ElasticSearch学习笔记(一)
ElasticSearch学习
环境准备
- JDK 1.8
- Node.js
相关文件
(Windows 练习的话,使用 6.2.2 版本较为稳定, 否则 Kibana 可能会遇到一些启动报错问题)
资源地址:csdn下载
百度云链接:百度网盘下载
提取码:1234
资源包括:
- Elasticsearch 6.2.2
- Kibana 6.2.2
- IK分词器 6.2.2
Elasticsearch-head :暂未遇到版本适配问题,可自行搜索下载。
Doug Cutting

1998年9月4日,Google公司在美国硅谷成立。
正如大家所知,它是一家做搜索引擎起家的公司。

无独有偶,一位名叫Doug Cutting的美国工程师,也迷上了搜索引擎。
他做了一个用于文本搜索的函数库(姑且理解为软件的功能组件),命名为Lucene。

Lucene是用JAVA写成的,目标是为各种中小型应用软件加入全文检索功能。
因为好用而且开源(代码公开),非常受程序员们的欢迎。
早期的时候,这个项目被发布在Doug Cutting的个人网站和SourceForge(一个开源软件网站)。
后来,2001年底,Lucene成为Apache软件基金会 jakarta项目 的一个子项目。

2004年,Doug Cutting再接再励,在Lucene的基础上,和Apache开源伙伴Mike Cafarella合作,开发了一款可以代替当时的主流搜索的开源搜索引擎,命名为Nutch。
Nutch是一个建立在Lucene核心之上的网页搜索应用程序,可以下载下来直接使用。
它在Lucene的基础上加了网络爬虫和一些网页相关的功能,目的就是从一个简单的站内检索推广到全球网络的搜索上,就像Google一样。
Nutch在业界的影响力比Lucene更大。
大批网站采用了Nutch平台,大大降低了技术门槛,使低成本的普通计算机取代高价的Web服务器成为可能。
甚至有一段时间,在硅谷有了一股用Nutch低成本创业的潮流。
随着时间的推移,无论是Google还是Nutch,都面临搜索对象“体积”不断增大的问题。
尤其是Google,作为互联网搜索引擎,需要存储大量的网页,并不断优化自己的搜索算法,提升搜索效率。

在这个过程中,Google确实找到了不少好办法,并且无私地分享了出来。
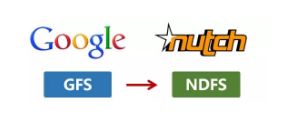
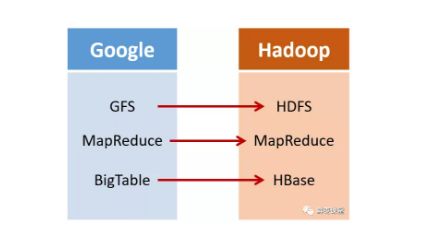
2003年,Google发表了一篇技术学术论文,公开介绍了自己的谷歌文件系统GFS****(Google File System)。这是Google公司为了存储海量搜索数据而设计的专用文件系统。
第二年,也就是2004年,Doug Cutting基于Google的GFS论文,实现了分布式文件存储系统,并将它命名为NDFS(Nutch Distributed File System)。
还是2004年,Google又发表了一篇技术学术论文,介绍自己的MapReduce编程模型。
这个编程模型,用于大规模数据集(大于1TB)的并行分析运算。
第二年(2005年),Doug Cutting又基于MapReduce,在Nutch搜索引擎实现了该功能。

2006年,当时依然很厉害的Yahoo(雅虎)公司,招安了Doug Cutting。

加盟Yahoo之后,Doug Cutting将NDFS和MapReduce进行了升级改造,并重新命名为
Hadoop(NDFS也改名为HDFS,Hadoop Distributed File System)。
这个,就是后来大名鼎鼎的大数据框架系统——Hadoop的由来。
而Doug Cutting,则被人们称为
Hadoop之父

