操作系统课程设计-进程管理
1.题目要求描述
本设计的目的是加深对进程概念及进程管理各部分内容的理解;熟悉进程管理中主要数据结构的设计及进程调度算法、进程控制机构的实施。要求设计一个允许n个进程并发运行的进程管理模拟系统。该系统包括有简单的进程控制,其进程调度算法可任意选择。每个进程用一个PCB表示,其内容根据具体情况设置。具体要求如下:
⑴设计一个模拟进程调度的系统;
(2)采用FCFS先来先服务调度算法,SPF短进程优先调度算法,HPF优先级调度算法,RR时间片轮转调度算法,HRRN高响应比优先调度算法
⑶自己根据算法需要确定PCB中的数据结构;
⑷能够显示进程的运行状态包括进程状态、占用CPU时间、要求服务时间等信息。
2.程序流程图及源代码注释
源代码注释
/*
* 用于判断给出的调度策略是否属于实时类(SCHED_RR和SCHED_FIFO)
*/
static inline int rt_policy(int policy)
{
if (unlikely(policy == SCHED_FIFO || policy == SCHED_RR))
return 1;
return 0;
}
/*
* 检测进程是否关联到实时调度策略
*/
static inline int task_has_rt_policy(struct task_struct *p)
{
return rt_policy(p->policy);
}
/*
* 这是RT调度类的优先级队列数据结构:
*/
struct rt_prio_array {
DECLARE_BITMAP(bitmap, MAX_RT_PRIO+1); /* 包含1位分隔符 */
/*
* 具有相同优先级的所有实时进程都保存在一个链表中
*/
struct list_head queue[MAX_RT_PRIO];
};
struct rt_bandwidth {
/* 嵌套在rq锁中: */
spinlock_t rt_runtime_lock;
ktime_t rt_period;
u64 rt_runtime;
struct hrtimer rt_period_timer;
};
//start_rt_bandwidth调用函数来完成rt_bandwidth高精度时钟的激活
static void start_rt_bandwidth(struct rt_bandwidth *rt_b)
{
ktime_t now;//等于now纳秒
if (!rt_bandwidth_enabled() || rt_b->rt_runtime == RUNTIME_INF)//如果rt_bandwidth_enabled()返回值为faulse且rt_b->rt_runtime == RUNTIME_INF;
return;
if (hrtimer_active(&rt_b->rt_period_timer))//如果hrtimer_active(&rt_b->rt_period_timer)返回值为true
return;
spin_lock(&rt_b->rt_runtime_lock);//调用函数
for (;;) {
unsigned long delta;
ktime_t soft, hard;
/*定时器的到期时间用ktime_t来表示,_
* softexpires字段记录了时间,定时器一旦到期,
* function字段指定的回调函数会被调用,
* 该函数的返回值为一个枚举值,
* 它决定了该hrtimer是否需要被重新激活:
*/
if (hrtimer_active(&rt_b->rt_period_timer))//如果hrtimer_active(&rt_b->rt_period_timer)返回值为true
break;
now = hrtimer_cb_get_time(&rt_b->rt_period_timer);
hrtimer_forward(&rt_b->rt_period_timer, now, rt_b->rt_period);
/*
*现在得到定时器的当前时间为ktime_t,rt_b-> rt_period
*是另一个ktime_t,指定推进定时器的时间
*/
soft = hrtimer_get_softexpires(&rt_b->rt_period_timer);
hard = hrtimer_get_expires(&rt_b->rt_period_timer);
delta = ktime_to_ns(ktime_sub(hard, soft));
__hrtimer_start_range_ns(&rt_b->rt_period_timer, soft, delta,
HRTIMER_MODE_ABS_PINNED, 0);
}
spin_unlock(&rt_b->rt_runtime_lock);
}
/*
* Sched_domains_mutex串行化对arch_init_sched_domains、
* detach_destroy_domains和partition_sched_domains的调用。
*/
static DEFINE_MUTEX(sched_domains_mutex);
/*
* DEFINE_MUTEX是来自于mutex.h中的一个宏,
* 用它可以定义一把互斥锁
*/
#ifdef CONFIG_GROUP_SCHED
/*#ifdef条件编译*/
#include
struct cfs_rq;
static LIST_HEAD(task_groups);
/*双向链表 list_head */
/* 任务组相关信息 */
struct task_group {
#ifdef CONFIG_CGROUP_SCHED
struct cgroup_subsys_state css;
#endif
#ifdef CONFIG_USER_SCHED
uid_t uid;
/* 用来降低权限 */
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
/* 这个组在每个CPU上的可调度实体 */
struct sched_entity **se;
/* 在每个CPU上由该组“拥有”的运行队列 */
struct cfs_rq **cfs_rq;
unsigned long shares;
#endif
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity **rt_se;
struct rt_rq **rt_rq;
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;
struct list_head list;
