自然语言处理(2)文本表示
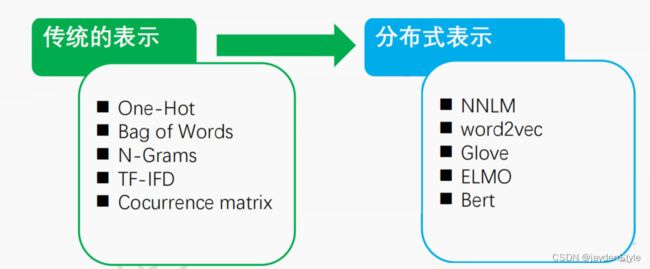
1 文本表示是什么
为什么需要文本表示:文字是人类认知过程中产生的高层认知抽象实体,我们需要将其转化为神经网络可以处理的数据类型。
文本表示的形式:类比与语音图像,我们希望可以将文字或单词转化为向量
文本的表示如下图所示
2 One-hot编码
One-hot即独立热词,词语被表示成一个维度为词表大小的向量,这个向量中只有一个维度是1其他位置都是0。
假如词表中只有四个个词“奥巴马”、“特朗普”、“宣誓”、“就职”,那么他们将被表示为:

One-hot表示的优点是简单易用,但是缺点也是致命的,如果一个词表有十万个单词,那么就需要十万维的向量来表示每一个单词,而每个向量只有一位是1,在储存上造成大量浪费,在深度学习场景中容易受到维度灾难的困扰。另外,奥巴马和特朗普都是美国统,而one-hot表示出的两个向量是正交向量,也就是他们之间毫无关系,这显然是丢失了相关语义信息。
3 word2vec
3.1 总体概述
word2vec是词的一种表示,他将词以固定维数的向量表示出来。例如 “我爱中国” 这句话通过分词分为 我/ 爱 / 中国,那么 这个时候这三个词都将表示为n维的词向量。中国= [x1, x2,…..,xn]。
相比与One-hot,word2vec充分利用上下文信息,对上下文进行训练。每个词不在是 只有一个位置为1,其余位置为0的稀疏向量。而是一个稠密的固定维度向量。直观上也可减少额外存储和计算开销。其次,在深层次的语义理解上,经过训练后的词向量能利用上下文信息。能判定找出相似词语。
word2vec有2种实现方式:(从实现方式上看两者两者只是输入输出发生了变化。)
(1)用上下文预测中心词:连续词袋-cbow(continue bag of word)
(2)利用中心词预测上下文:跳字-skip-gram

在文本表示的实现过程中,模型需要使用tf2中的Embedding。一般我们需要对文本进行分词处理,然后对分词进行序列化,然后统一输入的序列长度,最后把统一长度的序列化结果输入到Embedding层中。如图所示。
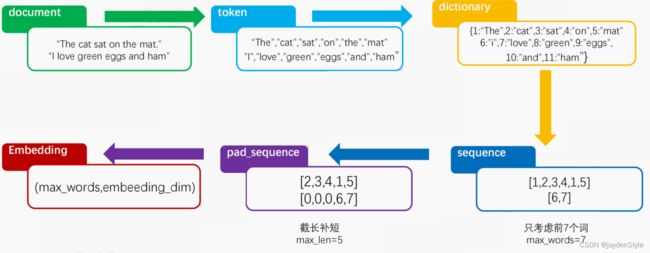
tf.keras中的embedding层的输入是一个二维整数张量, 形状为(samples,sequence_length),即(样本数,序列长度); 较短的序列应该用 0 填充,较长的序列应该被截断,保证输入的序列长度是相同的; Embedding 层输出是(samples,sequence_lengthembedding_dimensionality)的三维浮点数张量。
3.2 代码实例
代码实例:我们先从代码来直观的看看如何实现
使用TensorflowAPI中随机默认的向量来赋值给每一个向量:
# -*- coding: UTF-8 -*-
import tensorflow as tf
docs = ["The cat sat on the mat.", "I love green eggs and ham."]
