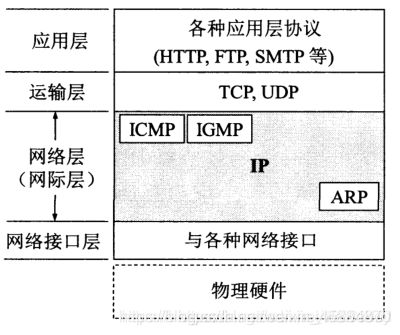
计算机网络笔记六(网络层:基础概念、IP协议、ICMP协议)
1.网络层基础
1.1补充
1.1.1打个比方
比如:应用层就是需要发送或者接收快递的人,IP地址就是接收或者发送人的住址,端口号就是房间里哪个人。那么需要发送快递,传输层就相当于快递公司,快递公司各有各的特点,有保证实时性的,有保证可靠的等等,网络层相当于传输过程中的一个个中转站,快递包裹从哪里来又到哪里去是它需要负责的。数据链路层就是快递员,他负责包裹的实际传输,是开飞机去传输包裹,还是开车去传输包裹?(粗浅看法,若有问题,后期更改)
1.1.2各层传输的数据单元
1.报文(message)
报文是网络中交换与传输的数据单元,也是网络传输的单元。报文包含了将要发送的完整的数据信息,其长短不需一致。报文在传输过程中会不断地封装成分组、包、帧来传输,封装的方式就是添加一些控制信息组成的首部,那些就是报文头。
2.分组(packet)
分组是在网络中传输的二进制格式的单元,为了提供通信性能和可靠性,每个用户发送的数据会被分成多个更小的部分。在每个部分的前面加上一些必要的控制信息组成的首部,有时也会加上尾部,就构成了一个分组。
3.数据包(data packet)
数据包是TCP/IP协议通信传输中的数据单元,也称为“包”。是指自包含的,带有足够寻址信息,可独立地从源主机传输到目的主机,而不需要依赖早期的源主机和目的主机之间交换信息以及传输网络的数据包。
4.数据报(datagram)
面向无连接的数据传输,其工作过程类似于报文交换。采用数据报方式传输时,被传输的分组称为数据报。
5.帧(frame)
帧是数据链路层的传输单元。它将上层传入的数据添加一个头部和尾部,组成了帧。
应用层 —— 消息 ( message)
传输层 —— 报文段,数据段(segment)
网络层 —— 分组、数据包(packet, datagram)
链路层 —— 帧(frame)
物理层 —— P-PDU(bit)
(《计算机网络——自顶向下方法》)
1.2网络层相关概念
1.2.1网络层功能
网络层向上只提供简单的、无连接的、尽最大努力交付的数据报服务,这里数据报就是IP数据报也就是分组。
1.2.2过程
在网络层,数据传输的基本单位是数据包(也称为分组)。在发送方,传输层的报文到达网络层时被分为多个数据块,在这些数据块的头部和尾部加上一些相关控制信息后,即组成了数据包(组包)。数据包的头部包含源结点和目标结点的网络地址(逻辑地址)。在接收方,数据从低层到达网络层时,要将各数据包原来加上的包头和包尾等控制信息去掉(拆包),然后组合成报文,送给传输层。
1.2.3网络层相关协议
1>地址解析协议 ARP(Address Resolution Protocol)
2>网际控制报文协议 ICMP(Internet Control Message Protocol)
3>网际组管理协议 IGMP(Internet Group Management Protocol)
4>网际协议 IP(Internet Protocol)
1.3子网划分
1.3.1IP地址组成及其分类
目前的IP地址是“IPv4”地址
IP地址有两部分组成
