MapReduce的核心思想与编程模型原理详解(含wordcount单词统计案例实现)
目录
一、MapReduce的定义
二、MapReduce的核心思想.
三、MapReduce编程模型
1. Map阶段
2. Reduce阶段
3. Map&Reduce
四、MapReduce编程指导思想(天龙八步)
1. Map阶段2个步骤
2. Shuffle阶段4个步骤
3. Reduce阶段2个步骤
五、Hadoop当中常用的数据类型
六、MapReduce编程入门之单词统计案例实现
第一步:创建maven工程并导入以下jar包
第二步:定义mapper类
第三步:定义reducer类
第四步:组装main程序
第五步:运行
一、MapReduce的定义
-
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
-
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
二、MapReduce的核心思想.
-
MapReduce思想在生活中处处可见。或多或少都曾接触过这种思想。MapReduce的思想核心是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。即使是发布过论文实现分布式计算的谷歌也只是实现了这种思想,而不是自己原创。
-
Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些==小任务可以并行计算,彼此间几乎没有依赖关系。==
-
Reduce负责“合”,即对map阶段的结果进行全局汇总。
-
这两个阶段合起来正是MapReduce思想的体现。
-
还有一个比较形象的语言解释MapReduce:
-
例子一:我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就越快。
-
现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
-
例子二:电影黑客帝国当中,特工”(Agents),Smith(史密斯)对付救世主Neo打不过怎么办?一个人打不过,就复制十个出来,十个不行就复制一百个
-
三、MapReduce编程模型
-
MapReduce是采用一种分而治之的思想设计出来的分布式计算框架
-
那什么是分而治之呢?
-
比如一复杂、计算量大、耗时长的的任务,暂且称为“大任务”;
-
此时使用单台服务器无法计算或较短时间内计算出结果时,可将此大任务切分成一个个小的任务,小任务分别在不同的服务器上并行的执行;
-
最终再汇总每个小任务的结果
-
-
MapReduce由两个阶段组成:
-
Map阶段(切分成一个个小的任务)
-
Reduce阶段(汇总小任务的结果)
-

1. Map阶段
- map阶段有一个关键的map()函数;
- 此函数的输入是键值对
- 输出是一系列键值对,输出写入本地磁盘。
2. Reduce阶段
- reduce阶段有一个关键的函数reduce()函数
- 此函数的输入也是键值对(即map的输出(kv对))
- 输出也是一系列键值对,结果最终写入HDFS
3. Map&Reduce

四、MapReduce编程指导思想(天龙八步)
- mapReduce编程模型的总结:
- MapReduce的开发一共有八个步骤其中map阶段分为2个步骤,shuffle阶段4个步骤,reduce阶段分为2个步骤
1. Map阶段2个步骤
- 第一步:设置inputFormat类,将数据切分成key,value对,输入到第二步
- 第二步:自定义map逻辑,处理我们第一步的输入kv对数据,然后转换成新的key,value对进行输出
2. Shuffle阶段4个步骤
- 第三步:对上一步输出的key,value对进行分区。(相同key的数据属于同一分区)
- 第四步:对每个分区的数据按照key进行排序
- 第五步:对分区中的数据进行规约(combine操作),降低数据的网络拷贝(可选步骤)
- 第六步:对排序后的数据进行分组,分组的过程中,将相同key的value放到一个集合当中(每组数据调用一次reduce方法)
3. Reduce阶段2个步骤
- 第七步:对多个map的任务进行合并,排序,写reduce函数自己的逻辑,对输入的key,value对进行处理,转换成新的key,value对进行输出
- 第八步:设置outputformat将输出的key,value对数据进行保存到文件中
五、Hadoop当中常用的数据类型
hadoop没有沿用java当中基本的数据类型,而是自己进行封装了一套数据类型,其自己封装的类型与java的类型对应如下
下表常用的数据类型对应的Hadoop数据序列化类型
| Java类型 | Hadoop Writable类型 |
|---|---|
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
| byte[] | BytesWritable |
六、MapReduce编程入门之单词统计案例实现
需求:现有一片短文数据格式如下,每一行数据之间都是使用空格进行分割,求取每个单词出现的次数
Seven times have I despised my soul
The first time when I saw her being meek that she might attain height
The second time when I saw her limping before the crippled
The third time when she was given to choose between the hard and the easy, and she chose the easy
The fourth time when she committed a wrong, and comforted herself that others also commit wrong
The fifth time when she forbore for weakness, and attributed her patience to strength
The sixth time when she despised the ugliness of a face, and knew not that it was one of her own masks
And the seventh time when she sang a song of praise, and deemed it a virtue第一步:创建maven工程并导入以下jar包
cdh版本的软件jar包下载参见以下这两个文档链接
CDH 5 Maven Repository
https://docs.cloudera.com/documentation/enterprise/release-notes/topics/cdh_vd_cdh5_maven_repo.html
Maven Artifacts for CDH 5.14.x Releases
https://docs.cloudera.com/documentation/enterprise/release-notes/topics/cdh_vd_cdh5_maven_repo_514x.html
cloudera
https://repository.cloudera.com/artifactory/cloudera-repos/
org.apache.hadoop
hadoop-client
2.6.0-mr1-cdh5.14.2
org.apache.hadoop
hadoop-common
2.6.0-cdh5.14.2
org.apache.hadoop
hadoop-hdfs
2.6.0-cdh5.14.2
org.apache.hadoop
hadoop-mapreduce-client-core