# 只考虑最常见的8个单词
max_words = 8
# 统一的序列化长度
# 截长补短 0填充
max_len = 5
# 词嵌入维度
embedding_dim = 3
# 分词
tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=max_words)
# fit_on_texts 获取训练文本的词表
tokenizer.fit_on_texts(docs)
# 字典索引
word_index = tokenizer.word_index
# 序列化
sequences = tokenizer.texts_to_sequences(docs)
# 统一序列长度
data = tf.keras.preprocessing.sequence.pad_sequences(sequences = sequences, maxlen= max_len)
# Embedding层
model = tf.keras.models.Sequential()
# 里面会有默认的生成随机向量
embedding_layer = tf.keras.layers.Embedding(input_dim=max_words, output_dim= embedding_dim, input_length=max_len)
model.add(embedding_layer)
model.compile('rmsprop', 'mse')
out = model.predict(data)
print(out)
print(out.shape)
# 查看权重
layer = model.get_layer('embedding')
print(layer.get_weights())
使用具体的文本数据来训练词向量,进一步尝试
# -*- coding: UTF-8 -*-
from tensorflow.keras.datasets import imdb
from tensorflow.keras import preprocessing
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Embedding,GlobalAveragePooling1D
# 特征单词数
max_words = 10000
# 在50单词后截断文本
# 这些单词都属于max_words中的单词
maxlen = 20
# 嵌入维度
embedding_dim = 8
# 加载数据集
# 加载的数据已经序列化过了,每个样本都是一个sequence列表
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_words)
# 统计序列长度,将数据集转换成形状为(samples,maxlen)的二维整数张量
x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen)
# 构建模型
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
# 将3维的嵌入张量展平成形状为(samples,maxlen * embedding_dim)的二维张量
model.add(Flatten())
#model.add(GlobalAveragePooling1D())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
model.summary()
print(model)
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
而在我们的工作中,我们一般直接使用别人大型公司做出来的API(别人的往往比你好…),下面是wrod2vec的正式使用:
# -*- coding: UTF-8 -*-
# 工作中直接用它,一般工业届都用它
from gensim.models import Word2Vec
import re
docs = ["The cat sat on the mat.", "I love green eggs and ham."]
sentences = []
# 去标点符号
stop = '[’!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~]+'
for doc in docs:
doc = re.sub(stop, '', doc)
sentences.append(doc.split())
# size嵌入的维度,window窗口大小,workers训练线程数
# 忽略单词出现频率小于min_count的单词
# sg=1使用Skip-Gram,否则使用CBOW
model = Word2Vec(sentences, vector_size=5, window=1, min_count=1, workers=4, sg=1)
print(model.wv['cat'])