①网络号码字段(net-id),用于区分不同网络。
②主机号码字段(host-id),用于区分一个网络内的不同主机
IP地址的分类 分三个部分进行讲述:
① 五类IP
② 特殊用途的IP
③ 私有IP
1 .五类IP
IPV4地址分为五类。
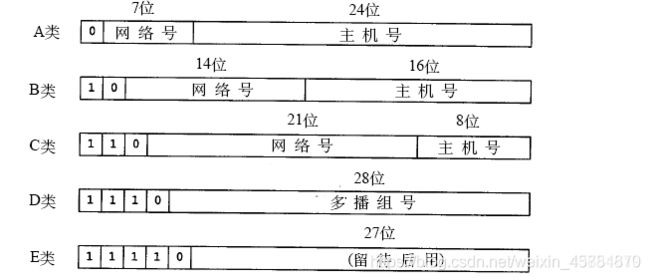 A: 0.0.0.0-127.255.255,其中段0和127不可用
A: 0.0.0.0-127.255.255,其中段0和127不可用
B: 128.0.0.0-191.255.255.255
C: 192.0.0.0-223.255.255.255
D: 224.0.0.0-239.255.255.255
E: 240.0.0.0-255.255.255.255,其中段255不可用
这其中除了段0和段127之外,还有一些IP地址因为有其他的用途,是不可以用作普通IP的。还有一部分被用作私有IP地址。
2 .特殊用途的IP
将这些特殊的IP地址分为三类,特殊IP地址、环回地址以及广播地址。
①特殊IP地址
如255.255.255.255。这个地址为本地广播地址
如0.0.0.0。如果作为网络地址,代表的意思是任何网络。作为主机接口地址,那就是这个这个网络上的这个主机的接口,一般作为请求分配地址时,发送DHCP请求报文源IP地址
②环回地址
A类网络地址127是一个保留地址,用于网络软件测试以及本地机进程间通信,叫做环回地址(loopback address)。无论什么程序,一旦使用环回地址发送数据,协议软件立即返回之,不进行任何网络传输。
含网络号127的分组不能出现在任何网络上。
③广播地址
TCP/IP规定,主机号全为"1"的网络地址用于广播之用,叫做广播地址。所谓广播,指同时向同一子网所有主机发送报文。
3 私有IP
与私有IP地址对应的是公有地址(Public address),由Inter NIC(Internet Network Information Center 因特网信息中心)负责。这些IP地址分配给注册并向Inter NIC提出申请的组织机构。通过它直接访问因特网。
私有IP的出现是为了解决公有IP地址不够用的情况。从A、B、C三类IP地址中拿出一部分作为私有IP地址,这些IP地址不能被路由到Internet骨干网上,Internet路由器也将丢弃该私有地址。如果私有IP地址想要连至Internet,需要将私有地址转换为公有地址。这个转换过程称为网络地址转换(Network Address Translation,NAT),通常使用路由器来执行NAT转换。
范围如下:
A: 10.0.0.0~10.255.255.255 即10.0.0.0/8
B:172.16.0.0~172.31.255.255即172.16.0.0/12
C:192.168.0.0~192.168.255.255 即192.168.0.0/16
A类地址应用于大型网络中,有2的24次方减2个可用地址
第一个八位组为网络部分,其余三个八位组为主机部分
B类地址应用于中型网络中,有2的16次方减2个可用地址
前两个八位组为网络部分,其余两个八位组为主机部分
C类地址应用于小型网络中,有2的8次方减2个可用地址
前三个八位组为网络部分,其余一个八位组为主机部分
