ChatGPT类工具如何实现「降维打击」| 聊天机器人闭门研讨观点总结
导读
随着ChatGPT出现,语言大模型的进步与对话交互方式相结合,正在搅动科研、产业,以及普通人的想象力。我们对智能的探索是正在步入决胜之局,还是仍在中场酣战;是需要精巧完备的一致系统,还是可以遵循实效至上Worse is Better的设计哲学?打造面向未来的LLM与Chatbot,技术人员面对哪些共同阻碍,有哪些极限有待超越,如何协作共赢?
在青源Workshop(第20期)|LLM and Chatbot: Endgame, Worse is Better, How to Win Big 研讨会上,智源社区与青源会邀请十余位相关领域专家,围绕以上话题展开热烈研讨。

引导报告环节,袁进辉提出:
ChatGPT 开启了全新维度的竞争。无论是科研单位还是企业,有 ChatGPT 类工具的加持将对不具备此类工具的竞争者形成「降维打击」;
实现 ChatGPT 需要解决数据、算力、工程架构和算法模型细节四大难题;
对 ChatGPT 的开源不仅是一个技术问题,更是一个机制问题,开源 ChatGPT 的成功可能成为国内开源深度学习框架、基础架构、AI 芯片生态成功的「秘密武器」。
邱锡鹏提出:
GPT 的知识边界仍然只是人类知识的一小部分。
以2022全国高考客观卷为例测试性能,ChatGPT 在文综等具有大量公开信息的科目上取得了 78% 的得分率,而在数学、物理、化学、历史等科目上表现欠佳。
车万翔提出:
ChatGPT的诞生,源于研究者「暴力美学」的手段。
如果大胆预测,ChatGPT能火几年,我猜可能是2到3年的时间,到2025年大概又要更新换代了。
工业界相较于学术界拥有巨大优势。这种「AI 的马太效应」会造成胜者通吃的局面。更加危急的是,任务、甚至研究领域之间的壁垒被打破了,所有的问题都可以转化为一个「Seq2Seq」问题,计算机视觉等领域的研究者也会逐渐涌入该领域。
与搜索引擎时代类似,如果将 OpenAI 比作当年的 Google,国内也一定会出现 ChatGPT 时代的「百度」。在这之前,许多机构和企业都有机会放手一搏,做出自己的大模型。相较于其它领域的研究者,NLPer 的真正优势可能在于更加了解语言。
符尧提出:
大规模语言模型的构建可以分为「预训练」、「指令微调」、「对齐」、「专门化」(Specialization)四步。
「涌现能力」曲线所示,只有当模型的大小增大到一定程度时,模型的能力(如举一反三、跨域迁移等能力)才会产生跳变。因此,只有大模型才能有效提升这些效果。
参会嘉宾名单
扫描下方二维码填写表单,获取更多相关岗位机会

一流科技袁进辉:
一起做一个完全开源的 ChatGPT?

袁进辉提出,与 ImageNet、AlphaGo 、Stable Diffusion 类似,ChatGPT 也是一次我们正在经历的重大技术革新。ChatGPT 的出现具有重大的经济意义和商业价值,有望重塑产业格局、引领机器学习基础架构和 AI 芯片的发展走向。从产业的角度,ChatGPT 开启了全新维度的竞争。无论是科研单位还是企业,有 ChatGPT 类工具的加持将对不具备此类工具的竞争者形成「降维打击」。

近十年来,开源运动对 AI 技术的发展起到了非常重大的作用。从数据角度看,ImageNet 数据集推进了计算机视觉的发展,LAION-5B 推动了 AIGC 的发展;从深度学习框架角度看,TensorFlow、PyTorch 成为了几乎所有深度学习模型的开发基础;从算法模型的角度看,CNN、Transformer、AlphaFold 等模型的开源促进了它们在各个行业的落地,科学家、工程师们可以在此基础上进行进一步的开发。实际上,中国互联网产业之所以能够迅速追赶上世界最先进的水平,在很大程度上得益于这些开源基础软件。
目前,ChatGPT 仍然没有开源,开源其代码的意义可能也不大。ChatGPT 是一个系统的工程,使用的数据、模型、训练架构并没有开源。在 ChatGPT 的帮助下,OpenAI 相较于其它企业具备了不对称的竞争优势,存在代际差异。
此外,由于全世界只有很小一部分研究者有机会参与到 ChatGPT 这类项目中,使得大量科学家和工程师无法参与其中、贡献自己的聪明才智。这并不利于整个研究社区和工业界的发展。