那么我们如何用自己的数据集来训练自己的word2vec词表呢?下面用一个实例来介绍。
文件目录如图所示:(以后的项目一般都用这种专注度分离的模式来编写代码,这样方便调试和扩展。)

首先,我们先用gensim包下的Word2Vec包来对数据集生成词向量。简单概括就是先读取data数据,然后把data放入到定义好的模型中训练,保存到指定的路径。
# -*- coding: UTF-8 -*-
from gensim.models import Word2Vec
import utils
"""
训练Word2Vec
"""
def train_w2v_model(sentences, embedding_vector_size):
w2v_model = Word2Vec(
sentences=sentences,
vector_size=embedding_vector_size,
min_count=3, window=5, workers=4)
w2v_model.save("data\word2vec.model")
if __name__ =="__main__":
corpus_path = "data\data.tsv"
sentences, _ = utils.read_corpus(corpus_path)
train_w2v_model(sentences, 100)
我们使用一个自定义的utils工具包来编写通用的一些方法,比如读取数据集,加载词向量,词向量转化成单词,单词转化为词向量的方法。
# -*- coding: UTF-8 -*-
import pandas as pd
import re
import codecs
import numpy as np
from gensim.models import Word2Vec
"""
清除标点符合及非法字符
"""
def split_sentence(sentence):
stop = '[’!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~]+'
sentence = re.sub(stop, '', sentence)
return sentence.split()
"""
读取数据集
"""
def read_corpus(path):
data = pd.read_csv(path, sep='\t')
sentences = data.review.apply(split_sentence)
return sentences, data
"""
加载词向量
"""
def load_w2v(w2v_path):
return Word2Vec.load(w2v_path)
"""
根据词向量构建word2id
"""
def word2id(w2v_model):
# 取得所有单词
vocab_list = list(w2v_model.wv.vocab.keys())
# 每个词语对应的索引
word2id = {word: index for index, word in enumerate(vocab_list)}
return word2id
"""
获得编码后的序列
"""
def get_sequences(word2id, sentences):
sequences = []
for sentence in sentences:
sequence = []
for word in sentence:
try:
sequence.append(word2id[word])
except KeyError:
pass
sequences.append(sequence)
return sequences
训练完成之后,我们发现保存目录data中新生成了一个词向量模型。这就是训练得到的word2vec模型。
为了这个模型更加切合我们自己的数据集,我们可以继续对这个模型进行训练。
Y = data.sentiment.values
# 划分数据集
X_train, X_test, Y_train, Y_test = train_test_split(
X_pad,
Y,
test_size=0.2,
random_state=42)
"""
构建分类模型
"""
# 让 tf.keras 的 Embedding 层使用训练好的Word2Vec权重
embedding_matrix = w2v_model.wv.vectors
model = Sequential()
model.add(Embedding(
input_dim=embedding_matrix.shape[0],
output_dim=embedding_matrix.shape[1],
input_length=maxlen,
weights=[embedding_matrix],
trainable=False))
#model.add(Flatten())
model.add(GlobalAveragePooling1D())
