【08】Flink 之 DataSet API(二):Transformation 操作
1、DataSet Transformation 部分详解
- Map:输入一个元素,然后返回一个元素,中间可以做一些清洗转换等操作
- FlatMap:输入一个元素,可以返回零个,一个或者多个元素
- MapPartition:类似map,一次处理一个分区的数据【如果在进行map处理的时候需要获取第三方资源链接,建议使用MapPartition】
- Filter:过滤函数,对传入的数据进行判断,符合条件的数据会被留下
- Reduce:对数据进行聚合操作,结合当前元素和上一次reduce返回的值进行聚合操作,然后返回一个新的值
- Aggregate:sum、max、min等
- Distinct:返回一个数据集中去重之后的元素,data.distinct()
- Join:内连接
- OuterJoin:外链接
- Cross:获取两个数据集的笛卡尔积
- Union:返回两个数据集的总和,数据类型需要一致
- First-n:获取集合中的前N个元素
- Sort Partition:在本地对数据集的所有分区进行排序,通过sortPartition()的链接调用来完成对多个字段的排序
2、MapPartition实践
2.1 Java代码实现
通常使用 MapFunction 实现如下:
data.map(new MapFunction() {
@Override
public String map(String value) throws Exception {
//获取数据库连接--注意,此时是每过来一条数据就获取一次链接
//处理数据
//关闭连接
return value;
}
});
MapPartitionFunction 实现如下:
data.mapPartition(
new MapPartitionFunction() {
@Override
public void mapPartition(Iterable values, Collector out)
throws Exception {
//获取数据库连接--注意,此时是一个分区的数据获取一次连接
// 【优点: 每个分区获取一次链接】
//values中保存了一个分区的数据
//处理数据
Iterator it = values.iterator();
while (it.hasNext()) {
String next = it.next();
String[] split = next.split("\\W+");
for (String word : split) {
out.collect(word);
}
}
//关闭链接
}
});
完整实现代码如下:
package com.Batch.BatchAPI;
import org.apache.flink.api.common.functions.MapPartitionFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.Iterator;
/**
* @Author: Henry
* @Description: 一次处理一个分区的数据,应用场景:关联第三方数据源
* @Date: Create in 2019/5/16 21:28
**/
public class BatchDemoMapPartition {
public static void main(String[] args) throws Exception{
//获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
ArrayList data = new ArrayList(); // 可以写 ArrayList<>()
data.add("hello you");
data.add("hello me");
DataSource text = env.fromCollection(data);
/*text.map(new MapFunction() {
@Override
public String map(String value) throws Exception {
//获取数据库连接--注意,此时是每过来一条数据就获取一次链接
//处理数据
//关闭连接
return value;
}
});*/
DataSet mapPartitionData = text.mapPartition(
new MapPartitionFunction() {
@Override
public void mapPartition(Iterable values, Collector out)
throws Exception {
//获取数据库连接--注意,此时是一个分区的数据获取一次连接
// 【优点: 每个分区获取一次链接】
//values中保存了一个分区的数据
//处理数据
Iterator it = values.iterator();
while (it.hasNext()) {
String next = it.next();
String[] split = next.split("\\W+");
for (String word : split) {
out.collect(word);
}
}
//关闭链接
}
});
mapPartitionData.print();
}
}
2.2、运行结果
