用ubuntu的docker搭建centos集群
1. 安装ubuntu
看双系统那篇
docker pull kasmweb/desktop:1.10.0-rolling
ubuntu看不了b站视频,是因为没有解析器:
sudo apt-get install ubuntu-restricted-extras
2. 配置网络ip
sudo nmcli networking on
3. 配置下载源
直接在**软件和更新**--选择**中国的服务器**
apt update && apt upgrade -y
apt-get install curl
service fwupd start
fwupdmgr refresh
fwupdmgr update
apt-get update
sudo apt-get --fix-broken install
sudo apt-get install -f
4. 下载所需软件
dpkg-I name.deb
a. 搜狗-配置-重启
b. vscode
c. wps
i. ctrl-print
ii. shift-ctrl-print
iii. 设置-快捷键
d. idea
**设置软件快捷方式**:
在桌面上新建idea.desktop,编辑以下代码,根据软件不同适当修改路径和名称
[Desktop Entry]
Name=IntelliJ IDEA
Comment=IntelliJ IDEA
Exec=/home//software/idea-IC-222.3345.118/bin/idea.sh
Icon=/home//software/idea-IC-222.3345.118/bin/idea.png
Terminal=false
Type=Application
Categories=Developer;
可以使用URL把已经存在的软件的快捷方式放到桌面:
自动存在的软件的快捷方式大都在/usr/share/applications/里面
[Desktop Entry]
Type=Link
Name=File Manager PCManFM
Icon=system-file-manager
URL=/usr/share/applications/pcmanfm.desktop
e. apt-get install -f
g. dpkg --configure -a
h. 软件中心看
i. 去软件官网有安装步骤、
i. Asbru-cm:curl -1sLf ‘https://’ | sudo -E bash
ii. apt-get install asbru-cm
5. 安装docker
a. sudo apt-get remove docker docker-engine docker.io containerd runc
b. sudo apt-get install apt-transport-https ca-certificates curl gnupg2 software-properties-common
c. curl -fsSL https://mirrors.cloud.tencent.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
d. echo \
"deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.cloud.tencent.com/docker-ce/linux/ubuntu/ \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
e. apt-get update
f. apt-get install docker-ce docker-ce-cli containerd.io
安装docker第二种:
curl -sSL https://get.daocloud.io/docker | sh
或者curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
配置docker国内镜像:
vi /etc/docker/daemon.json
添加:可以多加几个
{
"registry-mirrors": [
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com",
"https://mirror.ccs.tencentyun.com",
]
}
重启docker
sudo systemctl daemon-reload
sudo systemctl restart do
cker
sudo docker info 查看
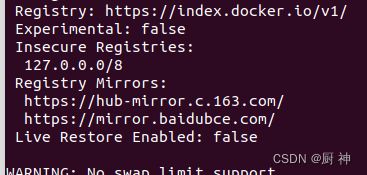
ubuntu 截图快捷键大全

6. docker安装mysql
sudo docker pull mysql:5.7.16
chmod -R 777 /export/data/mydata/mysql
sudo docker run -p 3306:3306 \
--name mysql \
--network centos-br0 \
--ip 192.172.0.6 \
-v /export/docker/dockerLoads/mysql/mydata/mysql/log:/var/log/mysql:rw \
-v /export/docker/dockerLoads/mysql/mydata/mysql/data:/var/lib/mysql-files:rw \
-v /export/docker/dockerLoads/mysql/mydata/mysql/conf:/etc/mysql:rw \
-v /etc/localtime:/etc/localtime:ro \
-e MYSQL_ROOT_PASSWORD=123456 \
-d mysql:v1
#导出数据
master#mysqldump -uroot -p dataBaseName > /opt/module/FileName.sql
#导入数据
mysql>create database dataBaseName;
mysql>source /opt/module/FileName.sql
mysql/data 是数据库文件存放的地方。必须要挂载到容器外,否则容器重启一切数据消失。
mysql/log 是数据库主生的log。建议挂载到容器外。
/etc/localtime:/etc/localtime:ro 是让容器的时钟与宿主机时钟同步,避免时区的问题,ro是read only的意思,就是只读
注意:conf,data,log文件夹必须是chmod 777
docker logs --tail 50 --follow --timestamps mysql查看日志
my.cnf模板
#my.cnf
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
[mysqld]
#
character_set_server=utf8
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M
#
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
#注意!!!在创建docker的时候下面三行要注释!!