实现 ChatGPT 需要解决以下四个方面的问题:(1)数据。大量高质量文本语料的抓取、存储、清洗(2)算力。庞大的计算资源(3)工程架构。大规模分布式系统,例如 Megatron-LM、DeepSpeed(4)算法模型细节。上述四大要素之间的组合也存在一些有待探究的地方。当模型规模增大到一定程度时,参数量增长的边际收益递减,而数据一般掌握在少数头部互联网公司手中。相较之下,数据是实现 ChatGPT 的最大障碍。
实际上,国内的企业、科研机构也曾发布各种大规模语言模型。然而,绝大部分企业的投入相较于 OpenAI 仍然有较大差距,这也导致了模型质量的差距。此外,大部分大模型的开源并不彻底,大部分用户在此基础上进行迭代创新,而目前学术界和企业界非常需要开源的 ChatGPT 项目,促进创新、形成合力。
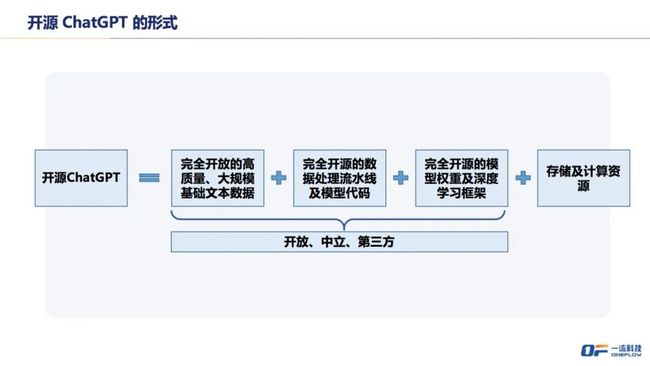
最终开源 ChatGPT 的形式如上图所示。我们不仅应该完全开放数据处理流水线及模型代码,还应该开放高质量、大规模的基础文本数据,以及模型权重即深度学习框架,并共享存储和计算资源。依托开放、中立的第三方完成上述合作。