struct task_group *parent;
struct list_head siblings;
struct list_head children;
};
#ifdef CONFIG_USER_SCHED
/* 将uid信息传递给create_sched_user()的助手函数*/
void set_tg_uid(struct user_struct *user)
{
user->tg->uid = user->uid;
}
/*
* 根任务组。
* 每个UID任务组(包括init_task_group又名UID-0)都是这个组的子组。
*/
struct task_group root_task_group;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* 默认任务组在每个cpu上的调度实体*/
static DEFINE_PER_CPU(struct sched_entity, init_sched_entity);
/* 每个cpu上的默认任务组cfs_rq*/
static DEFINE_PER_CPU_SHARED_ALIGNED(struct cfs_rq, init_tg_cfs_rq);
#endif /* CONFIG_FAIR_GROUP_SCHED */
#ifdef CONFIG_RT_GROUP_SCHED
static DEFINE_PER_CPU(struct sched_rt_entity, init_sched_rt_entity);
static DEFINE_PER_CPU_SHARED_ALIGNED(struct rt_rq, init_rt_rq);
#endif /* CONFIG_RT_GROUP_SCHED */
#else /* !CONFIG_USER_SCHED */
#define root_task_group init_task_group
#endif /* CONFIG_USER_SCHED */
/*
* Task_group_lock串行化了任务组的添加/删除,也改变了任务组的CPU共享。
*/
static DEFINE_SPINLOCK(task_group_lock);
#ifdef CONFIG_FAIR_GROUP_SCHED
/* 运行队列中与cfs相关的字段 */
struct cfs_rq {
/*
* load维护了所有这些进程的累积负荷值。
*/
struct load_weight load;
/*
* nr_running计算了队列上可运行进程的数目。
* 其实这个成员存储的不一定都是进程,也可能包含进程组
* 或者会话对应的调度实体的数量,所以
* 准确地说nr_running其实就是当前cfs_rq中管理的
* 调度实体的个数。
*/
unsigned long nr_running;
/*
* 记录当前队列中所有调度实体占用的CPU时间,
* 这里统计的时间是实际时钟,参见__update_curr()
*/
u64 exec_clock;
/*
* min_vruntime跟踪记录队列上所有进程的最小
* 虚拟运行时间。这个值实现与就绪队列
* 相关的虚拟时钟的基础。其名字很容易
* 产生一些误解,因为min_vruntime实际上可能
* 比最左边的树节点的vruntime大些。因为它是
* 单调递增的。
*/
u64 min_vruntime;
/*
* tasks_timeline是一个基本成员,用于在按时间排序
* 的红黑树中管理所有进程。rb_leftmost总是指向树
* 最左边的节点,即最需要被调用的进程。该
* 成员理论上可以通过遍历红黑树获得,但由于
* 我们通常只对最左边的结点感兴趣,因为这
* 可以减少搜索树花费的平均时间。
*/
struct rb_root tasks_timeline;
struct rb_node *rb_leftmost;
struct list_head tasks;
struct list_head *balance_iterator;
/*
* curr'指向cfs_rq上当前运行的实体。
*否则设置为NULL(即当前没有运行)。
*/
/*
* curr指向当前执行进程的可调度实体。
* next和last分别使用
* set_next_buddy()和set_last_buddy()设置,应该是在
* 调用try_to_wake_up()和wake_up_new_task()唤醒时设置。
* 如果next和last设置,则在pick_next_entity()会优先
* 选择这些进程来运行。
*
* next成员在启用NEXT_BUDDY特性时才会设置,该特性描述
* 如下:
* Prefer to schedule the task we woke last (assuming it failed
* wakeup-preemption), since its likely going to consume data we
* touched, increases cache locality.
* 在调度选择时优先选择我们最后唤醒
* 的进程(假设唤醒时抢占正在执行的进程
* 失败),因为它很有可能使用我们访问的数据,
* 提高缓存利用率。
*
* Prefer to schedule the task that ran last (when we did
* wake-preempt) as that likely will touch the same data, increases
* cache locality.
* 在调度选择时优先选择我们最后执行的进程(
* 这个进程在唤醒其他进程时被抢占),因为它
* 很有可能访问同样的数据,提供缓存利用率。
*
* next和last成员的设置参见check_preempt_wakeup()函数。
* 另外,这两个成员都只在当前就绪队列中
* 可运行进程的数量大于等于sched_nr_latency时才会设置。
*/
struct sched_entity *curr, *next, *last;
unsigned int nr_spread_over;
#ifdef CONFIG_FAIR_GROUP_SCHED
struct rq *rq; /*cfs_rq附加到的CPU运行队列*/
/*
*Leaf cfs_rqs保存任务(中最低的可调度实体
*一个层次结构)。Non-leaf lrqs保存其他更高的可调度实体
*(如用户、容器等)
*Leaf_cfs_rq_list将cpu中的叶子cfs_rq列表绑定在一起。这
*List用于负载均衡。
*/