#不然会出现File ‘./mysql-bin.index’ not found (Errcode: 13 - Permission denied)
#创建好mysql之后再解封
log_bin= /var/lib/mysql-files/mysql/mysql_bin
:
binlog_format=ROW
server_id=1
#
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M
datadir=/var/lib/mysql-files/data
#socket路径不对的话在运行时会报错,改成报错的路径
socket=/var/run/mysqld/mysqld.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
log-error=/var/log/mysql/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
[client]
default-character-set=UTF8
[mysql]
default-character-set=utf8
#生效:
chmod 644 my.cnf
#测试
show variables like "log_bin%";
show variables like '%log_bin%';
show variables like '%binlog_format%';
show variables like '%expire_logs_days%';
show variables like '%log_slave_updates%';
show variables like '%binlog_expire_logs_seconds%'; ----mysql 8.0
## 通过Docker命令进入Mysql容器内部
docker exec -it mysql /bin/bash
## 或者
docker exec -it mysql bash
grant all privileges on *.* to root@'%' identified by '123' with grant option;
flush privileges
7. docker安装:初始化centos
docker pull centos:centos7
docker run -itd --name centosBase --privileged centos:centos7 /usr/sbin/init
docker ps
docker exec -it master /bin/bash
yum -y install net-tools
ifconfig
useradd hadoop
passwd hadoop
vi /etc/hostname
hostname master && bash
yum install -y openssh-server
yum install -y openssh-clients
yum install centos-release-scl scl-utils-build
yum install -y devtoolset-8-toolchain
scl enable devtoolset-8 bash
vi /etc/ssh/sshd_config
Port 22
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
systemctl enable sshd
systemctl start sshd
systemctl enable sshd.service
passwd root
12345678
ps -e | grep sshd
netstat -an | grep 22
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #全都用户的家目录都分发
systemctl stop sshd
systemctl start sshd
# 配置网络,网段随意,也可以根据centosBase的网段创建-ifconfig、docker inspect centosBase查看
docker network create --subnet=172.172.0.0/24 centos-br0 #--subnet指定网段
docker network create -d bridge centos-br0 #创建随机网络
docker network ls
docker commit -p 40afbb92a913 myhadoop #容器做成镜像,也可以用容器名centosBase
docker images
docker commit -m="has update" -a="runoob" e218edb10161 runoob/ubuntu:v2 #完整例子
docker run -itd --name master --network hadoopNet -p 2002:2001 -p 4002:4001 --privileged mycentos /usr/sbin/init #-p 表示对外访问的端口
docker run -i -d --net docker-br0 --ip 172.172.0.10 --name nginx -v /usr/local/software/:/mnt/software/ 3bee3060bfc8 /bin/bash/init
