mapreduce
文章目录
- 什么是mapreduce
- 为什么会有mapreduce
- mapreduce的优缺点
-
- 优点
- 缺点
- mapreduce的核心思想
-
- 核心思想总结
- mapreduce的阶段分类
-
- 第一阶段(map)
- 第二阶段(reduce)
- partitioner
- hadoop序列化机制
-
- 为什么要序列化
- 什么是序列化
- hadoop和java序列化的比较
- 常用hadoop序列化数据类型
- 序列化接口Writable
-
- Writable的序列化和反序列化
- 排序接口WritableComparable
- 自定义对象实现mr的序列化接口
-
- 为什么要使用自定义类型?
- 如何自定义一个类型?
- mapreduce运行流程简述
- 分片机制
-
- 什么是分片?
- 源码解析
- 分片总结
- 运行流程
-
- maptask
- reducetask
- shuffle阶段
-
- 什么是shuffle
- map端
- reduce端
- shuffle流程
-
-
- 2.5.3 环形缓冲区的扩展:
-
- MapTask的具体执行流程
- ReduceTask具体执行流程
- combiner函数
- yarn资源管理器
-
- mapredcue1.x版本
- yarn的简介和设计思想
-
- 什么是yarn?
- yarn的设计思想
- yarn的三种调度器
-
- fifo调度器
- 容量调度器(capacity)
- 公平调度器(fair)
- job提交流程
- hadoop的压缩机制
-
- 要分析计算的文件为压缩文件时
- MapTask产生的临时文件压缩时
- ReduceTask产生的文件压缩时
- MapReduce的案例
-
- 奇数偶数和的统计
- 奇数行和偶数行的和的统计
- 小文件的处理
- TopN
- 二次排序
- 分组器的应用
- reduce-join
- map-join
什么是mapreduce
1、是apacheHadoop项目的一个核心模块
2、是对google提出来的分布式并行编程模型《MapReduce》论文的java开源实现
3、mapreduce是运行在hdfs上的一个分布式运算程序的编程框架,用于大数据集的并行运算
为什么会有mapreduce
1、在单机上处理海量数据,硬件资源有限,无法完成
2、而将单机程序扩展到集群中分布式运行,将极大增加程序的复杂度和开发难度
3、引入mapreduce框架后,开发人员可以将分布式计算的复杂性交由框架来处理
mapreduce的优缺点
优点
1、运行在hdfs上,具有高容错性和高扩展性
2、易于编程,不用编写分布式程序
3、适合处理计算大数据集
缺点
1、不适合实时计算
2、不适合流式计算(动态的输入数据)
3、不适合DAG(有向图)计算
mapreduce的核心思想
1)MapReduce设计的一个理念是“计算向数据靠拢”(移动计算),而不是“数据向计算靠拢”(移动数据)
2)将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,移动到有数据存储的集群节点上,一是可以减少节点间的数据移动开销。二是在存储节点上可以并行计算,大大提高计算效率问题。
因为移动数据需要大量的网络传输开销,尤其是在大规模数据环境下,这种开销尤为惊人,所以移动计算要比移动数据更加经济。
3)MapReduce一个完整的运算分为Map和Reduce两个部分。Map会处理本节点的原始数据,产生的数据会临时存储到本地磁盘。Reduce会跨节点fetch属于自己的数据,并进行处理,产生的数据会存储到HDFS上。
核心思想总结
一句话:移动计算而非移动数据,分而治之。
原因:因为移动数据,会占用大量的网络带宽,而网络带宽本来就很稀缺,传输时间与分析时间的比例大大提高了,
效率非常低。
反过来,因为计算程序的字节数量不是很大(100M足够大了),所以将计算程序移动到有数据的机器节点上,利用他们的cpu进行运算,一是比移动数据要大大节省了网络带宽和时间,二是可以并发运算,效率翻倍。这样,整个作业的时间只取决于分析时间。
MapReduce的一个完整程序包含两个部分,一部分是N个MapTask并行运算(程序分发到有数据的节点上运行),互不相干,效率翻倍,任务产生的数据临时存储到本地磁盘中。另一部分是N个ReduceTask并行运算,互不相干,需要从MapTask产生的数据中fetch自己要处理的数据,进行合并统计等,将最终分析结果存储到HDFS中。
因为MapReduce计算的数据一般都是大数据集,而开发人员编写的计算程序不会太大,而网络带宽是稀缺资源,移动大数据集的时间是非常长的,并且移动数据到一台机器上计算,单台机器的性能是及其低的,运算速度会及其长,所以选择将计算程序移动到拥有要处理的数据的机器上,这样不会占用很多的网络带宽,移动计算程序的时间不会太长,而且集群的运算性能比较好,会大大缩短计算时间,从而缩短整个作业的运行时间。
map阶段负责“分”,就是把一个复杂的或者计算量很大的任务分解成多个子任务,这些子任务并行运行,互不干扰,彼此之间没有依赖关系
reduce阶段负责“合”,就是把map阶段的计算结果汇总起来输出
mapreduce的阶段分类
分为2个阶段
第一阶段(map)
第一阶段,也称之为Map阶段。这个阶段会有若干个MapTask实例,完全并行运行,互不相干。每个MapTask会读取分析一个InputSplit(输入分片,简称分片)对应的原始数据。计算的结果数据会临时保存到所在节点的本地磁盘里。
第二阶段(reduce)
第二阶段,也称为Reduce阶段。这个阶段会有若干个ReduceTask实例并发运行,互不相干。但是他们的数据依赖于上一个阶段的所有maptask并发实例的输出。一个ReudceTask会从多个MapTask运行节点上fetch自己要处理的分区数据。经过处理后,输出到HDFS上。
partitioner
-
partitioner的作用是将mapper 输出的key/value划分成不同的partition,每个reducetask对应一个
partition。 -
默认情况下,partitioner先计算key的散列值(hash值)。然后通过reducetask个数执行取模运算:
key.hashCode%(reducer个数)。这样能够随机地将整个key空间平均分发给每个reducetask -
目的:
可以使用自定义Partitioner来达到reducetask的负载均衡, 提高效率。 -
适用范围:
需要非常注意的是:必须提前知道有多少个分区。比如自定义Partitioner会返回4个不同int值,而reducetask
number设置了小于4,那就会报错。所以我们可以通过运行分析任务来确定分区数。例如,有一堆包含时间戳的
数据,但是不知道它能追朔到的时间范围,此时可以运行一个作业来计算出时间范围。
注意:在自定义partitioner时一定要注意防止数据倾斜。
hadoop序列化机制
为什么要序列化
在基于类的编程语言中,我们说需要的数据都会被封装成对象,在内存中进行管理。可是有些时候,这样的对象,我们想直接存储到磁盘中,或者想进行网络传输,那么需要怎么做呢?
需要将对象序列化成0和1组成的字节序列,字节序列就可以存储到磁盘中,或者进行网络传输了。当我们需要对象时,就可以读取磁盘上的字节序列,或者接收网络传输过来的字节序列,进行反序列化成我们需要的对象就可以了。
什么是序列化
序列化
序列化是指将具有结构化的内存对象转为0和1组成的字节序列,以便进行网络传输或持久存储到设备的过程。
反序列化
反序列化指的是将字节序列转为内存中具有结构化的对象的过程。
序列化应用的两个领域
-1. 网络传输(进程通信)
-2. 永久存储
hadoop和java序列化的比较
hadoop会涉及到大量数据的传输(网络IO),比如进程之间的通信(RPC协议),reduceTask的fetch操作。而网络带宽是极其稀缺的,因此使用序列化机制是非常必要的。
Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,header,继承体系......),这些数据不是我们需要的,也不便于在网络中高效传输.
基于Hadoop在集群之间进行通讯或者RPC调用的时候,数据的序列化要快,体积要小,占用带宽要小的需求,因此,专门为hadoop单独开发了一套精简高效的序列化机制(Writable)。此序列化机制要求具有以下特点:
1)紧凑:紧凑的格式能让我们充分利用网络带宽,而带宽是数据中心最稀缺的资源;
2)快速:进程通信形成了分布式系统的框架,所以需要尽量减少序列化和反序列化的性能开销,这是基本的;
3)可扩展:协议为了满足新的需求变化,所以控制客户端和服务器过程中,需要直接引进相应的协议,这些是新协议,原序列化方式能支持新的协议报文;
4)互操作:能支持不同语言写的客户端和服务端进行交互;
需要注意的是: MapReduce的key和value,都必须是可序列化的。而针对于key而言,是数据排序的关键字,因此还需要提供比较接口:WritableComparable
常用hadoop序列化数据类型
常用的数据类型对应的hadoop数据序列化类型
| Java类型 | Hadoop Writable类型 | 释义 |
|---|---|---|
| boolean | BooleanWritable | 标准布尔型数值 |
| byte | ByteWritable | 单字节数值 |
| int | IntWritable | 整型数值 |
| float | FloatWritable | 单精度数 |
| long | LongWritable | 长整型数值 |
| double | DoubleWritable | 双精度数 |
| string | Text | 使用UTF8格式存储的文本 |
| map | MapWritable | 以键值对的形式存储Writable类型的数据 |
| array | ArrayWritable | 以数组的形式存储Writable类型的数据 |
| null | NullWritable | 当 |
NullWritable说明:

序列化接口Writable
Writable的序列化和反序列化
write() 是把每个对象序列化到输出流———Writable序列化
readFields()是把输入流字节反序列化-------Writable反序列化
排序接口WritableComparable
public interface WritableComparable<T> extends Writable, Comparable<T> {
}
扩展:


自定义对象实现mr的序列化接口
为什么要使用自定义类型?
自带的类实现了对整形,浮点型,布尔型及String(Text类)的封装,都是比较简单的数据类型,在实际应用中,对于一些属于用户自己的功能,系统无法预知,通常需要自定义数据类型。
如何自定义一个类型?