Hadoop这个名字,实际上是Doug Cutting他儿子的黄色玩具大象的名字。
所以,Hadoop的Logo,就是一只奔跑的黄色大象。

我们继续往下说。
还是2006年,Google又发论文了。
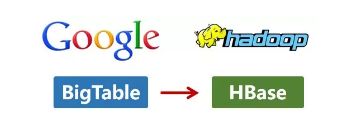
这次,它们介绍了自己的BigTable。
这是一种分布式数据存储系统,一种用来处理海量数据的非关系型数据库。
Doug Cutting当然没有放过,在自己的hadoop系统里面,引入了BigTable,并命名为HBase。
好吧,反正就是紧跟Google时代步伐,你出什么,我学什么。
所以,Hadoop的核心部分,基本上都有Google的影子。
2008年1月,Hadoop成功上位,正式成为Apache基金会的顶级项目。
同年2月,Yahoo宣布建成了一个拥有1万个内核的Hadoop集群,并将自己的搜索引擎产品部署在上面。
7月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,用时209秒。
回到主题
-
Lucene是一套信息检索工具包,并不包含搜索引擎系统,
-
它包含了索引结构、读写索引工具、相关性工具、排序等功能,
-
因此在使用Lucene时仍需要关注搜索引擎系统,例如数据获取、解析、分词等方面的东西
-
为什么要给大家介绍下Lucene呢,因为 solr 和 elasticsearch
-
都是基于该工具包做的一些封装和增强罢了
ElasticSearch概述
-
Elaticsearch,简称为es,
-
es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;
-
本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
-
es也使用Java开发,并使用 Lucene作为其核心来实现所有索引和搜索的功能,
-
但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
据国际权威的数据库产品评测机构DB Engines的统计,在2016年1月,ElasticSearch已超过Solr等,成为排名第一的搜索引擎类应用。
历史
多年前,一个叫做Shay Banon的刚结婚不久的失业开发者,由于妻子要去伦敦学习厨师,他便跟着也去了。在他找工作的过程中,为了给妻子构建一个食谱的搜索引擎,他开始构建一个早期版本的Lucene。
直接基于Lucene工作会比较困难,所以Shay开始抽象Lucene代码以便Java程序员可以在应用中添加搜索功能。他发布了他的第一个开源项目,叫做“Compass”。
后来Shay找到一份工作,这份工作处在高性能和内存数据网格的分布式环境中,因此高性能的、实时 的、分布式的搜索引擎也是理所当然需要的。然后他决定重写Compass库使其成为一个独立的服务叫做 Elasticsearch。
第一个公开版本出现在2010年2月,在那之后Elasticsearch已经成为Github上最受欢迎的项目之一,代码贡献者超过300人。一家主营Elasticsearch的公司就此成立,他们一边提供商业支持一边开发新功
能,不过Elasticsearch将永远开源且对所有人可用。
Shay的妻子依旧等待着她的食谱搜索……
谁在使用:
1、维基百科,类似百度百科,全文检索,高亮,搜索推荐
2、The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
3、Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
4、GitHub(开源代码管理),搜索上千亿行代码
5、电商网站,检索商品
6、日志数据分析,logstash采集日志,ES进行复杂的数据分析,ELK技术, elasticsearch+logstash+kibana
7、商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买
8、BI系统,商业智能,Business Intelligence。比如说有个大型商场集团,BI,分析一下某某区域最近 3年的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表,**区,最近3年,每年消费金额呈现100%的增长,而且用户群体85%是高级白领,开一个新商场。ES执行数据分析和挖掘, Kibana进行数据可视化
9、国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析
(ES热门的一个使用场景)
ES 和 solr 的差别
Elasticsearch简介
-
Elasticsearch是一个实时分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能。
-
它用于全文搜索、结构化搜索、分析以及将这三者混合使用:
维基百科使用 Elasticsearch 提供全文搜索并高亮关键字,以及输入实时搜索(search-asyou-type)和搜索纠错(did-you-mean)等搜索建议功能。
英国卫报使用 Elasticsearch 结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应。
StackOverflow 结合全文搜索与地理位置查询,以及 more-like-this 功能来找到相关的问题和答案。
Github 使用 Elasticsearch 检索1300亿行的代码。
但是Elasticsearch不仅用于大型企业,它还让像 DataDog 以及 Klout 这样的创业公司将最初的想法变成可扩展的解决方案。
Elasticsearch可以在你的笔记本上运行,也可以在数以百计的服务器上处理PB级别的数据 。
Elasticsearch是一个基于Apache Lucene™的开源搜索引擎。
无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
- 但是,Lucene只是一个库。
- 想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,
- 更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
- Elasticsearch 也使用 Java 开发,并使用Lucene作为其核心来实现所有索引和搜索的功能,
- 但是它的目的是通过简单的 RESTful API 来隐藏Lucene的复杂性,从而让全文搜索变得简单。
Solr 简介
- Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。
- Solr提供了比 Lucene 更为丰富的查询语言,
- 同时实现了可配置、可扩展,并对索引、搜索性能进行了优化
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,
Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,
Solr 根据xml文档添加、删除、更新索引。
Solr 搜索:只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。
Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
solr是基于 lucene 开发企业级搜索服务器,实际上就是封装了lucene。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。
用户可以通过 http请求,向搜索引擎服务器提交一定格式的文件,生成索引;
也可以通过提出查找请求,并得到返回结果。
Lucene简介
-
Lucene 是 apache 软件基金会 4 jakarta 项目组的一个子项目,
-
是一个开放源代码的全文检索引擎工具包,
-
但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
-
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
-
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。
-
Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。
-
在Java开发环境里Lucene是一个成熟的免费开源工具。
-
就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。
-
人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
Lucene是一个全文检索引擎的架构。
那什么是全文搜索引擎?
- 全文搜索引擎是名副其实的搜索引擎,国外具代表性的有Google、Fast/AllTheWeb、AltaVista、 Inktomi、Teoma、WiseNut等,国内著名的有百度(Baidu)。
- 它们都是通过从互联网上提取的各个网站的信息(以网页文字为主)而建立的数据库中,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户,因此他们是真正的搜索引擎。
- 从搜索结果来源的角度,全文搜索引擎又可细分为两种,
- 一种是拥有自己的检索程序(Indexer),俗称 “蜘蛛”(Spider)程序或“机器人”(Robot)程序,并自建网页数据库,搜索结果直接从自身的数据库中调用,如上面提到的7家引擎;
- 另一种则是租用其他引擎的数据库,并按自定的格式排列搜索结果,如 Lycos 引擎。
Elasticsearch 和 Solr 比较

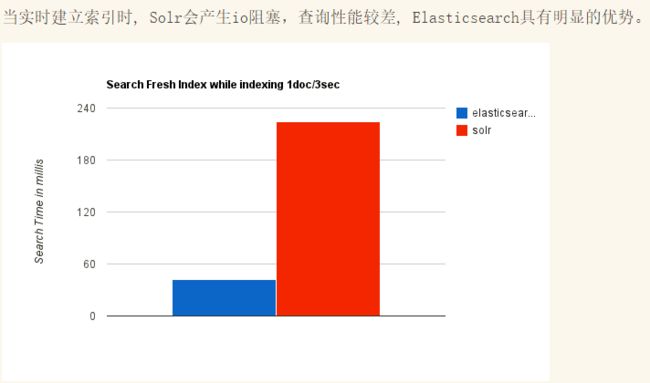
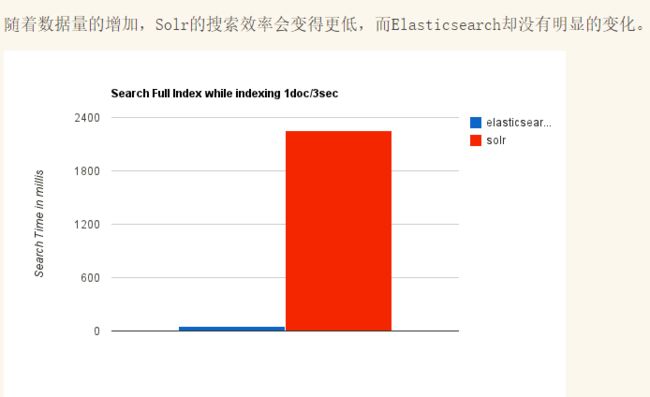

ElasticSearch vs Solr 总结
1、es基本是开箱即用,非常简单。Solr安装略微复杂一丢丢!
2、Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
3、Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持 json 文件格式。
4、Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑
5、Solr 查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;
- ES建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜索。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
6、Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而 Elasticsearch 相对开发维护者较少,更新太快,学习使用成本较高。
ElasticSearch安装
说明
我们需要下载和安装ElasticSearch的【服务端】和【客户端】!
注意:
ElasticSearch是使用java开发的,且本版本的es需要的jdk版本要是1.8以上,
所以安装ElasticSearch 之前保证JDK1.8+安装完毕,并正确的配置好JDK环境变量,否则启动 ElasticSearch 会失败。
下载
ElasticSearch的官方地址: https://www.elastic.co/products/elasticsearch
官方下载地址:https://www.elastic.co/cn/downloads/elasticsearch (很慢,可以下载!)
win下载:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.1.zip

学习的话使用 window 或者 linux 都是可以的,对于我们 java 开发来说没有区别,只是连接的问题!
Windows更加方便一点!所以我们前期都是用 Window 安装使用!后面我们再真正的安装到Linux服务器上跑项目!
window 下安装使用
1、解压window的压缩包!