#需要端口:
50070 50090 8088 9999 8020 9000 8485 8019 8032
2181 2888 3888
60010 60030
1000 9083
18080 4040 7077 8080 8081 8888
9092
6379
41212
3306
8081
光练习不搭建需要映射:
flink:8081 spark:8080 7077
hadoop:9000 50070 8088 9870 9820 19888
kafka:8020
hive:10000 9083
zookeeper:2181 2888 3888
redis:6379
clickhouse:9001
hbase:16010
volumn:
hadoop:/opt/module/hadoop/tmp/dfs/
sudo docker run -itd \
--name master \
--network centos-br0 \
--hostname master \
--add-host master:172.172.0.11 \
--add-host slave1:172.172.0.12 \
--add-host slave2:172.172.0.13 \
--ip 172.172.0.11 \
--privileged \
-p 50070:50070 -p 2181:2181 -p 8088:8088 -p 8020:8020 -p 9000:9000 -p 4040:4040 -p 9870:9870 -p 8080:8080 -p 16010:16010 -p 9001:9001 -p 10000:10000 -p 7077:7077 -p 23:22 \
-v /home/software:/opt/software \
-v /export/mdata:/opt/data \
-v /export/dfss/mdfs:/opt/module/hadoop/tmp/dfs \
centosbase /usr/sbin/init
sudo docker run -itd \
--name slave1 \
--network centos-br0 \
--hostname slave1 \
--add-host master:172.172.0.11 \
--add-host slave1:172.172.0.12 \
--add-host slave2:172.172.0.13 \
--ip 172.172.0.12 \
--privileged \
-p 50071:50070 -p 2182:2181 -p 8188:8088 -p 8021:8020 -p 9100:9000 -p 4041:4040 -p 9871:9870 -p 8081:8080 -p 16011:16010 -p 9011:9001 -p 10001:10000 -p 7177:7077 -p 24:22 \
-v /home/software:/opt/software \
-v /export/s1data:/opt/data \
-v /export/dfss/s1dfs:/opt/module/hadoop/tmp/dfs \
centosbase /usr/sbin/init
sudo docker run -itd \
--name slave2 \
--network centos-br0 \
--hostname slave2 \
--add-host master:172.172.0.11 \
--add-host slave1:172.172.0.12 \
--add-host slave2:172.172.0.13 \
--ip 172.172.0.13 \
--privileged \
-p 50072:50070 -p 2183:2181 -p 8288:8088 -p 8022:8020 -p 920:9200 -p 4042:4040 -p 9872:9870 -p 8082:8080 -p 16012:16010 -p 9012:9001 -p 10002:10000 -p 7277:7077 -p 25:22 \
-v /home/software:/opt/software \
-v /export/s2data:/opt/data \
-v /export/dfss/s2dfs:/opt/module/hadoop/tmp/dfs \
centosbase /usr/sbin/init
弄错了的话:
sudo docker stop 容器名
sudo docker rm 容器名
sudo docker rmi 镜像名
后续修改端口:
vi /var/lib/docker/containers/{容器id}/hostconfig.json /config.v2.json
添加或者修改就行
hostconfig.json 和 config.v2.json文件
!!!还需要22的端口!不然ssh不上!!!,只能docker exec -it master /bin/bash
-p 16020:16010 -p 9093:9092 -p 2182:2181 -p 7079:7077
-p 16030:16010 -p 9094:9092 -p 2183:2181 -p 7078:7077
50070 9870 10000 8088