如果需要将自定义的bean放在key中传输,则还需要实现comparable接口,因为MapReduce框中的shuffle过程一定会对key进行排序,此时,自定义的bean实现的接口应该是WritableComparable
案例:定义一个表示一对字符串的类型
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.Objects;
/**
* @Description 学习如何自定义hadoop类型:定义两个字符串属性的类型
*
* 第一种方式:可以直接实现WritableComparable接口
* 因为WritableComparable已经实现了Writable接口和Comparable接口
* 第二种方式:可以实现Writable接口和Comparable接口
* 注意:如果自定义的类型,会被作为key进行传输,那么必须要实现Comparable接口
* 因为底层会对key进行排序。
* 如果不作为key使用,只需要实现序列化接口Writable即可。
*/
public class TextPair implements WritableComparable {
private Text name;
private Text info;
public TextPair(){
name = new Text();
info = new Text();
}
public TextPair(Text name, Text info) {
this.name = name;
this.info = info;
}
/**
* 重载一个构造器
* @return
*/
public TextPair(String name,String info){
this.name = new Text(name);
this.info = new Text(info);
}
public Text getName() {
return name;
}
public void setName(Text name) {
this.name = name;
}
public Text getInfo() {
return info;
}
public void setInfo(Text info) {
this.info = info;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
TextPair textPair = (TextPair) o;
return Objects.equals(name, textPair.name) &&
Objects.equals(info, textPair.info);
}
@Override
public int hashCode() {
return Objects.hash(name, info);
}
public String toString(){
return "["+name.toString()+","+info.toString()+"]";
}
/**
* 序列化方法,将属性序列化成字节序列
* @param out
* @throws IOException
*/
public void write(DataOutput out) throws IOException {
//将属性写到输出流程
name.write(out);
info.write(out);
//如果不是hadoop类型,比如是java类型
// out.writeUTF(name);
// out.writeUTF(info);
}
/**
* 反序列化方法,从流中读取字节序列进行反序列化。
* @param in
* @throws IOException
*/
public void readFields(DataInput in) throws IOException {
//要按照序列化的顺序进行反序列化
name.readFields(in);
info.readFields(in);
}
public int compareTo(Object o) {
return 0;
}
}
mapreduce运行流程简述
一个完整的MapReduce程序在分布式运行时有三类实例进程:
1) MRAppMaster:负责整个程序的过程调度及状态协调
2) MapTask:负责map阶段的整个数据处理流程
3) ReduceTask:负责reduce阶段的整个数据处理流程
当一个作业提交后(mr程序启动),大概流程如下:
1、调用waitForCompletion方法创建jobCommiter实例,调用submitJobInternal方法监控任务的执行进度
2、jobCommiter对象会向resourcemanager申请一个jobID,这期间jobCommiter就会开始计算分片
3、如果成功申请到jobID,client就会将运行作业所需要的jar包以及配置文件和分片信息上传到hdfs上,这个文件的 副本数默认是10
4、准备工作做好,通知resourcemanager调用submitApplication方法提交作业
5、resourcemanager会通知yarn分配一个节点用来启动appmaster
6、之后appmaster会从hdfs上拉去任务资源,jar包,配置文件以及分片信息(元数据),为每一个切片创建maptask
7、appmaster会向resourcemanager申请一个节点来运行maptask,当maptask运行到5%时,appmaster就会想resoucemanager申请执行reducetask的资源。
8、当resourcemanager为maptask分配资源之后,appmaster就会与相应的nodemanager通信
9、运行任务前,yarn的子进程会先将运行需要的数据从hdfs上拉取到本地
10、然后开始运行maptask或者reducetask
12、当收到任务完成的通知后,appmaster会把状态设置为success。然后会就会将任务信息输出到控制台
分片机制
什么是分片?
MapReduce在进行作业提交时,会预先对将要分析的原始数据进行划分处理,形成一个个等长的逻辑数据对象,称之为输入分片(inputSplit),简称“分片”。MapReduce为每一个分片构建一个单独的MapTask,并由该任务来运行用户自定义的map方法,从而处理分片中的每一条记录。
源码解析
#1. MapReduce在进行作业提交时,会预先对将要分析的原始数据进行划分处理,形成一个个等长的逻辑数据对象,称之为输入分片(inputSplit),简称“分片”。
#2. MapReduce为每一个分片构建一个单独的MapTask,并由该任务来运行用户自定义的map方法,从而处理分片中的每一条记录。
#3. 源码:
public class FileSplit extends InputSplit implements Writable {
private Path file; //要处理的文件名
private long start; //当前逻辑分片的偏移量
private long length; //当前逻辑分片的字节长度
private String[] hosts; //当前逻辑分片对应的块数据所在的主机名
private SplitLocationInfo[] hostInfos;
public FileSplit() {}
public FileSplit(Path file, long start, long length, String[] hosts) {
this.file = file; //创建逻辑分片对象时调用的构造器
this.start = start;
this.length = length;
this.hosts = hosts;
}
//.....
}
#4. 源码解析:
(1) InputSplit是抽象父类型,真正使用的是FileSplit类型,此类型里封装了四个属性:
--1) Path file: 是一个文件路径
--2) long start: 相对于整个文件的字节偏移量
--3) long length: 就是FileSplit这个对象的对应的原始数据的字节数量,通常被称之为分片大小
--4) String[] hosts: 封装的是要处理的原始数据块文件的三个副本存储节点主机名
#5. 从上分析:
一旦创建分片对象,也就是使用new调用FileSplit构造器,创建对象时,要给以上属性赋值。这些数据我们称之为逻辑数据,也就是描述信息。
## 分片大小的选择
- 拥有许多分片,意味着处理每个分片所需要的时间要小于处理整个输入数据所花的时间(分而治之的优势)。
- 并行处理分片,且每个分片比较小。负载平衡,好的计算机处理的更快,可以腾出时间,做别的任务
- 如果分片太小,管理分片的总时间和构建map任务的总时间将决定作业的整个执行时间。
- 如果分片跨越两个数据块,那么分片的部分数据需要通过网络传输到map任务运行的节点,占用网络带宽,效率更低
- 因此最佳分片大小应该和HDFS上的块大小一致。hadoop2.x默认128M.
分片有1.1倍的冗余
分片总结
1)分片大小参数
通过分析源码,在FileInputFormat中,计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize)); 切片主要由这几个值来运算决定
| 参数 | 默认值 | 属性 |
|---|---|---|
| minsize | 1 | mapreduce.input.fileinputformat.split.minsize |
| maxsize | Long.MAXVALUE | mapreduce.input.fileinputformat.split.maxsize |
| blocksize | 块大小 | dfs.blocksize: |
可以看出,就是取minsize、maxsize、blocksize三者的中间的那个值。
1. 将maxsize调得比blocksize小,则会让切片变小,而且就等于配置的这个参数的值.
2. 将minsize调得比blockSize大,则会让切片变得比blocksize还大
3. 但是,不论怎么调参数,都不能让多个小文件"划入"一个split
2)创建过程总结
1. 获取文件大小及位置
2. 判断文件是否可以分片(压缩格式有的可以进行分片,有的不可以)
3. 获取分片的大小
4. 剩余文件的大小/分片大小>1.1时,循环执行封装分片信息的方法,具体如下:
封装一个分片信息(包含文件的路径,分片的起始偏移量,要处理的大小,分片包含的块的信息,分片中包含的块存在哪儿些机器上)
5. 剩余文件的大小/分片大小<=1.1且不等于0时,封装一个分片信息(包含文件的路径,分片的起始偏移量,要处理
的大小,分片包含的块的信息,分片中包含的块存在哪儿些机器上)
分片的注意事项:1.1倍的冗余。
3)分片细节问题总结
如果有多个分片
- 第一个分片读到末尾再多读一行
- 既不是第一个分片也不是最后一个分片第一行数据舍弃,末尾多读一行
- 最后一个分片舍弃第一行,末尾多读一行
- 为什么:前一个物理块不能正好是一行结束的位置啊
4)分片与块的区别
分片是逻辑数据,信息可能会跨块。分片是在mr分析文件时涉及到的概念
块是物理数据,不能跨节点。块是hdfs上的存储单位。
运行流程
maptask
- maptask调用FileInputFormat的getRecordReader读取分片数据
- 每行数据读取一次,返回一个(K,V)对,K是offset,V是一行数据
- 将k-v对交给MapTask处理
- 每对k-v调用一次map(K,V,context)方法,然后context.write(k,v)
- 写出的数据交给收集器OutputCollector.collector()处理
- 将数据写入环形缓冲区,并记录写入的起始偏移量,终止偏移量,环形缓冲区默认大小100M
- 默认写到80%的时候要溢写到磁盘,溢写磁盘的过程中数据继续写入剩余20%
- 溢写磁盘之前要先进行分区然后分区内进行排序
- 默认的分区规则是hashpatitioner,即key的hash%reduceNum
- 默认的排序规则是key的字典顺序,使用的是快速排序
- 溢写会形成多个文件,在maptask读取完一个分片数据后,先将环形缓冲区数据刷写到磁盘
- 将数据多个溢写文件进行合并,分区内排序(归并排序)
MapTask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度.那么,MapTask并行实例是否越多越好呢?其并行度又是如何决定呢?