对 ChatGPT 的开源不仅是一个技术问题,更是一个机制问题。开源 ChatGPT 的成功可能成为国内开源深度学习框架、基础架构、AI 芯片生态成功的「秘密武器」。
复旦大学邱锡鹏:
ChatGPT 的能与不能
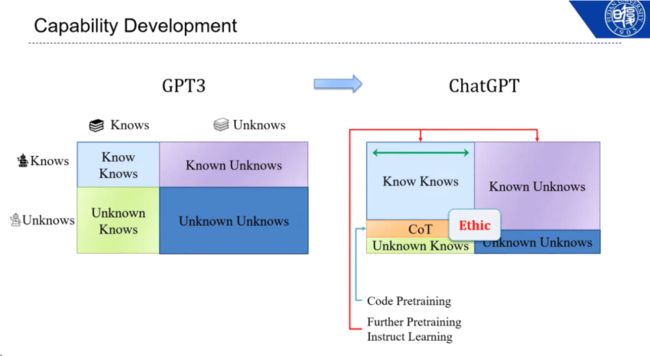
邱锡鹏认为,如果将 ChatGPT 视为一个智能体,我们会关心其能力边界,让智能体明白自己知道什么、不知道什么,使其与人类的意图对齐。如上图中的四象限所示,GPT 的知识边界仍然只是人类知识的一小部分。由于互联网上的知识有限,ChatGPT 对于化学、生物、医疗等领域的问题的回答质量还有待提高。
为了让 ChatGPT 演化出更强的能力,研究者们采取了以下措施:
(1)通过在训练语料中给出更多数据让模型了解更多的事实;
(2)通过广泛收集人类指令,让其明确自己不知道哪些内容,采取安全性策略(例如,继续预训练、指令学习);
(3)通过思维链 CoT 等范式释放智能体的能力,通过代码预训练等方式让智能体能够回答自己「不知道自己知道」的问题;
(4)让智能体避免回答存在伦理风险的问题。上述这些要素这也正是 ChatGPT 相较于 GPT3 的重要提升。
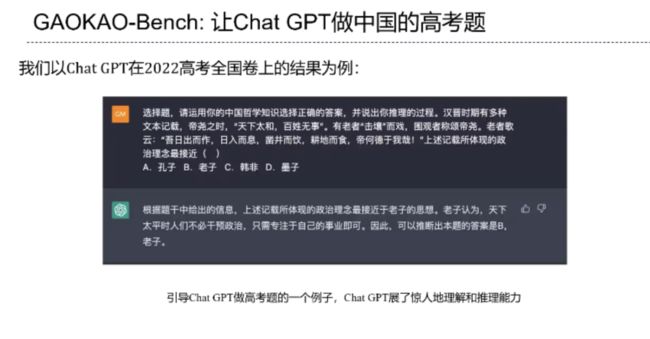
为了明确智能体的能力边界,我们需要构建评测大模型的 BenchMark。为了避免测试问题被 ChatGPT 见过,我们采用了 2022 年的高考试题来测试其性能(ChatGPT 的训练数据为 2021 年及以前知识)。我们发现,ChatGPT 的理解能力和推理能力十分强大,尤其是针对事实类问题而言。
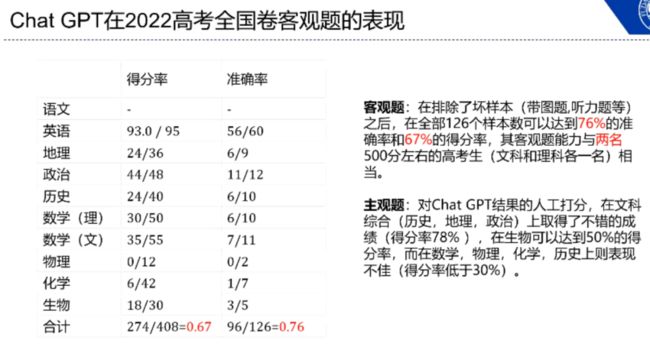
如上图所示,由于语文的阅读理解题很长,ChatGPT 无法处理,所以我们省略了语文科目的测试。在剔除掉非纯文字题目后,ChatGPT 可以在全部 126 个样本上实现 76%的准确率和 67% 的得分率,其客观题能力与 500 分左右的高考生相当。在主观题方面,通过对 ChatGPT 得到的结果进行人工打分,ChatGPT 在文综等具有大量公开信息的科目上取得了 78% 的得分率,而在数学、物理、化学、历史等科目上表现欠佳。