1.3.2子网掩码
子网掩码(subnet mask)又叫网络掩码、地址掩码、子网络遮罩,它是一种用来指明一个IP地址的哪些位标识的是主机所在的子网,以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合IP地址一起使用。子网掩码只有一个作用,就是将某个IP地址划分成网络地址和主机地址两部分。子网掩码是一个32位地址,用于屏蔽IP地址的一部分以区别网络标识和主机标识,并说明该IP地址是在局域网上,还是在远程网上。
子网掩码(subnet mask)是每个使用互联网的人必须要掌握的基础知识,只有掌握它,才能够真正理解TCP/IP协议的设置。
子网掩码–屏蔽一个IP地址的网络部分的"全1"比特模式。
对于A类地址来说,默认的子网掩码是255.0.0.0;
对于B类地址来说默认的子网掩码是255.255.0.0;
对于C类地址来说默认的子网掩码是255.255.255.0。
1.3.3子网划分
意义与作用:
节约IP地址,避免浪费。 限定广播的传播。 保证网络的安全。 有助于覆盖大型地理区域。
经过子网划分后,IP地址的子网掩码不再具有标准IP地址的掩码,由此IP地址可以分为两类:有类地址和无类地址
有类地址:标准的IP地址(A ,B, C 3类)属于有类地址
无类地址:经过子网划分的IP地址就是无类地址
实例:
如公司分到了一个C类地址192.168.100.0 /24
公司有四个部门每个部门的主机数不到50台
1.为4个公司划分4个子网,根据公式2的n次方等于4得出n等于2,及子网部位为2
2.主机部分位数为8-2=6,则可用的主机位数为2的6次方等于减2等于62,应为每个部门的主机数不超过50台所以可以满足
子网划分公式:
如果要将一个网络划分成多个子网,如何确定这些子网的子网掩码和IP地址中的网络号和主机号呢?子网划分的步骤如下:
第1步,将要划分的子网数目n转换为2的m次方。如要分8个子网,8=2^3。如果不是恰好是2的多少次方,则取大为原则,如要划分为6个,则同样要考虑2 ^3。
第2步,将上一步确定的幂m按高序占用主机地址m位后,转换为十进制。如m为3表示主机位中有3位被划为“网络标识号”占用,因网络标识号应全为“1”,所以主机号对应的字节段为“11100000”。转换成十进制后为224,这就最终确定的子网掩码。如果是C类网,则子网掩码为255.255.255.224;如果是B类网,则子网掩码为255.255.224.0;如果是A类网,则子网掩码为255.224.0.0。
在这里,子网个数与占用主机地址位数有如下等式成立:2m≥n。其中,m表示占用主机地址的位数;n表示划分的子网个数。根据这些原则,将一个C类网络分成4个子网。
参考:https://blog.csdn.net/weixin_43751619/article/details/84629127
2.IP协议
2.1IP的首部格式
一个ip数据报由首部和数据两部分组成,首部的前一部分是固定长度(这是所有ip数据报必须要有的),共20字节,是所有ip数据报必须具有的,而首部的固定部分的后面试一些可选字段,其长度是可变的,如下图所示:
 我们来看看其中固定部分的各个字段是什么意思
我们来看看其中固定部分的各个字段是什么意思