- bin:启动文件
- config:配置文件
- log4j2.properties:日志配置文件
- jvm.options:java虚拟机的配置
- elasticsearch.yml:es的配置文件
- data:索引数据目录
- lib:相关类库Jar包
- logs:日志目录
- modules:功能模块
- plugins:插件
2、双击ElasticSearch下的bin目录中的elasticsearch.bat启动,控制台显示的日志(等待启动完毕!):
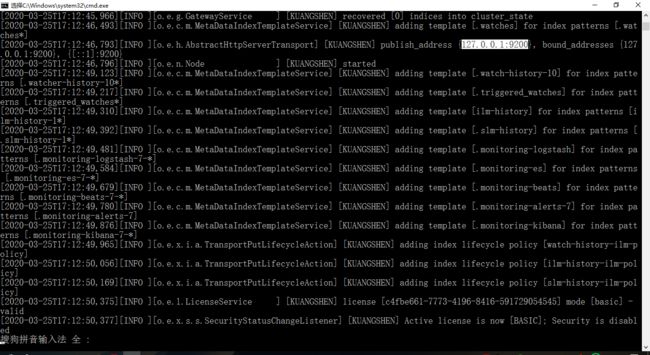
3、然后在浏览器访问:http://localhost:9200 得到如下信息,说明安装成功了:

ES - Head
安装ES的图形化界面插件客户端
elasticsearch-Head 是elasticsearch的集群管理工具,可以用于数据的浏览查询!
地址: https://github.com/mobz/elasticsearch-head/
1、下载 elasticsearch-head-master.zip
2、解压之后安装依赖!
- cnpm install
- npm run start
这将启动在端口9100上运行的本地web服务器,为elasticsearch-head服务!访问测试:

3、由于ES进程和客户端进程端口号不同,存在跨域问题,所以我们要在ES的配置文件中配置下跨域问题:


# 跨域配置:
http.cors.enabled: true
http.cors.allow-origin: "*"
4、重新启动ElasticSearch,使用 head 工具,点击【连接】!

ELK
ELK是 Elasticsearch、Logstash、Kibana 三大开源框架首字母大写简称。
市面上也被成为ElasticStack。
-
其中Elasticsearch是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。
像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用Elasticsearch作为底层支持框架,可见Elasticsearch提供的搜索能力确实强大,市面上很多时候我们简称Elasticsearch为es。
-
Logstash 是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)。
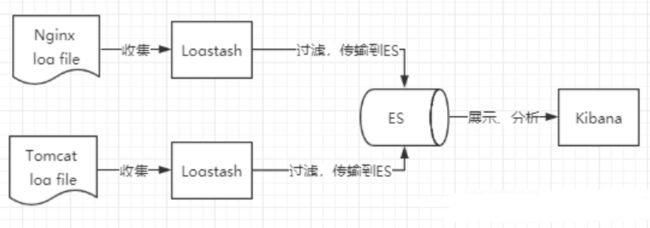
- Kibana可以将 elasticsearch 的数据通过友好的页面展示出来,提供实时分析的功能。
Kibana
- Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。
- 使用Kibana,可以通过各种图表进行高级数据分析及展示。
- Kibana让海量数据更容易理解。
- 它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态。
- 设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动 Elasticsearch索引监测。
官网:https://www.elastic.co/cn/kibana
1、下载Kibana https://www.elastic.co/cn/downloads/kibana (注意版本对应关系)
2、将压缩包解压即可(需要一些时间)!
3、然后进入到bin目录下,启动服务就可以了(需要等待启动完成),ELK基本上都是拆箱即用的
4、然后访问IP:5601,kibana会自动去访问9200,也就是elasticsearch的端口号(当然elasticsearch这个时候必须启动着),然后就可以使用kibana了!
5、现在是英文的,看着有些吃力,我们配置为中文的!
中文包在 kibana\x-pack\plugins\translations\translations\zh-CN.json (每个版本不一样,Kinana 7.6.1 是这样)
# 只需要在配置文件 kibana.yml 中加入
i18n.locale: "zh-CN"
6、重启查看效果!成功切换为中文的了!

ES核心概念
概述
在前面的学习中,我们已经掌握了es是什么,同时也把es的服务已经安装启动,
那么es是如何去存储数据,数据结构是什么,又是如何实现搜索的呢?
先来聊聊ElasticSearch的相关概念吧!
集群,节点,索引,类型,文档,分片,映射是什么?
elasticsearch 是面向文档的,关系行数据库 和 elasticsearch 客观的对比!
| Relational DB (关系型数据库) | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indices)(index) |
| 表(table) | types |
| 行(rows) | documents |
| 字段(列)(columns) | fields |
-
elasticsearch(集群)中可以包含多个索引(数据库),
-
每个索引中可以包含多个类型(表),
-
每个类型下又包含多 个文档(行),
-
每个文档中又包含多个字段(列)。
物理设计:
- elasticsearch 在后台把每个索引划分成多个分片,
- 每个分片可以在集群中的不同服务器间迁移
逻辑设计:
- 一个索引类型中,包含多个文档,比如说文档1,文档2。
- 当我们索引一篇文档时,可以通过这样的一各顺序找到它::
- 索引 → 类型 → 文档ID (对比数据库:库名 → 表名 → 行号)
- 通过这个组合我们就能索引到某个具体的文档。
- 注意:ID不必是整数,实际上它还是个字符串。
文档(Document)
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要属性 :
-
自我包含
- 一篇文档同时包含字段和对应的值,也就是同时包含 key:value!
- 可以是层次型的,一个文档中包含文档,复杂的逻辑实体!
-
灵活的结构
- 文档不依赖预先定义的模式
- 我们知道,关系型数据库中,要创建一个表,需要提前定义字段的类型
- 而在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
-
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,
- 比如一个年龄字段类型,可以是字符串也可以是整形。
- 因为elasticsearch会保存字段和类型之间的映射及其他的设置。
- 这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型(type)
- 类型,是文档的逻辑容器。(类比关系型数据库,表是行的容器)。
- 类型中对于字段的定义称为映射,比如 name 映射为字符串类型。
- 我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,
- 比如新增一个字段,那么elasticsearch是怎么做的呢?
- elasticsearch 会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,
- 如果这个值是18,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对。。。
- 所以最安全的方式就是提前定义好所需要的映射,然后这点跟关系型数据库就一样了:先定义好字段类型,然后再使用表。
索引(index)
- 索引是映射类型的容器,elasticsearch中的索引,是一个非常大的文档集合。
- 索引存储了【映射类型的字段】和其他设置。
- 然后它们被存储到了各个分片上。
我们来研究下分片是如何工作的。
物理设计 :节点和分片 如何工作
-
一个集群至少有一个节点,
-
而一个节点就是一个elasricsearch进程,
-
节点可以有多个索引。
-
默认的,如果你创建索引,那么索引将会由5个分片 ( primary shard ,又称主分片 ) 构成,
-
每一个主分片会有一个副本 ( replica shard ,又称复制分片 )