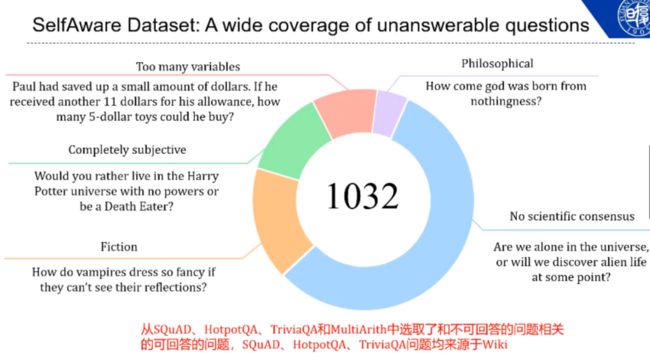
为了探索 ChatGPT 是否知道自己不能回答哪些问题,我们构造了 1032 道没有答案的问题,包含「逻辑混乱的数学题」、「完全主观」的问题、虚假的问题、没有答案的哲学问题、缺乏科学一致性的问题。此外,我们从主流问答数据机中抽取了与不可回答的问题相关的一些「可回答问题」作为混淆样本。
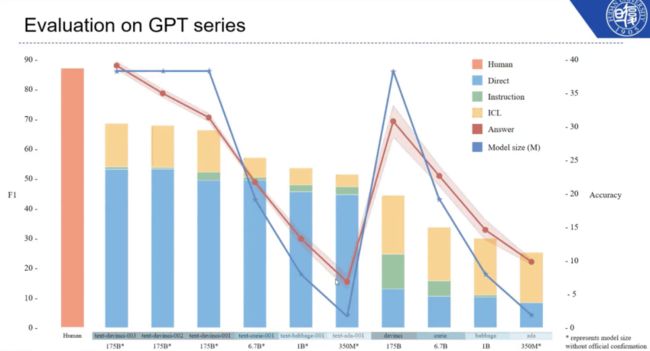
评测结果如上图,所示蓝色的曲线代表模型大小,测试涉及从 350M 到 175B 参数量的模型。实验结果表明,回答的准确率基本上与模型大小相关,模型越大则准确率越高。柱状图代表了不可回答的问题的 F1 值和准确率。人类大约有 80% 的概率发现自己无法回答的问题。
以达芬奇-3 模型为例,它大概有 50% 的概率发现自己无法回答问题。如果通过给出新的例子、In-context Learning 或指令学习,可以将该能力增长到 70% 左右。模型越小,其具有「自知之明」的能力就越差。此外,代码预训练也对提升模型发现自己无法回答问题的能力有很大的帮助。
哈尔滨工业大学车万翔:
ChatGPT时代,NLPer的危与机
自然语言处理领域的发展历史大致可以分为四个阶段:
(1)基于规则的小规模专家知识【1950-1990】
(2)浅层机器学习算法【1990-2010】
(3)深度学习算法【2010-2017】
(4)大规模预训练模型【2018-2023】
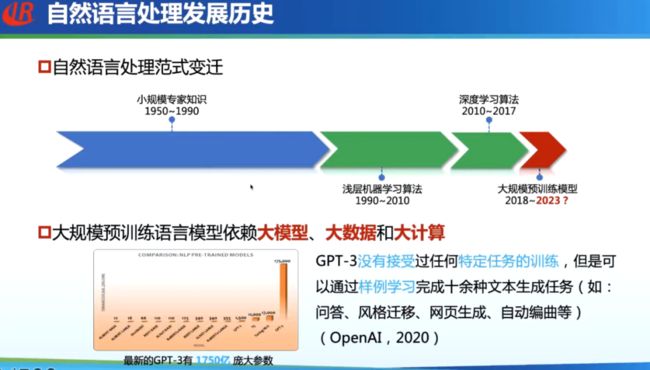
大规模预训练模型依赖于大模型,大数据、大算力。以 GPT-3 为例,该模型在没有经受过任何特定任务训练的情况下,可以通过样例学习完成十余种文本生成任务。