struct list_head leaf_cfs_rq_list;
struct task_group *tg; /* “拥有”此运行队列的组 */
#ifdef CONFIG_SMP
/*
* 任务负载的权重部分
*/
unsigned long task_weight;
/*
* h_load = weight * f(tg)
*
* 式中,f(tg)是赋给该组的递归权重分数。
*/
unsigned long h_load;
/*
* this cpu's part of tg->shares
*/
unsigned long shares;
/*
* load.weight at the time we set shares
*/
unsigned long rq_weight;
#endif
#endif
};
struct rq {
void check_preempt_curr(struct rq* rq, struct task_struct* p, int flags)
{
//如果是完全公平调度器,这里调用的是check_preempt_wakeup()。
rq->curr->sched_class->check_preempt_curr(rq, p, flags);
}
//处理就绪队列时钟的更新,本质上就是增加struct rq当前实例的时钟时间戳
inline void update_rq_clock(struct rq *rq)
{
rq->clock = sched_clock_cpu(cpu_of(rq));
}
}
// sysctl_sched_features,该变量表示调度器支持的特性,如GENTLE_FAIR_SLEEPERS(平滑的补偿睡眠进程),
static int sched_feat_show(struct seq_file *m, void *v)
{
int i;
//定义我们自己的开关,默认值是flase
for (i = 0; sched_feat_names[i]; i++) {
//sched_features表示调度器支持的特性
if (!(sysctl_sched_features & (1UL << i)))
seq_puts(m, "NO_");
seq_printf(m, "%s ", sched_feat_names[i]);
}
seq_puts(m, "\n");
return 0;
}
// sched_feat_write函数
static ssize_t;
sched_feat_write(struct file *filp, const char __user *ubuf,size_t cnt, loff_t *ppos)
{
char buf[64];
char *cmp = buf;
int neg = 0;
int i;
//如果数组长度大小大于63
if (cnt > 63)
cnt = 63;
//_user *ubuf表示指向用户区的指针
if (copy_from_user(&buf, ubuf, cnt))
return -EFAULT;
buf[cnt] = 0;
//定义我们自己的开关,默认值是flase
for (i = 0; sched_feat_names[i]; i++) {
int len = strlen(sched_feat_names[i]);
//甩头rncmp为字符串比较函数,当比较后为0时
if (strncmp(cmp, sched_feat_names[i], len) == 0) {
if (neg)
sysctl_sched_features &= ~(1UL << i);
else
sysctl_sched_features |= (1UL << i);
break;
}
}
//file-operations结构访问驱动程序的函数,这个结构每一个成员的名字都对应着一个调用
static const struct file_operations sched_feat_fops = {
.open = sched_feat_open,
.write = sched_feat_write,
.read = seq_read,
.llseek = seq_lseek,
.release = single_release,
};
//开启sched-init的debug功能
static __init int sched_init_debug(void)
{
debugfs_create_file("sched_features", 0644, NULL, NULL,
&sched_feat_fops);
return 0;
}
流程图:
系统总流程图
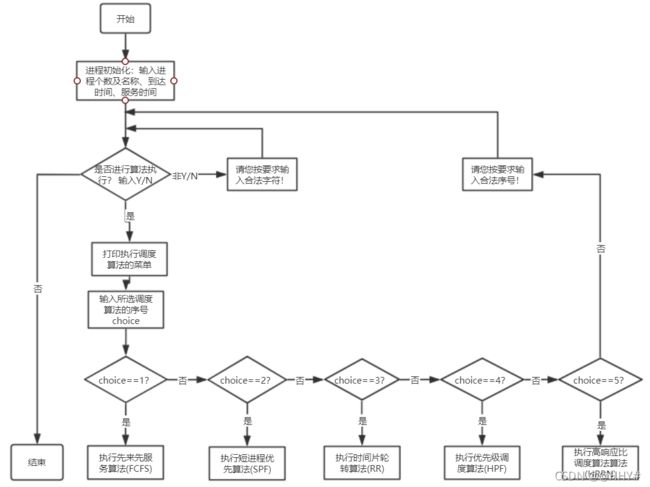
FCFS算法流程图
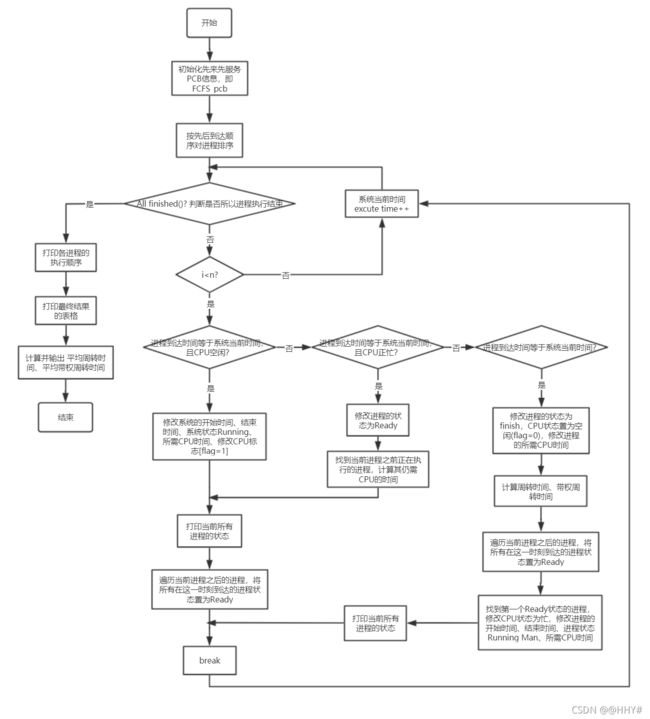
SPF算法流程图
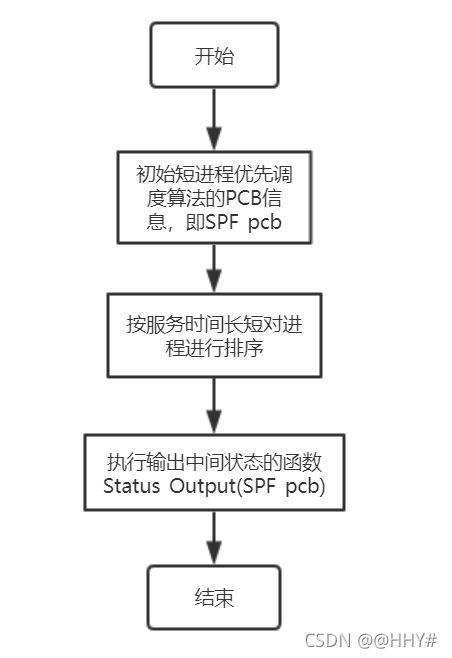
RR算法流程图
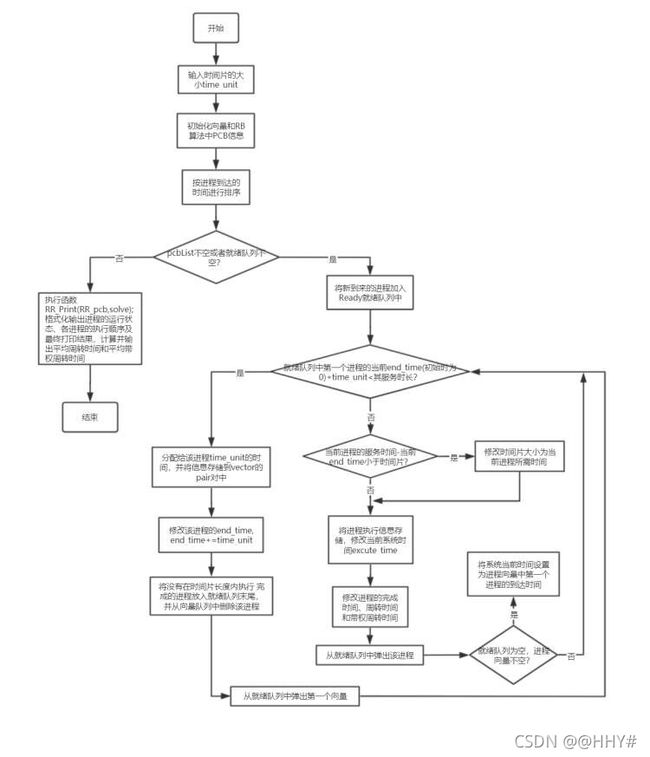
HPF算法流程图
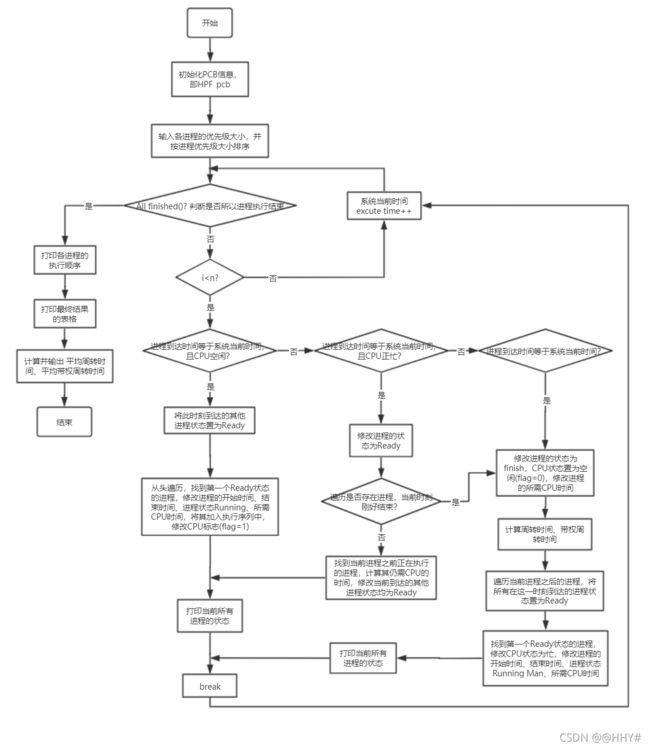
HRRN算法流程图

3.程序设计
(1)进程控制块PCB的数据结构
struct PCB
{
char process_name; //进程名
double arrival_time; //进程到达时间
double service_time; //进程要求服务时间
double start_time; //进程开始执行时间
double need_service_time; //进程还需占用CPU时间
double end_time; //进程执行完成时间
double process_priority; //进程优先级
double turnaround_time; //进程周转时间
double weight_turnaround_time; //进程带权周转时间
string status; //进程状态
};
(2)各种函数定义和声明
void Select_menu(); //选择菜单初始化
void Init_process(); //进程初始化
bool cmp_name(PCB a, PCB b); //按进程名排序,按序输出
bool cmp_time(PCB a, PCB b); //按进程到达时间排序
bool cmp_service_time(PCB a, PCB b); //按服务时间长短排序
bool cmp_process_priority(PCB a, PCB b); //按优先级大小排序
bool cmp_hrrn(Hrrn a, Hrrn b); //浮点数排序