docker run -itd --name server1 --network hadoopNet
-v /export/software:/export/software -v /sys/fs/cgroup:/sys/fs/cgroup
--ip 静态ip地址
--add-host hostname:ip //添加多个hosts
--add-host hostname2:ip
--hostname //设置hostname
--privileged //不加会导致没法使用root用户
myhadoop //镜像名
/usr/sbin/init //入口,不加没法使用系统命令
--add-host=master:172.17.0.1 %添加
如果在docker run的时候不添加ip和host的时候:
[centos中文乱码解决链接](https://chegva.com/3237.html)
[centos的sh脚本中文乱码解决失败链接](https://www.php.cn/centos/445270.htm)
docker exec master /bin/sh -c "echo test >> /etc/hosts" %启动中添加,把hosts放到不会改的文件里
docker exec master /bin/sh -c "echo 101.37.113.127 www.cnblogs.com >> /etc/hosts" % 同上
docker exec -it master /bin/bash
ssh root@master
docker stop containerId
docker rm containerID/containerName
docker rmi imageid/imageName
docker登录:
docker login --username=***
输入密码
#docker tag 镜像名 tag名
镜像上传:
#docker push tag名
root@userComputer:/home/user# docker tag 074a9cb5bb34 cry318265/mymaster:1.0.0
root@userComputer:/home/user# docker push cry318265/mymaster:1.0.0
8.docker安装centos: centos安装mysql
rpm -ivh mysql-community-common-5.7.18-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.18-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.18-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.18-1.el7.x86_64.rpm
yum install perl libaio numactl which
-
xshell
a. 我发现xshell ctrl+s会冻结窗口
b. ctrl+q解 -
环境变量
a. vi /home/hadoop/.bashrc
b. vi /etc/profile.d/bigdata.sh -
hive
a. nohup hive --service metastore &
b. https://www.136.la/jingpin/show-79889.html
c. (34条消息) hive常用日期函数整理_唯有一颗慎独心的博客-CSDN博客_hive 日期函数 -
scp -P 22端口 原地址 目标地址
-P制定scp端口
ha的spark配置:
spark.files file:///opt/spark-1.6.1-bin-hadoop2.6/conf/hdfs-site.xml,file:///opt/spark-1.6.1-bin-hadoop2.6/conf/core-site.xml来自 https://blog.csdn.net/weixin_42860281/article/details/92796332
用来spark支持ha的
8.docker 安装redis
sudo mkdir -p /export/data/myredis/myredis_conf
sudo mkdir -p /export/data/myredis/data
sudo chmod 777 /export/data/myredis/data/
sudo chmod 777 /export/data/myredis/myredis_conf/
cd /export/data/myredis/myredis_conf
sudo wget http://download.redis.io/redis-stable/redis.conf
#获取redis.conf配置文件
#注释掉bind (允许远程)
#修改protect-mode为no
#修改appendonly为yes(持久化)
#修改requirepass 123456(设置密码)
#如果daemonize为yes的话,就会和docker的后台冲突,导致redis启动不起来
docker pull redis:6.2.6
sudo docker run \
--restart=always --log-opt \
max-size=100m --log-opt \
max-file=2 \