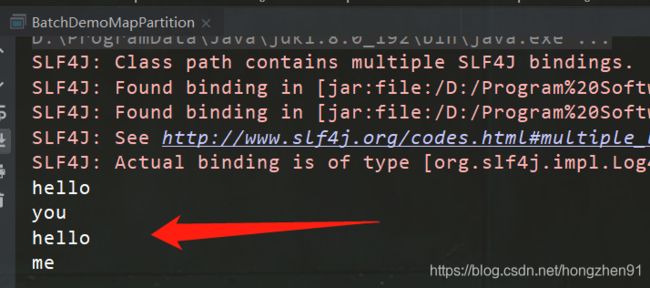
2.3、Scala代码实现
package cn.Batch
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable.ListBuffer
/**
* @Author: Henry
* @Description: 分区 Map
* @Date: Create in 2019/5/16 21:28
**/
object BatchDemoMapPartition {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val data = ListBuffer[String]() // 相当于 Java 中的 Array
data.append("hello you")
data.append("hello me")
val text = env.fromCollection(data)
text.mapPartition(it=>{
//创建数据库连接,建议吧这块代码放到try-catch代码块中
val res = ListBuffer[String]()
while(it.hasNext){
val line = it.next()
val words = line.split("\\W+")
for(word <- words){
res.append(word)
}
}
res
//关闭连接
}).print()
}
}
2.4、运行结果
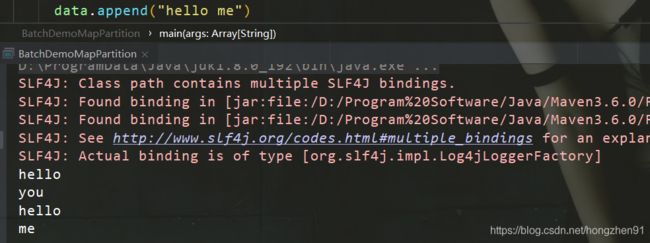
3、Distinct实践
3.1、Java代码实现
package com.Batch.BatchAPI;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
/**
* @Author: Henry
* @Description: 去重操作
* @Date: Create in 2019/5/16 21:28
**/
public class BatchDemoDistinct {
public static void main(String[] args) throws Exception{
//获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
ArrayList data = new ArrayList<>();
data.add("hello you");
data.add("hello me");
DataSource text = env.fromCollection(data);
FlatMapOperator flatMapData = text.flatMap(
new FlatMapFunction() {
@Override
public void flatMap(String value, Collector out)
throws Exception {
String[] split = value.toLowerCase().split("\\W+");
for (String word : split) {
System.out.println("单词:"+word);
out.collect(word); // 类似于 add 操作
}
}
});
flatMapData.distinct()// 对数据进行整体去重
.print();
}
}
3.2 运行结果
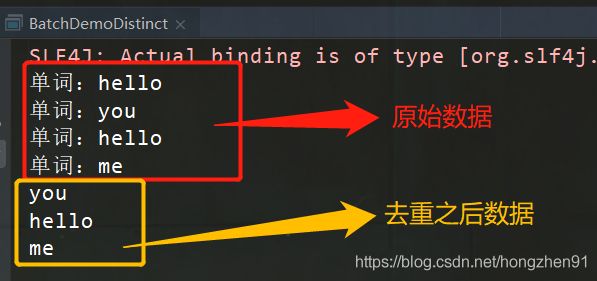
3.3、Scala代码实现
package cn.Batch
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable.ListBuffer
/**
* @Author: Henry
* @Description: 去重
* @Date: Create in 2019/5/16 21:28
**/
object BatchDemoDistinct {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val data = ListBuffer[String]()
data.append("hello you")
data.append("hello me")
val text = env.fromCollection(data)
val flatMapData = text.flatMap(line=>{
val words = line.split("\\W+")
for(word <- words){
println("单词:"+word)
}
words
})
// 如果数据类型是Tuple,可以指定按Tuple某个字段去重
flatMapData.distinct()
.print()
}
}
3.4、运行结果
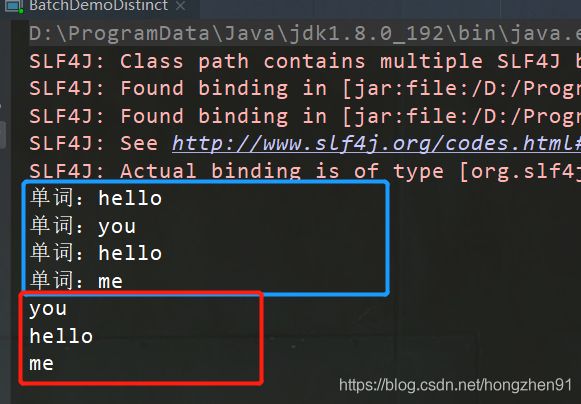
4、Join实践
4.1、Java代码实践
package com.Batch.BatchAPI;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import java.util.ArrayList;
/**
* @Author: Henry
* @Description: 内连接
* @Date: Create in 2019/5/16 21:28
