Java的WebMagic爬虫
WebMagic的基本作用
WebMagic是当前Java爬虫中最主要的框架.主要使用的是HttpClient和Jsoup.
主要结构
webMagic的结构主要是DownLoader,PageProcessor,Scheduler,Pipeline四大组件,主要对应爬虫生命周期中的下载,处理,管理和持久化等功能.
爬虫生命周期
一个完整的爬虫生命周期包括:网址管理,网页下载,内容提取,保存.例如通过IP限制、验证码检测等等,要顺利地完成数据采集任务,还需要深入研究如何突破反爬虫机制。
扩展部分
提供一些便捷的功能,例如注解模式编写爬虫等。同时内置了一些常用的组件,便于爬虫开发。
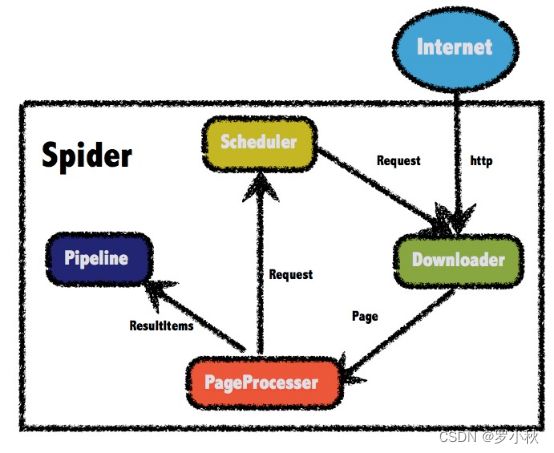
WebMagic的四个组件
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。面对不同的网页,有时需要自己去自定义自己的需求.
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
用于数据流转的对象
1.request
request是对URL地址的一层封装,一个Request对应一个URL地址。
它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方式。
2.Page
Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。
Page是WebMagic抽取过程的核心对象,它提供一些方法可供抽取、结果保存等。
功能使用
1.加入依赖
4.0.0
cn.crawler
crawler-webmagic
1.0-SNAPSHOT
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
如果代码出现问题,可以尝试使用参考以下资料自己修复webMagic原文档
2.加入配置文件
#添加log4j.properties配置文件
log4j.rootLogger=INFO,A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n基本案例
public class JobProcessor implements PageProcessor {
public void process(Page page) {
page.putField("author", page.getHtml().css("div.mt>h1").all());
}
private Site site = Site.me();
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new JobProcessor())
//初始访问url地址
.addUrl("https://www.jd.com/moreSubject.aspx")
.run();
}
}后续会持续更新!!!