-
如果硬件配置为2*12core + 64G,恰当的map并行度是大约每个节点20-100个map,最好每个map的执行时间至少一分钟。
-
如果job的每个map或者 reduce task的运行时间都只有30-40秒钟,那么就减少该job的map或者reduce数,每一个task(map|reduce)的setup和加入到调度器中进行调度,这个中间的过程可能都要花费几秒钟,所以如果每个task都非常快就跑完了,就会在task的开始和结束的时候浪费太多的时间。
-
配置task的JVM重用可以改善该问题:
(mapred.job.reuse.jvm.num.tasks,默认是1,表示一个JVM上最多可以顺序执行的task数目(属于同一个Job)是1。也就是说一个task启一个JVM)
- 如果input的文件非常的大,比如1TB,可以考虑将hdfs上的每个block size设大,比如设成256MB或者512MB
reducetask
- 数据按照分区规则发送到reducetask
- reducetask将来自多个maptask的数据进行合并,排序(归并排序)
- 按照key相同分组()
- 一组数据调用一次reduce(k,iterablevalues,context)
- 处理后的数据交由reducetask
- reducetask调用FileOutputFormat组件
- FileOutputFormat组件中的write方法将数据写出
Reduce Task的并行度同样影响整个job的执行并发度和执行效率,但与Map Task的并发数由切片数决定不同,Reduc Task数量的决定是可以直接手动设置
shuffle阶段
什么是shuffle
从map函数结束到reduce函数开始之间的过程称为shuffle阶段。
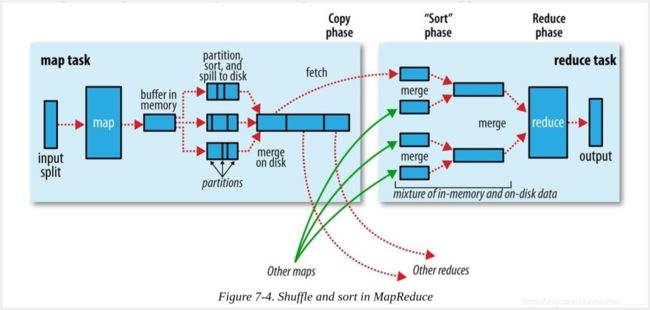
map端
map方法开始产生输出数据时,并不是简单地将它写到磁盘。这个过程非常复杂,它利用缓冲的方式写到内存并出于效率的考虑进行预排序(可以参考上图)
每个map任务都会有一个环形内存缓冲区用于存储map的输出数据。在默认情况下,缓冲区的大小为100MB,这个值可以通过mapreduce.task.io.sort.mb属性来调整。一旦缓冲区的内容达到阙值(默认是0.8,或者是80%,属属性是mapreduce.map.sort.spill.percent),一个后台线程便开始把内容溢写(spill)到磁盘里,这个位置由属性mapreduce.cluster.local.dir来指定的。在将数据溢写到磁盘过程中,map的输出数据继续写到缓冲区,但如果在此期间缓冲区被填满,map会被阻塞直到写磁盘过程完成。
在写磁盘之前,线程会根据分区器的逻辑把数据划分为不同的分区(partition)。然后,在每个分区中,后台线程会按键进行内存中排序(QuickSort,默认是字典顺序)。如果指定了一个combiner函数,它就在排序后的输出上运行。运行combiner函数使得map输出结果更紧凑,因此减少写到磁盘的数据和传递给reducer的数据。
每次内存缓冲区达到溢出阖值,就会新建一个溢出文件(spill file),因此在map任务写完其最后一个输出记录之后,可能会有几个溢出文件。在MapTask任务完成之前,多个溢出文件被合并成一个已分区且已排序的输出文件。配置属性mapreduce.task.io.sort.factor控制着一次最多能合并多少个文件,默认值是10。
如果至少存在3个溢出文件(通过mapreduce.map.combine.minspills属性设置)时,则combiner就会在输出文件写到磁盘之前再次运行。combiner可以在输入上反复运行,但并不影响最终结果。如果只有1或2个溢出文件,那么由于map输出规模减少,因而不值得调用combiner产生开销,因此不会为该map输出再次运行combiner。
为了使写磁盘的速度更快,节约磁盘空间,并且减少传给reducer的数据量,在溢写到磁盘的过程中对数据进行压缩往往是个很好的主意。在默认情况下,输出是不压缩的,但只要将mapreduce.map.output, compress设置为true,就可以轻松启用此功能。使用的压缩库由mapreduce.map.output.compress.codec指定,要想进一步了解压缩格式,请第六章。
1)扩展 MapOutputBuffer类型的详解
参考:org.apache.hadoop.mapred.MapTask.MapOutputBuffer
2)扩展 环形缓冲区的详解
reduce端
reducer通过HTTP得到输出文件的分区。用于文件分区的工作线程的数量由任务的mapreduce. shuffle.max. threads属性控制,此设置针对的是每一个节点管理器,而不是针对每个map任务。
现在转到处理过程的reduce部分。map输出文件位于运行MapTask的本地磁盘(注意,尽管map输出经常写到MapTask本地磁盘,但reduce输出并不这样)。现在,appmaster需要为分区文件运行reduce任务。并且,
reduce任务需要集群上若干个map任务的map输出作为其特殊的分区文件。每个map任务的完成时间可能不同,因此在每个任务完成时,reduce任务就开始复制其输出。这就是reduce任务的复制阶段。reduce任务有少量复制线程,因此能够并行取得map输出。默认值是5个线程,但这个默认值可以修改设置mapreduce.reduce.shuffle. parallelcopies 属性即可。
reducer如何知道要从哪台机器取得map输出呢?
map任务成功完成后,它们会使用心跳机制通知它们的application master。因此,对于指定作业,application master知道map输出和主机位置之间的映射关系。reducer中的一个线程定期询问master以便获取map输出主机的位置,直到获得所有输出位置。
由于第一个reducer可能失败,因此主机并没有在第一个reducer检索到map输出时就立即从磁盘上删除它们。相反,主机会等待,直到application master告知它删除map输出,这是作业完成后执行的。
如果map输出相当小,会被复制到reduce任务JVM的内存(缓冲区大小由mapreduce.reduce.shuffle.input. buffer.percent 属性控制,指定用于此用途的堆空间的百分比),否则,map输出被复制到磁盘。一旦内存缓冲区达到阖值大小(由 mapreduce.reduce.shuffle.merge.percent 决定)或达到 map 输出阖值(由 mapreduce. reduce. merge. inmem .threshold 控制),则合并后溢出写到磁盘中。如果指定combiner,则在合并期间运行它以降低写入硬盘的数据量。
随着磁盘上的溢写文件数量增多,后台线程会将它们合并为更大的、排好序的文件。这会为后面的合并节省一些时间。注意,为了合并,压缩的map输出(通过map任务)都必须在内存中被解压缩。
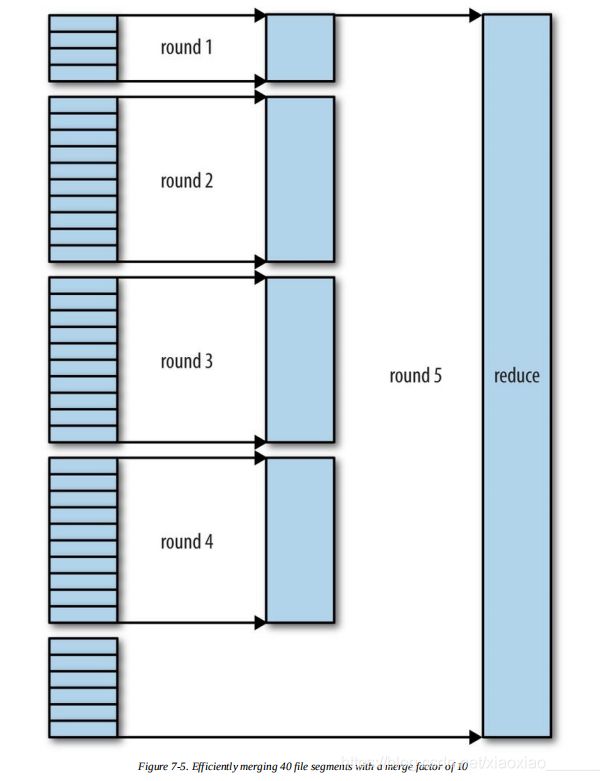
复制完所有map输出后,reduce任务进入排序阶段(更恰当的说法是合并阶段,因为排序是在map端进行的),这个阶段将合并map输岀,维持其顺序排序。这是循环进行的。比如,如果有50个map输出,而合并因子是10(10为默认设置,由mapreduce.task. io.sort.factor ,与 的合并类似),合并将进行 5 趟 ,每趟将10个文件合并成一个文件,因此最后有5个中间文件。
在最后阶段,即reduce阶段,直接把数据输入reduce函数,从而省略了一次磁盘往返行程,并没有将这5个文件合并成一个已排序的文件作为最后一趟。最后的合并可以来自内存和磁盘片段。
shuffle流程
不带环形缓冲区原理的叙述:
1. 从map函数输出到reduce函数接受输入数据,这个过程称之为shuffle.
2. map函数的输出,存储环形缓冲区(默认大小100M,阈值80M)
3. 当达到阈值时,准备溢写到本地磁盘(因为是中间数据,因此没有必要存储在HDFS上)。在溢写前要对数据进行分区整理,然后进行排序(quick sort,字典排序)
4. 如果有必要,可以在排序后,溢写前调用combiner函数进行运算,来达到减少数据的目的
5. 溢写文件有可能产生多个,然后对这多个溢写文件进行再次归并排序(也要进行分区和排序)。当溢写个数>=3时,可以再次调用combiner函数来减少数据。如果溢写个数<3时,默认不会调用combiner函数。
6. 合并的最终溢写文件可以使用压缩技术来达到节省磁盘空间和减少向reduce阶段传输数据的目的。(最终溢写文件是一个,存储在本地磁盘中)
7. Reduce阶段通过HTTP协议抓取属于自己的分区的所有map的输出数据(默认线程数是5,因此可以并发抓取)。
8. 抓取到的数据存在内存中,如果数据量大,当达到本地内存的阈值时会进行溢写操作,在溢写前会进行合并和排序(排序阶段),然后写到磁盘中,
9. 溢写文件可能会产生多个,因此在进入reduce之前会再次合并(合并因子是10),最后一次合并要满足10这个因子,同时输入给reduce函数,而不是产生最终一个临时合并文件(减少一次磁盘IO)。reduce函数输出数据会直接存储在HDFS上。
带上环形缓冲区的原理叙述:
1. 从map函数输出到reduce函数接受输入数据,这个过程称之为shuffle.