model.add(Dense(5))
model.add(Dense(1, activation='sigmoid'))
model.compile(
loss="binary_crossentropy",
optimizer='adam',
metrics=['accuracy'])
model.summary()
history = model.fit(
x=X_train,
y=Y_train,
validation_data=(X_test, Y_test),
batch_size=128,
epochs=10)
这样我们就训练出了我们自己的word2vec模型。
那么,我们在数学原理上,是如何实现向量的生成的呢?那就是之前说过的skip-gram和cbow,我们先说一下Skip-Gram
3.3 原理解析:Skip-Gram
在Skip-Gram模型中,我们用⼀个词来预测它在文本序列周围的词。
举个例子:假设文本序列是“我”、“爱”、“中国”、“这片” 和“土地”。以“中国”作为中心词,设时间窗口大小为 2。那么跳字模型所关心的是,给定中心词“中国”生成与它距离不超过2个词的背景词“我”、“爱”、“这片”和“土地”的条件概率。
用数学描述:假设词典索引集 V 的大小为 |V|,且 V={0,1,…,|V|−1}。给定一个长度为 T 的文本序列中,时间步 t 的词为 w(t)。当时间窗口大小为 m 时,跳字模型需要最大化给定任一中心词生成所有背景词的概率。
- ∏ t = 1 T ∏ − m ≤ j ≤ m , j ≠ 0 P ( w ( t + j ) ∣ w ( t ) ) \prod\limits_{t=1}^T\prod\limits_{-m\le{j}\le{m},j\not{=}0}P(w^{(t+j)}|w^(t)) t=1∏T−m≤j≤m,j=0∏P(w(t+j)∣w(t))
上式的最大似然估计与最小化以下损失函数等价:
- − 1 T ∑ t = 1 T ∑ − m ≤ j ≤ m , j ≠ 0 log P ( w ( t + j ) ∣ w ( t ) ) -\frac{1}{T}\sum\limits_{t=1}^T\sum\limits_{-m\le{j}\le{m},j\not{=}0}\log{P(w^{(t+j)}|w^{(t)})} −T1t=1∑T−m≤j≤m,j=0∑logP(w(t+j)∣w(t))
我们可以用V和U分别表示中心词和背景词的向量。换言之,对于词典中索引为i的词,它在作为中心词和背景词时的向量表示分别是 v i v_i vi 和 u i u_i ui 。而词典中所有词的这两种向量正是跳字模型所要学习的模型参数。为了将模型参数植入损失函数,我们需要使用模型参数表达损失函数中的给定中心词生成背景词的条件概率。
给定中心词,假设生成各个背景词是相互独立的。设中心词 w c w_c wc 在词典中索引为c,背景词 w o w_o wo 在词典中索引为o,损失函数中的给定中心词生成背景词的条件概率可以通过 softmax 函数定义为:
- P ( w 0 ∣ w c ) = e u 0 T v c ∑ i ϵ v e u i T v c P(w_0|w_c) = \frac{e^{u_0^Tv_c}}{\sum\limits_{i\epsilon{v}}e^{u_i^Tv_c}} P(w0∣wc)=iϵv∑euiTvceu0Tvc
当序列长度 T 较大时,我们通常在每次迭代时随机采样一个较短的子序列来计算有关该子序列的损失。然后,根据该损失计算词向量的梯度并迭代词向量。
下面我们看看如何计算随机采样的子序列的损失有关中心词向量的梯度。和上面提到的长度为T的文本序列的损失函数类似,随机采样的子序列的损失实际上是对子序列中给定中心词生成背景词的条件概率的对数求平均。通过微分,我们可以得到上式中条件概率的对数有关中心词向量 v c v_c vc 的梯度
- ∂ l o g P ( w 0 ∣ w c ) ∂ v c = u 0 − ∑ j ϵ v e u j T v c ∑ i ϵ v e u i T v c u j \frac{\partial{log}P(w_0|w_c)}{\partial{v_c}} = u_0 - \sum\limits_{j\epsilon{v}}\frac{e^{u_j^Tv_c}}{\sum\limits_{i\epsilon{v}}e^{u_i^Tv_c}}u_j ∂vc∂logP(w0∣wc)=u0−jϵv∑iϵv∑euiTvceujTvcuj
该式子也可以写成这样:
- ∂ l o g P ( w 0 ∣ w c ) ∂ v c = u 0 − ∑ j ϵ v P ( w j ∣ w j ) u j \frac{\partial{log}P(w_0|w_c)}{\partial{v_c}} = u_0 - \sum\limits_{j\epsilon{v}}P(w_j|w_j)u_j ∂vc∂logP(w0∣wc)=u0−jϵv∑P(wj∣wj)uj