**/
public class BatchDemoJoin {
public static void main(String[] args) throws Exception{
//获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//tuple2<用户id,用户姓名>
ArrayList> data1 = new ArrayList<>();
data1.add(new Tuple2<>(1,"zs"));
data1.add(new Tuple2<>(2,"ls"));
data1.add(new Tuple2<>(3,"ww"));
//tuple2<用户id,用户所在城市>
ArrayList> data2 = new ArrayList<>();
data2.add(new Tuple2<>(1,"beijing"));
data2.add(new Tuple2<>(2,"shanghai"));
data2.add(new Tuple2<>(3,"guangzhou"));
DataSource> text1 = env.fromCollection(data1);
DataSource> text2 = env.fromCollection(data2);
text1.join(text2).where(0)//指定第一个数据集中需要进行比较的元素角标
.equalTo(0)//指定第二个数据集中需要进行比较的元素角标
.with(
new JoinFunction, Tuple2, Tuple3>() {
@Override
public Tuple3 join(Tuple2 first, Tuple2 second)
throws Exception {
return new Tuple3<>(first.f0,first.f1,second.f1);
}
}).print();
System.out.println("==================================");
}
}
4.2、运行结果
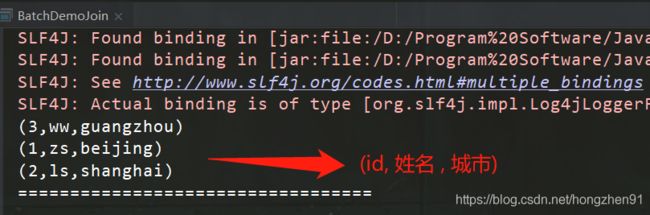
4.3、Scala代码实践
package cn.Batch
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable.ListBuffer
/**
* @Author: Henry
* @Description: Join操作
* @Date: Create in 2019/5/16 21:28
**/
object BatchDemoJoin {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val data1 = ListBuffer[Tuple2[Int,String]]()
data1.append((1,"zs"))
data1.append((2,"ls"))
data1.append((3,"ww"))
val data2 = ListBuffer[Tuple2[Int,String]]()
data2.append((1,"beijing"))
data2.append((2,"shanghai"))
data2.append((3,"guangzhou"))
val text1 = env.fromCollection(data1)
val text2 = env.fromCollection(data2)
text1.join(text2)
.where(0)
.equalTo(0)
.apply((first,second)=>{ // Java 此处可以使用map或with,Scala没有with,
(first._1,first._2,second._2)
}).print()
}
}
4.4、运行结果
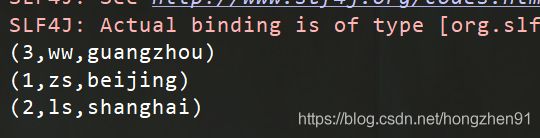
5、OuterJoin实践
5.1、Java代码实现
数据准备:
//tuple2<用户id,用户姓名>
ArrayList> data1 = new ArrayList<>();
data1.add(new Tuple2<>(1,"zs"));
data1.add(new Tuple2<>(2,"ls"));
data1.add(new Tuple2<>(3,"ww"));
//tuple2<用户id,用户所在城市>
ArrayList> data2 = new ArrayList<>();
data2.add(new Tuple2<>(1,"beijing"));
data2.add(new Tuple2<>(2,"shanghai"));
data2.add(new Tuple2<>(4,"guangzhou"));
DataSource> text1 = env.fromCollection(data1);
DataSource> text2 = env.fromCollection(data2);
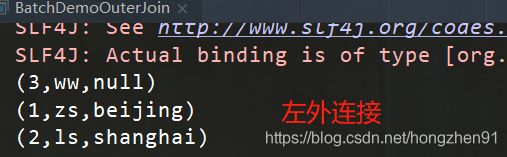
- 左外连接
/**
* 左外连接
*
* 注意:second这个tuple中的元素可能为null
*
*/
text1.leftOuterJoin(text2)
.where(0) // 指第一个数据集中的第1个字段
.equalTo(0)
.with(