2. map函数的输出,存储环形缓冲区(默认大小100M,阈值80M)
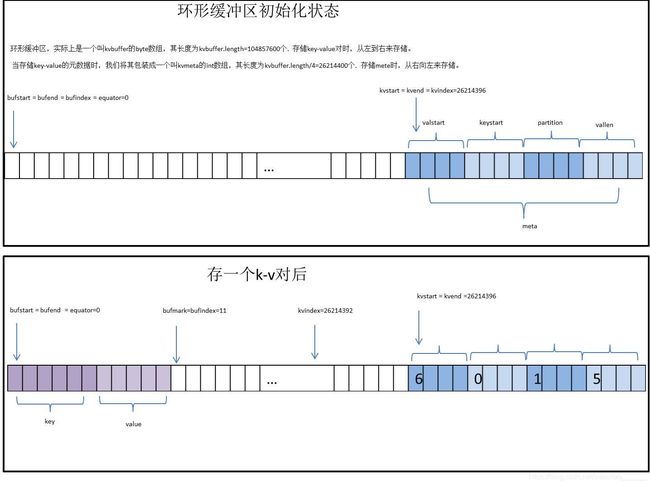
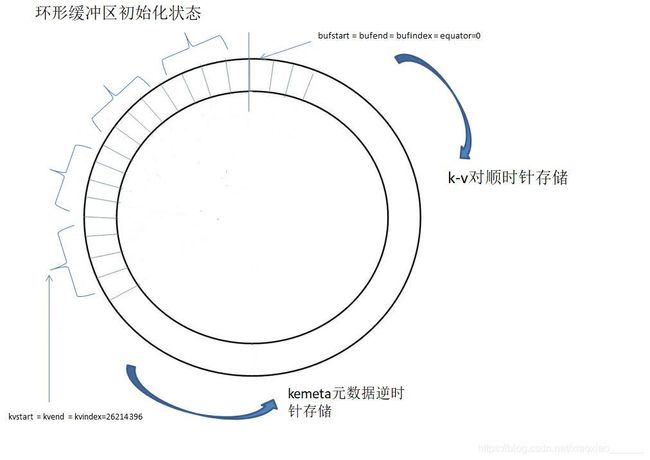
环形缓冲区:其实是一个字节数组kvbuffer. 有一个sequator标记,kv原始数据从左向右填充(顺时针),
kvmeta是对kvbuffer的一个封装,封装成了int数组,用于存储kv原始数据的对应的元数据valstart,
keystart,partition,vallen信息,从右向左(逆时针)。参考(环形缓冲区的详解一张)
3. 当达到阈值时,准备溢写到本地磁盘(因为是中间数据,因此没有必要存储在HDFS上)。在溢写前要进行对元数据分区(partition)整理,然后进行排序(quick sort,通过元数据找到出key,同一分区的所有key进行排序,排序完,元数据就已经有序了,在溢写时,按照元数据的顺序寻找原始数据进行溢写)
4. 如果有必要,可以在排序后,溢写前调用combiner函数进行运算,来达到减少数据的目的
5. 溢写文件有可能产生多个,然后对这多个溢写文件进行再次合并(也要进行分区和排序)。当溢写个数>=3时,可以再次调用combiner函数来减少数据。如果溢写个数<3时,默认不会调用combiner函数。
6. 合并的最终溢写文件可以使用压缩技术来达到节省磁盘空间和减少向reduce阶段传输数据的目的。(存储在本地磁盘中)
7. Reduce阶段通过HTTP协议抓取属于自己的分区的所有map的输出数据(默认线程数是5,因此可以并发抓取)。
8. 抓取到的数据存在内存中,如果数据量大,当达到本地内存的阈值时会进行溢写操作,在溢写前会进行合并和排序(排序阶段),然后写到磁盘中,
9. 溢写文件可能会产生多个,因此在进入reduce之前会再次合并(合并因子是10),最后一次合并要满足10这个因子,同时输入给reduce函数,而不是产生最终一个临时合并文件(减少一次磁盘IO)。reduce函数输出数据会直接存储在HDFS上。
2.5.3 环形缓冲区的扩展:
- 细节分析
在Hadoop这样的集群环境中,大部分map task与reduce task的执行是在不同的节点上。当然很多情况下Reduce执行时需要
跨节点去拉取其它节点上的map task结果。如果集群正在运行的job有很多,那么task的正常执行对集群内部的网络资源消耗
会很严重。这种网络消耗是正常的,我们不能限制,能做的就是最大化地减少不必要的消耗。还有在节点内,相比于内存,
磁盘IO对job完成时间的影响也是可观的。从最基本的要求来说,我们对shuffle过程的期望可以有:
a) 完整地从map task端拉取数据到reduce 端。
b) 在跨节点拉取数据时,尽可能地减少对带宽的不必要消耗。
c) 减少磁盘IO对task执行的影响。
OK,看到这里时,大家可以先停下来想想,如果是自己来设计这段shuffle过程,那么你的设计目标是什么。能优化的地方主要在于减少拉取数据的量及尽量使用内存而不是磁盘。shuffle过程横跨map与reduce两端,下面我会先说明总体流程,在详细说明map task和reduce task阶段.
MapTask的具体执行流程
这里的分析是基于Hadoop0.21.0的源码,以WordCount为例,并假设它有8个map task和3个reduce task。 如下图:
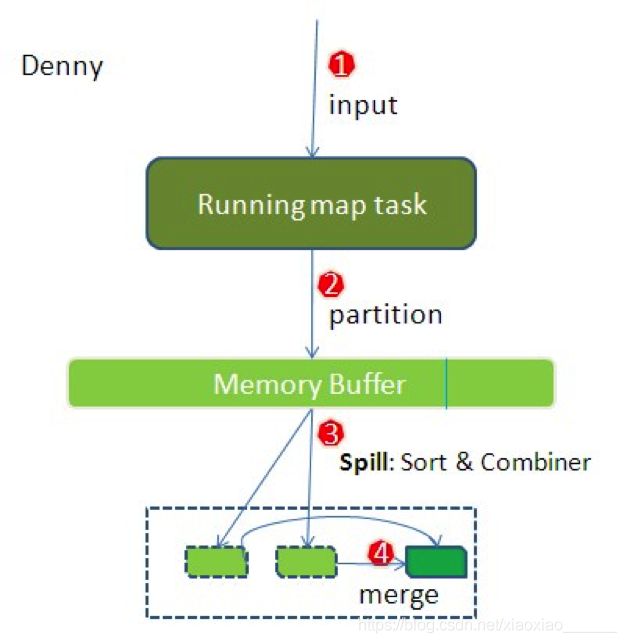
整个流程我分了四步。简单些可以这样说,每个map task都有一个内存缓冲区,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据。
这里的每一步都可能包含着多个步骤与细节,下面我对细节来一一说明:
-
在map task执行时,它的输入数据来源于HDFS的block,当然在MapReduce概念中,map task只读取split。Split与block的对应关系可能是多对一,默认是一对一。在WordCount例子里,假设map的输入数据都是像“aaa”这样的字符串。
-
在经过mapper的运行后,我们得知mapper的输出是这样一个key/value对: key是“aaa”, value是数值1。因为当前map端只做加1的操作,在reduce task里才去合并结果集。前面我们知道这个job有3个reduce task,到底当前的“aaa”应该交由哪个reduce去做呢,是需要现在决定的。
MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认对key hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。
在我们的例子中,“aaa”经过Partitioner后返回0,也就是这对值应当交由第一个reducer来处理。接下来,需要将数据写入内存缓冲区中,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。我们的key/value对以及Partition的结果都会被写入缓冲区。当然写入之前,key与value值都会被序列化成字节数组。
整个内存缓冲区就是一个字节数组,它的字节索引及key/value存储结构我没有研究过。如果有朋友对它有研究,那么请大致描述下它的细节吧。
- 这个内存缓冲区是有大小限制的,默认是100MB。当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写,字面意思很直观。这个溢写是由单独线程来完成,不影响往缓冲区写map结果的线程。溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。
在这里我们可以想想,因为map task的输出是需要发送到不同的reduce端去,而内存缓冲区没有对将发送到相同reduce端的数据做合并,那么这种合并应该是体现是磁盘文件中的。从官方图上也可以看到写到磁盘中的溢写文件是对不同的reduce端的数值做过合并。所以溢写过程一个很重要的细节在于,如果有很多个key/value对需要发送到某个reduce端去,那么需要将这些key/value值拼接到一块,减少与partition相关的索引记录.
在针对每个reduce端而合并数据时,有些数据可能像这样:“aaa”/1, “aaa”/1。对于WordCount例子,就是简单地统计单词出现的次数,如果在同一个map task的结果中有很多个像“aaa”一样出现多次的key,我们就应该把它们的值合并到一块,这个过程叫reduce也叫combine。但MapReduce的术语中,reduce只指reduce端执行从多个map task取数据做计算的过程。除reduce外,非正式地合并数据只能算做combine了。其实大家知道的,MapReduce中将Combiner等同于Reducer.
如果client设置过Combiner,那么现在就是使用Combiner的时候了。将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用。那哪些场景才能使用Combiner呢?从这里分析,Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以从我的想法来看,Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。Combiner的使用一定得慎重,如果用好,它对job执行效率有帮助,反之会影响reduce的最终结果。
- 每次溢写会在磁盘上生成一个溢写文件,如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个溢写文件存在。当map task真正完成时,内存缓冲区中的数据也全部溢写到磁盘中形成一个溢写文件。最终磁盘中会至少有一个这样的溢写文件存在(如果map的输出结果很少,当map执行完成时,只会产生一个溢写文件),因为最终的文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做Merge。Merge是怎样的?如前面的例子,“aaa”从某个map task读取过来时值是5,从另外一个map 读取时值是8,因为它们有相同的key,所以得merge成group。什么是group。对于“aaa”就是像这样的:{“aaa”, [5, 8, 2, …]},数组中的值就是从不同溢写文件中读取出来的,然后再把这些值加起来。请注意,因为merge是将多个溢写文件合并到一个文件,所以可能也有相同的key存在,在这个过程中如果client设置过Combiner,也会使用Combiner来合并相同的key。
至此,map端的所有工作都已结束,最终生成的这个文件也存放在TaskTracker够得着的某个本地目录内。每个reduce task不断地通过RPC从JobTracker那里获取map task是否完成的信息,如果reduce task得到通知,获知某台TaskTracker上的map task执行完成,shuffle的后半段过程开始启动。
ReduceTask具体执行流程
简单地说,reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge,也最终形成一个文件作为reduce task的输入文件。见下图:
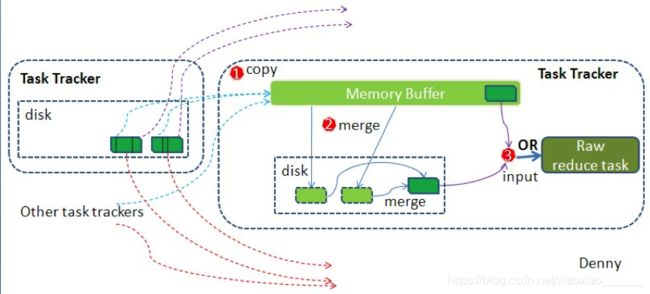
如map 端的细节图,shuffle在reduce端的过程也能用图上标明的三点来概括。reducer真正运行之前,所有的时间都是在拉取数据,做merge,且不断重复地在做。如前面的方式一样,下面我也分段地描述reduce 端的shuffle细节:
- Copy过程,简单地拉取数据
reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
每个reduce task都会有一个后台进程GetMapCompletionEvents,它获取heartbeat中(从JobTracker)传过来的已经完成的task列表,并将与该reduce task对应的数据位置信息保存到mapLocations中,mapLocations中的数据位置信息经过滤和去重(相同的位置信息因为某种原因,可能发过来多次)等处理后保存到集合scheduledCopies中,然后由几个拷贝线程(默认为5个)通过HTTP并行的拷贝数据,同时线程InMemFSMergeThread和LocalFSMerger会对拷贝过来的数据进行归并排序。
- Merge阶段
这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为shuffle阶段reducer不运行,所以应该把绝大部分的内存都给shuffle用。这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,是吧。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
- Reducer的输入文件
不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为reducer的输入,但默认情况下,这个文件是存放于磁盘中的。至于怎样才能让这个文件出现在内存中,之后的性能优化篇我再说。当reducer的输入文件已定,整个shuffle才最终结束。然后就是reducer执行,把结果放到HDFS上。
Hadoop处理流程中的两个子阶段严重降低了其性能。第一个是map阶段产生的中间结果要写到磁盘上,这样做的主要目的是提高系统的可靠性,但代价是降低了系统的性能,实际上,Hadoop的改进版–MapReduce Online去除了这个阶段,而采用其他更高效的方式提高系统可靠性;另一个是shuffle阶段采用HTTP协议从各个map task上远程拷贝结果,这种设计思路(远程拷贝,协议采用http)同样降低了系统性能。实际上,Baidu公司正试图将该部分代码替换成C++代码来提高性能。
主要有两个方面影响shuffle阶段的性能:(1)数据完全是远程拷贝(2)采用HTTP协议进行数据传输。对于第一个方面,如果采用某种策略(修改框架),让你reduce task也能有locality就好了;对于第二个方面,用新的更快的数据传输协议替换HTTP,也许能更快些,如UDT协议
宏观上,Hadoop每个作业要经历两个阶段:Map phase和reduce phase。对于Map phase,又主要包含四个子阶段:从磁盘上读数据-》执行map函数-》combine结果-》将结果写到本地磁盘上;对于reduce phase,同样包含四个子阶段:从各个map task上读相应的数据(shuffle)-》sort-》执行reduce函数-》将结果写到HDFS中。
combiner函数
集群的可用带宽本来就很稀缺,因此在不影响结果数据的前提下,尽可能的减少磁盘IO和网络传输,是非常合适的。Hadoop允许用户针对map任务的输出指定一个combiner函数(其实是一个运行在map端的reduce函数),用于优化MR的执行效率。
