccount 类和 BankDB 类:
class BankAccount final
{
public:
BankAccount(int acctNum,std::string_view name)
:mAcctNum(acctNum),mClientName(name){}
void setAcctNum(int acctName){mAcctNum = acctName;}
int getAcctNum() const{ return mAcctNum; }
void setClientName(std::string_view name){ mClientName = name;}
std::string_view getClientName() const{ return mClientName; }
private:
int mAcctNum;
std::string mClientName;
};
class BankDB final
{
public:
//Adds account to the bank database, if an account exists already
//with that number,the new account is not added,Returns true
//if the account is added,false if it's not
bool addAccount(const BankAccount& account);
//Removes the account accNum from the database
void deleteAccount(int acctNum);
//Returns a reference to the account represented
//by its number or the client name
//Throw out_of_range if the account is not found
BankAccount& findAccount(int acctNum);
BankAccount& findAccount(std::string_view name);
//Adds all the accounts from db to this database
//Deletes all the accounts from db
void mergeDatabase(BankDB& db);
private:
std::map<int, BankAccount> mAccounts;
};
下面是 BankDB 方法的实现,其中带有代码注释;
bool BankDB::addAccount(const BankAccount& acct)
{
//Do the actual insert,using the account number as the key
auto res = mAccounts.emplace(acct.getAcctNum(),acct);
//or;auto res = mAccounts.insert(make_pair(acct.getAcctNum(),acct));
//Return the bool field of the pair specifying success or failure
return res.second;
}
void BankDB::deleteAccount(int acctNum)
{
mAccounts.erase(acctNum);
}
BankAccount& BankDB::findAccount(int acctNum)
{
//Finding an element via its key can be done with find()
auto it = mAccounts.find(acctNum);
if(it == end(mAccounts))
{
throw out_of_range("No account with that number.");
}
//Remember that iterators into maps refer to pairs of key/value
return it->second;
}
BankAccount& BankDB::findAccount(string_view name)
{
//Finding an element by a non-key attribute requires a linear
//search through the elements Uses c++17 structured bindings
for(auto &[acctNum,account]:mAccounts)
{
if(account.getClientName() == name)
{
return account; //found it!
}
}
//if your compiler doesn't support the above c++17 structured
//bindings yet,you can use the following implementation
//for(auto& p : mAccounts)
//{
// if(p.second.getClientName() == name) {return p.second; }
//}
throw out_of_range("No account with that name");
}
void BankDB::mergeDatabase(BankDB& db)
{
//Use C++17 merge()
mAccounts.merge(db.mAccounts);
//Or:mAccounts.insert(begin(db.mAccounts),end(db.mAccounts));
//Now clear the source database
db.mAccounts.clear();
}
下面是 BankDB 方法的实现,其中带有代码注释;
int main()
{
BankDB db;
db.addAccount(BankAccount(100,"Nich"));
db.addAccount(BankAccount(200,"Scott"));
try
{
auto& acct = db.findAccount(100);
cout<<"Found account 100"<<endl;
acct.setClientName("Nich");
auto& acct2 = db.findAccount(1000);
}
catch(const out_of_range& caughtException)
{
cout<<"Unable to find account: "<<caughtException.what()<<endl;
}
return 0;
}
输出
xz@xiaqiu:~/study/test/test$ ./test
Found account 100
Unable to find account: No account with that number.