new JoinFunction, Tuple2, Tuple3>() {
@Override
public Tuple3 join(Tuple2 first, Tuple2 second) throws Exception {
if(second==null){
return new Tuple3<>(first.f0,first.f1,"null");
}else{
return new Tuple3<>(first.f0,first.f1,second.f1);
}
}
}).print();
- 右外连接
/**
* 右外连接
*
* 注意:first这个tuple中的数据可能为null
*
**/
text1.rightOuterJoin(text2)
.where(0)
.equalTo(0)
.with(new JoinFunction, Tuple2, Tuple3>() {
@Override
public Tuple3 join(Tuple2 first, Tuple2 second)
throws Exception {
if(first==null){
return new Tuple3<>(second.f0,"null",second.f1);
}
return new Tuple3<>(first.f0,first.f1,second.f1);
}
}).print();
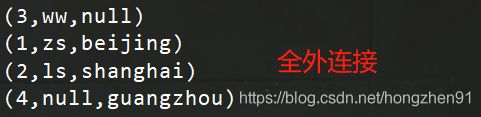
- 全外连接
/**
* 全外连接
*
* 注意:first和second这两个tuple都有可能为null
*
*/
text1.fullOuterJoin(text2)
.where(0)
.equalTo(0)
.with(new JoinFunction, Tuple2, Tuple3>() {
@Override
public Tuple3 join(Tuple2 first, Tuple2 second) throws Exception {
if(first==null){
return new Tuple3<>(second.f0,"null",second.f1);
}else if(second == null){
return new Tuple3<>(first.f0,first.f1,"null");
}else{
return new Tuple3<>(first.f0,first.f1,second.f1);
}
}
}).print();
5.2、Scala代码实现
- 左外连接
/**
* 左外连接
*
* 注意:second这个tuple中的元素可能为null
*
*/
text1.leftOuterJoin(text2).where(0).equalTo(0).apply((first,second)=>{
if(second==null){
(first._1,first._2,"null")
}else{
(first._1,first._2,second._2)
}
}).print()
- 右外连接
/**
* 右外连接
*
* 注意:first这个tuple中的数据可能为null
*
**/
text1.leftOuterJoin(text2).where(0).equalTo(0).apply((first,second)=>{
if(first==null){
(second._1,second._2,"null")
}else{
(second._1,second._2,second._2)
}
}).print()
- 全外连接
/**
* 全外连接
*
* 注意:first和second这两个tuple都有可能为null
*
*/
text1.fullOuterJoin(text2).where(0).equalTo(0).apply((first,second)=>{
if(first==null){
(second._1,"null",second._2)
}else if(second==null){
(first._1,first._2,"null")
}else{
(first._1,first._2,second._2)
}
}).print()
5.3、运行结果
- 左外连接
- 右外连接

- 全外连接
6、Cross(笛卡尔积)实践
6.1、Java代码实现
package com.Batch.BatchAPI;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.CrossOperator;
import org.apache.flink.api.java.operators.DataSource;
import java.util.ArrayList;
/**
* @Author: Henry
* @Description: 求数据笛卡尔积,交叉相乘
* @Date: Create in 2019/5/16 21:28
**/
public class BatchDemoCross {
public static void main(String[] args) throws Exception{
//获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//tuple2<用户id,用户姓名>
ArrayList data1 = new ArrayList<>();
data1.add("zs");
