大数据bigdata
前言:
大数据就是互联网发展到现今阶段的一种表象或特征而已,没有必要神话它或对它保持敬畏之心,在以云计算为代表的技术创新大幕的衬托下,这些原本看起来很难收集和使用的数据开始容易被利用起来了,通过各行各业的不断创新,大数据会逐步为人类创造更多的价值。
定义:是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
提出时间:2008年8月中旬
大数据的5V特点(IBM提出):
- Volume(大量)、
- Velocity(高速)、
- Variety(多样)、
- Value(低价值密度)、
- Veracity(真实性)
大数据与云计算
从技术上看,大数据与云计算的关系就像一枚硬币的正反面一样密不可分。大数据必然无法用单台的计算机进行处理,必须采用分布式架构。它的特色在于对海量数据进行分布式数据挖掘。但它必须依托云计算的分布式处理、分布式数据库和云存储、虚拟化技术。
结构
大数据包括结构化、半结构化和非结构化数据,非结构化数据越来越成为数据的主要部分。
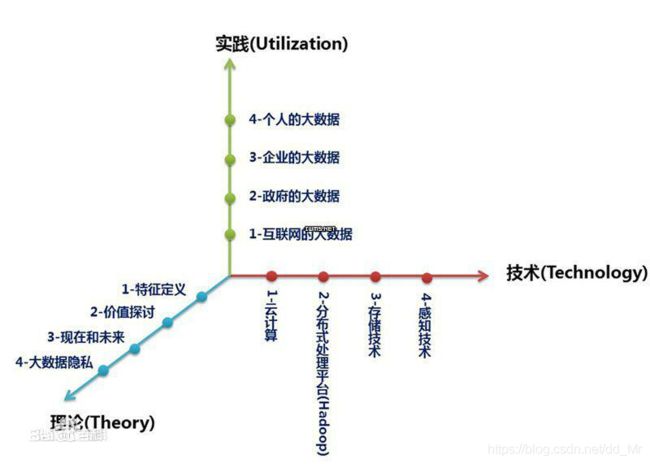
想要系统了解大数据
从3个层面:
其次,想要系统的认知大数据,必须要全面而细致的分解它,着手从三个层面来展开:
第一层面是理论,理论是认知的必经途径,也是被广泛认同和传播的基线。在这里从大数据的特征定义理解行业对大数据的整体描绘和定性;从对大数据价值的探讨来深入解析大数据的珍贵所在;洞悉大数据的发展趋势;从大数据隐私这个特别而重要的视角审视人和数据之间的长久博弈。
第二层面是技术,技术是大数据价值体现的手段和前进的基石。在这里分别从云计算、分布式处理技术、存储技术和感知技术的发展来说明大数据从采集、处理、存储到形成结果的整个过程。
第三层面是实践,实践是大数据的最终价值体现。在这里分别从互联网的大数据,政府的大数据,企业的大数据和个人的大数据四个方面来描绘大数据已经展现的美好景象及即将实现的蓝图。
应用
- 洛杉矶警察局和加利福尼亚大学合作利用大数据预测犯罪的发生。
- Google流感趋势(Google Flu Trends)利用搜索关键词预测禽流感的散布。
- 统计学家内特·西尔弗(Nate Silver)利用大数据预测2012美国选举结果
- 麻省理工学院利用手机定位数据和交通数据建立城市规划。
- 梅西百货的实时定价机制。根据需求和库存的情况,该公司基于SAS的系统对多达7300万种货品进行实时调价。
- 医疗行业早就遇到了海量数据和非结构化数据的挑战,而近年来很多国家都在积极推进医疗信息化发展,这使得很多医疗机构有资金来做大数据分析
-视频链接:https://www.bilibili.com/video/BV1AT4y137gS?p=79
数据库编程接口
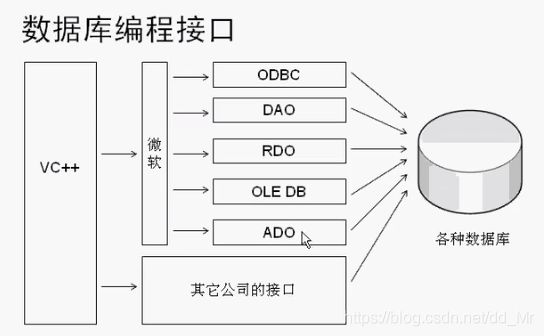
微软的数据库