随机采样的子序列有关其他词向量的梯度同理可得。训练模型时,每一次迭代实际上是用这些梯度来迭代子序列中出现过的中心词和背景词的向量。
训练结束后,对于词典中的任一索引为i的词,我们均得到该词作为中心词和背景词的两组词向量 v i v_i vi和 u i u_i ui;
在自然语言处理应用中,我们会使用跳字模型的中心词向量。
3.4 原理解析:CBOW
CBOW模型与Skip-Gram模型类似。与Skip-Gram模型最大的不同是, CBOW模型用一个中心词在文本序列前后的背景词来预测该中心词。
举个例子:假设文本序列是“我”、“爱”、“中国”、“这片”和“土地”。以“中国”作为中心词,设时间窗口大小为 2。连续词袋模型所关心的是,给定与中心词距离不超过 2 个词的背景词“我”、“爱”、“这片”和“土地”生成中心词“中国”的条件概率。
假设词典索引集 V 的大小为 |V|,且 V={0,1,…,|V|−1}。给定一个长度为T 的文本序列中,时间步 t 的词为 w(t)。当时间窗口大小为 m 时,CBOW模 型需要最大化给定背景词生成任一中心词的概率;
- ∏ t = 1 T P ( w ( t ) ∣ w ( t − m ) , … , w ( t − 1 ) , w ( t + 1 ) , … , w ( t + m ) ) \prod\limits_{t=1}^TP(w^{(t)}|w^{(t-m)},\dots,w^{(t-1)},w^{(t+1)},\dots,w^{(t+m)}) t=1∏TP(w(t)∣w(t−m),…,w(t−1),w(t+1),…,w(t+m))
上式的最大似然估计与最小化以下损失函数等价:
- − ∏ t = 1 T log P ( w ( t ) ∣ w ( t − m ) , … , w ( t − 1 ) , w ( t + 1 ) , … , w ( t + m ) ) -\prod\limits_{t=1}^T\log{P}(w^{(t)}|w^{(t-m)},\dots,w^{(t-1)},w^{(t+1)},\dots,w^{(t+m)}) −t=1∏TlogP(w(t)∣w(t−m),…,w(t−1),w(t+1),…,w(t+m))
我们可以用V和U分别表示背景词和中心词的向量。换言之,对于词典中索引为i 的词,它在作为背景词和中心词时的向量表示分别是 v i v_i vi和 u i u_i ui。而词典中所有词的这两种向量正是连续词袋模型所要学习的模型参数。为了将模型参数植入损失函数,我们需要使用模型参数表达损失函数中的给定背景词生成中心词的概率。设中心词 w c w_c wc在词典中索引为c,背景词 w o 1 , … , w o 2 m w_{o1},\dots,w_{o2m} wo1,…,wo2m在词典中索引为 o 1 , c … , o 2 m o_1,c\dots,o_{2m} o1,c…,o2m,损失函数中的给定背景词生成中心词的概率可以通过 softmax 函数定义为:
- P ( w c ∣ w o 1 , … , w o 2 m ) = e u c T ( v o 1 + ⋯ + v o 2 m / ( 2 m ) ) ∑ i ϵ v e ( u i T ( v o 1 + ⋯ + v o 2 m ) ) / ( 2 m ) P(w_c|w_{o1},\dots,w_{o2m})=\frac{e^{u_c^T(v_{o1}+\dots+v_{o2m}/(2m))}}{\sum\limits_{i\epsilon{v}} e^{(u^T_i(v_{o1}+\dots+v_{o2m}))}/(2m)} P(wc∣wo1,…,wo2m)=iϵv∑e(uiT(vo1+⋯+vo2m))/(2m)eucT(vo1+⋯+vo2m/(2m))
和跳字模型一样,当序列长度T较大时,我们通常在每次迭代时随机采样一个较短的子序列来计算有关该子序列的损失。然后,根据该损失计算词向量的梯度并迭代词向量。通过微分,我们可以计算出上式中条件概率的对数有关任一背景词向量。
3.5 进一步优化方式
我们可以看到,无论是跳字模型还是连续词袋模型,每一步梯度计算的开销与词典V的大小相关。当词典较大时,例如几十万到上百万,这种训练方法的计算开销会较大。因此,我们将使用近似的方法来计算这些梯度,从而减小计算开销。
常用号的近似训练方法包括:
(1)负采样
(2)层序softmax
3.5.1 负采样
接下来,我们以跳字模型为例来讨论负采样。
实际上,词典V的大小之所以会在损失中出现,是因为给定中心词 w c w_c wc 生成背景词 w o w_o wo 的条件概率 P ( w o ∣ w c ) P(w_o|w_c) P(wo∣wc) 使用了softmax运算,而softmax运算正式考虑了背景词可能是词典中的任一词,并体现在分母上。
不妨换个角度考虑给定中心词生成背景词的条件概率。我们先定义噪声词分布 P ( w ) P(w) P(w),接着假设给定中心词 w c w_c wc生成背景词 w o w_o wo 由以下相互独立事件联合组成来近似:
(1)中心词 w c w_c wc和背景词 w o w_o wo同时出现时间窗口。