–1. 意义:就是在shuffle阶段,尽可能的减少磁盘IO和网络IO
–2. 运行时机:排序后溢写时
(1) 在环形缓冲区排序后溢写前
(2) 溢写文件比较多,归并排序后,形成最终一个临时文件前,注意如果溢写文件个数小于<3,就不会调用
(3) reduce阶段的归并排序如果产生溢写文件,那就是在归并排序后,溢写前
–3. 本质:其实就是运行在shuffle阶段的reduce函数,父类就是Reducer。
–4. 注意事项:使用combiner函数可以,但是不能影响最终结果
(1)类似求最大值,最小值,求和等操作时可以的
(2)求平均值,不可以,因为可能会影响结果。
–5. 定义后,使用job.setCombinerClass(xxxxxxxx.class);
–6. Combiner是一种优化组件
特点总结:
1. Combiner是MR程序中Mapper和Reduce之外的一种组件
2. Combiner组件的父类就是Reducer
3. Combiner和Reducer之间的区别在于运行的位置
4. Reduce阶段的Reducer是每一个接收全局的Map Task 所输出的结果
5. Combiner是在合并排序后运行的。因此map端和reduce端都可以调用此函数。
6. Combiner的存在就是提高当前网络IO传输的性能,是MapReduce的一种优化手段。
7. Combiner在驱动类中的设置:
job.setCombinerClass(MyCombiner.class);
注意:combiner不適合做求平均值这类需求,很可能就影响了结果。
mapTask: 1 2 3 4 reduectTask 1 2 3 4
mapTask 3 4 2 5 3 4 2 5 reduce函数寻找最大值,5
如果指定了combiner函数
mapTask: 1 2 3 4 排序后会运行combiner 找最大值 4 reduectTask
mapTask 3 4 2 5 排序后会运行combiner 找最大值 5 reduce函数寻找最大值,5
mapTask: 1 2 3 4 5 reduce 1 2 3 4 5 3 4 2 5 平均值29/ 9= 3.222
mapTask 3 4 2 5
mapTask: 1 2 3 5 4 指定combiner 3
mapTask 3 4 2 5 3.5 3.25
yarn资源管理器
mapredcue1.x版本
- 在Hadoop1.x时,只有HDFS和MapReduce两个模块
- MapReduce在作业运行中,有两个组件JobTracker和TaskTracker. 这两个组件负责资源的调度和监听,汇报等工作,还没有yarn框架的概念
- JobTracker负责:
–1. 作业提交后的资源调度
–2. 与TaskTracker通信并为mapTask和reduceTask分配资源
–3. 监听所有作业和所有任务的执行情况 - TaskTracker负责:
–1. 运行相应的mapTask或者是reduceTask
–2. 向jobTracker汇报运行状态信息。
yarn的简介和设计思想
什么是yarn?
–1. 为了解决MapReduce1.x框架功能的繁冗(又做计算分析,又做资源管理)及其不足,团队提供了一个全新的资源管理系统框架,被称之为YARN
–2. YARN是Hadoop2.x里的核心模块之一,是一个资源管理系统,负责为计算框架分配资源,相当于分布式的操作系统
–3. 由于具有通用性,所以也可以为spark,tez等计算框架分配资源
yarn的设计思想
–1. 整个资源管理系统中的功能如资源分配,作业调度,作业监控都设计成独立的子进程
–2. 包含一个常驻的全局资源管理器:resourcemanager
–3. 每一个计算程序对应一个applicationmaster
–4. 每一个节点都有一个常住的守护进程NodeManager
–5. 资源被称为container(cpu,内存,磁盘,网络等)
与MapReduce1.x的比较
resourcemanager + applicationmaster+timelineserver 相当于1.x里的jobtracker
nodemanager 相当于1.x里的tasktracker
container 相当于slot
yarn的三种调度器
fifo调度器
–1. 调度器维护一个队列,会将所有提交的作业放入这个队列中,然后队列中的任务一一执行,前面的执行完毕,后面才开始执行
–2. 优点:简单,不需要配置
–3. 缺点:每一个作业都会占有集群上的所有资源,比如有一个小作业可能执行1分钟就结束,但是前面有一个大作业要执行半小时,所以这个小作业要等待半小时,而不是小作业一提交就执行。
容量调度器(capacity)
–1. 调度器维护了两个队列,其中一个队列用于存储小作业,保证小作业已提交就立即执行。
–2. 此调度器会预留集群上的一些资源给小作业,即使没有小作业,这一部分资源也是空闲的,所有大作业在提交后,即使没有小作业,也不能使用集群上的全部资源,所以运行时间会较长
–3. YARN默认使用的调度器就是容量调度器
公平调度器(fair)
–1. 目的是为所有的作业尽可能的公平分配集群上的资源。
–2. 当集群上只有一个作业提交时,这个作业会占用所有资源
–3. 当集群上再有作业提交时,正在运行的作业会腾出一部分资源给刚刚提交的作业,保证了所有的作业都在提交后就直接执行,没有等待状态。
job提交流程
- 调用waitForCompletion方法每秒轮询作业的进度,内部封装了submit()方法,用于创建JobCommiter实例,
并且调用其的submitJobInternal方法。提交成功后,如果有状态改变,就会把进度报告到控制台。错误也会报告到
控制台 - JobCommiter实例会向ResourceManager申请一个新应用ID,用于MapReduce作业ID。这期间JobCommiter也会进行检查输出路径的情况,以及计算输入分片。
- 如果成功申请到ID,就会将运行作业所需要的资源(包括作业jar文件,配置文件和计算所得的输入分片元数据文件)上传到一个用ID命名的目录下的HDFS上。此时副本个数默认是10.
- 准备工作已经做好,再通知ResourceManager调用submitApplication方法提交作业。
- ResourceManager调用submitApplication方法后,会通知Yarn调度器(Scheduler),调度器分配一个容器,在节点管理器的管理下在容器中启动 application master进程。
- application master的主类是MRAppMaster,其主要作用是初始化任务,并接受来自任务的进度和完成报告。
- 然后从HDFS上下载资源,主要是split和计算程序。然后为每一个split创建MapTask以及参数指定的ReduceTask,任务ID在此时分配
- 然后Application Master会向资源管理器请求容器,首先为MapTask申请容器,然后再为ReduceTask申请容器。(5%)
- 一旦ResourceManager中的调度器(Scheduler),为Task分配了一个特定节点上的容器,Application Master就会与NodeManager进行通信来启动容器。
- 运行任务是由YarnChild来执行的,运行任务前,先将资源本地化(jar文件,配置文件,缓存文件)
- 然后开始运行MapTask或ReduceTask。
- 当收到最后一个任务已经完成的通知后,application master会把作业状态设置为success。然后Job轮询时,知道成功完成,就会通知客户端,并把统计信息输出到控制台
hadoop的压缩机制
Hadoop中的压缩体现在三个地方
–1. 要分析计算的文件是否为压缩文件
–2. MapTask产生的临时文件是否要压缩
–3. ReduceTask产生的文件是否要压缩
要分析计算的文件为压缩文件时
–1. 如果这个压缩格式,不支持切分,那么这个文件在HDFS上即使有100个块,也只有一个InputSplit,也就是说只有一个MapTask,势必会产生网络IO。
–2. 支持切分的压缩格式只有bzip2, 还有一种叫LZO,但是LZO压缩文件必须提前建立索引才可以
MapTask产生的临时文件压缩时
–1. 优势是产生磁盘IO和网络IO
–2. 既然是临时文件,那么压缩算法就不应该太复杂(太复杂会带来CPU的性能开销特别大)
所以要使用cpu性能开销比较低的压缩算法,比如snappy
–3. MapTask默认是没有开启压缩的,如果想要开启,需要修改配置,默认的压缩算法为deflate
ReduceTask产生的文件压缩时
–1. 目的就是减少HDFS上磁盘空间
–2. 默认是没有开启,想要开启需要修改配置
MapReduce的案例
奇数偶数和的统计
a.txt文件的内容如下,写一个mr程序,统计奇数的和与个数,以及偶数的和与个数
10
20
234
10
23
15
21
123
10
3
4
5
2
3
10
打印效果如下:
奇数 193 7
偶数 300 8
package com.xx;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class OddAndEvenSum {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf =new Configuration();
Job job = Job.getInstance(conf, "OddAndEvenSum");
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputValueClass(Text.class);
FileSystem fileSystem = FileSystem.get(conf);
Path out=new Path("F:\\Hadoop\\Phase02-04-Mapreduce\\day02\\output");
if (fileSystem.exists(out)){
fileSystem.delete(out, true);
}
job.setJarByClass(OddAndEvenSum.class);
FileInputFormat.setInputPaths(job, new Path("F:\\Hadoop\\Phase02-04-Mapreduce\\day02\\OddAndEvenSumDataSource.txt"));
FileOutputFormat.setOutputPath(job, out);
boolean b = job.waitForCompletion(true);
System.out.println(b);
}
static class MyMapper extends Mapper<LongWritable, Text,Text, IntWritable>{
Text k2=new Text();
IntWritable v2 =new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
int num = Integer.parseInt(value.toString());
if (num%2==0){
k2.set("偶数");
}else
k2.set("奇数");
v2.set(num);
context.write(k2, v2);
}
}
static class MyReducer extends Reducer<Text,IntWritable,Text,Text>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
int count=0;
for (IntWritable value : values) {
sum+=value.get();
count++;
}
context.write(key, new Text(sum+"\t"+count));
}
}
}
奇数行和偶数行的和的统计
自定义FileInputFormat
案例需求:统计奇数行的sum和偶数行的sum,数据
f1.txt
12
13
24
123
234
56
1
35
6
使用默认的输入规则TextInputFormat不能完成上述需求
案例分析:
- k1不再是行偏移量,让其成为行号:1,2,3,4,5
- v1是行数据
- 数据扭转
1 12 奇数,[12,24,234,…] 奇数:total
2 13 偶数,[13,123,56,…] 偶数:total
3 24
…
package com.xx;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.LineReader;
import java.io.IOException;
/**
* - k1不再是行偏移量,让其成为行号:1,2,3,4,5
* - v1是行数据
* - 数据扭转
* -->map--> -->reduce-->
* 1 12 奇数,[12,24,234,...] 奇数:total
* 2 13 偶数,[13,123,56,...] 偶数:total
* 3 24
* .....