void FCFS(); //先来先服务调度算法
void SPF(); //短进程优先调度算法
void HPF(); //HPF优先级调度算法
void RR(); //RR时间片轮转算法
void Status_Output(PCB O_PCB[]); //SPF输出中间状态
void HRRN(); //高响应比优先调度算法
void Print(PCB Tmp_pcb[]); //格式化输出
void Prio_Print(PCB Tmp_pcb[]); //带优先级格式化输出
void Result_Print(PCB Tmp_pcb[]); //最终结果打印(各进程的完成时间,各进程的周转时间及带权周转时间)
void RR_Print(PCB Tmp_pcb[],vector
bool All_finished(PCB pd_pcb[]); //判断是不是所有进程都已经执行结束,作为循环的判断条件(状态输出的时间优化)
(3)主函数
int main()
{
Init_process(); //进程初始化
while(1)
{
char YorN = 'Y';
cout<<"请问是否要执行对进程的调度?(格式:Y or N)请输入:";
cin>>YorN;
if(YorN == 'N')
{
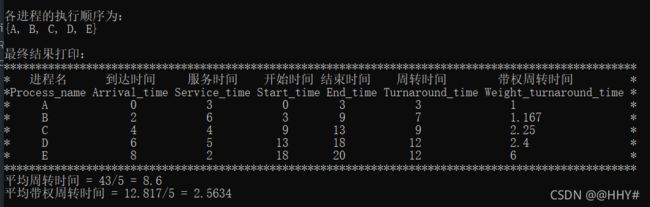
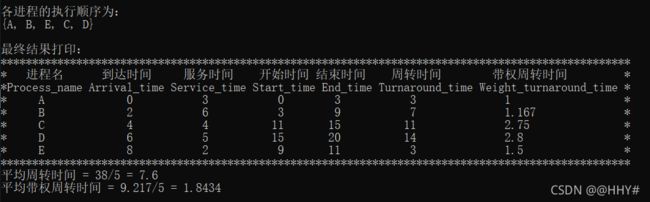
cout<<"执行结束,系统已退出!"< break; } else if(YorN == 'Y') { cout< Select_menu(); //调度算法选择菜单 cout< int choice; cout< cin>>choice; switch (choice) { case 1: FCFS(); break; case 2: SPF(); break; case 3: RR(); break; case 4: HPF(); break; case 5: HRRN(); break; default : cout<<"请您按要求输入合法序号!"< } } else cout<<"请您按要求输入合法字符!"< } return 0; } (4)FCFS先来先服务调度算法 void FCFS() { PCB FCFS_pcb[N]; for(int i=0; i < n; i++) FCFS_pcb[i] = pcb[i]; sort(FCFS_pcb,FCFS_pcb+n,cmp_time); //按到达时间排序 for(int excute_time = FCFS_pcb[0].arrival_time; All_finished(FCFS_pcb); excute_time++) //按总时间遍历 输出中间状态 { for (int i = 0; i < n; i++) //遍历进程 { if(FCFS_pcb[i].arrival_time == excute_time && !flag) { FCFS_pcb[i].start_time = excute_time; //当前CPU空闲,且进程已到达,从当前时间开始执行 FCFS_pcb[i].end_time = excute_time + FCFS_pcb[i].service_time; //修改该进程的结束时间 = 当前时间 + 服务时间 FCFS_pcb[i].status = "Running"; //修改进程状态 为 Running FCFS_pcb[i].need_service_time = FCFS_pcb[i].service_time; flag = 1; //当前CPU已被占用 cout << "T = "< Print(FCFS_pcb); for(int j = i; j < n; j++) //其他有在当前时刻到达的进程置为Ready { if(FCFS_pcb[j].arrival_time <= excute_time && FCFS_pcb[j].status == "WFA") FCFS_pcb[j].status = "Ready"; } cout< break; } else if(FCFS_pcb[i].arrival_time==excute_time && flag && FCFS_pcb[i].status == "WFA") { FCFS_pcb[i].status = "Ready"; //某进程到达,但是CPU被占用着,该进程状态为 Ready for(int j = 0; j < i; j++) //修改当前进程之前进程的状态 { if(FCFS_pcb[j].status == "Running") //找到状态为Running的进程——一定只有一个 { FCFS_pcb[j].need_service_time = FCFS_pcb[j].end_time - excute_time;//结束时间 - 当前时间 = 进程仍需CPU的时间 break; } } cout << "T = "< Print(FCFS_pcb); for(int j = i; j < n; j++) //其他有在当前时刻到达的进程置为Ready { if(FCFS_pcb[j].arrival_time <= excute_time && FCFS_pcb[j].status == "WFA") FCFS_pcb[j].status = "Ready"; } cout< break; } else if(FCFS_pcb[i].end_time == excute_time && FCFS_pcb[i].status == "Running") //某进程当前时刻执行完毕 { FCFS_pcb[i].status = "Finish"; //某进程执行完毕 flag = 0; //CPU空闲 FCFS_pcb[i].need_service_time = 0; //不再需要CPU FCFS_pcb[i].turnaround_time = excute_time - FCFS_pcb[i].arrival_time; //周转时间 = 当前时间 - 到达时间 FCFS_pcb[i].weight_turnaround_time=1.0* (FCFS_pcb[i].turnaround_time)/(FCFS_pcb[i].service_time); //带权周转时间 = 周转时间 / 服务时间 FCFS_pcb[i].weight_turnaround_time=((int)((FCFS_pcb[i].weight_turnaround_time*1000) + 0.5)) * 