-p 6379:6379 --name redis \
--network centos-br0 \
--ip 172.172.0.7 \
-v /export/data/myredis/myredis_conf:/etc/redis/redis.conf \
-v /export/data/myredis/data:/data \
-d redis:6.2.6 redis-server /etc/redis/redis.conf \
--appendonly yes \
--requirepass 123456
#-v只能文件夹,但是redis要求必须有redis.conf,所以可以写成原为redis_conf是一个文件夹,里面有redis.conf ,redis里面写redis.conf
#restart=always 开机自启
#log 日志
#p 端口
#name 名字
#v 挂载,只能文件夹
#d 后台
#redis-server 指明配置文件
#appendonly yes 持久化
#requirepass 设置密码
#测试
sudo docker exec -it redis /bin/bash
或者
sudo docker exec -it redis redis-cli -a 123456
redis-cli
redis-cli --raw //中文出现乱码用
auth 123456
set a 1
9. centOs安装zookeeper
要改的文件:zoo.cfg,zkdata
 记得把zkData写在
记得把zkData写在
/opt/data里面,不然mysql的binlog会报错
10 centOs安装java
11. centOs 安装 hadoop-standalone
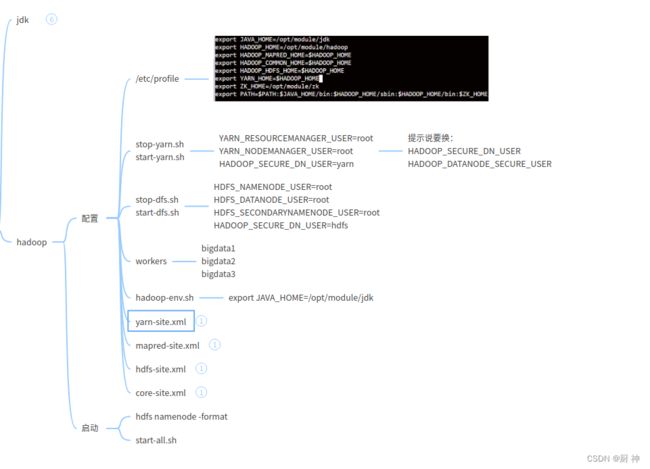
文件:stop/start-yarn.sh stop/start-dfs.sh workers hadoop-env.sh yarn-site.xml mapred-site.xml hdfs-site.xml core-site.xml
#yarn
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
#mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop</value>
</property>
<property>
<name>mapred.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop</value>
</property>
</configuration>
#core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/module/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
#hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/module/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/module/hadoop/tmp/dfs/data</value>
</property>
</configuration>
自动配置hadoop的脚本,可以在idea里面编辑好再放到一个文件夹,最后运行这个脚本
因为本人sh技术不行,此脚本因为会重复堆加语句,所以只能运行一遍
#!/bin/bash
HADOOP_HOME=/opt/module/hadoop
dir=$HADOOP_HOME/sbin/
#dir=~/server/test/
fileName=$dir"stop-yarn.sh"
sed -i '2aYARN_RESOURCEMANAGER_USER=root\nYARN_NODEMANAGER_USER=root\nHADOOP_DATANODE_SECURE_USER=yarn\n' $fileName
fileName=$dir"start-yarn.sh"
sed -i '2aYARN_RESOURCEMANAGER_USER=root\nYARN_NODEMANAGER_USER=root\nHADOOP_DATANODE_SECURE_USER=yarn\n' $fileName
fileName=$dir"start-dfs.sh"
sed -i '2aHDFS_NAMENODE_USER=root\nHDFS_DATANODE_USER=root\nHDFS_SECONDARYNAMENODE_USER=root\nHADOOP_DATANODE_SECURE_USER=hdfs\n' $fileName
fileName=$dir"stop-dfs.sh"
sed -i '2aHDFS_NAMENODE_USER=root\nHDFS_DATANODE_USER=root\nHDFS_SECONDARYNAMENODE_USER=root\nHADOOP_DATANODE_SECURE_USER=hdfs\n' $fileName
echo "export JAVA_HOME=/opt/module/jdk" >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh
for file in `ls`
do
if [[ $file = *".xml" ]]
then
cp ./$file $HADOOP_HOME/etc/hadoop/$file
fi
done
cp workers $HADOOP_HOME/etc/hadoop/workers
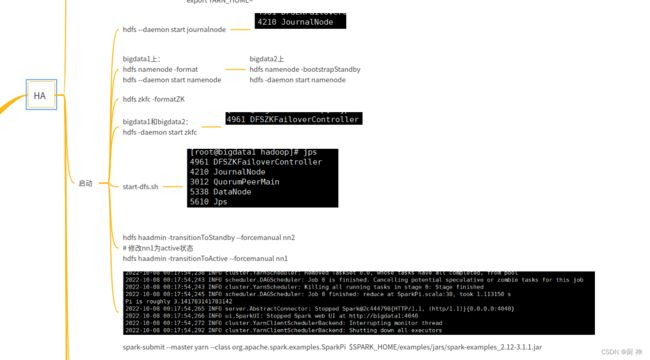
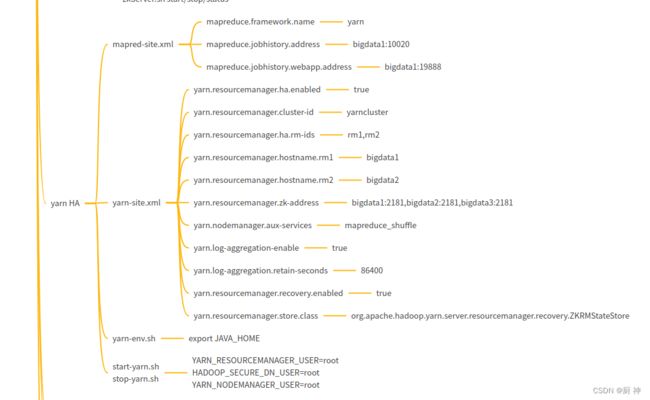
12. centos安装hadoop-ha
就几个配置文件


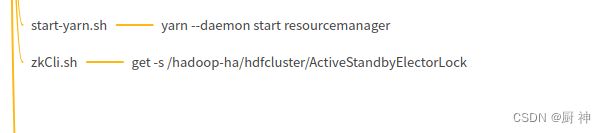
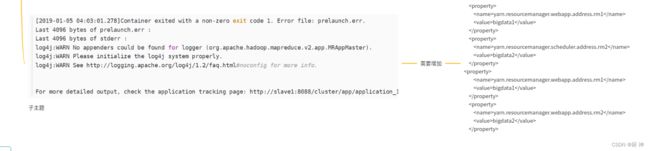
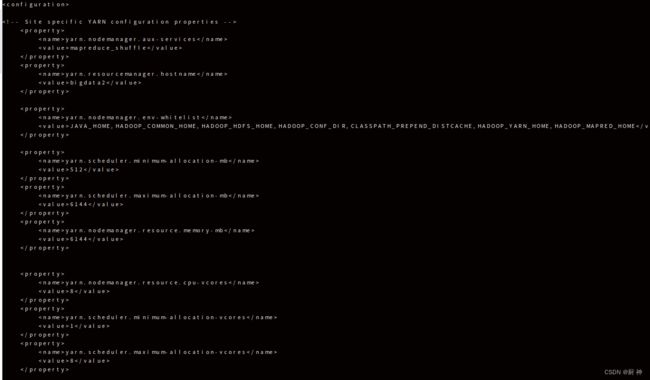
13.centOs安装 hive
文件:hive-site.xml mysql-connector的jar包
提前创建好数据库:
sudo docker exec -it mysql /bin/bash
mysql -uroot -p123456
create databse metastore
在hive里面schematool -initSchema -dbType mysql -verbose
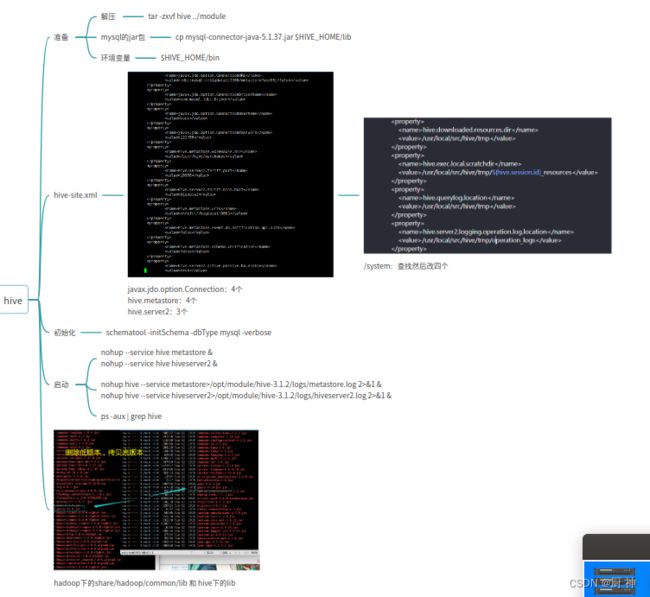
#启动hive的脚本
#!/bin/bash
HIVE_HOME=/opt/module/hive
#start metastore
${HIVE_HOME}/bin/hive --service metastore >>${HIVE_HOME}/logs/metastore.log 2>&1 &
echo "start metastore"
${HIVE_HOME}/bin/hiveserver2 >>${HIVE_HOME}/logs/hiveserver2.log 2>&1 &
echo "start hiveserver2"
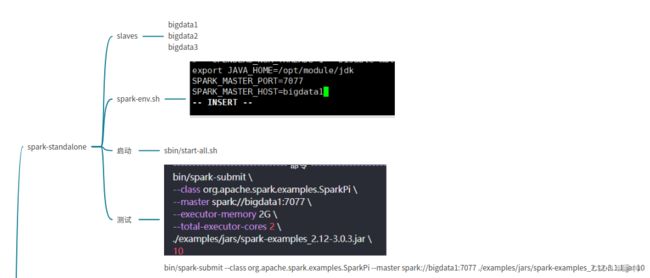
14. centOs安装spark-standalone
文件: slaves spark-env.sh
启动脚本:$SPARK_HOME/sbin/start-all.sh
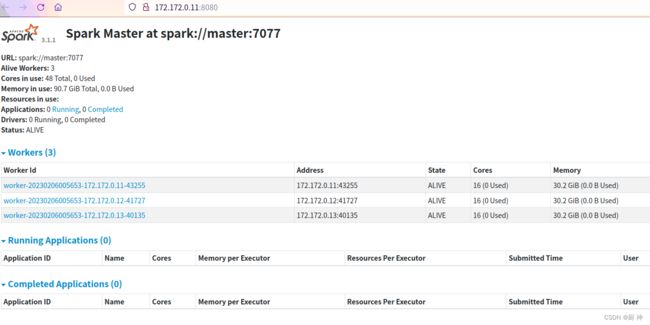
在master:8080查看
15.centOos安装 spark-yarn-hadoopStandalone
yarn-site.xml spark-env.sh hive-site.xml

#spark-default.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/directory
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.yarn.historyServer.address=master:18080
spark.history.ui-poort=18080
#spark-env.sh
export JAVA_HOME=/opt/module/jdk
export YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
export HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://master:9000/directory
-Dspark.history.retainedApplications=30"
#测试
start-all.sh #启动hadoop
hadoop fs -mkdir /directory #建一个文件夹
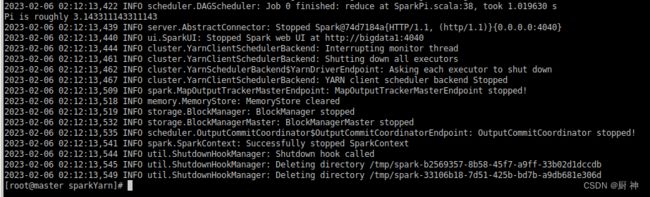
spark-submit --class org.apache.spark.examples.SparkPi --master yarn $SPARK_HOME/examples/jars/spark-examples_2.12-3.1.1.jar 10
出现这个错误说明是yarn-site.xml没有配置vmem-check-enabled和pmem-check-enabled

正确结果(Pi is roughly 3.14…)
更改spark-env.sh 添加YARN_CONF_DIR
yarn-site.xml:添加pmem/vmem-check-enabled
spark-default.conf:添加eventLog
spark-env.sh:添加history
hive-site.xml:cp
slaves:三台机子
16. spark-yarn-hadoopha
17. hbase
找到篇好文章
文件:hbase-env.sh hbase-site.xml regionservers
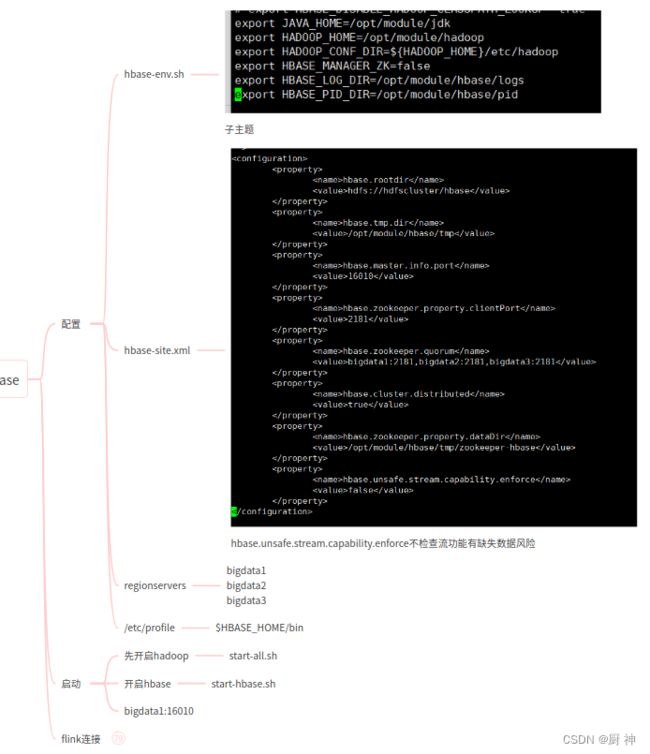
#hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/module/hbase/tmp</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