运用计算机语言对数据库进行编程
所有的数据库都可以使用odbc进行操作
编程接口对于各种语言都是通用的
第二节

ado是com组件
_T("")就是把引号内的字符串转换为宽字节的Unicode编码,和TEXT("")作用是一样的。
宽字节就是unicode.
一般来说建议使用unicode,因为操作系统内部就是使用的unicode(win98不是),
如果用多字节的话,操作系统还要帮你转一遍.
unicode每个英文也占两个字节,多字节占一个字节,汉字都是占两字节.
evc中全部是使用unicode.
windows用很多api,象SetWindowTextA,SetWindowTextW,前者是多字节,后者是unicode版本.
1,如何在虚拟机中安装ubuntu
首先需要下载Ubuntu,和虚拟机
去Ubuntu的官网下载,可以下载以前的版本,用外网会更快
视频中是18.04版本的Ubuntu
教程链接:https://www.bilibili.com/video/BV1zt411G7Vn?p=2
–
创建套接字:
create(端口号,socket类型,ip地址(null表示接收任何ip地址的请求))
侦听连接请求:
listen(等待连接队伍的最大长度)
接收连接请求:
accept(????)
发送信息:
send(发送数据的缓冲指针,数据大小,调用方式默认为0)
接收信息:
receive(接收数据的缓冲,缓冲大小,默认调用方式为0)
c++的参数
1,func(int a,int b, int c=1,int d)
如果c是默认参数,则d也必须是默认参数
2,函数包括函数声明和函数实现
函数的实现和声明,其中只能有一个有默认参数,如果两个都有默认参数,那么会报错。
函数的占位参数,
void func(int a ,int ){
cout<<“这是一个参数”<
int main(){
func(1,2);
}
//这个传值虽然没有什么用,但是也必须填一下
void func(int a ,int =12){
cout<<“这是一个参数”<
int main(){
func(1);
}
这样也可以!
C++MFC网络编程-即时通讯程序03
在mfc中,所有类均有一个变量m_hWnd表示该类的实例句柄
使用csocket
创建与csocket类相关联的csocketfile类对象
创建csocketfile类相关联的carchive类对象
使用carchive类对象在客户端和服务器之间进行数据传输
关闭或销毁csocket,csocketfile,carchive类的3个对象
指针是指向的地址!
&a这个代表的也是地址,引用类型,后接地址
在c++中,通过new创建出来的对象,在堆上分配内存,没有名字,只能得到一个指向它的指针,所以必须使用一个指针变量来接收这个指针。否则,以后无法找到这个对象了。更没有办法使用这个对象。使用 new 在堆上创建出来的对象是匿名的,没法直接使用,必须要用一个指针指向它,再借助指针来访问它的成员变量或成员函数。
栈内存是程序自动管理的,不能使用 delete 删除在栈上创建的对象;堆内存由程序员管理,对象使用完毕后可以通过 delete 删除。在实际开发中,new 和 delete 往往成对出现,以保证及时删除不再使用的对象,防止无用内存堆积。
在栈上创建出来的对象都有一个名字,比如 stu,使用指针指向它不是必须的。
栈(Stack)和堆(Heap)是 C/C++ 程序员必须要了解的两个概念,我们已在《C语言和内存》专题中进行了深入讲解,相信你必将有所顿悟。
有了对象指针后,可以通过箭头->来访问对象的成员变量和成员函数,这和通过结构体指针来访问它的成员类似,请看下面的示例:
pStu -> name = “小明”;
pStu -> age = 15;
pStu -> score = 92.5f;
pStu -> say();
WSAAsyncSelect:异步套接字,用来接收并显示所发送的消息。
服务器:1,初始化(套接字的创建,ip地址的绑定)
2,监听,发送,接收数据的功能
h头文件:各种变量,常量,函数,类,进行声明和定义
cpp源文件:程序的主体,函数,类的具体实现代码
资源文件:图片,声音,视频等
类视图中,点击属性,添加新的事件消息,重写某些方法的实现代码
#include
stdlib 头文件即standard library标准库头文件,stdlib 头文件里包含了C、C++语言的最常用的系统函数,该文件包含了的C语言标准库函数的定义。
库函数可以理解为工具包,系统已经提供了一些基本的工具供你使用,比如printf函数可以实现输出信息到控制台,scanf可以从键盘读取输入,每一个具体的工具都有自己所属的工具包,也就是说不同的库函数都有自己所属的.h文件,要用某一个库函数就需要先导入它所属的工具包才行,在语句中就是通过include来实现。

stdlib.h头文件包括的常用的函数有malloc()、calloc()、realloc()、free()、system()、atoi()、atol()、rand()、srand()、exit()等等。