1.0 / 1000;//保留两位小数——四舍五入 for(int j = i; j < n; j++) //如果当前进程执行结束时,下一进程刚好到达,状态位需进行修改 { if(FCFS_pcb[j].arrival_time == FCFS_pcb[i].end_time) { FCFS_pcb[j].status = "Ready"; } } for(int j=i ; j { if(FCFS_pcb[j].status == "Ready") { flag = 1; FCFS_pcb[j].start_time=excute_time; //开始时间等于当前时间 FCFS_pcb[j].end_time=excute_time+FCFS_pcb[j].service_time; //进程的结束时间 = 当前时间 + 服务时间 FCFS_pcb[j].status="Running"; //修改进程状态 为 Running FCFS_pcb[j].need_service_time = FCFS_pcb[j].service_time; break; } } cout << "T = "< Print(FCFS_pcb); cout< break; } } } cout< cout<<"{"; for(int i = 0; i < n-1; i++) cout< cout< cout< Result_Print(FCFS_pcb); average_TT = 0; average_WTT = 0; for(int i = 0; i < n; i++) { average_TT += FCFS_pcb[i].turnaround_time; average_WTT += FCFS_pcb[i].weight_turnaround_time; } cout<<"平均周转时间 = "; cout< cout< (5)SPF短进程优先调度算法 void SPF() { PCB SPF_pcb[N]; for(int i=0; i < n; i++) SPF_pcb[i] = pcb[i]; sort(SPF_pcb,SPF_pcb+n,cmp_service_time); //按服务时间长短排序 Status_Output(SPF_pcb); } (6)HPF优先级调度算法 void HPF() { PCB HPF_pcb[N]; PCB Res_PCB[N]; int t = 0; for(int i = 0; i < n; i++) HPF_pcb[i] = pcb[i]; cout<<"请您依次输入代表进程{"; for(int i = 0; i < n-1; i++) cout< cout< for(int i = 0; i < n; i++) cin>>HPF_pcb[i].process_priority; sort(HPF_pcb,HPF_pcb+n,cmp_process_priority); //按优先级大小排序 cout< int excute_time = HPF_pcb[0].arrival_time; flag = 0; for(int i = 0; i < n; i++) //找所有进程中最早到达的进程时间即为系统的初始时间 { excute_time = excute_time > HPF_pcb[i].arrival_time ? HPF_pcb[i].arrival_time : excute_time; } for(; All_finished(HPF_pcb); excute_time++) //按总时间遍历 输出中间状态 { for (int i = 0; i < n; i++) //遍历进程 { if(HPF_pcb[i].arrival_time == excute_time && !flag) //先到的进程若CPU空闲则先执行,就绪队列中有其他进程排队时,选择优先级高的进程 { for(int j = 0; j < n; j++) //同时间到达的,均修改状态 { if(HPF_pcb[j].arrival_time <= excute_time && HPF_pcb[j].status == "WFA") HPF_pcb[j].status = "Ready"; } for(int j = 0; j <= i; j++) //同时间到达的,先选优先级高的 { if(HPF_pcb[j].status == "Ready") { HPF_pcb[j].start_time=excute_time; //当前CPU空闲,到达的进程执行 HPF_pcb[j].end_time=excute_time + HPF_pcb[j].service_time; //非抢占式,故该进程结束时间= 当前时间 + 服务时间 HPF_pcb[j].need_service_time=HPF_pcb[j].service_time; //仍需要占用CPU的时间 HPF_pcb[j].status="Running";//修改当前进程的状态为Running Res_PCB[t++] = HPF_pcb[j]; flag = 1; break; } } cout<<"T = " < Prio_Print(HPF_pcb); cout< break; } else if(HPF_pcb[i].arrival_time == excute_time && flag && HPF_pcb[i].status == "WFA") //某进程结束,当前进程到达 { bool mark = 0; HPF_pcb[i].status = "Ready";//某进程到达,但CPU被占用着,该状态为Ready for(int j = 0; j < n; j++) { if(HPF_pcb[j].status == "Running" && HPF_pcb[j].end_time == excute_time) //找到正在执行的进程,有且只有一个,这个进程刚好结束 { HPF_pcb[j].status = "Finish"; //某进程执行完毕 flag = 0; HPF_pcb[j].need_service_time = 0; //不再需要CPU资源 HPF_pcb[j].turnaround_time = excute_time - HPF_pcb[j].arrival_time; //周转时间 = 当前时间 - 到达时间 HPF_pcb[j].weight_turnaround_time = 1.0 * (HPF_pcb[j].turnaround_time)/(HPF_pcb[j].service_time); //带权周转时间 = 周转时间 / 服务时间 