版本:占4位,指IP协议的版本。目前IP、协议的版本号大多数还是4(即IPv4)
首部长度:占4位,可表示的最大数值是15个单位(一个单位为4字节),因此IP的首部长度的最大值是60字节。
区分服务:占8位,用来获得更好的服务。只有在使用区分服务(DiffServ)时,这个字段才起作用,在一般的情况下都不使用这个字段
总长度:占16位,指首部和数据之和的长度,单位为字节,因此数据报的最大长度为65535字节。总长度必须不超过最大传送单元MTU
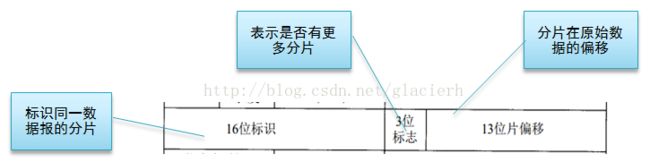
标识:占16位,它是一个计数器,用来产生IP数据报的标识。注意,这不是序号,因为IP是无连接服务,不需要进行排序接收,但是,如果当一个数据报过长,超出了MTU,所以必须分片时,标识就可以把相同的标识的数据报片整合起来变成原来的数据报。
标志:占三位,目前只有前两位有意义。标志字段的最低位是MF(More Fragment),MF=1表示后面“还有分片”;MF=0表示最后一个分片。标志字段中间一位是DF(Don`t Fragment),只有当DF=0时才允许分片。
片偏移:占13位,指出较长的分组在分片后某片在原分组中的相对位置(片偏移以8个字节为偏移单位)
生存时间:占8位,记为TTL(Time to Live),指示数据报在网络中可通过的路由器数的最大值。也就是跳数限制,当TTL减为零时,就会被抛弃。
协议:占8位,指出此数据报携带的数据使用何种协议(TCP,UDP、ICMP、IGMP等),以便目的主机的IP层将数据部分上交给那个处理过程
首部检验和:首部检验和的计算采用16位二进制反码求和算法,只检验首部不检验数据部分。
原地址:占四字节
目的地址:占四字节
可变部分:长度为1~40字节,IP地址中的可变部分可用于支持很多操作,但很多情况都用不上,而且会增加路由器处理分组的开销,所以IPv6中的数据报首部做成了固定长度。
2.2IP的分片
2.2.1分片原因
在TCP/IP分层中,数据链路层用MTU(Maximum Transmission Unit,最大传输单元)来限制所能传输的数据包大小,MTU是指一次传送的数据最大长度,不包括数据链路层数据帧的帧头,如以太网的MTU为1500字节,实际上数据帧的最大长度为1512字节,其中以太网数据帧的帧头为12字节。
当发送的IP数据报的大小超过了MTU时,IP层就需要对数据进行分片,否则数据将无法发送成功。
2.2.2MSS的原理
MSS就是TCP数据包每次能够传输的最大数据分段。为了达到最佳的传输效能TCP协议在建立连接的时候通常要协商双方的MSS值,这个值TCP协议在实现的时候往往用MTU值代替(需要减去IP数据包包头的大小20Bytes和TCP数据段的包头20Bytes)所以往往MSS为1460。通讯双方会根据双方提供的MSS值得最小值确定为这次连接的最大MSS值。
当IP数据报被分片后,每一片都成为一个分组,具有自己的IP首部,并在选择路由时与其他分组独立。这样,当数据报的这些片到达目的端时有可能会失序,但是在IP首部中有足够的信息让接收端能正确组装这些数据报片。