-
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。
-
实际上,
- 一个分片是一个Lucene索引,一个包含倒排索引的文件目录
- 倒排索引的结构使得 elasticsearch 在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。
倒排索引
elasticsearch 使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。
这种结构适用于快速的全文搜索, 一个索引由文档中所有不重复的列表构成,
对于每一个词,都有一个包含它的文档列表。
例如,现在有两个文档, 每个文档包含如下内容:
# 文档 1 包含内容
Study every day, good good up to forever
# 文档 2 包含内容
To forever study every day, good good up
- 为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),
- 然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档 :
| term(词条) | doc_1(是否存在) | doc_2(是否存在) |
|---|---|---|
| Study | √ | × |
| To | x | √ |
| every | √ | √ |
| forever | √ | √ |
| day | √ | √ |
| study | × | √ |
| good | √ | √ |
| every | √ | √ |
| to | √ | × |
| up | √ | √ |
现在,我们试图搜索 to forever,只需要查看包含每个词条的文档
| term | doc_1 | doc_2 |
|---|---|---|
| to | √ | × |
| forever | √ | √ |
| total(总计) | 2 | 1 |
- 两个文档都匹配,但是第一个文档比第二个匹配程度更高。
- 如果没有别的条件,现在,这两个包含关键字的文档都将返回(并携带一个表示匹配度的数据)。
再来看一个示例,比如我们通过博客标签来搜索博客文章。
那么【倒排索引列表】就是这样的一个结构 :

- 如果要搜索含有 python 标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。
- 只需要查看【标签】这一栏,然后获取相关的文章ID即可。
elasticsearch的索引和Lucene的索引对比
-
在elasticsearch中,索引被分为多个分片,每份分片是一个Lucene的索引。
-
所以一个elasticsearch索引是由多个Lucene索引组成的。
-
elasticsearch 使用 Lucene作为底层!
-
如无特指,索引都是指 elasticsearch的索引(index)。
接下来的一切操作都在 kibana 中 Dev Tools下的 Console里完成。
ES基础操作
IK 分词器插件
什么是IK分词器?
- 分词:
- 即把一段中文或者别的划分成一个个的关键字
- 我们在搜索时候会把搜索信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作
- 默认的中文分词是将每个字看成一个词,比如 “我爱狂神” 会被分为"我",“爱”,“狂”,“神”
- 这显然是不符合要求的,所以我们需要安装【中文分词器ik】来解决这个问题。
IK提供了两个分词算法:ik_smart 和 ik_max_word,
- ik_smart 为【最少】切分
- ik_max_word 为【最细粒度】划分
安装步骤
1、下载ik分词器的包,Github地址:https://github.com/medcl/elasticsearch-analysis-ik/ (版本要对应)
2、下载后解压,并将目录拷贝到ElasticSearch根目录下的 plugins 目录中。

3、重新启动 ElasticSearch 服务,在启动过程中,你可以看到正在加载**“analysis-ik”**插件的提示信息,服务启动后,在命令行运行 elasticsearch-plugin list 命令,确认 ik 插件安装成功。

4、在 kibana 中测试 ik 分词器,并就相关分词结果和 icu 分词器进行对比。
ik_max_word :
细粒度分词,会穷尽一个语句中所有分词可能

ik_smart :
粗粒度分词,优先匹配最长词,只有1个词!

5、我们输入超级喜欢狂神说!发现狂神说被切分了
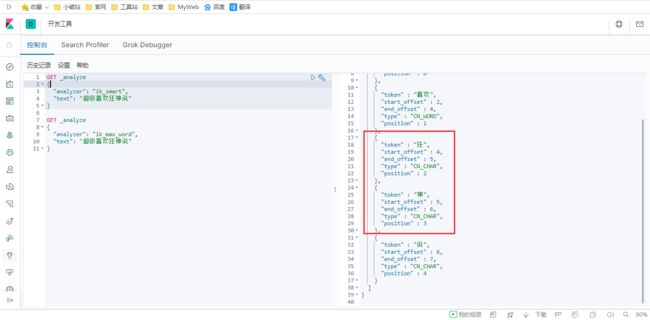
如果我们想让系统识别【狂神说】是一个词,需要编辑自定义词库。
步骤:
-
进入elasticsearch/plugins/ik/config目录
-
新建一
-
个my.dic文件,编辑内容:
狂神说 -
修改IKAnalyzer.cfg.xml(在ik/config目录下)
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">my.dicentry>
<entry key="ext_stopwords">entry>
properties>
修改完配置重新启动elasticsearch,再次测试!
发现监视了我们自己写的规则文件:

再次测试,发现【狂神说】变成了一个词:

到了这里,我们就明白了分词器的基本规则和使用了!
Rest风格说明
- 一种软件架构风格,而不是标准
- 只是提供了一组设计原则和约束条件。
- 它主要用于客户端和服务器交互类的软件。
- 基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
基本Rest命令说明:
| method(方法) | url(地址) | 描述 | 类比数据库 |
|---|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) | 指定库、表后,插入行(指定ID) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) | 指定库、表后,插入行(不指定ID) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 | 指定库、表,修改指定行 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 | 指定库、表,删除指定行 |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档id | 指定库、表,获取指定行 |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 | 指定库,获取指定表的所有行数据 |
基础测试
1、首先我们浏览器 http://localhost:5601/ 进入 kibana里的Console
2、首先让我们在 Console 中输入 :
// 命令解释
// 【PUT 创建命令】【test1 索引】 【type1 类型】 【1 id】
PUT /test1/type1/1
{
"name":"狂神说",
"age":16
}
返回结果 (是以REST ful 风格返回的 ):
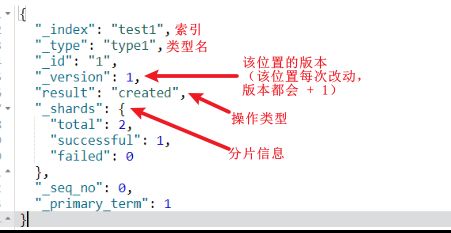
// 警告信息:不支持在文档索引请求中指定类型
// 而是使用无类型的端点(/{index}/_doc/{id}, /{index}/_doc,或 {index}/_create/{id})。
{
"_index" : "test1", // 索引
"_type" : "type1", // 类型
"_id" : "1", // id
"_version" : 1, // 版本
"result" : "created", // 操作类型
"_shards" : { // 分片信息
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
3、那么 name 这个字段用不用指定类型呢?
-
字符串类型:text、keyword
-
数值类型:long、integer、 short、 byte、 double、 float、 half_float、 scaled_float
-
日期类型:date
-
布尔值类型:boolean
-
二进制类型:binary
-
等等…
4、指定字段类型(可以显示指定,否则默认指定)
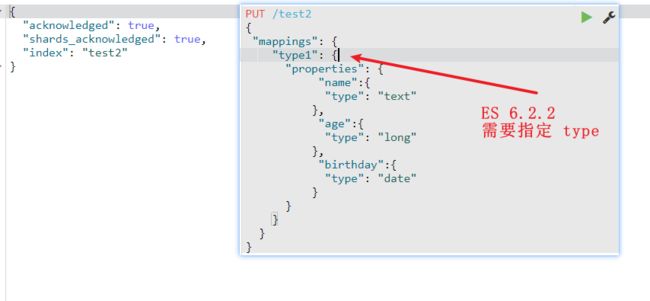
PUT /test2
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
}
}
}
}
输出:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test2"
}
注意:
ES 7.x 版本开始,可以直接在创建 Index 时指定字段类型,因为会有一个默认的 Type 为_doc
ES 6.x版本的话,不能这样操作,需要在指定的 type 中才能,如果不指定,则报错
修改前
修改后

5、查看一下索引字段
GET test2
输出:
{
"test2": {
"aliases": {},
"mappings": {
"type1": {
"properties": {
"age": {
"type": "long"
},
"birthday": {
"type": "date"
},
"name": {
"type": "text"
}
}
}
},
"settings": {
"index": {
"creation_date": "1651125126686",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "fLR2SE0WRAKn-wne5tnLbg",
"version": {
"created": "6020299"
},
"provided_name": "test2"
}
}
}
}
6、我们看上列中 字段类型是我自己定义的,那么如果 我们不定义类型 会是什么情况呢?
PUT /test3/_doc/1
{
"name":"狂神说",
"age":13,
"birth":"1997-01-05"
}
输出
{
"_index": "test3",
"_type": "_doc",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
查看一下test3索引:
GET test3
返回结果
{
"test3": {
"aliases": {},
"mappings": {
"_doc": {
"properties": { //这里可以看到属性类型(被自动设置了!)
"age": {
"type": "long"
},
"birth": {
"type": "date"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
},
"settings": {
"index": {
"creation_date": "1651125346147",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "kaXOU_zzSNWmaxsbTCEl5g",
"version": {
"created": "6020299"
},
"provided_name": "test3"
}
}
}
}
我们看上列没有给字段指定类型那么es就会默认给我配置字段类型!
对比关系型数据库 :
PUT test1/type1/1 : 索引test1相当于关系型数据库的库,类型type1就相当于表 ,1 代表数据中的主键 id
-
这里需要补充的是 ,在 elastisearch5 版本前,一个索引下可以创建多个类型
-
但是在 elastisearch5 后,一个索引只能对应一个类型
-
而id相当于关系型数据库的主键id
-
如果不指定,就会默认生成一个20位的 uuid,属性相当关系型数据库的 column(列)。
-
而结果中的 result 则是操作类型,现在是 created ,表示第一次创建。
-
如果再次点击执行该命令那么result 则会是 updated
-
我们细心则会发现 _version 开始是1,现在你每点击一次就会增加一次。表示该位置的第几次更改。
7、我们在来学一条命令 (elasticsearch 中的索引的情况) :
GET _cat/indices?v
返回结果:查看我们所有索引的状态健康情况 分片,数据储存大小等等。

8、那么怎么删除一条索引呢(库)呢?
DELETE /test1
返回
{
"acknowledged" : true # 表示删除成功!
}
增删改查命令
PUT :创建数据
第一条数据:
PUT /kuangshen/user/1
{
"name":"狂神说",
"age":18,
"desc":"一顿操作猛如虎,一看工资2500",
"tags":["直男","技术宅","温暖"]
}
第二条数据 :
PUT /kuangshen/user/2
{
"name":"张三",
"age":3,
"desc":"法外狂徒",
"tags":["渣男","旅游","交友"]
}
第三条数据:
PUT /kuangshen/user/3
{
"name":"李四",
"age":30,
"desc":"mmp,不知道怎么形容",
"tags":["靓女","旅游","唱歌"]
}
查看下数据:

注意⚠ :当执行命令时,如果数据不存在,则新增该条数据,如果数据存在,则覆盖更新该条数据。
(通过 /index/type/id 的 id 进行指定)
通过 GET 命令查询一下 :
GET kuangshen/user/1
返回结果:
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "狂神说",
"age" : 18,
"desc" : "一顿操作猛如虎,一看工资2500",
"tags" : [
"直男",
"技术宅",
"温暖"
]
}
}
如果你想更新数据 可以【通过指定 id 】来覆盖这条数据 :
PUT /kuangshen/user/1
{
"name":"狂神说Java",
"age":18,
"desc":"一顿操作猛如虎,一看工资2.5",
"tags":["直男","技术宅","温暖"]
}
返回结果:
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
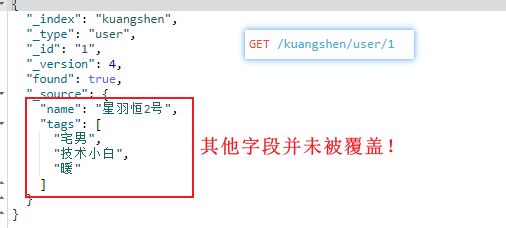
PUT 确实可以更新数据,但这是覆盖更新
PUT /kuangshen/user/1 { "name":"星羽恒", "tags":["宅男","技术小白","暖"] }
就好比数据库中,想要更新某一行的某列的数据,
则需要先把其他列的信息原封不动地填入
这显然是不符合预期的,所谓【覆盖更新】
所以 PUT 更适合用来新增数据
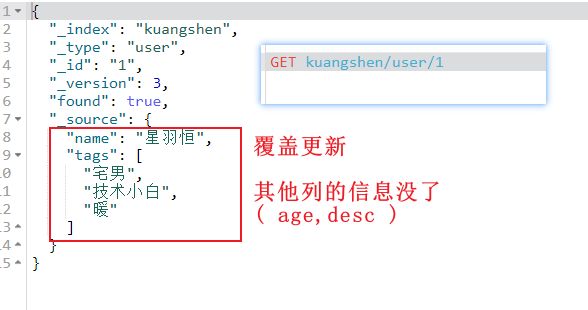
那怎样是我们想要的更新呢?↓
POST + /_update:更新数据
我们使用 POST 命令,在 id 后面跟 /_update ,要修改的指定字段放到 doc 文档(属性)中即可。
POST /kuangshen/user/1/_update
{
"doc":{
"name":"星羽恒2号"
}
}
返回结果
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "1",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1
}
此时再
GET /kuangshen/user/1
GET + /_search**?**q= :条件查询
简单的查询获取,我们上面已经不知不觉的使用熟悉了:
GET kuangshen/user/1
但这是知道了 index 、 type 和 id 的情况下,而大多数情况我们是不知道 id 的
所以需要条件查询(类似数据库中的,where )
GET kuangshen/user/_search?q=name:狂神说
通过 _serarch?q=name:狂神说 查询条件是name属性【有】“狂神说”的那些数据。
注意:这里说的是【有】,完全包含即可,无需完全相同,“真子串”
返回结果:

我们看一下结果
- 返回并不是 数据本身,是给我们了一个 hits (命中),还有 _score得分,
- 就是根据算法算出和查询条件,匹配度高,得分就高。
测试:
// 放入数据
PUT /kuangshen/user/4
{
"name":"羽恒12",
"age": 18
}
PUT /kuangshen/user/5
{
"name":"羽234恒",
"age": 18
}
PUT /kuangshen/user/6
{
"name":"羽23456恒",
"age": 18
}
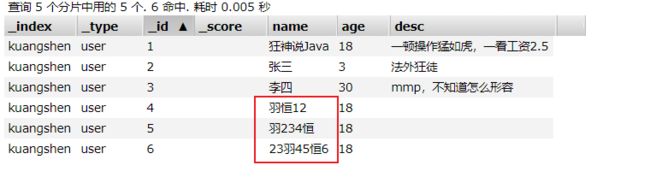
搜索“羽恒”
GET kuangshen/user/_search?q=name:羽恒

构建查询
GET kuangshen/user/_search
{
"query":{
"match":{
"name": "羽恒"
}
}
}
上例,查询条件是一步步构建出来的,将查询条件添加到 match 中即可。返回结果还是一样的:

除此之外,我们还可以获取type中的全部数据
(类似数据库:select * from table_name,获取某个表的所有数据行)
这是一个查询但是没有条件
GET kuangshen/user/_search
match_all的值为空,表示没有查询条件,也一样。
GET kuangshen/user/_search
{
"query":{
"match_all": {}
}
}
返回结果:该 index/type 下的,全部查询出来了!
如果有个需求,我们仅是需要查看 name 和 desc 两个属性,其他的不要怎么办?
类似【select name , desc from table_name】
GET kuangshen/user/_search
{
"query":{
"match_all": {}
},
"_source": ["name","desc"]
}
如上例所示,在查询中,通过 _source 来控制仅返回 name 和 age 属性。
- 注意:是有哪个就返回哪个,都有就都返回
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 6,
"max_score": 1,
"hits": [
{
"_index": "kuangshen",
"_type": "user",
"_id": "5",
"_score": 1,
"_source": {
"name": "羽234恒" //只有 name,没有 desc
}
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "2",
"_score": 1,
"_source": {
"name": "张三",
"desc": "法外狂徒"
}
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "4",
"_score": 1,
"_source": {
"name": "羽恒12"
}
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "6",
"_score": 1,
"_source": {
"name": "23羽45恒6"
}
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "1",
"_score": 1,
"_source": {
"name": "狂神说Java",
"desc": "一顿操作猛如虎,一看工资2.5"
}
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "3",
"_score": 1,
"_source": {
"name": "李四",
"desc": "mmp,不知道怎么形容"
}
}
]
}
}
- 一般的,我们推荐使用构建查询
- 以后在与程序交互时的查询等也是使用构建查询方式处理查询条件
- 因为该方式可以构建更加复杂的查询条件,也更加一目了然
排序查询
我们说到排序,有人就会想到:【正序】 或 【倒序】, 那么我们先来倒序:
- sort 与 query 同级
GET kuangshen/user/_search
{
"query":{
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
上例,在条件查询的基础上,我们又通过 sort 来做排序,排序字段是 age , order 是 desc 降序。
"sort": [
{
"排序字段": {
"order": "desc降序 / asc 升序"
}
}
索引中:

结果
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 6,
"max_score": null,
"hits": [
{
"_index": "kuangshen",
"_type": "user",
"_id": "3",
"_score": null,
"_source": {
"name": "李四",
"age": 30, // 30
"desc": "mmp,不知道怎么形容",
"tags": [
"靓女",
"旅游",
"唱歌"
]
},
"sort": [
30
]
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "5",
"_score": null,
"_source": {
"name": "羽234恒",
"age": 22 // 22
},
"sort": [
22
]
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "4",
"_score": null,
"_source": {
"name": "羽恒12",
"age": 21 // 21
},
"sort": [
21
]
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "6",
"_score": null,
"_source": {
"name": "23羽45恒6",
"age": 20
},
"sort": [
20
]
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "1",
"_score": null,
"_source": {
"name": "狂神说Java",
"age": 18,
"desc": "一顿操作猛如虎,一看工资2.5",
"tags": [
"直男",
"技术宅",
"温暖"
]
},
"sort": [
18
]
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "2",
"_score": null,
"_source": {
"name": "张三",
"age": 3,
"desc": "法外狂徒",
"tags": [
"渣男",
"旅游",
"交友"
]
},
"sort": [
3
]
}
]
}
}
正序,就是 desc 换成了 asc
GET kuangshen/user/_search
{
"query":{
"match_all": {}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
注意:在排序的过程中,只能使用【可排序的属性】进行排序。
那么可以排序的属性有哪些呢?
- 数值型
- 日期:date
- ID
其他都不行!
分页查询
添加字段 from 和 size
"from": n, //取第 n 页
"size": m //每页 m 条
如,根据 id 排序升序后,每页2条,取第2页,
则预想中是取到第二个红框对应的数据:李四 + 羽恒12