*
* 如果想要完成上述需求,那么需要重新定义输入规则,也就是重写输入规则
*/
public class OddLineEvenLineSum {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "OddLineEvenLineSum");
job.setJarByClass(OddLineEvenLineSum.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setInputFormatClass(com.xx.MyOddLineEvenLineInputFormat.class);
Path path = new Path("F:\\qianfeng2\\Hadoop\\Phase02-04-Mapreduce\\day03\\output");
FileSystem fileSystem = FileSystem.get(conf);
if (fileSystem.exists(path)) {
fileSystem.delete(path, true);
}
FileInputFormat.setInputPaths(job, new Path("F:\\qianfeng2\\Hadoop\\Phase02-04-Mapreduce\\day03\\datasource.txt"));
FileOutputFormat.setOutputPath(job, path);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
Text k2 = new Text();
LongWritable v2 = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if (key.get() % 2 == 0) {
k2.set("偶数");
} else
k2.set("奇数");
v2.set(Long.parseLong(value.toString()));
context.write(k2, v2);
}
}
class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
LongWritable v3 = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for (LongWritable value : values) {
sum += value.get();
}
v3.set(sum);
context.write(key, v3);
}
}
class MyOddLineEvenLineRecordReader extends RecordReader<LongWritable, Text> {
private long start;
private long end;
private LineReader in;
private FSDataInputStream fileIn;
private LongWritable key;
private Text value;
private Path path;
private long lineNum;
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
//获取子类型对象
FileSplit split1 = (FileSplit) split;
//取出分片的偏移量给start赋值
start = split1.getStart();
//计算出分片对应的原始数据的结束位置
end = start + split1.getLength();
//为path赋值
path = split1.getPath();
//获取流对象,要先获得分布式文件系统对象,获取配置文件对象
Configuration conf = context.getConfiguration();
FileSystem fileSystem = FileSystem.get(conf);
//分布式文件系统对象必须打开一个文件才能获取到流对象
fileIn = fileSystem.open(path);
//设置从哪里开始读
fileIn.seek(start);
//为in赋值,其实可以用fileIn读取文件,但是LineReader提供了readLine方法,故使用LineReader
in = new LineReader(fileIn);
//初始化key
key = new LongWritable();
//初始化value
value = new Text();
//为lineNum赋值
lineNum = 1;
}
/**
* nextKeyValue方法才是真正读数据的
*
* @return
* @throws IOException
* @throws InterruptedException
*/
@Override
public boolean nextKeyValue() throws IOException {
//第一行时,lineNum是1
key.set(lineNum);
//为读下一行做准备
lineNum++;
if (in.readLine(value)>0) {
return true;
} else
return false;
}
@Override
public LongWritable getCurrentKey() throws IOException, InterruptedException {
return key;
}
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return 0;
}
@Override
public void close() throws IOException {
in.close();
}
}
/**
* 自定义一个输入规则
* K1: 行号 LongWritable
* V1: 行记录 Text
*/
class MyOddLineEvenLineInputFormat extends FileInputFormat<LongWritable, Text> {
@Override
public RecordReader<LongWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
return new MyOddLineEvenLineRecordReader();
}
/**
* 要处理的文件是否支持切分
*
* @param context
* @param file
* @return
*/
@Override
protected boolean isSplitable(JobContext context, Path file) {
return true;
}
}
小文件的处理
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
*
*
* 如果一个job要处理的文件中,有很多小文件存在,那么势必会有很多个MapTask。管理作业的时间就会决定着整个作业的完成时间。
* 相对来说,分析时间的比例就大大降低了。所以,不符合的设计需求。
*
* 因此我们在进行作业前,可以先将小文件合并成大文件,然后再进行作业。
*
* 小文件的优化无非以下几种方式:
* 在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS
* 在业务处理之前,在HDFS上使用mapreduce程序对小文件进行合并
* 在mapreduce处理时,可采用combineInputFormat提高效率
*
*
* 这次使用第二种方式,先将小文件合并成大文件。
* 文件1:
* 1901xxxxx
* 1901xxxxx
* .......
* 文件2:
* 1902xxxxx
* 1902xxxxx
* .......
* 文件3:
* 1903xxxxx
* 1903xxxx
* ......
*
*
*
* 0,1901xxxxx
* 128,1901xxxxx------>reduce(128, 1901xxxx,1902xxxxx)
* ..,.....
* 0, 1901
* 0, 1902
* 0, 1903
* 128 1901xxxx
* 128 1902xxxxx
*
*
*
*
*
* 分析:
* k1,v1 ------>k2,v2 ------>k3,v3
* 多个Maptask ---->1个reduceTask
*
*
* mapTask负责一行一行的读取,这一行一行数据封装成v1,然后作为v2,传递给reduceTask的reduce里的list
* 写的时候只需要将list循环写出去即可。
*
* 1901xxxxx
* 1901xxxx
* ......
* 1902xxxx
* ......
* 1903xxxx
*
* 这种方式,因为行偏移量一直是K, k1,k2,k3.所以不能保证每一个小文件里的数据在新文件中时紧凑的。
*
*
* 如何让每个小文件的数据在新文件中是紧凑的。
*
* 方法如下: 重写输入规则,一个v1封装一个小文件里的所有的数据。有31文件,就有31个v1,此时无需考虑k.
*
* 注意:默认使用的输入规则是TextInputFormat类型
*
*/
public class MergeDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,"merge");
// job.setMapperClass(MergeMapper.class);
// job.setReducerClass(MergeReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
//设置输入规则:
job.setInputFormatClass(MergeFileInputFormat.class);
FileInputFormat.addInputPath(job,new Path("D:\\academia\\The teaching material\\The required data\\data-mr\\ncdc1")); //使用main方法的形式参数当成路径,非常灵活,用的时候可以很灵活的赋值路径
Path outputPath = new Path("D:/mergeoutput");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outputPath)){
fs.delete(outputPath,true);
}
FileOutputFormat.setOutputPath(job,outputPath);//使用args参数的第二个元素充当输出路径,灵活
//提交作业
System.exit(job.waitForCompletion(true)?0:1);
}
}
//class MergeMapper extends Mapper{
// @Override
// protected void map(NullWritable key, Text value, Context context) throws IOException, InterruptedException {
// context.write(key,value);
// }
//}
//class MergeReducer extends Reducer{
// @Override
// protected void reduce(NullWritable key, Iterable values, Context context) throws IOException, InterruptedException {
// for (Text value : values) {
// context.write(NullWritable.get(),value);
// }
// }
//}
/**
* 重写输入规则,用来读取k1,v1
*
* k1是NullWritable ,因为我们不需要k1
* v1是整个小文件的所有的数据,因此是Text类型
*/
class MergeFileInputFormat extends FileInputFormat<NullWritable, Text> {
@Override
public RecordReader<NullWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
return new MergeRecordReader();
}
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
}
class MergeRecordReader extends RecordReader<NullWritable, Text>{
private FSDataInputStream fileIn;
private NullWritable key;
private Text value;
private FileSplit fileSplit;
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
//获取真正要读取的文件路径
fileSplit= (FileSplit) split;
Path path = fileSplit.getPath();
//获取分布式文件系统对象
Configuration conf = context.getConfiguration();
FileSystem fileSystem = FileSystem.get(conf);
fileIn = fileSystem.open(path);
//给v1初始化
value = new Text();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
try{
//此方法用于读取文件的数据,封装成k1,v1
byte[] content = new byte[(int) fileSplit.getLength()];
//利用工具类IOUtils的readFully方法,将输入流里的字节存储到字节数组中
IOUtils.readFully(fileIn,content,0,content.length);
//再讲字节数组封装到v1上
value.set(content,0,content.length);
}catch (Exception e){
IOUtils.closeStream(fileIn);
//返回false 表明没有数据。
return false;
}
//返回true,表明还有数据要读取
return true;
}
@Override
public NullWritable getCurrentKey() throws IOException, InterruptedException {
return NullWritable.get();
}
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return 0;
}
@Override
public void close() throws IOException {
}
}
TopN
package com.xx;
/*
数据格式如下:
{"movie":"1193","rate":"5","datetime":"978300760","uid":"1"}
{"movie":"661","rate":"3","datetime":"978302109","uid":"1"}
{"movie":"914","rate":"3","datetime":"978301968","uid":"1"}
{"movie":"3408","rate":"4","datetime":"978300275","uid":"1"}
{"movie":"2355","rate":"5","datetime":"978824291","uid":"1"}
{"movie":"1197","rate":"3","datetime":"978302268","uid":"1"}
{"movie":"1287","rate":"5","datetime":"978302039","uid":"1"}
{"movie":"2804","rate":"5","datetime":"978300719","uid":"1"}
{"movie":"594","rate":"4","datetime":"978302268","uid":"1"}
{"movie":"919","rate":"4","datetime":"978301368","uid":"1"}
{"movie":"595","rate":"5","datetime":"978824268","uid":"1"}
{"movie":"938","rate":"4","datetime":"978301752","uid":"1"}
{"movie":"2398","rate":"4","datetime":"978302281","uid":"1"}
*/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.codehaus.jackson.map.ObjectMapper;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class TopN {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "max");
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(MovieWritable.class);
FileInputFormat.addInputPath(job, new Path("F:\\Hadoop\\Phase02-04-Mapreduce\\day02\\rating.json"));
Path output = new Path("F:\\Hadoop\\Phase02-04-Mapreduce\\day02\\tobNOutput");
FileSystem fileSystem = FileSystem.get(conf);
if (fileSystem.exists(output)) {
fileSystem.delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
//提交程序
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
class MyMapper extends Mapper<LongWritable, Text, LongWritable, MovieWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
ObjectMapper objectMapper = new ObjectMapper();
/**
* readValue(String json,Class class)
* 这个方法是将json字符串的键值对进行解析,如果指定的类中的属性有和解析出来的某一个key相同,那么就会将这个key对应的value只赋值给类中的属性
*/
MovieWritable movieWritable = objectMapper.readValue(value.toString(), MovieWritable.class);
//取出uid封装成k2
LongWritable k2 = new LongWritable(movieWritable.getUid());
context.write(k2, movieWritable);
}
}
class MyReducer extends Reducer<LongWritable, MovieWritable, LongWritable, MovieWritable> {
@Override
protected void reduce(LongWritable key, Iterable<MovieWritable> values, Context context) throws IOException, InterruptedException {
List<MovieWritable> list = new ArrayList<>();
for (MovieWritable value : values) {