#和本机zookeeper所在zkdata保持一致,且server.x的x和myid一致
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper/zkdata</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
#hbase-env.sh
export JAVA_HOME=/opt/module/jdk
export HADOOP_HOME=/opt/module/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HBASE_MANAGER_ZK=false
#HBASE_MANAGES_ZK=true 表示用hbase自带的,默认就是hbase自带的,false表示用户制定的
export HBASE_LOG_DIR=/opt/module/hbase/logs
export HBASE_PID_DIR=/opt/module/hbase/pid
#backup-masters
master
slave1
#在哪一台机器上启动HBase,那一台机器就是主Master
#同时也会把backup-masters文件中配置的机器启动为masters角色,作为备用Master。
#备用的Master可以有多个,个数不限。
#regionservers
master
slave1
slave2
#测试
#注意:时间同步问题 新手遇到困难先删/hbase(就是rootdir所有文件夹)
hbase shell
help #命令大全
help "create" #命令具体格式
create 't_teacher',{NAME='uname'} #建表
create 't_student','sex','age','course'
list #显示表
put 't_student','nv','age','18',
put 't_student','nv','course','bigData' #表插入数据
describe 't_student' #表详情
scan 't_student' #select 查看表数据
get 't_student','nv'
delete 't_student','nv','sex' #删除一条数据的一个字段
deleteall 't_student','nv' #删除一条数据
disable 't_teacher' #删除表,先disable再drop
drop 't_student'
exit #退出
hive和hbase集成设置
文件:hive-site.xml hive-env.sh
#hive-site.xml
<property>
<name>hive.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
#hive-env.sh
export HADOOP_HOME=/opt/module/hadoop
export HBASE_HOME=/opt/module/hbase
18. kafka
文件:server.properties
 配置kafka自动删除:自己根据情况改,我是就不想让他留。
配置kafka自动删除:自己根据情况改,我是就不想让他留。
server.properties添加:
vi $KAFKA_HOME/conf/server.properties
#可以运行kafka.topics.sh --delete --topic test --zookeeper master:2181,slave1:2181,slave2:2181
#但是因为实在zk,就算你delete了,也是假的,需要在zk里面运行:zk-cli ---rmr /brokers/topics/test和删除zk的tmp/tmp/kafka-logs才行
delete.topic.enable=true
#segment存活时间,改成 1小时
log.rentention.hours=1
#segment存活大小,改成10M
log.retention.bytes=10485760
#检查segment是否超过存活时间和存活大小的检查间隔
log.retention.check.interval.ms=60000
#多大生成一次segment,默认1G,改成10M
log.segment.bytes=10485760
#多久生成一次segment,单位小时,默认7天
log.segment.ms=1
#kafka启动脚本
#!/bin/bash
KAFKA_HOME=/opt/module/kafka
if [ $# -lt 1 ]
then
echo "Input Args Error....."
exit
fi
case $1 in
start)
sleep 10
;;
esac
for i in master slave1 slave2
do
case $1 in
start)
echo "==================START $i KAFKA==================="
ssh $i $KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
;;
stop)
echo "==================STOP $i KAFKA==================="
ssh $i $KAFKA_HOME/bin/kafka-server-stop.sh stop