尽管IP分片过程看起来是透明的,但有一点让人不想使用它:即使只丢失一片数据也要重传整个数据报。因为IP层本身没有超时重传的机制——由更高层来负责超时和重传(T C P有超时和重传机制,但UDP没有。一些UDP应用程序本身也执行超时和重传)。当来自T C P报文段的某一片丢失后,T C P在超时后会重发整个T C P报文段,该报文段对应于一份IP数据报。没有办法只重传数据报中的一个数据报片。事实上,如果对数据报分片的是中间路由器,而不是起始端系统,那么起始端系统就无法知道数据报是如何被分片的。就这个原因,经常要避免分片。
MTU=MSS+20(IP首部)+20(TCP首部);
一般网络协商使用MTU代替MSS
2.2.3IP分片的实现
IP分片发生在IP层,不仅源端主机会进行分片,中间的路由器也有可能分片,因为不同的网络的MTU是不一样的,如果传输路径上的某个网络的MTU比源端网络的MTU要小,路由器就可能对IP数据报再次进行分片。而分片数据的重组只会发生在目的端的IP层。
在IP首部有4个字节是用于分片的,如下图所示。前16位是IP数据报的标识,同一个数据报的各个分片的标识是一样的,目的端会根据这个标识来判断IP分片是否属于同一个IP数据报。中间3位是标志位,其中有1位用来表示是否有更多的分片,如果是最后一个分片,该标志位为0,否则为1。后面13位表示分片在原始数据的偏移,这里的原始数据是IP层收到的传输的TCP或UDP数据,不包含IP首部。
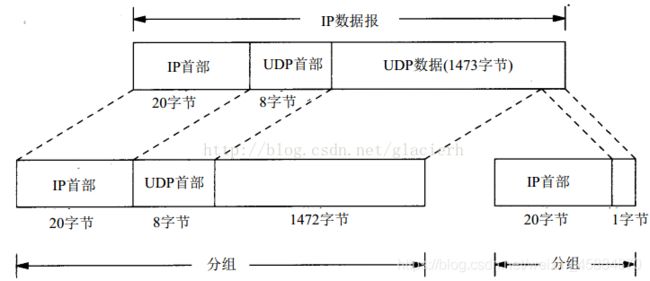
 需要注意的,在分片的数据中,传输层的首部只会出现在第一个分片中,如下图所示。因为传输层的数据格式对IP层是透明的,传输层的首部只有在传输层才会有它的作用,IP层不知道也不需要保证在每个分片中都有传输层首部。所以,在网络上传输的数据包是有可能没有传输层首部的。
需要注意的,在分片的数据中,传输层的首部只会出现在第一个分片中,如下图所示。因为传输层的数据格式对IP层是透明的,传输层的首部只有在传输层才会有它的作用,IP层不知道也不需要保证在每个分片中都有传输层首部。所以,在网络上传输的数据包是有可能没有传输层首部的。
2.2.4避免IP分片
在网络编程中,我们要避免出现IP分片,那么为什么要避免呢?原因是IP层是没有超时重传机制的,如果IP层对一个数据包进行了分片,只要有一个分片丢失了,只能依赖于传输层进行重传,结果是所有的分片都要重传一遍,这个代价有点大。由此可见,IP分片会大大降低传输层传送数据的成功率,所以我们要避免IP分片。
对于UDP包,我们需要在应用层去限制每个包的大小,一般不要超过1472字节,即以太网MTU(1500)—UDP首部(8)—IP首部(20)。
对于TCP数据,应用层就不需要考虑这个问题了,因为传输层已经帮我们做了。在建立连接的三次握手的过程中,连接双方会相互通告MSS(Maximum Segment Size,最大报文段长度),MSS一般是MTU—IP首部(20)—TCP首部(20),每次发送的TCP数据都不会超过双方MSS的最小值,所以就保证了IP数据报不会超过MTU,避免了IP分片。
2.2.5IP分片算法的原理
分片重组是IP层一个最重要的工作,其处理的主要思想:当数据包从一个网络A进入另一个网络B时,若原网络的数据包大于另一个网络的最大数据包的长度,必须进行分片。