2.6.0-cdh5.14.2
junit
junit
4.11
test
org.testng
testng
RELEASE
test
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.8
1.8
UTF-8
org.apache.maven.plugins
maven-shade-plugin
2.4.3
package
shade
true
第二步:定义mapper类
package com.xsluo;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 自定义mapper类需要继承Mapper,有四个泛型,
* keyin: k1 行偏移量 Long
* valuein: v1 一行文本内容 String
* keyout: k2 每一个单词 String
* valueout : v2 1 int
* 在hadoop当中没有沿用Java的一些基本类型,使用自己封装了一套基本类型
* long ==>LongWritable
* String ==> Text
* int ==> IntWritable
*/
public class MyMapper extends Mapper {
/**
* 继承mapper之后,覆写map方法,每次读取一行数据,都会来调用一下map方法
* @param key:对应k1
* @param value:对应v1
* @param context 上下文对象。承上启下,承接上面步骤发过来的数据,通过context将数据发送到下面的步骤里面去
* @throws IOException
* @throws InterruptedException k1 v1
* 0;hello world
* k2 v2
* hello 1
* world 1
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行数据并按照分隔符切分
String[] words = value.toString().split(" ");
Text text = new Text();
IntWritable intWritable = new IntWritable(1);
for (String word : words) {
//将每个单词出现都记做一次
//key2 Text类型
//v2 IntWritable类型
text.set(word);
//将我们的key2 v2写出去到下游
context.write(text,intWritable);
}
}
}
第三步:定义reducer类
package com.xsluo;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer {
//第三步:分区。相同key的数据发送到同一个reduce里面去,相同key合并,value形成一个集合
/**
* 继承Reducer类之后,覆写reduce方法
*
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int result = 0;
for (IntWritable value : values) {
//将我们的结果进行累加
result += value.get();
}
//输出数据
IntWritable intWritable = new IntWritable(result);
context.write(key,intWritable);
}
}
第四步:组装main程序
package com.xsluo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MyRunner extends Configured implements Tool {
/**
* 实现Tool接口之后,需要实现一个run方法,
* 这个run方法用于组装我们的程序的逻辑,其实就是组装八个步骤
* @param args
* @return
* @throws Exception
*/
@Override
public int run(String[] args) throws Exception {
/***
* 第一步:读取文件,解析成key,value对,k1 v1
* 第二步:自定义map逻辑,接受k1 v1 转换成为新的k2 v2输出
* 第三步:分区。相同key的数据发送到同一个reduce里面去,key合并,value形成一个集合
* 第四步:排序 对key2进行排序。字典顺序排序
* 第五步:规约 combiner过程 调优步骤 可选
* 第六步:分组
* 第七步:自定义reduce逻辑接受k2 v2 转换成为新的k3 v3输出
* 第八步:输出k3 v3 进行保存
*
*/
//获取Job对象,组装我们的八个步骤,每一个步骤都是一个class类
Configuration conf = super.getConf();
Job job = Job.getInstance(conf,"wordcount");
//实际工作当中,程序运行完成之后一般都是打包到集群上面去运行,打成一个jar包
//如果要打包到集群上面去运行,必须添加以下设置
job.setJarByClass(MyRunner.class);
//第一步:读取文件,解析成key,value对,k1:行偏移量 v1:一行文本内容
job.setInputFormatClass(TextInputFormat.class);
//指定我们去哪一个路径读取文件
TextInputFormat.addInputPath(job,new Path("file:///E:\\===BigData===\\06_KKB\\0806-MapReduce计算框架初探\\wc.txt"));
//第二步:自定义map逻辑,接受k1 v1 转换成为新的k2 v2输出
job.setMapperClass(MyMapper.class);
//设置map阶段输出的key,value的类型,其实就是k2 v2的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//第三步到六步:分区,排序,规约,分组都省略
//第七步:自定义reduce逻辑
job.setReducerClass(MyReducer.class);
//设置key3 value3的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//第八步:输出k3 v3 进行保存
job.setOutputFormatClass(TextOutputFormat.class);
//一定要注意,输出路径是需要不存在的,如果存在就报错
TextOutputFormat.setOutputPath(job,new Path("hdfs://node01:8020/output"));
//提交job任务
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
/**
* 程序入口
* @param args
*/
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//提交run方法之后,得到一个程序的退出状态码
int i = ToolRunner.run(conf, new MyRunner(), args);
//根据我们 程序的退出状态码,退出整个进程
System.exit(i);
}
}
第五步:运行
1、本地运行
查看结果:
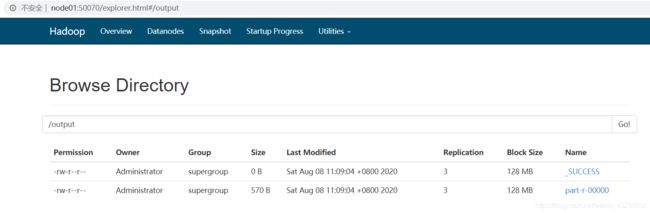
2、集群运行
-
打包并上传至Hadoop集群服务器
-
执行命令运行:hadoop jar jarFile [mainClass] args...