(2)中心词 w c w_c wc和第1个噪声词 w 1 w_1 w1不同时出现在该时间窗口(噪声词 w 1 w_1 w1按噪声词分 布 P ( w ) P(w) P(w)随机生成,且假设不为背景词wo)。
…
(3) 中心词 w c w_c wc和第K个噪声词wK不同时出现在该时间窗口(噪声词 w K w_K wK 按噪声词分布 P ( w ) P(w) P(w)随机生成,且假设不为背景词 w o w_o wo)。
下面,我们可以使用 θ ( x ) = 1 1 + e − x \theta(x)=\frac{1}{1+e^{-x}} θ(x)=1+e−x1函数来表达中心词 w c w_c wc和背景词 w o w_o wo同时出现在该训练窗口的概率:
- P ( D = 1 ∣ w o , w c ) = θ ( u o T v c ) P(D=1|w_o,w_c) = \theta(u_o^Tv_c) P(D=1∣wo,wc)=θ(uoTvc)
那么,给定中心词 w c w_c wc生成背景词 w o w_o wo的条件概率的对数可以近似为:
- log P ( w o ∣ w c ) = log P ( D = 1 ∣ w o , w c ) ∏ k = 1 , w k − P ( w ) K P ( D = 0 ∣ w k , w c ) \log{P(w_o|w_c)}= \log{P(D=1|w_o,w_c)\prod\limits_{k=1,w_k-P(w)}^KP(D=0|w_k,w_c)} logP(wo∣wc)=logP(D=1∣wo,wc)k=1,wk−P(w)∏KP(D=0∣wk,wc)
假设噪声词 w k w_k wk在词典中的索引为 i k i_k ik,上式可改写为:
- log P ( w o ∣ w c ) = log 1 1 + e − u o T v c + ∑ k = 1 , w k − P ( w ) K log ( 1 − 1 1 + e − u i k T v c ) \log{P(w_o|w_c)} = \log\frac{1}{1+e^{-u^T_ov_c}}+\sum\limits_{k=1,w_k-P(w)}^K\log(1-\frac{1}{1+e^{-u^T_{i_k}v_c}}) logP(wo∣wc)=log1+e−uoTvc1+k=1,wk−P(w)∑Klog(1−1+e−uikTvc1)
因此,有关给定中心词 w c w_c wc生成背景词 w o w_o wo的损失是:
- − log P ( w o ∣ w c ) = − log 1 1 + e − u o T v c − ∑ k = 1 , w k − P ( w ) K log 1 1 + e u i k T v c -\log{P(w_o|w_c)}=-\log\frac{1}{1+e^{-u_o^Tv_c}}-\sum\limits_{k=1,w_k-P(w)}^K\log\frac{1}{1+e^{u^T_{i_k}v_c}} −logP(wo∣wc)=−log1+e−uoTvc1−k=1,wk−P(w)∑Klog1+euikTvc1
假设词典V很大,每次迭代的计算开销由O(|V|)变为O(K)。当我们把K取较小
值时,负采样每次迭代的计算开销将较小。
当然,我们也可以对连续词袋模型进行负采样。有关给定背景词 w t − m , … , w t − 1 , w t + 1 , … , w t + m w^{t-m},\dots,w^{t-1},w^{t+1},\dots,w^{t+m} wt−m,…,wt−1,wt+1,…,wt+m生成中心词 w c w_c wc的损失:
- − log P ( w t ∣ w t − m , … , w t − 1 , w t + 1 , … , w t + m ) -\log{P(w^t|w^{t-m},\dots,w^{t-1},w^{t+1},\dots,w^{t+m}}) −logP(wt∣wt−m,…,wt−1,wt+1,…,wt+m)
在负采样中可以近似为:
- − log 1 1 + e − u c T ( v o 1 + ⋯ + v o 2 m ) 2 m − ∑ k = 1 , w k − P ( w ) K log 1 1 + e u i k T ( v o 1 + ⋯ + v o 2 m ) 2 m -\log\frac{1}{1+e^{\frac{-u_c^T(v_{o1}+\dots+v_{o2m})}{2m}}}-\sum\limits_{k=1,w_k-P(w)}^K\log\frac{1}{1+e^{\frac{u_{ik}^T(v_{o1+\dots+v_{o2m}})}{2m}}} −log1+e2m−ucT(vo1+⋯+vo2m)1−k=1,wk−P(w)∑Klog1+e2muikT(vo1+⋯+vo2m)1
同样,当我们把 K 取较小值时,负采样每次迭代的计算开销将较小。
3.5.1 层序softmax