然而,相较于 ChatGPT,OpenAI 两年前发布的GPT-3 并没有引起如此之大的关注度。究其原因,其中之一可能是该模型缺乏知识推理能力,可解释性也欠佳。该模型的原始论文指出,该模型在「故事结尾选择」任务上的能力比哈工大丁效老师等人所提出的具有知识推理能力的模型性能低 4.1%。GPT-3 此类预训练语言模型在深层次语义理解能力上与人类认知水平还有很大差距。
为了解决该问题,一些研究者考虑向模型中引入知识;另一些研究者则采取「暴力美学」的手段,并发展出了如今的 ChatGPT。

如上图所示,ChatGPT 的效果惊艳,不仅能够给出正确的答案,还具有一定的可解释性。
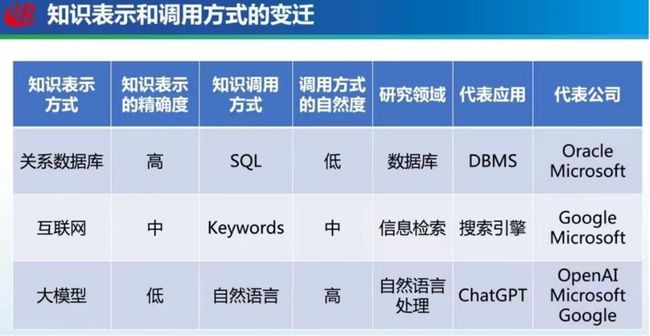
ChatGPT 的成功本质上反映了人们对知识的表示和调用方式产生了重大变革。
在关系型数据库时代,符号化的知识表示精度很高,但是需要使用 SQL 语句调用,较为复杂且不自然,代表性的应用为 DBMS,代表公司为Oracle和微软;
在互联网时代,知识以文字、图像、音频、视频等形式存在,我们通过输入查询关键词来调用知识,代表性的应用为搜索引擎,这个阶段代表公司有谷歌和微软;
在大模型时代,知识表示为大模型及其参数,大模型相当于一个知识库,其知识表示精度较低。在 GPT-3 刚出现时,尽管蕴含大量的知识,但是其调用方式并不自然(构建 Prompt)。ChatGPT 则实现了使用自然语言指令调用知识,这种知识的表示和调用方式是一种根本性的变革。代表公司为OpenAI,微软谷歌以及百度等国内公司也在陆续发力。
语言技术的四个阶段
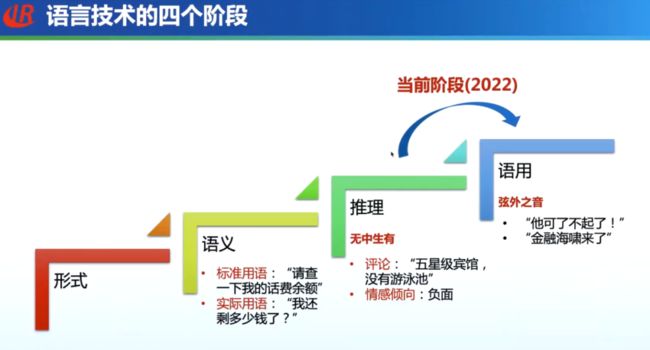
以 Bert 为代表的预训练语言模型主要解决了语义匹配的问题;ChatGPT 相对较好地解决了推理任务;下一阶段,自然语言处理算法需要考虑语用问题,对于同样的语言输入,模型需要理解不同语气、表情、语音、语调所蕴含的不同意义。
ChatGPT的核心技术

