【深度学习】激活函数
1.什么是激活函数
激活函数(Activation functions)对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用。它们将非线性特性引入到我们的网络中。如图示,在神经元中,输入的 inputs 通过加权求和后,最后被作用了一个函数,这个函数就是激活函数。引入激活函数是为了增加神经网络模型的非线性。没有激活函数的每层都相当于矩阵相乘。即使叠加了若干层,还是个矩阵相乘。

2.激活函数简介
2-1 非线性函数作为激活函数
假若网络中全部是线性部件,那么线性的组合还是线性,与单独一个线性分类器无异。这样就做不到用非线性来逼近任意函数。
使用非线性激活函数 ,以便使网络更加强大,增加它的能力,使它可以学习复杂的事物,复杂的表单数据,以及表示输入输出之间非线性的复杂的任意函数映射。使用非线性激活函数,能够从输入输出之间生成非线性映射。
2-2 激活函数作用
如果不用激活函数,每一层输出都是上层输入的线性函数,而线性方程的复杂度有限,无论神经网络有多少层,输出都是输入的线性组合,神经网络将无法学习和模拟其他复杂类型的数据,这种情况就是最原始的感知机(Perceptron)。
如果使用激活函数,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,可以把当前特征空间通过一定的线性映射转换到另一个空间,这样神经网络就可以应用到众多的非线性模型中。
3.常见的激活函数
3-1 sigmoid
1.函数定义

2.函数图像

3.导数图像
4.函数特点
(1)梯度消失:Sigmoid 函数趋近 0 和 1 的时候变化率会变得平坦,此时Sigmoid 的梯度趋近于 0。神经网络使用 Sigmoid 激活函数进行反向传播时,输出接近 0 或 1 的神经元其梯度趋近于 0。这些神经元叫作饱和神经元,这些神经元的权重不会更新。此外,与此类神经元相连的神经元的权重也更新得很慢。该问题叫作梯度消失,容易造成网络无法执行反向传播。
(2)计算成本高:exp() 函数与其他非线性激活函数相比,计算成本高昂。
3-2 tanh
1.函数定义

2.函数图像

3.导数图像

4.函数特点
Tanh 函数将其压缩至-1 到 1 的区间内。与 Sigmoid 不同,Tanh 函数的输出以零为中心,因为区间在-1 到 1 之间。在实践中,Tanh 函数的使用优先性高于 Sigmoid 函数。负数输入被当作负值,零输入值的映射接近零,正数输入被当作正值。梯度消失(gradient vanishing)的问题的问题仍然存在。
3-3 Relu
1.函数定义

2.函数图像

3.导数图像

4.函数特点
ReLU 函数从图像上看,是一个分段线性函数,把所有的负值都变为 0,而正值不变,这样就成为单侧抑制。 当输入 x<0 时,输出为 0,当 x> 0 时,输出为 x。因为有了这单侧抑制,才使得神经网络中的神经元也具有了稀疏激活性。该激活函数使网络更快速地收敛。在正区域(x> 0 时)它不会饱和,即它可以对抗梯度消失问题,因此神经元至少在一半区域中不会把所有零进行反向传播。由于使用了简单的阈值化(thresholding),ReLU 计算效率很高。在区间变动很大的情况下,ReLu 激活函数的导数或者激活函数的斜率都会远大于 0,在实践中,使用 ReLu 激活函数神经网络通常会比使用 sigmoid 或者 tanh 激活函数学习的更快。
3-4 Leaky Relu
1.函数定义
leaky ReLU是ReLU的一个变种,当x<0时,函数的梯度不为0,而是一个很小的常数 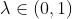 ,如0.1、0.01。
,如0.1、0.01。

2.函数图像

3.导数图像

4.函数特点
Leaky ReLU 的概念是:当 x < 0 时,它得到 0.01 的正梯度。该函数一定程度上缓解了 ReLU 问题。Leaky ReLU 可以得到更多扩展。不让 x 乘常数项,而是让 x 乘超参数,这看起来比 Leaky ReLU 效果要好。sigmoid 和 tanh 函数的导数在正负饱和区的梯度都会接近于 0,这会造成梯度弥散,而 Relu 和Leaky ReLu 函数大于 0 部分都为常数,不会产生梯度弥散现象。
Relu 进入负半区的时候,梯度为 0,神经元此时不会训练,产生所谓的稀疏性,而 Leaky ReLu 不会产生这个问题。
3-5 P-Relu
1.函数定义
![]()
2.函数图像

3.导数图像

4.函数特点
其中 α 是超参数。这里引入了一个随机的超参数 α ,它可以被学习,因为你可以对它进行反向传播。这使神经元能够选择负区域最好的梯度,有了这种能力,它们可以变成 ReLU 或 Leaky ReLU。
3-6 SoftPlus
1.函数定义
![]()
2.函数图像

3.导数图像
4.函数特点
Softplus 函数类似于 ReLU 函数,但是相对较平滑,像 ReLU 一样是单侧抑制。它的接受范围很广:(0, + inf)。Softplus函数可以看作是ReLU函数的平滑。相比于早期的激活函数,Softplus函数和ReLU函数更加接近脑神经元的激活模型,其导数为sigmoid。
3-7 softmax
1.函数定义

该元素的softmax值,就是该元素的指数与所有元素指数和的比值。
2.计算过程

3.函数特点
在二分类任务时,使用sigmoid激活函数。而在处理多分类问题的时候,需要使用softmax函数。softmax每一项输出的区间范围的(0,1),并且所有项相加的和为1。
4.激活函数的特点
4-1 非线性
当激活函数是非线性的,一个两层的神经网络就可以基本上逼近所有的函数。但如果激活函数是恒等激活函数f(x) = x,就不满足这个性质,而且如果多层感知机使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的;
4-2 可微性
在进行参数更新时,反向传播需要求梯度,当优化方法是基于梯度的时候,就需要激活函数是可微的。
4-3 输出值范围
当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况下,一般需要更小的 Learning Rate。
5.激活函数选择
1.sigmoid 激活函数:除了输出层是一个二分类问题基本不会用它。
2.tanh 激活函数:tanh 几乎适合所有场合,未解决梯度消失。
3.ReLu 激活函数:最常用的默认函数,如果不确定用哪个激活函数,就使用 ReLu 或者 Leaky ReLu,再去尝试RELU函数的其他变种激活函数。