层序softmax是另一种常用的近似训练法。它利用了二叉树这一数据结构。树的每个叶子节点代表着词典V中的每个词。我们以图为例来描述层序 softmax的工作机制:
假设 L ( w ) L(w) L(w) 为从二叉树的根节点到词w的叶子节点的路径(包括根和叶子节点)上的节点数。设 n ( w , j ) n(w,j) n(w,j) 为该路径上第j个节点,并设该节点的向量为 u n ( w , j ) u_{n(w,j)} un(w,j)。以上图为例, L ( w 3 ) = 4 L(w3)=4 L(w3)=4。设词典中的词wi的词向量为 v i v_i vi。那么跳字模型和连续词袋模型所需要计算的给定词 w i w_i wi生成词w的条件概率为:
- p ( w ∣ w i ) = ∏ j = 1 L ( w ) − 1 θ ( [ n ( w , j + 1 ) = l e f t C h i l d ( n ( w , j ) ) ] ⋅ u n ( w , j ) T v i ) p(w|w_i) = \prod\limits_{j=1}^{L(w)-1}\theta([n(w,j+1)=leftChild(n(w,j))]\cdot u_{n(w,j)}^Tv_i) p(w∣wi)=j=1∏L(w)−1θ([n(w,j+1)=leftChild(n(w,j))]⋅un(w,j)Tvi)
其中 θ ( x ) = 1 1 + e − x , l e f t C h i l d ( n ) \theta(x)=\frac{1}{1+e^{-x}},leftChild(n) θ(x)=1+e−x1,leftChild(n) 是节点n的左孩子节点,如果判断x为真, [ [ x ] ] = 1 [[x]]=1 [[x]]=1;反之 [ [ x ] ] = − 1 [[x]]=-1 [[x]]=−1。由于 θ ( x ) + θ ( − x ) = 1 \theta(x)+\theta(-x) = 1 θ(x)+θ(−x)=1,给定词 w i w_i wi生成词典V中任一词的条件概率之和为1这一条件也将满足:
- ∑ w ϵ V P ( w ∣ w i ) = 1 \sum\limits_{w\epsilon{V}}P(w|w_i) = 1 wϵV∑P(w∣wi)=1
让我们计算上图中给定词 w i w_i wi生成词 w 3 w_3 w3的条件概率。我们需要将 w i w_i wi的词向量 v i v_i vi和根节点到 w 3 w_3 w3路径上的非叶子节点向量一一求内积。由于在二叉树中由根节点到叶子节点 w 3 w_3 w3的路径上需要向左、向右、再向左地遍历(图中红线的路径),我们得到:
- P ( w 3 ∣ w i ) = θ ( u n ( w 3 , 1 ) T v i ) ⋅ θ ( − u n ( w 3 , 2 ) T v i ) ⋅ θ ( u n ( w 3 , 3 ) T v i ) P(w_3|w_i)=\theta(u_{n(w_3,1)}^Tv_i)\cdot\theta(-u_{n(w_3,2)}^Tv_i)\cdot\theta(u_{n(w_3,3)}^Tv_i) P(w3∣wi)=θ(un(w3,1)Tvi)⋅θ(−un(w3,2)Tvi)⋅θ(un(w3,3)Tvi)
在使用softmax的跳字模型和连续词袋模型中,词向量和二叉树中非叶子节点向量是需要学习的模型参数。假设词典V很大,每次迭代的计算开销由O(|V|) 下降至O(log2|V|)。
4 Clove(一种更别致的词向量表示)
GloVe的全称叫Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。我们通过对向量的运算,比如欧几里得距离或者cosine相似度,可以计算出两个单词之间的语义相似性。
Stanford NLP Group的Jeffrey Pennington, Richard Socher, Christopher D. Manning在2014年的Empirical Methods in Natural Language Processing (EMNLP)上发表的一篇论文:GloVe: Global Vectors for Word Representation。
Glove实现分为以下三步:
(1)构建一个共现矩阵(Co-ocurrence Matrix);
Co-occurrence:协同出现指的是两个单词w1和w2在一个Context Window范围内共同出现的次数;
Context Window:指的是某个单词w的上下文范围的大小,也就是前后多少个单词以内的才算是上下文?比如一个Context Window Size = 2的示意图如下:
(2)构建词向量(Word Vector)和共现矩阵(Co-ocurrence Matrix)之间的近似关系;
(3)构造loss function
比如:我们有如下的语料库:
- He is not lazy. He is intelligent. He is smart.
