Java爬虫系列 - 爬虫补充内容+ElasticSearch展示数据
一,定时任务


Cron表达式



@Component
public class TaskTest {
@Scheduled(cron = "0/5 * * * * *") // 从0秒开始,每个五秒 执行一次 { 秒 分 时 天 月 周 }
public void test(){
System.out.println("定时任务执行了");
}
}二,网页去重
之前我们对下载的url地址进行了去重操作,避免同样的url下载多次。其实不光url需要去重,我们对下载的内容也需要去重。
在网上我们可以找到许多内容相似的文章。但是实际我们只需要其中一个即可,同样的内容没有必要下载多次,那么如何进行去重就需要进行处理了
去重方案介绍
指纹码对比
最常见的去重方案是生成文档的指纹门。例如对一篇文章进行MD5加密生成一个字符串,我们可以认为这是文章的指纹码,再和其他的文章指纹码对比,一致则说明文章重复。
但是这种方式是完全一致则是重复的,如果文章只是多了几个标点符号,那仍旧被认为是不重复的,这种方式并不合理
BloomFilter
这种方式就是我们之前对url进行去重的方式,使用在这里的话,也是对文章进行计算得到一个数,再进行对比,缺点和方法1是一样的,如果只有一点点不一样,也会认为不重复,这种方式不合理。
KMP算法
KMP算法是一种改进的字符串匹配算法。KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。能够找到两个文章有哪些是一样的,哪些不一样。
这种方式能够解决前面两个方式的“只要一点不一样就是不重复”的问题。但是它的时空复杂度太高了,不适合大数据量的重复比对。
还有一些其他的去重方式:最长公共子串、后缀数组、字典树、DFA等等,但是这些方式的空复杂度并不适合数据量较大的工业应用场景。我们需要找到一款性能高速度快,能够进行相似度对比的去重方案
Google 的 simhash 算法产生的签名,可以满足上述要求。这个算法并不深奥,比较容易理解。这种算法也是目前Google搜索引擎所目前所使用的网页去重算法。
SimHash
1. 流程介绍
simhash是由 Charikar 在2002年提出来的,为了便于理解尽量不使用数学公式,分为这几步:
1、分词,把需要判断文本分词形成这个文章的特征单词。
2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字。
3、加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”
“51区”计算为 “ 5 -5 5 -5 5 5”。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。
“美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”
把每一位进行累加, “4+5 -4±5 -4+5 4±5 -4+5 4+5”à“9 -9 1 -1 1 9”
5、降维,把算出来的 “9 -9 1 -1 1 9”变成 0 1 串,形成最终的simhash签名。
2. 签名距离计算
我们把库里的文本都转换为simhash签名,并转换为long类型存储,空间大大减少。现在我们虽然解决了空间,但是如何计算两个simhash的相似度呢?
我们通过海明距离(Hamming distance)就可以计算出两个simhash到底相似不相似。两个simhash对应二进制(01串)取值不同的数量称为这两个simhash的海明距离。
举例如下: 10101 和 00110 从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。对于二进制字符串的a和b,海明距离为等于在a XOR b运算结果中1的个数(普遍算法)。
参考项目
代理的使用
有些网站不允许爬虫进行数据爬取,因为会加大服务器的压力。其中一种最有效的方式是通过ip+时间进行鉴别,因为正常人不可能短时间开启太多的页面,发起太多的请求。
我们使用的WebMagic可以很方便的设置爬取数据的时间, 但是这样会大大降低我们爬取数据的效率,如果不小心ip被禁了,会让我们无法爬去数据,那么我们就有必要使用代理服务器来爬取数据。
1. 代理服务器
代理(英语:Proxy),也称网络代理,是一种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。
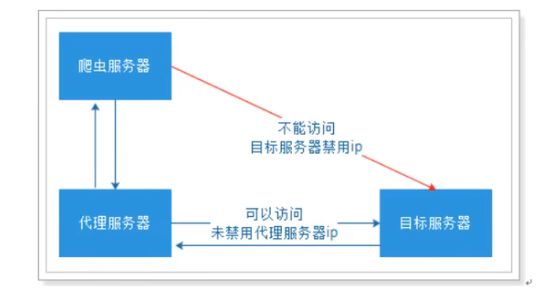
提供代理服务的电脑系统或其它类型的网络终端称为代理服务器(英文:Proxy Server)。一个完整的代理请求过程为:客户端首先与代理服务器创建连接,接着根据代理服务器所使用的代理协议,请求对目标服务器创建连接、或者获得目标服务器的指定资源。
我们就需要知道代理服务器在哪里(ip和端口号)才可以使用。网上有很多代理服务器的提供商,但是大多是免费的不好用,付费的还行。
2. 使用代理
WebMagic使用的代理APIProxyProvider。因为相对于Site的“配置”,ProxyProvider定位更多是一个“组件”,所以代理不再从Site设置,而是由HttpClientDownloader设置。