HPF_pcb[j].weight_turnaround_time = ((int)((HPF_pcb[j].weight_turnaround_time*1000) + 0.5)) * 1.0 / 1000; for(int m = i; m < n; m++) //若有其他进程也在当前时刻到达,状态位需进行修改 { if(HPF_pcb[m].arrival_time <= HPF_pcb[j].end_time && HPF_pcb[j].status == "WFA") { HPF_pcb[m].status = "Ready"; } } for(int k=0;k { if(HPF_pcb[k].status == "Ready") { flag = 1; HPF_pcb[k].start_time = excute_time; //开始时间等于当前时间 HPF_pcb[k].end_time = excute_time + HPF_pcb[k].service_time; //进程的结束时间 = 当前时间 + 服务时间 HPF_pcb[k].status = "Running"; //修改进程状态 为 Running Res_PCB[t++] = HPF_pcb[k]; HPF_pcb[k].need_service_time = HPF_pcb[k].service_time; break; } } mark = 1; } else if(HPF_pcb[j].status == "Running" && HPF_pcb[j].end_time!=excute_time) //找到正在执行的进程,有且只有一个,正在执行 { HPF_pcb[j].need_service_time = HPF_pcb[j].end_time - excute_time; //结束时间 - 当前时间 = 进程仍需CPU时间 mark = 1; for(int m = i; m < n; m++) { if(HPF_pcb[m].arrival_time <= excute_time && HPF_pcb[m].status == "WFA") { HPF_pcb[m].status = "Ready"; } } } if(mark) break; } cout<<"T = " < Prio_Print(HPF_pcb); cout< break; } else if(HPF_pcb[i].end_time == excute_time && HPF_pcb[i].status == "Running") //某进程执行结束 { HPF_pcb[i].status = "Finish"; //某进程执行完毕 flag = 0; HPF_pcb[i].need_service_time = 0; //不再需要CPU资源 HPF_pcb[i].turnaround_time = excute_time - HPF_pcb[i].arrival_time; //周转时间 = 当前时间 - 到达时间 HPF_pcb[i].weight_turnaround_time = 1.0 * (HPF_pcb[i].turnaround_time)/(HPF_pcb[i].service_time); //带权周转时间 = 周转时间 / 服务时间 HPF_pcb[i].weight_turnaround_time = ((int)((HPF_pcb[i].weight_turnaround_time*1000) + 0.5)) * 1.0 / 1000; //保留两位小数——四舍五入 for(int j = i; j < n; j++) //如果当前进程执行结束时,下一进程刚好到达,状态位需进行修改 { if(HPF_pcb[j].arrival_time == HPF_pcb[i].end_time && HPF_pcb[j].status == "WFA") { HPF_pcb[j].status = "Ready"; } } for(int j=0;j < n; j++) //找第一个ready进程 { if(HPF_pcb[j].status == "Ready") { flag = 1; HPF_pcb[j].start_time=excute_time; //开始时间等于当前时间 HPF_pcb[j].end_time=excute_time + HPF_pcb[j].service_time; //进程的结束时间 = 当前时间 + 服务时间 HPF_pcb[j].status="Running"; //修改进程状态 为 Running Res_PCB[t++] = HPF_pcb[j]; HPF_pcb[j].need_service_time = HPF_pcb[j].service_time; break; } } cout << "T = "< Prio_Print(HPF_pcb); cout< break; } } } cout< cout<<"{"; for(int i = 0; i < n-1; i++) cout< cout< cout< Result_Print(HPF_pcb); average_TT = 0; average_WTT = 0; for(int i = 0; i < n; i++) { average_TT += HPF_pcb[i].turnaround_time; average_WTT += HPF_pcb[i].weight_turnaround_time; } cout<<"平均周转时间 = "; cout< cout< (7)RR时间片轮转调度算法 void RR() { PCB RR_pcb[N]; int t=0; cout<<"请输入时间片大小:"; cin>>time_unit; vector for(int i = 0; i < n; i++) RR_pcb[i] = pcb[i]; for(int i=0;i { pcbList.push_back(pcb[i]); //向量初始化 } sort(RR_pcb,RR_pcb+n,cmp_time); //按到达时间进行排序 sort(pcbList.begin(),pcbList.end(),cmp_time); //for (int i = 0; i < n; i++) // cout< //cout< int excute_time =(*pcbList.begin()).arrival_time; //第一个进程开始时间 