我们假设Context Window=2,那么我们就可以得到如下的co-occurrence
matrix:

优点:这个方法比字数统计与tfidf都要进步一点,为什么呢? 因为它不再认为单词是独立的,而考虑了这个单词所在附近的上下文,这是一个很大的突破。 如果两个单词经常出现在同一个上下文中,那么很可能他们有相同的含义。比如vodka和brandy可能经常出现在wine的上下文里,那么在这两个单词相对于wine的co-occurrence就应该是相近的,于是我们就可以认为这两个单词的含义是相近的。
Glove的实现三步走:
(1)构建一个共现矩阵(Co-ocurrence Matrix)
根据语料库(corpus)构建一个共现矩阵(Co-ocurrence Matrix) X,矩阵中每一个元素 X i j X_{ij} Xij代表单词 i 和上下文单词 j 在特定大小的上下文窗口(context window)内共同出现的次数;
一般而言,这个次数的最小单位是1,但是GloVe不这么认为:它根据两个单词在上下文窗口的距离d;
提出了一个衰减函数(decreasing weighting): d e c a y = 1 d decay=\frac{1}{d} decay=d1用于计算权重,也就是说距离越远的两个单词所占总计数(total count)的权重越小。
(2)构建词向量(Word Vector)和共现矩阵(Co-ocurrence Matrix)之间的近似关系
论文的作者提出以下的公式可以近似地表达两者之间的关系:
- w i T w j ^ + b i + b j ^ = log ( X i j ) w_i^T\hat{w_j}+b_i+\hat{b_j} = \log(X_{ij}) wiTwj^+bi+bj^=log(Xij) (1)
(3)构造Loss function
- J = ∑ i , j = 1 V f ( X i j ) ( w i T w j ^ + b i + b j ^ − log ( X i j ) ) 2 J = \sum\limits_{i,j=1}^Vf(X_{ij})(w_i^T\hat{w_j}+b_i+\hat{b_j} - \log(X_{ij}))^2 J=i,j=1∑Vf(Xij)(wiTwj^+bi+bj^−log(Xij))2 (2)
我们知道在一个语料库中,肯定存在很多单词他们在一起出现的次数是很多的(frequent co-occurrences),那么我们希望:
1.这些单词的权重要大于那些很少在一起出现的单(rare cooccurrences),所以这个函数要是非递减函数(non-decreasing);
2.但我们也不希望这个权重过大(overweighted),当到达一定程度之后应该不再增加;
3.如果两个单词没有在一起出现,也就是Xij=0,那么他们应该不参与到loss function的计算当中去,也就是f(x)要满足f(0)=0。
满足以上两个条件的函数有很多,作者采用了如下形式的分段函数:
- f ( x ) = { ( x x m a x ) a i f x < x m a x 1 o t h e r w i s e f(x)=\begin{cases} (\frac{x}{x_{max}})^a \quad if \quad x
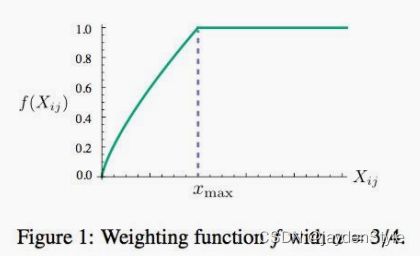
虽然很多人声称GloVe是一种无监督(unsupervised learing)的学习方式(因为它确实不需要人工标注label),但其实它还是有label的,这个label就是公式2中的 l o g ( X i j ) log(X_{ij}) log(Xij),而公式2中的向量 w w w 和 w ^ \hat{w} w^ 就是要不断更新/学习的参数,所以本质上它的训练方式跟监督学习的训练方法没什么不一样,都是基于梯度下降的。
具体地,这篇论文里的实验是这么做的:采用了AdaGrad的梯度下降算法,对矩阵X中的所有非零元素进行随机采样,学习曲率(learning rate)设为0.05,在vector size小于300的情况下迭代了50次,其他大小的vectors上迭代了100次,直至收敛。
最终学习得到的是两个vector是 w w w 和 w ^ \hat{w} w^ ,因为X是对称的(symmetric),所以从原理上讲 w w w 和 w ^ \hat{w} w^ 是也是对称的,他们唯一的区别是初始化的值不一样,而导致最终的值不一样。
所以这两者其实是等价的,都可以当成最终的结果来使用。但是为了提高鲁棒性,我们最终会选择两者之和 w w w 和 w ^ \hat{w} w^ 作为最终的vector(两者的初始化不同相当于加了不同的随机噪声,所以能提高鲁棒性)。在训练了400亿个token组成的语料后,得到的实验结果如下图所示:
