利用InceptionV3实现图像分类
最近在做一个机审的项目,初步希望实现图像的四分类,即:正常(neutral)、涉政(political)、涉黄(porn)、涉恐(terrorism)。有朋友给推荐了个github上面的文章,浏览量还挺大的。地址如下:
https://github.com/xqtbox/generalImageClassification
我导入试了一下,发现博主没有放他训练的模型文件my_model.h5,所以代码trainMyDataWithKerasModel.py不能直接运行。必须先自己训练个模型才行,所以只好自己搞了。我开发电脑上安装的python版本是3.9.12,这个版本通常会遇到兼容性的问题,所以我决定先搭建个虚拟环境来测试一下。虚拟环境就用3.7.16了。
1、执行:conda create -n InceptionV3 python=3.7

在C:\Users\用户名\anaconda3\envs目录下创建虚拟环境InceptionV3目录。
2、执行:conda activate InceptionV3

启动InceptionV3虚拟环境。
3、执行:pip install -i https://pypi.douban.com/simple/ tensorflow==1.14.0

我的显卡是Nvidia GeForce RTX 3060的,CUDA是11.8,Cudnn是8.7.0,查了一下对应的。查了一下对应tensorflow版本是1.14.0,所以就安装这个。
4、执行:pip install -i https://pypi.douban.com/simple/ protobuf==3.19.0

5、执行:pip install -i https://pypi.douban.com/simple/ tensorflow_hub==0.9.0

6、执行:pip install -i https://pypi.douban.com/simple/ opencv-python

7、执行:pip install -i https://pypi.douban.com/simple/ scikit-learn

8、执行:pip install -i https://pypi.douban.com/simple/ albumentations==1.2.0

9、执行:pip install -i https://pypi.douban.com/simple/ h5py==2.10.0

10、执行:pip install -i https://pypi.douban.com/simple/ matplotlib

11、执行:pip install -i https://pypi.douban.com/simple/ Tensorflow-gpu==2.4.0
12、执行:pip install -i https://pypi.douban.com/simple/ keras==2.6.0

13、下面是训练代码,文件名是train1.py
import numpy as np
from tensorflow.keras.optimizers import Adam
import cv2
from tensorflow.keras.preprocessing.image import img_to_array
from sklearn.model_selection import train_test_split
from tensorflow.python.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
from tensorflow.keras.applications import InceptionV3
import os
import tensorflow as tf
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.models import Sequential
import albumentations
norm_size = 224
datapath = 'data/train'
EPOCHS = 20
INIT_LR = 3e-4
labelList = []
# 这里是分类详情
dicClass = {'neutral':0, 'political':1, 'porn':2, 'terrorism':3}
# 这是分类个数
classnum = 4
batch_size = 2
np.random.seed(42)
# tf.config.list_physical_devices('GPU')
# tf.test.is_gpu_available()
def loadImageData():
imageList = []
listClasses = os.listdir(datapath) # 类别文件夹
print(listClasses)
for class_name in listClasses:
label_id = dicClass[class_name]
class_path = os.path.join(datapath, class_name)
image_names = os.listdir(class_path)
for image_name in image_names:
image_full_path = os.path.join(class_path, image_name)
labelList.append(label_id)
imageList.append(image_full_path)
return imageList
print("开始加载数据")
imageArr = loadImageData()
labelList = np.array(labelList)
print("加载数据完成")
print(labelList)
trainX, valX, trainY, valY = train_test_split(imageArr, labelList, test_size=0.3, random_state=42)
train_transform = albumentations.Compose([
albumentations.OneOf([
albumentations.RandomGamma(gamma_limit=(60, 120), p=0.9),
albumentations.RandomBrightnessContrast(brightness_limit=0.2, contrast_limit=0.2, p=0.9),
albumentations.CLAHE(clip_limit=4.0, tile_grid_size=(4, 4), p=0.9),
]),
albumentations.HorizontalFlip(p=0.5),
albumentations.ShiftScaleRotate(shift_limit=0.2, scale_limit=0.2, rotate_limit=20,
interpolation=cv2.INTER_LINEAR, border_mode=cv2.BORDER_CONSTANT, p=1),
albumentations.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, p=1.0)
])
val_transform = albumentations.Compose([
albumentations.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, p=1.0)
])
def generator(file_pathList, labels, batch_size, train_action=False):
L = len(file_pathList)
while True:
input_labels = []
input_samples = []
for row in range(0, batch_size):
temp = np.random.randint(0, L)
X = file_pathList[temp]
Y = labels[temp]
image = cv2.imdecode(np.fromfile(X, dtype=np.uint8), -1)
if image.shape[2] > 3:
image = image[:,:,:3]
if train_action:
image = train_transform(image=image)['image']
else:
image = val_transform(image=image)['image']
image = cv2.resize(image, (norm_size, norm_size), interpolation=cv2.INTER_LANCZOS4)
image = img_to_array(image)
input_samples.append(image)
input_labels.append(Y)
batch_x = np.asarray(input_samples)
batch_y = np.asarray(input_labels)
yield (batch_x, batch_y)
checkpointer = ModelCheckpoint(filepath='best_model.hdf5',
monitor='val_acc', verbose=1, save_best_only=True, mode='max')
reduce = ReduceLROnPlateau(monitor='val_acc', patience=10,
verbose=1,
factor=0.5,
min_lr=1e-6)
model = Sequential()
model.add(InceptionV3(include_top=False, pooling='avg', weights='imagenet'))
model.add(Dense(classnum, activation='softmax'))
optimizer = Adam(learning_rate=INIT_LR)
model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['acc'])
# print('trainX = ' + str(trainX))
# print('trainY = ' + str(trainY))
model.add(tf.keras.layers.BatchNormalization())
history = model.fit(generator(trainX, trainY, batch_size, train_action=True),
steps_per_epoch=len(trainX) / batch_size,
validation_data=generator(valX, valY, batch_size, train_action=False),
epochs=EPOCHS,
validation_steps=len(valX) / batch_size,
callbacks=[checkpointer, reduce])
model.save('my_model.h5')
print(history)
loss_trend_graph_path = r"WW_loss.jpg"
acc_trend_graph_path = r"WW_acc.jpg"
import matplotlib.pyplot as plt
print("Now,we start drawing the loss and acc trends graph...")
# summarize history for acc
fig = plt.figure(1)
plt.plot(history.history["acc"])
plt.plot(history.history["val_acc"])
plt.title("Model acc")
plt.ylabel("acc")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.savefig(acc_trend_graph_path)
plt.close(1)
# summarize history for loss
fig = plt.figure(2)
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("Model loss")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.savefig(loss_trend_graph_path)
plt.close(2)
print("We are done, everything seems OK...")13.1、norm_size = 224 设置输入图像的大小,InceptionV3默认的图片尺寸是224×224。但是我的图片有300px以上的,好像也没什么问题
13.2、datapath = ‘data/train’ 设置图片存放的路径
13.3、EPOCHS = 20 epochs的数量,关于epoch的设置多少合适,这个问题很纠结,一般情况设置300足够了,如果感觉没有训练好,再载入模型训练。
13.4、INIT_LR = 1e-3 学习率,一般情况从0.001开始逐渐降低,也别太小了到1e-6就可以了。
13.5、classnum = 12 类别数量,数据集有两个类别,所有就分为两类。
13.6、batch_size = 4 batchsize,根据硬件的情况和数据集的大小设置,太小了loss浮动太大,太大了收敛不好,根据经验来,一般设置为2的次方。windows可以通过任务管理器查看显存的占用情况。
14、工程目录的文件如下图:

其中train1.py是训练程序;test.py是检测程序,本文后面会再详细讲怎么用;FormatImages.py是格式化图片的程序,功能就是把从网上爬下来比较大的图片等比压缩成300px以内。
data目录存放的就是训练用的数据,如下图:

其中train存放的是训练图片,test存放的是测试图片。train下的目录如下图:

可以看到,图中的train目录中的文件夹名要与train1.py中dicClass的值对应起来,训练数据放到对应目录下就可以了。如下图:

15、下面开始训练了,在训练之前有几个事情要做一下。
首先检查一下自己的cuda安装好没有,方法是在cmd下面输入命令nvcc -V,如果显示版本号就没问题了,如下图:

如果还没有安装也没关系,先看看自己显卡的cuda版本,如下图:
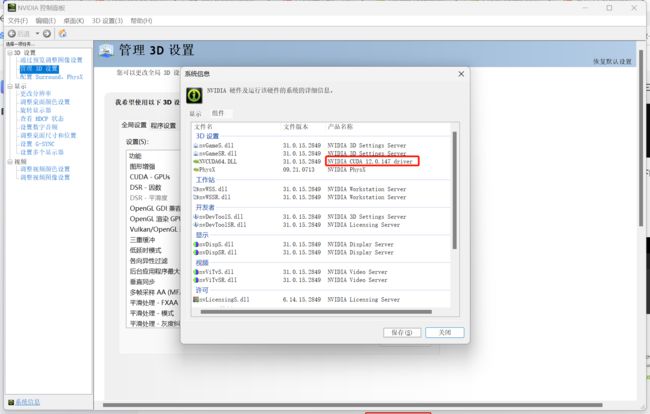
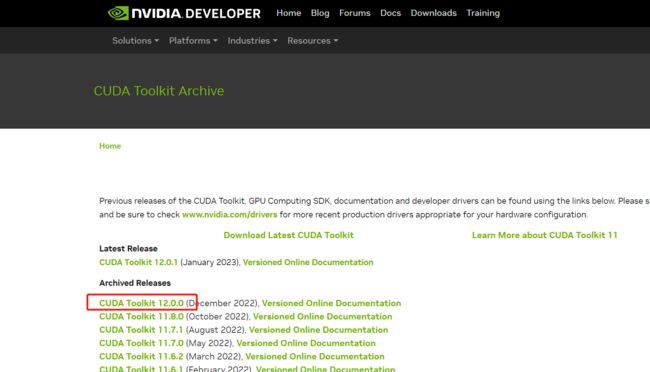
然后去https://developer.nvidia.com/cuda-toolkit-archive下载显卡对应版本的cuda工具包。如下图:
下载完成后安装到默认目录就行,一般是安装在C:\Program Files\NVIDIA GPU Computing Toolkit,如下图:









安装完成后在到https://developer.nvidia.com/rdp/cudnn-download去下载cudnn

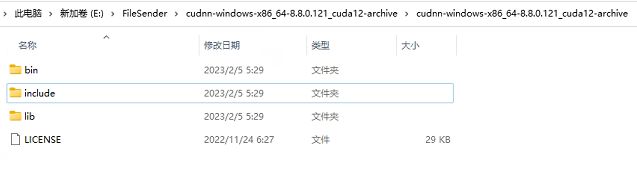
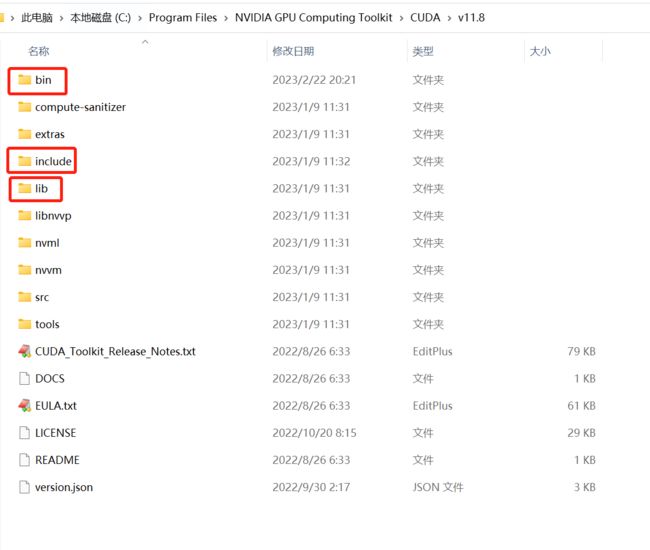
下载完成后解压缩,把解压缩后的目录cudnn-windows-x86_64-8.8.0.121_cuda12-archive下的bin、include、lib三个目录里的文件分别复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8的bin、include、lib三个目录里。如下图:
最后到https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#install-zlib-windows下载ZLIB.DLL。如下图:

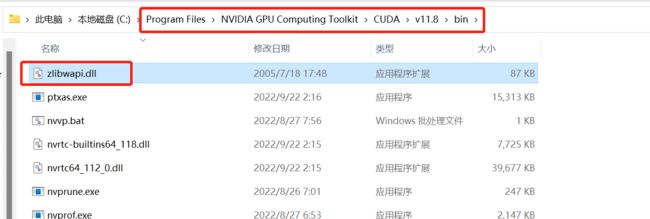
下载完成后解压缩,把解压后zlib123dllx64\dll_x64\zlibwapi.dll文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin目录下


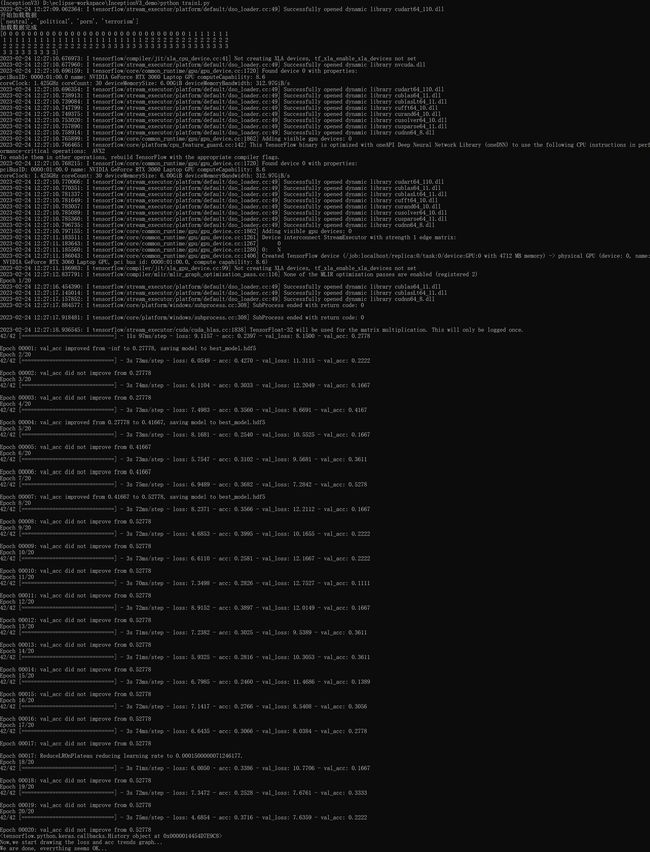
现在,在train1.py目录下执行:python train1.py
可以看一下任务管理器,压力应该都在GPU上:

16、训练完成后,可以看到train1.py目录下多了几个文件,如下图:

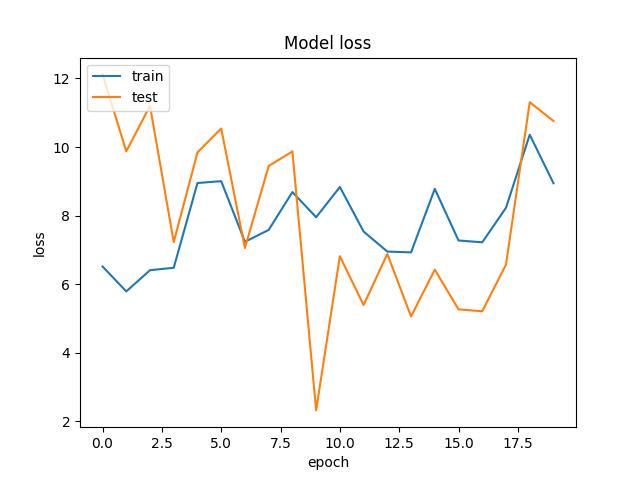
其中my_model.h5就是咱们训练出来的模型文件。WW_acc.jpg和WW_loss.jpg是训练结果保存的图,看了一下觉得还不错。