GET kuangshen/user/_search
{
"query":{
"match_all": {}
},
"sort": [
{
"_id": {
"order": "asc"
}
}
],
"from": 2,
"size": 2
}
返回结果:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 6,
"max_score": null,
"hits": [
{
"_index": "kuangshen",
"_type": "user",
"_id": "3",
"_score": null,
"_source": {
"name": "李四",
"age": 30,
"desc": "mmp,不知道怎么形容",
"tags": [
"靓女",
"旅游",
"唱歌"
]
},
"sort": [
"3"
]
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "4",
"_score": null,
"_source": {
"name": "羽恒12",
"age": 21
},
"sort": [
"4"
]
}
]
}
}
确实如此!
学到这里,我们也可以看到,我们的查询条件越来越多,开始仅是简单查询,慢慢增加条件查询,增加排序,对返回 结果进行限制。
所以,我们可以说:对elasticsearch于 来说,所有的查询条件都是可插拔的,彼此之间可以分割。
布尔查询
先增加一个数据:
PUT /kuangshen/user/4
{
"name":"狂神说",
"age":3,
"desc":"一顿操作猛如虎,一看工资2500",
"tags":["直男","技术宅","温暖"]
}
must (类似数据库中的 AND )
我要查询所有 name 属性含“羽恒 ”的数据,并且年龄为20岁的!
GET kuangshen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "羽恒"
}
},
{
"match": {
"age": 20
}
}
]
}
}
}
我们通过在 bool 属性内使用 must 来作为查询条件!看结果,是不是有点像 and 的感觉,里面的条件(match)需要都满足(包含,或等于)!
should (类似数据库中的 OR)
那么我要查询 name 为狂神 或 age 为18 的呢?
将 must 改为 should 即可!
GET kuangshen/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "羽恒"
}
},
{
"match": {
"age": 20
}
}
]
}
}
}
返回结果
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 1.7803833,
"hits": [
{
"_index": "kuangshen",
"_type": "user",
"_id": "6",
"_score": 1.7803833,
"_source": {
"name": "23羽45恒6",
"age": 20
}
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "2",
"_score": 1,
"_source": {
"name": "张三",
"age": 20,
"desc": "法外狂徒",
"tags": [
"渣男",
"旅游",
"交友"
]
}
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "4",
"_score": 0.98010236,
"_source": {
"name": "羽恒12",
"age": 21
}
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "5",
"_score": 0.5753642,
"_source": {
"name": "羽234恒",
"age": 22
}
}
]
}
}
返回的结果中,有 age = 20 的,有 name 包含 羽恒 的
must_not (类似数据库中的 NOT)
我想要查询 年龄不是 18 的 数据
GET kuangshen/user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"age": 18
}
}
]
}
}
}
Filter (范围过滤)
- 前面的 must 和 not ,都是绝对的 = 和 !=
- 而 filter 就是用来 < 、>、<=、>= 的
查询所有 age大于10,小于等于20 的数据
GET kuangshen/user/_search
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
}
}
}
结果
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 0,
"hits": [
{
"_index": "kuangshen",
"_type": "user",
"_id": "6",
"_score": 0,
"_source": {
"name": "23羽45恒6",
"age": 20
}
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "2",
"_score": 0,
"_source": {
"name": "张三",
"age": 20,
"desc": "法外狂徒",
"tags": [
"渣男",
"旅游",
"交友"
]
}
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "1",
"_score": 0,
"_source": {
"name": "狂神说Java",
"age": 18,
"desc": "一顿操作猛如虎,一看工资2.5",
"tags": [
"直男",
"技术宅",
"温暖"
]
}
}
]
}
}
这里就用到了 filter 条件过滤查询,过滤条件的范围用 【range】表示, 【gt】表示大于,大于多少呢?是10。
其余操作如下 :
- gt :大于
- gte :大于等于
- lt :小于
- lte :小于等于
短语检索
要查询 tags 包含“男”的数据
GET kuangshen/user/_search
{
"query":{
"match": {
"tags": "男"
}
}
}
返回了所有标签中带【男】的记录
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.2876821,
"hits": [
{
"_index": "kuangshen",
"_type": "user",
"_id": "2",
"_score": 0.2876821,
"_source": {
"name": "张三",
"age": 20,
"desc": "法外狂徒",
"tags": [
"渣男", //男
"旅游",
"交友"
]
}
},
{
"_index": "kuangshen",
"_type": "user",
"_id": "1",
"_score": 0.2876821,
"_source": {
"name": "狂神说Java",
"age": 18,
"desc": "一顿操作猛如虎,一看工资2.5",
"tags": [
"直男", //男
"技术宅",
"温暖"
]
}
}
]
}
}
既然按照标签检索,那么,能不能写多个标签呢?
基于分词器的特点,空格左右算一个词,所以用空格间隔即可。
(当然,也可以不用空格,细粒度下会自动分词)
GET kuangshen/user/_search
{
"query":{
"match": {
"tags": "男友"
}
}
}
返回:只要含有其中一个标签的,就返回。
term:查询精确查询
term 查询是【直接通过倒排索引】指定的词条,也就是精确查找。
term 和 match的区别:
- match:
- 是经过分析(analyer)的,也就是说,文档是先被分析器处理了
- 根据不同的分析器,分析出的结果也会不同
- 会根据分词结果进行匹配。
- term:
- 是不经过分词的
- 直接去【倒排索引】查找精确的值。
注意 ⚠ :
- 我们现在 用的 es7 版本
- 所以我们用 mappings properties 去给多个字段(fields)指定类型的时候,不能给我们的索引指定类型:
PUT testdb
{
"mappings": {
//"_doc":{ 这是 es 7 之前版本,需要指定的
"properties": {
"name":{
"type":"text"
},
"desc":{
"type": "keyword"
}
}
//}
}
}
插入数据
PUT testdb/_doc/1
{
"name": "狂神说Java name",
"desc": "狂神说Java desc"
}
PUT testdb/_doc/2
{
"name": "狂神说Java name",
"desc": "狂神说Java desc2"
}
上述中 testdb 索引中
- 字段【name】(普通类型)在被查询时会被分析器进行【分词后】匹配查询。
- 而字段【desc】(keyword 类型)不会被分析器处理。
我们来验证一下:
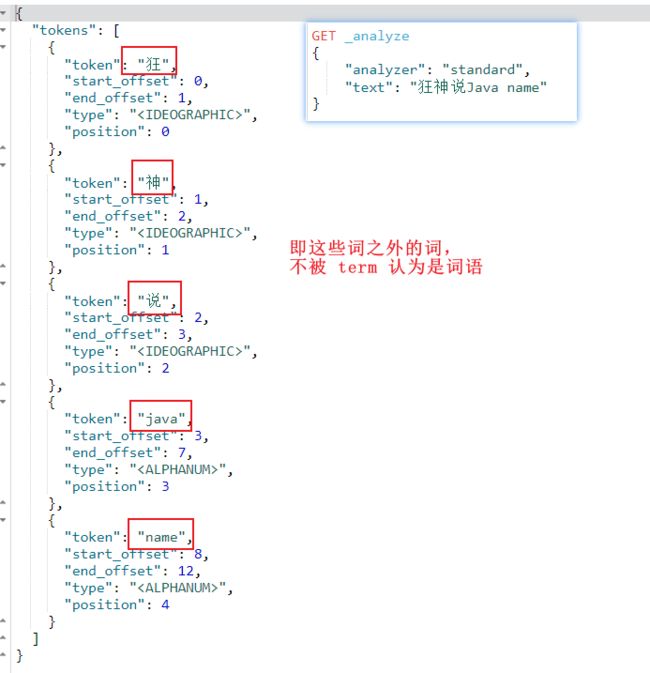
GET _analyze
{
"analyzer": "keyword",
"text": "狂神说Java name"
}
结果:没有被分析,分出来仍然是一整个字符串
- 这也意味着,用 term 去匹配时,只有该字符串才能匹配成功
{
"tokens" : [
{
"token" : "狂神说Java name",
"start_offset" : 0,
"end_offset" : 12,
"type" : "word",
"position" : 0
}
]
}
再测试
GET _analyze
{
"analyzer": "standard",
"text": "狂神说Java name"
}
结果:字符串是不是被分析了,分成了多个词串
- 这也意味着,用 term 去匹配时,只有这些被分出来的词可以匹配成功
{
"tokens": [
{
"token": "狂",
"start_offset": 0,
"end_offset": 1,
"type": "" ,
"position": 0
},
{
"token": "神",
"start_offset": 1,
"end_offset": 2,
"type": "" ,
"position": 1
},
{
"token": "说",
"start_offset": 2,
"end_offset": 3,
"type": "" ,
"position": 2
},
{
"token": "java",
"start_offset": 3,
"end_offset": 7,
"type": "" ,
"position": 3
},
{
"token": "name",
"start_offset": 8,
"end_offset": 12,
"type": "" ,
"position": 4
}
]
}
基于上述认知,此时使用 term 来查询一下:
// 用被分析器分析后的词进行查询,name 是 text ,所以可以被成功分词,而“狂”就在这些词中
GET testdb/_search
{
"query": {
"term": {
"name": "狂"
}
}
}
结果:符合预期