具体技术进展方面,ChatGPT 的核心技术主要包含以下四点:(1)大规模预训练模型;(2)Prompt/Instruction Tuning;(3)在代码上进行继续预训练;(4)基于人类反馈的强化学习 RLHF。这些技术的融合形成了惊艳的效果。
NLP学术界如何应对ChatGPT的挑战

ChatGPT时代,为了应对当前的挑战,自然语言领域的研究者可以借鉴信息检索研究者的经验。首先,学术界可能不再进行系统级别的研究,主要集中在相对边缘的研究方向上;其次,使用工业界巨头提供的数据进行实验,并不一定能得出可靠的结论,由于存在隐私问题,数据的真实性存疑;通过调用公司提供的 API 进行研究,一旦模型被调整,其结论有可能也会改变。
与搜索引擎时代类似,如果将 OpenAI 比作当年的 Google,国内也一定会出现 ChatGPT 时代的「百度」。在这之前,许多机构和企业都有机会放手一搏,做出自己的大模型。相较于其它领域的研究者,NLPer 的真正优势可能在于更加了解语言。
爱丁堡大学符尧:
Pretraining, Instruction Tuning,
Alignment, On the Source of
Large Language Model Abilities

大规模语言模型的构建可以分为「预训练」、「指令微调」、「对齐」、「专门化」(Specialization)四步。
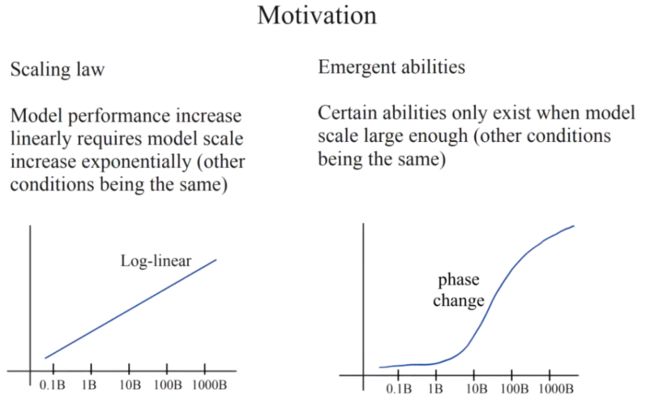
在观察模型的能力时,我们往往需要以动态的视角观察其演化过程。如上图左侧的「缩放法则」所示,当保持其它条件恒定时,模型大小、数据量大小、指令数量等因素的指数级增长将导致 In-Context Learning、零样本学习、分布外泛化、分布内泛化等性能效果的线性提升。如上图右侧的「涌现能力」曲线所示,只有当模型的大小增大到一定程度时,模型的能力(例如,举一反三、跨域迁移的能力)才会产生跳变。因此,只有大模型才能有效提升这些效果。
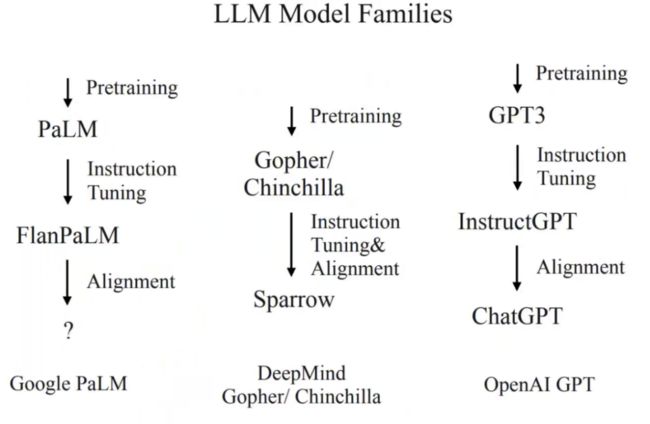
此外,我们还应该纵向地观察模型家族的演化。与 GPT 系列类似,我们不妨观察 PaLM 和 Gopher/Chinchilla 模型家族的变化。Google 通过预训练得到了 PaLM 模型,经过指令微调得到了 FlanPaLM、再经过 Alignment 得到它们最新的模型。DeepMind 通过预训练得到了 Gopher/Chinchilla,再通过指令微调和对齐得到 Sparrow 模型。
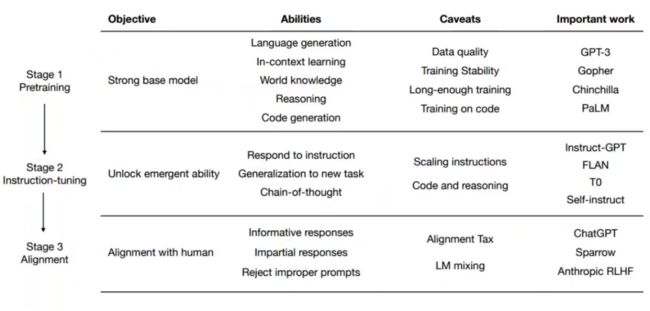
综合上述,我们可以将此类模型的发展分为三个阶段:
(1)预训练。得到强大的基础模型,获得语言生成、In-context Learning、获取世界知识、推理、代码生成等能力。模型大小的指数级增长伴随着数据量的指数级增长。
(2)指令微调。指令种类指数增长,导致模型零样本迁移能力的线性增长。思维链等能力有时会在预训练后直接出现(例如,PaLM)。指令微调的效果和基础模型息息相关。
(3)对齐。牺牲模型能力,换取模型的「安全」。将模型的某些能力弱化,使其在特定方面符合人类的期望。

预训练旨在得到强大的基础模型。一些著名的预训练模型如上图左侧所示。值得一提的是,Galactica 模型本身的预训练效果不错,然而由于其返回的结果不太符合人类预期(对齐欠佳)所以被 Meta 下线后开源。Galactica 的开源模型包含 30B 参数和 120B 参数两个版本,可以直接在 Hugging Face 上下载。预训练可以得到语言生成、世界知识、In-context Learning、代码理解/生成、复杂推理/思维链等能力。

指令微调旨在加强预训练模型的已有能力,或者开发出预训练模型不具备的能力,要求指令种类足够多,每种指令的例子也要足够多。指令的指数级增长会带来跨域迁移能力的线性增长。单个指令下实例数指数级增长也会带来该指令能力的线性增长,但可能使其它指令的能力弱化。因此,指令微调的思路为让模型在各项维度上的能力全面扩张。
目前意识到指令微调重要性的工作并不多。其中,「LM self-instruct」较为出色,它模拟了未经过指令微调的初代 GPT 175B 到经过指令微调的 Text-davinci 001 之间的演化。
如上图右侧所示,指令微调可以有效提升模型的各项泛化能力。其中,组合泛化能力尤为重要。例如,如果给定的指令同时包含摘要、问答、生成代码的指令,模型可以自动将这三项能力混合在一起,同时完成问答、摘要生成、代码生成的任务。
我们可以将指令视为线性代数中的一组基,将不同能力混合在一起实际上就是对线性空间中的基做线性组合或凸组合。模型在没有见过指令时,只能在学到的空间内做内插,而很难外推到没有学习到的基上。

对齐旨在塑造模型的「价值观」,使其符合人类的期望,进而塑造模型的「人格」。对齐将决定模型回答的字数、回答信息的倾向性和方式。在训练时,可先进行监督学习、再进行 RLHF,充分发挥 RLHF 的效果。神奇的是,经过对齐操作后,模型遇到无法解决的问题,会回答「不知道」。