//取值,重新封装(因为hadoop中的迭代器是将迭代器对象的地址赋值给新集合中的元素,所以最后遍历集合时会出现新集合中所有元素都是同一个
// ,即旧集合中的最后一个元素)
MovieWritable movieWritable = new MovieWritable(value.getUid(), value.getMovie(), value.getRate(), value.getDatetime());
list.add(movieWritable);
}
//用集合工具类进行排序
Collections.sort(list);
for (int i = 0; i < 10; i++) {
MovieWritable aa = list.get(i);
context.write(key, aa);
}
}
}
class MovieWritable implements WritableComparable<MovieWritable> {
private long uid;
private long movie;
private long rate;
private long datetime;
public MovieWritable() {
}
public MovieWritable(long uid, long movie, long rate, long datetime) {
this.uid = uid;
this.movie = movie;
this.rate = rate;
this.datetime = datetime;
}
public long getUid() {
return uid;
}
public void setUid(long uid) {
this.uid = uid;
}
public long getMovie() {
return movie;
}
public void setMovie(long movieId) {
this.movie = movieId;
}
public long getRate() {
return rate;
}
public void setRate(long rate) {
this.rate = rate;
}
public long getDatetime() {
return datetime;
}
public void setDatetime(long datetime) {
this.datetime = datetime;
}
@Override
public int compareTo(MovieWritable o) {
return (int) (o.getRate() - this.getRate());
}
@Override
public String toString() {
return uid + "\t"+movie +
"\t" + rate ;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(uid);
out.writeLong(movie);
out.writeLong(rate);
out.writeLong(datetime);
}
@Override
public void readFields(DataInput in) throws IOException {
uid = in.readLong();
movie = in.readLong();
rate = in.readLong();
datetime = in.readLong();
}
}
二次排序
package com.qf.mr.secondsort;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.codehaus.jackson.map.ObjectMapper;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* 二次排序: 先按照某一个字段进行排序(升序或者降序),如果相同,再按照第二个字段排序
*
* 案例演示: 所有电影信息排序:
* 先按照uid降序,如果相同,再按照电影id升序排序。
*
*
* 注意:如果想要使用reduce阶段,在reduce里的集合中排序,那么所有的电影应该在同一个集合里。
*
*
*/
public class MovieDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "max");
job.setMapperClass(MovieMapper.class);
job.setReducerClass(MovieReducer.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(MovieBean.class);
FileInputFormat.addInputPath(job,new Path("D:\\academia\\The teaching material\\The required data\\data-mr\\topn"));
Path output = new Path("D:/output");
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(output)){
fileSystem.delete(output,true);
}
FileOutputFormat.setOutputPath(job,output);
//提交程序
System.exit(job.waitForCompletion(true)?0:1);
}
}
class MovieMapper extends Mapper<LongWritable, Text,LongWritable, MovieBean> {
/**
*
* @param key
* @param value 是json字符串 {"movi":"2294","rate":"4","datetime":"978824291","uid":"1"}
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
ObjectMapper objectMapper = new ObjectMapper();
/**
* readValue(String json, Class class)
* 将json字符串的键值对,进行解析,如果指定的类型中的属性与解析出来的某一个key相同,那么就将key对应的value值赋值给
* 对应的属性
*/
MovieBean bean = objectMapper.readValue(value.toString(), MovieBean.class);
//取出UID,封装成k2
LongWritable k2 = new LongWritable(9999);
context.write(k2,bean);
}
}
/**
* 既然k2 是四个9. 而这四个9不需要成为k3打印出去,只需要打印电影信息即可,因此K3,我们可以设计为NullWritable
*/
class MovieReducer extends Reducer<LongWritable, MovieBean, NullWritable, MovieBean> {
/**
*
* @param key
* @param values 是同一个用户的所有的MovieBean
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(LongWritable key, Iterable<MovieBean> values, Context context) throws IOException, InterruptedException {
List<MovieBean> list = new ArrayList<MovieBean>();
/**
* 因为hadoop迭代器的底层是使用指针指向某一个元素,当存储到新集合时,所有的元素都是通过指针指向了最后一个元素
* 因此造成了集合的元素是同一个对象
*
* 怎么解决上述问题,只需要在指针指向某一个元素时,将元素身上的属性值取出来再次封装成新对象即可
*/
for (MovieBean value : values) {
//取值,重新封装
MovieBean bean = new MovieBean(value.getUid(),value.getMovie(),value.getRate(),value.getDatetime());
list.add(bean);
}
//调用集合的工具类对list进行排序,底层就会调用comparaTo方法
Collections.sort(list);
//只需要写出前10名
for (int i = 0; i < list.size(); i++) {
MovieBean movieBean = list.get(i);
context.write(NullWritable.get(),movieBean);
}
}
}
class MovieBean implements WritableComparable<MovieBean> {
private long uid;
private long movie;
private long rate;
private long datetime;
public MovieBean(){
}
public MovieBean(long uid, long movie, long rate, long datetime) {
this.uid = uid;
this.movie = movie;
this.rate = rate;
this.datetime = datetime;
}
public long getUid() {
return uid;
}
public void setUid(long uid) {
this.uid = uid;
}
public long getMovie() {
return movie;
}
public void setMovie(long movie) {
this.movie = movie;
}
public long getRate() {
return rate;
}
public void setRate(long rate) {
this.rate = rate;
}
public long getDatetime() {
return datetime;
}
public void setDatetime(long datetime) {
this.datetime = datetime;
}
public String toString(){
return uid+"\t"+movie+"\t"+rate;
}
/**
* 即使当成V2,不需要排序,但是我们想要将对象放入集合中进行排序,那么就必须重新此方法
* @param o
* @return
*
* 升序:
* this - other
* 降序:
* other - this
*/
public int compareTo(MovieBean o) {
int result = (int)(o.getUid() - this.getUid());
if(result ==0 ){
result = (int)(this.getMovie() -o.getMovie());
}
return result;
}
public void write(DataOutput out) throws IOException {
out.writeLong(uid);
out.writeLong(movie);
out.writeLong(rate);
out.writeLong(datetime);
}
public void readFields(DataInput in) throws IOException {
uid = in.readLong();
movie = in.readLong();
rate = in.readLong();
datetime = in.readLong();
}
}
利用shuffle阶段对K2进行排序,来完成二次排序
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.codehaus.jackson.map.ObjectMapper;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 二次排序: 先按照某一个字段进行排序(升序或者降序),如果相同,再按照第二个字段排序
*
* 案例演示: 所有电影信息排序:
* 先按照uid降序,如果相同,再按照电影id升序排序。
*
*
* 利用shuffle阶段对K2进行排序,来完成二次排序
*
*
*/
public class MovieDriver_V2 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "max");
job.setMapperClass(MovieMapper.class);
job.setReducerClass(MovieReducer.class);
job.setOutputKeyClass(MovieBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job,new Path("D:\\academia\\The teaching material\\The required data\\data-mr\\topn"));
Path output = new Path("D:/output");
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(output)){
fileSystem.delete(output,true);
}
FileOutputFormat.setOutputPath(job,output);
//提交程序
System.exit(job.waitForCompletion(true)?0:1);
}
static class MovieMapper extends Mapper<LongWritable, Text,MovieBean, NullWritable> {
/**
*
* @param key
* @param value 是json字符串 {"movi":"2294","rate":"4","datetime":"978824291","uid":"1"}
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
ObjectMapper objectMapper = new ObjectMapper();
/**
* readValue(String json, Class class)
* 将json字符串的键值对,进行解析,如果指定的类型中的属性与解析出来的某一个key相同,那么就将key对应的value值赋值给
* 对应的属性
*/
MovieBean bean = objectMapper.readValue(value.toString(), MovieBean.class);
context.write(bean,NullWritable.get());
}
}
/**
* 既然k2 是四个9. 而这四个9不需要成为k3打印出去,只需要打印电影信息即可,因此K3,我们可以设计为NullWritable
*/
static class MovieReducer extends Reducer<MovieBean, NullWritable,MovieBean, NullWritable> {
/**
*
* @param key
* @param values 是同一个用户的所有的MovieBean
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(MovieBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
static class MovieBean implements WritableComparable<MovieBean> {
private long uid;
private long movie;
private long rate;
private long datetime;
public MovieBean(){
}
public MovieBean(long uid, long movie, long rate, long datetime) {
this.uid = uid;
this.movie = movie;
this.rate = rate;
this.datetime = datetime;
}
public long getUid() {
return uid;
}
public void setUid(long uid) {
this.uid = uid;
}
public long getMovie() {
return movie;
}
public void setMovie(long movie) {
this.movie = movie;
}
public long getRate() {
return rate;
}
public void setRate(long rate) {
this.rate = rate;
}
public long getDatetime() {
return datetime;
}
public void setDatetime(long datetime) {
this.datetime = datetime;
}
public String toString(){
return uid+"\t"+movie+"\t"+rate;
}
/**
* 即使当成V2,不需要排序,但是我们想要将对象放入集合中进行排序,那么就必须重新此方法
* @param o
* @return
*
* 升序:
* this - other
* 降序:
* other - this
*/
public int compareTo(MovieBean o) {
int result = (int)(o.getUid() - this.getUid());
if(result ==0 ){
result = (int)(this.getMovie() -o.getMovie());
}
return result;
}
public void write(DataOutput out) throws IOException {
out.writeLong(uid);
out.writeLong(movie);
out.writeLong(rate);
out.writeLong(datetime);
}
public void readFields(DataInput in) throws IOException {
uid = in.readLong();
movie = in.readLong();
rate = in.readLong();
datetime = in.readLong();
}
}
}
利用shuffle阶段对K2进行排序,来完成二次排序, 并且减少reduce函数的调用次数,也就是减少分组,需要提供分组器
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.codehaus.jackson.map.ObjectMapper;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 二次排序: 先按照某一个字段进行排序(升序或者降序),如果相同,再按照第二个字段排序
*
* 案例演示: 所有电影信息排序:
* 先按照uid降序,如果相同,再按照电影id升序排序。
*
*
* 利用shuffle阶段对K2进行排序,来完成二次排序
* 并且减少reduce函数的调用次数,也就是减少分组,需要提供分组器
*
*
*/
public class MovieDriver_V3 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "max");
job.setMapperClass(MovieMapper.class);
job.setReducerClass(MovieReducer.class);
job.setOutputKeyClass(MovieBean.class);
job.setOutputValueClass(NullWritable.class);
//设置分组器
job.setGroupingComparatorClass(MovieComparator.class);