;;
*)
echo "Input Args Error....."
exit
;;
esac
done
#测试
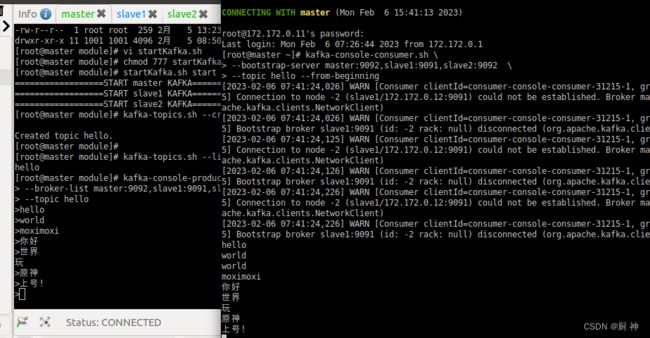
#创建topuc
kafka-topics.sh --create \
--zookeeper master:2181,slave1:2181,slave2:2181 \
--replication-factor 2 \
--topic hello --partitions 1
#查看topic
kafka-topics.sh --list \
--zookeeper master:2181,slave1:2181,slave2:2181
#producer
kafka-console-producer.sh \
--broker-list master:9092,slave1:9091,slave2:9092 \
--topic hello
#consumer
kafka-console-consumer.sh \
--bootstrap-server master:9092,slave1:9091,slave2:9092 \
--topic hello --from-beginning
19. sqoop
#sqoop-env.sh
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/home/hadoop/hadoop-2.9.2
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/home/hadoop/hadoop-2.9.2
#set the path to where bin/hbase is available
export HBASE_HOME=/home/apps/habase
#Set the path to where bin/hive is available
export HIVE_HOME=/home/apps/hive
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/home/apps/zookeeper/conf
#mysql连接jar包
mv mysql-connector-java-5.1.48.jar /home/apps/sqoop/lib
#hadoop驱动包
cp $HADOOP_HOME/share/hadoop/common/hadoop-common-3.1.3.jar $SQOOP_HOME/lib/
cp $HADOOP_HOME/share/hadoop/hdfs/hadoop-hdfs-3.1.3.jar $SQOOP_HOME/lib/
cp $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.1.3.jar $SQOOP_HOME/lib/
#测试
sqoop-version
sqoop list-databases \
--connect jdbc:mysql://172.172.0.6:3306/ \
--username root \
--password 12345678
20. flume
文件:flume-env.sh hdfs-site.xml core-site.xml 6个jar包

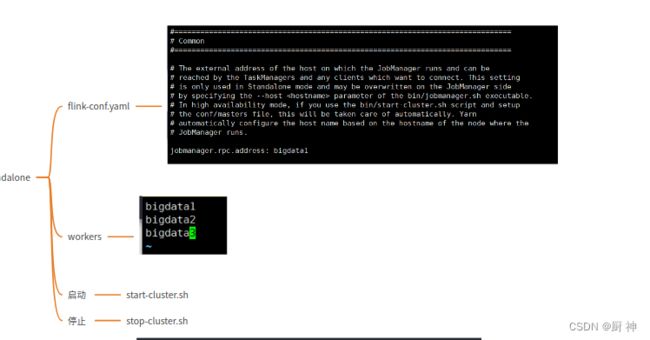
21. flink standalone
文件:flink-conf.yarml workers
start-cluster.sh后在8080查看
 22. flink on yarn
22. flink on yarn
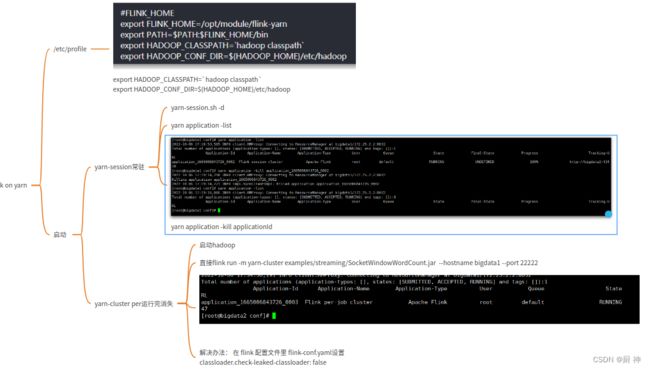 HADOOP_CLASSPATH放在PATH之后,不然不生效
HADOOP_CLASSPATH放在PATH之后,不然不生效
#测试
yum install nc -y
nc -lk 22222
flink run -m yarn-cluster examples/streaming/SocketWindowWordCount.jar --hostname master--port 22222
在8088端口的任务列表里指向webUI
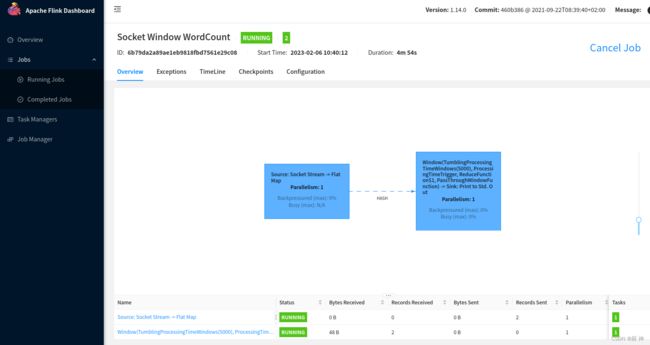
添加classloader.check-leaked-classloader:false到 flink-conf.yaml

23. clickhouse
文件:
/etc/clickhouse-server/config.xmltpc_port修改端口
/etc/clickhouse-server/config.d/listen.xml 修改为0.0.0.0为只支持ipv4,::为ipv4和ipv6都支持
/etc/clickhouse-server/users.d/default-password.xml修改密码,为哈希格式,echo -n 123456 | sha256sum | tr -d '-'获取哈希
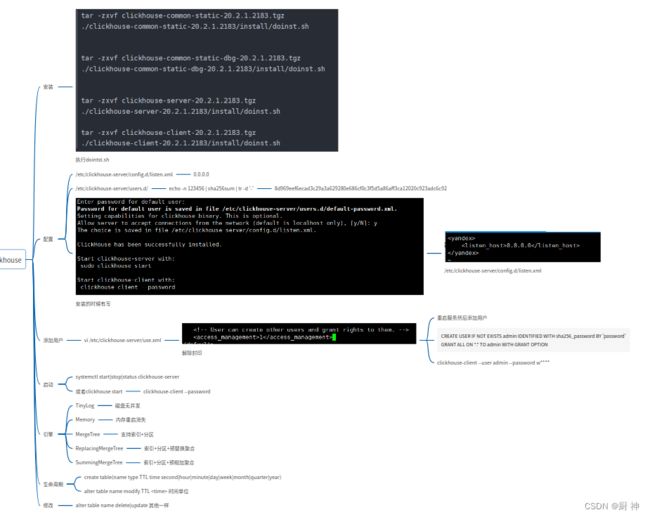
clickhouse start
clickhouse-client --password --port <tcp_port端口号>