在经过了预训练、指令微调、对齐操作后,我们进一步考虑对模型进行专门化处理,使 ChatGPT 的能力从大学生成长为博士生或教授。我们假设模型的总体能力有限,可能需要弱化模型的某些能力,同时增强其它期望的能力。

如上图所示,在进行模型专门化时,我们首先也需要进行模型预训练,接着进行指令微调。我们发现,对指令微调后的模型进行专门化处理的效果要远远优于对原始预训练模型进行专门化处理的效果。
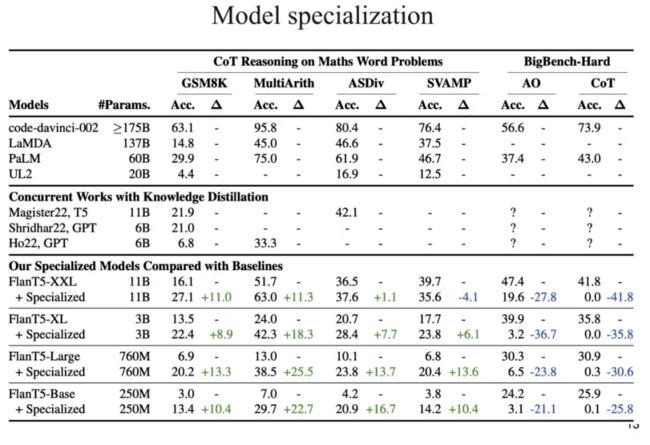
如上图所示,针对数学问题,我们考虑测试模型的思维链推理能力。经过专门化后,模型在 BigBench-Hard 这种通用测试上的能力有所下降,而在数学问题上的思维链推理能力有所增强。通用能力下降的程度预模型大小相关,模型越大,通用能力下降得越少。为了测试模型的分布外泛化能力,我们使用 GSM8K 作为训练数据集,使用 MultiArith、ASDiv、SVAMP 作为测试集。
Q&A
Q1 :开源共享已经成为了学界、业界的共识。请问推进该工作的难度主要有哪些?
袁进辉:难度主要在于建立合适的机制,让各方明确参与其中需要作出的贡献以及对自身的帮助。在组织过程中,需要公正、公开、透明地进行决策。在具体操作层面上,需要重视数据部分的工作,建立合适的数据确权、声誉匹配机制以及相应的规范。
Q2:中英文数据质量又何区别,在中文上开发 ChatGPT 这样的模型有哪些数据层面上的难点?
邱锡鹏:中文互联网上数据的清洗难度高于英文数据,整体质量也较差。在训练时,英文数据的比重应该较大。当模型规模足够大时,跨语言的能力会十分强。
Q3:在资源有限的情况下,如何培训大模型训练研究和工程人员?因为试错成本很⾼,不可能每⼈64卡,按照学习怎么⽤ CNN做CIFAR-10分类那样学习?
邱锡鹏:学术界和工业界的研究风格有所差别。一方面,我们承认大模型很重要,它是很好的基础。另一方面,我们也追求多样性的研究。就大模型本身而言,也有很多值得研究的地方,例如领域适配。我们也需要在其它路线上进行技术储备,并非所有信息非要记载到达模型中。此外,智能体之间也应该有所差异。
符尧:充分利用自己可支配的卡跑实验,并结合多篇同一领域的论文,相互对比。利用 DeepSpeed 等工具也可以在实验室的服务器上验证一些较大的模型(例如,参数量为 11B)。结合「放缩法则」,我们可以观测到曲线的规律,并对其进行外推,许多模型能力在参数量为 11B 时就可以被观测到。实际上,OpenAI 在开发 GPT-3 之前,就率先研究了「放缩法则」,在小模型上先通过多次试验总结出曲线规律,预测出了模型能力随规模增大而变化的趋势,最终才决定推动 GPT-3 项目。
Q4:现在大厂纷纷入局ChatGPT,未来还会有哪些新的应用场景?
袁进辉:比如我们可以借助 ChatGPT 实现更智能的数字助理,为人类提供外脑,增强人类的智慧。它可以帮助我们完成看病求医、购物决策,甚至是股票决策。越来越多的人可以获得更加专业性的建议。
更多内容 尽在智源社区