ProxyProvider有一个默认实现:SimpleProxyProvider。它是一个基于简单Round-Robin的、没有失败检查的ProxyProvider。可以配置任意个候选代理,每次会按顺序挑选一个代理使用。它适合用在自己搭建的比较稳定的代理的场景。
如果需要根据实际使用情况对代理服务器进行管理(例如校验是否可用,定期清理、添加代理服务器等),只需要自己实现APIProxyProvider即可。
请求能返回地址的api:https://api.myip.com/
免费代理服务器地址:免费私密代理 - 米扑代理 (mimvp.com)
为了避免干扰,先把之前项目中的其他任务的@Component注释掉,再在案例中加入编写以下逻辑:
@Component
public class ProxyTest implements PageProcessor {
@Scheduled(fixedDelay = 1000)
public void process() {
// 创建下载器 Downloader
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
// 给下载器设置代理服务器信息
httpClientDownloader.setProxyProvider(SimpleProxyProvider.from(new Proxy("221.122.91.65", 80)));
Spider.create(new ProxyTest())
.addUrl("https://api.myip.com/")
.setDownloader(httpClientDownloader)// 设置下载器
.run();
}
@Override
public void process(Page page) {
System.out.println(page.getHtml().toString());
}
private Site site = Site.me();
@Override
public Site getSite() {
return site;
}
}
三, ElasticSearch环境准备
安装ElasticSearch服务:Download Elasticsearch | Elastic点击下载需要用到的环境,百度云中
下载 elasticsearch-5.6.16.zip 并解压, 推荐使用1.8及以上64位jdk
进入bin中启动 elasticsearch.bat
当出现以下内容表示启动完成

访问地址是http://127.0.0.1:9200 访问该地址得到json数据表示ElasticSearch安装启动完成
安装ES的图形化界面插件
安装ElasticSearch的head插件,完成图形化界面的效果,完成索引数据的查看。采用本地安装方式进行head插件的安装。elasticsearch-5-*以上版本安装head需要安装node和grunt。
1)安装head插件:GitHub - mobz/elasticsearch-head:弹性搜索集群的 Web 前端
将head压缩包elasticsearch-head-master.zip解压到任意目录,但是要和elasticsearch的安装目录区别开
2)安装nodejs:Index of /download/release/v8.9.4/ (nodejs.org)
直接下一步就行了
3)将grunt安装为全局命令 ,Grunt是基于Node.js的项目构建工具
在cmd控制台中输入如下执行命令:
npm install -g grunt-cli
ps:如果安装不成功或者安装速度慢,可以使用淘宝的镜像进行安装:
npm install -g cnpm –registry=https://registry.npm.taobao.org
后续使用的时候,只需要把npm xxx 换成 cnpm xxx 即可
修改elasticsearch配置文件:elasticsearch.yml,增加以下三句命令:
http.cors.enabled: true
http.cors.allow-origin: "*"
network.host: 127.0.0.1
重启
进入head目录启动head,在命令提示符下输入命令:
grunt server

根据提示访问http://localhost:9100,效果如下:
PS:如果第5步失败,执行以下命令
npm install grunt
再次运次那个grunt server, 根据提示按以下方式依次安装组件
npm install grunt-contrib-clean grunt-contrib-concat grunt-contrib-watch grunt-contrib-connect grunt-contrib-copy grunt-contrib-jasmine
安装成功后再执行 grunt server即可
安装分词器
解压elasticsearch-analysis-ik-5.6.8.zip
将解压后的elasticsearch文件夹拷贝到elasticsearch-5.6.8\plugins下,并重命名文件夹为ik
重新启动ElasticSearch,即可加载IK分词器
Node.js--下载/安装/配置--安装步骤/安装教程/加快速度/使用国内镜像--Windows/Linux/Docker_IT利刃出鞘的博客-CSDN博客
详情参考博客:
(87条消息) Java爬虫系列(五) - 爬虫补充内容+ElasticSearch展示数据_yzhSWJ的博客-CSDN博客