Ready.push(*pcbList.begin()); pcbList.erase(pcbList.begin()); while(!pcbList.empty()||!Ready.empty()) { while(!pcbList.empty()&&excute_time>=(*pcbList.begin()).arrival_time)//将新进程加入就绪队列 { Ready.push(*pcbList.begin()); pcbList.erase(pcbList.begin()); } if(Ready.front().end_time + time_unit < Ready.front().service_time)//将时间片用完但没运行完的进程加入队尾 { solve.push_back(pair Ready.front().end_time += time_unit; excute_time += time_unit; while(!pcbList.empty()&& (*pcbList.begin()).arrival_time <= excute_time) //未执行完,将其放入ready的末尾 { Ready.push(*pcbList.begin()); pcbList.erase(pcbList.begin()); } Ready.push(Ready.front()); Ready.pop(); } else //进程执行完 { int tmp_time_unit = time_unit; if(Ready.front().service_time - Ready.front().end_time { tmp_time_unit -= Ready.front().service_time - Ready.front().end_time; } solve.push_back(pair excute_time += tmp_time_unit; Ready.front().end_time = excute_time; Ready.front().turnaround_time = Ready.front().end_time - Ready.front().arrival_time; Ready.front().weight_turnaround_time = (double)Ready.front().turnaround_time / Ready.front().service_time; for(int i = 0; i < n; i++) { if(RR_pcb[i].process_name == Ready.front().process_name) { RR_pcb[i].turnaround_time = Ready.front().turnaround_time; RR_pcb[i].weight_turnaround_time = Ready.front().weight_turnaround_time; RR_pcb[i].end_time = RR_pcb[i].turnaround_time + RR_pcb[i].arrival_time; } } Ready.pop(); if(Ready.empty() && !pcbList.empty()) { excute_time = (*pcbList.begin()).arrival_time; } } } RR_Print(RR_pcb,solve); } (8)HRRN高响应比优先调度算法 void HRRN() { PCB HRRN_pcb[N]; bool vis[N] ={0}; //标记数组,标记进程是不是被放进执行序列汇总 int sequence[N] = {0},t=0; //存进程执行的序列下标 ——便于转化PCB结构体数组,得到正确的执行顺序 for(int i = 0; i < n; i++) HRRN_pcb[i] = pcb[i]; //备份PCB结构体数组 sort(HRRN_pcb,HRRN_pcb+n,cmp_time); //先对各进程按到达时间排序 int excute_time = HRRN_pcb[0].arrival_time; int total_time = HRRN_pcb[0].arrival_time; //第一个进程到达时间 + 所有进程的服务时间 = 总时间 flag = 0; //flag=0 表示CPU空闲 for(int i = 0; i < n; i++) //计算总时间 { total_time += HRRN_pcb[i].service_time; excute_time = excute_time > HRRN_pcb[i].arrival_time ? HRRN_pcb[i].arrival_time : excute_time;//开始时间(找最早到达的进程到达时间) } int Cutoftime = excute_time; //时间片切割(为了回溯遍历到达进程,以计算各进程响应比) for(; excute_time<=total_time; excute_time++) //按总时间遍历 先确定执行顺序 { if(excute_time == Cutoftime) //时间切割 { int obj = 0; memset(hrrn,0,sizeof(0)); //初始化动态变化的一维数组(存响应比) for(int i = 0; i < n; i++) { if(HRRN_pcb[i].arrival_time <= Cutoftime && !vis[i]) { hrrn[obj].value = (Cutoftime - HRRN_pcb[i].arrival_time)*1.0/HRRN_pcb[i].service_time + 1; hrrn[obj].id = i; obj++; } } sort(hrrn,hrrn+obj,cmp_hrrn); sequence[t++] = hrrn[0].id; //取响应比值最大的 下标加入序列 vis[hrrn[0].id] = 1; Cutoftime += HRRN_pcb[hrrn[0].id].service_time; //更新切割时间段 继续循环 } else continue; } cout<<"该调度算法下进程执行顺序为:(对应的下标输出)"< cout<<"{"; for(int i = 0; i < n-1; i++) cout< cout< PCB t_HRRN_pcb[N]; for(int i = 0; i < n; i++) t_HRRN_pcb[i] = HRRN_pcb[sequence[i]]; //用计算得到的顺序执行HRRN Status_Output(t_HRRN_pcb); } 运行结果 FCFS SPF RR HRRN 通过对linux系统中进程管理系统中进程调度的代码的理解,对我们本次的课设有很大的帮助,linux操作系统的源代码比较多,进程调度相关代码分布比较零散,所以我们只是选取了一部分代码。 