因而在IP数据包的报头有若干标识域注明分片包的共同标识号、分片的偏移量、是否最后一片及是否允许分片。传输途中的路由器利用这些标识域进行分片,目的主机把收到的分片进行重组以恢重数据。因此,分片包在经过网络监测设备、安全设备、系统管理设备时,为了获取信息、处理数据,都必须完成数据包的分片或重组。
![]() R:保留未用;DF:Don’t Fragment,“不分片”位,如果将这一比特置1,IP 层将不对数据报进行分片;MF:More Fragment,“更多的片”,除了最后一片外,其它每个组成数据报的片都要把比特置1;Fragment Offset:该片偏移原始数据包开始处的位置。偏移的字节数是该值乘以8。
R:保留未用;DF:Don’t Fragment,“不分片”位,如果将这一比特置1,IP 层将不对数据报进行分片;MF:More Fragment,“更多的片”,除了最后一片外,其它每个组成数据报的片都要把比特置1;Fragment Offset:该片偏移原始数据包开始处的位置。偏移的字节数是该值乘以8。
100-----保留未用
010-----不分片
001----- 有分片
000-----该ID标识下最后一个分片数据包
参考:https://blog.csdn.net/shenwansangz/article/details/44305965
2.3IP选路
2.3.1相关概念
IP选路,即IP寻路,就是根据路由表中的记录,来决定当前数据报是直接交付(目的地址属于当前局域网)还是发往下一跳路由(隶属于不同的局域网)。
路由!我们通常讲的路由是指路由信息,也就是去往目的地的一条信息,它指明了去往目的地的方向。同时,路由也可以表示寻径,是指路由器在收到IP包后,去寻找自己路由信息进行转发的过程。
路由表就是存放路由信息的地方。
2.3.2路由表包含的内容
路由条目必须包含的五项内容:前缀/掩码、下一跳、出接口、管理距离(AD)或叫优先级、度量。
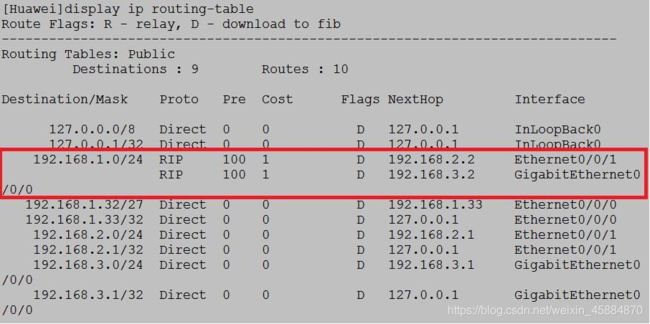 如上表:
如上表:
destination/mask:前缀与掩码,表示目标网络。
proto:产生方式,direct就是直接自动生成,RIP、OSPF等都是动态路由协议产生,static是静态路由协议产生。
pre:优先级,与proto的协议相对应,direct优先级最高为0,OSPF为10,Static为60……
cost:开销,越小越优先,当优先级(使用的协议)一样时看cost,cost依据的是带宽。
Flags:一种是D,一种是R
NextHop:下一跳地址
Interface:接口
路由器负责为数据包选择一条最优路径,并进行转发。每个路由器都维护有自己的网路图,以便计算自身与其他节点之间的最短路径来更新其路由表。路由表中如果有多个匹配目的网络的路由条目,则路由器会选择掩码最长的条目。
2.3.3路由器转发IP包的原则
1> 有路由匹配就转发,没有就丢弃
2> 匹配多条时遵循最长匹配原则(掩码)
3> 生成路由表的三种途径
a:直接自动生成
b:静态路由协议
c:动态路由协议
路由协议用于路由器之间帮助路由器构建路由表的网路协议
小型网络可能只需要直连和静态路由就能构建完整的路由表。
大型网络则必须使用动态路由协议让路由器之间相互学习路由信息,从而构建完整的路由表。
静态路由与动态路由的比较
静态路由:
网络管理员手动地将静态路由输入到路由表中。
网络拓扑改变需要手动更新路由。
路由行为可以精确控制。
使用情况:
在只需要简单路由的小网络中。
在hub and spoke网络拓扑中。
当想快速创建一个临时路由时。
动态路由:
网络路由协议在拓扑或业务改变时自动调整动态路由。
路由器通过动态的交换路由更新来学习和维护到远程目的地的路由。
路由器通过共享路由表消息来发现新的网络。
使用情况:
大型网络中
网络需要拓展。
IP通信是双向的
从源访问目的经过的每一个网络节点都必须有去往目的网络的路由。
从目的响应源经过的每一个网络节点都必须有去往源网络的路由。
去向与回程是两条完全不同且不相关的两条路由。
动态路由是指路由器能够自动地建立自己的路由表,并且能够根据实际实际情况的变化适时地进行调整。动态路由机制的运作依赖路由器的两个基本功能:对路由表的维护;路由器之间适时的路由信息交换。
两个著名的动态路由协议:
RIP(路由信息协议):基于距离矢量算法,它选择路由的度量标准(metric)是跳数,最大跳数是15跳,如果大于15跳,它就会丢弃数据包。
缺点:
1). RIP的15跳限制,超过15跳的路由被认为不可达
2). RIP不能支持可变长子网掩码(VLSM),导致IP地址分配的低效率
3). 周期性广播整个路由表,在低速链路及广域网云中应用将产生很大问题
4). 收敛速度慢于OSPF,在大型网络中收敛时间需要几分钟
5). RIP没有网络延迟和链路开销的概念,路由选路基于跳数。拥有较少跳数的路由总是被选为最佳路由即使较长的路径有低的延迟和开销
6). RIP没有区域的概念,不能在任意比特位进行路由汇
OSPF(开放式最短路径优先):基于链路状态及最短路径树算法,较之RIP略显复杂。
优点:
1).没有跳数的限制
2).支持可变长子网掩码(VLSM)
3).使用组播发送链路状态更新,在链路状态变化时使用触发更新,提高了带宽的利用率
4).收敛速度快,状态更新能快速覆盖整个网络。
5).具有认证功能
参考:https://blog.csdn.net/wh1511995112/article/details/51474692
3.ICMP协议(次要)
3.1ICMP协议是一个网络层协议。
一个新搭建好的网络,往往需要先进行一个简单的测试,来验证网络是否畅通;但是IP协议并不提供可靠传输。如果丢包了,IP协议并不能通知传输层是否丢包以及丢包的原因。所以我们就需要一种协议来完成这样的功能–ICMP协议。
3.2ICMP协议的功能
ICMP协议的功能主要有:
1.确认IP包是否成功到达目标地址
2.通知在发送过程中IP包被丢弃的原因
如下图所示:
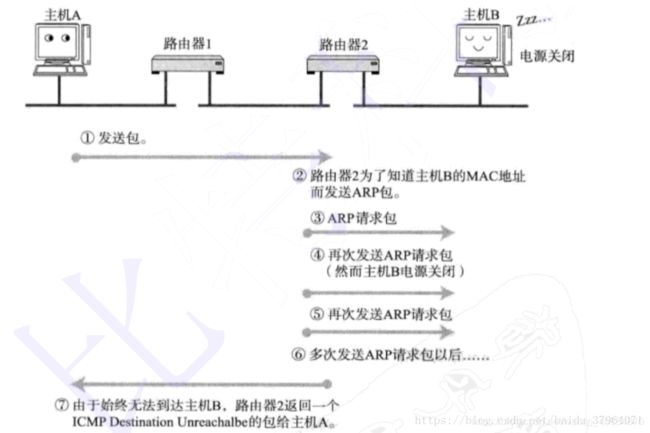
我们需要注意几点:
1.ICMP是基于IP协议工作的,但是它并不是传输层的功能,因此仍然把它归结为网络层协议
2. ICMP只能搭配IPv4使用,如果是IPv6的情况下, 需要是用ICMPv6
3.3ICMP的报文格式
ICMP报文包含在IP数据报中,IP报头在ICMP报文的最前面。一个ICMP报文包括IP报头(至少20字节)、ICMP报头(至少八字节)和ICMP报文(属于ICMP报文的数据部分)。当IP报头中的协议字段值为1时,就说明这是一个ICMP报文。ICMP报头如下图所示。