data1.add("ww");
//tuple2<用户id,用户所在城市>
ArrayList data2 = new ArrayList<>();
data2.add(1);
data2.add(2);
DataSource text1 = env.fromCollection(data1);
DataSource text2 = env.fromCollection(data2);
CrossOperator.DefaultCross cross = text1.cross(text2);
cross.print();
}
}
6.2、Scala代码实现
package cn.Batch
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable.ListBuffer
/**
* @Author: Henry
* @Description: 笛卡尔积 操作
* @Date: Create in 2019/5/16 21:28
**/
object BatchDemoCross {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val data1 = List("zs","ww")
val data2 = List(1,2)
val text1 = env.fromCollection(data1)
val text2 = env.fromCollection(data2)
text1.cross(text2).print()
}
}
6.3、运行结果
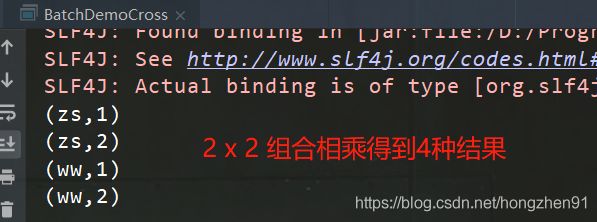
7、Union实践
7.1、Java代码实现
package com.Batch.BatchAPI;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.UnionOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import java.util.ArrayList;
/**
* @Author: Henry
* @Description: 将数据合并在一起,返回两个数据集的总和,熟悉类型需要一致
* @Date: Create in 2019/5/16 21:28
**/
public class BatchDemoUnion {
public static void main(String[] args) throws Exception{
//获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
ArrayList> data1 = new ArrayList<>();
data1.add(new Tuple2<>(1,"zs"));
data1.add(new Tuple2<>(2,"ls"));
data1.add(new Tuple2<>(3,"ww"));
ArrayList> data2 = new ArrayList<>();
data2.add(new Tuple2<>(1,"lili"));
data2.add(new Tuple2<>(2,"jack"));
data2.add(new Tuple2<>(3,"jessic"));
DataSource> text1 = env.fromCollection(data1);
DataSource> text2 = env.fromCollection(data2);
System.out.println("---------------------------");
text1.print();
text2.print();
UnionOperator> union = text1.union(text2);
System.out.println("---------------------------");
union.print();
}
}
7.2、Java代码实现
package cn.Batch
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable.ListBuffer
/**
* @Author: Henry
* @Description: Union操作
* @Date: Create in 2019/5/16 21:28
**/
object BatchDemoUnion {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val data1 = ListBuffer[Tuple2[Int,String]]()
data1.append((1,"zs"))
data1.append((2,"ls"))
data1.append((3,"ww"))
val data2 = ListBuffer[Tuple2[Int,String]]()
data2.append((1,"jack"))
data2.append((2,"lili"))
data2.append((3,"jessic"))
val text1 = env.fromCollection(data1)
val text2 = env.fromCollection(data2)
text1.union(text2).print()
}
}
7.3、运行结果
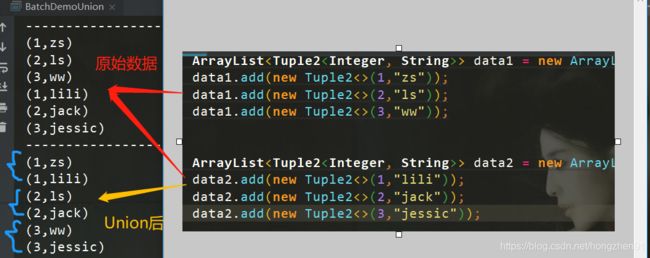