如果用没被分词器分出来的词呢?
GET testdb/_search
{
"query": {
"term": {
"name": "狂神"
}
}
}
结果:为空

GET testdb/_search // keyword 不会被分析,所以直接查询
{
"query": {
"match": {
"desc":"狂神说Java desc"
}
}
}
查找多个精确值(terms)
(略)
官网地址:https://www.elastic.co/guide/cn/elasticsearch/guide/current/_finding_multiple_exact_values.html
PUT testdb/_doc/3
{
"t1": "22",
"t2": "2020-4-16"
}
PUT testdb/_doc/4
{
"t1": "33",
"t2": "2020-4-17"
}
//查询 term 精确查找多个值
GET testdb/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"t1": "22"
}
},
{
"term": {
"t1": "33"
}
}
]
}
}
}
除了bool查询之外:
terms + [词数组]
GET testdb/_doc/_search
{
"query": {
"terms": {
"t1": ["22", "33"]
}
}
}
POST + /_delete_by_query :条件删除
根据上面学习的 query 语句,对匹配到的结果进行删除
如下,将删除 item_index 下,所有 query 到的结果
POST item_index/_delete_by_query
{
"query":{
"term":{
"titleKey":"testItem"
}
}
}
highlight 高亮显示
highlight
"highlight" :{
"fields": {
"name":{} //结果集中,要高亮的字段
}
}
GET kuangshen/user/_search
{
"query":{
"match": {
"name": "狂神"
}
},
"highlight" :{
"fields": {
"name":{}
}
}
}
返回结果:
{
"took": 72,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.5753642,
"hits": [
{
"_index": "kuangshen",
"_type": "user",
"_id": "1",
"_score": 0.5753642,
"_source": {
"name": "狂神说Java",
"age": 18,
"desc": "一顿操作猛如虎,一看工资2.5",
"tags": [
"直男",
"技术宅",
"温暖"
]
},
"highlight": {
"name": [
"狂神说Java"
]
}
}
]
}
}
我们可以看到: 狂神经帮我们加上了一个标签
这是es帮我们加的标签。
我们也可以自定义样式:
"highlight" :{
"pre_tags": "", //前缀
"post_tags": "", //后缀
"fields": {
"name":{}
}
}
GET kuangshen/user/_search
{
"query":{
"match": {
"name": "狂神"
}
},
"highlight" :{
"pre_tags": "", //前缀
"post_tags": "", //后缀
"fields": {
"name":{}
}
}
}
结果:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.5753642,
"hits": [
{
"_index": "kuangshen",
"_type": "user",
"_id": "1",
"_score": 0.5753642,
"_source": {
"name": "狂神说Java",
"age": 18,
"desc": "一顿操作猛如虎,一看工资2.5",
"tags": [
"直男",
"技术宅",
"温暖"
]
},
"highlight": {
"name": [
"狂神说Java"
]
}
}
]
}
}
需要注意的是:
- 自定义标签中属性或样式中的逗号,一律用英文状态的【单引号】表示
- 与外部 es 语法的双引号区分开。
拓展
1、elasticsearch 在第一个版本的开始,每个文档都储存在一个索引中,并分配一个映射类型
2、映射类型用于表示被索引的文档或者实体的类型,这样带来了一些问题
-
导致后来在 elasticsearch6.0.0 版本中,一个文档只能包含一个映射类型
-
而在 7.0.0 中,映射类型则将被弃用,到了 8.0.0 中则将完全被删除。
3、只要记得,一个索引下面只能创建一个类型就行了
-
即,一个 Index 下,实质上只有一个 type
-
这个 type 中有多个字段,每个字段的类型都是唯一的
-
类比数据库而言,一个库只能有一张表,该表中的字段可变,每行数据插进来,有该字段则填充,无该字段则为 null 或扩列。
4、如果在创建Index的映射时,没有指定文档类型名字,那么该索引的默认type的名字就是 _doc
- 不指定文档id则会自动帮我们生成一个id字符串。