如下图:

字段说明:

3.4ICMP大概分为两类报文
一类是通知出错原因 ;一类是用于诊断查询
类型及含义如下:
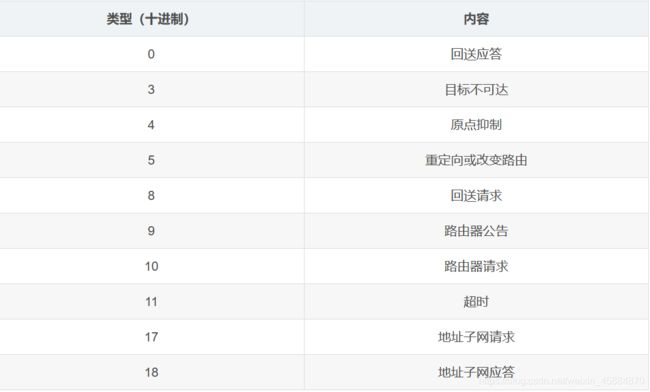 常见的ICMP报文
常见的ICMP报文
响应请求
我们用的ping操作中就包括了响应请求(类型字段值为8)和应答(类型字段值为0)ICMP报文。
过程:
一台主机向一个节点发送一个类型字段值为8的ICMP报文,如果途中没有异常(如果没有被路由丢弃,目标不回应ICMP或者传输失败),则目标返回类型字段值为0的ICMP报文,说明这台主机存在。
目标不可达,源抑制和超时报文
这三种报文的格式是一样的。
(1)目标不可到达报文(类型值为3)在路由器或者主机不能传递数据时使用。
例如:我们要连接对方一个不存在的系统端口(端口号小于1024)时,将返回类型字段值3、代码字段值为3的ICMP报文。
常见的不可到达类型还有网络不可到达(代码字段值为0)、主机不可达到(代码字段值为1)、协议不可到达(代码字段值为2)等等。
(2)源抑制报文(类型字段值为4,代码字段值为0)则充当一个控制流量的角色,通知主机减少数据报流量。由于ICMP没有回复传输的报文,所以只要停止该报文,主机就会逐渐恢复传输速率。
(3)无连接方式网络的问题就是数据报会丢失,或者长时间在网络游荡而找不到目标,或者拥塞导致主机在规定的时间内无法重组数据报分段,这时就要触发ICMP超时报文的产生。
超时报文(类型字段值为11)的代码域有两种取值:代码字段值为0表示传输超时,代码字段值为1表示分段重组超时。
时间戳请求
时间戳请求报文(类型值字段13)和时间戳应答报文(类型值字段14)用于测试两台主机之间数据报来回一次的传输时间。
传输时,主机填充原始时间戳,接受方收到请求后填充接受时间戳后以类型值字段14的报文格式返回,发送方计算这个时间差。
(有些系统不响应这种报文)
3.5基于ICMP的几种用法
ping命令
用法如下:
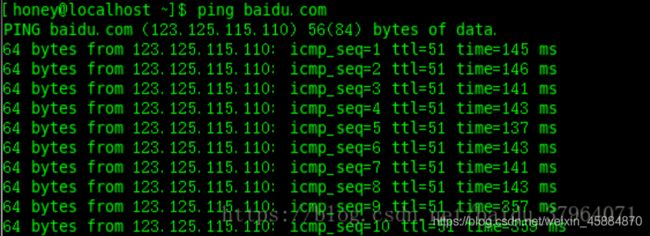 注意, 此处 ping 的是域名,不是url.
注意, 此处 ping 的是域名,不是url.
ping命令的功能
(1)能验证网络的连通性
(2)会统计响应时间和TTL(IP包中的Time To Live,生存周期)
那么如何验证的呢?
(1)ping命令会先发送一个 ICMP Echo Request给对端
(2)对端接收到之后, 会返回一个ICMP Echo Reply
(3)若没有返回,就是超时了,会认为指定的网络地址不存在。
问题:
telnet是23端口,ssh是22端口,那么ping是什么端口?
答:ping命令是基于ICMP,是在网络层。
而端口号,是传输层的内容。所以在ICMP中根本就不关注端口号这样的信息。
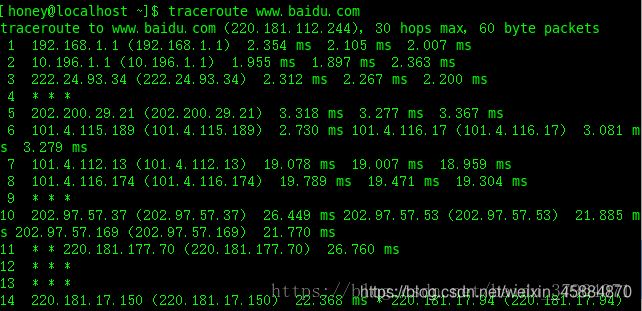
traceroute
traceroute也是基于ICMP协议实现的。
功能:
打印出可执行程序主机,一直到目标主机之前经历多少路由器。
举例如下:
参考:https://blog.csdn.net/baidu_37964071/article/details/80514340