8、FirstN实践
8.1、Java代码实现
package com.Batch.BatchAPI;
import org.apache.flink.api.common.operators.Order;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import java.util.ArrayList;
/**
* @Author: Henry
* @Description: 获取集合中的前N个元素
* @Date: Create in 2019/5/16 21:28
**/
public class BatchDemoFirstN {
public static void main(String[] args) throws Exception{
//获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
ArrayList> data = new ArrayList<>();
data.add(new Tuple2<>(2,"zs"));
data.add(new Tuple2<>(4,"ls"));
data.add(new Tuple2<>(3,"ww"));
data.add(new Tuple2<>(1,"xw"));
data.add(new Tuple2<>(1,"aw"));
data.add(new Tuple2<>(1,"mw"));
// 转换成 flink 数据格式
DataSource> text = env.fromCollection(data);
//获取前3条数据,按照数据插入的顺序
System.out.println("======= 获取前3条数据 ===========");
text.first(3).print();
//根据数据中的第一列进行分组,获取每组的前2个元素
System.out.println("======= 获取每组前2个元素 ========");
text.groupBy(0).first(2).print();
//根据数据中的第一列分组,再根据第二列进行组内排序[升序],获取每组的前2个元素
System.out.println("======== 分组二次排序-1 =========");
text.groupBy(0)
.sortGroup(1, Order.ASCENDING) // 降序 DSCENDING
.first(2).print();
//不分组,全局排序获取集合中的前3个元素,针对第一个元素升序,第二个元素倒序
System.out.println("======== 不分组二次排序-2 =========");
text.sortPartition(0,Order.ASCENDING)
.sortPartition(1,Order.DESCENDING) // 排序可以连续调用
.first(3).print();
}
}
8.2、Scala代码实现
package cn.Batch
import org.apache.flink.api.common.operators.Order
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable.ListBuffer
/**
* @Author: Henry
* @Description: FirstN 操作
* @Date: Create in 2019/5/16 21:28
**/
object BatchDemoFirstN {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val data = ListBuffer[Tuple2[Int,String]]()
data.append((2,"zs"))
data.append((4,"ls"))
data.append((3,"ww"))
data.append((1,"xw"))
data.append((1,"aw"))
data.append((1,"mw"))
val text = env.fromCollection(data)
//获取前3条数据,按照数据插入的顺序
text.first(3).print()
println("==============================")
//根据数据中的第一列进行分组,获取每组的前2个元素
text.groupBy(0).first(2).print()
println("==============================")
//根据数据中的第一列分组,再根据第二列进行组内排序[升序],获取每组的前2个元素
text.groupBy(0).sortGroup(1,Order.ASCENDING).first(2).print()
println("==============================")
//不分组,全局排序获取集合中的前3个元素,
text.sortPartition(0,Order.ASCENDING).sortPartition(1,Order.DESCENDING).first(3).print()
}
}
8.3、运行结果
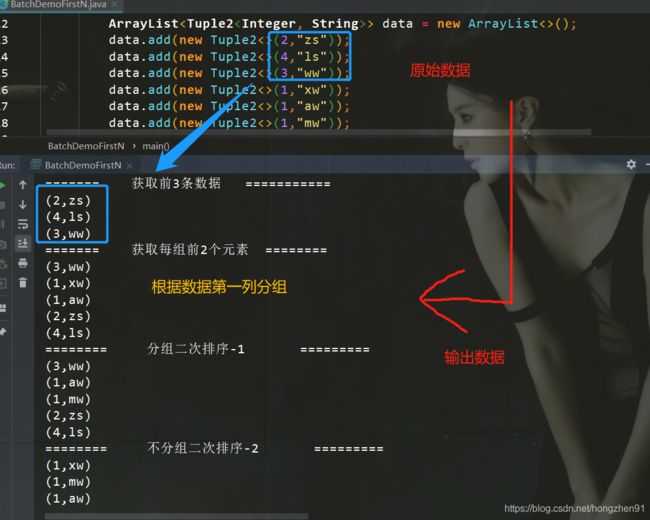
下一节:【09】Flink 之 DataSet API(三):DataSet Sink 操作