本次课程设计主要是进程调度系统设计,涉及进程调度相关算法,如FCFS先来先服务调度算法,SPF短进程优先调度算法,HPF优先级调度算法,RR时间片轮转调度算法,HRRN高响应比优先调度算法。在设计进程调度,首先要设计相关的PCB数据结构。设计相关算法时,需要弄清楚算法的思想和重点,如下: (1)先来先服务调度算法(FCFS) 在先来先服务调度算法中,优先执行先到达的进程;在占用CPU资源执行期间,不会被其他进程抢占CPU资源,直至当前进程执行完,释放处理机。在算法实现中,为便于输出所有关键时刻的进程状态,采用遍历时间轴、多状态匹配的方式执行。 ① 首先,初始化算法中PCB信息(保存至FCFS_pcb中,详见.cpp文件,且以下算法类似),并对进程按照到达时间进行排序。 ② 遍历过程中,考虑到存在CPU长时间空闲、下一个进程到达时刻晚的情况,用All_finished()函数时刻监测进程的状态信息。一方面,结合实际可能发生的情况,保证了所有进程正常执行完毕,并输出打印中间状态;另一方面,实现了FCFS算法调度的时间优化。 ③ 在多状态匹配中,有以下几种情况: a. 在当前系统时间下,某一进程到达,此时CPU处于空闲状态: 修改当前进程的PCB信息(包括进程的开始时间、结束时间、进程状态置为Running)、修改CPU标志,置flag为1(表示CPU处于忙状态)。修改完成后,格式化输出打印进程状态信息。遍历当前进程之后的进程,将所有在当前系统时刻到达的进程状态置为Ready。 b. 在当前系统时间下,某一进程到达,此时CPU处于忙状态: 修改当前进程的PCB信息(进程状态置为Ready),打印输出后,将所有当前系统时刻到达的进程状态置为Ready。 c. 某进程的结束时间等于系统当前的时间: 修改进程的状态为Finish,CPU状态置为空闲状态,并计算周转时间、带权周转时间。遍历当前进程之后的进程,将所有在这一时刻之后到达的进程状态置为Ready。由于当前系统空闲,故找到第一个Ready状态的进程,修改PCB信息。打印当前时刻的进程状态,开始下一个时刻的循环。 ④ 当按时间轴遍历结束后,所有进程都执行完毕,格式化输出打印所有进程的最终状态,计算并输出平均周转时间、平均带权周转时间。 (2)短进程优先算法(SPF) 在短进程优先调度算法中,优先执行当前时刻到达且服务时间较短的进程;在占用CPU资源执行期间,不会被其他进程抢占CPU资源,直至当前进程执行完,释放处理机。在算法实现中,为便于输出所有关键时刻的进程状态,采用遍历时间轴、多状态匹配的方式执行。 ① 初始化算法中PCB信息,并对进程按照服务时长进行降序排序。 ② 执行输出中间状态的函数Status_Output() 说明:SPF与HRRN的输出中间状态函数进行了封装,包括中间所有过程的遍历输出及最终平均周转时间及平均带权周转时间的计算。 (3)时间片轮转算法(RR) 时间片轮转算法是FCFS的优化,在一个规定时间片内,当前进程若没有执行完, 也需要让出处理机,在就绪队列的队尾进行排队。等所有进程都已在就绪队列后,按照就绪队列中的顺序及时间片大小进行轮转。 RR算法需要维护一个PCB向量和一个Ready队列,当均为空时,表明所有进程执行结束。否则,继续轮转,直至执行结束。 (4)优先级调度算法(HPF) 在优先级调度算法中,优先执行高优先级的进程。在算法实现中,默认数值大的表示优先级高。 ① 首先,初始化算法中PCB信息,并对进程按照优先级大小进行降序排序,优先级相同时,按到达时间进行升序排序。 ② 遍历过程中,用All_finished()函数时刻监测进程的状态信息。一方面,结合实际可能发生的情况,保证了所有进程正常执行完毕,并输出打印中间状态;另一方面,实现了算法调度的时间优化。 ③ 在多状态匹配中,有以下几种情况: a. 在当前系统时间下,某一进程到达,此时CPU处于空闲状态: 将此刻到达的其他进程状态置为Ready,找到第一个状态为Ready的进程,修改当前进程的PCB信息(包括进程的开始时间、结束时间、进程状态置为Running)、修改CPU标志,置flag为1(表示CPU处于忙状态)。修改完成后,格式化输出打印进程状态信息(输出优先权列)。 b. 在当前系统时间下,某一进程到达,此时CPU处于忙状态: 修改当前进程的PCB信息(进程状态置为Ready),遍历状态为Running的进程(有且只有一个)。若Running进程恰好在这一时刻结束,则修改其状态为Finish,后续处理过程同c;若Running进程在这一时刻未结束,计算Running进程仍需CPU的时间,将所有当前系统时刻到达的进程状态置为Ready,并打印输出当前所有进程的状态。 c. 某进程的结束时间等于系统当前的时间: 修改进程的状态为Finish,CPU状态置为空闲状态,并计算周转时间、带权周转时间。遍历当前进程之后的进程,将所有在这一时刻之后到达的进程状态置为Ready。由于当前系统空闲,故找到第一个Ready状态的进程,修改PCB信息。打印当前时刻的进程状态,开始下一个时刻的循环。 ④ 当按时间轴遍历结束后,所有进程都执行完毕,格式化输出打印所有进程的最终状态,计算并输出平均周转时间、平均带权周转时间。 说明:输出中间状态的函数Status_Output()中所分情况同HPF类似,故不再重复叙述,三者不同之处在于HPF在格式化输出中调用自己的格式化输出,比另外两种算法多一列优先权列。 (5)高响应比优先调度算法(HRRN) 在高响应比优先调度算法中,需要先找到进程执行的序列,具体实现为:计算进程响应比,选择高响应比的进程执行;由于在占用CPU资源执行期间,不会被其他进程抢占CPU资源,直至当前进程执行完,释放处理机。因此,计算响应比的时刻可以进行时间划分,这样提高了执行效率。 ① 首先,初始化算法中PCB信息,计算系统执行的总时间,并对进程按照到达时间进行排序,初始化开始执行时间和总时间。 ② 遍历过程中,利用结构体hrrn动态调整和计算当前时刻到达进程且未执行的响应比,并选择响应比最大的加入执行序列。 ③ 根据计算好的执行序列,初始化t_HRRN_pcb,并执行输出中间状态的函数Status_Output()。 在编写进程调度算法,我们只根据其含义和思想简单地实现了算法调度,其中还有很多细节没有考虑和有些部分没有实现。通过本次课设,我们对操作系统的理解更加深入,收获更多。 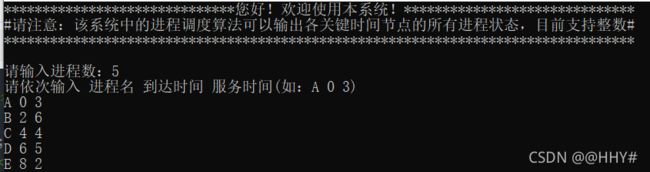
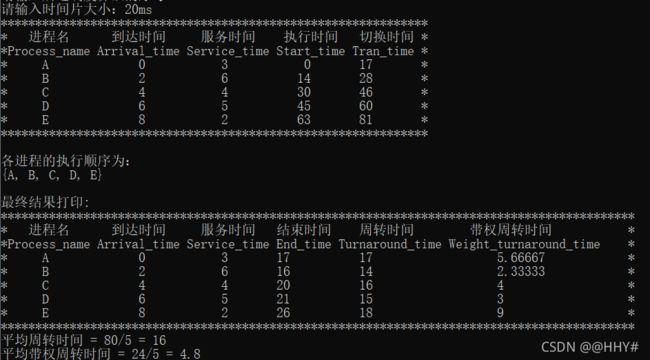
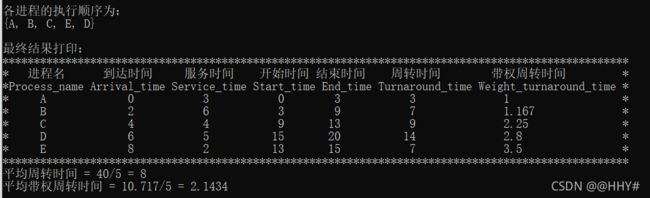
4、总结