17、接下来要验证一下模型的效果,现在data\test\放一张用于预测的图。如下图:

18、下面是测试代码,文件名是test.py:
import cv2
import numpy as np
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
import time
import albumentations
norm_size = 224
imagelist = []
emotion_labels = {
0: 'neutral',
1: 'political',
2: 'porn',
3: 'terrorism',
}
val_transform = albumentations.Compose([
albumentations.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, p=1.0)
])
emotion_classifier = load_model("best_model.hdf5")
t1 = time.time()
image = cv2.imdecode(np.fromfile('data/test/01.jpg', dtype=np.uint8), -1)
image = val_transform(image=image)['image']
image = cv2.resize(image, (norm_size, norm_size), interpolation=cv2.INTER_LANCZOS4)
image = img_to_array(image)
imagelist.append(image)
imageList = np.array(imagelist, dtype="float")
out = emotion_classifier.predict(imageList)
print(out)
pre = np.argmax(out)
emotion = emotion_labels[pre]
t2 = time.time()
print(emotion)
t3 = t2 - t1
print(t3)其中emotion_labels是分类,填上与训练文件中一致的内容。
在image = cv2.imdecode(np.fromfile('data/test/01.jpg', dtype=np.uint8), -1)这行修改路径,指向到用于预测的图片位置。
19、执行python test.py

可以看到,data/test/01.jpg被预测成为terrorism,验证正确。至此大功告成。
后记:我是python的领域的新兵,在开发过程中遇到最麻烦的事情就是版本的问题。tensorflow最新版本已经2.11.0了,但是使用起来会有各种问题。我尝试了很多版本,查了不少资料,最后才确定了能用的这个组合。尤其是过程中gpu一直利用不上,程序总是使用cpu在训练,经过一顿折腾总算是能用了,但是为什么这么组合,我也没有找到一个清晰的说明,希望能有大神能给解释一下CUDA、Cudnn、tensorflow、tensorflow-gpu的版本怎么组合最合理。下面把我虚拟环境的配置发上来供大家参考:
Package Version
----------------------- ---------
absl-py 0.15.0
albumentations 1.2.0
astor 0.8.1
astunparse 1.6.3
cachetools 5.3.0
certifi 2022.12.7
charset-normalizer 3.0.1
cycler 0.11.0
flatbuffers 1.12
fonttools 4.38.0
gast 0.3.3
google-auth 2.16.1
google-auth-oauthlib 0.4.6
google-pasta 0.2.0
grpcio 1.32.0
h5py 2.10.0
idna 3.4
imageio 2.25.1
importlib-metadata 6.0.0
joblib 1.2.0
keras 2.6.0
Keras-Applications 1.0.8
Keras-Preprocessing 1.1.2
kiwisolver 1.4.4
Markdown 3.4.1
MarkupSafe 2.1.2
matplotlib 3.5.3
networkx 2.6.3
numpy 1.19.5
oauthlib 3.2.2
opencv-python 4.7.0.68
opencv-python-headless 4.7.0.68
opt-einsum 3.3.0
packaging 23.0
Pillow 9.4.0
pip 22.3.1
protobuf 3.19.0
pyasn1 0.4.8
pyasn1-modules 0.2.8
pyparsing 3.0.9
python-dateutil 2.8.2
PyWavelets 1.3.0
PyYAML 6.0
qudida 0.0.4
requests 2.28.2
requests-oauthlib 1.3.1
rsa 4.9
scikit-image 0.18.3
scikit-learn 1.0.2
scipy 1.7.3
setuptools 65.6.3
six 1.15.0
tensorboard 2.11.2
tensorboard-data-server 0.6.1
tensorboard-plugin-wit 1.8.1
tensorflow 1.14.0
tensorflow-estimator 2.4.0
tensorflow-gpu 2.4.0
tensorflow-hub 0.9.0
termcolor 1.1.0
threadpoolctl 3.1.0
tifffile 2021.11.2
typing-extensions 3.7.4.3
urllib3 1.26.14
Werkzeug 2.2.3
wheel 0.38.4
wincertstore 0.2
wrapt 1.12.1
zipp 3.14.0