FileInputFormat.addInputPath(job,new Path("D:\\academia\\The teaching material\\The required data\\data-mr\\topn"));
Path output = new Path("D:/output");
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(output)){
fileSystem.delete(output,true);
}
FileOutputFormat.setOutputPath(job,output);
//提交程序
System.exit(job.waitForCompletion(true)?0:1);
}
static class MovieMapper extends Mapper<LongWritable, Text,MovieBean, NullWritable> {
/**
*
* @param key
* @param value 是json字符串 {"movi":"2294","rate":"4","datetime":"978824291","uid":"1"}
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
ObjectMapper objectMapper = new ObjectMapper();
/**
* readValue(String json, Class class)
* 将json字符串的键值对,进行解析,如果指定的类型中的属性与解析出来的某一个key相同,那么就将key对应的value值赋值给
* 对应的属性
*/
MovieBean bean = objectMapper.readValue(value.toString(), MovieBean.class);
context.write(bean,NullWritable.get());
}
}
/**
* 既然k2 是四个9. 而这四个9不需要成为k3打印出去,只需要打印电影信息即可,因此K3,我们可以设计为NullWritable
*/
static class MovieReducer extends Reducer<MovieBean, NullWritable,MovieBean, NullWritable> {
/**
*
* @param key
* @param values 是同一个用户的所有的MovieBean
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(MovieBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
for (NullWritable value : values) {
context.write(key,NullWritable.get());
}
}
}
static class MovieBean implements WritableComparable<MovieBean> {
private long uid;
private long movie;
private long rate;
private long datetime;
public MovieBean(){
}
public MovieBean(long uid, long movie, long rate, long datetime) {
this.uid = uid;
this.movie = movie;
this.rate = rate;
this.datetime = datetime;
}
public long getUid() {
return uid;
}
public void setUid(long uid) {
this.uid = uid;
}
public long getMovie() {
return movie;
}
public void setMovie(long movie) {
this.movie = movie;
}
public long getRate() {
return rate;
}
public void setRate(long rate) {
this.rate = rate;
}
public long getDatetime() {
return datetime;
}
public void setDatetime(long datetime) {
this.datetime = datetime;
}
public String toString(){
return uid+"\t"+movie+"\t"+rate;
}
/**
* 即使当成V2,不需要排序,但是我们想要将对象放入集合中进行排序,那么就必须重新此方法
* @param o
* @return
*
* 升序:
* this - other
* 降序:
* other - this
*/
public int compareTo(MovieBean o) {
int result = (int)(o.getUid() - this.getUid());
if(result ==0 ){
result = (int)(this.getMovie() -o.getMovie());
}
return result;
}
public void write(DataOutput out) throws IOException {
out.writeLong(uid);
out.writeLong(movie);
out.writeLong(rate);
out.writeLong(datetime);
}
public void readFields(DataInput in) throws IOException {
uid = in.readLong();
movie = in.readLong();
rate = in.readLong();
datetime = in.readLong();
}
}
/**
* 之前的分组是1000209组,
* 想要重新分组,按照uid分组,可以划分为6040组
*/
public static class MovieComparator extends WritableComparator{
/**
* 分组器的编写,可以重新定义分组的比较规则,默认情况下分组比较规则依然调用的是WritableComparable的comparaTo方法
*
* 构造器调用两个参数,第一个参数,是比较对象的类对象,第二个参数true表示创建实例。
*/
public MovieComparator(){
super(MovieBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
MovieBean aMovieBean = (MovieBean) a;
MovieBean bMovieBean = (MovieBean) b;
return (int)(aMovieBean.getUid() - bMovieBean.getUid());
}
}
}
分组器的应用
reduce-join
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/**
* reduce - join :
* 原理就是:对不同文件的数据进行打标记,然后在reduce端进行笛卡尔积组合
* 缺点: 所有的数据都会被传输到reduce阶段,在reduce阶段进行笛卡尔积组合,性能比较低。
*
*
* emp dept
* smith 1000 10 10 sales shanghai
* john 2000 20 20 clerk beijing
* jack 2000 10 30 manager cc
* rose 2000 30 40 k hz
* michael 2000 10
* hanmm 2000 20
* lilei 2000 30
* ironman ,, 2000
*
*
* 查询:做一个内连接:每个员工的信息及其部门信息
*
* smith 1000 10 10 sales shanghai
* jack 2000 10 10 sales shanghai
*
*
*
* john 2000 20 20 clerk beijing
* hanmm 2000 20 20 clerk beijing
*
*
* rose 2000 30 30 manager cc
* lilei 2000 30 30 manager cc
*/
public class ReduceJoinDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,"reduce-join");
job.setMapperClass(ReduceJoinMapper.class);
job.setReducerClass(ReduceJoinReducer.class);
job.setMapOutputValueClass(DataStr.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path("D:\\academia\\The teaching material\\The required data\\data-mysql"));
Path outputPath = new Path("D:/reduce-join-output");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outputPath)){
fs.delete(outputPath,true);
}
FileOutputFormat.setOutputPath(job,outputPath);//使用args参数的第二个元素充当输出路径,灵活
System.exit(job.waitForCompletion(true)?0:1);
}
public static class ReduceJoinMapper extends Mapper<LongWritable, Text,Text,DataStr>{
Text joinkey = new Text();
DataStr dataStr = new DataStr();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
FileSplit fileSplit = (FileSplit)context.getInputSplit();
String path = fileSplit.getPath().toString();
//解析行记录
String[] split = value.toString().split(",");
if (path.contains("emp.txt")){
joinkey.set(split[7]);//获取关联字段进行封装
dataStr.setJoinkey(joinkey.toString());
dataStr.setLabel("1"); // 打标记 1标识emp.txt文件
dataStr.setContent(split[0]+"\t"+split[1]+"\t"+split[2]+"\t"+split[3]+"\t"+split[4]+"\t"+split[5]+"\t"+split[6]);
}else{
joinkey.set(split[0]);
dataStr.setJoinkey(joinkey.toString());
dataStr.setLabel("2");
dataStr.setContent(split[1]+"\t"+split[2]);
}
//写出去
context.write(joinkey,dataStr);
}
}
static class ReduceJoinReducer extends Reducer<Text,DataStr,Text,Text>{
List<DataStr> emp = new ArrayList<DataStr>();
List<DataStr> dept = new ArrayList<DataStr>();
@Override
protected void reduce(Text key, Iterable<DataStr> values, Context context) throws IOException, InterruptedException {
//此时的values是同一个key的多个文件里的行记录,需要分别存储到不同的集合中
Iterator<DataStr> iterator = values.iterator();
while (iterator.hasNext()){
DataStr ds = iterator.next();
if(ds.getLabel().equals("1")){
DataStr ds1 = new DataStr(ds.getJoinkey(),ds.getLabel(),ds.getContent());
emp.add(ds1);
}else{
DataStr ds1 = new DataStr(ds.getJoinkey(),ds.getLabel(),ds.getContent());
dept.add(ds1);
}
}
//进行笛卡尔积的组合
for (DataStr dataStr : emp) {
for (DataStr str : dept) {
context.write(key,new Text(dataStr.getContent()+"\t"+str.getContent()));
}
}
//将集合清空,为了下一组重新笛卡尔积
emp.clear();
dept.clear();
}
}
static class DataStr implements WritableComparable<DataStr>{
private String joinkey;//关联条件的字段
private String label;//标记字段,为了区分开不同文件的行数据
private String content;
public DataStr(){}
public DataStr(String joinkey, String label, String content) {
this.joinkey = joinkey;
this.label = label;
this.content = content;
}
public String getJoinkey() {
return joinkey;
}
public void setJoinkey(String joinkey) {
this.joinkey = joinkey;
}
public String getLabel() {
return label;
}
public void setLabel(String label) {
this.label = label;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public int compareTo(DataStr o) {
return this.joinkey.compareTo(o.getJoinkey());
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(joinkey);
out.writeUTF(label);
out.writeUTF(content);
}
@Override
public void readFields(DataInput in) throws IOException {
joinkey = in.readUTF();
label = in.readUTF();
content = in.readUTF();
}
public String toString(){
return joinkey+"\t"+content;
}
}
}
map-join
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
/**
* map-join的原理:
* 一定要有一个小文件(小表),大小在几十兆以内。利用map端的分布式缓存来提前存储小表中的数据。
* 然后再map函数中进行join,这样join后的数据就会大大减少,从而降低网络IO.
*
*
* map-join效率高于reduce-join.
*
*/
public class MapJoinDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//设置job的mapper类型,reducer没有需要特殊写的逻辑,因此使用默认提供的即可
job.setMapperClass(MapJoinMapper.class);
//设置job的输出类型的泛型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置要先缓存的数据的路径
Path minPath = new Path("D:\\academia\\The teaching material\\The required data\\data-mysql/dept.txt");
/**
* Path对象的toUri方法可以返回一个URI对象
*/
URI uri = minPath.toUri();
/**
* 调用addCacheFile方法添加缓存路径,这个缓存路径是一个URI对象来描述的。
*/
job.addCacheFile(uri);
//设置其他文件的输入路径以及输出路径
FileInputFormat.setInputPaths(job,new Path("D:\\academia\\The teaching material\\The required data\\data-mysql/emp.txt"));
Path outputPath = new Path("D:/map-join-output");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outputPath)){
fs.delete(outputPath,true);
}
FileOutputFormat.setOutputPath(job,outputPath);//使用args参数的第二个元素充当输出路径,灵活
System.exit(job.waitForCompletion(true)?0:1);
}
public static class MapJoinMapper extends Mapper<LongWritable, Text,Text,Text> {
Map<String,String> map = new HashMap<String,String>();
Text value2 = new Text();
//map端join就是在mapTask运行前先将小表的数据读进内存,封装到Hashmap中
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//调用getCacheFiles()返回URI数组,因为就封装了一个路径,所以获取第一个元素,就是我们需要的缓存路径
URI cacheFile = context.getCacheFiles()[0];
String path = cacheFile.getPath();
//使用IO流读取文件即可
BufferedReader br = new BufferedReader(new FileReader(path));
String line = "";
while((line=br.readLine())!=null){
String[] split = line.split(",");
//连接字段作为key,剩下的作为value
map.put(split[0],split[1]+"\t"+split[2]);
}
br.close();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
//判断一下v1中的关联字段在不在map中,如果在,v1应该和map中的对应的value进行组合
if(map.containsKey(split[7])){
//将map中对应的value和v1中的其他数据进行组合,封装成一个Text对象
value2.set(map.get(split[7])+"\t"+value.toString());
}
context.write(new Text(split[7]),value2);
}
}
}